[Agent] WEB-SHEPHERD: Advancing PRMs for Reinforcing Web Agents
[Agent] WEB-SHEPHERD: Advancing PRMs for Reinforcing Web Agents
- paper: https://arxiv.org/pdf/2505.15277
- github: https://github.com/kyle8581/Web-Shepherd
- archived (인용수: 0회, ‘25-08-10 기준)
- downstream task: GUI Agent
1. Motivation
-
학습 & test-time 모두에 활용될 specialized reward model이 현재까지 부재하다.
-
기존까지는 Best-of-n 방식으로 test-time에 prompting기반으로 generalist MLLM에게 맡겼다.
-
이는 cost & speed에 큰 문제가 있다.
ex. WebArena의 경우, 812 task를 GPT-4o에 의탁할 경우, $14,000 / A100 x 40hours가 걸린다.
-
-
Step-wise로 reward를 계산하는 모델이 부재하다.
$\to$ process reward model (PRM)을 제안하여 두 가지를 모두 충족시켜보자!
2. Contribution
-
최초로 web navigation의 trajectory를 평가하기 위한 전문가 reward model인 WEB-SHEPHERD를 제안함
-
기존에는 마지막 status만 가지고 reward를 계산하는 ORM (Output Reward Model)임.
-
Web-Shepherd는 중간 step마다 reward를 계산하는 PRM (Process Reward Model)임.
-
Web navigation의 경우, 중간에 instruction에 대한 판단을 필요로 하는 경우가 많음
ex. Refund 가능한 항공 티켓을 예약하는데 8 step이 필요. 하지만, 티켓이 refund가 안된다는건 중간에 알수 있음.
-
Instruction을 sub-instruction (여기서는 checklist)를 출력하도록 학습함.
-
-
-
Web navigation에 필요한 PRM을 학습가 가능한 benchmark인 WebPRM COLLECTION을 제안함
- 사람이 수동으로 labeling한 instruction (easy/medium/hard)로 구성됨
- 40K step-level annotations가 있음
