[MM] KIMI K2.5: VISUAL AGENTIC INTELLIGENCE
[MM] KIMI K2.5: VISUAL AGENTIC INTELLIGENCE
- paper: https://arxiv.org/pdf/2602.02276
- github: https://github.com/MoonshotAI/Kimi-K2.5
- huggingface: https://huggingface.co/moonshotai/Kimi-K2.5
- archived (인용수: 33회, ‘26-04-02 기준)
- downstream task: multimodal
1. Introduction
- 기존에 LLMs (Gemini 3 Pro / Claude Opus 4.5 / GPT-5.2)는 reasoning 능력 & agentic tool calling 능력의 향상이 되고 있다.
본 테크 리포트에서는 2가지 관점에서 성능을 더욱 끌어 올렸다.
-
Joint Optimization Text & Vision
-
Early fusion vision(10) : text (90)로 token 비율을 학습하는게 middle / late fusion보다 성능이 나음을 실험적으로 증명했음
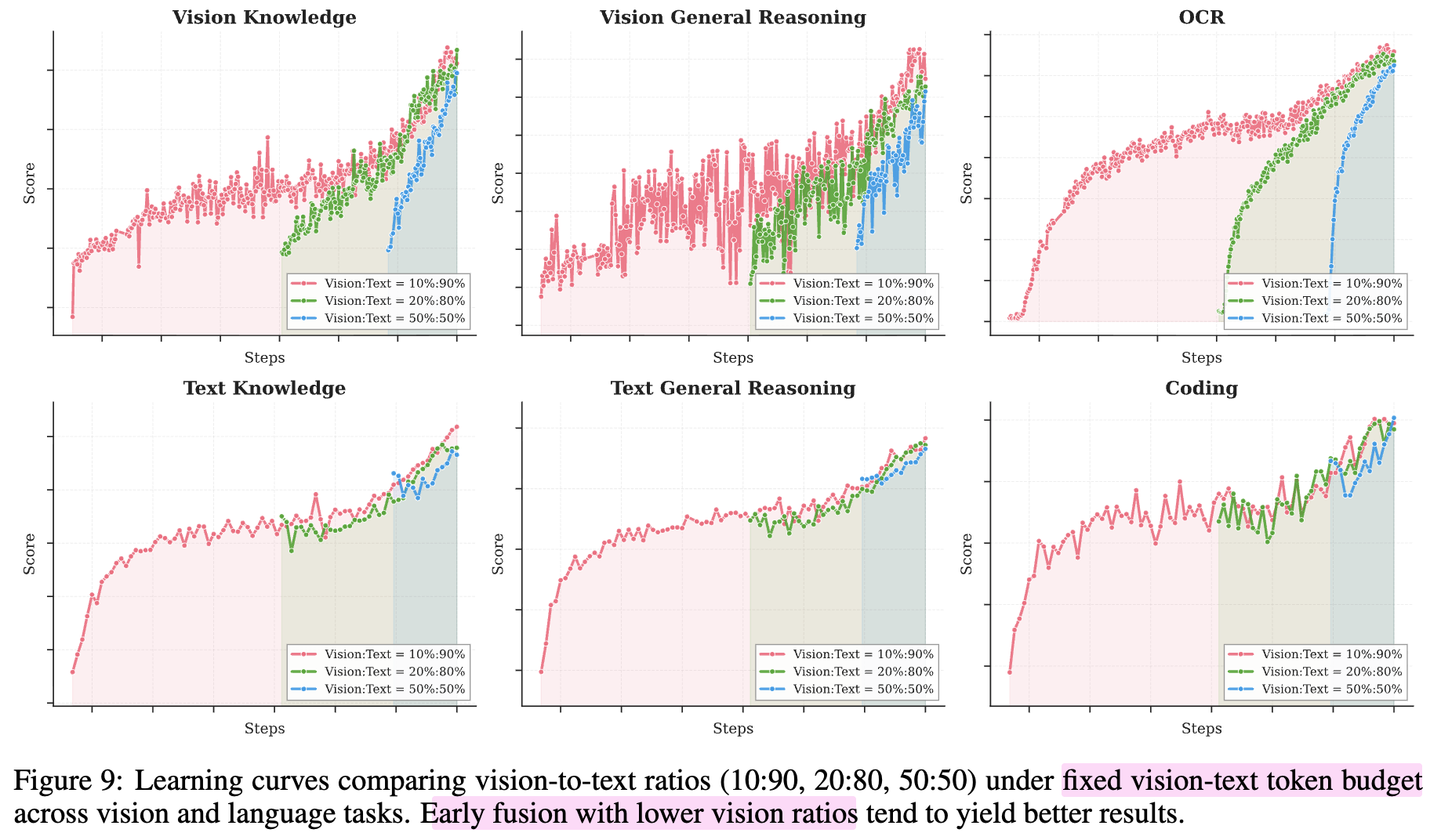
-
Video tokens는 4개의 연속된 frame에 대해 temporal axis로 patch level 평균을 취하였음 $\to$ 이미지 encoder의 강력한 feature를 그대로 활용할수 있게됨 + 4x 긴 비디오 처리가 가능해짐
-
zero-vision SFT를 통해 이미지+text pair가 없더라도, 수많은 text 데이터를 가지고, SFT를 수행함.
