VisualWebArena: Evaluating Multimodal Agents on Realistic Visually Grounded Web Tasks
[WebAgent] VisualWebArena: Evaluating Multimodal Agents on Realistic Visually Grounded Web Tasks
- paper: https://arxiv.org/pdf/2401.13649
- github: https://github.com/web-arena-x/visualwebarena
- ACL 2024 acepted (인용수: 243회, ‘25-06-29 기준)
- downstream task: Visual특성이 강한 domain (Shopping, 중고거래, Reddit)의 Web automation tasks
1. Motivation
-
기존의 Web Agent 연구들은 대부분 text-only LLM 기반이였다.
-
하지만, Web의 GUI는 “사람의 시각적 이해”를 위해 고안된 특성이 있다. 따라서, 시각적 이해 능력은 web task에서 매우 필수적이다.
$\to$ 언어적 정보에 시각적 정보를 추가한 Multi-modal LLM 전용 benchmark를 제안해보자!
2. Contribution
-
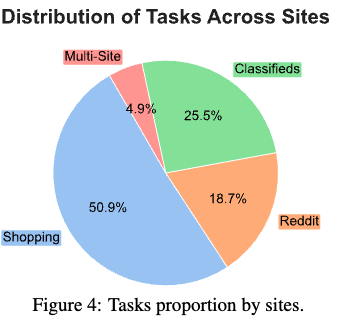
시각적 이해를 바탕으로한 910개의 task를 3개의 domain (Classifieds, Shopping, Reddit)에서 제안함

- WebArena에서 파생됨
- 2개 (Shopping, Reddit) $\to$ WebArena와 동일
- 1개 (Classifieds) $\to$ 새롭게 추가
- Visual Grounded tasks로 구성됨
- 25.2%의 task는 질문에 image가 포함됨 (interleaved image-text)
- WebArena에서 파생됨
-
SOTA VLM기반 모델이 SOTA text-only LLM에 비해 성능이 좋으나 (16.4% vs. 12.75%), human에 비해 월등히 성능이 떨어짐을 확인 (88.7%)
- 성능을 올릴만한 연구할게 많다는걸 어필하는 듯
-
제안한 visual-webarena benchmark에서 SoM (Set-of-Mark) 기반 VLM baseline을 제안함
3. VisualWebArena
3.1 Observation Space
-
Raw web page HTML (Document Object Model tree)
-
Accessibility Tree
-
Web screenshots (RGB)
-
Set-of-Mark (SoM)

3.2 Action Space
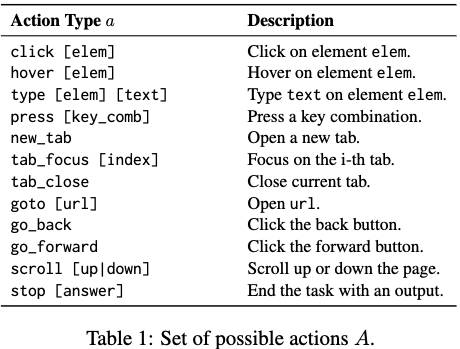
3.3 Evaluation
Information Seeking Tasks
Expected output ($\hat{a}$): string. Ground Trutu ($a^*$)과의 correctness를 기준으로 평가.
-
exact_match($\bold{I}_{\hat{a}==a*}$): 예측값이 정답과 정확히 일치하면 1, 아니면 0 -
must_include: 예측값($\hat{a}$)안에 정답($a^$)이 전부 포함되어야 함 $a^ \in \hat{a}$. unordered list의 출력이거나 특정 keyword를 포함한 형태일 경우 사용ex. $\hat{a}$=”$$1.99,$2.50,$10.00$” 이고, $a^*$=${"1.99", "2.50", "10.00"}$이면 1
-
fuzzy_match: LLM(GPT-4-Turbo)에 query를 날려 $a^*, \hat{a}$가 의미론적으로 일치하는지를 평가. LLM이 “correct”하면 1, “incorrect”하면 0을 부여. 주로 open-ended setting일 경우 (ex. 이미지에 대한 묘사를 시키는 경우) -
must_exclude:must_include와 반대 급부로, $a^*$ 중에 1개라도 $\hat{a}$에 포함될 경우 reward 0을 부여하고, 아니면 1을 부여.
새로운 eval 함수
-
eval_vqa:fuzzy_match와 동일하게 VLM (Blip-2-T5XL)모델을 사용하여 image & question을 주고, VLM이 정답 $a^*$할 경우 1, 아니면 0의 reward를 부여. Open-ended task 평가에 유용함ex. “Buy me a green hoodie under $10.” $\to$ 이를 만족하는 products는 많지만, 전부를 열거하기 힘들 경우.
