[Agent] Magma: A Foundation Model for Multimodal AI Agents
[Agent] Magma: A Foundation Model for Multimodal AI Agents
- paper: https://arxiv.org/pdf/2502.13130
- github: https://github.com/microsoft/Magma
- CVPR 2025 accepted (인용수: 39회, ‘25-08-17 기준)
- downstream task: UI Navigation, robot manipulation, Multimodal VQA
1. Motivation
-
많은 Generalist Agent AI라고 하는 연구들이 특정 도메인 특화 능력을 위해 일반적인 multimodal 이해능력을 희생하고 있다.
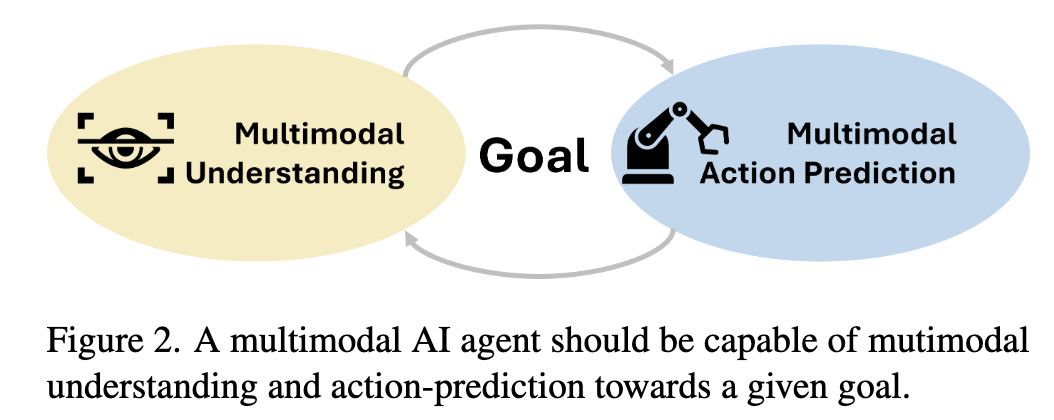
$\to$ 일반화된 멀티모달 이해 능력을 갖추었으며, 일반화된 Agent 능력(Action Prediction)을 지닌 Foundation Agent model을 반들어보자!
-
단순하게 대량의 이종(heterogeneous) vision-language / action dataset을 통합하는 것은 이득을 주지 못한다.
- UI navigation : Mind2Web, AITW
- Vision-Language Understanding: GQA, VideoMME
- Robitic Manipulation: Bridge, LIBERO
$\to$ 인터페이스가 다르기 때문. 인터페이스를 통합해보자!
2. Contribution
-
물리적 환경 / 디지털 환경에서 generalist Agentic AI, Magma를 제안함
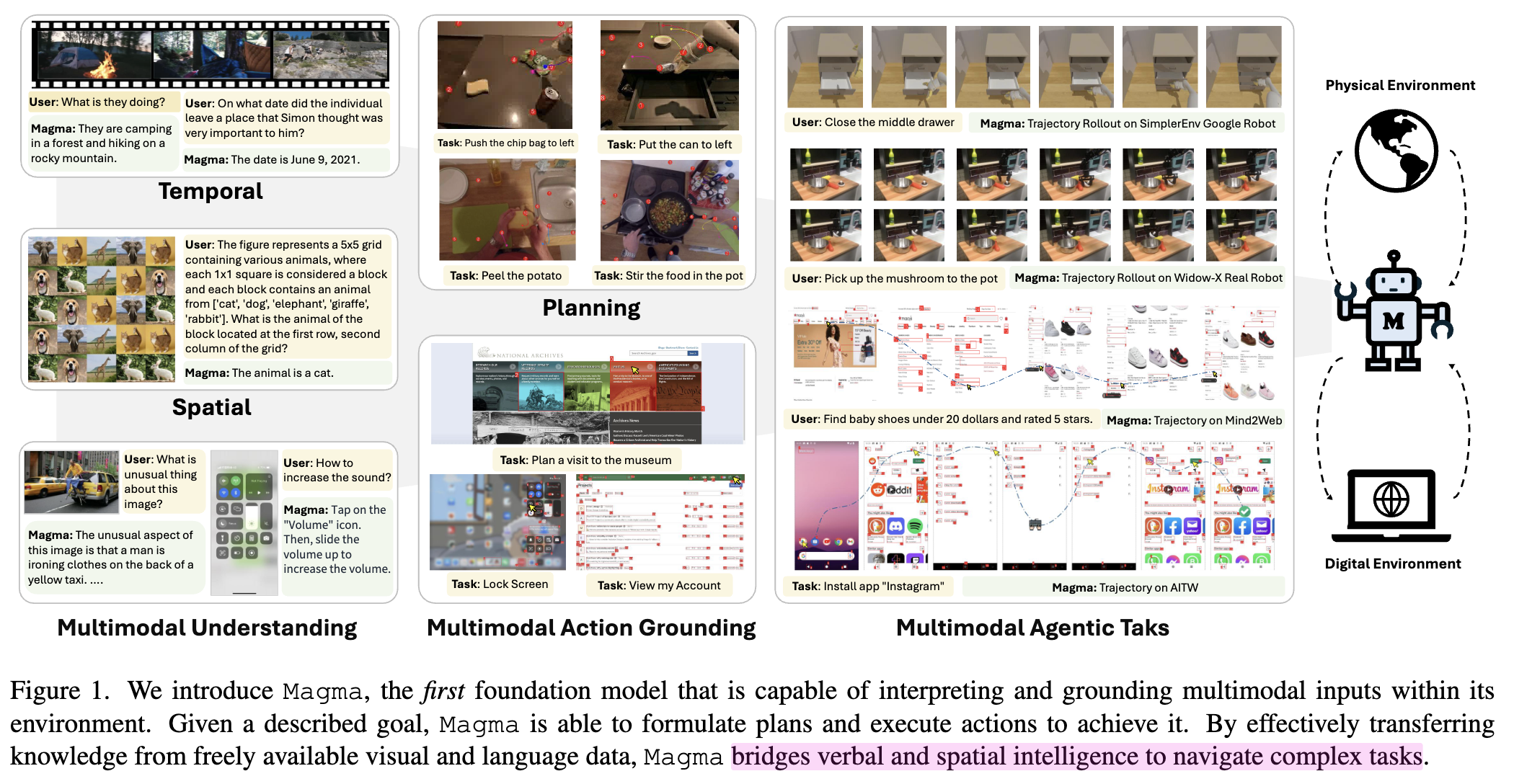
- 멀티모달 이해 능력
- 공간-시간적 reasoning 능력
-
Set-of-Mark & Trace-of-Mark 기반으로 모델의 시공간에 대한 이해능력을 키울 수 있는 pretraining dataset interface를 제안
-
Open-source VL dataset뿐만 아니라 UI, robotic data, human instructional videos를 SoM+ToM기반으로 라벨링한 데이터셋 공개 $\to$ 39M dataset
-
Robotic Manipulation + UI Navigation에서 SoTA