- instruction
- next action prediction
- annotated checklist
-
PRM을 평가하기 위한 benchmark인 WEBREWARD BENCH를 제안함
-
resource-intensive web navigation agent가 불필요한 PRM인 Web-Shepherd는 85%의 정확도를 보임 (GPT-4o-mini보다 10%이상 우수하며 5%의 prompt만 필요)
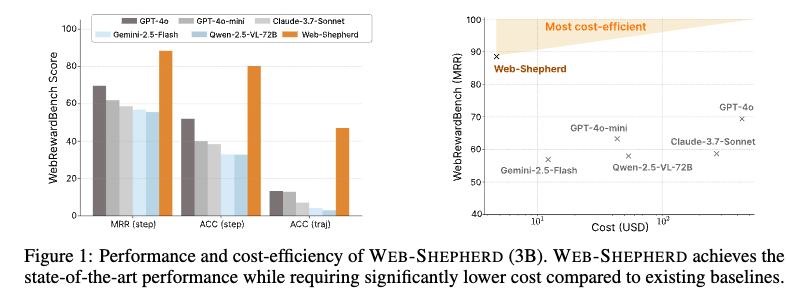
-
3. Web-Shepherd
-
POMDP (Partially Observable Markov Decision Process)

- state space $S$
- action space $A$
- transition function $T$
- reward function $R$
- instruction space $I$
- observation space $O$
3.1 WebPRM Collection
- training data collection
- $(I, O, C, A^+, A^-)$
- $C$: checklist
- $A^+, A^-$: chosen action sequence / rejected action sequence
- $(I, O, C, A^+, A^-)$
3.1.1 Collecting User Instruction & Expert Trajectory
-
Playwright에서 접근 가능한 website list를 Mind2Web dataset에서 취득
-
라벨러들에게 자체 annotation toolkit에 대해 3시간 강의를 수행 후, instruction / 난이도에 대해 라벨링 수행
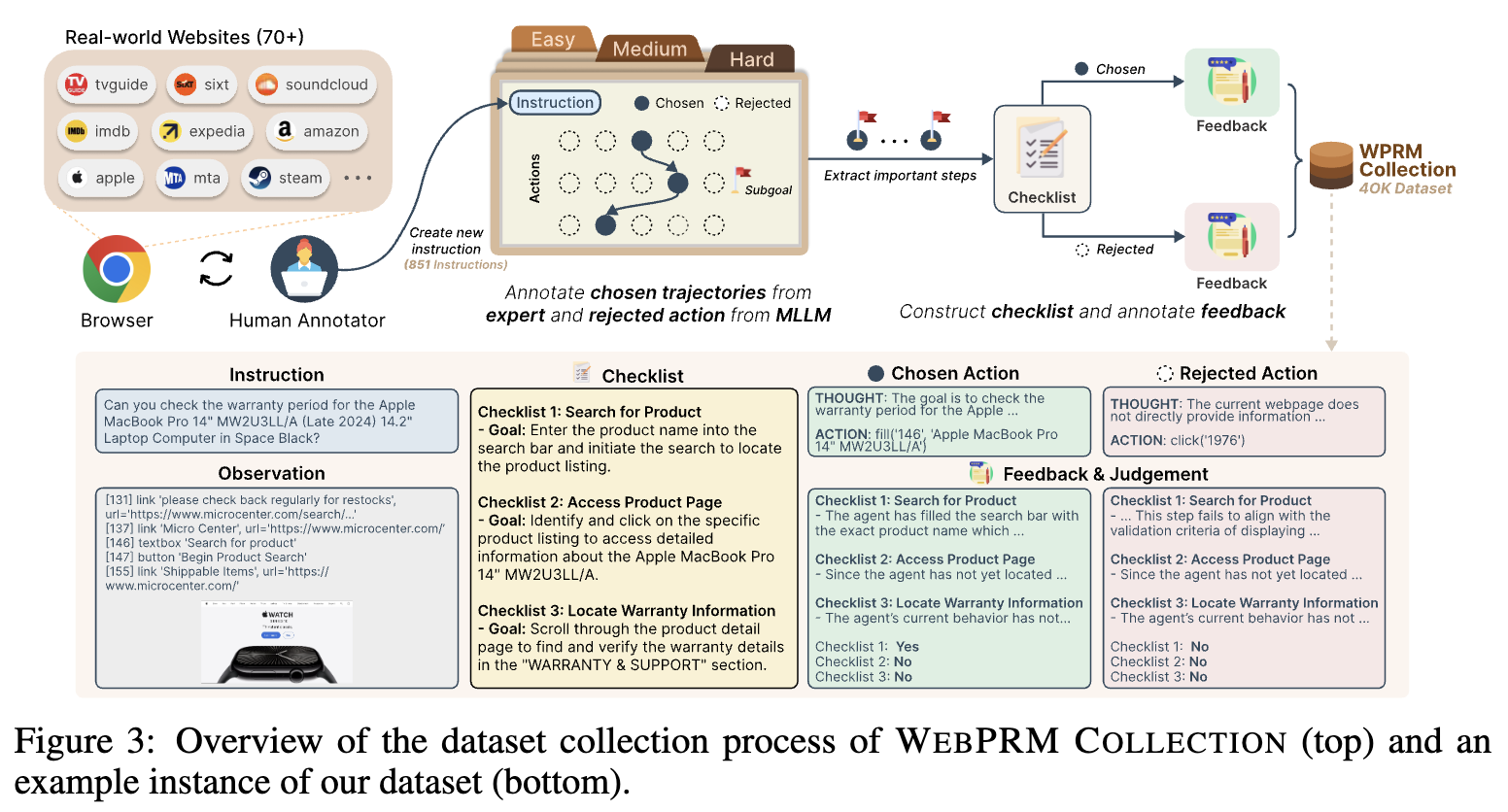
-
10명의 human 검수자 & pm이 검수
3.1.2 Annotating Checklist & Rejected Action
-
Checklist
-
ChatGPT-4o에게 subgoal을 분석(reasoning)하고, checklist를 제공받아 데이터셋 구축
- action의 순서와 무관해지기 위해 coarse한 checklist를 주문함
ex. filter A and filter B $\to$ $filtering$
-
-
Rejected Actions
- 다양한 policy 모델에게 질의하여 sample당 5개씩 추출.
