[DG][SS] Rein: Harnessing Vision Foundation Models
[DG][SS] Rein: Harnessing Vision Foundation Models for Domain Generalized Semantic Segmentation
- paper: https://arxiv.org/pdf/2312.04265v3.pdf
- github: https://github.com/w1oves/Rein
- ‘23.12 archived (인용수: 0회, ‘24-02-17 기준)
- downstream task: DG for SS
1. Motivation
-
DiNOv2, SAM, CLIP, EVA02 등 Vision Foundation Model (VFM)이 각종 downstream task에서 좋은 성과를 발휘함
-
하지만, Domain Generalized Semantic Segmentation (DGSS) downstream task에 대해서는 unexplored.
$\to$ 이 분야로 연구를 해보자!
2. Contribution
-
Stronger: VFM을 frozen시키고 decoder (SAM)을 붙이는 것만으로도 previous backbone들에 비해 우월한 성능 향상을 보임을 확인
- Fewer: learnable-parameter token을 가지고, 각 token이 object와 link되게끔 backbone feature을 refine함으로써 적은 학습 가능한 parameter만 가지고, pretrained knowledge을 보존하는 Rein이라는 학습 기법을 제아함
- Superior: DGSS downstream task에서 SOTA
3. Rein
-
Overall Digram
-
Core Concept
-
MLP layer ($L_1, .. , L_i$)의 weight는 건들지 않고, 출력되는 feature map을 refine하는 것
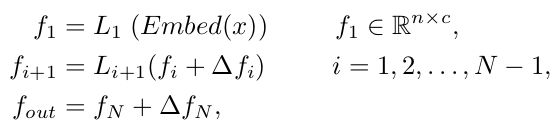
-
$\Delta f_N$: N번째 Rein에 의해 출력된 feature-map의 변화량
-
$\Delta f_i$: i번째 Rein에 의해 출력된 feature-map의 변화량
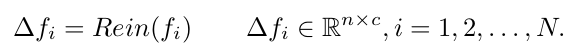
-
Embed: Image 를 image token으로 바꾸는 Tokenizer
-
n, c: patch의 갯수, token의 dimension
-
-
Adapting difference of dataset (ImageNet vs. Cityscapes) + difference of task (Classification vs. Semantic Segmentation)을 위해 Learnable Token을 사용
-
