WEBAGENT-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
[WebAgent] WEBAGENT-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
- paper: https://arxiv.org/pdf/2505.16421
- github: https://github.com/weizhepei/WebAgent-R1 (깡통)
- archived (인용수: 1회, ‘25-06-03 기준)
- downstream task: Multi-turn Web Automation
1. Motivation
-
RL이 LLM의 reasoning 성능 향상에 기여한다는 최근 연구가 나타났다. (DeepSeek-R1)
-
하지만 이는 math reasoning과 같은 non-interactive reasoning 분야에 대해서 single turn interaction을 위주로 연구되었다.
-
web agent연구는 multi-turn interaction을 학습하는 것이 challenging했기에 web browsing과 같은 분야에 적용이 어려웠다.
$\to$ WebAgent를 위한 end-to-end multi-turn RL framework를 제안해보자!
2. Contribution
-
Dynamic Content Compression & Asynchronous Trajectory Roll-out mechanism을 반영한 end-to-end multi-turn RL framework for Webagent, Webagent-R1을 제안함
-
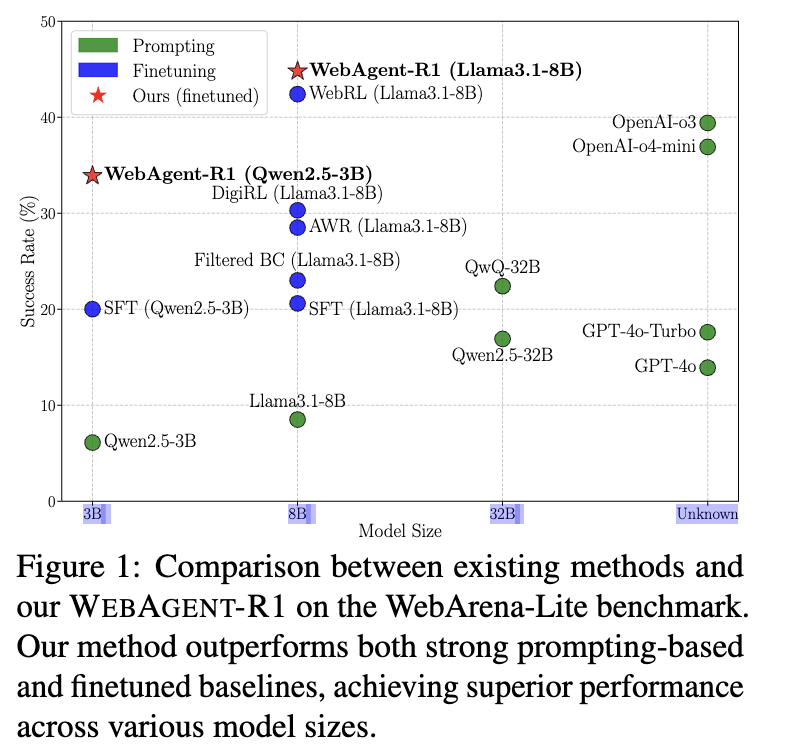
Baseline Qwen-2.5-3B를 success-rate 등 각종 수치에서 성능 boosting (WebArena-Lite) 및 SOTA
-
Behavior cloning, thinking-based-prompting, test-time scaling등 long-CoT reasoning의 유효성을 입증
3. WebAgent-R1
3.1 Problem Formulation
- Web task를 Partially Observable Markov Decision Process (POMDP)로 재정의함
- POMDP의 arguments
- $(S, A, T, R)$
- $S$: State (상태). web의 content로, text-only HTML을 의미
- $A$: Action space를 의미. web에서 자주 사용하는 operation의 집합.
