[Agent] VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents
[Agent] VisualAgentBench: Towards Large Multimodal
Models as Visual Foundation Agents
- paper: https://arxiv.org/pdf/2408.06327
- github: https://github.com/THUDM/VisualAgentBench
- ICLR 2025 accepted (인용수: 22회, ‘25-08-09 기준)
- downstream task: GUI Navigation (WebArena, Mobile), Visual Design (CSS), Embodied (OmniGibson, MineCraft)
1. Motivation
-
기 존재하는 benchmark는 복잡한 real-world environment에서 LMM이 Visual-Foundation-Agent로써 interaction 능력에 대하여 최대 잠재능력을 발휘하기에는 불충분한 challenge만 있다.
- 고전적인 tasks: VQA, OCR, REG, human exams…
- single environments: Household, Gaming, Web, Desktop scenarios…
$\to$ Visual Agent를 만들기 위한 학습/평가 benchmark를 제안해보자!
2. Contribution
-
Visual Agent를 위한 학습 / 평가가능하며, 다양하고 실제적인 challenge로 구성된 benchmark인 VAB를 제안함
-
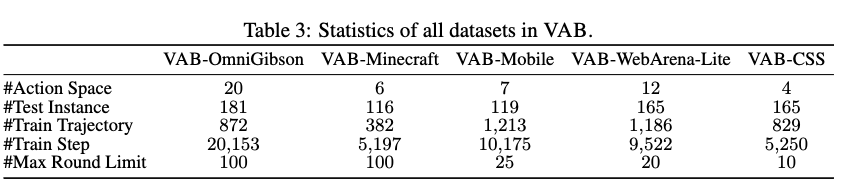
Hybrid data curation pipeline을 통해 VAB training set를 구성함 $\to$ 4,482 고품질의 training trajectories를 5 environment에서 추출함
-
5개의 proprietary LMM APIs + 8개의 open LMMs를 활용하여 baseline 지표를 도출함.
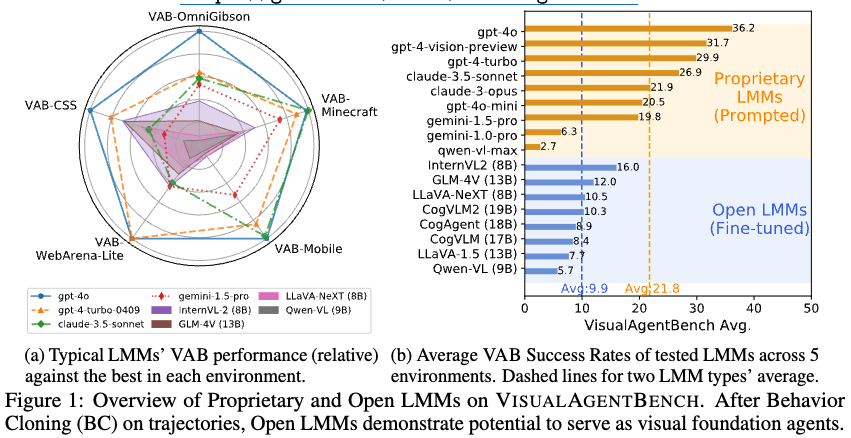
- propreitary LMM과 opensource LMM의 성능 괴리가 존재함을 확인
- Behavior Cloning을 통해 학습하면 open LMM이 visual agent로서 성능 향상을 확인함
3. VisualAgentBench
3.1 Problem Formulation & VAB Design Features
- LMM-as-Visual-Foundation-Agent
- POMDP (Partially Observable Markov Decision Process) problem로 정의
- state space $S$
- action space $A$
- transition function $T$
- reward function $R$
- instruction space $I$
- observation space $O$ $\to$ Visual input (images / videos)를 포함
- POMDP (Partially Observable Markov Decision Process) problem로 정의
- Design Features of VAB
- Visual-Centric: HTML과 같이 사람이 인터넷을 HTML없이 읽는 것에 착안하여, GUI를 task에 포함함
- High-Level Decision Making: text response를 통해 action을 호출함으로써 high-level planning & interacting을 구현
- Interactive Evaluation
- Trajectories for Behavior Cloning: 유효한 instructions, trajectories, 그리고 reward functions를 만들어 제공함.
