[RL] SimPO: Simple Preference Optimization with a Reference-Free Reward
[RL] SimPO: Simple Preference Optimization with a Reference-Free Reward
- paper: https://arxiv.org/pdf/2405.14734
- github: https://github.com/princeton-nlp/SimPO
- NeurIPS 2024 accepted (인용수: 504회, ‘25-07-20 기준)
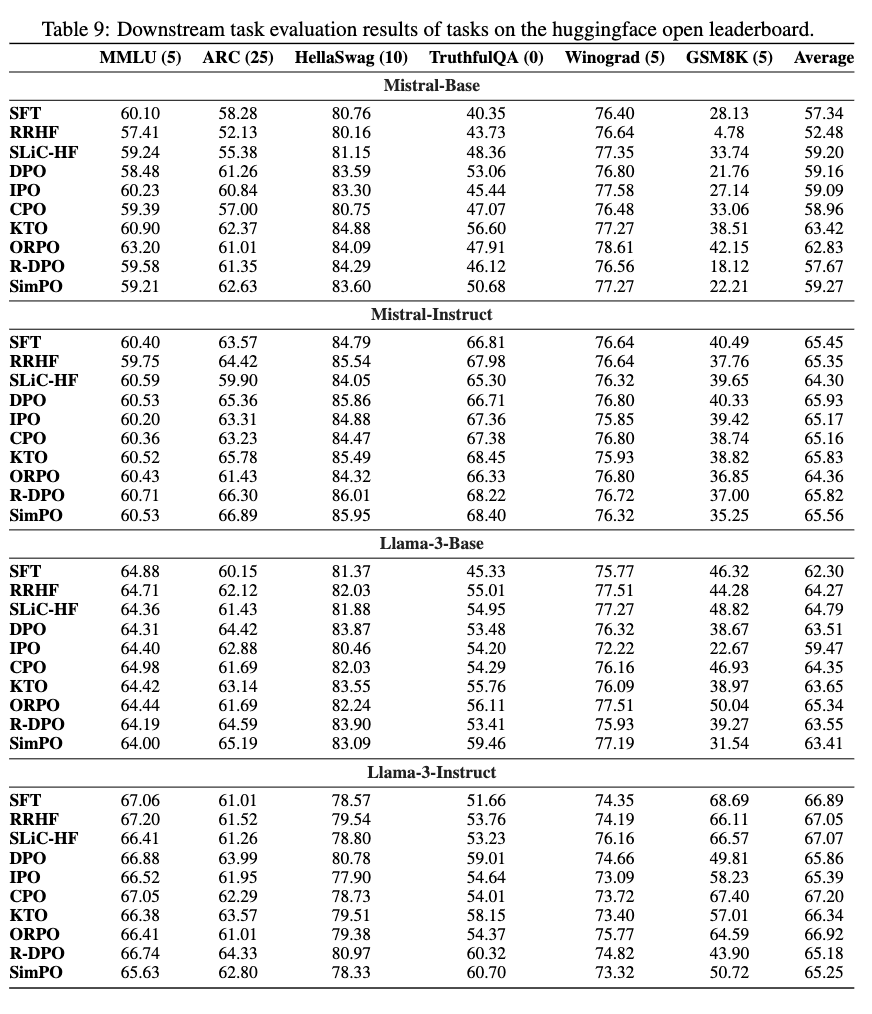
- downstream task: 인문/자연과학의 이해(MMLU), 상식 추론(ARC, HellaSwag, Wino-Grad), 수학 (GSM8K)
1. Motivation
-
LLM을 지도학습 한 이후, 사람의 선호도를 반영하는 후학습 방식 (RLHF)는 별도의 reward 모델을 두는 불편한 절차로 인해, 최근에는 해당 모델 없이 선호/비선호 데이터셋만 가지고 학습 가능한 DPO (Direct Preference Optimization)이 대두되었다.
-
DPO 방식은 SFT로 학습한 reference model (freezed)과 DPO로 학습중인 policy model 간의 log probability 비율을 가지고 reward를 계산한다.
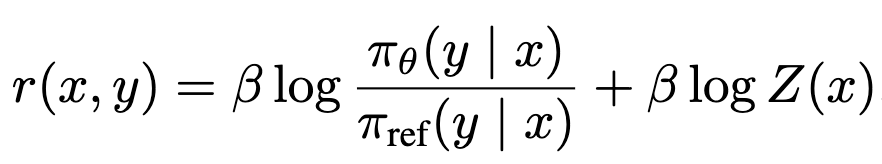
- Z(x): Parition function. log probability의 정규화 (norm=1) 관련 상수라 무시
-
해당 reward는 decoing 시 guide하는 generation metric (ex. Beam Search)과 align이 되어있지 않아, 학습-추론 괴리로 인해 suboptimal하게 학습이 된다.
$\to$ Reference model도 불필요하며, generation metric의 guiding rule과 align된 새로운 RL 방식을 제안해보자!
2. Contribution
-
Simple하고 effective한 offline preference optimization 방식인 SimPO를 제안한다.