-
eval_fuzzy_image_match: query image가 정답 image와 유사한지를 SSIM (Structural Similarity Index Measure) 기준으로 평가. Threshold보다 높을 경우 1, 아니면 0을 부여
Navigation and Actions
- 각 evaluator는

4. Curating Visually Grounded Tasks
4.1 Web Environments
-
Classifieds: 중고나라 같은 웹사이트.
-
65,955 래의 listing이 있음
-
Visually grounded tasks 중심으로 구성 (posting, searching, commenting, etc)
-
Content Management System (CMS)로는 OS-Class 기반으로 구현
- search, posting, commenting 함수 제공함
- review, rating도 가능
-
3주간 Craigslist 카테고리에서 데이터를 취득 (북미 지역)
-
scrubadubPython package 기반으로 개인 정보 제거 (Personally Idenfiable Information)- 주소, 전화 번호, 이름, email 등을 임의로 수정
-
예시
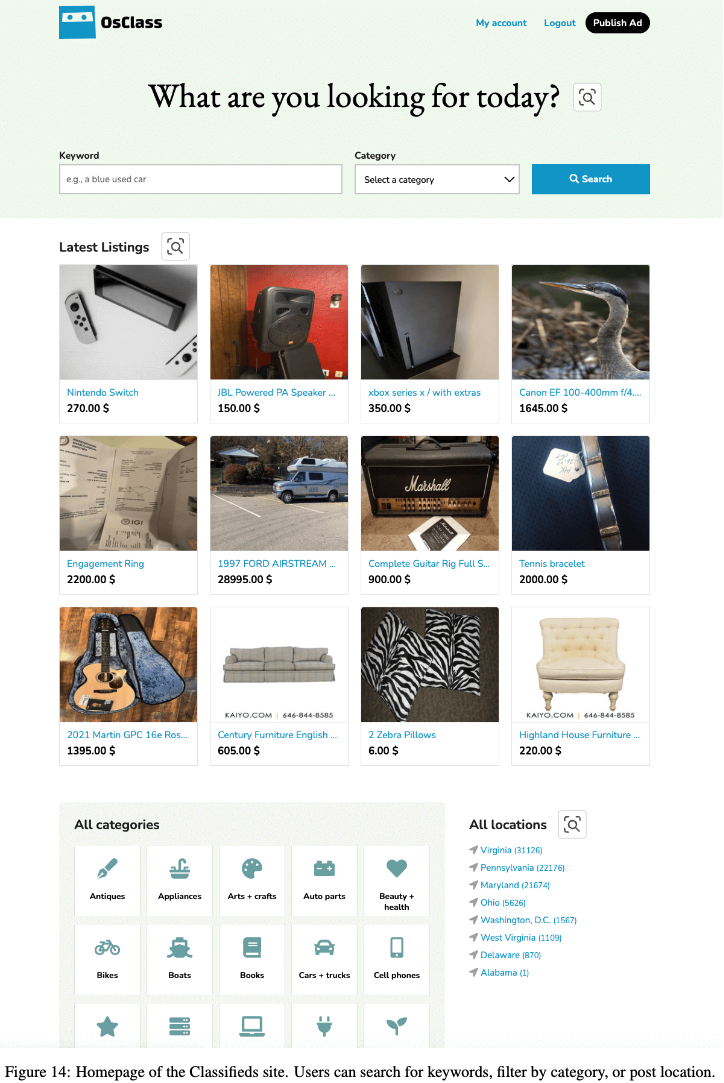
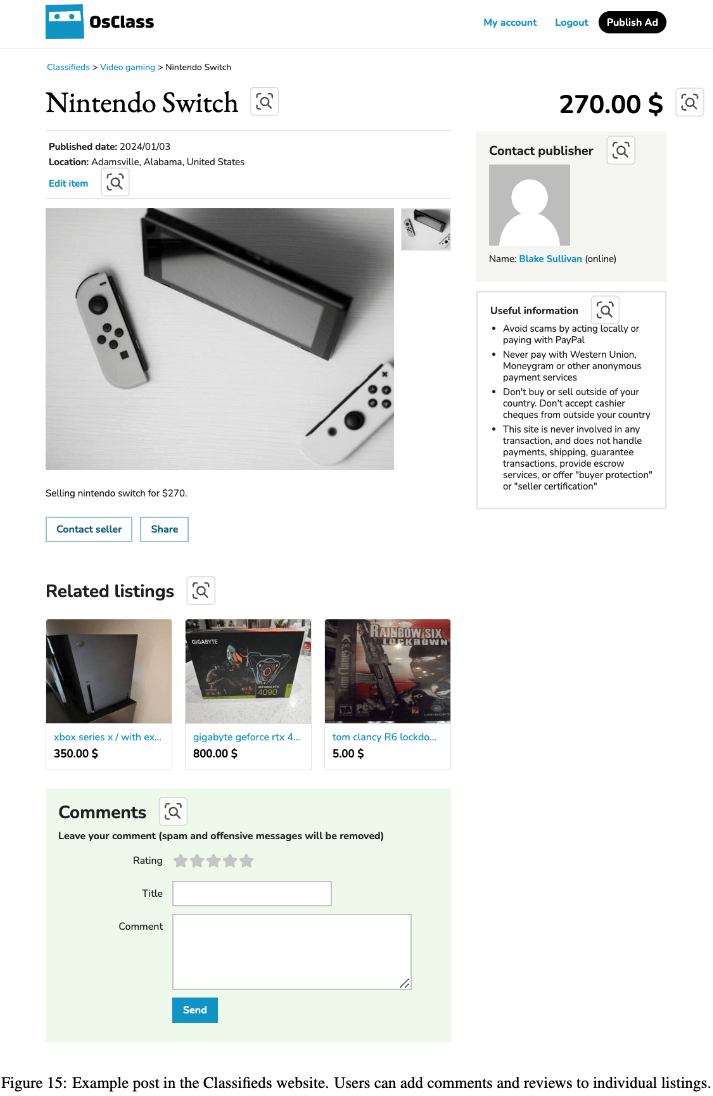
-
- Shopping
- WebArena와 동일하게 Amazon에서 스크랩한 내용을 WebShop에 배포한 걸로 채움
- 단, 상품 이미지를 시각적으로 이해해야 성공적으로 navigating & task를 수행할 수 있도록 구현
- Reddit
- 31,464 post로 구성되며, 다양한 이미지로 구성된 forums, memes, natural images, consumer electornics, charts로 구성
4.2 Tasks
-
Task Creation
-
910개의 새로운 task을 구현
-
Webarena와 동일한 방식으로 realistic visually grounded task를 만듦
- 6명의 석사생 (공저자)들을 대상으로 intent templates를 생성 (*Find me the *) 사이 가격.
ex. “Find me the cheaptest red Toyota. It should be between $3000 to $6000” $\to$ 314개의 template을 만듦. (2.9 tasks per template)
- Annotator의 역할
- 창의적 & website의 visual layout을 사용할것, 이미지를 사용할 것, cross-site 기능을 이용할것, realistic할 것 을 지시함