-
Magma의 pretraining 기법이 시공간에 대한 이해능력을 키움을 여러 실험적 근거를 통해 입증함
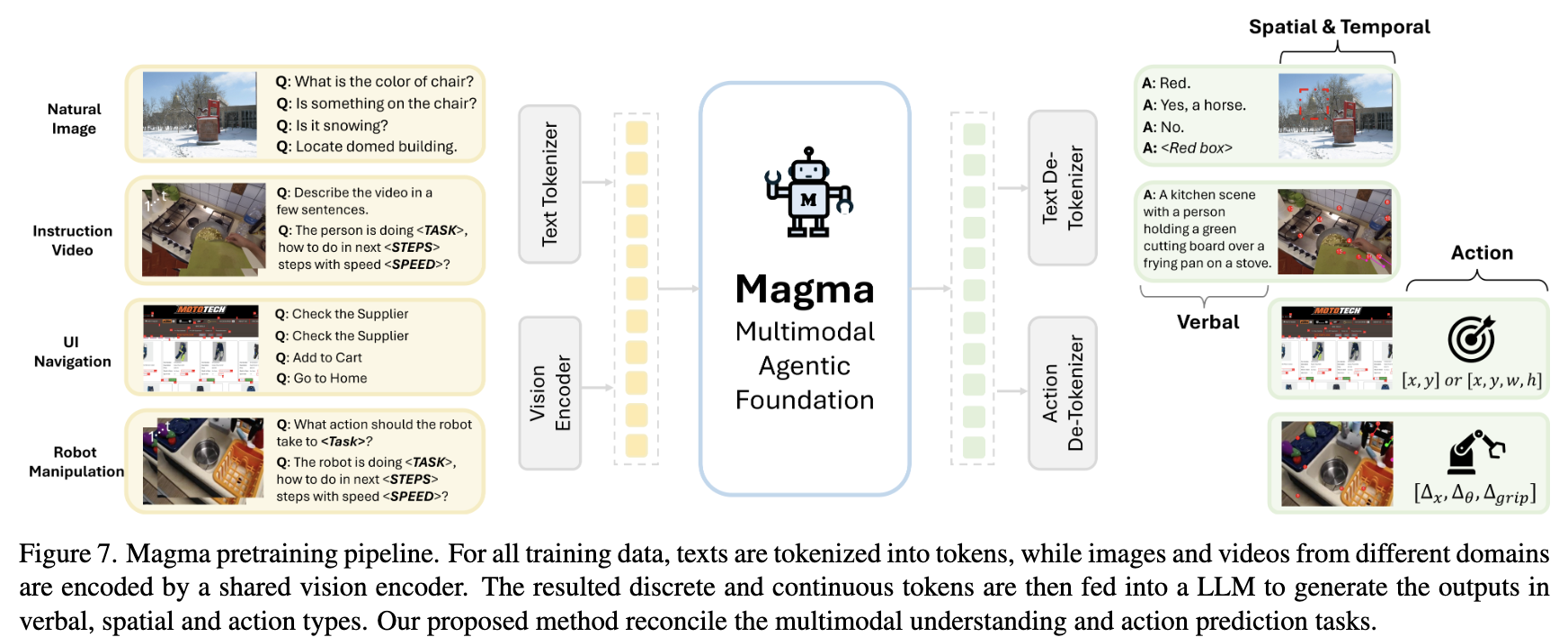
3. Multimodal Agentic Modeling
3.1 Problem Definition
-
multimodal understanding + action-taking 모두 갖추어야 함
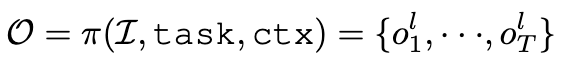
-
$I$: 과거 visual observations ${I_1,I_2,…,I_k}$
-
task: text로 정의된 task description -
ctx: context -
$O \in {o_1^l, .., o_T^l}$
-
T개의 token
-
$l$: verbal or spatial
-
UI Navigation: action type + location/box
ex. “type”: “click”, (x,y) / (x,y,w,h)
-
Robotic manipulation (3D): 6-DoF displacement
ex. (x,y,z,yaw,pitch,roll)
-
Multimodal understanding: text output
-
-
본 논문에서는 모든 출력을 text로 표현함
- 2D-action: LLM이 거의 사용하지 않은 256-special token
-
-
3.2 Methods
- Pretraining Objectives
- 이종의 대량의 학습 데이터를 통합하여 학습하는 인터페이스가 필요
- 단순한 방법: 2D/3D coordinate을 text화 $\to$ in/out domain gap이 커서 다른 방법을 강구
- Data Scaling-Up
- Vision-Langauge dataset은 다양성 / 규모 측면에서 한계가 있음
- Video의 경우, human actions / human-object interaction 라벨이 대규모 / 다양하게 많아 이를 활용
- 새로운 제안
- Trace-of-Mark: SoM에서 영감을 받음
- AI모델에게 시간축으로 longer horizon에 대한 action을 강제로 학습시킴으로써 unlabeled video data를 활용할수 있음
3.2.1 Set-of-Mark for Action Grounding
-
공식
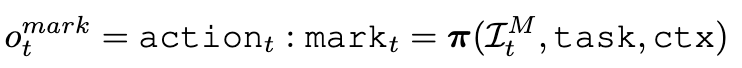