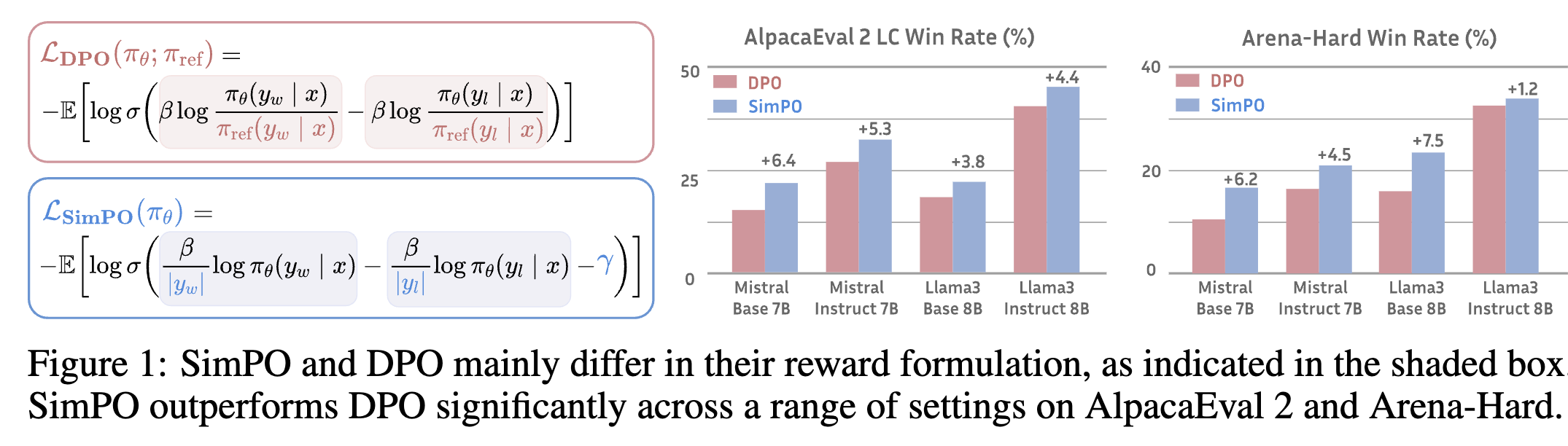
- Length Normalized Reward: 각 token별 log probability의 Average값을 reward로 설계함 $\to$ decoding guide (beam search) 방식과 align + Reference model 불필요
- win/lose responses 차이에 margin $\gamma$를 추가하여 더욱 격차가 나도록 학습을 수행
-
Performance advantage
- 최신 DPO-variant (reference-free objective ORPO)보다 다양한 학습 셋업/benchmark에서 우수한 성능
- AlpacaEval 2, Aerna-Hard (+6.4point, +7.5point)
- 최신 DPO-variant (reference-free objective ORPO)보다 다양한 학습 셋업/benchmark에서 우수한 성능
-
Minimal Length exploitation
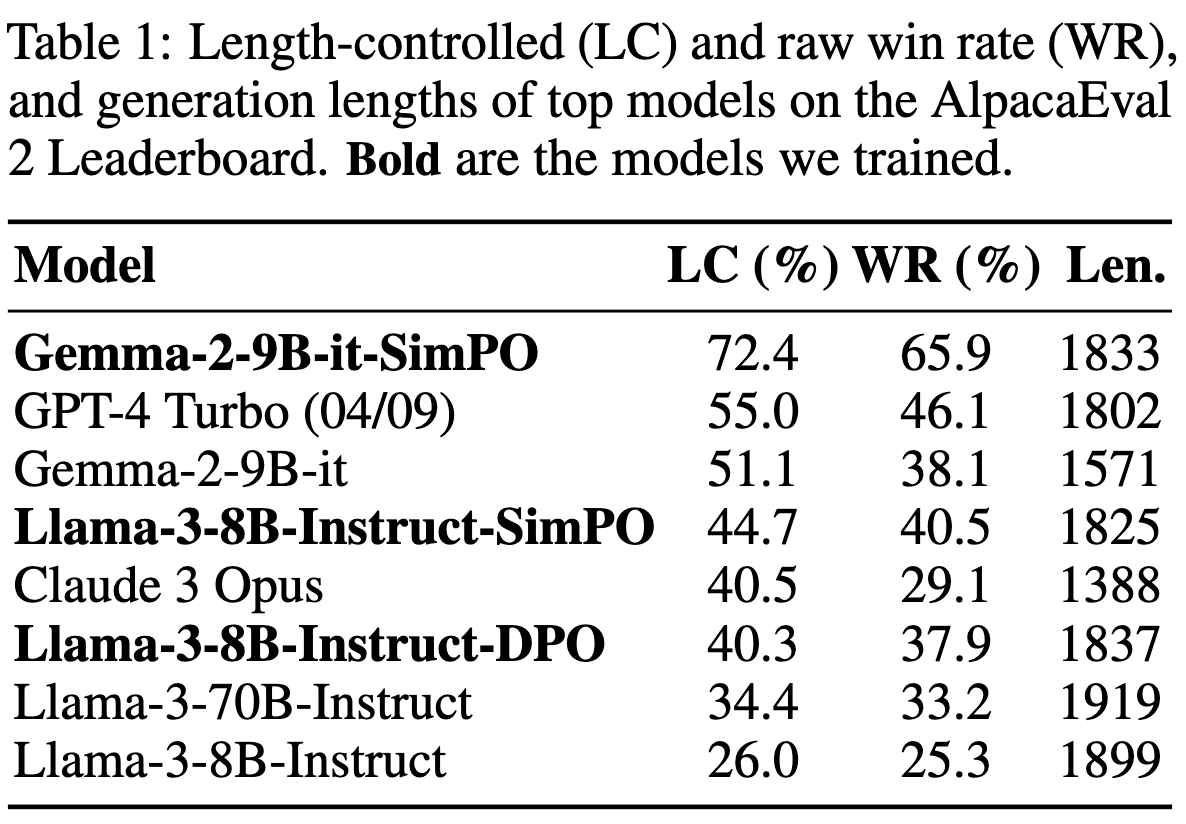
- 출력길이를 거의 늘리지 않으면서 질높은 output을 생성
3. SimPO
3.1. Background: Direct Preference Optimization
-
Reward: Reference model기반으로 policy model과의 log probability 비율로 정의
-
장점: Reward 모델이 별도로 불필요
-
단점: Reference model이 필요
-
-
Loss: Bradley-Terry (BT) ranking objective에 적용하여 preference optimization loss를 정의
-
Bradley-Terry ranking objective
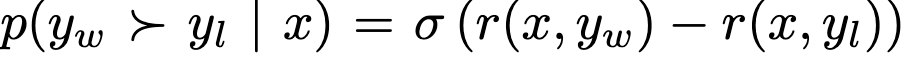
-
DPO Loss
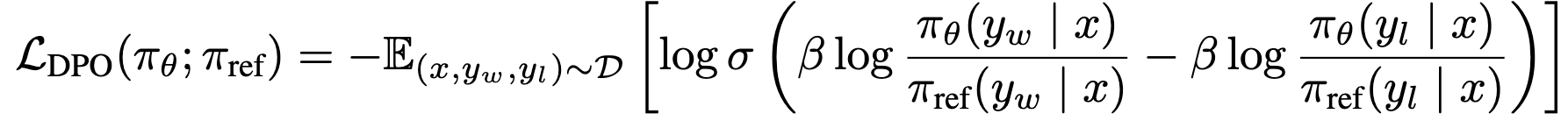
-
3.2 A Simple Reference-Free Reward Aligned with Generation
-
DPO의 reward와 generation간의 discrepacy
-