-
$T(s_{s+1} s_t,a_t)$: Environment dynamics. web page가 action에 따라 변화한 tracking history - $R$: Reward function. {0,1} 이진값을 가짐
- $(S, A, T, R)$
- POMDP의 arguments
- Dataset
- WebArena-Lite를 따름
3.2 Behavior Cloning
-
Expert의 demonstration을 paired dataset로 저장하여 행동을 모방하도록 Web Agent를 학습하여 초기 policy model을 훈련시킴
-
Fixed dataset of expert demonstration
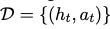
-
$h_t$: t step에서 full interaction history
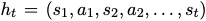
-
$a_t$: t step에서 예측한 action
-
-
policy $\pi_{\theta}$ 모델은 SFT (Supervised-Fine-Tuning)하기 위해 아래 loss를 이용
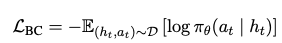
- SFT 수행의 목적: Web Agent가 action space에 정의된 기초적인 web interaction skill를 학습시킴
3.3 End-to-End Multi-Turn Reinforcement Learning
-
Overall framework
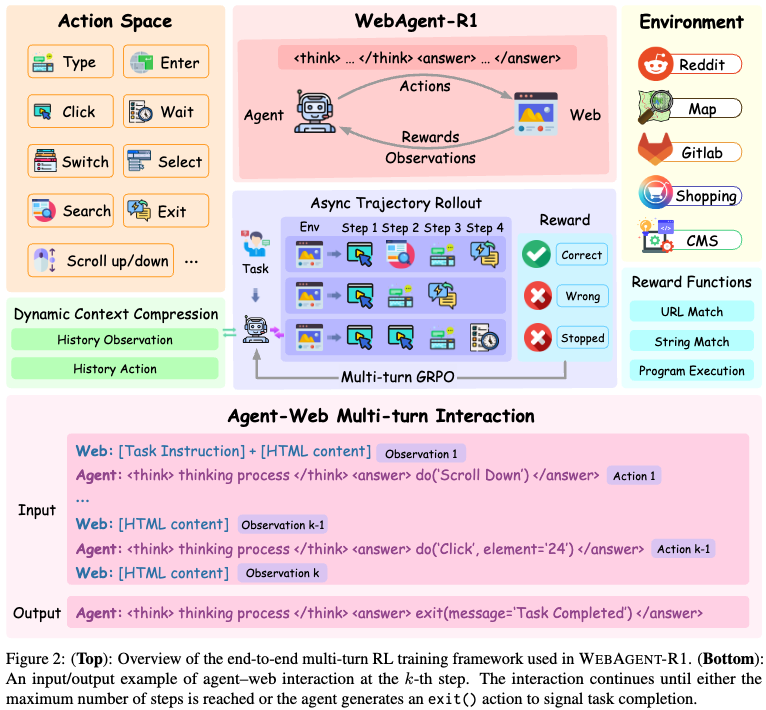
-
Dynamic Context Compression
-
문제상황
- multi-turn으로 누적된 action, state를 다음 step에 누적하는 과정에서 observed된 web task는 수천 token을 수반한다.
- 이를 raw data 그대로 넣으면 memory issue가 발생한다.
-
해결안
-
새로운 observation이 도착하면, 이전의 history들은 단순화되어 context length를 줄임과 동시에 완벽한 action history를 갖도록 dynamic context compression 전략을 활용한다.
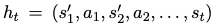
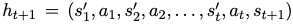
- $s_i’$: i번째 simplified HTML
-
loss mask update
- 실시간으로 history가 업데이트 되기 때문에, action token에 대해서만 loss가 반영되도록 loss mask도 따라서 업데이트 해준다.
-
-
-
Multi-turn GRPO
-
Group of trajectories
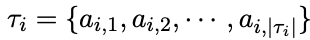
- $\tau_i$: i번째 trajectory. trajectory는 전체 과정에 대한 action을 저장한다.
-
Loss
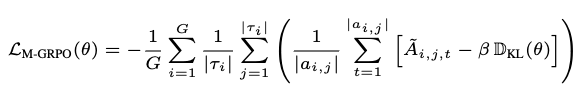
-
$\tilde{A}{i,j,t}$: t번째 token에 대한 $a{i,j}$ action의 advantage
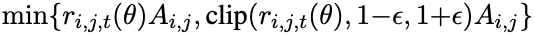
-
$r_{i,j,t}$: importance sampling tem
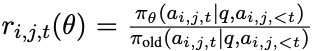
-
$\epsilon, \beta$: ;hyperparameters
-
$A_{i,j}$: group relative advantage
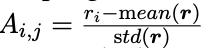
-
$\bold{r}$: reward. rule-based reward function으로부터 계산됨
-
-
-
-
Asynchronous Trajectory Rollout
- 문제상황: Group trajectory를 얻기 위해서는 environment과 반복된 interaction이 수반되어야 한다. 이는 많은 시간을 요구한다.
- 해결안
- asynchronous rollout 전략을 활용하여 독립된 여러개의 browser instance ${\Epsilon_1, \Epsilon_2, …, \Epsilon_G}$를 초기화한다.
