Mask2former
[Seg] Mask2Former
- paper: https://arxiv.org/pdf/2112.01527
- github: https://github.com/facebookresearch/Mask2Former
- CVPR 2022 accepted (인용수: 3248회, ‘25-09-07 기준)
- downstream task: Semantic Segmentation, Instance Segmentation, Panoptic Segmentation
1. Motivation
-
semantic seg / instance seg / panoptic seg 모두를 한번에 학습하는 architecture가 등장했으나, domain specific 모델에는 성능이 미치지 못함
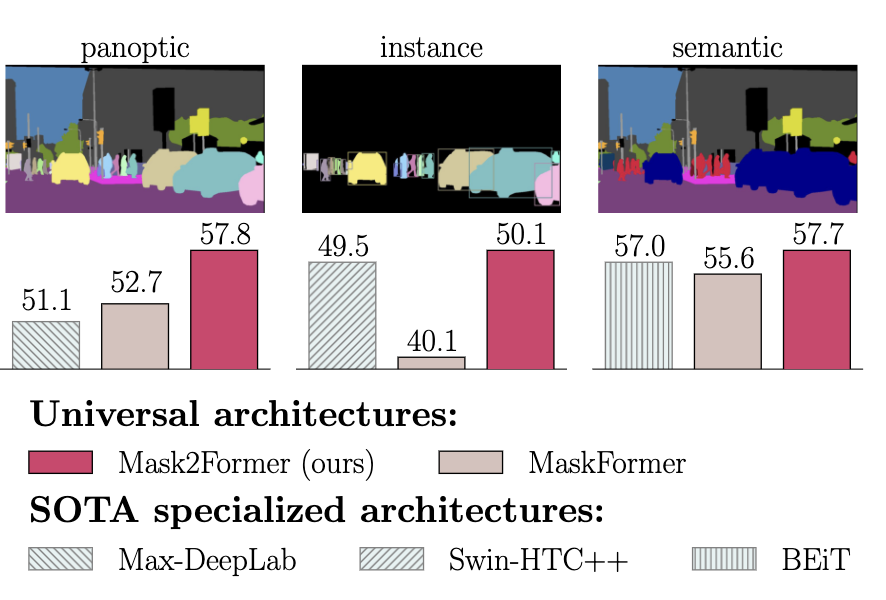
$\to$ 3개의 task를 1번에 학습하여 domain specific한 모델급 성능을 내는 모델을 만들어보자!
2. Contribution
- 3개의 통합된 segmentation task를 SOTA급으로 수행하는 Mask2Former를 제안함
- Masked Attention기반의 cross-attention (mask 내부만 cross-attention)를 통해 학습 수렴 속도 향상 & 성능 향상하는 masked attention를 제안함
- Multi-scale로 high resolution feature를 사용
- 최적화를 통해 성능 향상
- self/cross attention layer 순서 변경
- dropout 제거
- learnable query features 사용
- mask 전부를 학습에 활용하지 않고, random selected point만 사용하여 3x 메모리 향상 + 성능유지함
3. Mask2Former
-
Mask Classification
-
N개의 이진 마스크 + N개의 카테고리 라벨을 예측
-
DETR에서 영감을 받아 좋은 feature를 찾기 위해 3가지 모듈로 구성
-
backbone
- 저해상도의 feature를 추출
-
pixel decoder
- 저해상도의 feautre를 고해상도 per-pixel embedding으로 점진적 upsampling
-
transformer decoder
-
masked attention
