RLRF: Rendering-Aware Reinforcement Learning for Vector Graphics Generation
[SVG-GEN] RLRF: Rendering-Aware Reinforcement Learning for Vector Graphics Generation
- paper: https://arxiv.org/pdf/2505.20793
- github: X
- archived (인용수: 0회, 25-05-31 기준)
- downstream task: SVG code generation
1. Motivation
-
최근 VLM의 성능 향상으로, perceptual input으로부터 structured visual code를 생성하는 연구가 많이 진행되고 있다.
- StarVector는 Clip-V와 LLM을 통해 SVG generation을 code synthesis 문제로 정의하여 푼다.
-
하지만, 해당 연구들의 결과는 OOD (out-of-distribution)에 취약하고, consistency issue에 봉착한다.
-
이는 VLM의 autoregressive한 특성으로부터 기인한다. 즉, token별 discrete sampling을 수행하기 때문에, SVG rendering process는 non-differentiable함으로 인해 rendering된 이미지에 대해 visual feedback을 받지 못한다.
$\to$ visual feedback을 학습중에 받을수 있는 새로운 방법을 제안해보자!
2. Contribution
-
Rendering SVG roll-out을 Reward signal로 삼는 새로운 RLRF (Reinforcement Learning with Rendering Feedback)을 제안함
- SVG Generation with RL을 inverse rendering code generation task로 재정의
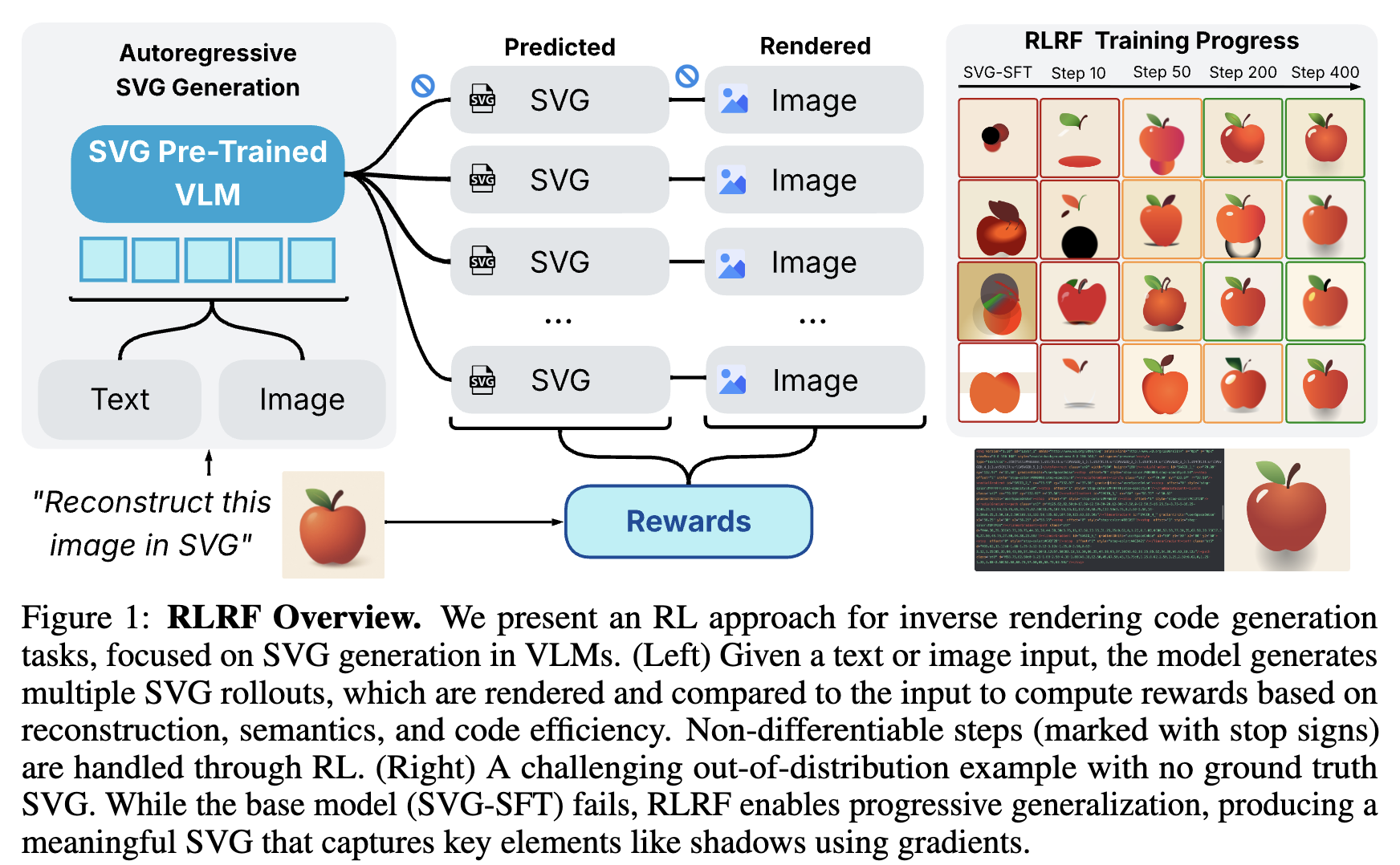
-
새로운 Set or Reward를 제안함
- Pixel-level similarity
- Semantic alignment
- code efficiency
-
SVG Generalization task에서 SOTA
3. Related Works
3.1 SVG Generation
크게 3가지 카테고리로 분류된다.
- 고전 기법
- 윤곽을 따서 이미지 내 영역을 clustering하여 효과적으로 shape을 추출, 해당 영역에 대한 code를 생성함. $\to$ 구조적이지 않고, 장환한 코드 생성 야기함
- Latent Variable Models
- 더 나은 interpolation 성능 및 transfer 성능을 보이지만, SVG subset의 제약으로 가독성이 떨어지는 code를 생성함
- LLM
- SVG generation을 renderable한 code generation task로 재정의함. 하지만 해당 연구는 rendering 과정이 non-differential하기 때문에 visual output의 validity를 반영하지 못함으로, 불충분하고 부정확한 SVG code 생성함.
3.2 Vision-Language Models (VLMs)
- Vision / Langauge 각각의 모듈의 엄청난 발전으로, 입력된 visual input로부터 SVG 뿐 아니라 TikZ, CAD code를 생성하는 inverse rendering 연구가 활발히 진행되고 있다.
- 하지만 hallunication 문제 등 일반화 성능이 떨어지는데 이는 rendering 결과에 대한 visual feedback이 없기 때문이다.
3.3 Reinforcement Learning Post-Training
- 대부분의 RL to code generation이 code의 execution correctness에 초점을 맞추고 있을 뿐, visual / structural feedback은 못하고 있다.