- 개별 browser instance는 개별 cookies를 관리한다.
- agent는 개별 browser와 독립적으로 interaction을 비동기적으로 수행함으로써 다양한 history & trajectories를 효율적으로 쌓는다.
-
Reweard Design
- Rule-based reward
- task-specific criteria (ex. reaching target page)를 binary reward (0 or 1)로 제공한다.
- Rule-based reward
4. Experiments
-
Web Environment
- Self-hostable & realisitic web 환경을 제공하는 WebArena를 활용한다.
- 범위: social forums(Reddit), collaborative coding (GitLab), e-commerce content management system (CMS), open streetmaps (Map), online shopping (Shopping)
- Self-hostable & realisitic web 환경을 제공하는 WebArena를 활용한다.
-
Dataset & Evaluation Metrics
- WebArena-Lite
- 9,460 trajectories + behavior cloning dataset
- WebArena 중, human verified 버전.
- Train/Val = 647/165 tasks
- Success rate
- built-in rule-based rubrics 활용
- WebArena-Lite
-
Baselines
- (pretrained): Qwen2.5, Llama3.1, GPT-4
- (reasoning-based) QwQ, OpenAIo3
- (finetuning): Qwen2.5-3B / Llama3.1-8B
-
Main Results
-
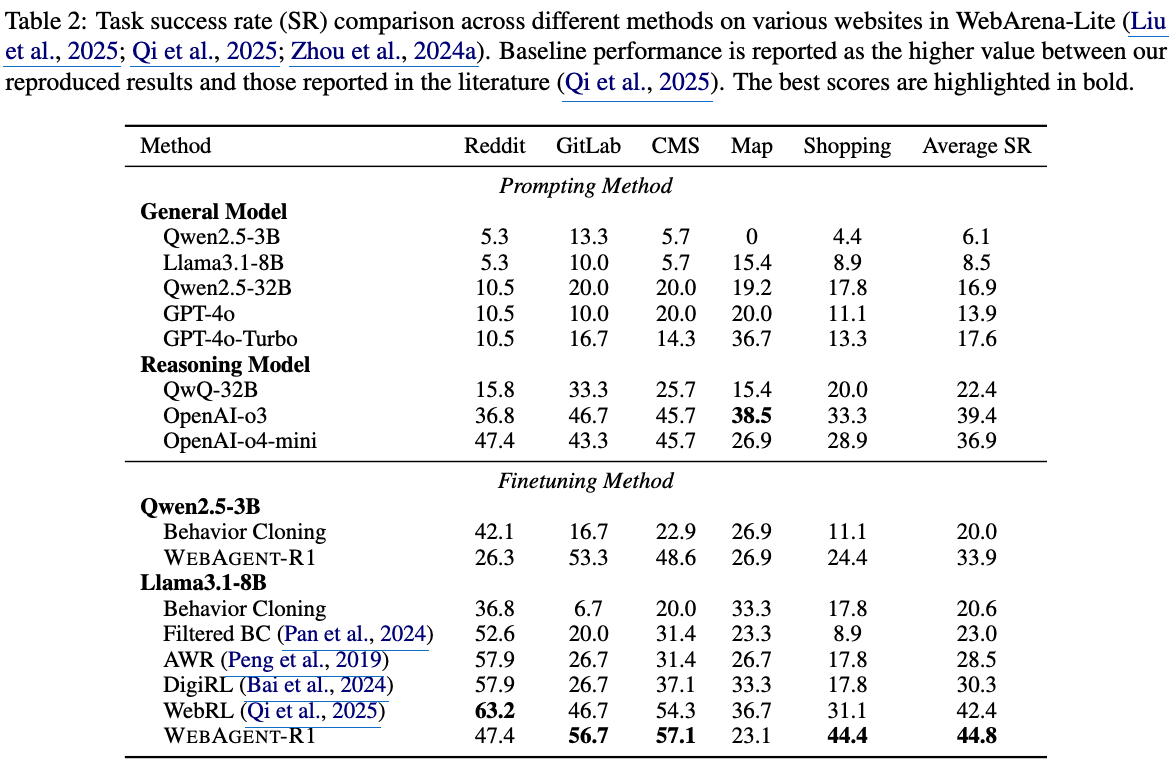
정량적 결과
-
OpenAI GPT-o3의 succeess rate가 39.4%로, web task를 수행하기엔 역부족이다.
