[UDA][OD] NAS: Unsupervised Domain Adaptive Detection with Network Stability Analysis
[UDA][OD] Unsupervised Domain Adaptive Detection with Network Stability Analysis
- paper: https://arxiv.org/pdf/2308.08182.pdf
- git : https://github.com/tiankongzhang/NSA
- ICCV 2023 accpetd ( 인용수: 0회, ‘23.10/23 기준)
1. Motivation
- control theory robustness system은 internal/external disturbance에 consistent해야 함
- UDA task를 image, region, instance에 대한 disturbance에 robust하도록 만드는 task로 바라봄
2. Contribution
- ECA & ICA
- External Consistency analysis : model output이 disturbance에 Robust하게 consistent한지 평가
- Internal Concistency analysis : model의 중간 feature가 disturbance에 Robust하게 concsistent한지 평가
- HID & LID & InsD
- Heavy Image level Disturbances : 큰 object, 큰 region의 scale, view에 variation을 준 augmented image
- Light Image level Disturbances : 작은 object, 작은 region의 scale, view에 variation을 준 augmented image
- Instance level Disturbances : 동일 class 다른 객체간 거리 차이를 좁히도록 Contrastive learning으로 학습 (SupCon)
3. Network Stability Analysis
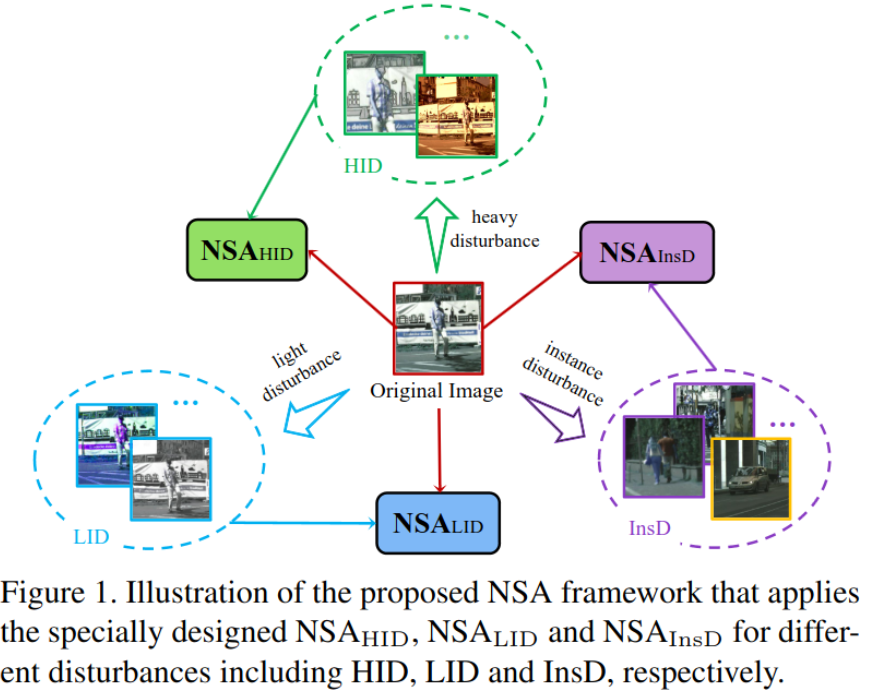
-
Overall Diagram
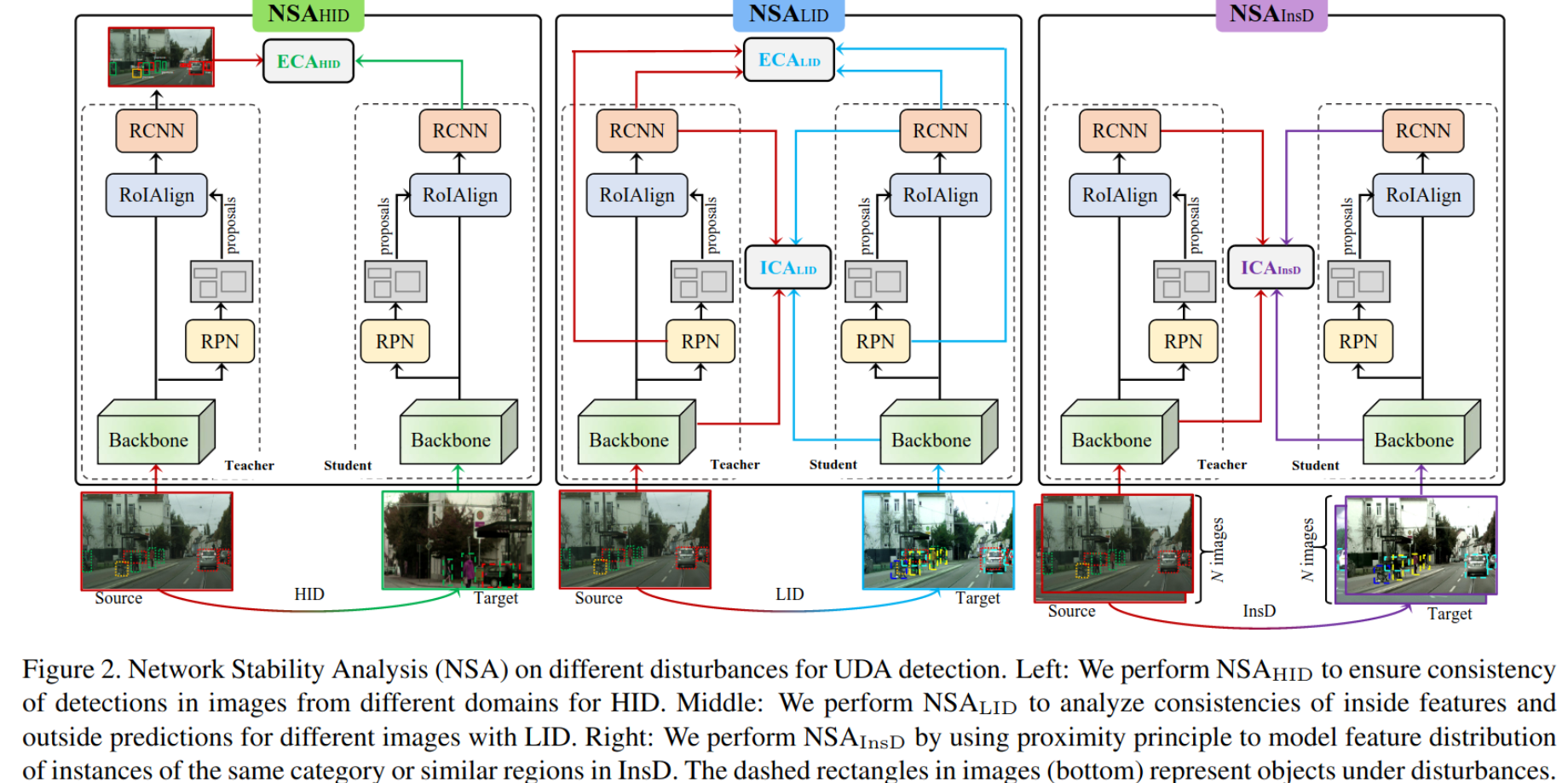
-
Total Loss & NSA Loss
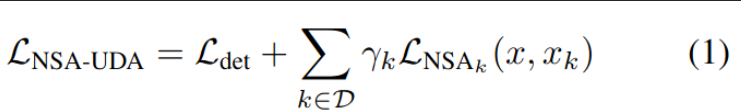
-
-
Base Detection Architecture

- Faster-RCNN & FCOS & Deformable DETR
-
$NSA_{HID}$
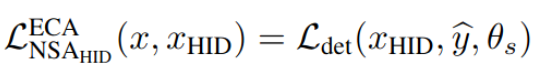
- $\theta_s$ : student parameter (detector)
- $\hat{y}$ : teacher pseudo label
- $x_{HID}$ : HID augmented image
- random resize / random horizontal flip / center crop / color and texture enhancement