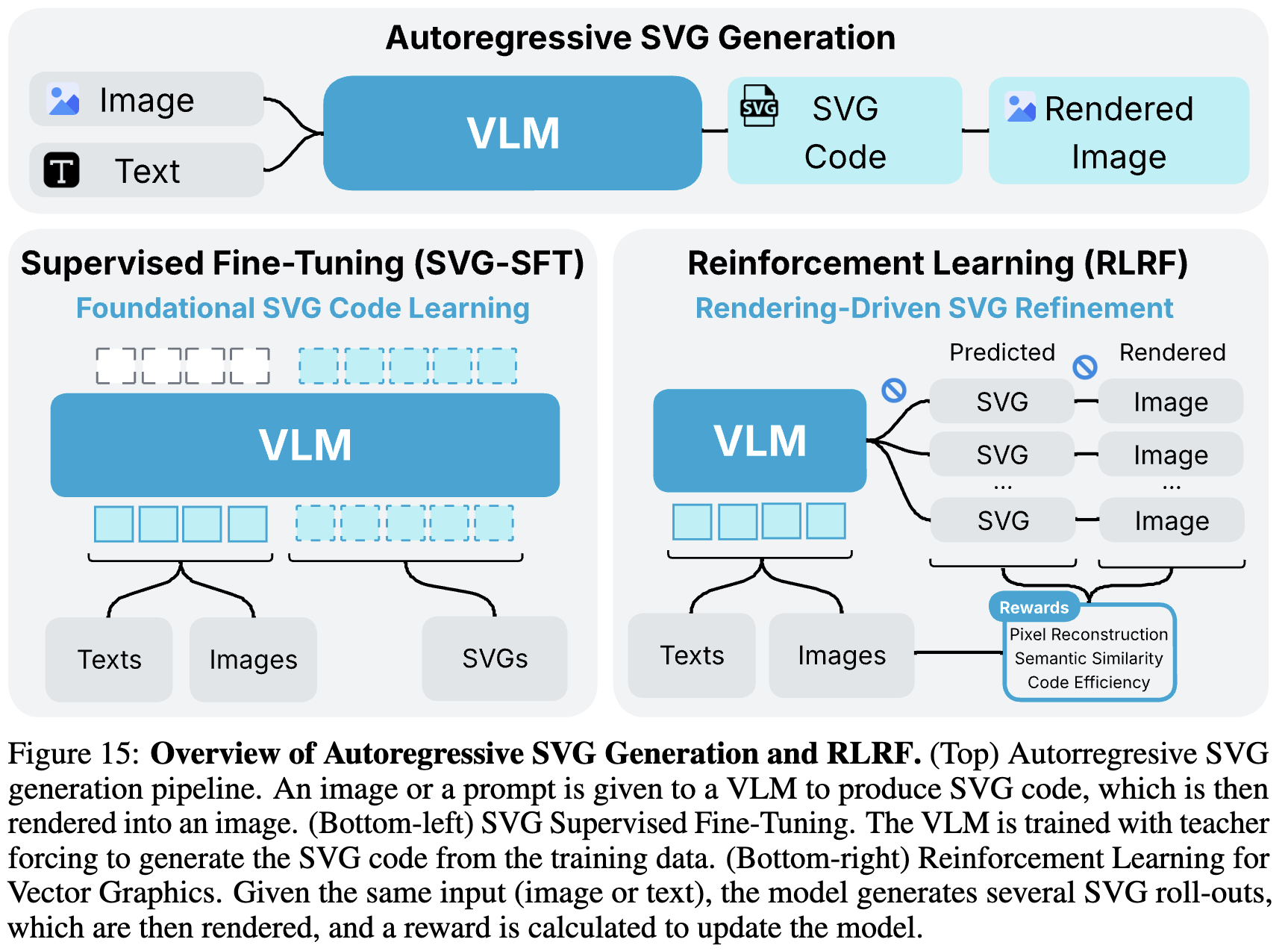
4. RLRF: Reinforcement Learning with Rendering Feedback
4.1 Two-stage Training
- SVG-SFT: Img2SVG code generation
- RLRF: code2Img
-
SVG-SFT
-
Loss
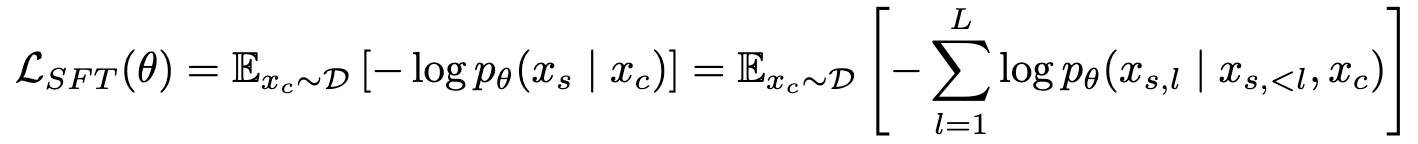
- $x_c$: conditial input. 여기서는 image 혹은 text가 될 수 있다.
- $x_s$: ground truth SVG tokens
-
-
RLRF
-
일반적인 RL Loss
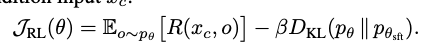
- R: Reward. GRPO (Grou Relative Policy Optimization)을 적용
-
o: $p_{\theta}( x_c)$ RL로 학습된 모델의 출력값 - $p_{\theta}$: RL로 학습된 모델
- $p_{\theta_{sft}}$: sft로 학습된 모델. 고정값.
