[SSL][CLS] Sound-Based Sleep Staging By Exploiting Real-World Unlabeled Data
[SSL][CLS] Sound-Based Sleep Staging By Exploiting Real-World Unlabeled Data
- paper: https://openreview.net/pdf?id=mIRztWMsVJ
- github: x
- ICLR Time Series Representation Learning workshop 2024 accpeted(인용수: 0회, ‘24-01-08 기준)
- downstream task: SSL for sequence prediction task
1. Motivation
-
음성 신호 기반의 sleep-staging을 딥러닝 기반으로 풀고자 함
-
집안에서 labeled-data를 취득하기 어려움 $\to$ real-world sleep sound unlabeled (+noisy) data를 학습에 어떻게 활용하면 좋을까?
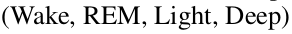
2. Contribution
-
time-series data (sound-data)에 self-supervised learning을 접목한 sequential consistency loss를 제안함
-
1개의 음성 신호 sample만 가지고, 깨었는지, Rem수면인지 얕은 잠인지, 깊은 잠인지 알 수 없음 $\to$ sequential data를 가지고 매 sample이 어떤 상태인지 예측
-
-
out-of-distribution data를 고려한 semi-supervised contrastive loss를 제안함
3. Purposed
-
Model
- baseline: sequence-to-sequence 기반 SoundSleepNet
- backbone+head구조를 따옴
- SleepFormer : MobileViTV2 + head (FC layer)
- baseline: sequence-to-sequence 기반 SoundSleepNet
-
Loss
-
Supervised Loss
-
Cross Entropy Loss
-
매 frame을 sequence 내에서 예측
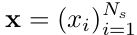 $\to$
$\to$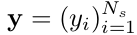
-
-
Unsupervised Loss
-
Sequential Consistency Loss
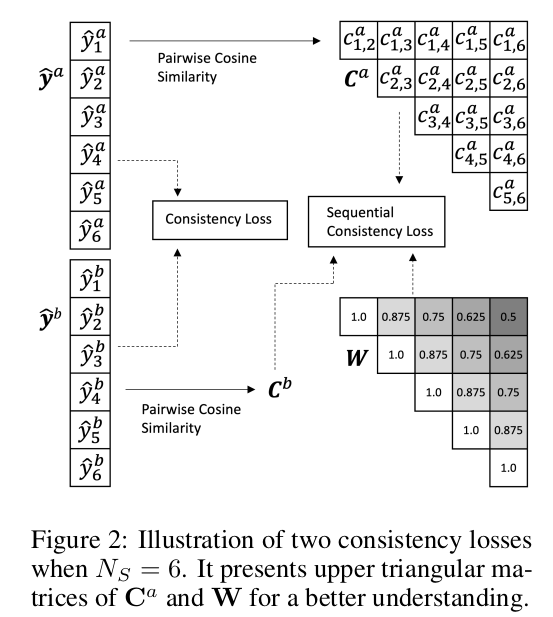
-
서로 다른 augmentation $a, b$를 동일 sample에 대해 적용 후, sequential data별로 similarity metrix를 계산하여, weighting을 부여한 채로 consistency를 loss로 매김 $\to$ 가까운 sample일수록 유사도가 높을 것이라 가정함
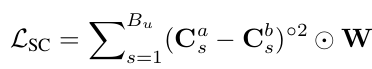
-
C$_s^a$: a-augmented s 번째 sequence의 similarity metric $\in N_s \times N_s$
-
C$_s^b$: b-augmented s 번째 sequence의 similarity metric $\in N_s \times N_s$
-
W: Weighted metric. 가까운 sequence내 sample엔 더 높은 가중치 부여. vice versa
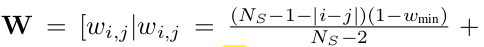
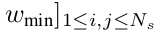
- $w_{min}$: 가장 멀리 떨어진 sample에 해당하는 weight. 위 식에서는 $N_s=6$일 때 0.5
-
-
-
Semi-supervised consistency Loss
-
baseline: Class-aware Semi-Supervised Contrastive Loss (CSSCL)
-
supervised contrastive loss로, OOD sample을 in-class feature에서 밀어내도록 학습
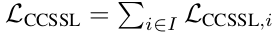
- i: i번째 augmented sample $\in [0,…,2*N]$
- N: 전체 sample의 갯수 =$B_uN_s$
- $B_u$: unlabeled-sequence의 batch size
- $N_s$: sequence의 길이
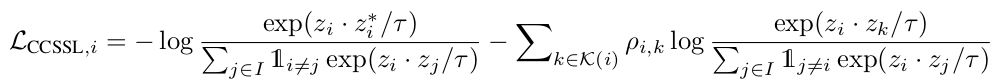
- $z_i$: i번째 sample의 feature
- $z_i^* =z_{(i+N) \% 2N}$ : i번째 sample의 (다른) augmented feature
- $K(i)$: i번째 sample의 pseudo label과 같은 class에 속한 index group
- $\rho_{i,k}=max(\hat{y}_i)max(\hat{y}_k)$
$\to$ noisy label이 많은 경우, CCSSL은 unreliable하다. 따라서 Semi-sup Contrastive Loss를 제안한다..
-
-
Semi-Supervised Contrastive Loss (SSC) : reliable labeled-data를 anchor로 사용하여 trustyworthy postive data는 PULL, negative data는 PUSH
-
이때, labeled data (m)에 대해서는 detach하여 loss를 흘리지 않는다.
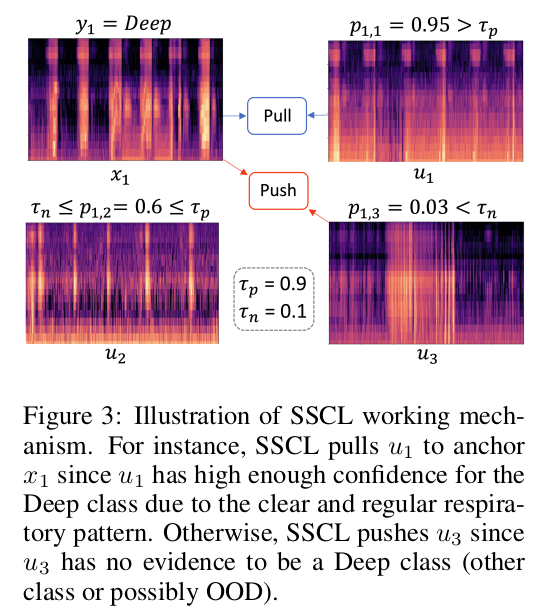
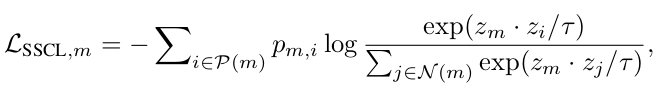
- $m$: m번째 labeled (anchor) data
- $p_{m,i}$: $y_m \times \hat{y}_i$
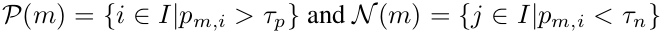
-
-
-
Total Loss
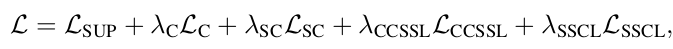
- 특이한건, Pseudo label를 활용하지 않았다.
-
-
4. Experiments
-
Home-PSG dataset (Asleep dataset, 공개 안함) + Ablation

-
PSG-Audio dataset (opened data)