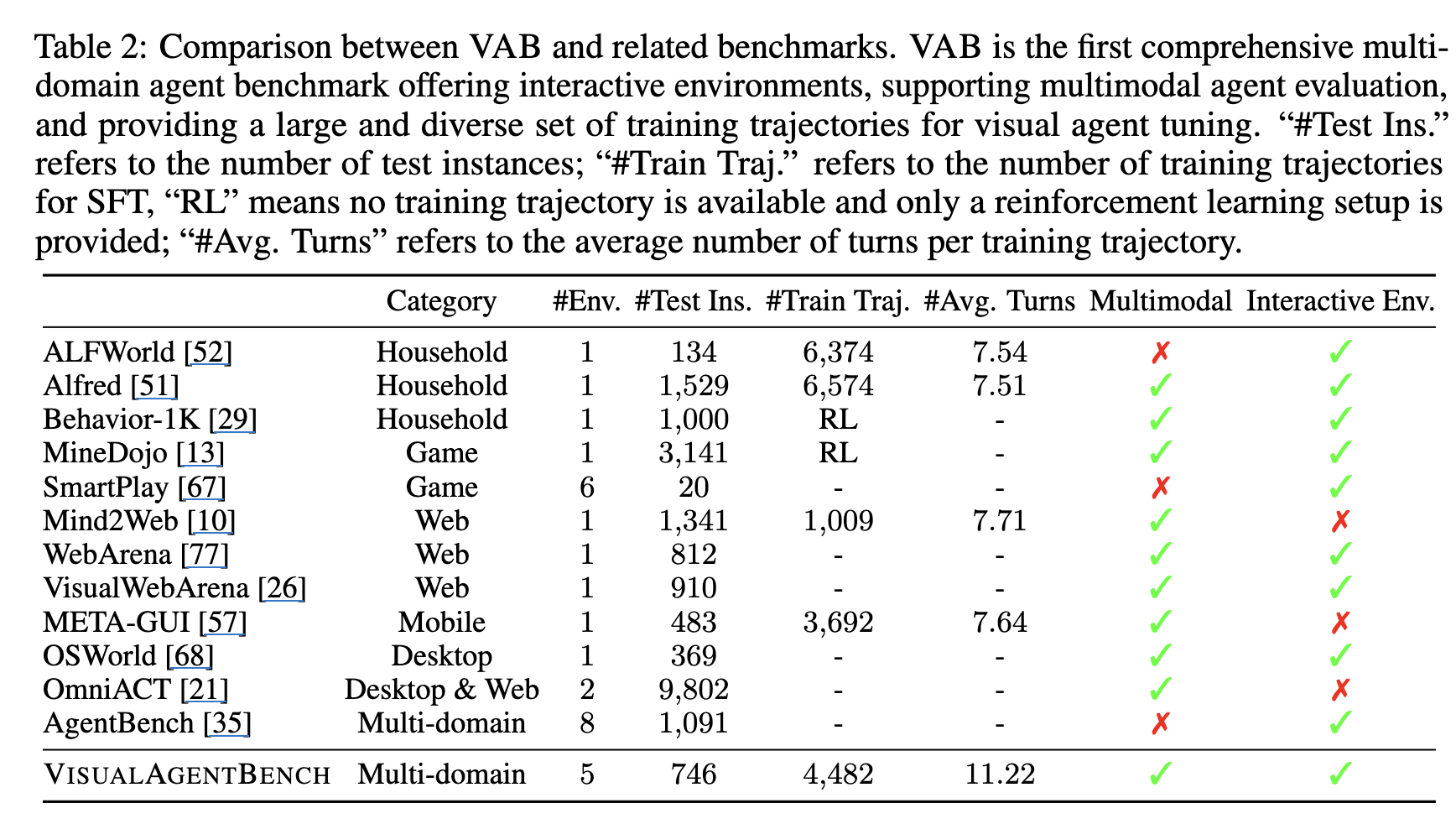
3.2 VisualAgentBench: Tasks and Environments
-
overview
3.2.1 Embodied Agent
-
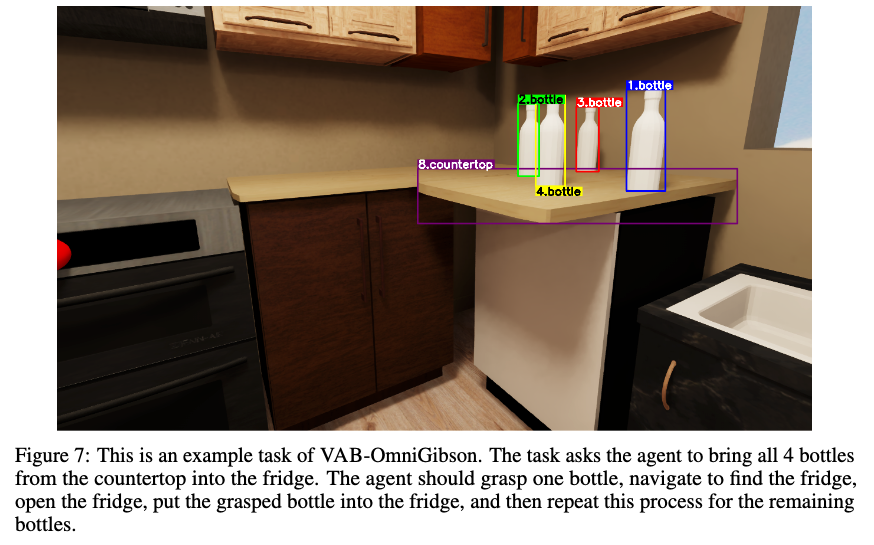
VAB-OmniGibson
-
가상의 가정환경에서 일어나는 복잡하고 다양한 everyday tasks를 수행하는 환경
-
environment: OmniGibson, high-fidelity의 Nvidia Omiverse로 이뤄진 simulator
-
물리적 효과, 다양한 scenes로 구성된 특성을 지님
-
insruction 예시
ex. Put all 8 plates from the countertops into the cabinet in the kitchen
-
action 예시
ex.
put_inside,grasp
-
-
Test set
- Behaviro-1K benchmark에서 181개 test task instances를 추출하여 저자가 손수 annotation 수행
-
Train set
- rule-based solver를 도입하여 long-horizon activies를 subtasks로 쪼갬 $\to$ 785 training task instances 생성
- LMM(
gpt-4-vision-preview)을 이용하여 87개 instances 생성 $\to$ 총 872 training trajectories 생성
-
Metrics: Behavior Domian Definition Language (BDDL)로 구성된 action에 대한 Success Rate
-
Action


-
예시
-
-