-
GRPO Loss
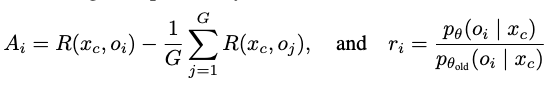
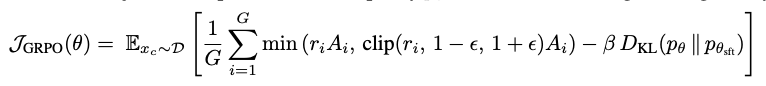
-
4.2 Rewards for Vector Graphics Rendering
- 장점: 완전 자동, 고퀄리티의 reward signal을 human annotation 없이 생성
- 평가항목
- image reconstruction accuracy
- semantic alignment
- code efficiency
- Rendering module: CairoSVG
4.2.1 Image Reconstruction Rewards
-
Pixel-level reconstruction Loss: -1~1로 정규화된 Pixel level image기반 L2 loss
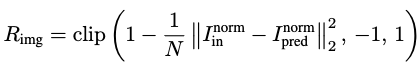
- $I_{in}^{norm}$: input Image. zero-mean, one-std로 정규화
- $I_{pred}^{norm}$: 생ㅇ성된 SVG code로부터 rendering된 Image. zero-mean, one-std로 정규화
-
L2 Canny Loss: -1~1로 정규화된 Canny Edge Detector + Dilation (3x3 kernel, 1 iteration) + Gaussian Blur (size 13)로 추출한 이미지기반 L2 loss
- 목적: 윤곽을 더 잘 추출하여 structural alignment를 잘 수행하기 위함
4.2.2 Semantic Alignment
-
Img2SVG
-
Dreamsim을 이용하여 이미지간의 유사도를 계산함
-
추가로, Shape-focused feedback을 위해 Canny Edge detector 통과후 DreamSim 유사도 계산함