- rule-based filtering으로 같은 역할을 하는 action을 배제
-
Dataset Statistics
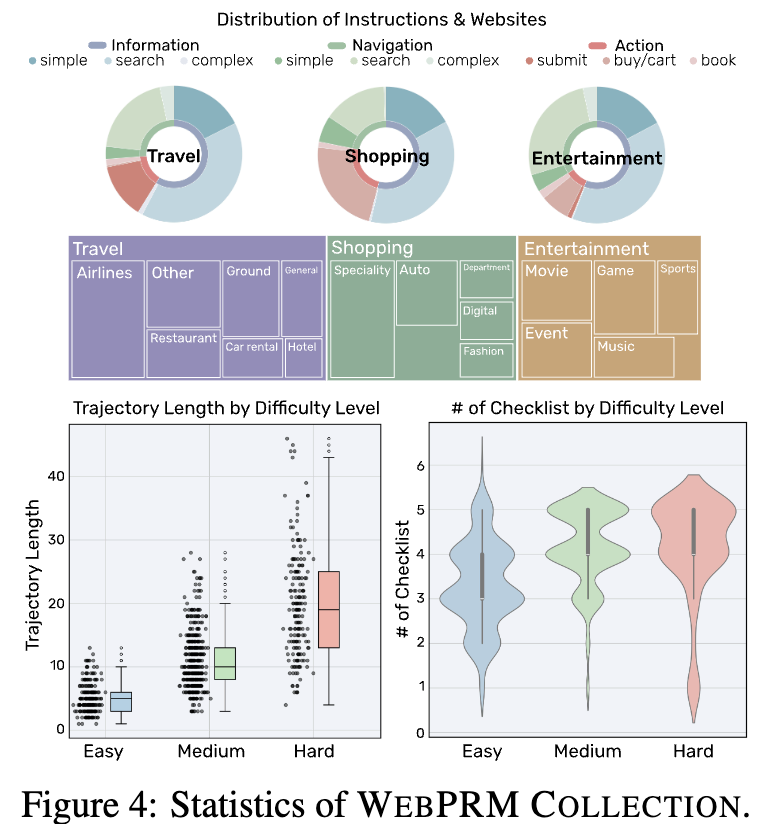
- trajectory의 길이와 checklist의 갯수가 비례함
- easy (<5), medium (<9), hard에 따라 분포가 나뉨
3.2 Web-Shepherd
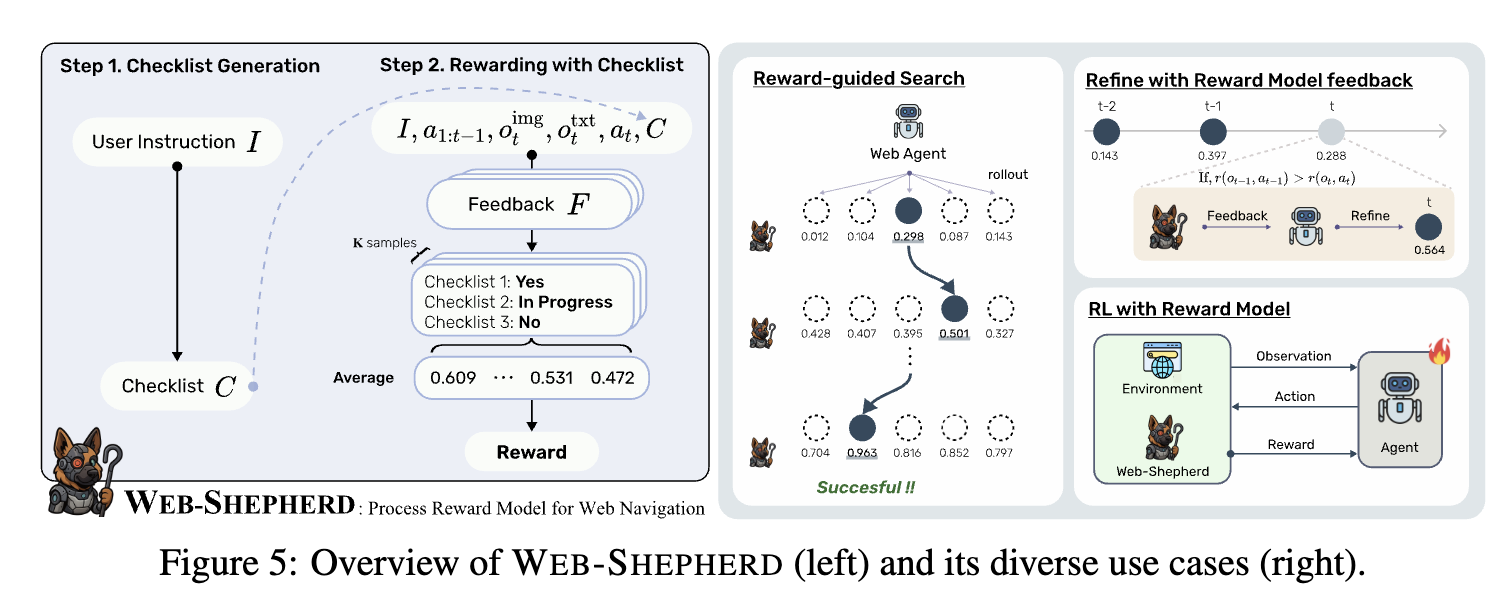
-
input
- instruciton
-
output
-
checklist
-
checklist별 reward를 할당
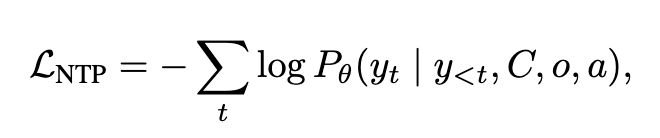