- binary mask segmentation영역에 대해 object queries와 image features를 가지고 segmentation 수행
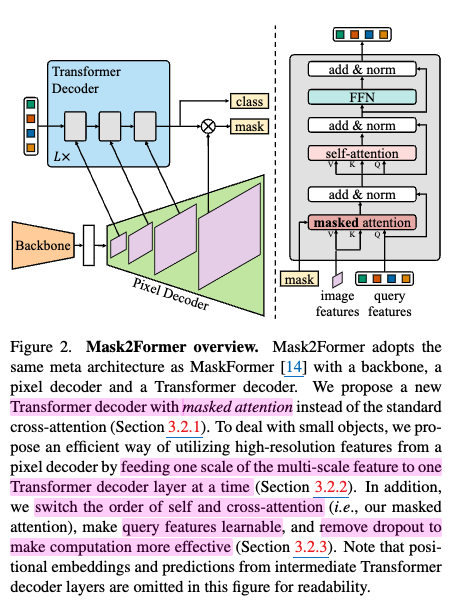
$\to$ Tranformer의 느린 수렴 속도는 global하게 cross-attention하는 특성 때문인데, 이를 mask 영역으로 한정함으로써 수렴 속도 향상 + 성능 향상
-
as-is (cross-attention)
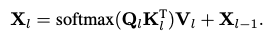
-
to-be (masked cross-attention)
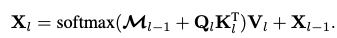
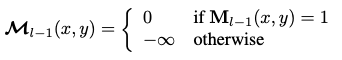
-
high-resolution features
- as-is
- 최상위 high-resolution feature만 단독으로 사용 (Output Stride: 8)
- to-be
- pyramid 형식 (round-robin)으로 저해상도 ~ 고해상도 feature를 모두 사용 (Output Stride: 32, 16, 8, 4)
- learnable scale embedding + 개별적인 positional embedding 사용
- as-is
-
Optimization improvements
- self- / cross- attention layer 순서를 바꿈
- 근거: query feature는 zero-initialized되었고, image연관된 정보가 없기 때문에, self-attention해도 무용지물이라 판단
- query feature ($\bold{X}_l$) 도 learnable하게 바꿈
- self- / cross- attention layer 순서를 바꿈
-
-
-
Improving Training Efficency
-
전체 mask point가 아닌, random sampled K point만 가지고 학습 (K = 112x112 = 12,544)
-
matching loss: bipartite loss
- final loss: importance sampling기반으로 prediction & ground truth로 계산
$\to$ 3배의 메모리 효율 + 성능 향상
-
-
-
4. Experiments
-
Implementation details
-