추론 환경에서는 reference model이 없이 policy model의 log-likelyhood만 존재하므로, mismatch가 발생함
-
다른 말로하면, 반드시 아래가 만족하는게 아님
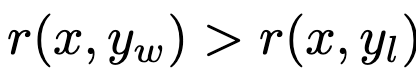 $\to$
$\to$ 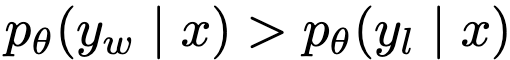
-
이는 DPO의 확률분포를 보면 50%만 win probability가 lose probability보다 높은 걸 통해, 증명할 수 있음
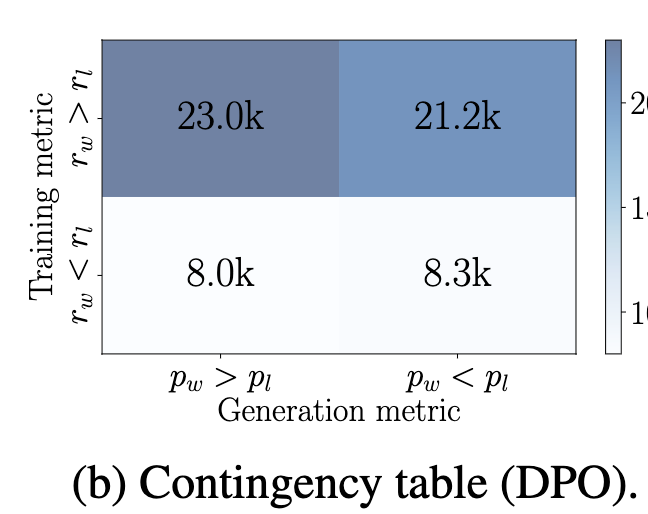
-
-
Length Normalized Reward Function
-
Summed log-probability: 이는 긴 정답의 확률이 낮아지는 특성으로 인해, win이 Lose보다 긴 문장일 경우 인위적으로 win의 probability를 높이게 되어, 성능 하락을 유발함
-
Average log-probability: length-bias를 없애며, generation(추론) 환경과 정렬된 reward
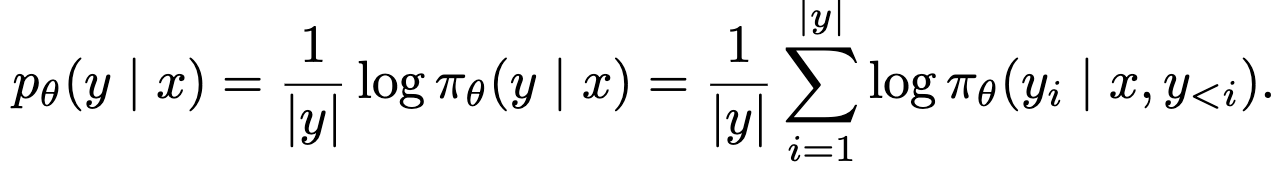
-
SimPO Reward
- 장점: Reward model / Reference model 불필요
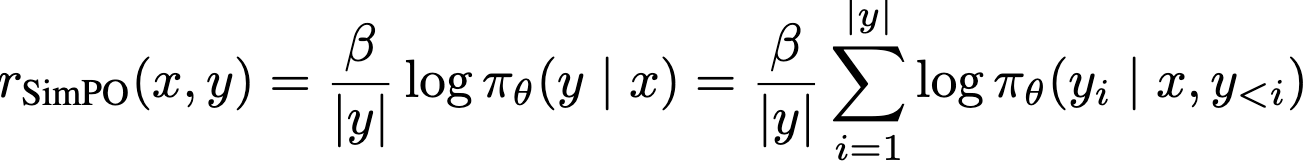
-
3.3 SimPO Objective
-
Target Reward Margin: $\gamma > 0$
-
Bradley-Terry Objective with margin
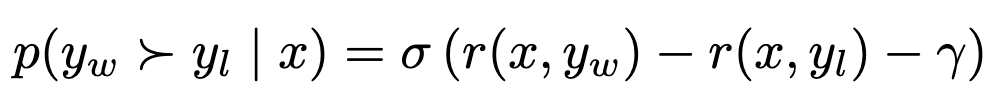
-
Objective
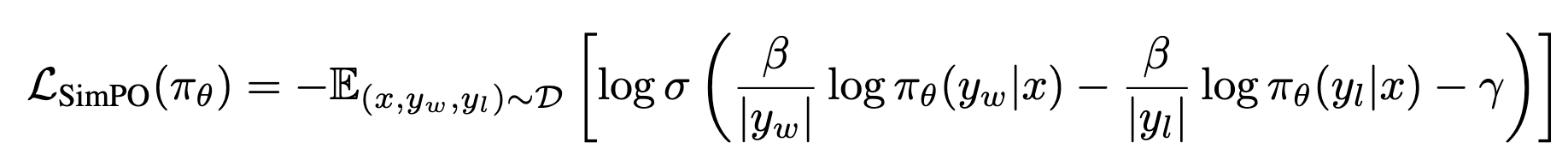
-
Gradients vs. DPO
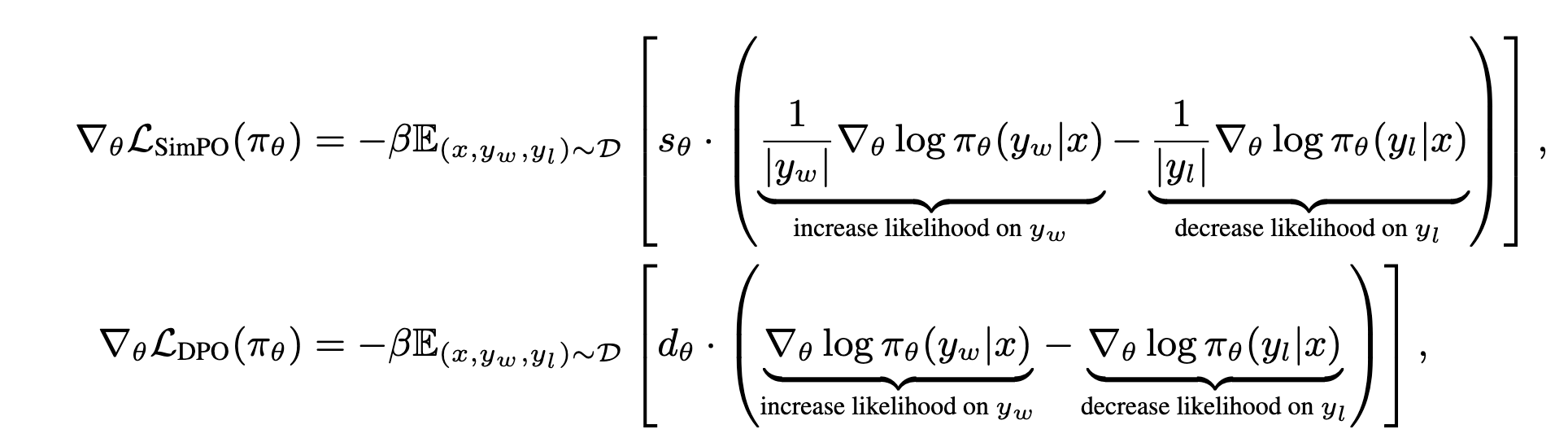
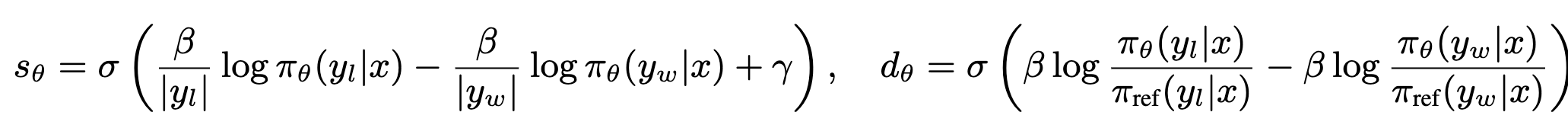
- DPO는 length bias가질 확률이 높음
- SimPO는 policy model의 win prob / lose prob만으로 구현되어, 직관적인 reward 적용 가능
4. Experiments
4. 1 Experiment setup
-
