[TTA][PT] TPT: Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models
[TTA][PT] TPT: Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models
- paper: https://arxiv.org/pdf/2209.07511.pdf
- github: https://arxiv.org/pdf/2209.07511.pdf
- NeurIPS 2022 accepted (인용수: 88회, ‘24-01-18 기준)
- downstream task: TTA for CLS
1. Motivation
- 최근 Vision-Language model들의 발전으로 Prompt Tuning기반이 각광받고 있다.
- Few shot 기반 Domain specific한 loss로 학습시, generalization 성능을 잃을 수 있다.
- etc, CoOp, CoCoOp등은 few-shot 기반으로 downstream task specific하게 학습하기 때문
- single sample기반 prompt tuning을 VLM으로 Test-time Adaptation하는 것은 본 논문이 최초라고 주장함
- Data-distribution shift가 있는 상황에서 generlization 성능을 유지하면서, prompt를 optimization할 수 있는 방법은 없을까?
2. Contribution
-
학습 데이터 (annotation)이 전혀 없이도 single image 기반으로도 prompt를 optimize할 수 있는 TPT (Test-time Prompt Tuning)기법을 제안
- Contrastive Learning 기반 같은 이미지를 여러번 augmented하여 consistency regularization을 loss로 주게 되면, decision boundary가 low density region으로 옮겨가는 경향이 있다고 함.
-
Confidence 기반 selection 모듈을 통해 동일 augmentation이더라도, low confidence한 view는 prompt tuning에 사용하지 않는 plug-and-play 모듈 제안
-
