[Agent] ZeroGUI: Automating Online GUI Learning at Zero Human Cost
[Agent] ZeroGUI: Automating Online GUI Learning at Zero Human Cost
- paper: https://arxiv.org/pdf/2505.23762
- github: https://github.com/OpenGVLab/ZeroGUI
- archived (인용수: 0회, ‘25-08-19 기준)
- downstream task: GUI Navigation (OSWorld, AndroidApp)
1. Motivation
-
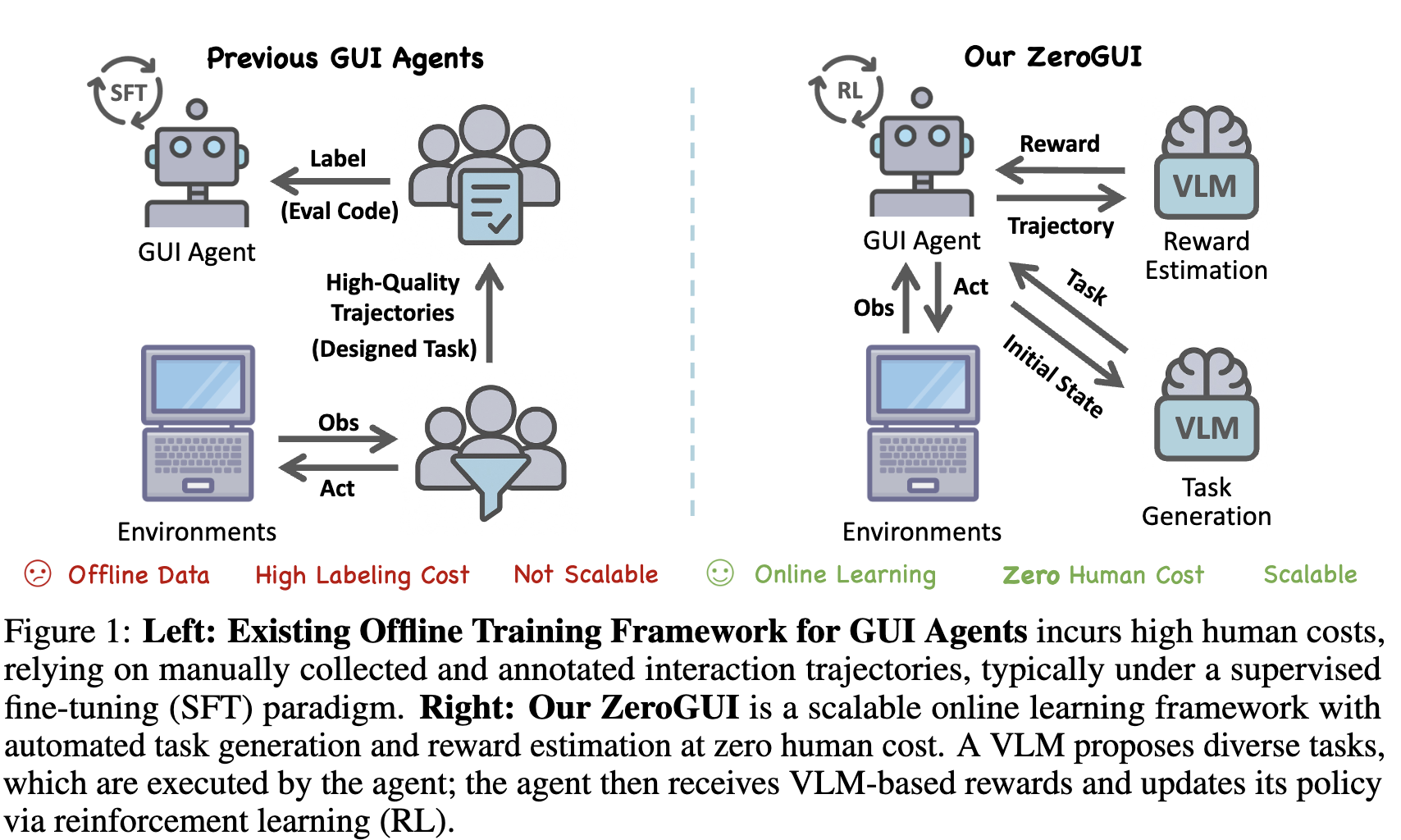
기존의 GUI Agent는
- 고품질의 수동 라벨 (element grounding, action trajectory)을 요구하므로
- 동적 & 상호작용하는 환경에 적응하는데 한계가 많다.