Token과 feature map간의 attention-map을 만듦
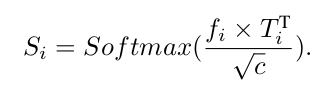
- $T_i, f_i, S_i$: i번째 layer의 token, feature map, similarity map
- c: token dimension
-
Refined feature : 해당 token이 attention 하고자 하는 부분이 없을 수 도 있으므로, 이를 고려하고자 1st column은 제외한 채로 refined feature를 생성
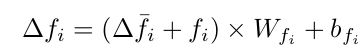
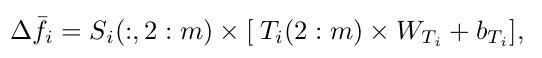
-
-
Mapping tokens to instances
-
DETR의 query에서 영감을 받아 learnable query를 token으로 생성하고자 함
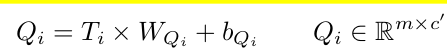
- $Q_i, T_i, W_{Q_i}, b_{Q_i}$: i번째 layer의 query, token, weight, and bias
-
매 layer마다 query를 만들면 계산량이 많아지므로, token들의 평균, max, 그리고 마지막 layer 값만 사용
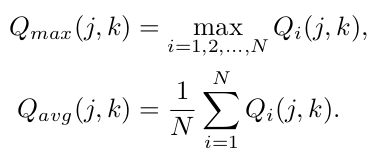
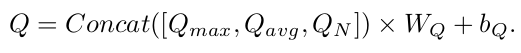