$\to$ CLIP의 학습 데이터에 SVG image가 없기에, 해당 signal은 유의미하지 못함
-
-
Text2SVG
-
CLIP 모델의 textual embedding, Visual embedding간의 유사도를 계산함
-
VLM-as-a-judge를 활용함
$\to$ Qwen-2.5-VL-7B를 활용하여 aesthetic quality & visual resemblance & semantic accuracy를 고려하여 reward signal로 활용함


-
4.2.3 Code efficiency
-
Token Length Loss
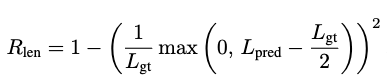
- $L_{gt}$: ground trugh SVG code token length
- $L_{pred}$: generated SVG code token length
-
Final Reward
위에 설명한 K(=3)개의 reward의 합
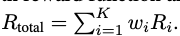
5. Experiments
5.1 Experimental Setup
-
Img2SVG
- Models
- Qwen-2.5-VL
- StartVector-1B
- Datasets
- SVG-Stack dataset (1.7M)
- 2.1M $\to$ 1,7M: image url / embedded base64 image가 너무 길 경우 제거하여 해당 데이터를 memorize하는걸 방지
- SVG-Stack-Hard Test set (0.6K)
- 3K $\to$ 0.6K: broken / white-background / low-color entropy / 500 token 이하 SVG 제거하여 evaluation 속도 향상
- SVG-Emoji
- SVG-Fonts
- SVG-Icons
- SVG-Stack dataset (1.7M)
- Models
-
Text2SVG
- Models