VAB-Minecraft
-
open-world 환경에서 일반화된 agent를 위한 다양한 task를 수행 (survival, harvesting, crafting, combat, creative tasks, etc)
-
instruction 예시
ex. Get a fishing rod in your inventory
-
environment: Minecraft로, JARVIS-1에서 정의한 action space를 채택.
-
Test-set
- 수동으로 116개의 task를 annotation
-
Train-set
- GPT-4-turbo를 bootstrapping해서 새로운 task를 design $\to$ 176 tasks
- GPT-4o를 JARVIS 1 memory에 할당하여 bootstrapping해서 새로운 task를 design $\to$ 206 tasks $\to$ total 382 trajectories
-
Actions

-
예시

-
-
GUI Agent
-
LMM이 UI element와 layout에 대한 이해해야 풀수 있음
-
VAB-Mobile: MOTIF, AITW는 offline으로 구성됨. VAB-Mobile은 Android Virtual Device(AVD) 기반으로 구현
-
instruction 예시
ex. Find a hotpot restaurant nearby and make a reservation for me tonight
-
Test-set
- 8개의 application에서 119개의 task를 취득
-
action space

-
-
VAB-Webarena-Lite: WebArena의 평가셋 812 중 165개를 선별하여 evaluation benchmark로 구성함.