- input
- $I_t^M$: t번째 SoM screenshot
task: instructionctx: context
- output
- $mark_t$: t step에서 ai model이 주어진 task, context, SoM Image에대해 grounding하여 예측한 element index
- input
3.2.2 Trace-of-Mark for Action Planning
-
공식
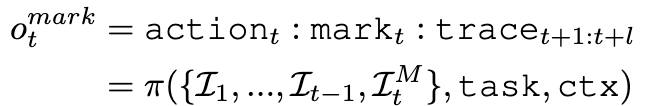
- input
- ${I_1,…,I_{t-1},I_t^M}$: (t-1)개 video frames + t번째 SoM screenshot
task: instructionctx: context
- output
- $action_t$: t step에서 예측한 action type
- $mark_t$: t step에서 grounding하여 예측한 mark
- $trace_{t+1:t+l}$: l번째 미래까지 예측한 mark의 위치
- CoTracker 을 활용하여 trace를 추출
- input
3.3 Modeling
- Vision Encoder: 고해상도 이미지 처리를 효율적으로 수행하는 CNN기반의 ConvNeXt
- LLM: LLaMA-3-8B
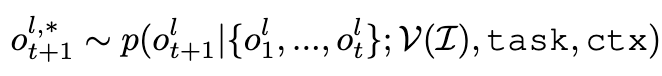
4. Multimodal Agentic Pretraining
4.1 Datasets

4.2 SoM and ToM Generation

4.2.1 SoM for UI Navigation
-
Textual label

- bbox와 overlap이 최소화되도록 배치
4.2.2 SoM and ToM for Videos and Robotic Data
-
Trace 추출

- CoTracker 모델 활용
- t step frame에서 균등하게 배치된 $s^2$의 point grid를 생성
- (l-t)개의 frame에 대해space에서 point를 추출
- 신뢰도
- YouCook2BB의 bbox를 기준으로 추출성능 평가 $\to$ 0.89
- CoTracker 모델 활용
-
Segment & CLIP-score 필터
- video의 text가 noisy할수도 있음 $\to$ Clip-score 0.25미만은 제외
-
Global motion 제거

-
대부분의 video에서 화면전환은 1인칭 관찰자의 움직임이 반영됨.