- Qwen3
- Datasets
- Flickr30k
- MM-Icons
- MM-Illustrations (Eval-only, OOD)
- Models
-
Img2SVG SVG-SFT
-
Qwen2.5-VL (3B/7B)
-
GPU
- 4 x 8 H100 GPUs (3B)
- 8 x 8 H100 GPUs (7B)
$\to$ 4d (3poch)
- lr: 1e-5
- max token: 32K
- batch size: 1024
-
-
-
Img2SVG RLRF
-
Models
- Qwen2.5-VL
- StarVector-1B
-
Datasets
- SVG-Stack에서 20K high-entropy samples만 추출 (+ 500 token 이상의 rich in visual detail)
- batch size: 32
- roll-out: 64 $\to$ 2048 batch size
-
GPU
-
Qwen2.5VL
-
4 x 8 H100 GPUs
$\to$ 3days (500 step)
-
-
Qwen3
-
1 x 8 H100 GPUs
$\to$ 1day
-
-
-
No KL Divergence term
-
-
Implementation detail
- code base
- SFT
- LLaMA-Factory : https://github.com/hiyouga/LLaMA-Factory
- RLRF
- EasyR1: https://github.com/xuyongfu/EasyR1-0530
- verl: https://github.com/volcengine/verl
- PipelineRL: https://huggingface.co/blog/ServiceNow/pipelinerl (Roll-out을 renderingtl iddle 현상을 완화해주는 framework)
- SFT
- Dynamic MaxLength