Model & Training Setting
- Llama-3-8B Base / Instruct
- Mistral-7B Base / Instruct
- Gemma-2-9B Instruct
-
Evaluation Benchmarks

- Benchmarks
- MT-Bench
- AlpacaEval 2
- Arena-Hard v0.1
- Evaluation Metrics
- Win Rate (WR)
- Length-Controlled win rate (LC)
- Benchmarks
-
Baselines

4.2 Main Results & Ablations
-
정량적 결과
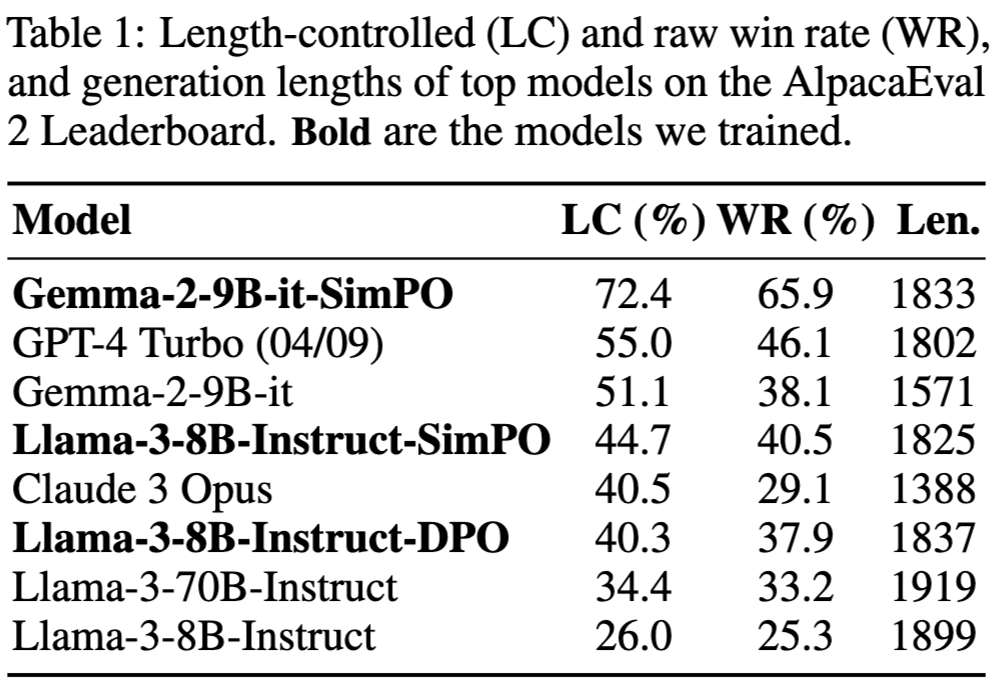
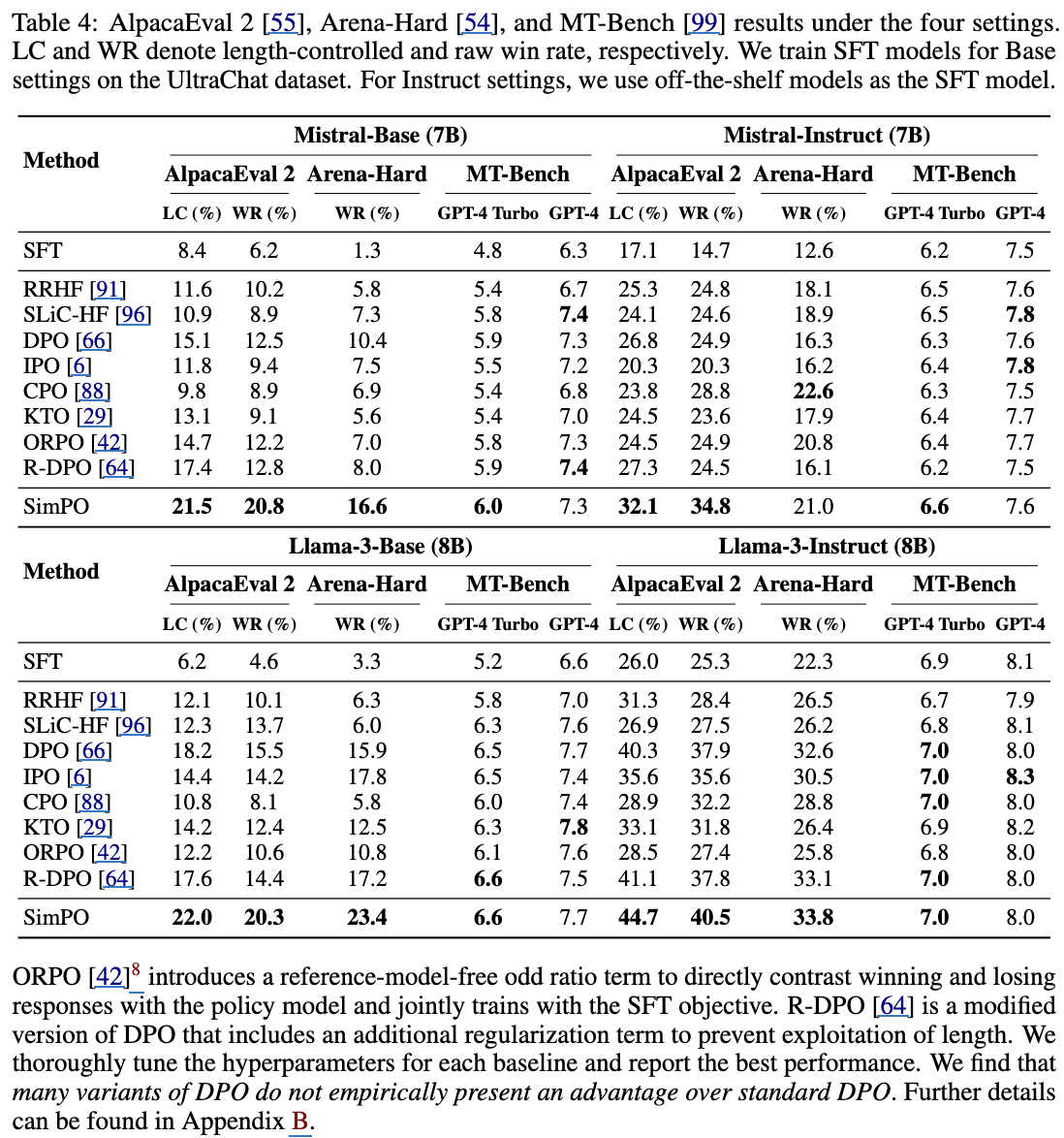
-
Length가 길어야 성능이 좋은 benchmark (Arena-Hard)만 CPO가 높고, 나머지는 SimPO가 좋음
-
단 MT-Bench와 같이 평가 성능에 randomness가 가미된 경우, 성능이 안좋게 나옴
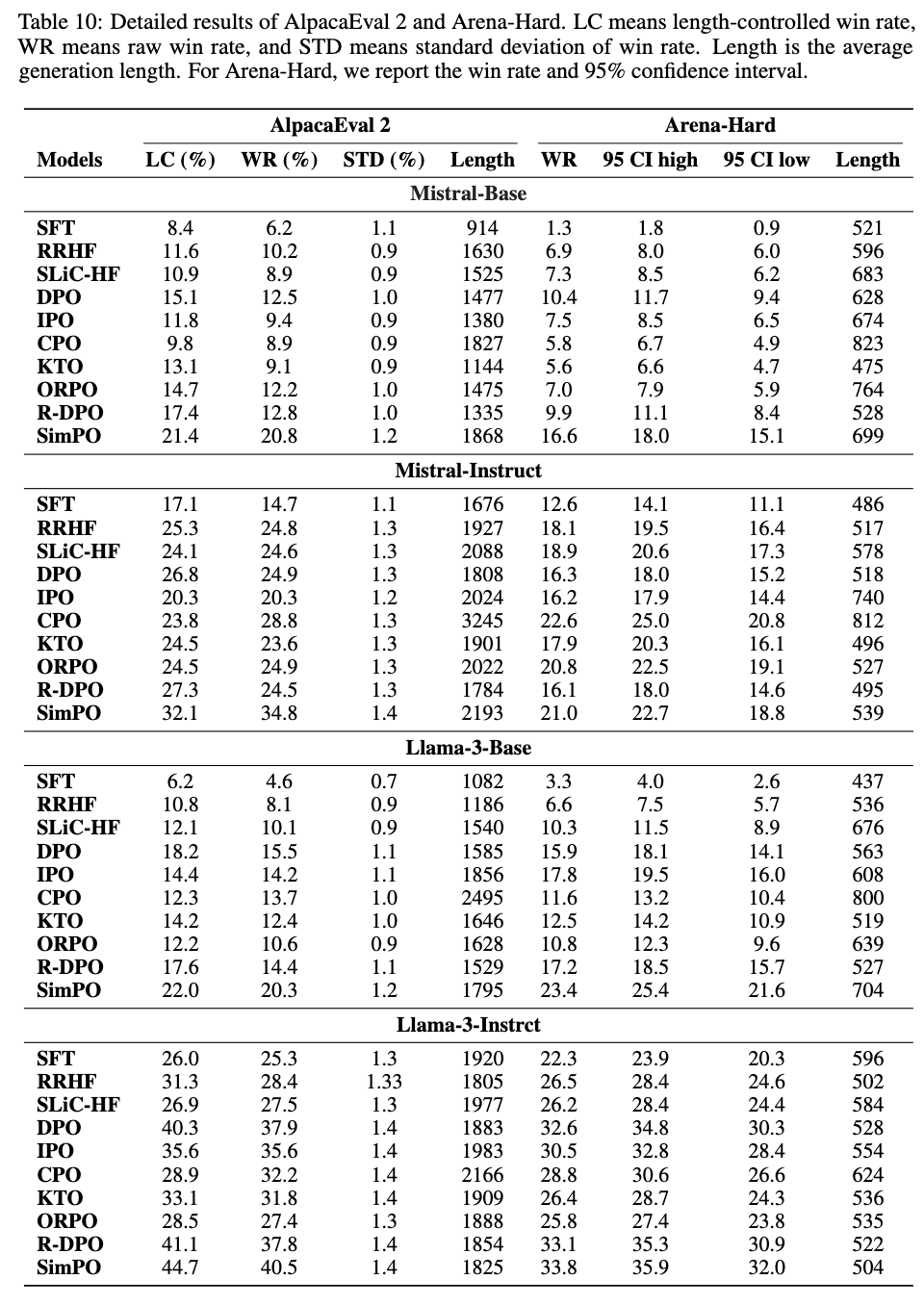
- pretrianed로는 Instruct가 base보다 낫다.
-
-
Ablation Studies
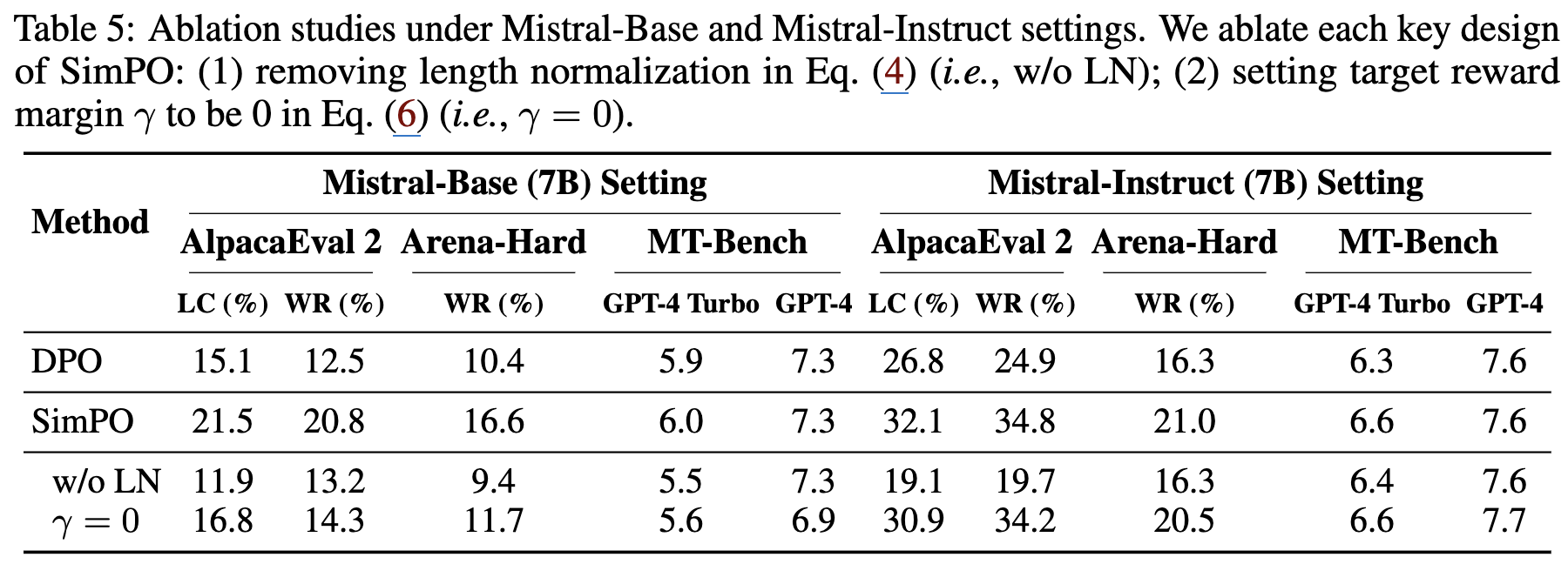
4.3 Length Normalization (LN)는 Length Exploitation을 방지
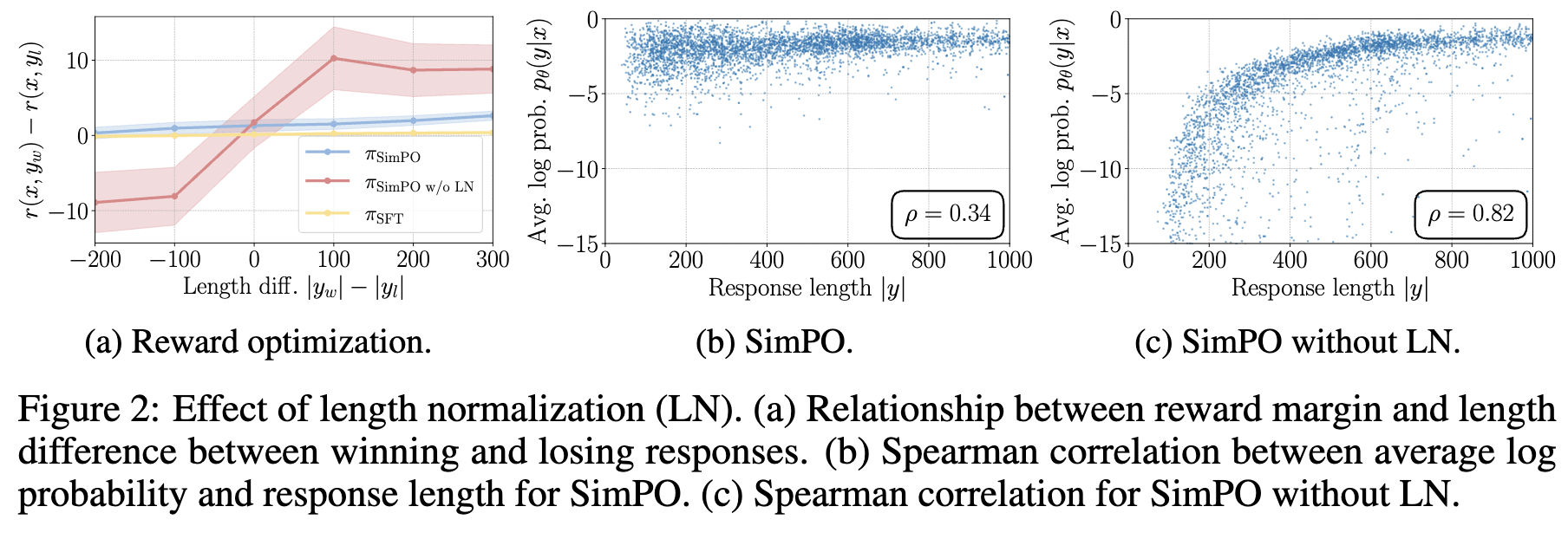
- LN은 win/loss probability difference를 증대시킨다. (a)
- LN을 제거하면, reward와 response length간의 양의 상관관계를 갖는다. 즉 Length Exploition (b vs. c)
4.4 SimPO의 Target Margin의 효과
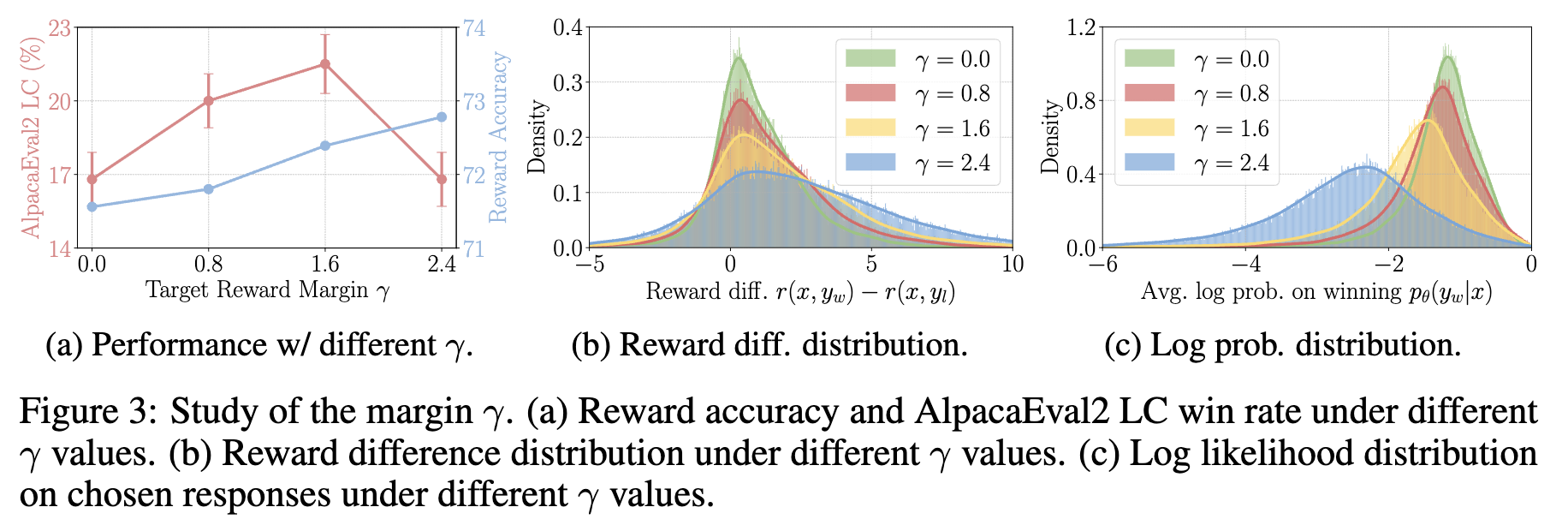
- $\gamma$에 따른 효과 (a)
- winning accuracy: win response가 lose response보다 높게 나오는 경우의 accruacy
- 항상 $\gamma$가 높다고 좋은건 아님
- $\gamma$에 따른 Reward 분포 (b, c)