- $y=[F;J]$: Feedback과 Judgement
-
reward
-
YES + In Progress token에 대한 probability score를 계산
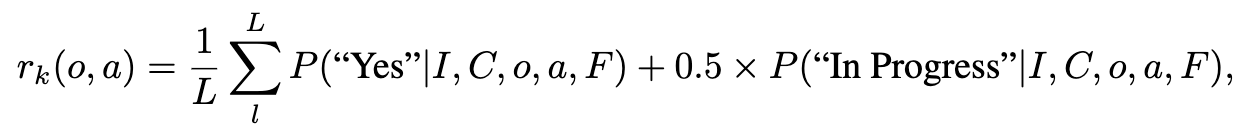
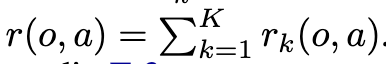
-
다양한 실험 결과, 이게 제일 좋았다고 함
-
-
4. Experiments
4.1 PRM
-
Dataset Construction
-
WebArena에서 수동으로 67개 instance
-
Mind2Web에서 expert trajectory 그대로 사용하여 707 instance
-
총 774개 instance 기반으로 rejected action 추출하여 PRM evaluation benchmark를 추출
-
-
Metrics
- MRR: Mean Reciprocal Rank
- Step Accuracy: chosed action trajectory에서 예측한 step list의 비율
- Trajectory Accuracy: $a_t^+, a_t^-$전체 중에 PRM 모델이 top-1에 $a_t^+$를 1순위로 예측한 비율
- Model architecture
- Qwen-2.5-3B / Qwen-3-8B + LoRA (3-epoch)
-