- Batch 내 GT code의 max값을 기준으로 Max Length를 step별로 지정함 $\to$ 초기 학습시에 긴 output 생성을 방지하고 학습속도 향상하는 효과
- code base
-
Evaluation Metrics
- IMG2SVG
- SSIM, MSE: Pixel-level Fidelity
- DINO Score, LPIPS: Perceptual Similarity
- Code Efficiency: GT와의 distance (token-level) +면 더욱 compact한 code라는 뜻
- Text2SVG
- VLM-as-a-judge
- IMG2SVG
5.2 Evaluation
-
IMG2SVG
-
정량적 결과
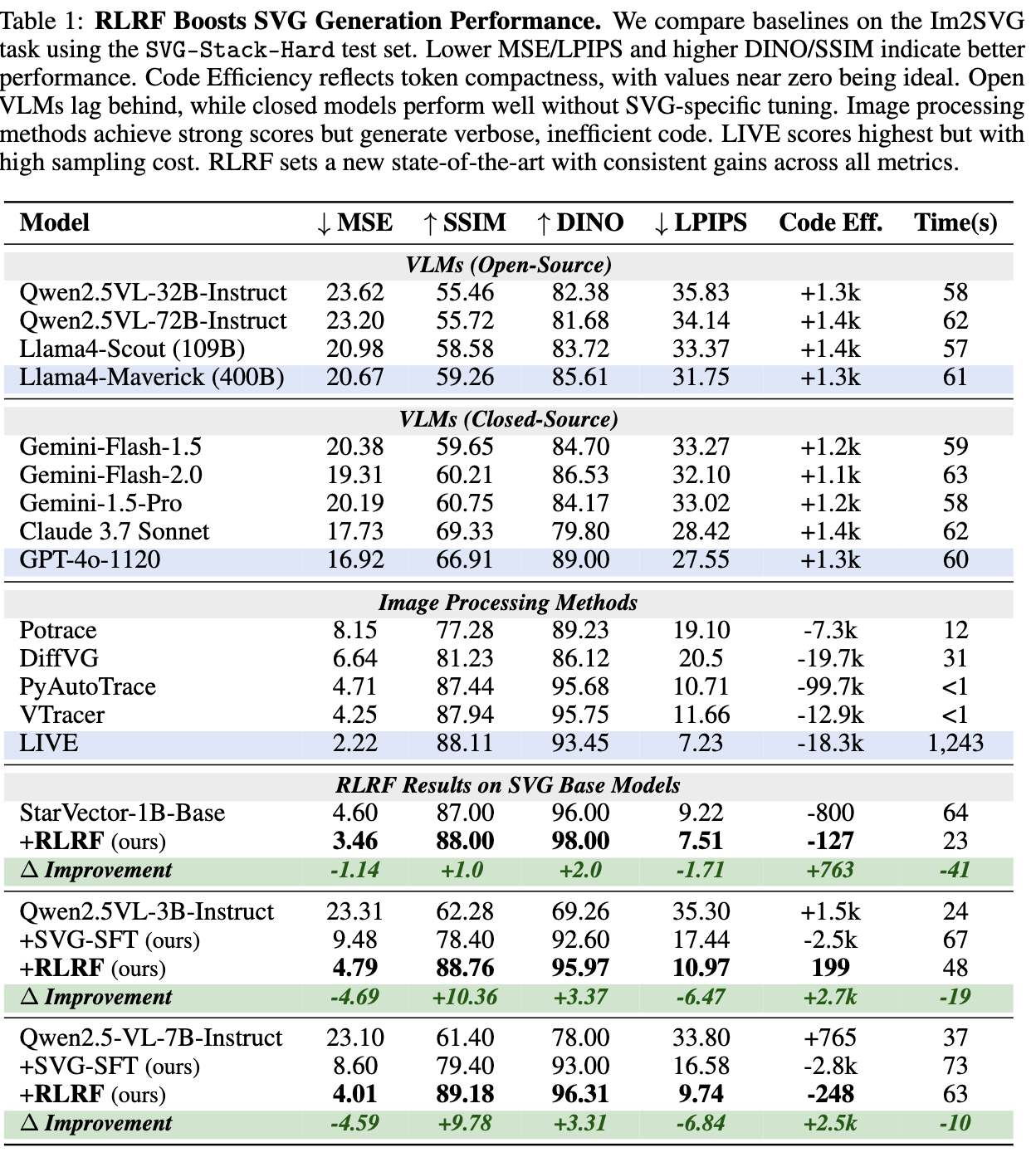
-
OOD에 대한 정량적 결과

-
정성적 결과
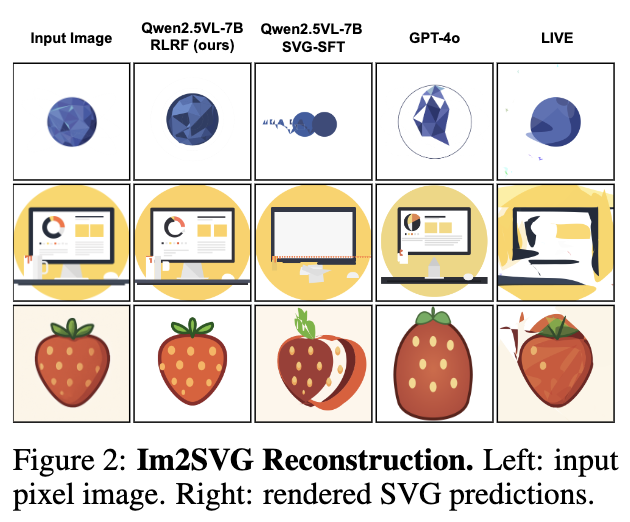
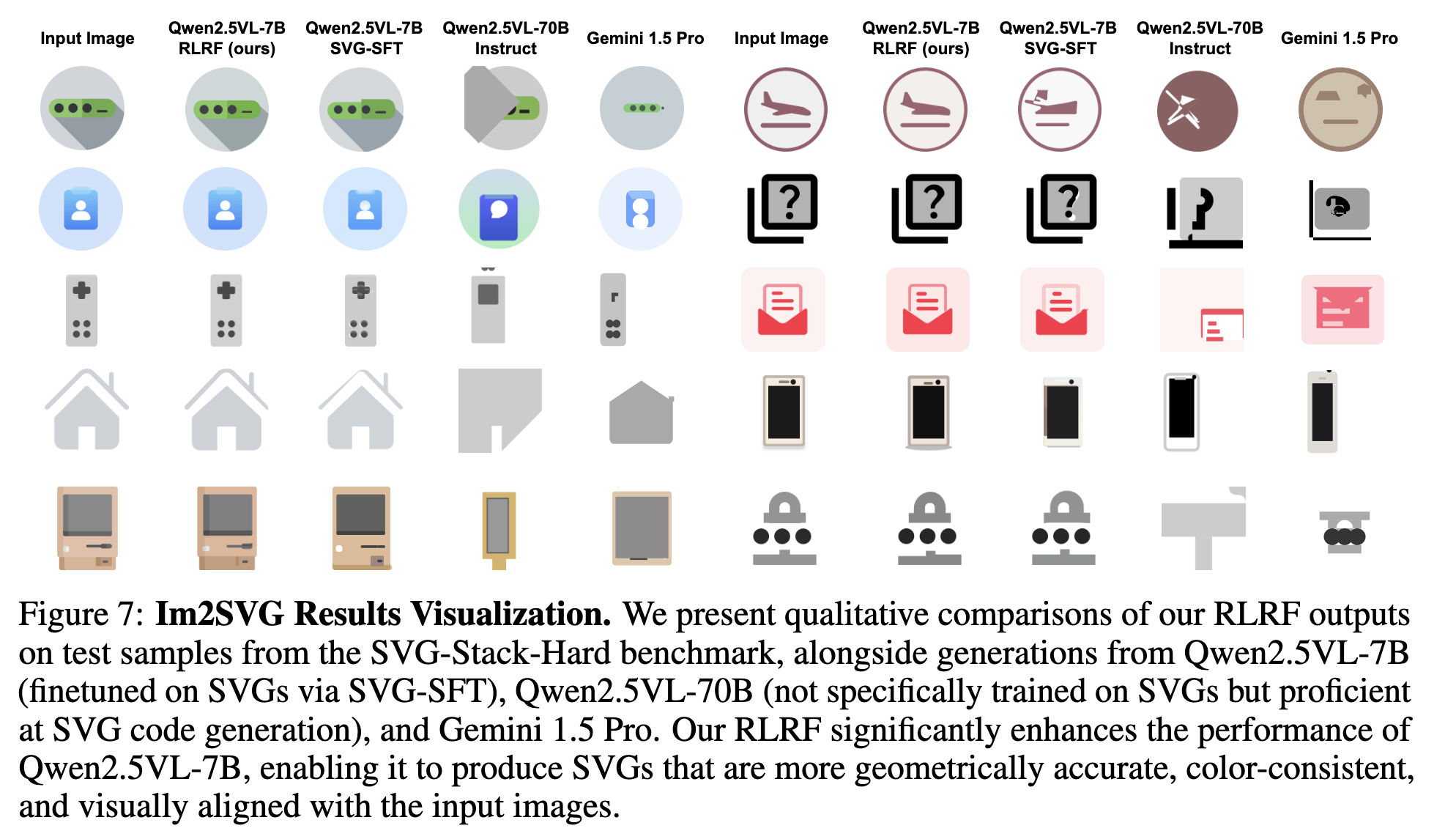

-
OOD에 대한 정성적 결과
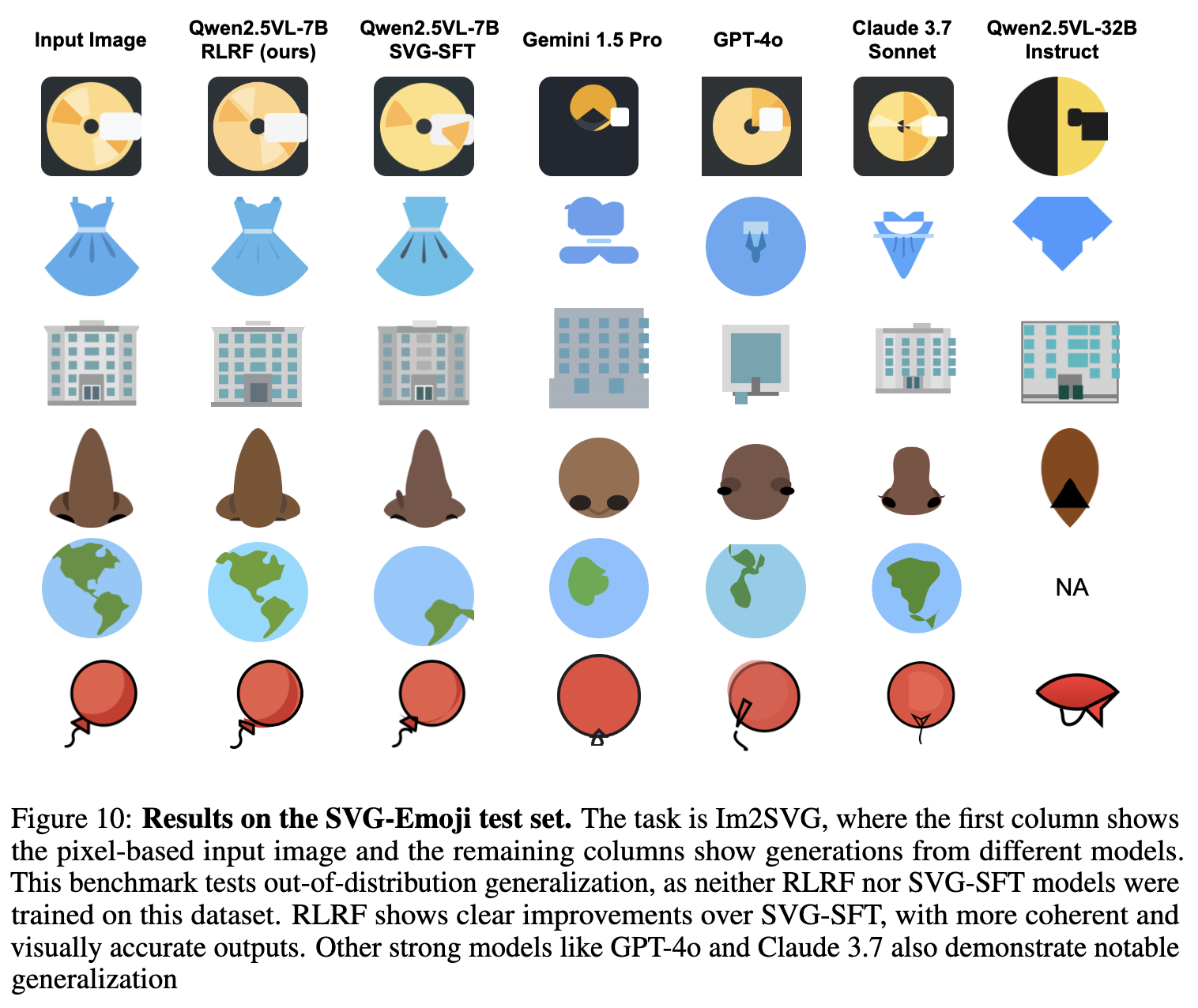

-
-
Text2SVG
-
정량적 결과
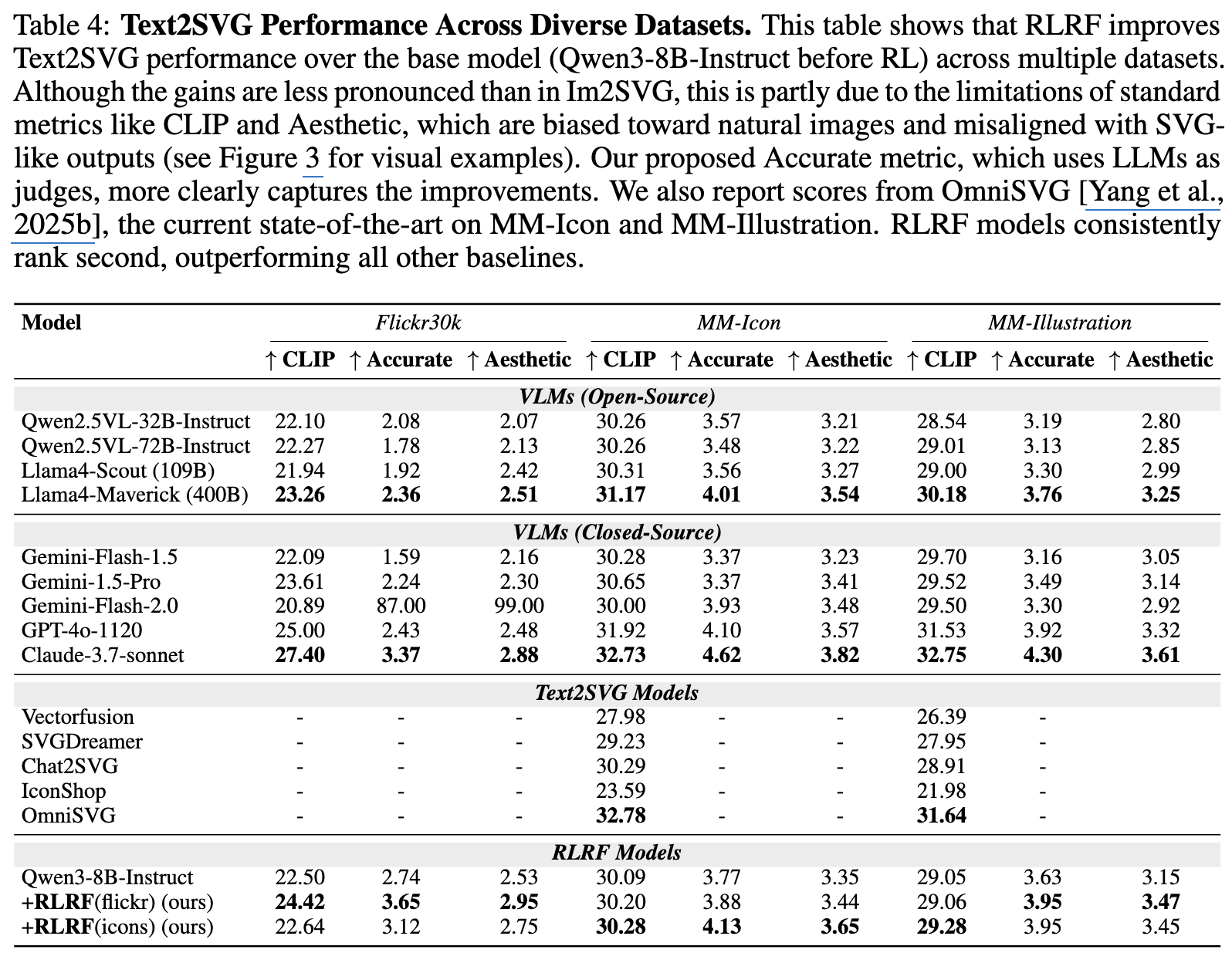
-
정성적 결과
-
Qwen3-8B-RLRF vs. others
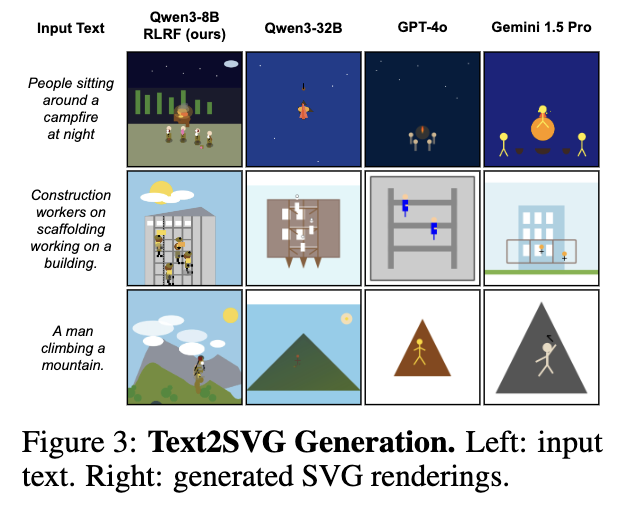
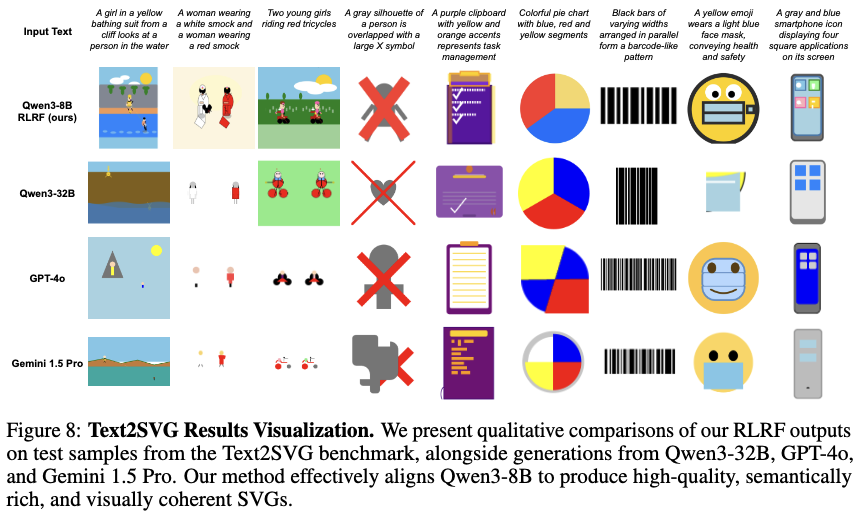
-
Qwen3-8B-RLRF result

-
-
5.3 Ablation Studies
-
Temperature에 따른 성능분석
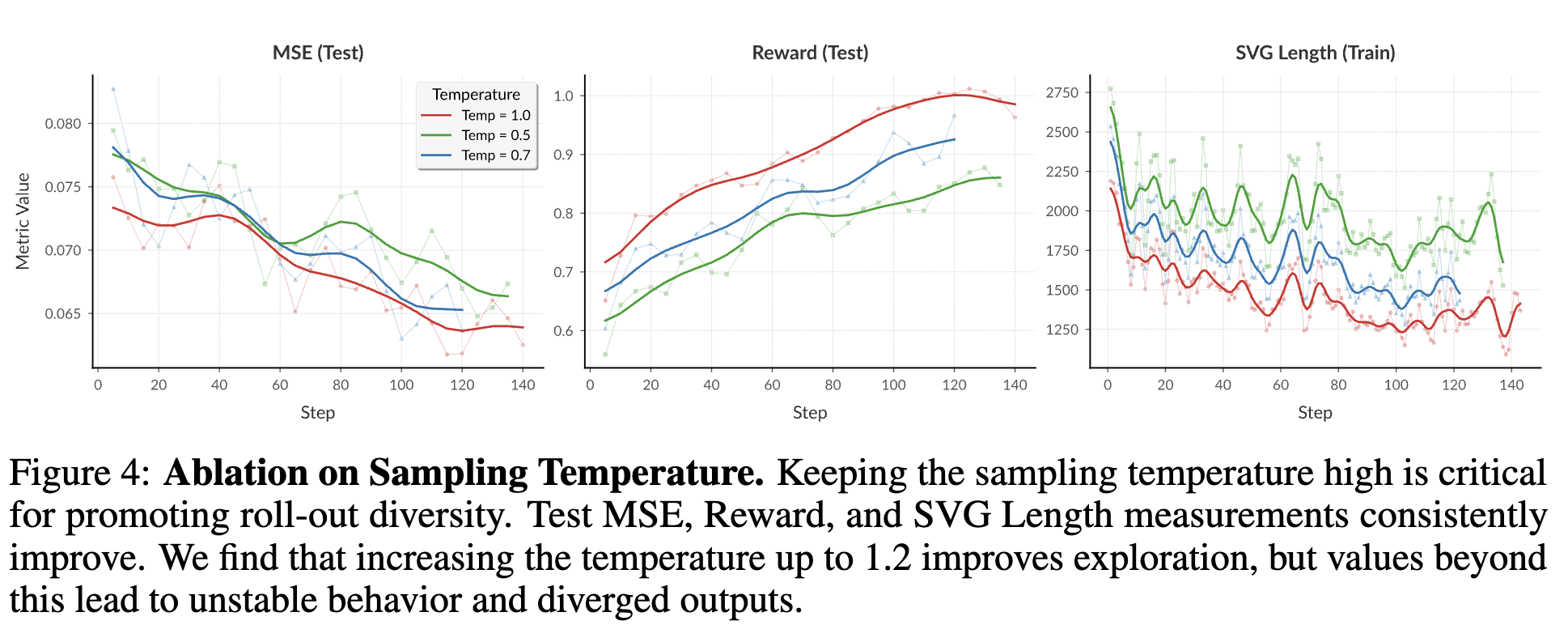
- Temperature가 높아질수록 output의 diversity가 증가해, roll-out이 다양한 출력을 갖게 되고, 이는 GRPO으로 성능 향상에 기인함.