- $\gamma$가 클수록 flatten됨. 학습 초반에는 성능 향상되나, 결국엔 너무 크면 degradation 발생
4.5 SimPO vs. DPO In-Depth Analysis
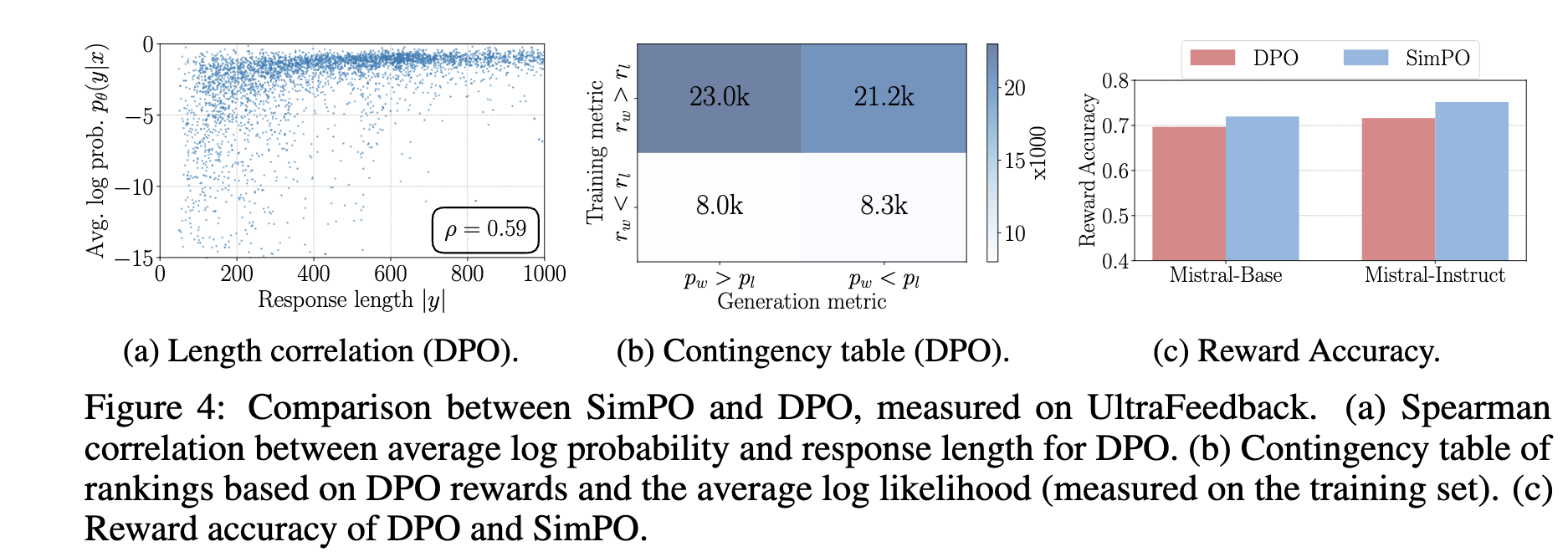
-
DPO가 Length bias를 내재적으로 줄이는 효과가 있음. 이는 Reference Model간의 log probability 계산 방식때문임 (0.59 vs. 0.82) (a)
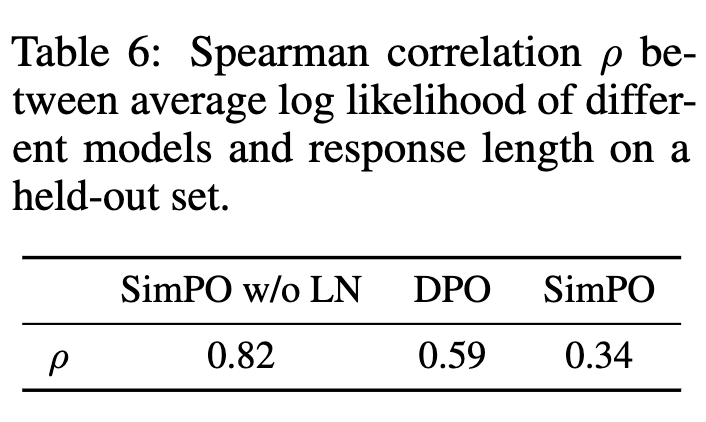
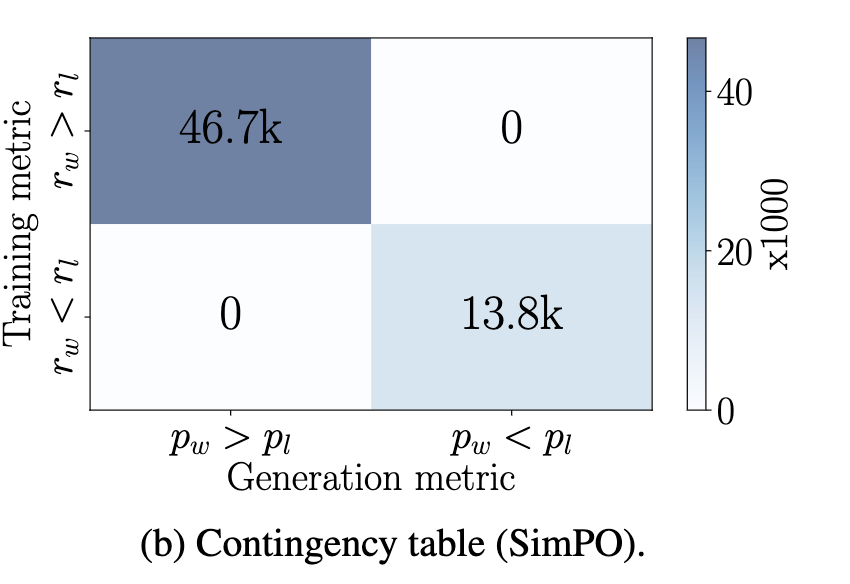
-
DPO는 generation likelygood와 mismatch함 (50%이상) (b). 반면 SimPO는 100% align됨
-
DPO는 SimPO보다 열등한 성능을 달성함 (c)
-
-
SimPO & DPO의 $\beta$에 따른 KL Divergence
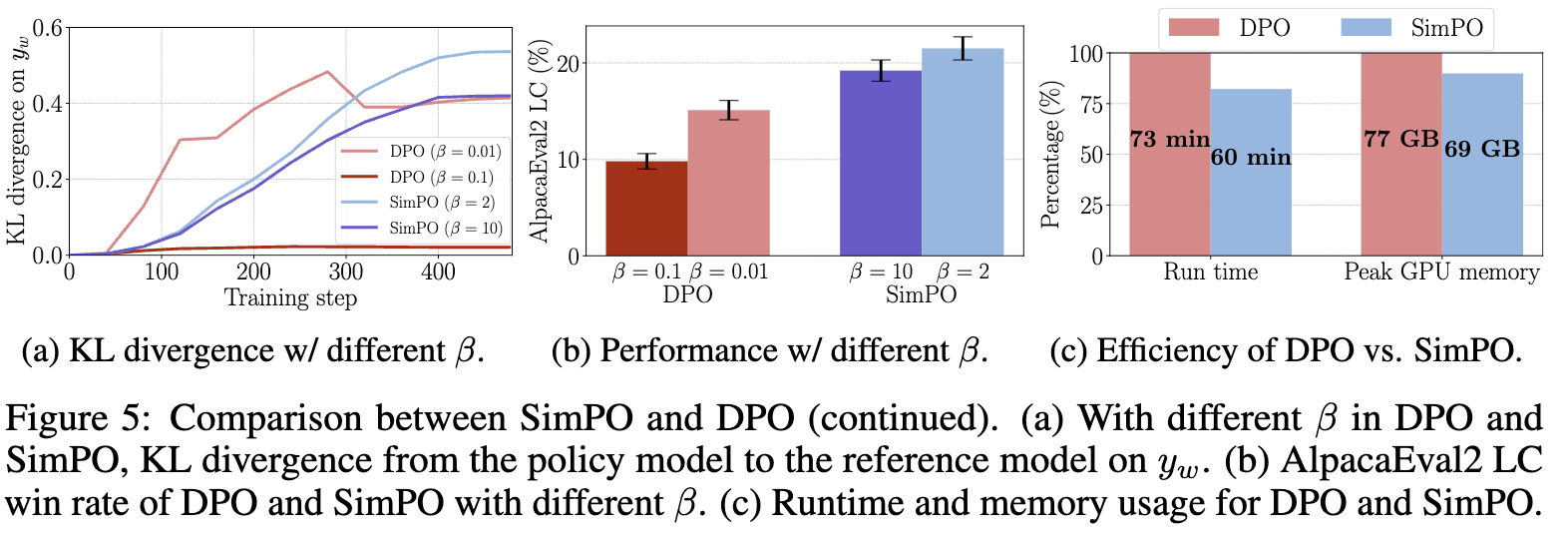
- DPO: $\beta$가 커질수록 explicitly KLD를 Loss로 반영한 DPO의 KLD는 확연히 줄어듦 (a)
- SimPO: $\beta$가 커질수록, reward가 많이 반영됨에 따라 implicity하게 KLD가 줄어듦. $\beta가 커짐에 따라 성능 하락하는 이유로는 Reference Model간 격차가 줄어드는 방향으로 reward hacking 가능성 있어보임 (b)
- SimPO가 memory 효율성이 뛰어남 (c)
-
한계점
-
Math에서는 SimPO가 DPO보다 성능이 떨어짐
- Template기반 negative 생성 (2+2=4: positive, 2+2=5: negative) 방식이 simPO에서는 비효율적일수 있음
-
6. Q&A
- decoding 방식이 beam search야? 다른 방식과 비교실험한게 있어?
SimPO 논문에서 디코딩 방식에 대해 질문 주신 내용에 대해 자세히 살펴보겠습니다.
SimPO 논문의 디코딩 방식
논문 5페이지 “Decoding hyperparameters” 섹션에 따르면, SimPO 모델의 생성에 사용된 디코딩 방식은 벤치마크마다 다릅니다.