-
finetuned (BC-only) 3B 역시 20%이다. 이는 GPT-4o를 능가하는데, 이는 GTP-4o의 모델의 크기가 작아서가 아니라, 모델이 HTML과 web-specific behaviors를 이해하지 못해서라고 가설을 세웠다.
$\to$ domain-specific finetuning이 절실함을 알 수 있다.
-
Reasoning models가 general LLM보다 성능이 좋은것(OpenAI-o3 > GPT-4o)을 미루어 보아, web task와 같은 복잡한 task를 푸는데 thinking process가 필수적임을 깨닫는다.
-
RL process가 BC-SFT 이후에 추가로 수행되면, 성능이 비약적으로 향상된다. 이는 RL 학습 과정에서 dynamic web interactions을 수행하는 과정에서 모델이 trial-and-error를 겪으면서 long-horizon decision-making 능력을 배우기 때문이다.
-
이전 RL(WebRL, DigiRL) 역시 성능향상이 있었으나, 우리의 방식이 더 좋은 성능인걸 미루어보아, end-to-end multi-turn RL이 효과적임을 입증한다.
-
-
-
Training Dynamics
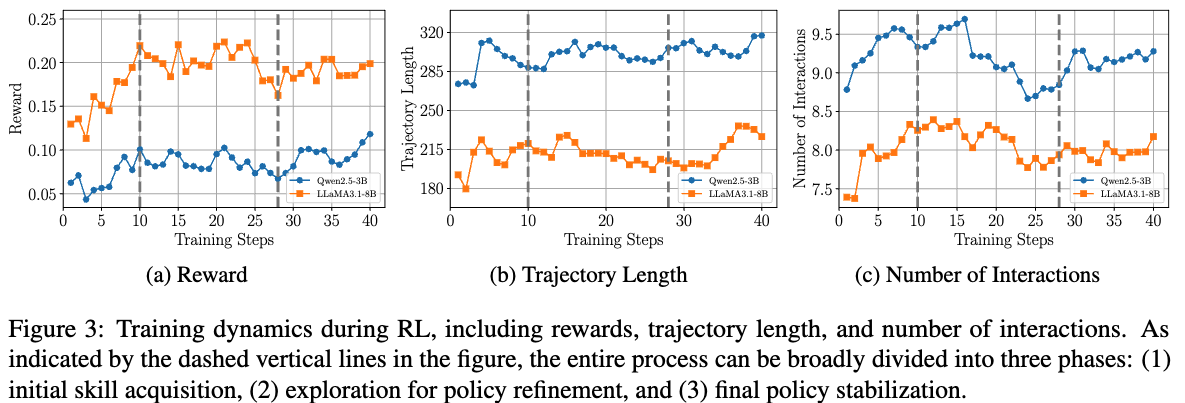
$\to$ vertical line을 기점으로 3 phase로 나눌 수 있다. (1) 초기 skill 획득 (2) policy refinement를 위한 탐험 (3) 안정화 단계
- reward
- phase 1: 빠른 reward 증가하는 단계. agent가 basic skill을 배우고, simpler task를 성공적으로 수행하는 단계.
- phase 2: reward가 수렴하는 단계. 다른 전략을 취하면서 policy를 수정하는 단계.
- phase 3: reward가 다시 증가하는 단계. 안전성을 향상하는 단계.
- trajectory length (Number of tokens across all multi-turn interactions)
- phase 1: trajectory length가 증가하는 단계.
- phase 2: 안정화되는 단계.
- phase 3: length가 다시 증가하는 단계. 더 구체적인 출력을 의미한다.
- number of interactions
- phase 1: interaction 횟수가 증가하는 단계. agent가 더 proactive해짐.
- phase 2: interaciton 횟수가 줄어듦. 효율적으로 interaction을 수행하는 단계.
- phase 3: 안정화 단계.
