Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
[Seg] Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
- paper: https://arxiv.org/pdf/2503.06520
- github: https://github.com/dvlab-research/Seg-Zero
- archived (인용수: 33회, ‘25-06-07 기준)
- downstream task: Reasoning Segmentation
1. Motivation
-
reasoning segmentation 분야는 일반적인 *segmentation과는 다르게 nauanced query를 기반으로 target object에 대한 pixel mask를 생성하기에, robot과 같은 real-world에 적용하기 적합함.
ex. “food” $\to$ indentify food that provided sustained energy
-
DeepSeek-R1과 같은 최신 연구에 의하면, pure RL기반 학습한 모델은 reasoning 능력이 향상됨
-
기존의 reasoning segmentation분야는 주로 sft (supervised finetuning)기법으로 학습했기에, out-of-distribution 분포에 대해 일반화 성능과 명시적 reasoning이 약헀음
- 주요 원인 2가지
- sft는 in-domain-distribution에서는 좋은 성능을 내지만, ood에서는 catastrophic forgetting으로 인해 성능이 저하됨
- explicit reasoning 없이 segmentation을 수행하므로, 복잡한 시나리오에 대한 성능이 나쁨
- 주요 원인 2가지
$\to$ explicit reasoning + reinforcement learining으로 성능을 향상시켜보자!
2. Contribution
-
새로운 모델 구조와 pure RL 기반 reasoning segmentation 모델 Seg-Zero를 제안함.

- 매우 뛰어난 reasoning 능력을 보임
- Reasoning model (LLM)과 segmentation model(SAM2)을 decoupling함
- Format / Accuracy reward를 세부적으로 설계함 (+GRPO)
-
Reasoning chain 유무에 따른 RL / sft 에 대한 성능 분석 결과를 제공
-
SOTA 달성함으로써 RL의 성능 입증
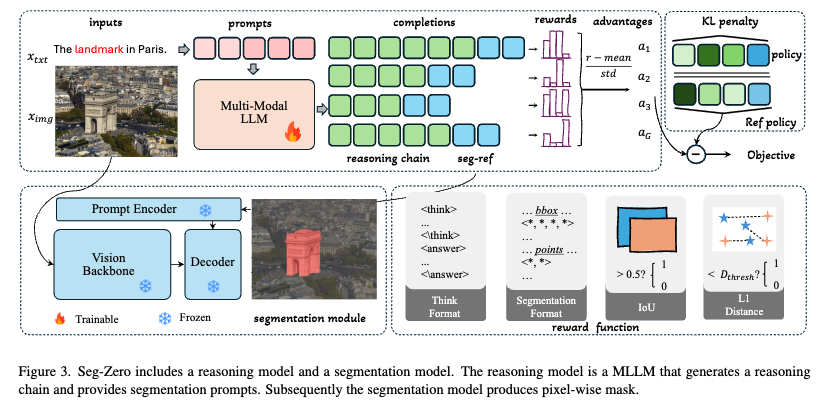
3. Seg-Zero
3.1 Pipeline Formulation

-
notation
-
Reasoning model
- input
- image $\bold{I}$
- label $\bold{T}$
- output
- bbox & 2 points
- input
-
Segmentation model
- input
- bbox & 2 points
- output
- binary segmentation mask $\bold{M}$
- input
-
3.2 Seg-Zero Model
-
architecture
-
Reasoning Model
-
Qwen2.5-VL을 사용
-
bbox 잘 예측하지만, segmentation mask를 생성하지 못하므로, bbox뿐만 아니라 point 2개를 추가로 예측을 수행
-
reinforcement learning 단계에서는 format reward를 통해 output이 구조화된 형태로 출력되도록 학습
-
구조화된 출력값은 후처리 함수 $G$를 통해 bbox와 2 point값을 추출
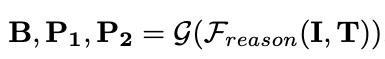
-
-
Segmentation Model
-
현존하는 최신 모델 SAM2를 사용
-
해당 모델은 다양한 형태의 prompt를 입력으로 활용 가능함. (bbox, points, etc)
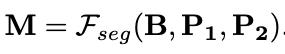
-
-
Test-time Reasoning
-
명시적인 Chain-of-Thought 을 통해 reasoning skill을 학습시키기 보다, User prompt를 통해 predefined format을 따르도록 훈련시킴