정량적 결과
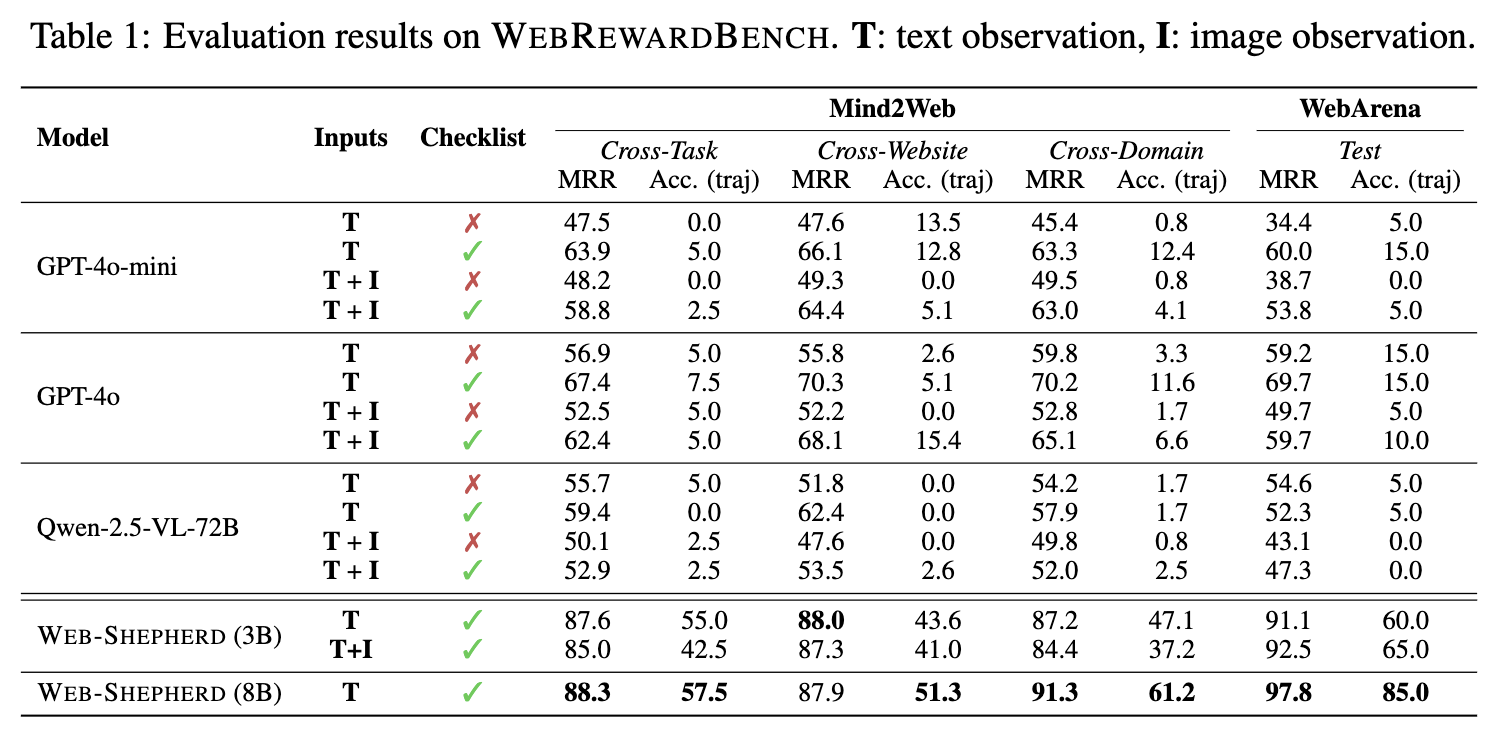
-
Checklist는 고품질 reward 생성에 매우 중요
-
Multimodal은 reward signal에는 큰 영향이 없음
-
4.2 Reward Gudied Trajectory Search
-
BoN (Best-of-n)
- n번 ensemble하여, 최적의 trajectory를 reward model의 signal기반으로 선택
- policy model: GPT-4o-mini / GPT-4o
- reward model: Web-Shepherd / GPT-4o-mini
-
정량적 결과