다양한 domain shift상황에서 image classification (natural distribution shift, cross-dataset generalization)에 및 visual reasoning에 적용하여 성능 우위를 보임
- natural distribution shift : Corruption등
- cross-dataset generalization: class가 다른 경우 (open-vocabulary)
3. TPT
-
Overview
-
Image Classification
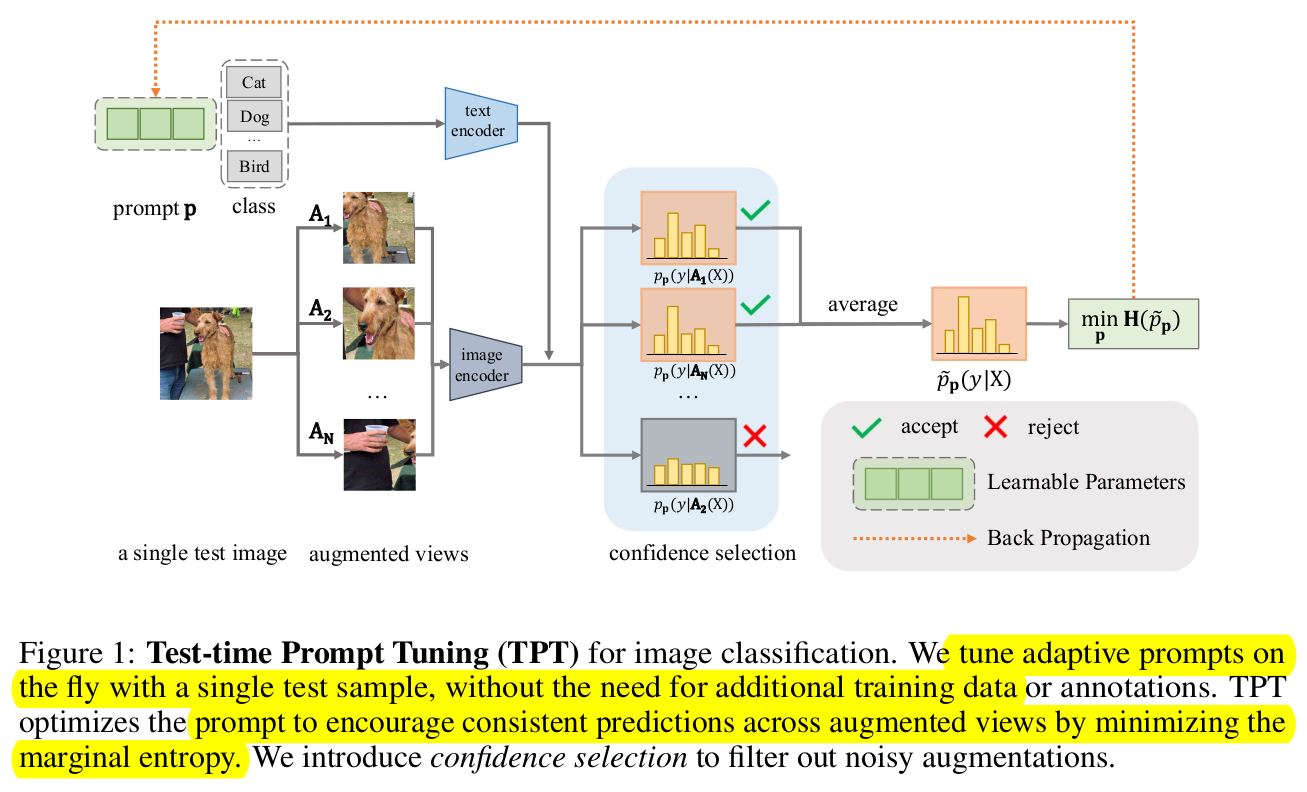
-
baseline : CLIP
-
Visual Encoder, Text Encoder로 구성됨

-
class token을 추가한 text embedding vector와 image embeddinb vector의 similarity를 classification score로 바라봄
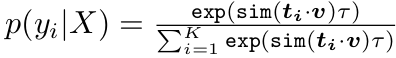
-
-
-
Original Prompt Tuning : downstream task loss를 통해 prompt를 tuning $\to$ G.T. (y) 사용