- 이미지를 사용할 경우, loyalty-free, attribution-free여야 할것
- Reward function을 구현
- 창의적 & website의 visual layout을 사용할것, 이미지를 사용할 것, cross-site 기능을 이용할것, realistic할 것 을 지시함
- 실제 상황을 가정하여 5.1% (46개의 tasks)는 풀지 못하는 task로 구현 (unachieveable) $\to$ agent가 초기에 종료하기를 기대함. 단, 이유를 설명해야 함 (fuzzy_match로 평가함)
-
-
Visually Grounded Tasks
-
VisualWebArena의 핵심적인 특징은 “visual grounding”을 내재한 tasks로 구성되었음 -
Agent에게 visual understanding을 요구하며, html text-only외 visual 정보를 해석해야만 해결가능함
ex. “green polo shirt”
-
-
Task Complexity
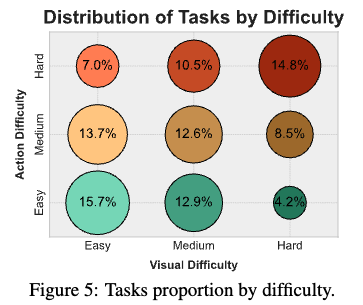
-
action & visual difficulty를 annotation함
-
action difficulty: human이 해당 task를 성공적으로 수행하기 위해 필요한 예측된 step 수
- Easy: <4 actions
- Medium: 4 ~ 9 actions
- Hard: 9> actions
-
visual difficulty
-
Easy: visual identification 갯수가 4보다 작은 basic한 경우
ex. colors, shapes, high-level object detection
- Medium: 식별할만한 패턴이 있거나, 의미론적으로 이해해야 하거나, 크고 짧은 OCR text가 존재하는 경우
- Hard: 여러 이미지가 있거나, 작고 긴 OCR text가 존재하거나, 세세한 detail이 있는 경우
-
$\to$ overall difficulity는 두 값의 평균으로 구함
-
-
-
Human Performance
-
7명의 학부생을 대상으로 실험을 진행
-
몇명은 task 생성에 기여했던 사람들임
-
동일한 사람에게 할당되어, data leakage 발생하지 않도록 함
-
230 tasks를 기반으로 평가를 진행
$\to$ 88.7% 성공률을 보임
-
Failure case 분석
-
주로 task를 제대로 읽지 않거나, 목표의 일부를 빼먹은 경우였음
ex. wishlist에 넣으라고 했는데, shopping cart에 넣는 경우
-
수많은 검색을 요구하는 경우도 주로 틀림. 5 ~ 10분 이상 걸리는 경우 많이들 틀렸음