-
-
Shared weights for MLP
-
token to embedding space로 linear transform하는 MLP를 모든 layer마다 shared하여 학습할 parameter의 수를 줄임
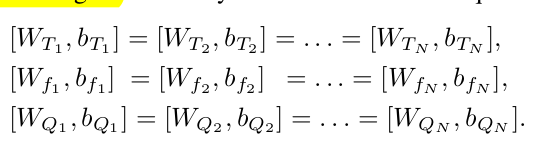
-
-
Low rank token sequence
-
redundunt한 정보를 학습하는 특성을 고려하여 Token의 dimension (c)에 비해 적은 rank r의 두 metric 곱으로 token을 설계함
-
ex. bicycle의 head-light vs. car의 head-light
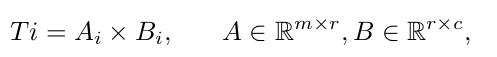

-
-
-
Overall Loss
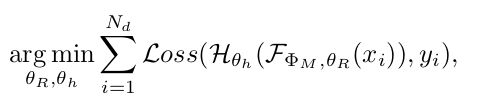
- $\Phi_M$: VFM의 frozen parameter
- $\theta_R$: Decoder head의 parameter
- $\theta_r$: Rein의 learnable tokens
- F: forward process of VFM using Rein
- $N_d$: Dataset의 전체 이미지 수
4. Experiments
-
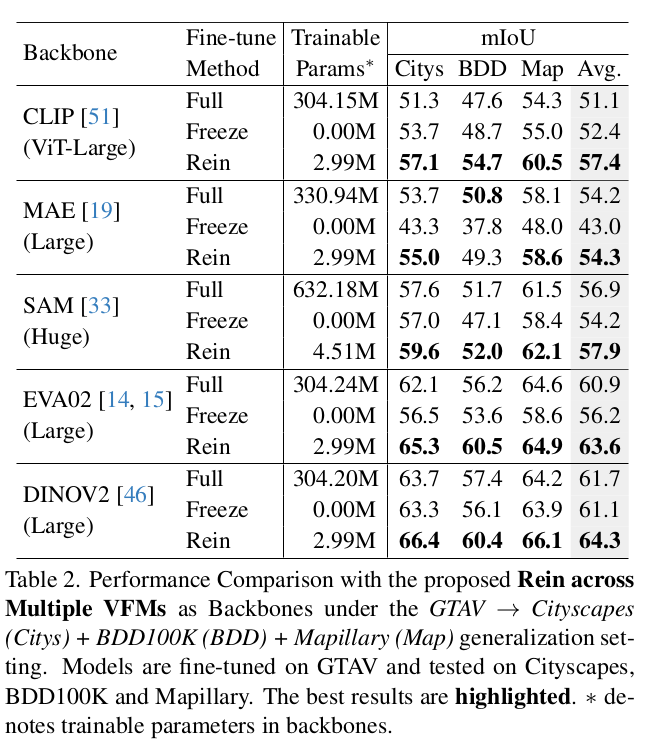
Multiple backbone별 Synthetic to Real 성능 비교