- Early fusion Pretraining 덕분에 zero-vision SFT를 하더라도 vision text의 성능 하락 없이 tool-calling 능력 & visual reasoning 능력이 향상됨
-
마지막으로 joint RL로 성능을 더욱 향상시킴
-
-
Agent Swarm: Parellel Agent Orchestration
- 매우 복잡한 테스크를 수행하기 위해 수백 reasoning steps를 처리하다보면 unacceptable latency + limit task complexity 이슈가 생김
- Parallel-Agent Reinforcement Learning (PARL)을 도입하여 agentic RL 학습에 활용함으로써 tool execution을 최적화 시킴.
- sub-agents 호출하는 orchestrator만 학습하고, sub-agents는 freeze함 $\to$ 학습 복잡도를 단순화하여 credit assignment ambiguity를 방지.
- 약 4.5배 latency 향상 + 성능도 72.8% $\to$ 79%로 향상 (item-level F1 score)
2. Joint Optimization of Text and Vision
2.1 Pretraining
-
기존 방식 (Qwen-3-VL)
- 초기에 Text tokens만 학습하고, later stages (SFT)에 높은 비율(50%)로 visual token을 fusion하는 방식 (post-hoc add-on)
-
제안 방식 (Native Multimodal Pre-Trianing)
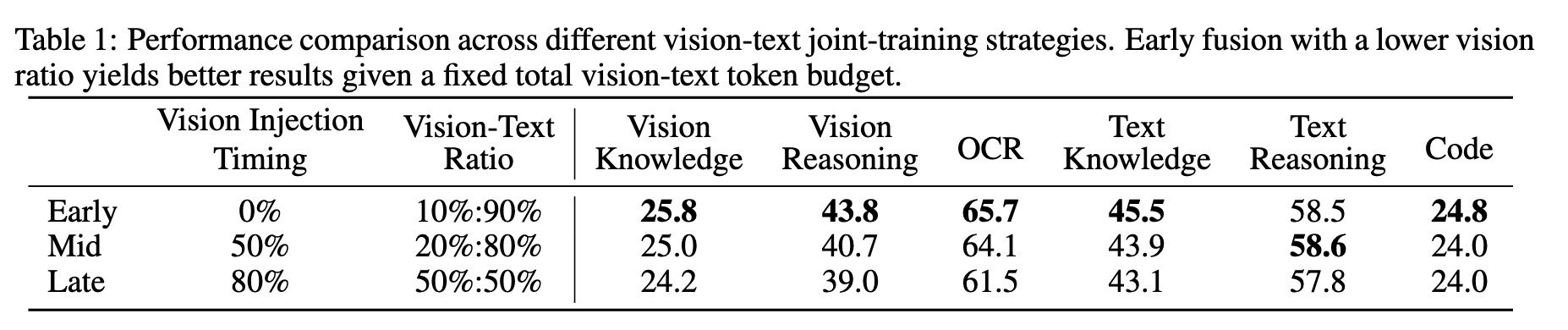
- Pretraining시점부터 joint하게 visual + text tokens를 활용하는 방식
- 단, visual token의 비율을 낮추는게 효과적임 (10%)
2.2 Zero-Vision SFT
-
기존 방식
- Pretraining VLMs는 vision기반의 tool-calling을 수행하지 못해, cold-start 문제를 겪는다.
- 즉, 수동으로 라벨링하거나 prompt engineering으로 CoT data를 생성하여 학습데이터를 만듦. $\to$ 제약이 있음
- Pretraining VLMs는 vision기반의 tool-calling을 수행하지 못해, cold-start 문제를 겪는다.