-
이를 효율적으로 제거하기 위해, 미래 frame에서 예측한 mark positions를 기반으로 homography matrix를 3x3로 예측하여 상쇄
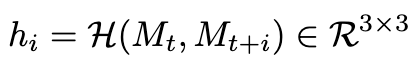
-
4.3 Pretraining
-
Architecture
-
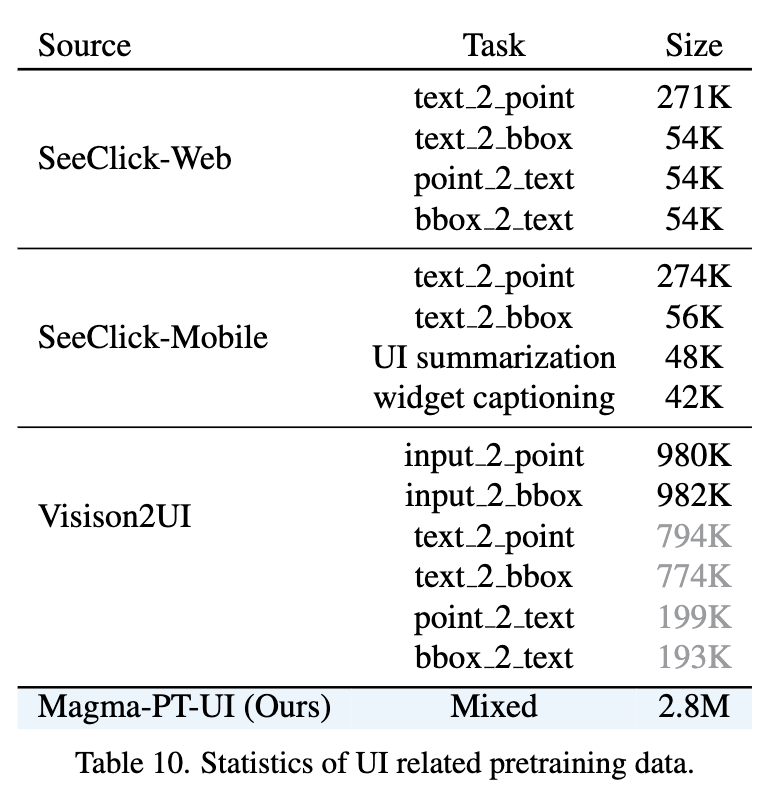
UI Navigation Datasets (2.8M)