-
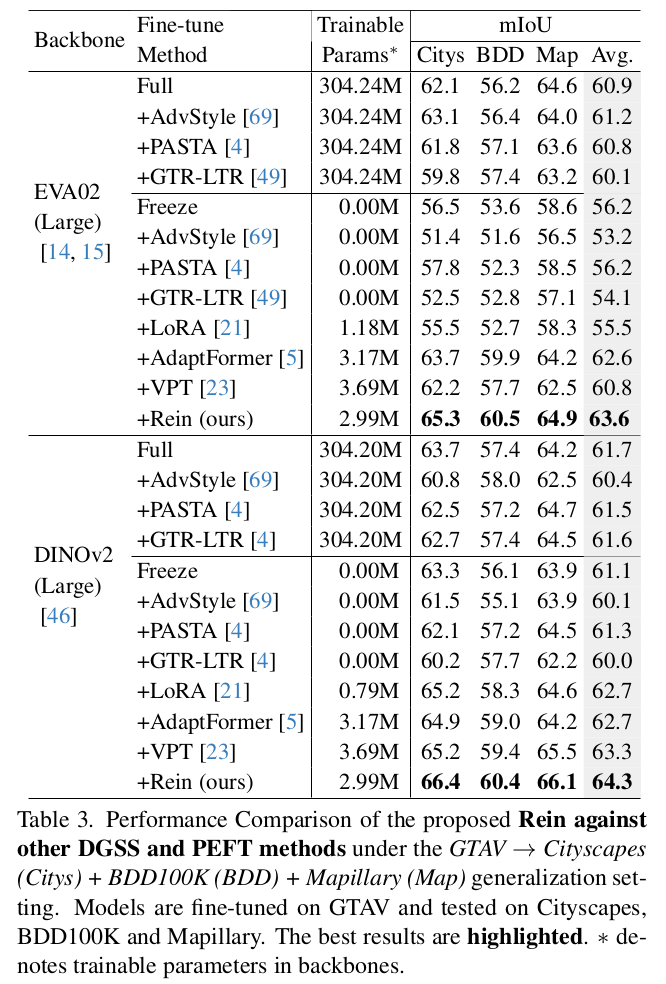
SOTA PEFT (Parameter-Efficient Fine Tuning) 와 Synthetic to Real 성능 비교
-
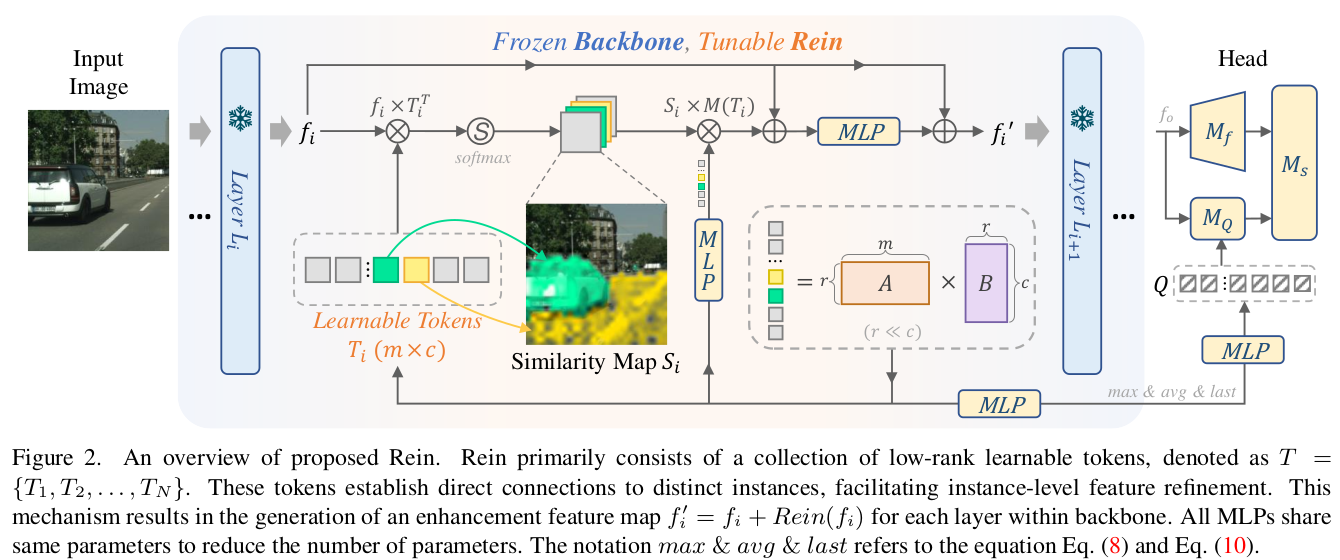
SOTA DGSS와 성능 비교
- Synthetic to Real
- Quantitative Result
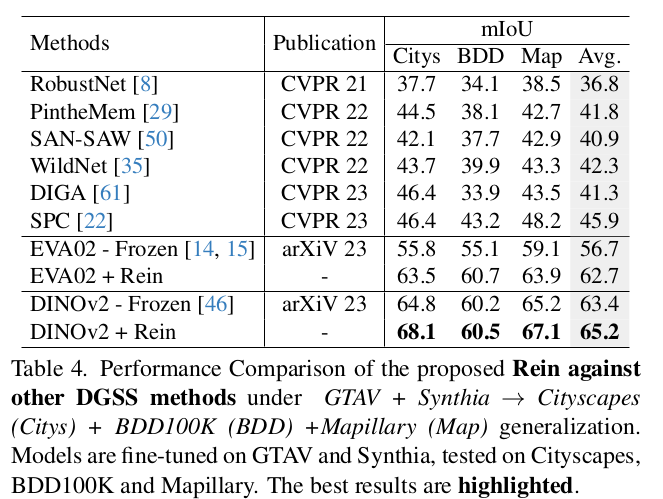
-
Qualtitative Result
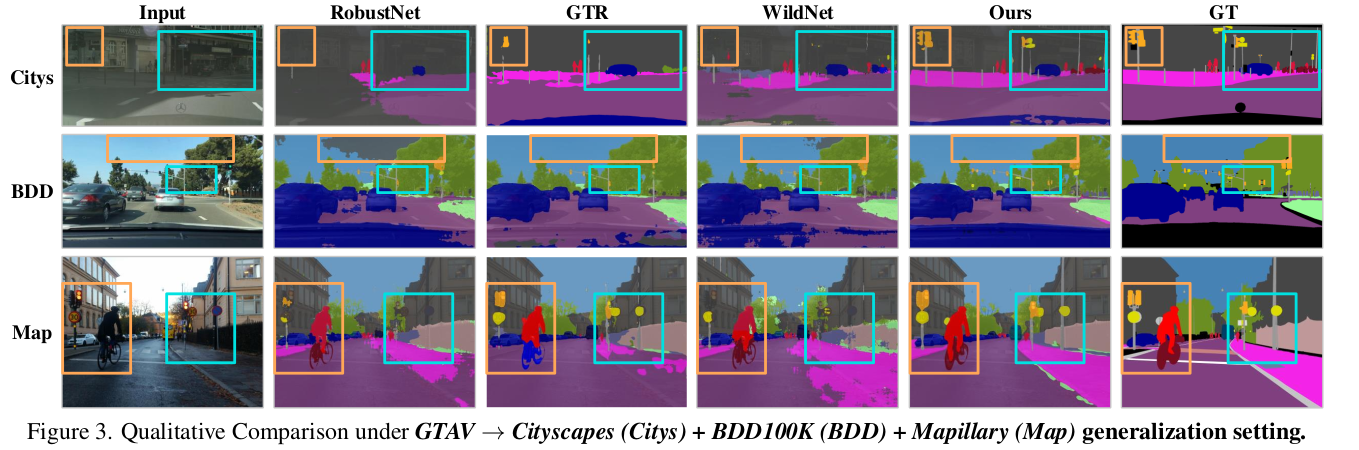
- Synthetic to Real
-
Cityscapes 2 BDD100k
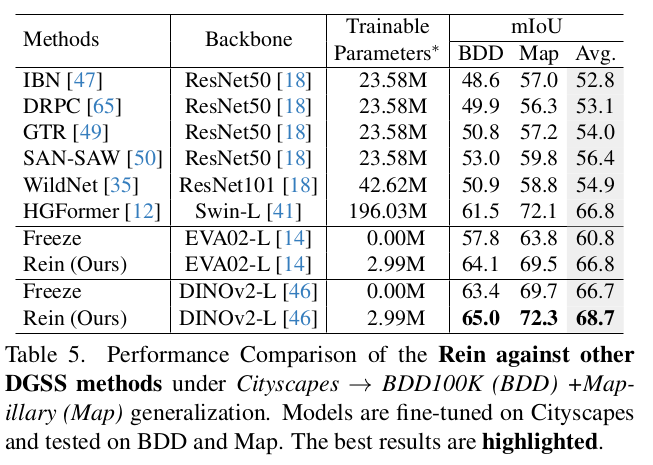
-
Ablation Studies
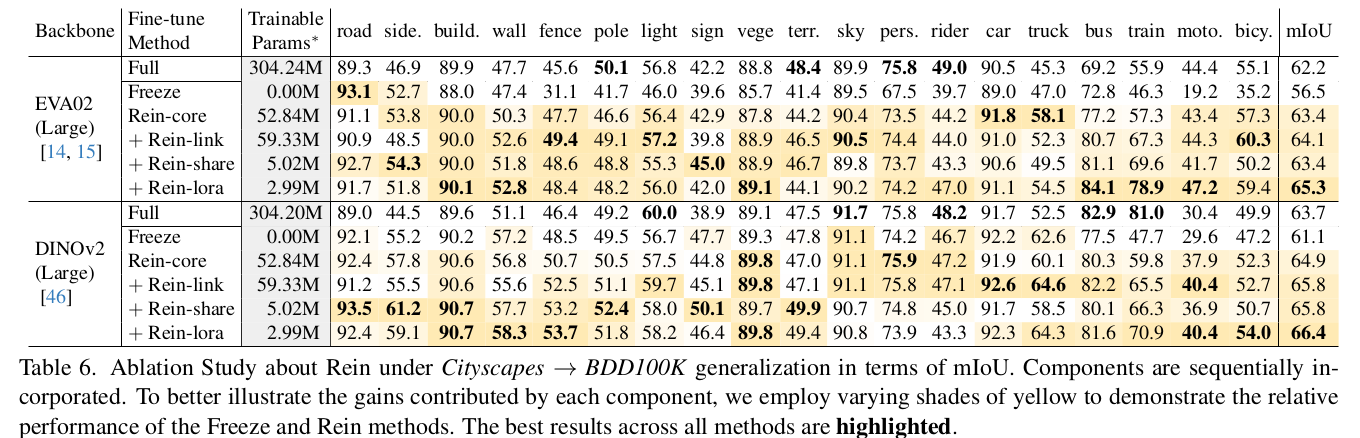
-
m length에 따른 ablation
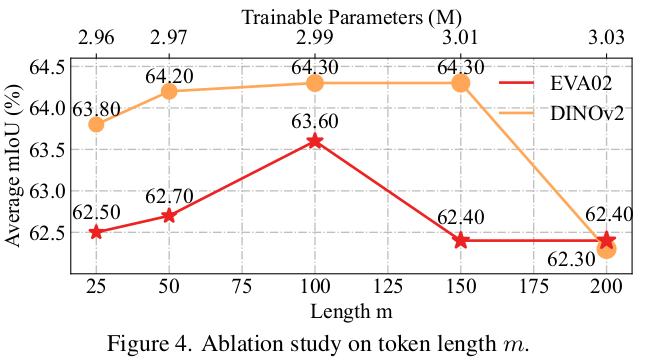
-
LoRA dimension r에 따른 ablation
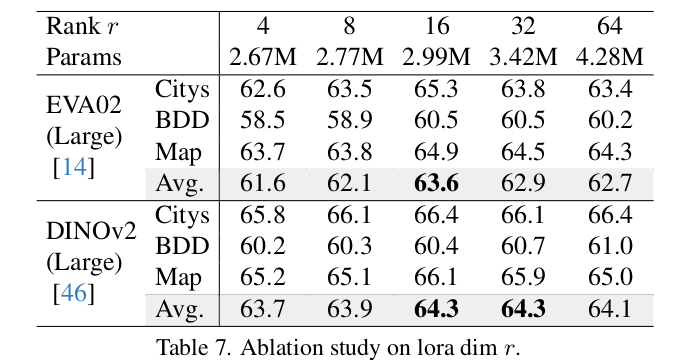
-
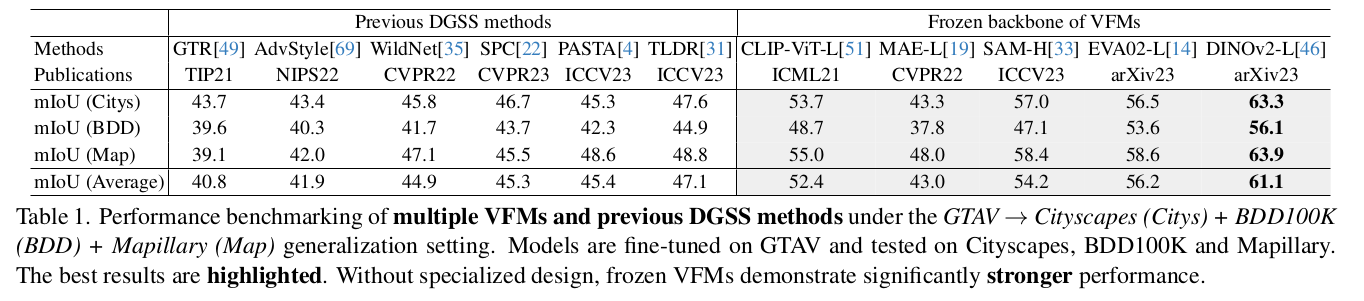
Training Time & GPU memory & Storage