-
-
3.3 Reward Functions
5가지 Reward function을 설계함
- Thinking Format Reward
- model이
... 안에서 구조화된 thinking process를 따르도록 학습 - 정답은
... 안에서 출력하도록 학습
- model이
- Segmentation Format Reward
- soft & strict 두가지 유형의 reward를 설계함
- soft: bbox, points라는 keyword가 존재하면 reward 1를 부여 (must_include)
- strict: model 출력안에 bbox, points_1, points_2가 존재하면 reward 1를 부여 (must_include)
- Bbox IoU Reward
- 예측한 bbox와 정답 bbox간의 IoU가 0.5이상이면 reward 1를 부여
- Bbox L1 Reward
- 예측한 bbox와 정답 bbox간의 L1 distance가 10 pixel 이내이면 reward 1를 부여
- Point L1 Reward
- 예측한 points와 정답 points 간의 L1 distance가 100 pixel 이내이면 reward 1를 부여
- soft & strict 두가지 유형의 reward를 설계함
3.4 Training
-
Data Preparation
-
RefCOCOg를 기반으로 학습셋을 구성함
-
정답 Box는 segmentation mask를 기반으로 leftmost, topmost, rightmost, bottom-most 픽셀값을 기반으로 구현
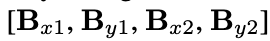
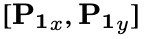

-
두 center points는 인접하는 가장큰 원의 중점을 활용
-
다른 데이터셋과의 일관성을 유지하기 위해 이미지 해상도는 840x840 pixels로 resize함
-
-
GRPO
- reasoning data를 cold-start시에 하나도 넣지 않음
- pretrianed Qwen2.5-VL-3B를 사용하여 GRPO로 학습함
- reasoning data를 cold-start시에 하나도 넣지 않음
4. Experiments
4.1 Experimental Settings
- Datasets
- Train
- RefCOCOg에서 9K samples 취득함
- Test
- RefCOCO(+/g)
- ReasonSeg
- Train
- Implementation Details
- Model
- Qwen2.5-VL-3B + Sam2-Large
- GPU
- 8xH200 GPU + DeepSpeed Library
- batch size
- 16
- sampling number
- 8: 8개의 병렬 process를 띄워 각각 2개씩
, 를 생성하여 총 16 batch를 구성한다는 의미로 해석됨.
- 8: 8개의 병렬 process를 띄워 각각 2개씩
- learning rate
- 1e-6
- 0.01 weight decay
- Model
- Evaluation Metrics
- gIoU
4.2 SFT vs. RL
-
결과
-
정량적 결과
-
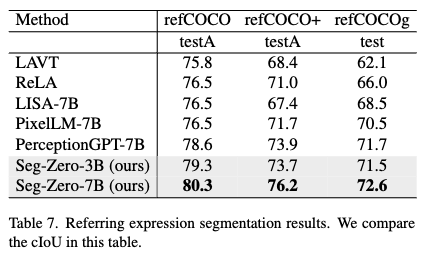
Referring Expression Segmentation
-
Reasoning Segmentation
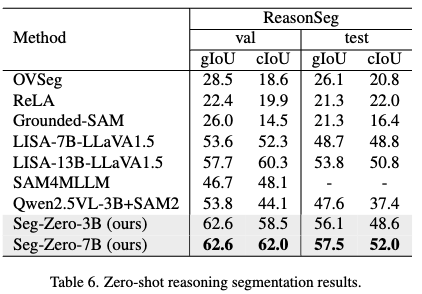
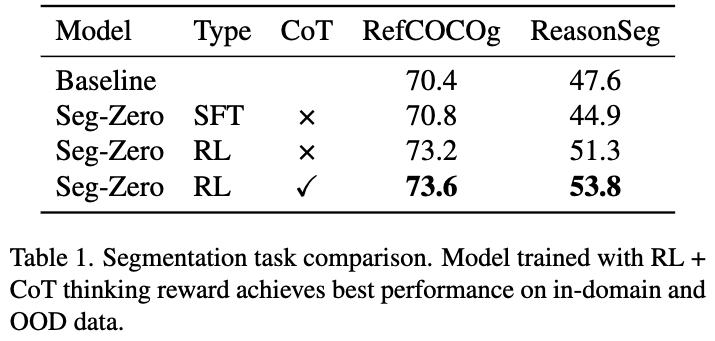
- In-domain (RefCOCOg)에서는 SFT가 Baseline과 거의 유사한 성능을 내지만, Out-of-domain (ReasonSeg)은 성능이 하락함 $\to$ Catastrophic forgetting (아래 그림에서도 볼수 있음)
- 반면 RL은 In-domain / Out-of-domain 모두에서 성능 향상을 보임
- RL은 In-domain / Out-of-domain 모두에서 CoT를 추가하면 성능 향상됨.