-
Robotic Manipulation
- 970K trajectories (Open-X-Embodiment)
- 9.4M image-lanuage-action triplets
- 970K trajectories (Open-X-Embodiment)
-
Video
- 25M clips
-
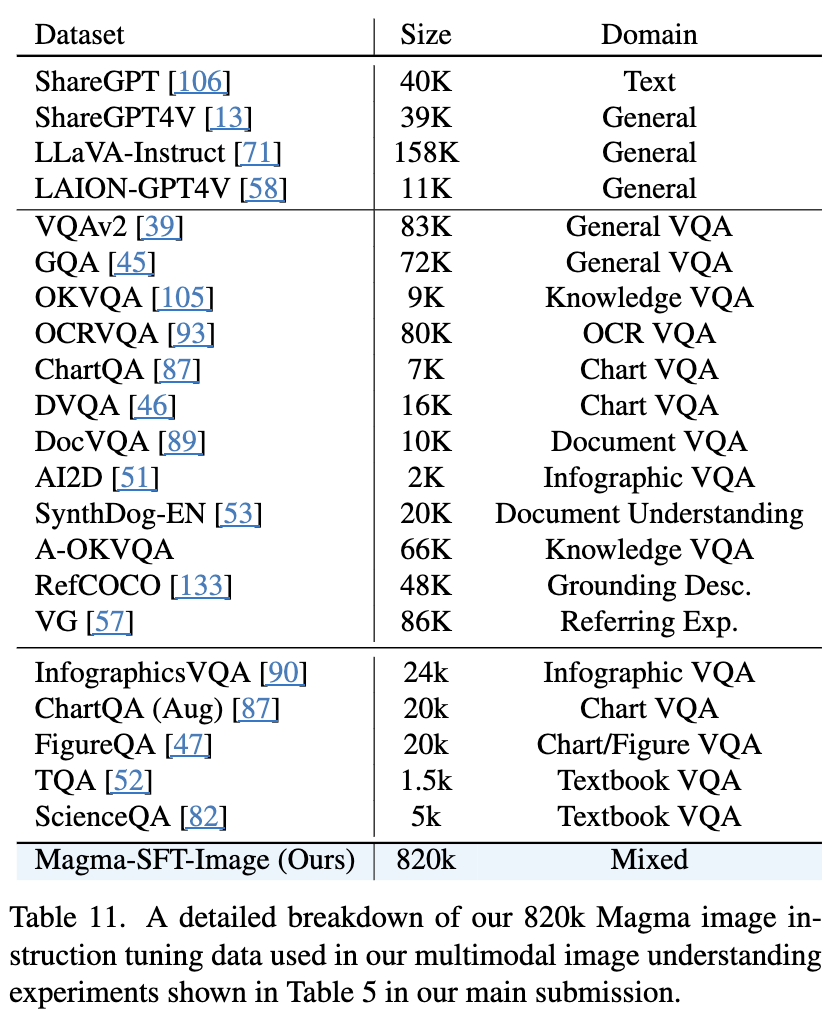
Multimodal dataset (820K)