Playwright를 통해 HTML SoM를 생성함-
HTML SoM, clickable element에 대해 텍스트 설명을 추가
-
Test-set: 165개의 task를 WebArena에서 추출
-
Train-set:
playwrightscript를 통해 rule-based로 1,186개의 training set 추출 (+reward function) -
action space

-
예시
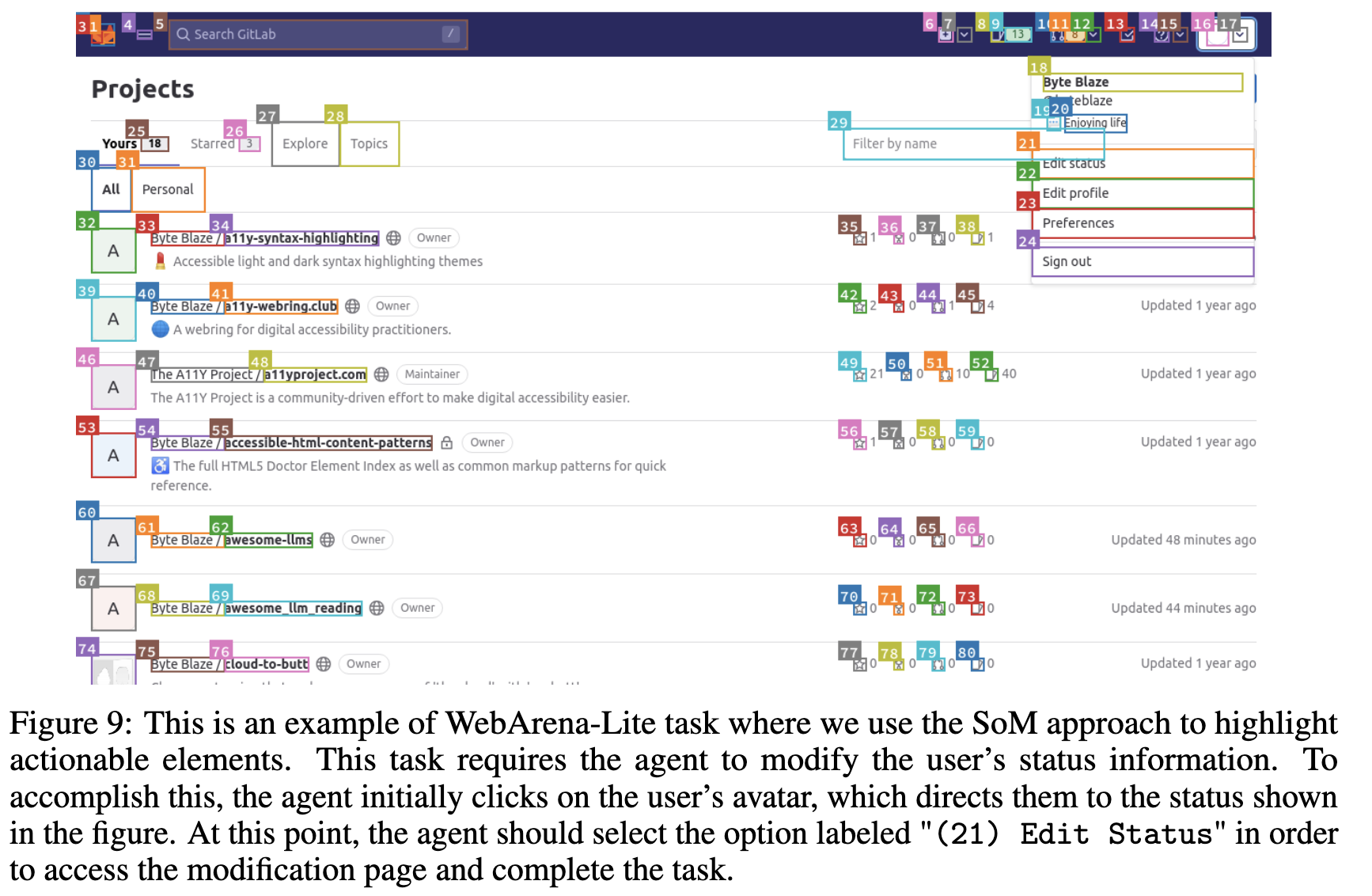
-
-
-
Visual Design Agent
-
CSS style에 web-frontend design task로, 임의로 one-step 망가뜨리고 (source) target image를 원복하는 CSS code를 생성하는 task.