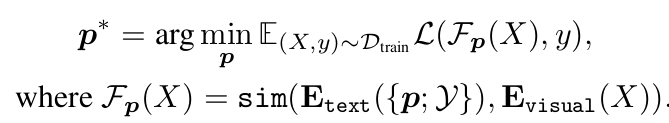
- P$^*$: $\in \mathbb{R}^{L \times D}$
- L: Token의 수
- D: embedding 사이즈
- P$^*$: $\in \mathbb{R}^{L \times D}$
-
TPT Prompt Tuning: G.T. (y)가 필요 없음
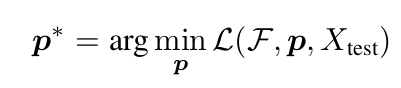
-
N번의 augmentation중 Top-K개의 Confidence Selection을 통과한 Ensemble Entropy Loss 를 사용 $\to$ 10%가 제일 좋았다고 함
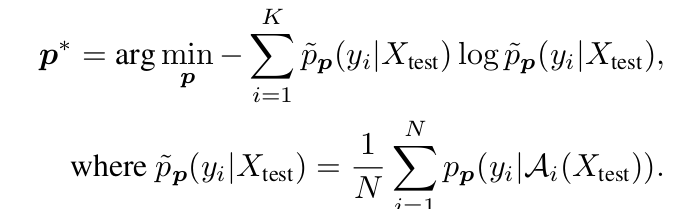
- N: Augmentation한 횟수
- K: Top-K confidence score의 prompt
- $\tilde{p}_P$: i번째 augmented view의 similarity score $\in \mathbb{R}^C$
- C: Class 갯수
-
최종 식
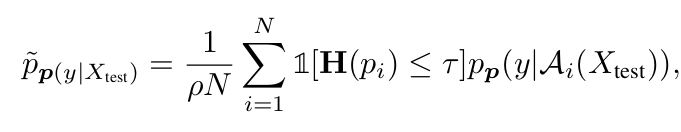