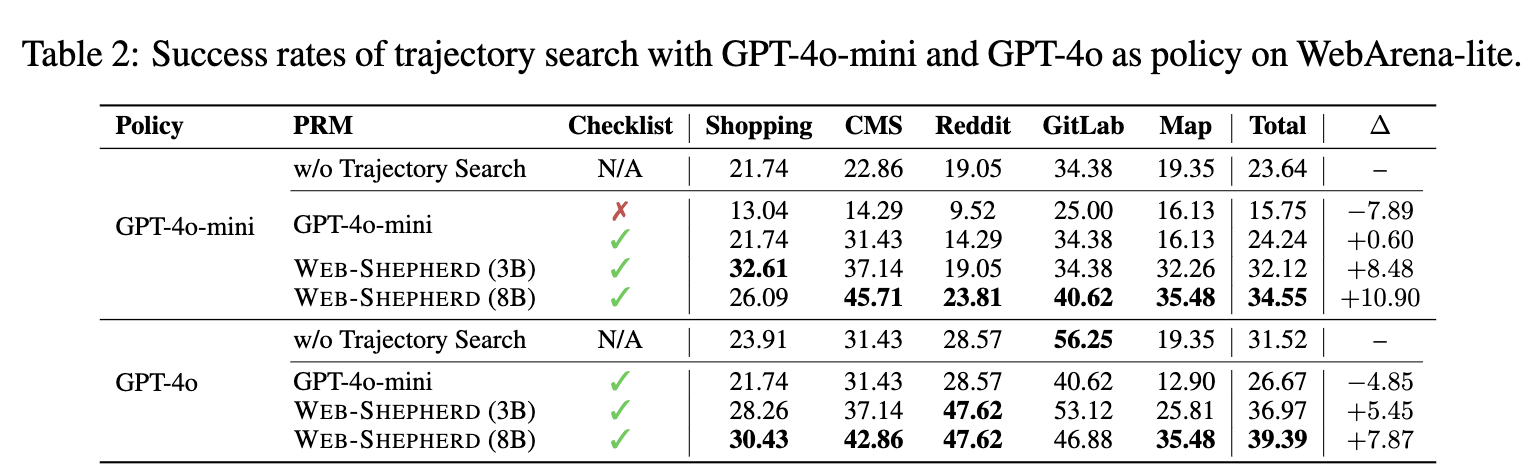
-
Step-wise-feedback

-
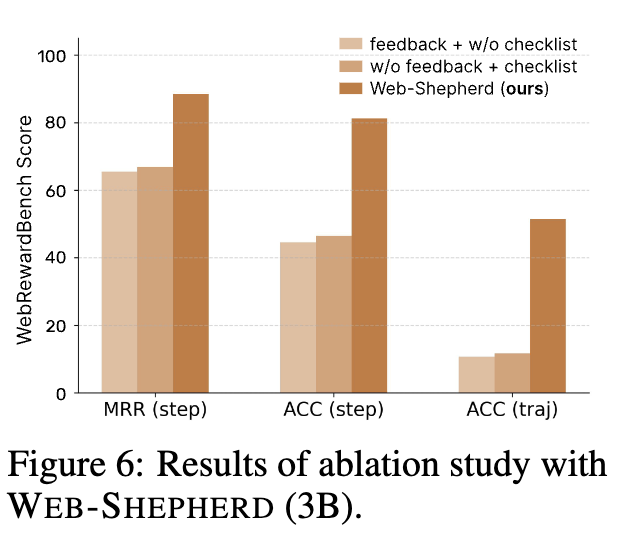
Ablation Studies
-
Checklist의 quality가 reward accuracy에 미치는 영향
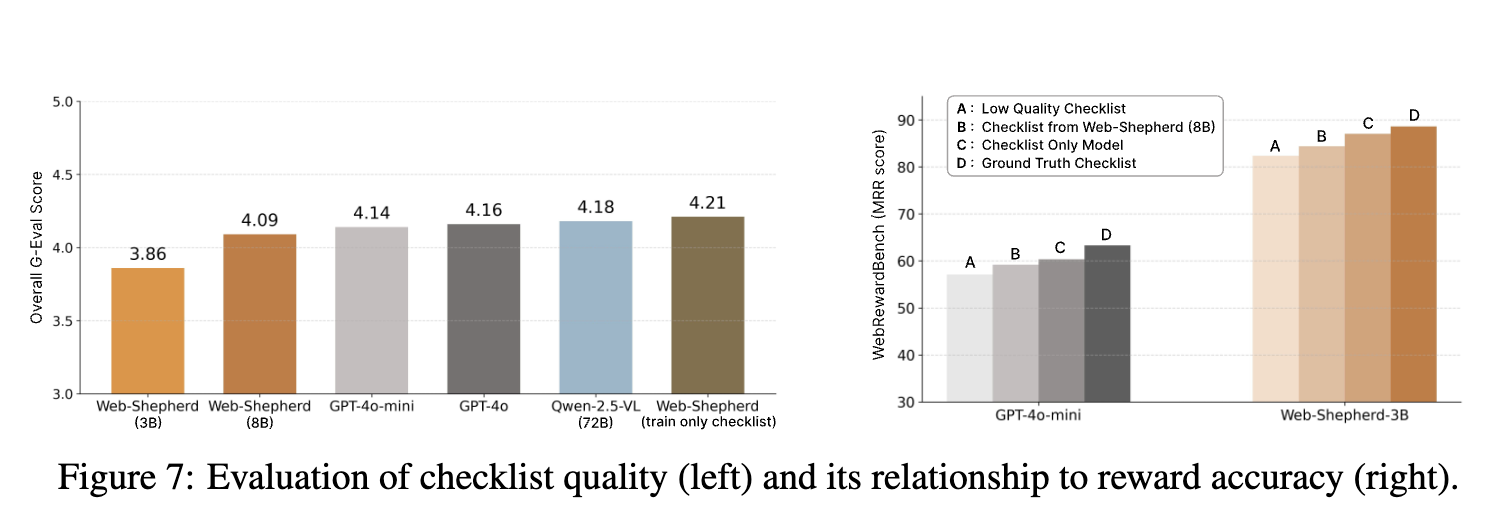
- 좋은 checklist를 뽑을수록, reward 모델의 accuracy는 향상됨
-
BT model (Bradley-Terry) vs. Web-Shepherd
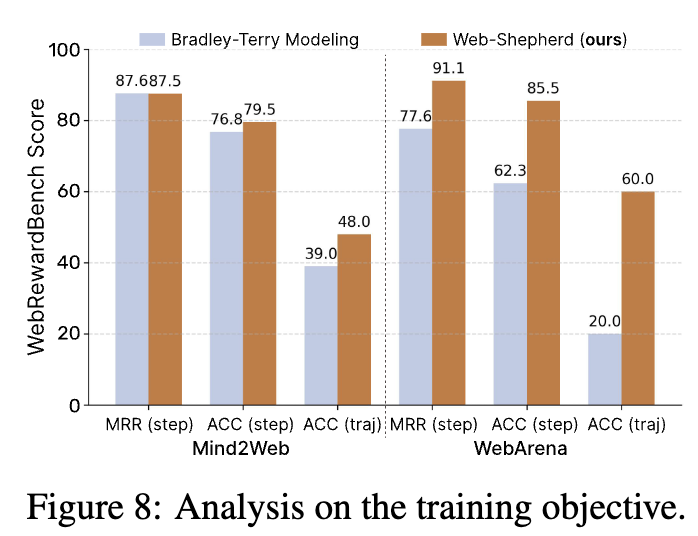
-
비용 효율성