-
Data collection: Random Corruption (single-corruption task)
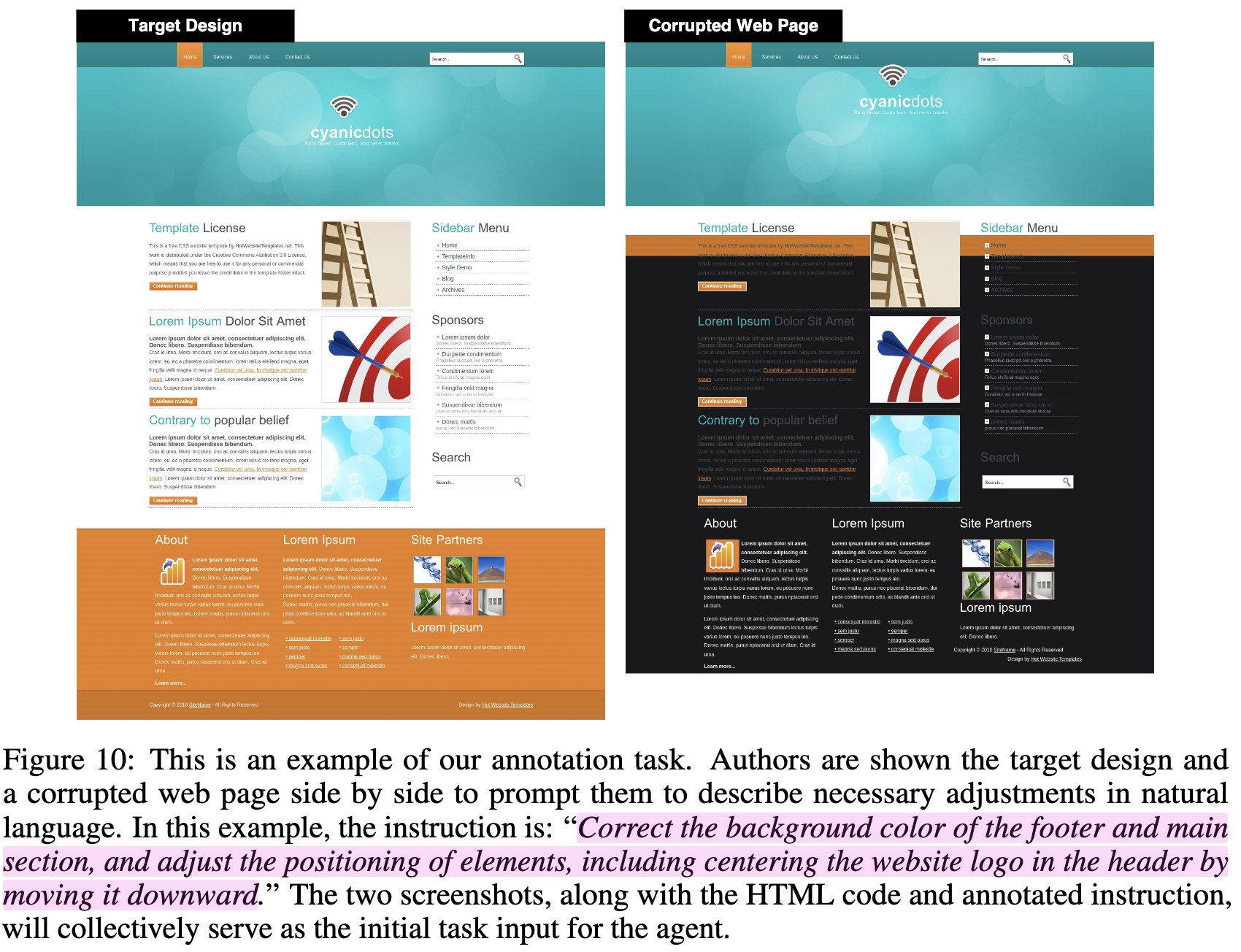
- source / target간의 차이를 instruction으로 만들어 제공
-
action space


-
Metric
- SSIM 0.9이상
-
3.3 Methodology for VAB Data Collection
3.3.1 Task Instance Collection: Prototyping and Instantiation
다양하고, real-world를 포괄하는 task를 추출할것
-
Prototyping
- high-level goals를 표현하는 task prototypes를 placeholder를 통해 만듦
-
Instantiation
-
Environment에서 관측된 element, conditions로 해당 protytpes가 grounding됨 (대치)
-
Judging functions가 여기서 생성됨 (reward function)
-
LLM이 expression의 다양성을 만듦 (paraphrase)
ex. VAB-CSS에서 single-corruption후, SSIM 0.8이하만 filtering하여 natural language description으로 difference를 묘사
ex. VAB-WebArena에서 40개의 task prototype를 생성하고, valid / invalid item으로 채움 (ex.