- scale : [1, $S_{HID}$], $S_{HID}$=3.5
- random resize / random horizontal flip / center crop / color and texture enhancement
- External consistency만 적용
- Internal feature는 너무 다른 값을 내므로 0으로 setting ($L_{NSA_{HID}}^{ICA}(x, x_{HID}$)
-
$NSA_{LID}$
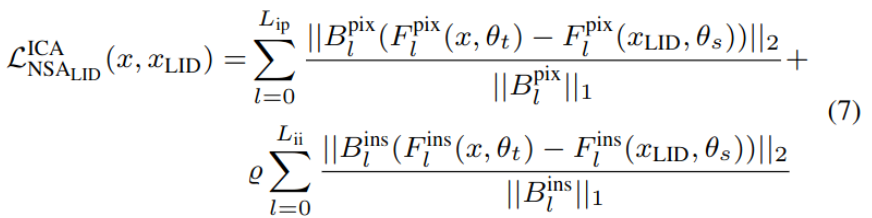
-
LID는 intrinsic (feature) + extrinsic (output) consistency 모두 적용
-
$L_{ii}$, $L_{ip}$ : instance-level, pixel-level internal feature layer의 갯수
-
$F^{pix}_l$ : pixel-level l 번쨰 layer의 feature
-
$F^{ins}_l$ : instance-level l 번쨰 layer의 feature
-
$B^{pix}_l$ : pixel-level l번쨰 layer의 weight → edge에 weight를 많이 주도록 구현
-
$B^{ins}_l$ : instance-level l번쨰 layer의 weight
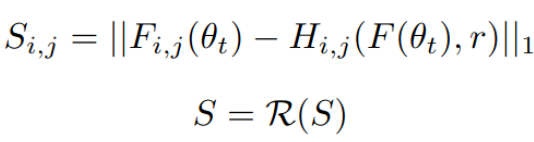
-
$H_{i,j}$(F,r) : i,j번째 중심을 기준으로 rxr window의 평균값