- 대부분의 GUI benchmark는 학습셋을 제공하지 않고, real-world task는 label이 부족하다.
$\to$ 자동으로 new task를 생성하고, reward를 메길수 있는 시스템을 연구해보자!
2. Contribution
- 사람의 라벨이 필요없는 online-learning framework인 ZeroGUI를 제안
- VLM 기반으로 새로운 task를 생성
- VLM 기반으로 reward를 생성
- 2단계의 학습 방법 제안
- generated task 기반 학습하는 step
- test-time adaptation step
- 다양한 GUI 환경에서 success rate를 향상시킴
3. ZeroGUI
-
Formulation
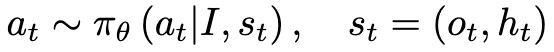
- I: 이미지
- $s_t$: t step에서 state
- $o_t$: t step에서 관측값
- $h_t$: 이전 step에서 observation + action history
-
Trajectory
-
Overall Diagram
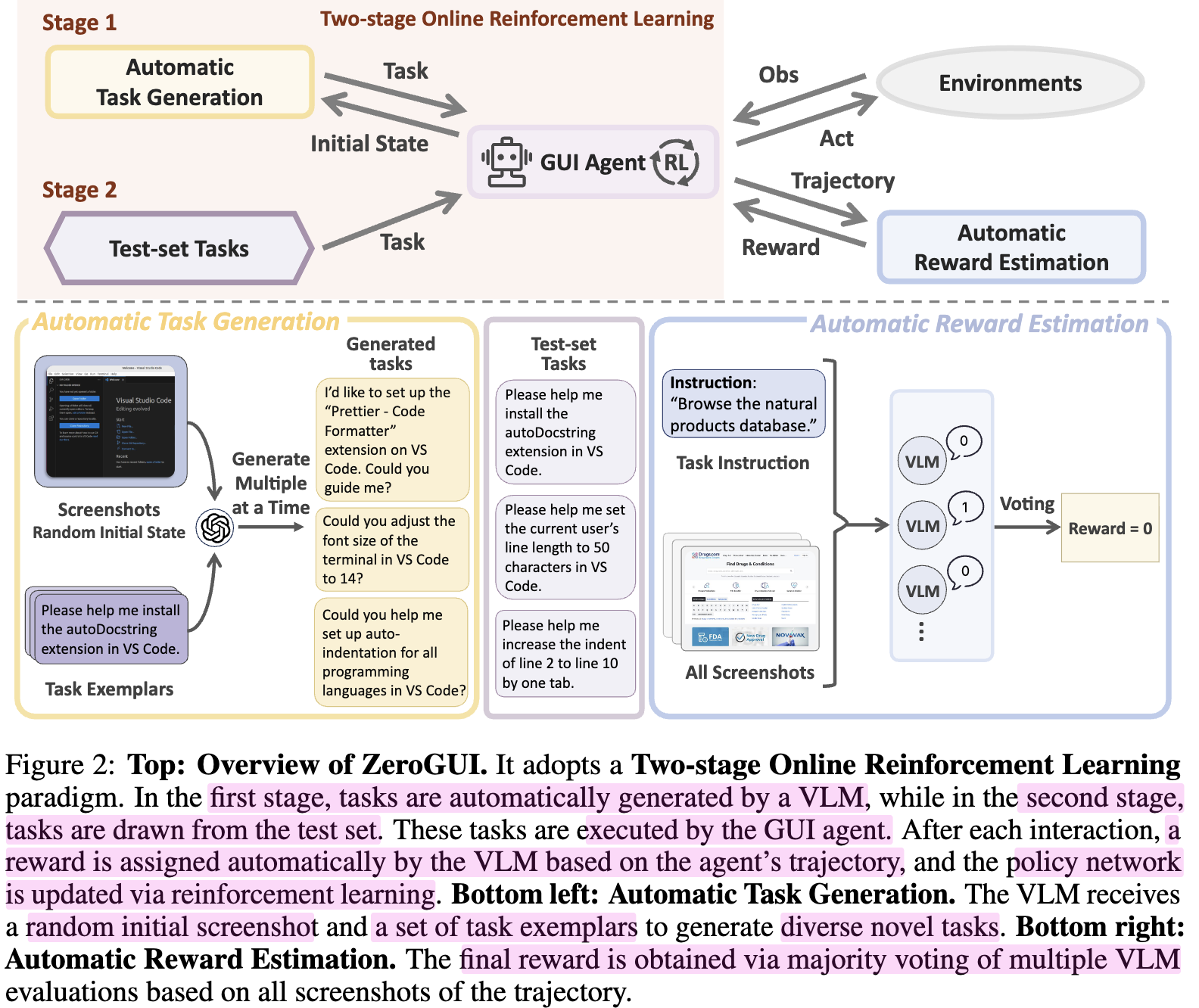
3.1 Automatic Task Generation
- Exempler-Guided Prompting
- Benchmark에서 제공하는 예시 task와 임의의 inital screenshot을 기반으로 다양하되, operation constraint를 만족하는 new task를 생성