-
제안 방식
-
motivation: 고품질 text SFT 데이터는 다양하고 풍부하게 존재함. Pretraining시에 vision을 충분히 학습했으므로, zero-vision SFT를 통해 visual & agentic(tool-calling) 능력을 활용할 수 있음
-
object size 예측 (binarization & counting)

-
-
2.3 Joint Multimodal RL
-
Outcome based RL
- visual 입력에 대한 reasoning이 필수적이므로, 추가 RL 학습이 필요
- Visual Grounding & counting
- Chart & Document understanding : structuerd visual information & text 추출
- Vision-critical STEM 문제들
- visual 입력에 대한 reasoning이 필수적이므로, 추가 RL 학습이 필요
-
Rejection-Sampling Fine-tuning (RFT)를 통해 self-improving data pipeline를 중간에 추가 학습
-
그 이후 RL 학습
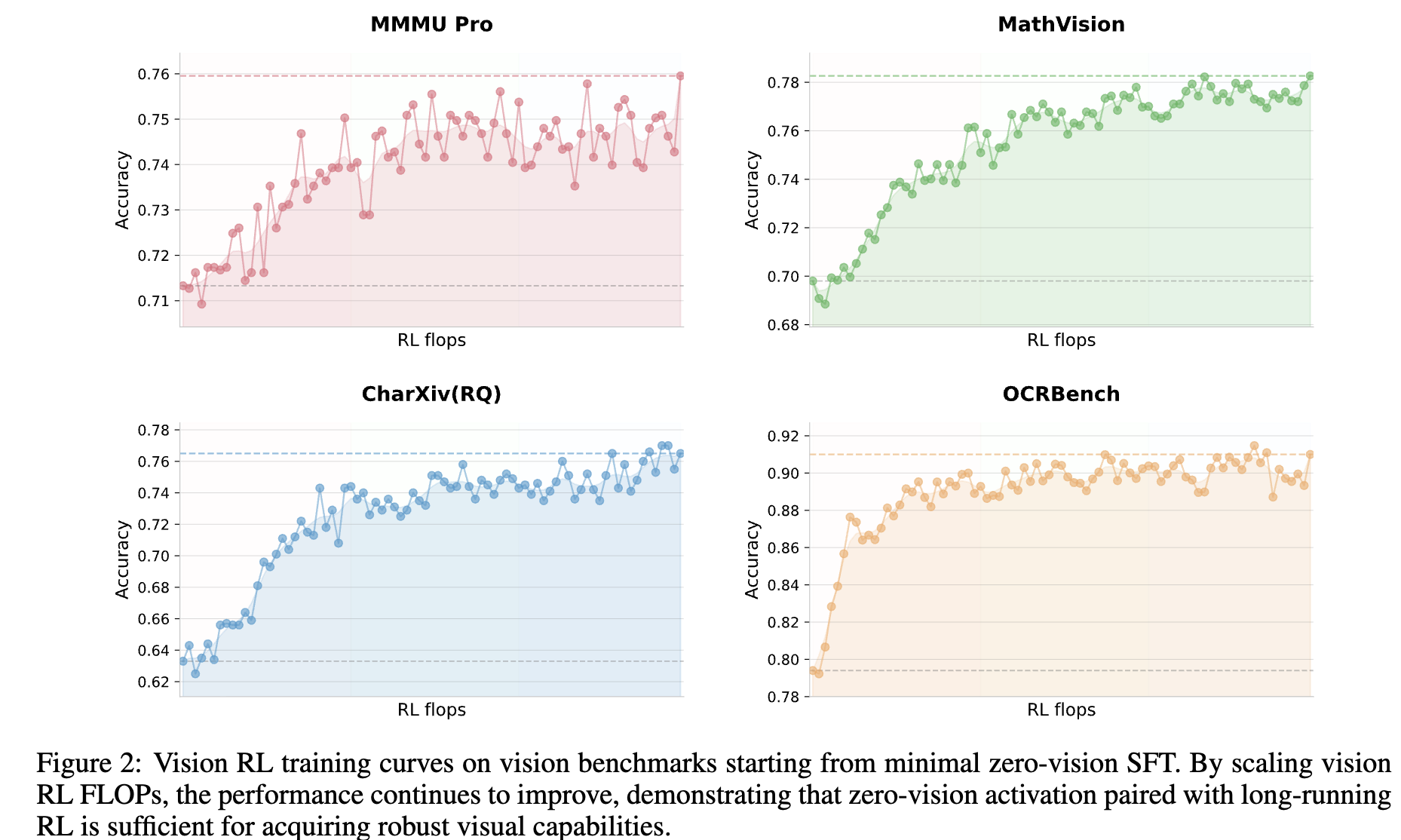
-
Vision RL이 textual tasks의 성능도 향상시킴