- VQA task에서 RL에 CoT를 추가하는 것은 미세한 성능 향상만 보임. 즉 task마다 CoT로 인한 성능 향상이 다름
-
-
정성적 결과


-
-
Ablation Study: default settings: RL with GRPO (9K samples)
-
Design of Bbox & Points에 따른 성능 분석
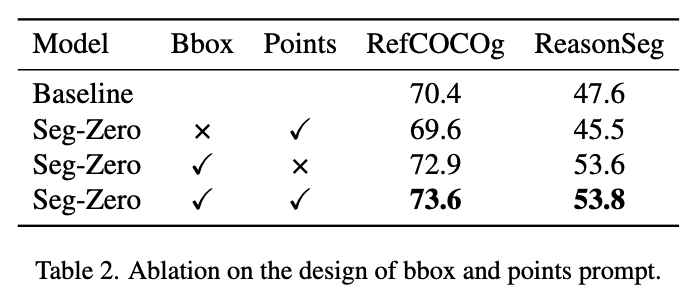
-
Soft vs. Hard Accuracy Rewards에 따른 성능 분석
-
soft reward는 reward를 soft하게 (0/1이 아닌) 메기는 방식
-
IoU Reward : IoU 값 그 자체
-
L1 Reward: $1 - \frac{L1_{dist}}{max{image_size}}$