-
R : minmax normalization
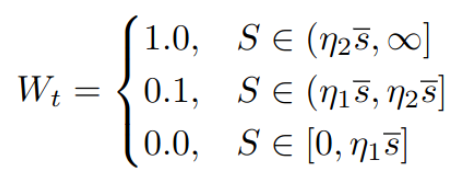
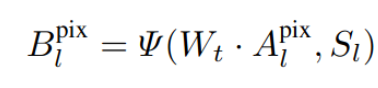
-
$\Psi$ : center point의 값과 rxr region의 max 값중 random sampling하는 operator

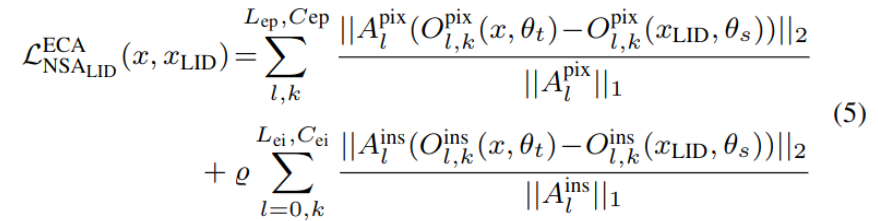
-
-
-
$O^{pix}_l$ : l번째 teacher 혹은 student의 layer의 pixel output
-
$O^{ins}_l$ : l번째 teacher 혹은 student의 layer의 instance output
-
$L_{ep}$, $L_{ei}$ : externel prediction layer 의 갯수 (category, instance)
-
$C_{ep}$, $C_{ei}$ : prediction category의 갯수
- FRCNN : {‘class’, ‘box’}
- FCOS : {‘class’, ‘box’, ‘centerness’}
-
$\rho$ : instance level adaptation indicator
- 1 : adapt instance
- 0 : not adapt instance
-
$A^{pix}$ : weight coefficient of each pixel
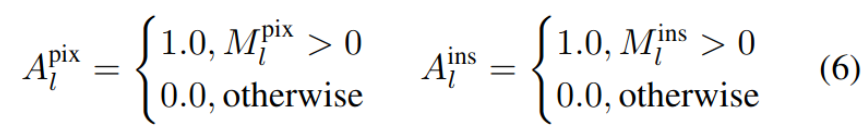