5. Experiments
-
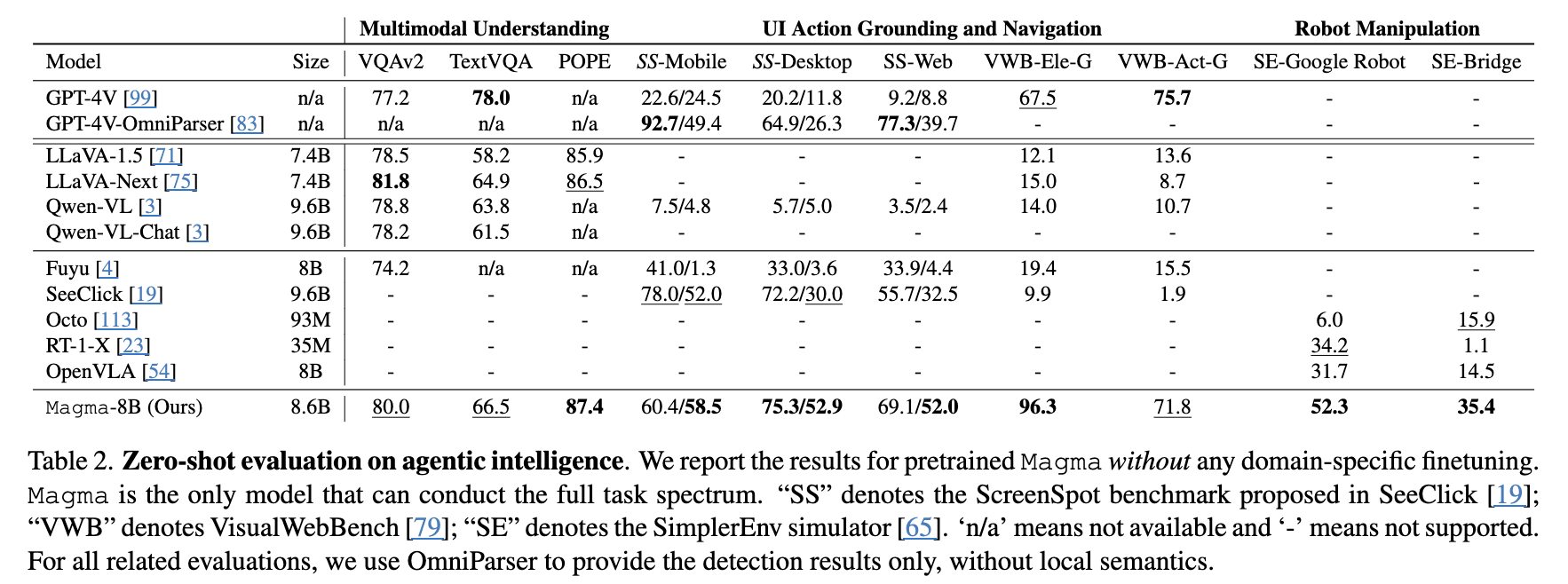
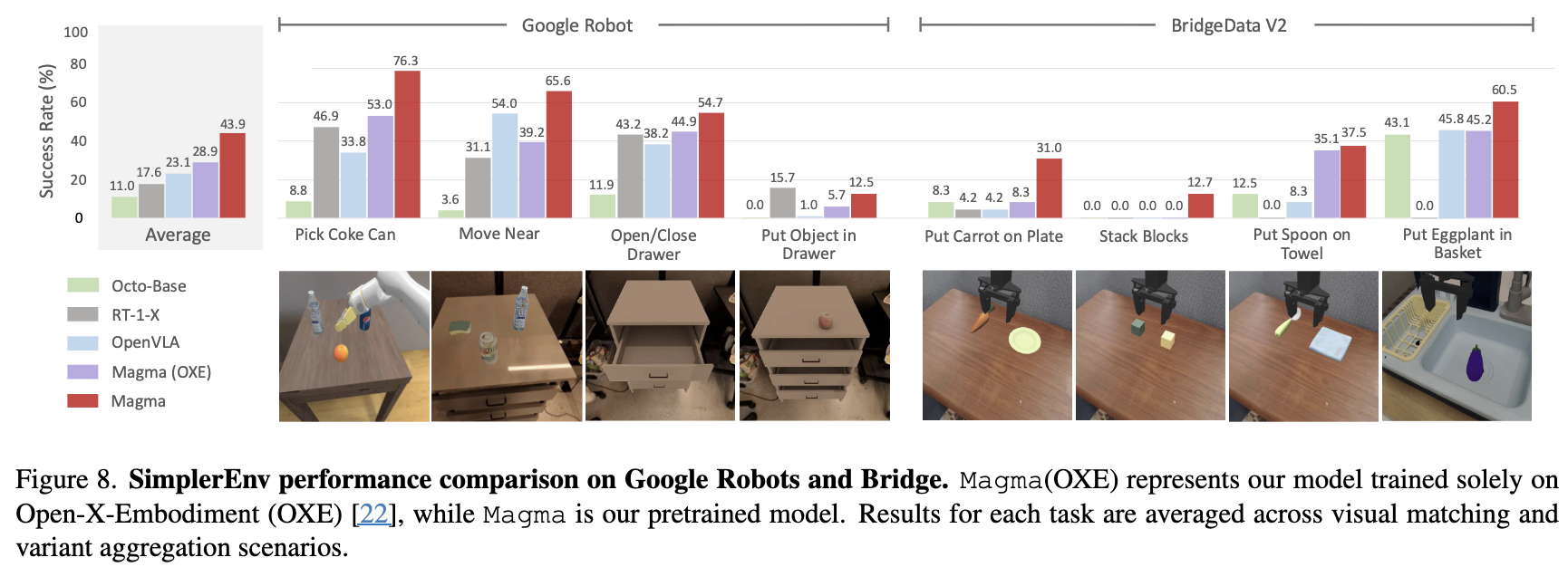
정량적 결과
-
정성적 결과


-
Ablation Studies
-
Video dataset 유/무 & SoM/ToM 유무에 따른 성능 분석
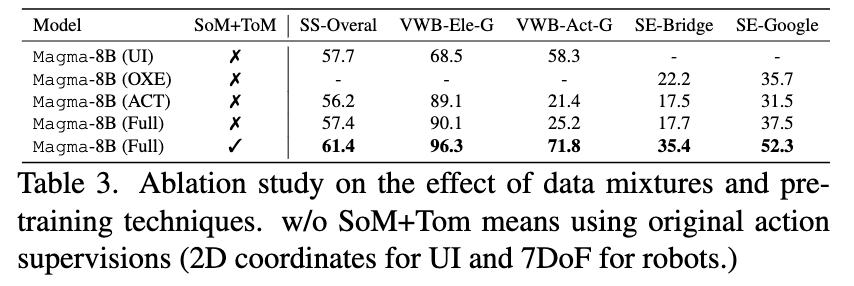
-