-
-
-
Soft vs. Strict Format Reward에 따른 성능 분석

- strict가 성능 향상에 기여함
- strict가 초기에 학습 속도가 더디고, 장기적으로 갈수록 더 많은 token을 출력하는 경향이 생김
- strict가 성능 향상에 기여함
-
Model scale에 따른
- 성능 분석
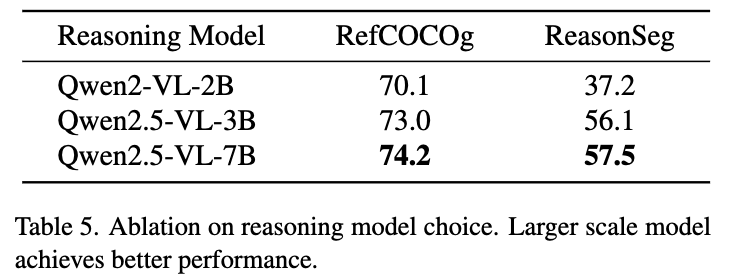
-
Completion Length의 분석
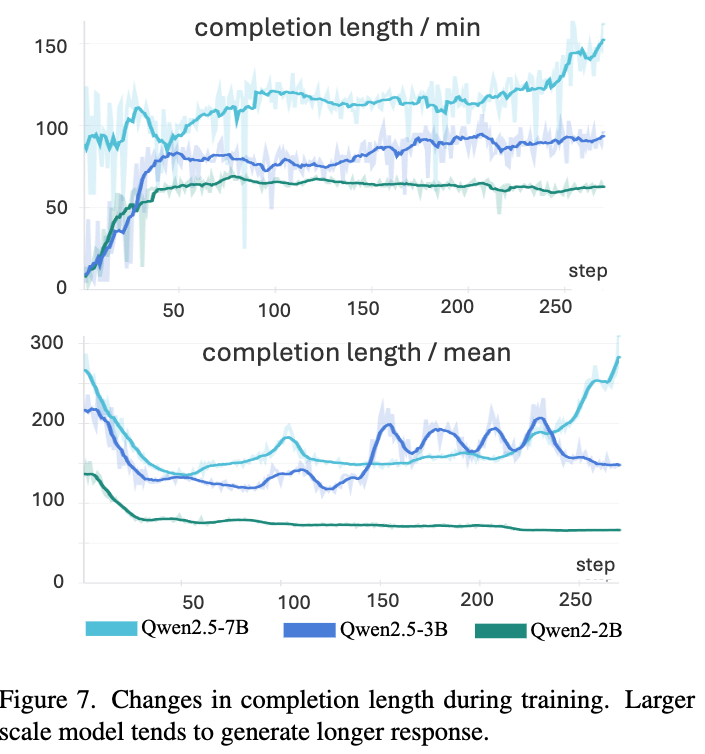
-
중간에 length가 줄어드는 것을 분석한 결과, 초기에는 format을 맞추기 위해서 짧은 값을 내뱉으나, 학습이 진행될수록 format으로 인한 reward 이상의 성능 향상을 위해 세부적인 response를 내뱉도록 reasoning을 늘리는 경향을 발견
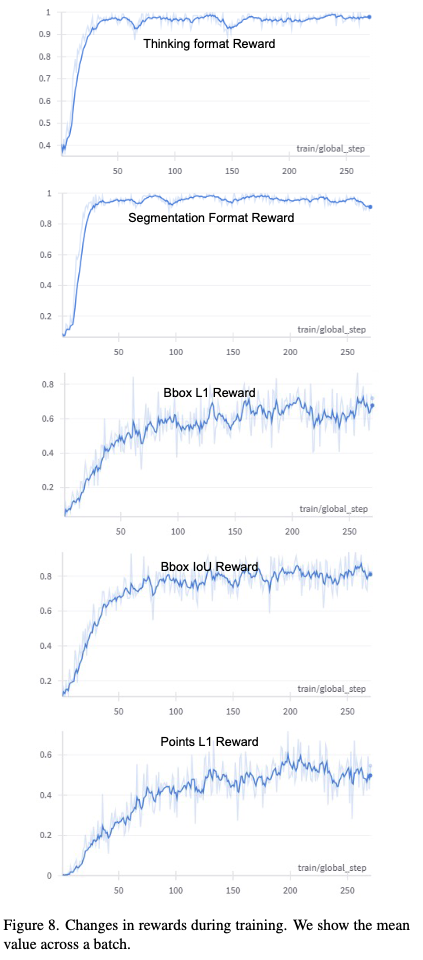
- format reward는 1로 빠르게 수렴하고, 그뒤에 accuracy rewards가 올라가는 경향을 볼 수 있음
-
-
5. Related Works
5.1 Reasoning in Large Models
- OpenAI-o1은 inference-time scaling을 통해 성능 향상됨을 보임
- DeepSeek-R1을 기점으로 GRPO기반 RL이 다양한 분야에서 reasoning 능력의 향상을 보임
- R1-V: counting 능력 향상
- Open-R1: mathematical reasoning 능력 향상
5.2 Semantic Segmentation with Reasoning
- Semantic segmentation분야에서 혁신적인 모델들이 등장했음
- DeepLab, MaskFormer, SAM
- Referring Expression Segmentation task는 이와는 다르게, 주어진 query에 해당하는 instance의 mask를 예측함으로써 더 복잡함
-
LISA
-