- M: label 혹은 pseudo label로 생성된 mask
-
$A^{ins}$ : weight coefficient of each instance
-
-
HID와 동일 + deviation degree (ratio of offset distance & stride of feature block)
- scale : [1, S_LID], S_LID = 1.5
- deviation degree : [0, D_LID], D_LID=0.25
-
-
$NSA_{InsD}$
-
Intrinsic consistency loss만 고려 ($L_{NSA_{ISD}}^{ECA}$=0)
-
instance-level 의 feature를 object별로 graph생성
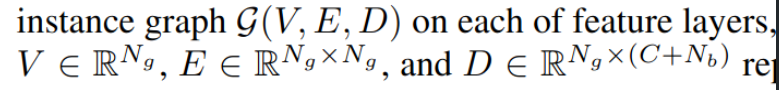
-
Edge weigh는 동일 category instance간의 거리로 weighting
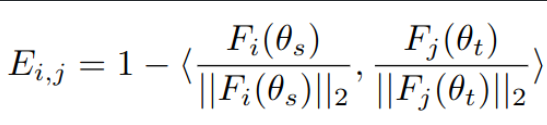
- Background sample은 edge값을 근거로 sorting해서 취득
-
C class center feature
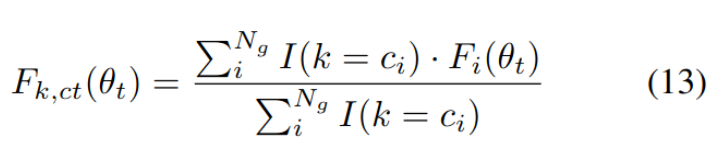
- $N_g$: Node의 갯수 (sample의 갯수)
- $F_{k,ct}$ : k번째 class의 feature center
- $c_i$ : i 번째 node의 class index
-
Nodes
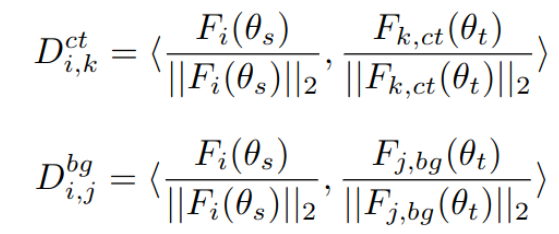