Pixel Decoder = 6 Layers, MSDeformAttn (os4, os8, os16, os32)
-
Transformer Decoder = 3 Layers, Auxiliary loss가 각 layer별로 추가 학습 (+learnable query)
-
Loss
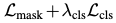
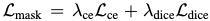
-
후처리
- mask confidense x class confidense score로 계산
-
-
정량적 결과
-
Panoptic segmentation
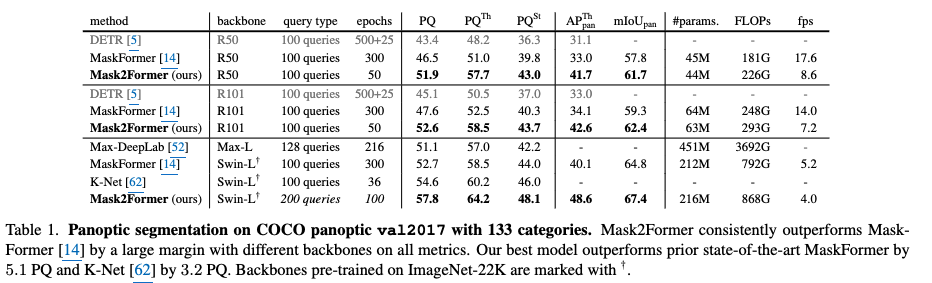
-
Instance Segmentation
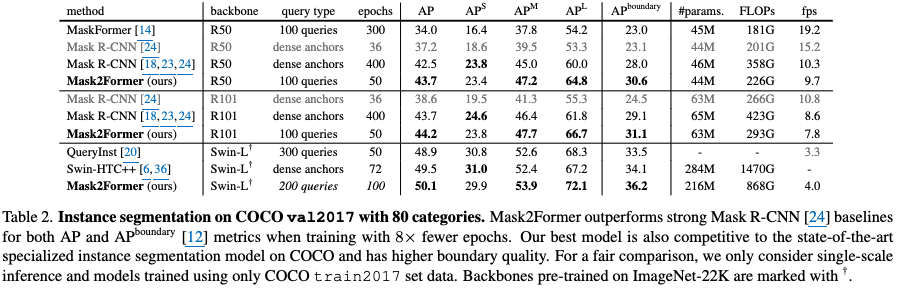
-
Semantic Segmentation
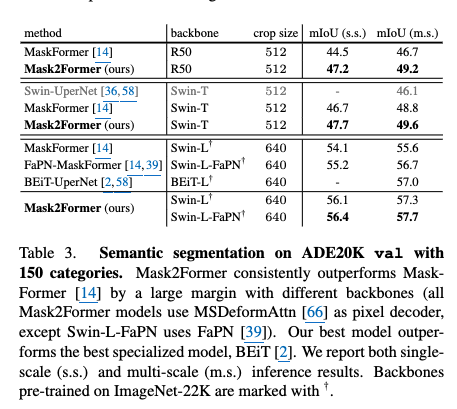
-
-
Ablation Studies
-
Masked Attention & High resolution 유무에 따른 성능 분석
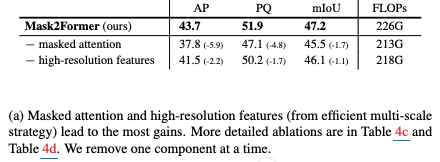
-
Optimization improvement 유무에 따른 성능 분석
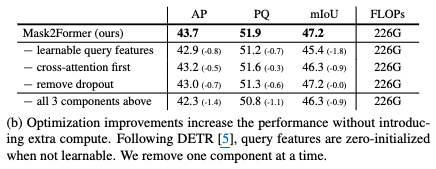
-
다른 masked attention과 비교 분석
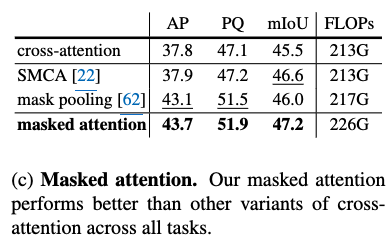
-
다른 multi-scale과 비교분석
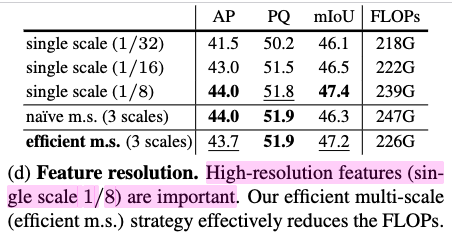
-
다른 Pixel decoder 비교 분석
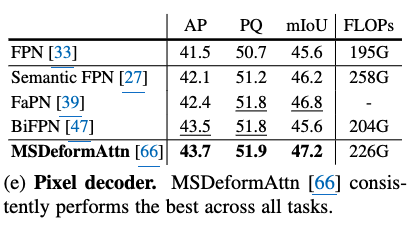
-
Random sampled Point loss vs. Full point loss
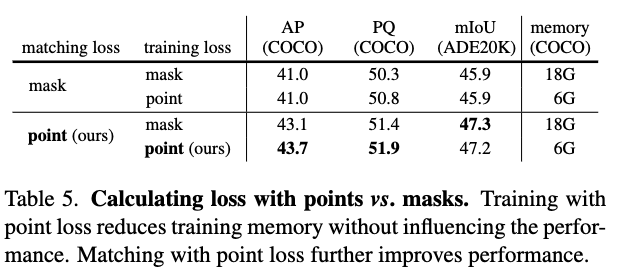
-
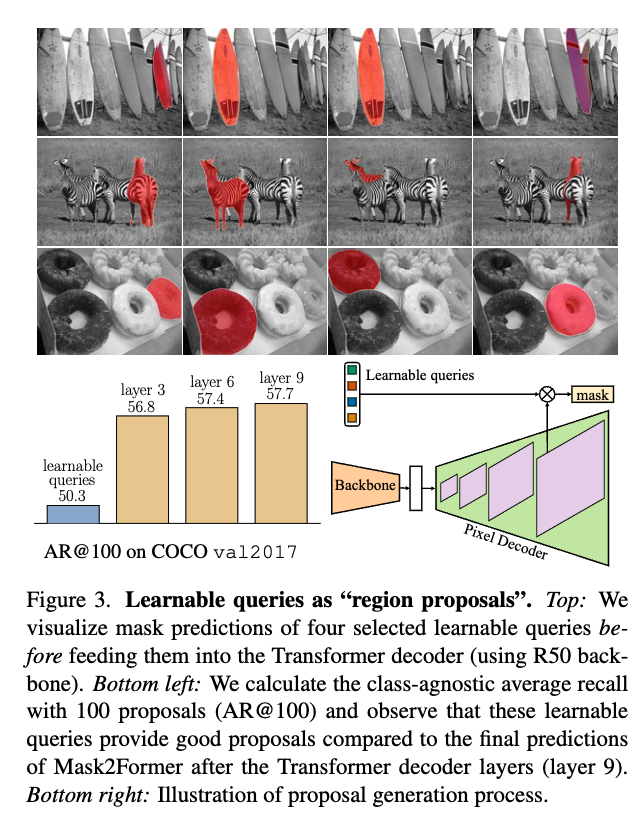
Learnable queries as Region Proposal
-
Learable query는 Transformer decoder의 입력으로 들어가기전에도 상당히 좋은 region을 추출함
-
-
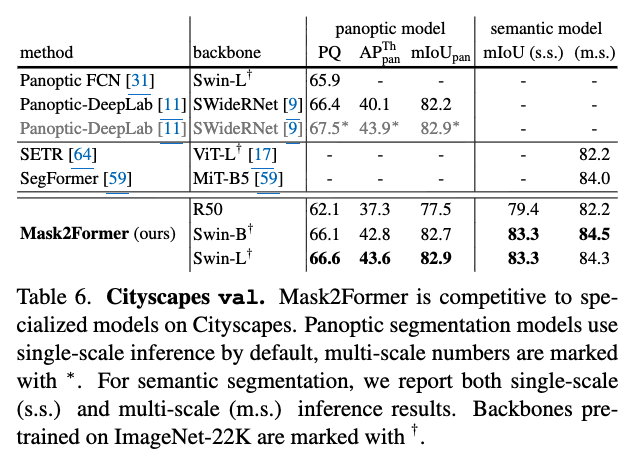
Generalized to Other Datasets
-