- reward
-
Ablation Study
-
Qwen2.5-3B 기반으로 실험 진행
-
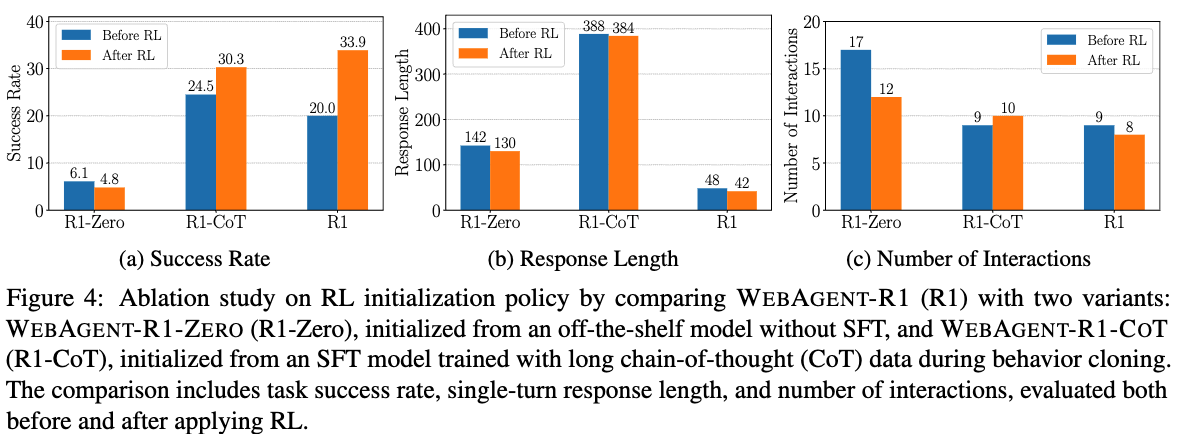
BC-SFT 유무에 따른 성능 비교 (WebAgent-R1-Zero (no BC-SFT) / WebAgent-R1-CoT (BC-SFT + M-GRPO))
- 시사점
- BC-SFT는 꼭 필요하다. 없으면 M-GRPO하면 오히려 성능이 하락한다. (6.1% $\to$ 4.8%)
- long-CoT data를 BC에 추가하는것은 성능 향상된다. CoT-SFT 방식으로 학습한 모델이 더욱 성능이 좋다. (24.5% vs 20.0%)
- CoT data는 QwQ-32B를 통해 추출한다.
- RL학습시 long-CoT는 제한적 성능 향상됨. 가설은 CoT-SFT가 RL에서 탐험해야할 space를 제약하기 때문일 것이다. (30.3% vs 33.9%)
- 시사점
-
Thinking format 유무에 따른 성능 비교
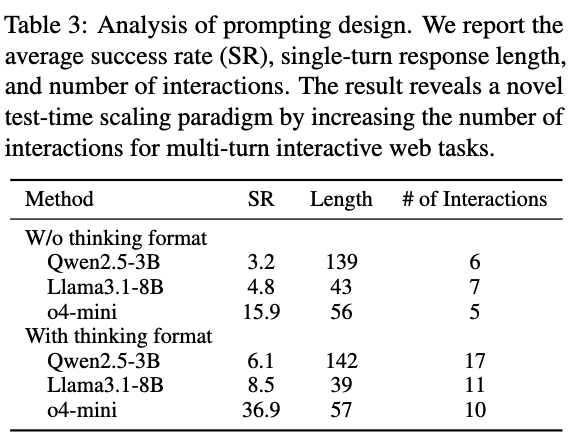
-
thinking format이 있을때 비약적으로 성능이 향상됨 (3.2%/4.8%/15.9% vs. 6.1%/8.5%/36.9%)
-
전체 trajectory length는 비슷함 (139 vs. 142)
-
# of interactions가 증가함 (6 vs. 17)
-
인위적으로 interaction 수를 늘리는 test-time scaling 기법을 실험해보니, 실제로 좋아진다.
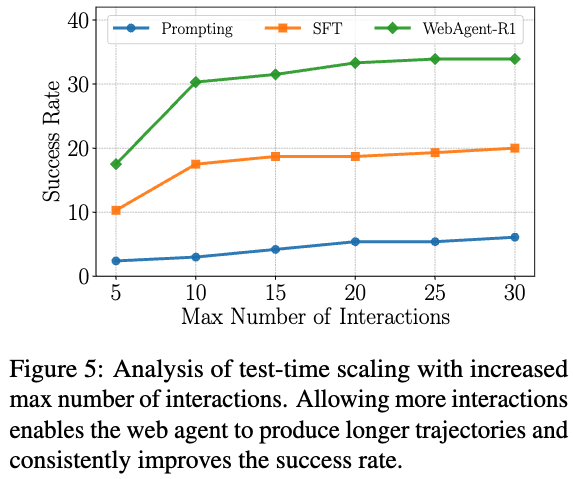
-
-