- AlpacaEval 2:
sampling decoding strategy(샘플링 디코딩 전략)을 사용합니다.- 온도(temperature)는 모델 설정(Mistral-Base: 0.7, Mistral-Instruct: 0.5, Llama 3 모델: 0.9)에 따라 다르게 적용됩니다.
- 샘플링 디코딩은 확률 분포에 따라 토큰을 무작위로 선택하는 방식입니다. 온도가 높을수록 더 무작위적이고 다양한 응답을 생성하며, 온도가 낮을수록 더 결정론적이고 확률이 높은 토큰을 선택하는 경향이 있습니다.
- Arena-Hard:
- 모든 설정과 모델에 대해
default greedy decoding(기본 그리디 디코딩)을 사용합니다. - 그리디 디코딩은 각 단계에서 가장 높은 확률을 가진 토큰을 선택하여 시퀀스를 생성하는 방식입니다. 이는 가장 직접적이고 결정론적인 디코딩 방식입니다.
- 모든 설정과 모델에 대해
- MT-Bench:
- 벤치마크의
official decoding configuration을 따릅니다. - MT-Bench는 카테고리별로 다른 샘플링 온도를 정의하고 있습니다.
- 벤치마크의
Beam Search 사용 여부 및 다른 방식과의 비교 실험
-
Beam Search 사용 여부: 논문 본문에서 SimPO 모델을 평가할 때 명시적으로 Beam Search를 사용했다고 언급된 부분은 없습니다. 위에서 언급했듯이 AlpacaEval 2와 MT-Bench는 샘플링 디코딩을, Arena-Hard는 그리디 디코딩을 사용했습니다. 하지만 논문 3페이지, SimPO의 ‘길이-정규화된 보상(length-normalized reward)’ 개념을 설명하는 부분에서 다음과 같은 문장이 있습니다: “This metric is commonly used for ranking options in beam search [35, 53] and multiple-choice tasks within language models [12, 41, 62].” 이 문장은 “평균 로그 확률”이라는 메트릭 자체가 빔 서치에서 옵션을 랭킹할 때 일반적으로 사용된다는 것을 설명하는 것이며, SimPO 모델을 훈련하고 평가하는 과정에서 빔 서치를 직접 사용했다는 의미는 아닙니다.