ex. “Find and navigate to the comments of this exact image” 혹은 “Find the cheapest, …”
-
-
5. Baselines
- 모든 baseline 모델들은 3 in context learning 기반 few-shot prompting으로 진행
5.1 Text-based LLM Agents
- Chain-of-Thought prompting으로 진행
- Models
- GPT-4-Turbo (
gpt-4-1106-preview) - GPT-3.5 Turbo (
gpt-3.5-turbo-1106) - Gemini-Pro
- LLaMA-2-70B
- Mixtral-8x7B
- GPT-4-Turbo (
5.2 Image Caption Augmented LLM Agents
- 모든 image element에 대해 pretrained image captioning model(Blip-2-T5XL, LLaVA-v1.5-7B)을 써서 caption을 생성함
- image와 함께 text (alt-text)를 LLM 입력으로 제공함
- 최종적으로는 success rate에 더 도움이 되고 / 가볍고 / 적은 GPU VRAM을 활용하는 Blip-2-T5XL을 사용함
5.3 Multimodal Agents
- Models
- GPT-4V
- Gemini-Pro
- IDEFICES-80B-Instruct
- CogVLM
- Input format
- Image Screenshot + Captions + Accessibility Tree
- Image Screenshot + Captions + SoM
- SoM: JavaScript를 활용해서 unique ID+bbox를 그려준 이미지
-
정량적 결과
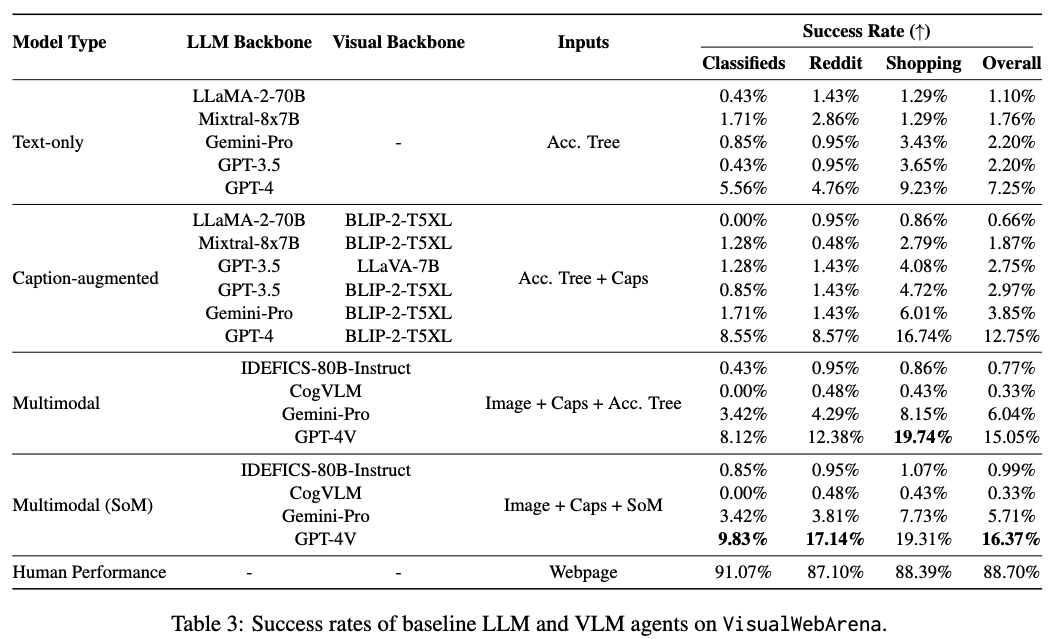
- GPT는 accessibility tree보다 SoM이 더 도움이 됨
- Text-based LLM (12.75%) < Multimodality (16.37%) < Human (88.70%)
- 다른 모델들은 도움이 안됨
- GPT는 accessibility tree보다 SoM이 더 도움이 됨
-
정성적 결과

-
Ablation Study
-
GPT-4v + SoM의 Task type에 따른 성능 분석
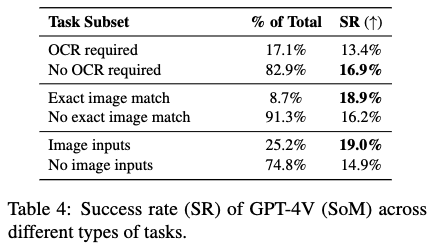
- OCR text가 존재할경우 성능이 감소함 (13.4% vs. 16.9%) $\to$ OCR은 bottleneck임
- Exact Match 성능이 평균보다 우세함 $\to$ image Exact Match는 bottleneck이 아님
- Input으로 이미지 존재하는 경우 성능이 우세함 $\to$ not a bottleneck
-