Efficient Finetuning
-
pretraining 이후 downstream별 추가 학습
-
UI Navigation
-
Mind2Web
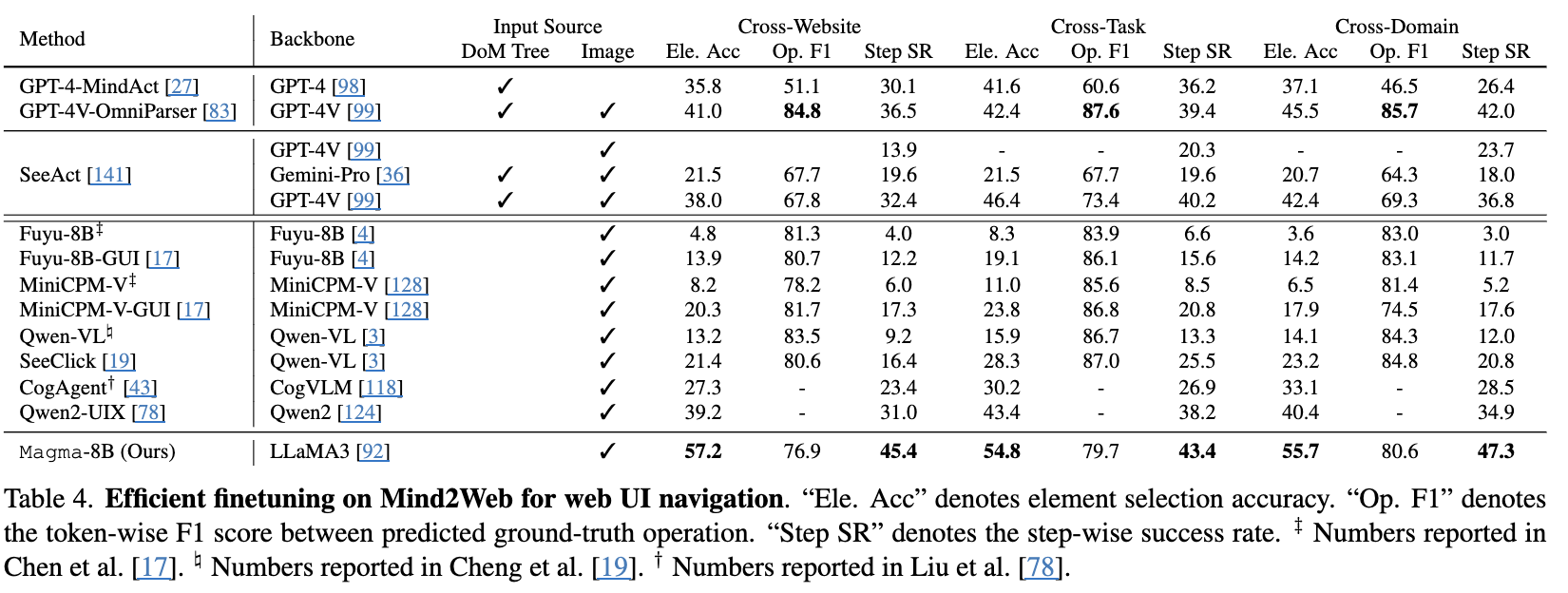
-
AITW
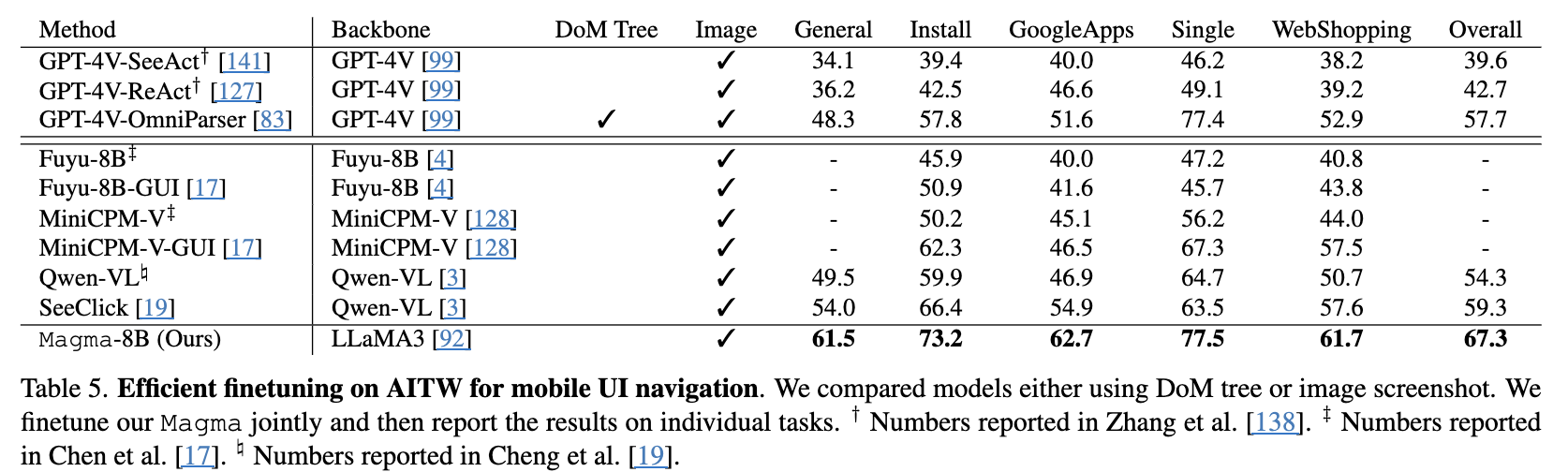
-
-
Robot Manipulation
-
OpenVLA
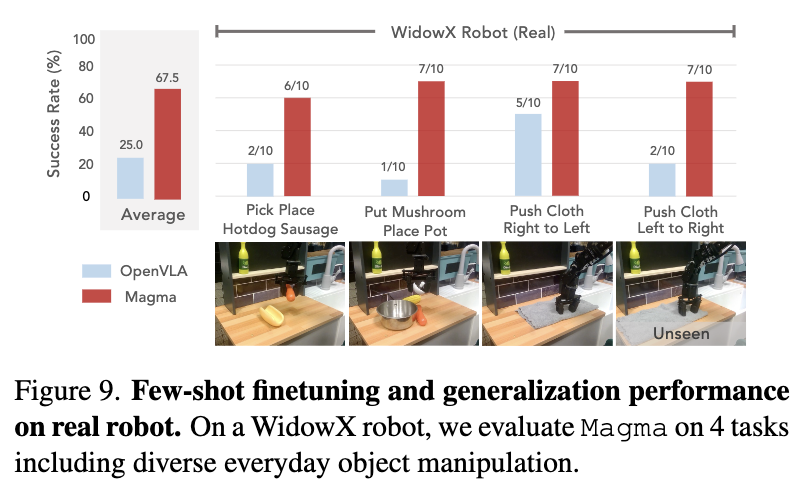