-
다른 디코딩 방식과의 비교 실험: SimPO 논문 자체에서는 그리디 디코딩, 샘플링 디코딩 외에 Beam Search 등 다른 디코딩 방식과의 직접적인 비교 실험을 수행하지 않았습니다. 논문의 주요 초점은 DPO와 같은 기존 선호도 최적화 알고리즘과의 비교를 통해 “학습 목표 함수(objective function)”의 효과와 효율성을 입증하는 데 있습니다.
왜 비교 실험을 하지 않았을까?
- 초점의 한계: 한 논문에서 모든 가능한 변수를 실험하기는 어렵습니다. SimPO의 주된 기여는 새로운 보상 함수와 목표 마진을 제안하여 훈련 과정을 개선하는 것이었으므로, 디코딩 전략 비교는 주된 연구 범위가 아니었을 것입니다.
- 벤치마크 표준: AlpacaEval 2, Arena-Hard, MT-Bench와 같은 인기 있는 벤치마크는 종종 특정 디코딩 설정(예: 샘플링 온도)을 표준으로 제안합니다. 이는 서로 다른 모델 간의 비교를 공정하게 하기 위함이며, 연구팀은 이러한 표준을 따랐을 가능성이 높습니다.
- 그리디/샘플링의 일반성: 그리디 디코딩과 샘플링 디코딩은 LLM 생성에서 가장 기본적인 디코딩 방식이며, 다양한 모델과 시나리오에서 널리 사용됩니다.
추가 연구 방향 제안
그럼에도 불구하고, 디코딩 전략이 SimPO와 같은 선호도 최적화 모델의 최종 성능에 미치는 영향은 매우 흥미로운 연구 주제가 될 수 있습니다. 예를 들어:
- Beam Search와의 상호작용: SimPO가 “평균 로그 확률”을 보상으로 사용하기 때문에, 이 메트릭을 기본으로 하는 Beam Search와 특히 시너지가 있을 수 있습니다. SimPO로 훈련된 모델이 Beam Search를 사용했을 때, 다른 PO 모델보다 더 큰 성능 향상을 보이는지 실험해볼 수 있습니다.
- 다양한 디코딩 파라미터 튜닝: 온도, top-k, top-p, 빔 폭(beam width) 등 다양한 디코딩 파라미터가 SimPO 모델의 성능에 어떻게 영향을 미치는지 체계적으로 탐구할 수 있습니다.
- 길이 제어 디코딩: SimPO가 길이 편향을 억제한다고 하지만, 여전히 특정 길이 제어 디코딩(예: length penalty in beam search, min/max length constraints)과 결합했을 때의 효과를 비교할 수 있습니다.
이러한 실험들은 SimPO가 실제 배포 환경에서 어떻게 최적으로 활용될 수 있는지에 대한 중요한 통찰을 제공할 것입니다.
- generation guide를 SimPO가 따른다고 헀을때, 이는 greedy decoding, sampling decoding에는 안맞지 않아?
이 질문 또한 매우 핵심적이고 날카로운 통찰을 담고 있습니다! “생성 메트릭과 보상이 일치한다”는 SimPO의 강점이 과연 모든 디코딩 방식에 동일하게 적용되는지에 대한 의문은 타당합니다.
결론부터 말씀드리자면, SimPO의 ‘평균 로그 확률’ 기반 보상 설계는 Greedy decoding과 Sampling decoding에도 여전히 유효하지만, Beam Search에서 가장 직관적인 형태의 일치를 보여줍니다.
좀 더 자세히 설명해 드릴게요.
SimPO의 “생성 가이드 메트릭”과 각 디코딩 방식
SimPO가 따르는 ‘생성 가이드 메트릭’은 본질적으로 “높은 확률을 가진 시퀀스를 생성하라”는 것입니다. SimPO의 보상 함수는 특정 시퀀스 $y$에 대해 다음과 같이 정의됩니다:
\[r_{\text{SimPO}}(x, y) = \beta \frac{1}{|y|} \sum_{i=1}^{|y|}\log \pi_\theta(y_i | x, y_{<i})\]이것은 시퀀스 $y$의 토큰당 평균 로그 확률에 비례합니다. 즉, SimPO는 $\pi_\theta$가 선호되는 시퀀스에 대해 이 평균 로그 확률을 높이도록 학습하는 것입니다.
이제 각 디코딩 방식에 적용해 봅시다.
- Greedy Decoding (그리디 디코딩):
- 원리: 각 스텝에서
가장 높은 확률을 가진 단일 토큰을 선택합니다. - SimPO와의 일치성: 그리디 디코딩은 전역적인 시퀀스 확률을 최적화하지는 않지만, 지역적으로(locally) 가장 높은 확률을 추구합니다. SimPO가 학습을 통해 모델 $\pi_\theta$의 전체적인 확률 분포를 개선하여, 선호되는 응답에 높은 평균 로그 확률을 할당하도록 만들었다면, 그리디 디코딩 시에도 모델은 그러한 “좋은” 시퀀스를 생성할 가능성이 높아집니다.
- 즉, SimPO 훈련은 모델이 각 토큰을 선택할 때 더 ‘정확하고 유창한’ 토큰에 높은 확률을 할당하도록 유도하므로, 그리디 디코딩 시에도 전반적으로 높은 품질의 시퀀스가 나올 확률이 높아집니다. “좋은” 평균 로그 확률을 갖는 시퀀스는 각 토큰의 확률도 전반적으로 높을 것이기 때문입니다.
- 불일치보다는 간접적인 일치에 가깝습니다.
- 원리: 각 스텝에서
- Sampling Decoding (샘플링 디코딩):
- 원리: 각 스텝에서
확률 분포에 따라 토큰을 무작위로 샘플링합니다 (temperature, top-k, top-p 등의 파라미터로 제어). - SimPO와의 일치성: 샘플링 디코딩은 그리디 디코딩보다 다양성을 추구하지만, 여전히 모델의 확률 분포를 기반으로 합니다. SimPO가 선호되는 응답의 평균 로그 확률을 높이도록 학습시켰다면, 샘플링 디코딩 시에도 모델이 생성하는 시퀀스들은 전반적으로 더 높은 확률 값을 가질 가능성이 커집니다.
- 이는 샘플링 풀에 “좋은” 토큰이 더 높은 확률로 포함되어, 이를 통해 더 나은 품질의 시퀀스가 샘플링될 기회가 증가하기 때문입니다.
- 그리디와 마찬가지로 간접적인 일치이며, 모델의 내부 확률 분포가 개선되었기 때문에 다양한 샘플링된 결과물들의 품질이 향상되는 효과를 기대할 수 있습니다.
- 원리: 각 스텝에서
- Beam Search (빔 서치):
- 원리: 여러 후보 시퀀스를 유지하면서, 각 단계에서 이들의
총 로그 확률 (또는 길이에 정규화된 평균 로그 확률)을 기반으로 다음 스텝의 후보들을 평가하고 가장 높은 시퀀스들을 선택하여 탐색합니다. - SimPO와의 일치성: 빔 서치는 SimPO의 보상 메트릭인
평균 로그 확률을 가장 직접적으로 최적화하는 디코딩 방식 중 하나입니다. 빔 서치의 목적 자체가 시퀀스의 전역적인 확률(즉, 총 로그 확률 또는 평균 로그 확률)을 최대화하는 것이기 때문입니다. - 따라서 SimPO의 훈련 목표(선호 시퀀스의 평균 로그 확률 최대화)와 빔 서치의 작동 방식은 가장 강하고 직접적인 일치를 이룹니다. 논문에서 빔 서치를 언급하며 SimPO의 보상 메트릭이 빔 서치에서 사용된다고 한 것은 바로 이러한 이유 때문입니다.
- 원리: 여러 후보 시퀀스를 유지하면서, 각 단계에서 이들의
결론: 불일치하는 것이 아니라, 일치하는 정도의 차이
Greedy decoding과 Sampling decoding이 Beam Search처럼 “시퀀스 전체의 평균 로그 확률을 직접적으로 최적화하는” 방식은 아닙니다. 그러나 SimPO의 훈련은 모델의 기본적인 확률 할당 능력을 개선하여 선호되는 시퀀스에 더 높은 토큰별 확률 및 전반적인 평균 로그 확률을 할당하도록 유도합니다.
따라서:
- Beam Search: SimPO의 훈련 목표와 디코딩 목표가 가장 직접적으로 일치하여 최적의 시너지를 기대할 수 있습니다.
- Greedy/Sampling Decoding: SimPO 훈련으로 인해 모델의 내부적인 확률 분포가 개선되므로, 이들을 사용하더라도 더 높은 품질의 시퀀스를 생성할 가능성이 높아집니다. 보상 함수가 “모델 생성 메트릭과 잘 일치한다”는 주장은 이러한 확률 분포 개선의 효과를 포괄적으로 설명하는 것입니다. 불일치하는 것이 아니라, 빔 서치만큼 ‘완벽하게 직접적’이지는 않지만, 여전히 유효한 시너지를 낸다고 볼 수 있습니다.