- $\rho$: Top-K percentile (default: 0.1)
- $\tau$: confidence score (default: 0.1)
-
-
Visual Reasoning
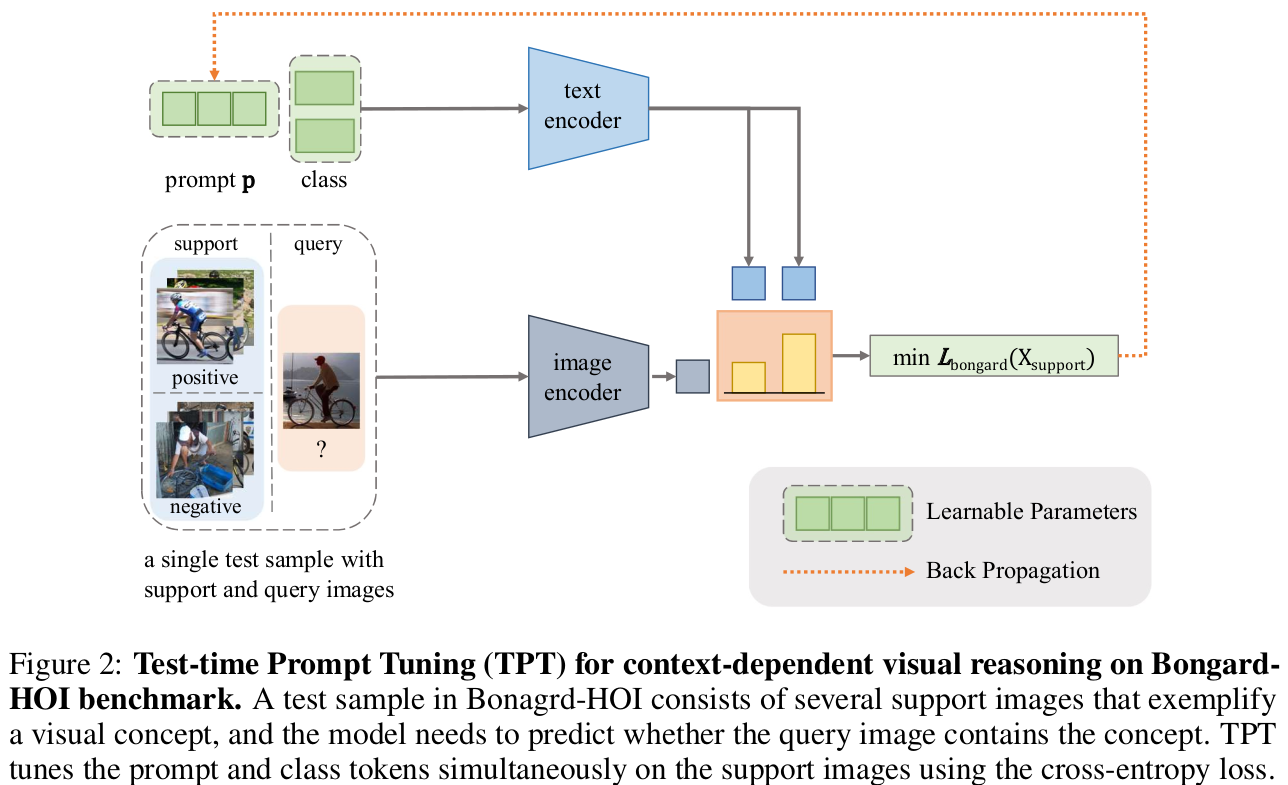
- 2개의 support set, 1개의 query set으로 구성된 context-dependent visual reasoning task
- Humain Object Interaction (HOI) dataset으로, “ride bike”와 같은 binary classification 으로 볼 수 있음
-
HOI Visual Reasoning Prompt Tuning
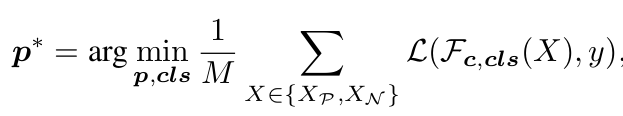
- M: Support set의 갯수 (default: 2)
- p: prompt vector $\in \mathbb{R}^{L \times D}$
- L: prompt의 갯수
- D: embedding 사이즈
- cls: class token. Visual Reasoning에서는 prompt와 함께 tuning함