-
API-based: GPT-4o
- input tokens: 81,287
- output tokens: 1,953
-
serving based: A100 ($1.19/hours)
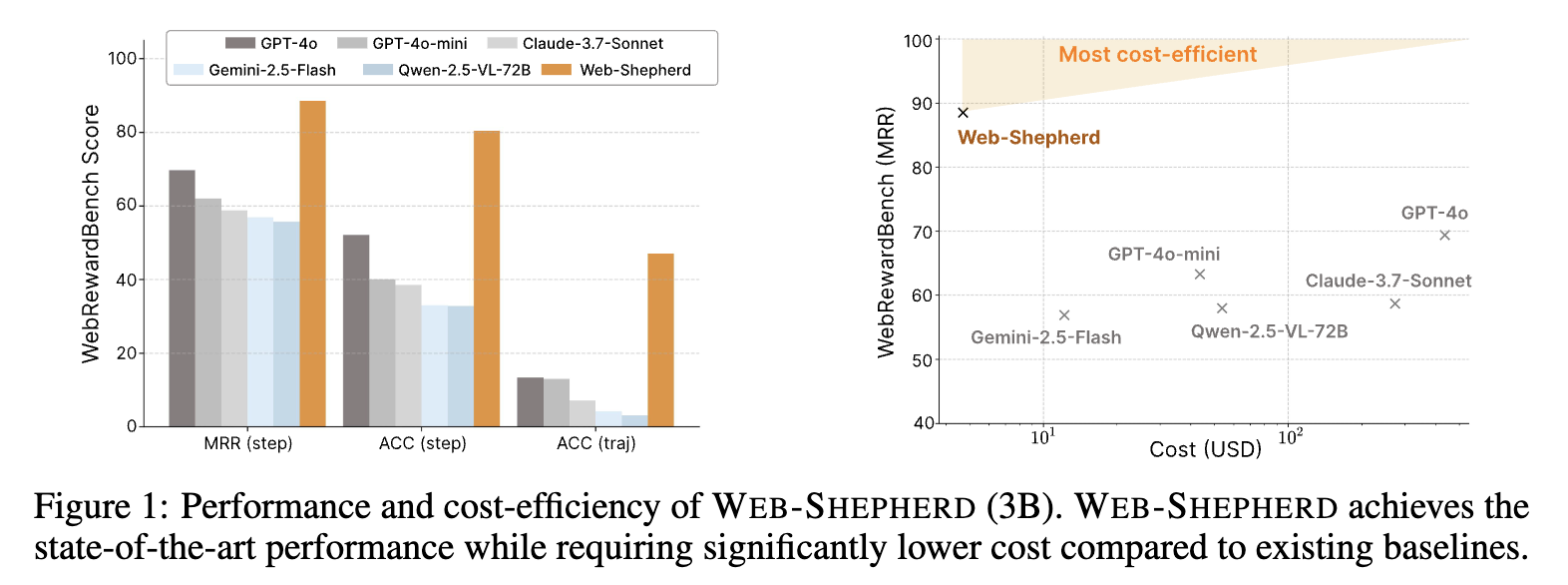
-
-
Case Study
-
30개 success / 30개 fail trajectories의 reward를 분석
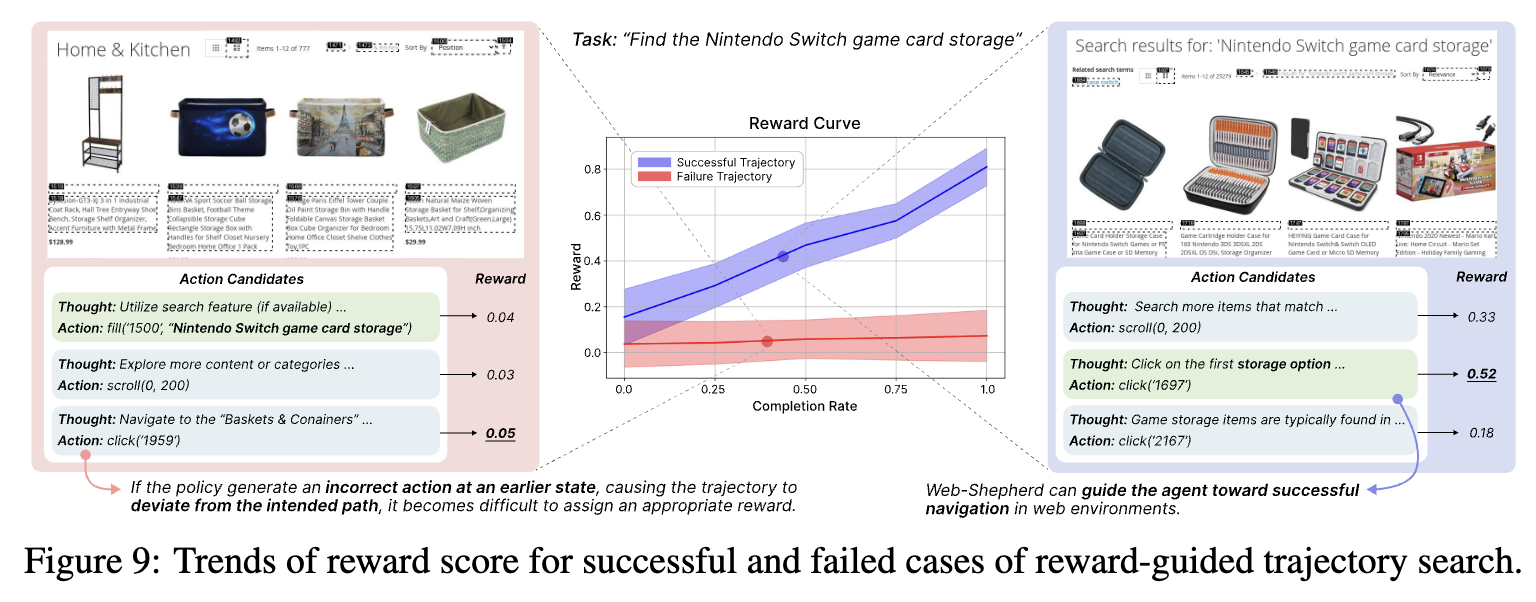
- success trajectory: reward가 점진적으로 향상되는 패턴
- failed trajectory: 낮은 점수에서 flat한 패턴
-
-