이러한 이해는 SimPO가 왜 그리디 및 샘플링 디코딩 벤치마크에서도 좋은 성능을 보이는지 설명해 줍니다. 모델이 ‘좋은’ 시퀀스에 높은 확률을 할당하도록 학습되었다면, 어떤 디코딩 방식이든 그 확률을 활용하여 더 나은 결과를 낼 가능성이 커지기 때문입니다.
- 왜 불일치라 표현햇냐면, Sampling decoding & greedy decoding은 말한것처럼 지엽적인 token당 probability만 보기 때문에, 결국에는 문제의 동기인 긴 문장에 대해 부풀리는 문제가 발생하도록 추론하는 건데, 이는 학습-추론 misalign이 아닌가 싶어서 물었던 거야
$\to$ 아, 정말 핵심을 꿰뚫는 질문입니다! “지엽적인 토큰당 확률만 보는 디코딩 방식이 결국 길이 편향 문제를 재발시키지 않는가?”라는 의문은 매우 합리적이고 중요합니다. 다시 논문이 DPO에서 지적한 ‘mismatch’의 본질과 SimPO가 이를 해결하는 방식을 더 깊이 있게 파고들 필요가 있겠네요.
말씀하신 대로, DPO에서 ‘mismatch’가 발생하는 근본적인 원인은 다음과 같습니다:
-
DPO의 훈련 목표: $r_{\text{DPO}}(x, y_w) - r_{\text{DPO}}(x, y_l)$를 크게 만드는 것입니다. 여기서 $r_{\text{DPO}}$는 $\beta \log \frac{\pi_\theta(y x)}{\pi_{\text{ref}}(y x)}$ 입니다. -
LLM의 생성 메트릭: 추론 시 모델이 실제로 “좋은” 시퀀스를 선택하는 기준은 (특히 빔 서치에서) 시퀀스 전체의 평균 로그 확률($\frac{1}{ y } \sum \log \pi_\theta(y_i x, y_{<i})$)입니다. (그리디/샘플링은 이를 직접 최적화하지는 않지만, 목표는 여전히 ‘높은 확률’ 기반의 유창한 시퀀스 생성입니다.)
DPO의 Mismatch와 길이 편향의 연결고리
논문이 DPO에서 ‘mismatch’를 지적한 핵심은 ‘보상 순위’와 ‘평균 로그 확률 순위’가 일치하지 않는다는 것입니다 (Figure 4b).
-
DPO 보상 문제 (Summed log-prob과의 관계): 만약 선호 쌍 $(x, y_w, y_l)$에서 $y_w$가 $y_l$보다 훨씬 길다고 가정합시다. DPO는 $r_{\text{DPO}}(x, y_w) > r_{\text{DPO}}(x, y_l)$이 되도록 학습합니다. 이때, $\log \pi_\theta(y | x)$ (총 로그 확률) 항은 길이가 길수록 더 음수(절대값 증가)가 됩니다.
-
DPO는 이 총 로그 확률 차이 $\left( \sum \log \pi_\theta(y_w x) - \sum \log \pi_{\text{ref}}(y_w x) \right) - \left( \sum \log \pi_\theta(y_l x) - \sum \log \pi_{\text{ref}}(y_l x) \right)$를 최적화합니다. -
만약 $y_w$가 길어 $\sum \log \pi_\theta(y_w x)$가 매우 작은 음수라면, DPO는 이 값을 충분히 ‘덜 음수’로 만들기 위해 $y_w$의 토큰별 확률을 ‘과도하게’ 높이도록 학습될 수 있습니다. (논문의 “artificially inflate probabilities for longer sequences”가 바로 이것입니다.) - 이 ‘과도한 부풀리기’는 모델이 실제로는 유창하지 않거나 반복적인 토큰에도 높은 확률을 할당하게 만들 수 있습니다.
-
-
추론 시 문제: 모델이 훈련 과정에서 위와 같이 ‘과도한 부풀리기’를 학습했다고 가정해 봅시다.
- 그리디/샘플링 디코딩: 추론 시 이 디코딩 방식들은 각 스텝에서
지역적으로 가장 높은 확률을 가진 토큰을 선택하거나 샘플링합니다. 만약 모델이 이전에 ‘과도한 부풀리기’를 통해 (길이가 긴) 특정 토큰 시퀀스에 높은 확률을 할당하도록 학습되었다면, 그리디/샘플링 디코딩은 이러한 ‘부풀려진’ 확률을 따라가면서 불필요하게 긴 시퀀스를 생성하거나, 실제로 품질은 떨어지는 (그러나 훈련 시 보상은 높았던) 응답을 생성할 수 있습니다. - 이것이 바로 DPO에서 ‘mismatch’가 ‘길이 편향’과 ‘퇴화’로 이어진다는 논문의 주장입니다. DPO는 보상 순위를 통해 길이 편향을 학습할 수 있고, 그 결과로 모델이 길고 저품질의 응답을 생성하게 되는 것입니다. 즉, DPO 훈련은 ‘총 로그 확률 순위’를 기반으로 하지만, 실제 생성 시에는 (빔 서치에서) ‘평균 로그 확률’이 중요한데, DPO 훈련이 ‘평균 로그 확률’을 실제적으로 개선하지 못할 수 있다는 것이죠.
- 그리디/샘플링 디코딩: 추론 시 이 디코딩 방식들은 각 스텝에서
SimPO가 이 문제를 해결하는 방식
SimPO는 이 문제를 근본적으로 해결합니다.
-
SimPO의 훈련 목표: $r_{\text{SimPO}}(x, y_w) - r_{\text{SimPO}}(x, y_l)$를 크게 만드는 것입니다. 여기서 $r_{\text{SimPO}}$는 $\beta \frac{1}{ y } \sum \log \pi_\theta(y_i x, y_{<i})$ 입니다. - 핵심: SimPO는 훈련 목표 자체에 길이 정규화된 평균 로그 확률을 사용합니다.
- 이는 모델이 학습 시 ‘토큰당 평균적인 품질’을 높이도록 유도합니다. 즉, $y_w$가 $y_l$보다 길든 짧든, 모델은 $y_w$의 ‘토큰당 평균 로그 확률’이 $y_l$보다 높도록 노력합니다.
- 이 훈련 방식은 모델이 특정 길이에 대해 확률을 인위적으로 부풀릴 필요가 없어집니다. 왜냐하면 보상 자체가 길이에 독립적으로 ‘평균 품질’을 평가하기 때문입니다.
- 추론 시 SimPO의 동작:
SimPO 훈련을 통해 $\pi_\theta$는 어떤 길이의 시퀀스든 진정으로 ‘좋은’ 시퀀스에 높은 평균 로그 확률을 할당하도록 학습됩니다.
- 그리디/샘플링 디코딩: 모델의 내부 확률 분포가 개선되었기 때문에, 각 스텝에서 선택되는 토큰들이 전반적으로 더 높은 확률을 가지게 됩니다. 이는 결과적으로 생성되는 시퀀스의 평균 로그 확률도 높아지고, 품질도 향상됩니다. ‘과도한 부풀리기’ 현상이 없어졌으므로, 이러한 디코딩 방식들도 더 이상 ‘길이 편향’ 문제를 유발하지 않습니다.
- Beam Search: 빔 서치는 SimPO의 훈련 목표와 완벽하게 일치하므로, SimPO가 훈련된 모델은 빔 서치에서 더 효율적으로 고품질의 시퀀스를 탐색하고 생성할 수 있습니다.
요약:
SimPO는 DPO의 ‘학습-추론 불일치’가 훈련 과정에서 모델이 보상을 높이기 위해 (데이터셋의 길이 편향에 따라) 시퀀스 확률을 ‘과도하게 부풀리는’ 현상으로 이어진다고 분석합니다. 이 ‘부풀리기’는 실제 생성 메트릭(유창성, 비반복성)과 충돌하여 긴 저품질 응답을 초래합니다.
SimPO는 훈련 목표 자체를 ‘평균 로그 확률’로 정의하여 이러한 ‘과도한 부풀리기’를 원천적으로 차단합니다. 그 결과, SimPO로 훈련된 모델은 어떤 디코딩 방식을 사용하더라도 진정한 ‘토큰당 품질’을 바탕으로 시퀀스를 생성하려 하기 때문에, ‘길이 편향’ 문제 없이 더 나은 품질의 응답을 제공할 수 있습니다.
따라서 그리디/샘플링 디코딩에서도 SimPO 모델이 더 좋은 성능을 보이는 것은, 디코딩 방식 자체를 바꾼 것이 아니라, 모델의 내부적인 확률 할당 로직이 SimPO 훈련을 통해 근본적으로 개선되었기 때문이라고 볼 수 있습니다.