product, categories, prices)
-
3.3.2 Training Trajectory Collection: 3-level Strategies

- Program-based Solvers:
playwrightscript 등을 활용하여 prototype-specific programs으로 생성 - LMM Agent Bootstrapping: memory augmentations를 활용한 LMM (
chatgpt-4o)를 활용하여 trajectory를 생성 - Human Demonstration: human expert가 trajectory를 생성
4. Experiments
-
정량적 결과
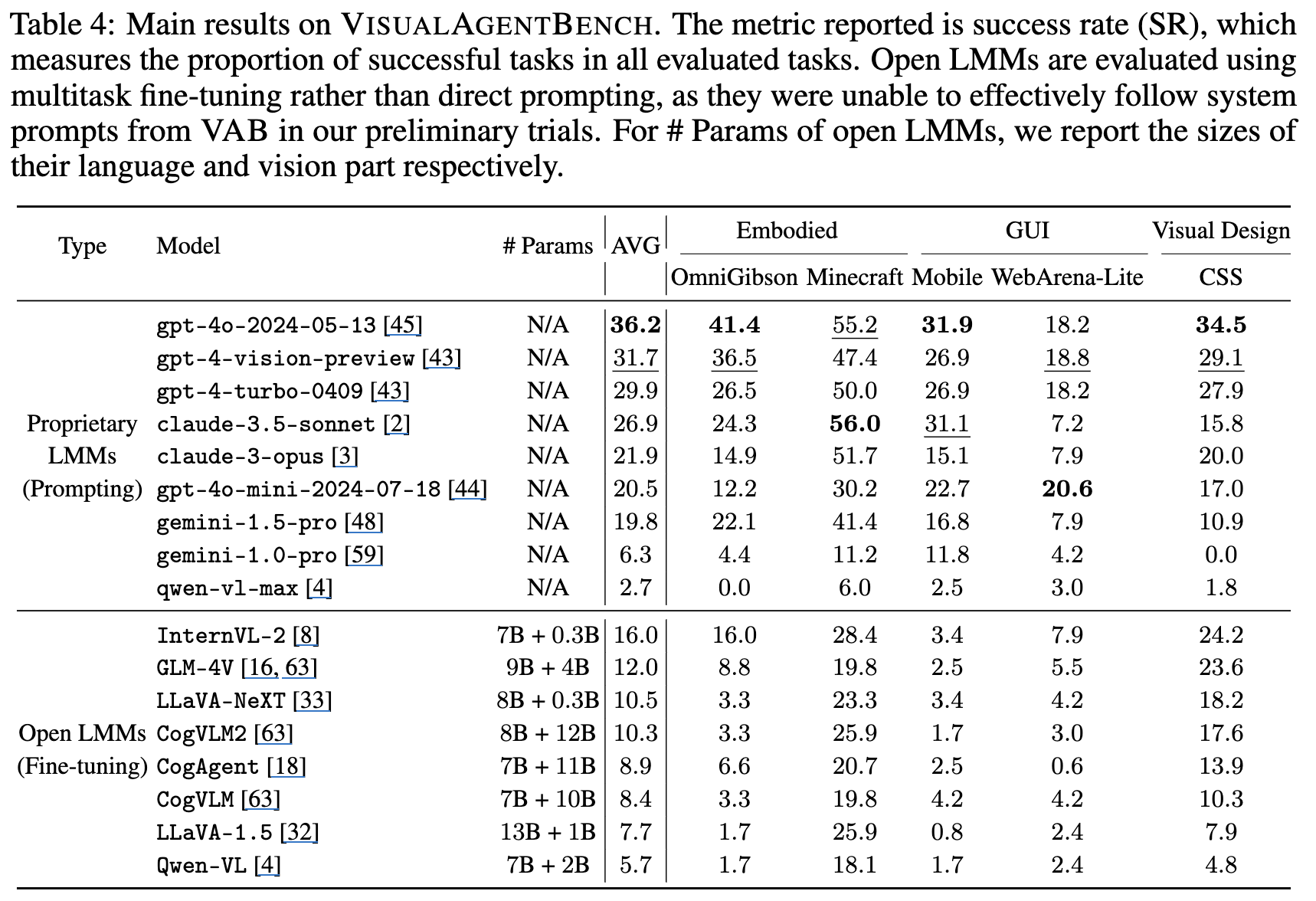
-
Ablation Studies
-
Object label 유/무에 따른 VAB-OmniGibson 결과
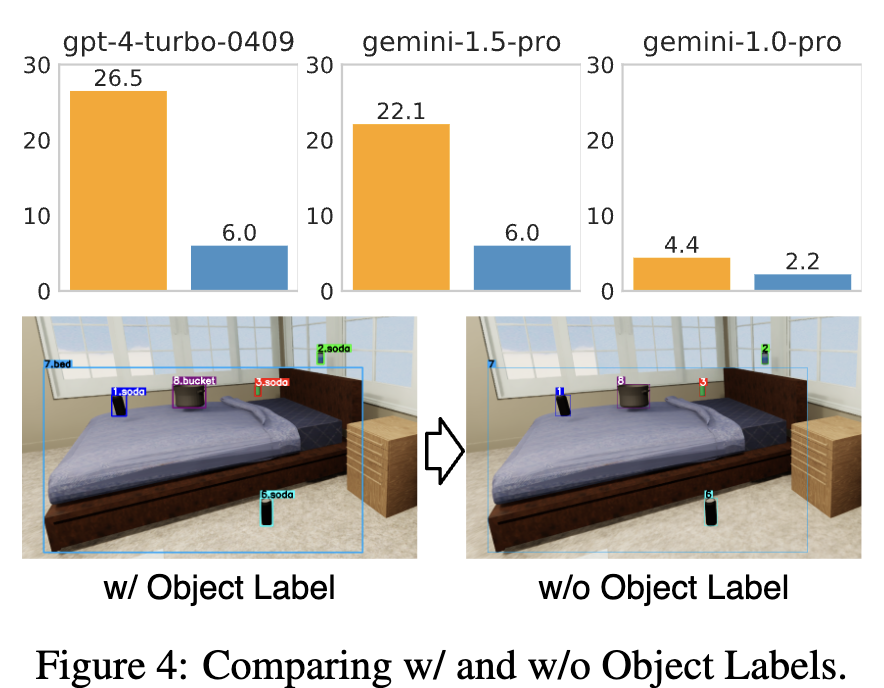
- 유가 훨씬 좋다.