- Multi-Candidate Generation
- MLLM에게 한 번이 아닌, 여러번 후보 tasks를 생성하도록 하여 다양성을 확보
3.2 Automatic Reward Estimation
-
기존의 reward system은 복잡한 command으로 구성된 script로 file의 content를 체크하거나 system state를 확인하였음
$\to$ 이는 비용효율적이지 않음
-
VLM기반의 reward 시스템으로 하게 되면, 비용 효율적이나 FN / FP가 발생할 소지가 있음
-
여러 VLM 후보에게 voting을 시켜 견고한 reward를 산출하도록 함
- FP가 성능 하락에 더욱 민감하다는 점에 착안하여, 전체 screenshot history를 다 입력
- agent의 action history는 제거함 (hallunication 우려)
-
3.3 Two Stage Online Reinforcement Learning
-
New task로 학습하는것 뿐만 아니라, Test-time Adaptation을 적용하고자 함 (GRPO 기반)
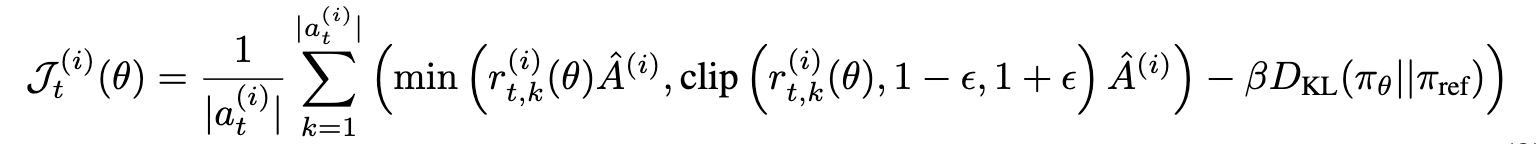
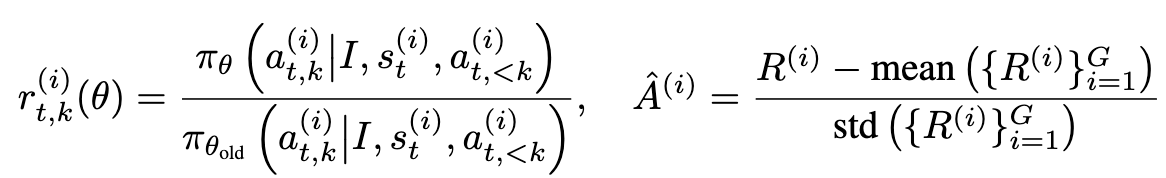
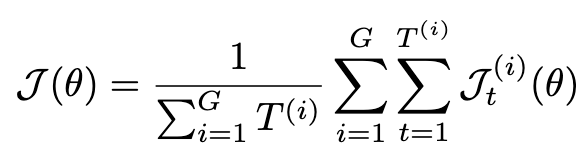
-
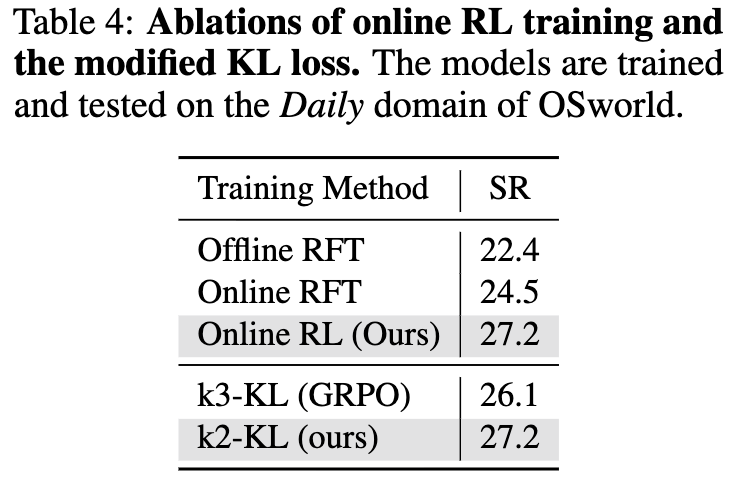