- D_i,k^ct : i번째 node의 k번째 feature center와 거리
- D_i,k^bg : i번째 node의 k번째 background sample
-
ISA Loss
-
같은 class내 isntance간 당기고, vice-versa
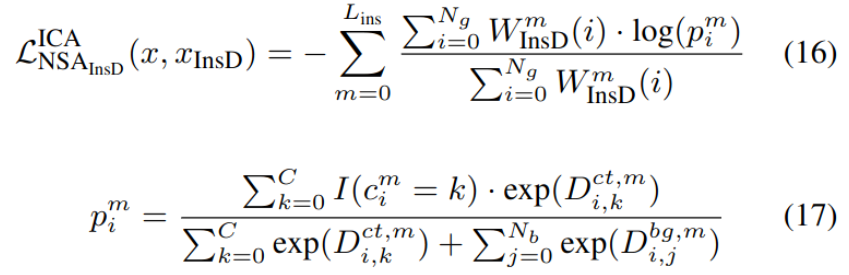
- $I(c^m_i=k)$: instance sample이 k class이면 1, 아니면 0
- $W_{InsD}^m$ : instance weight of nodes
- forground = 1, background = 0
- $L_{ins}$ : instance feature layer의 갯수
-
-
-
-
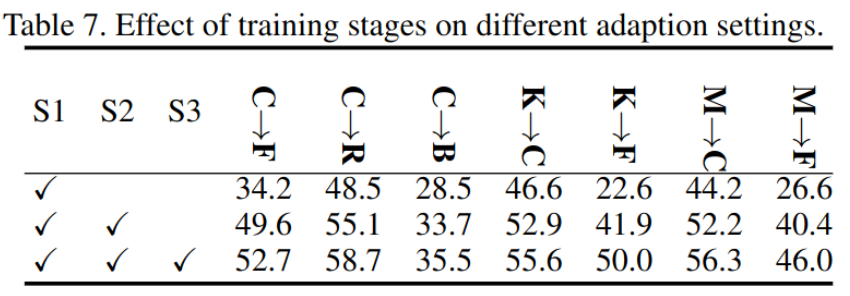
Optimization
- stage 1 (S1) : pretrained source only
- stage 2 (S2): update teacher by ema (source only)
- stage 3 (S3) : source + target
-
Experiments
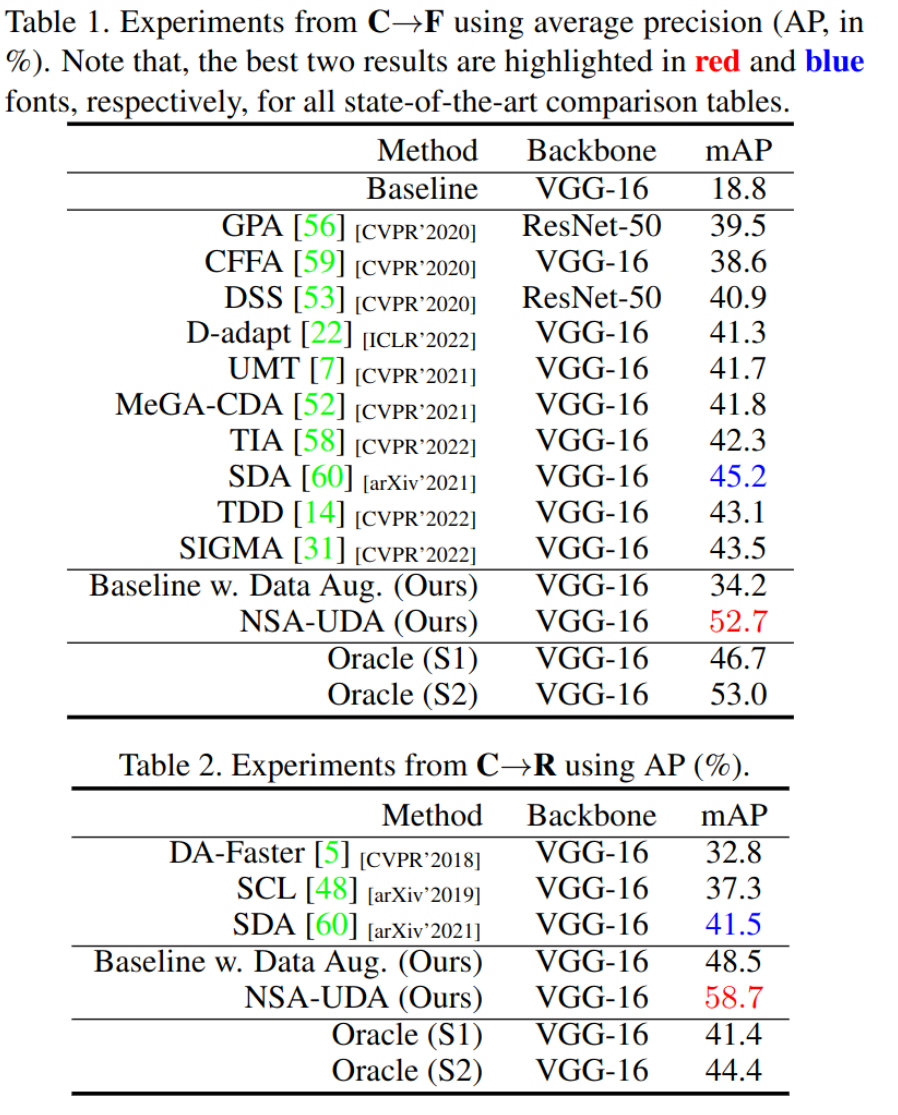
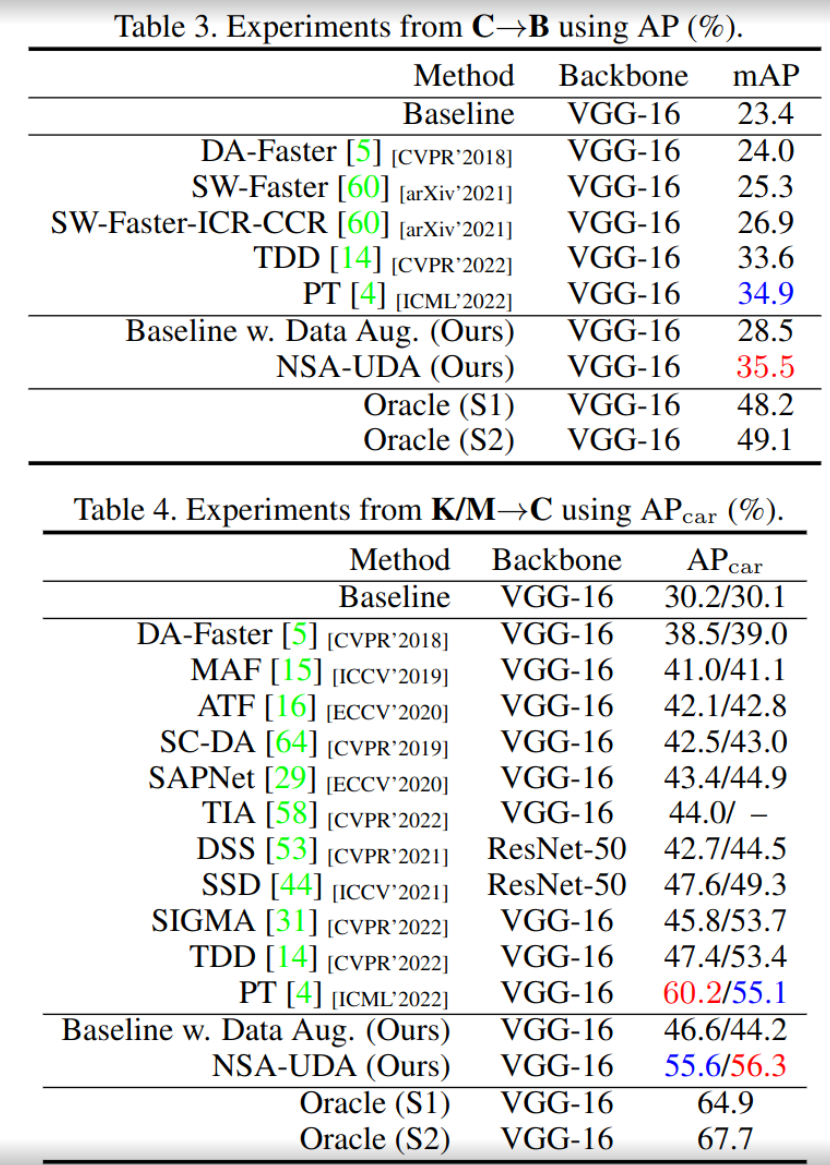
-
ablation study & different od
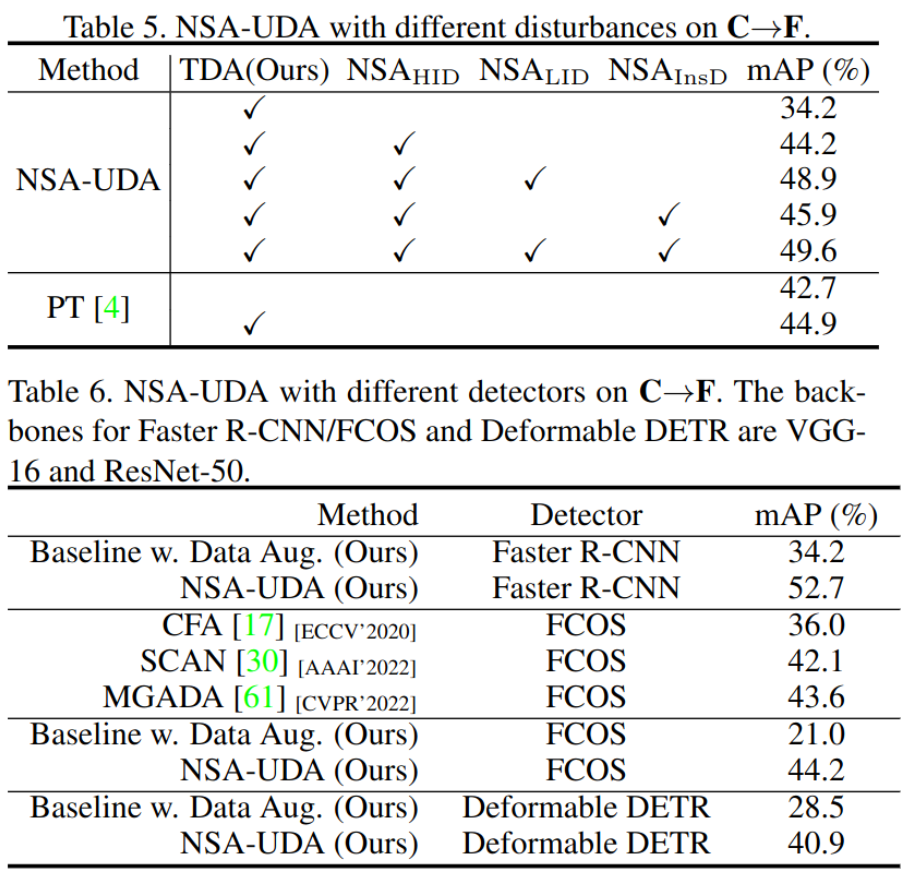
-
optimization step에 따른 성능