-
Roll-out 갯수에 따른 성능분석
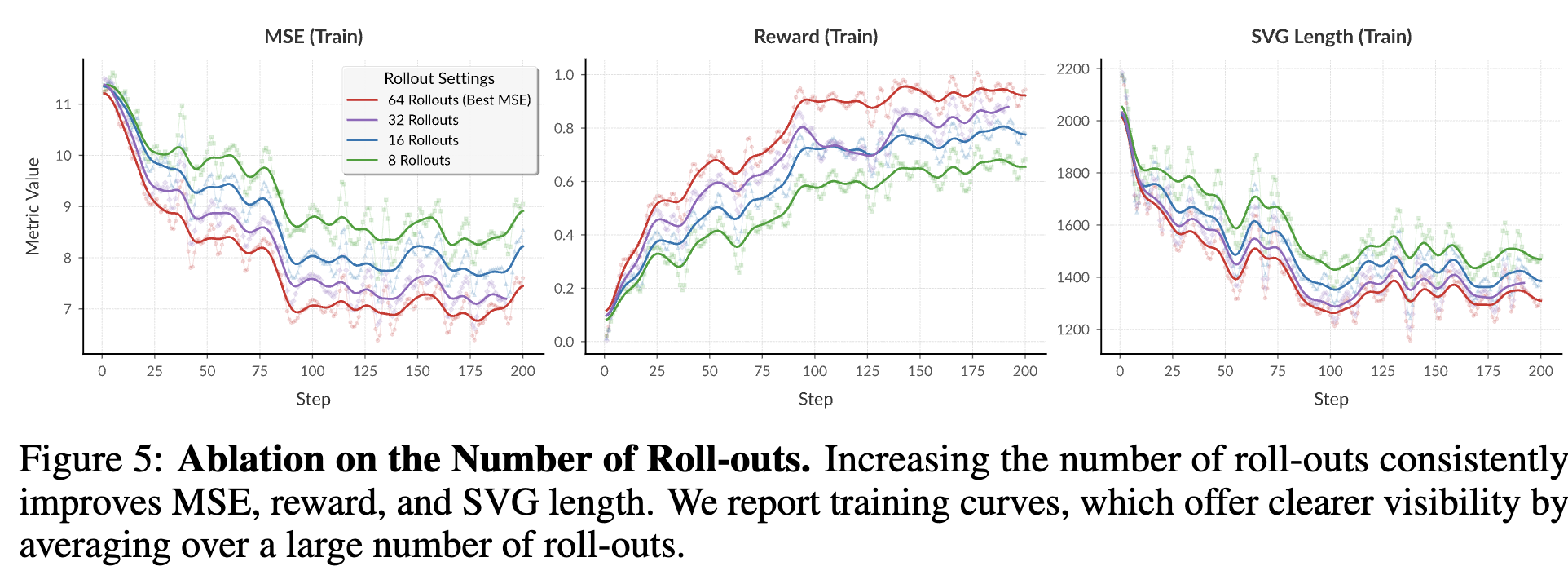
- roll-out 갯수가 증가할수록 GRPO덕분에 성능이 향상됨
-
SVG-SFT 유무에 따른 성능분석
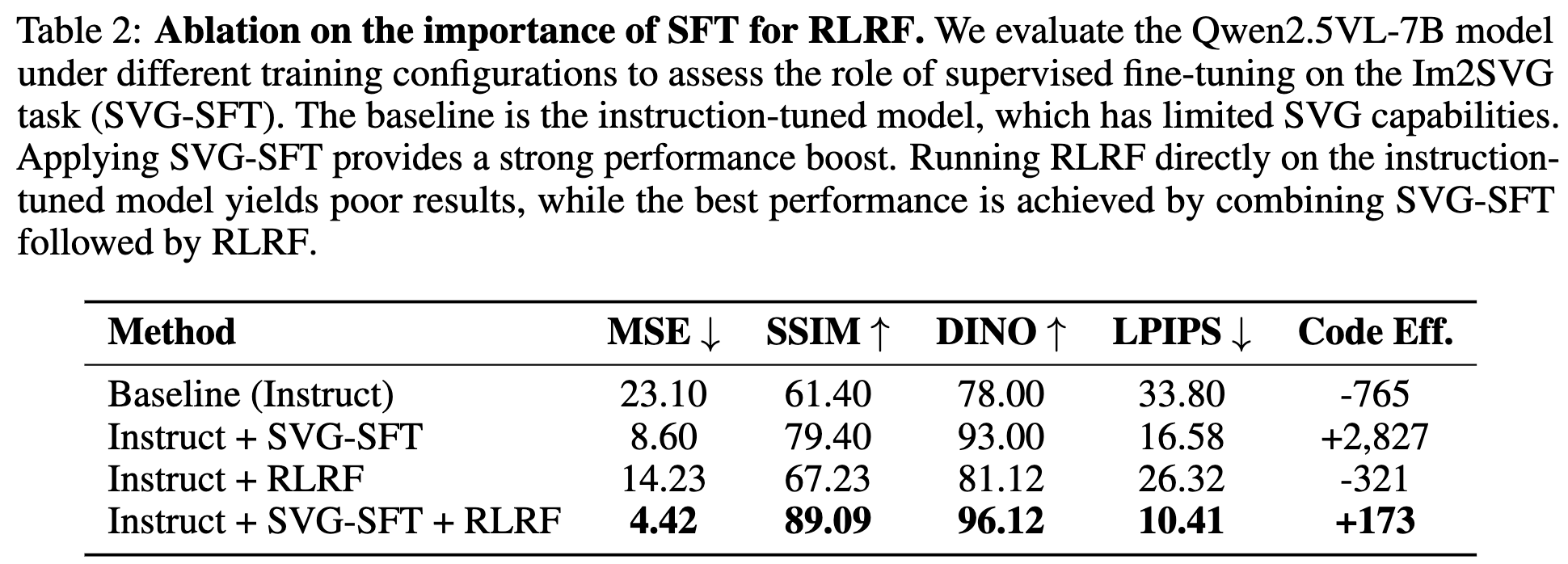
- SVG-SFT 학습 후에 RLHF를 하는것이 모델이 SVG 구조에 대한 이해를 할수 있게되어, 성능향상에 도움이 됨
-
Reward Signal에 따른 성능 분석
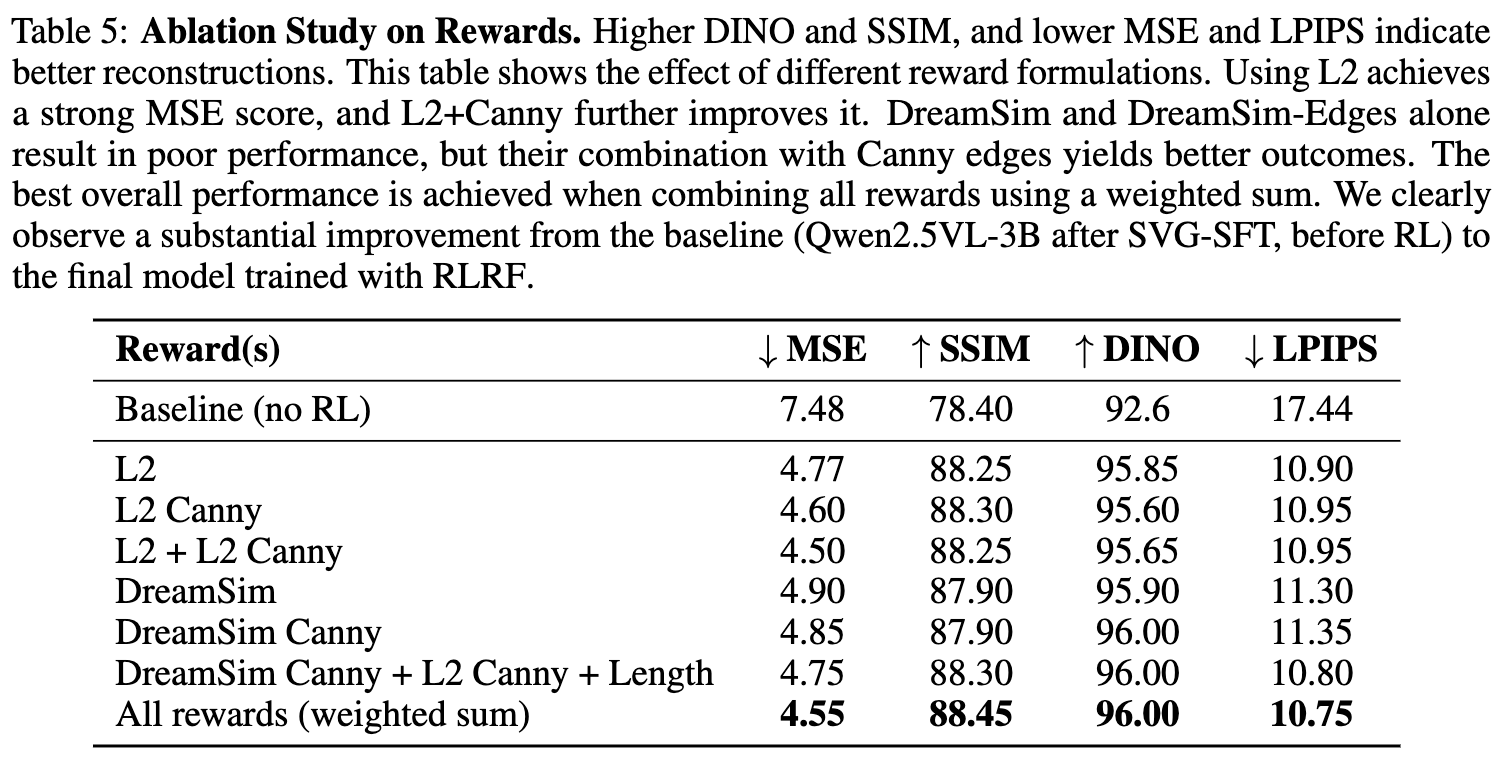
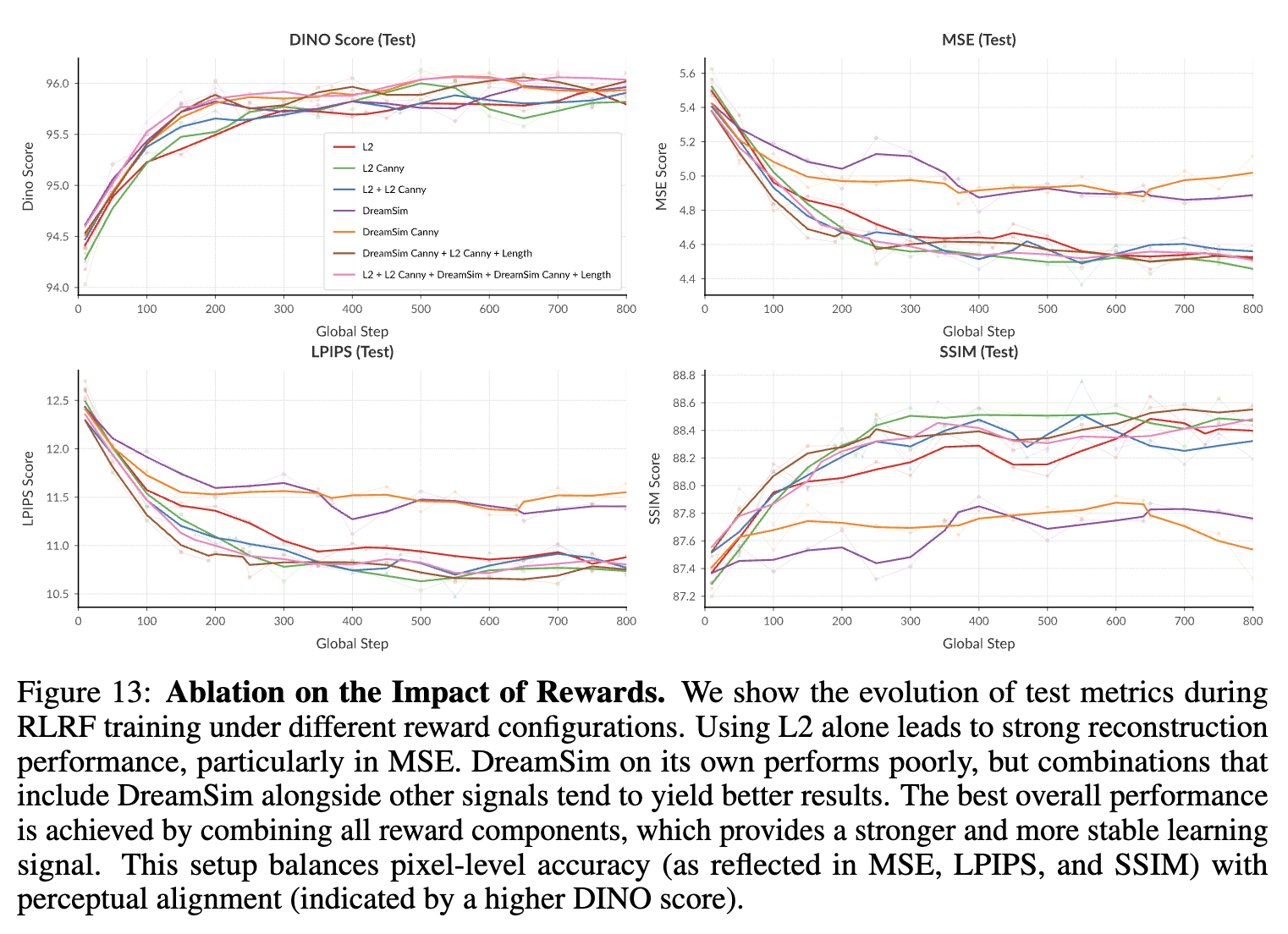
5.4 Reward Hacking
-
Small ViewBox Hack
-
model이 매우 작은 viewBox를 출력하는 경향을 발견함
<svg ... viewBox=0 0 1 1> -
이는 prediction된 box크기를 기준으로 gt image를 resize하여 reconstruction하였기 때문에, 결과적으로 모든 정보를 손실함으로써 reward를 증가시켰음
-
해결방안: original image로 resize수행하여 해결
-
-
SVG Length Collapse
- gt code의 token length의 절반이하일 경우, 매우 높은 reward를 제공하기에, 매우 짧은 code만 생성하곤 했음
- 해결방안: 이보다 짧을 경우 -1의 penalty를 강제 부여함. 또한, 초기에는 length loss weight를 0.1로 작게 주고, 점차 늘리도록 학습하여 해결
-
Text-in-Image hack
- CLIP-based reward를 사용한 Text2SVG task에서
tag에 들어갈 부분에 + prompt input을 넣는 형태로 reward를 hacking하고 있었음 - 해결책:
+ prompt input형태는 전처리하여 제거하고, Qwen-2.5-VL-72B-base를 VLM-as-a-judge로 추가하여 해결함
- CLIP-based reward를 사용한 Text2SVG task에서