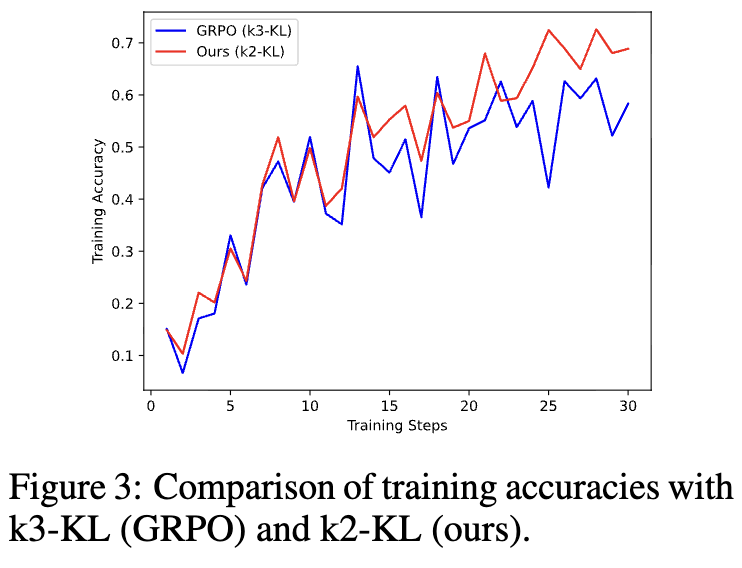
KLD Loss가 gradient가 너무 커지므로 학습의 안정성을 헤쳐, L2 loss로 바꿈
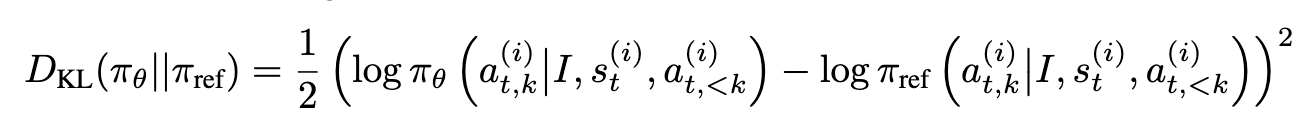
4. Experiments
-
Evaluation Metrics
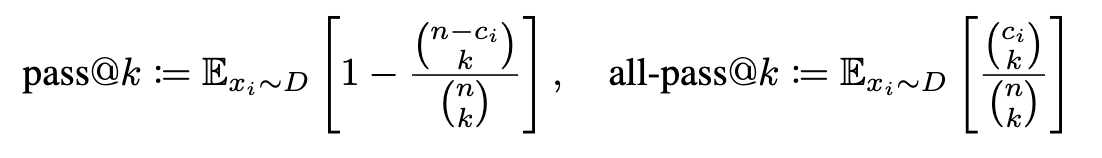
-
Benchmark
- AndroidLab
- OSWorld
-
Task Generation
- GPT-4o로 OSWorld/AndoridLab을 각각 725/175 개씩 생성
-
Reward System
- Qwen-2.5-VL-32B x 4번 query
-
Policy Model
- UI-TARS-7B-DPO