- 2개의 support set, 1개의 query set으로 구성된 context-dependent visual reasoning task
-
4. Experiments
-
Natural Distribution Shift (vs. Few-shot VLM settings)
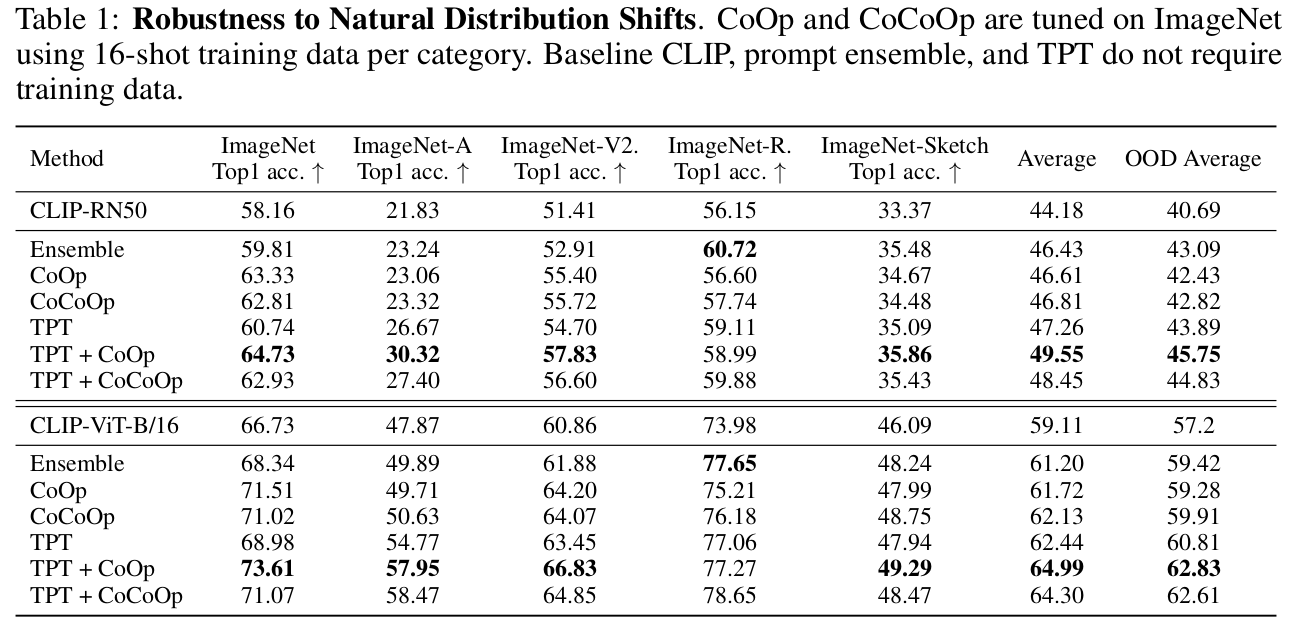
-
Cross-datasets (vs. Few-shot VLM settings)
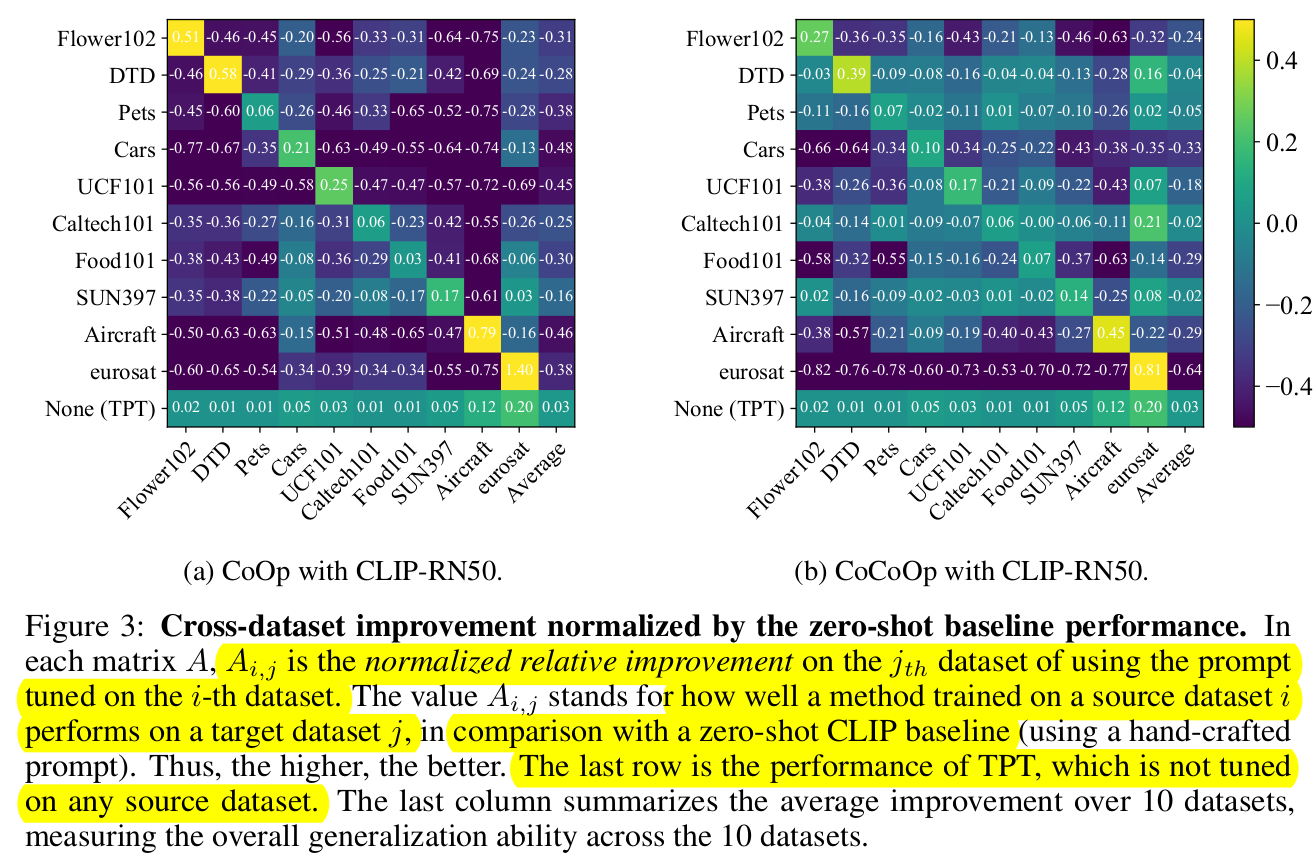
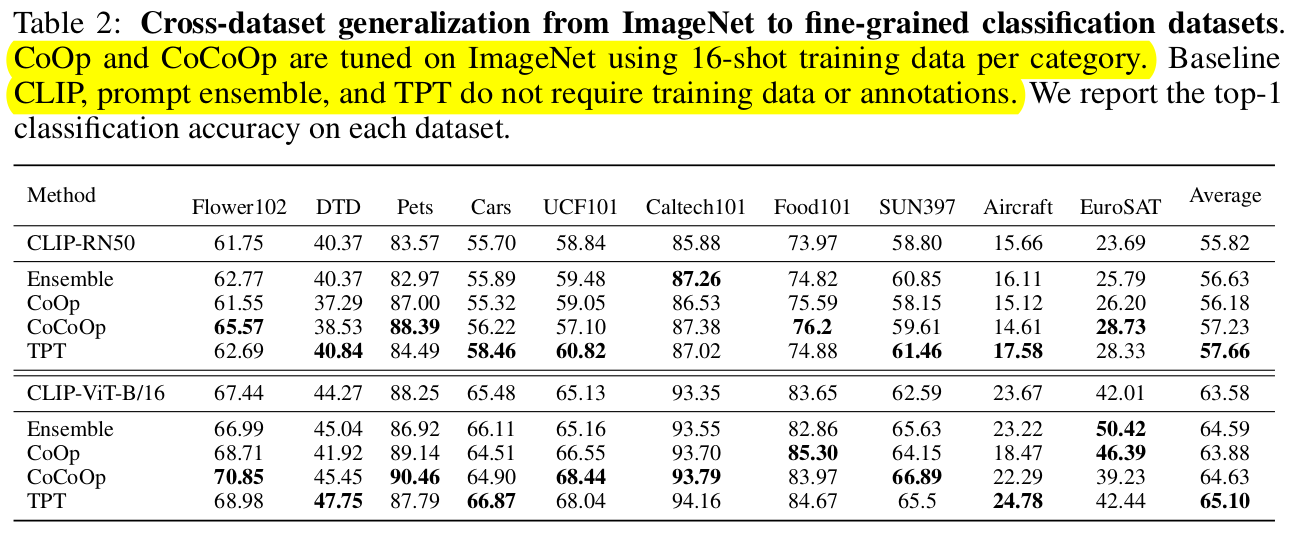
-
Visual Reasoning
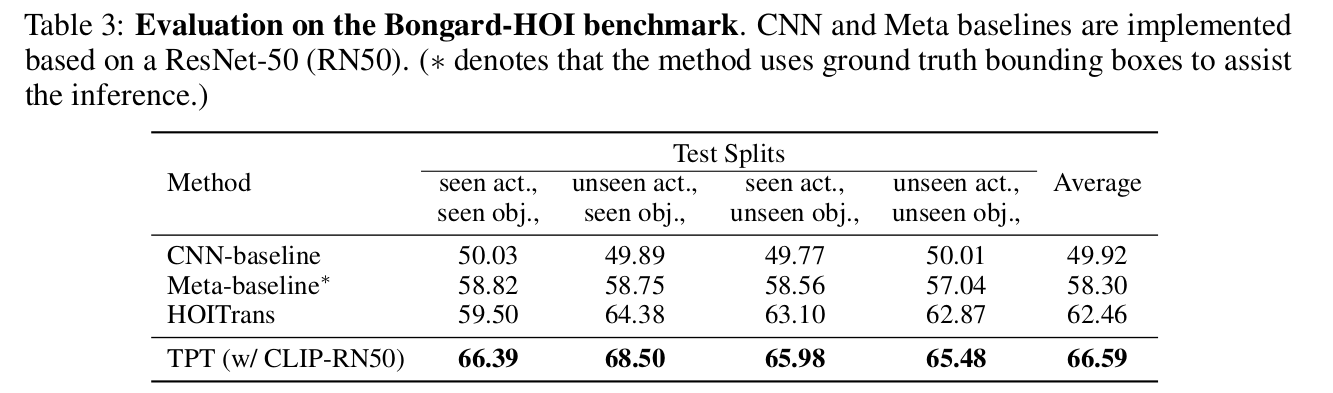
-
Ablation Studies
-
Top-k percentil ($\rho$)와 tuning parameter에 따른 성능 변화
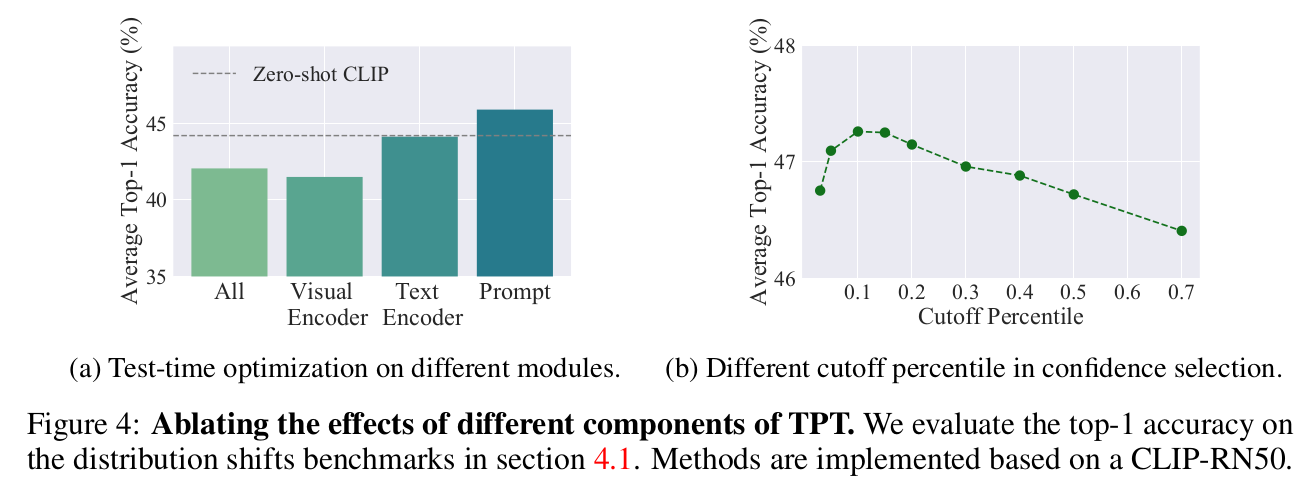
- (a) Tuning parameter 로 prompt tuning이 제일 tuning 최적화 효과가 좋다
-