-
SoM 유/무에 따른 VAB-WebArena 성능
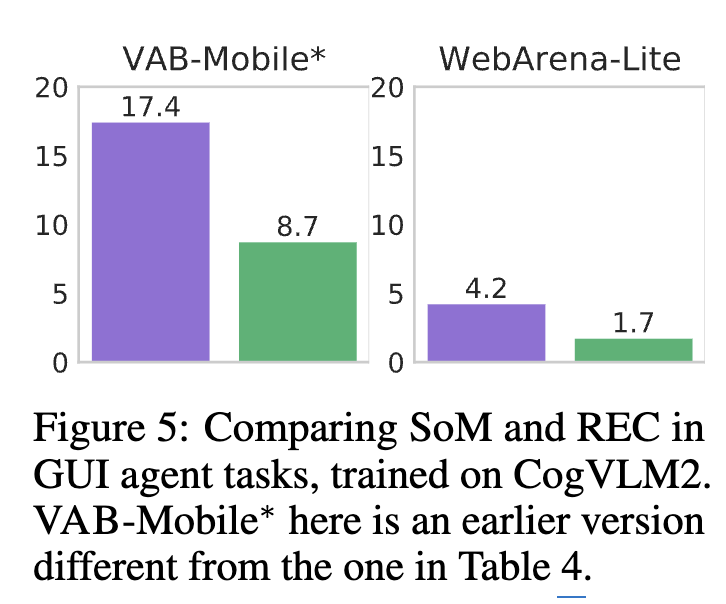
- SoM이 REC (pixel좌표 예측하는 task)보다 훨씬 좋다.
-
ReAcT vs. AcT (w/o CoT)

- Task마다 다르지만, 종합적으로 CoT 유무는 큰 성능차이가 없다. (오히려 없는게 좋을수도 있다.)
-
incorrect actions가 존재할 때, success rate
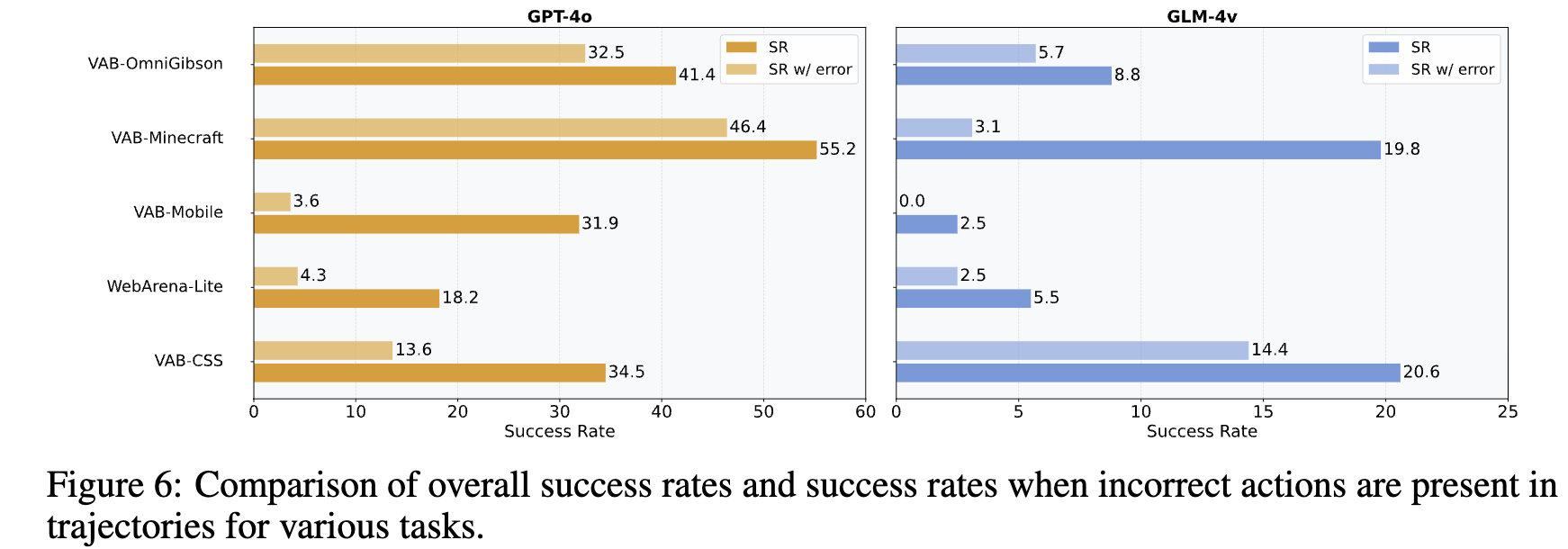
- GPT-4o는 incorrect action이 존재해도 성능이 좋다 $\to$ error recovery 성능이 좋다는 것을 반증
-