- Aguvis-7B
-
rollout step
- DAPO Dynamic Sampling 기반 16K sequences 취득
-
정량적 결과
-
OSWorld
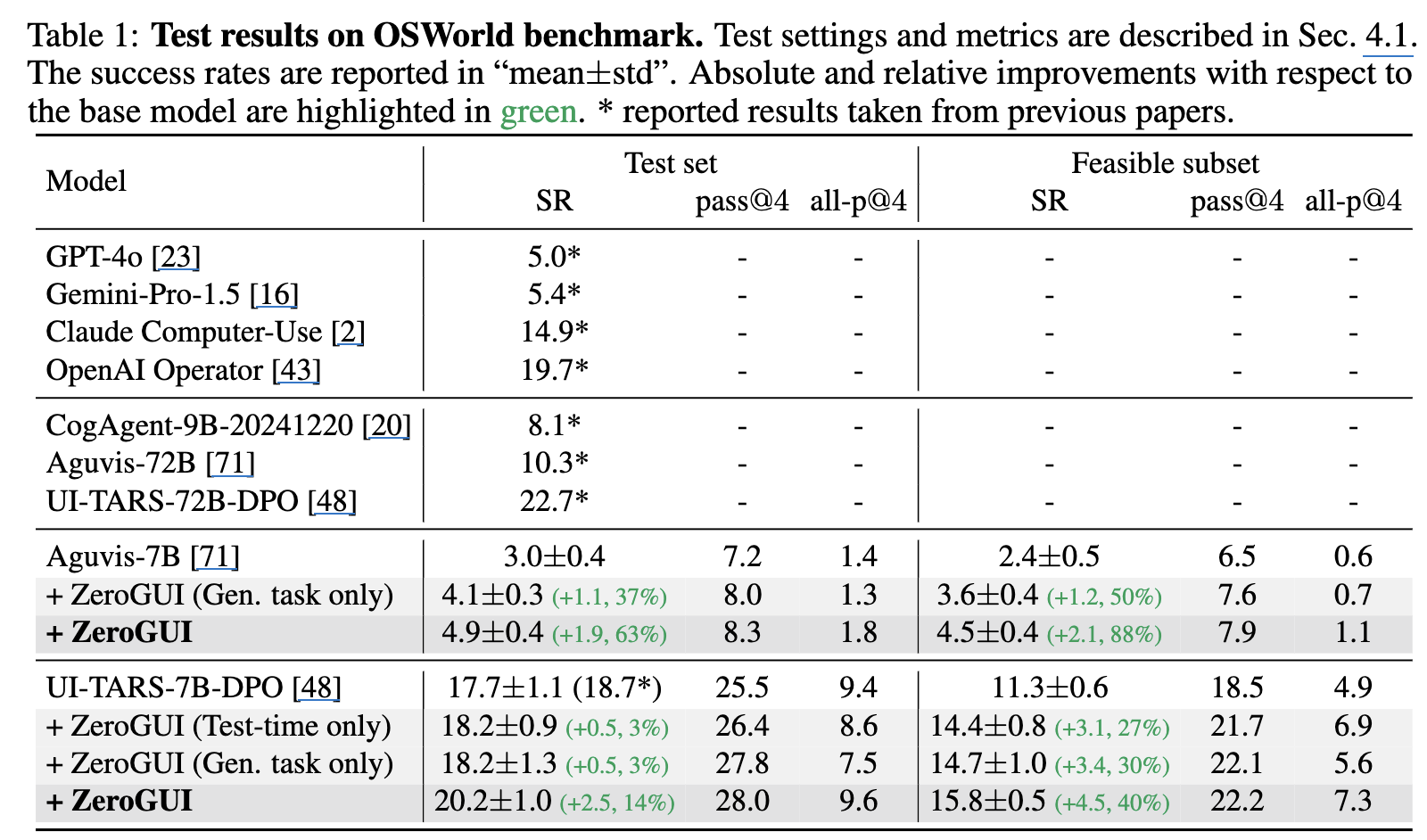
-
AndroidLap
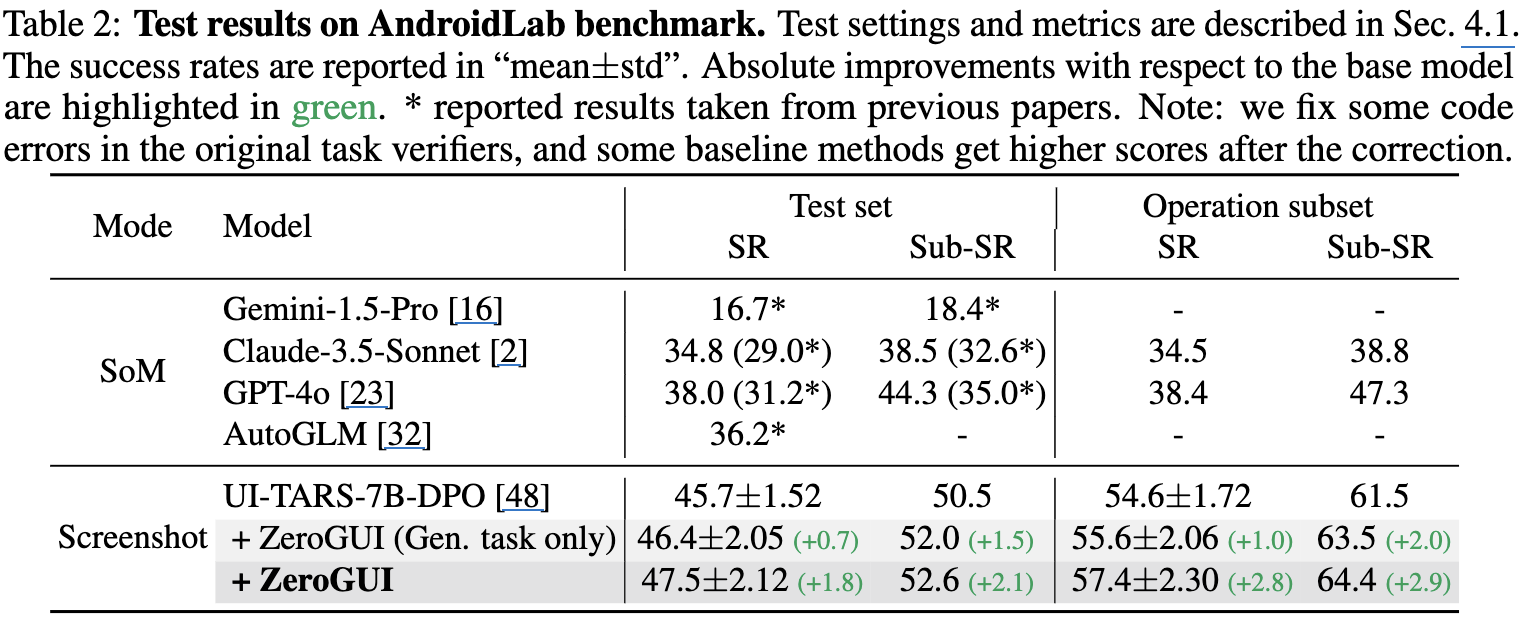
-
-
Ablation Studies
-
Example 유/무 & Multi. candidate 유/무 & Reward System 유/무 에 따른 성능 분석
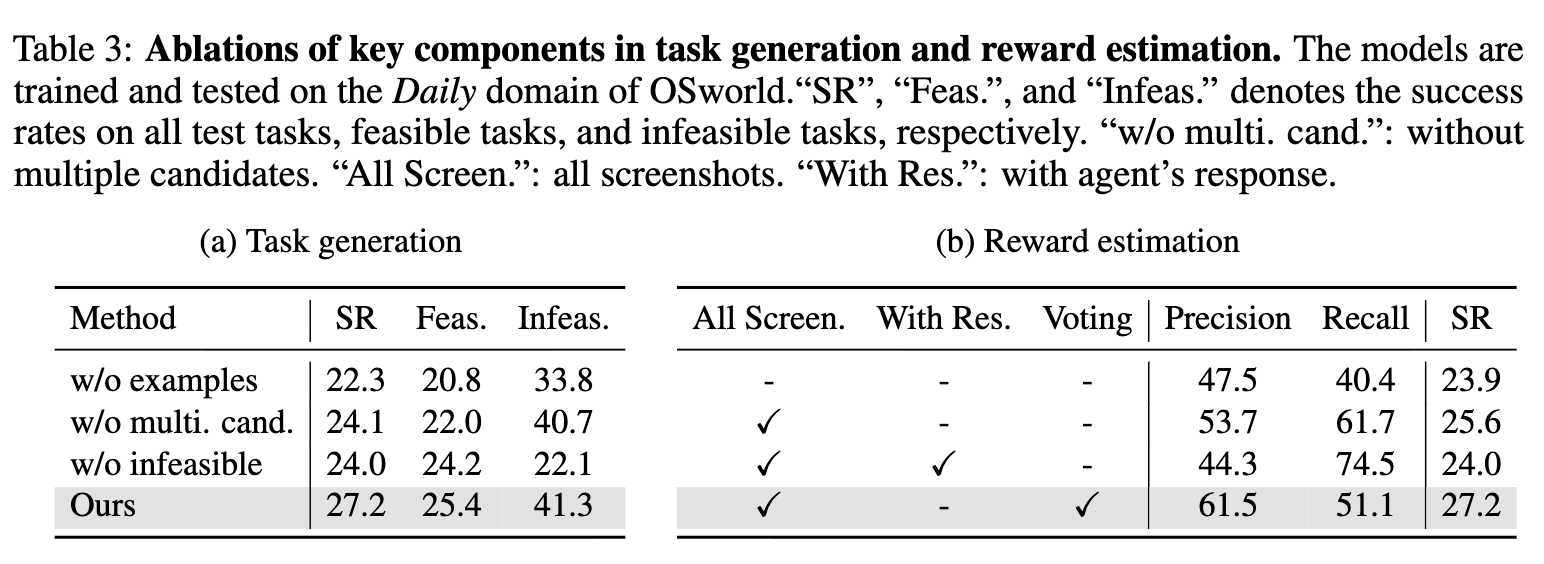
-
KLD Loss에 따른 accuracy & accuracy trajectory
-