-
LIBERO
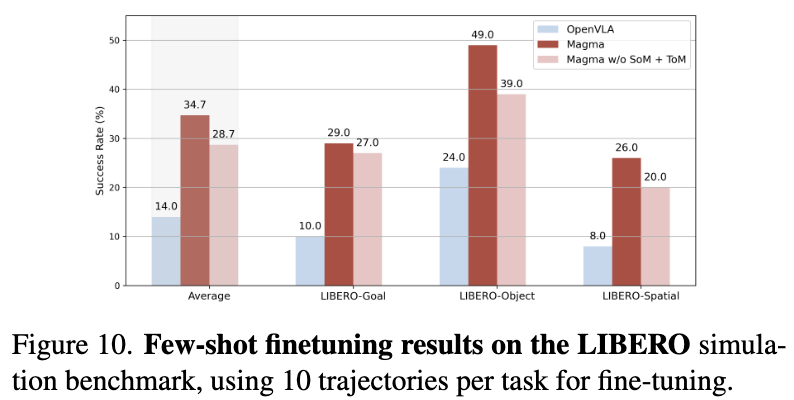
-
-
Spatial Reasoning
-
정량적 결과
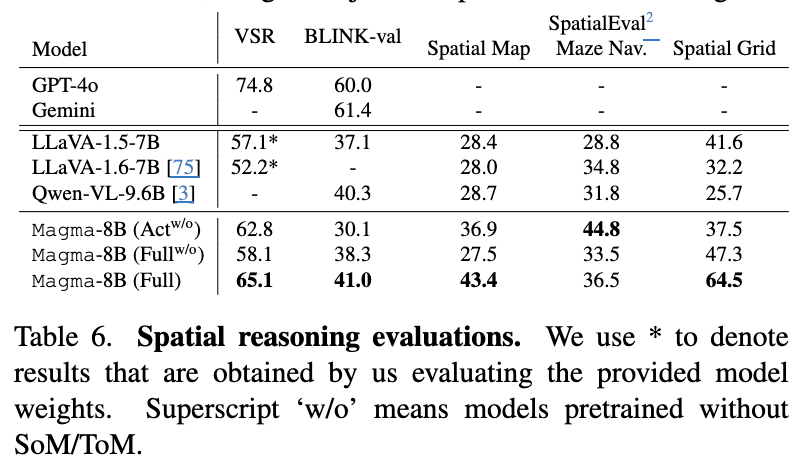
-
정성적 결과

-
-
Multimodal Understanding
-
Image
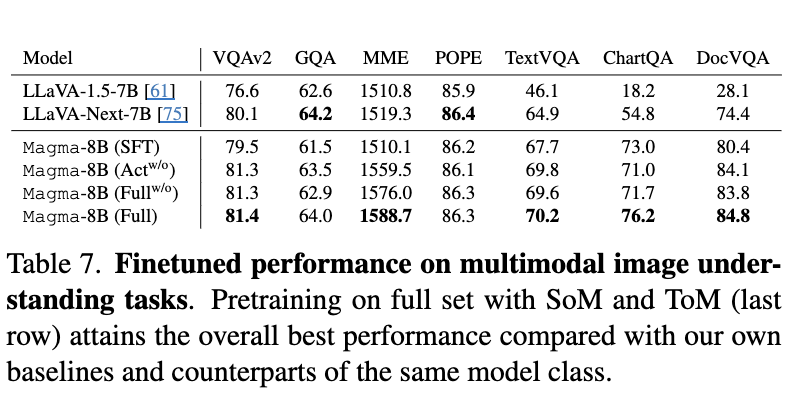
-
Video
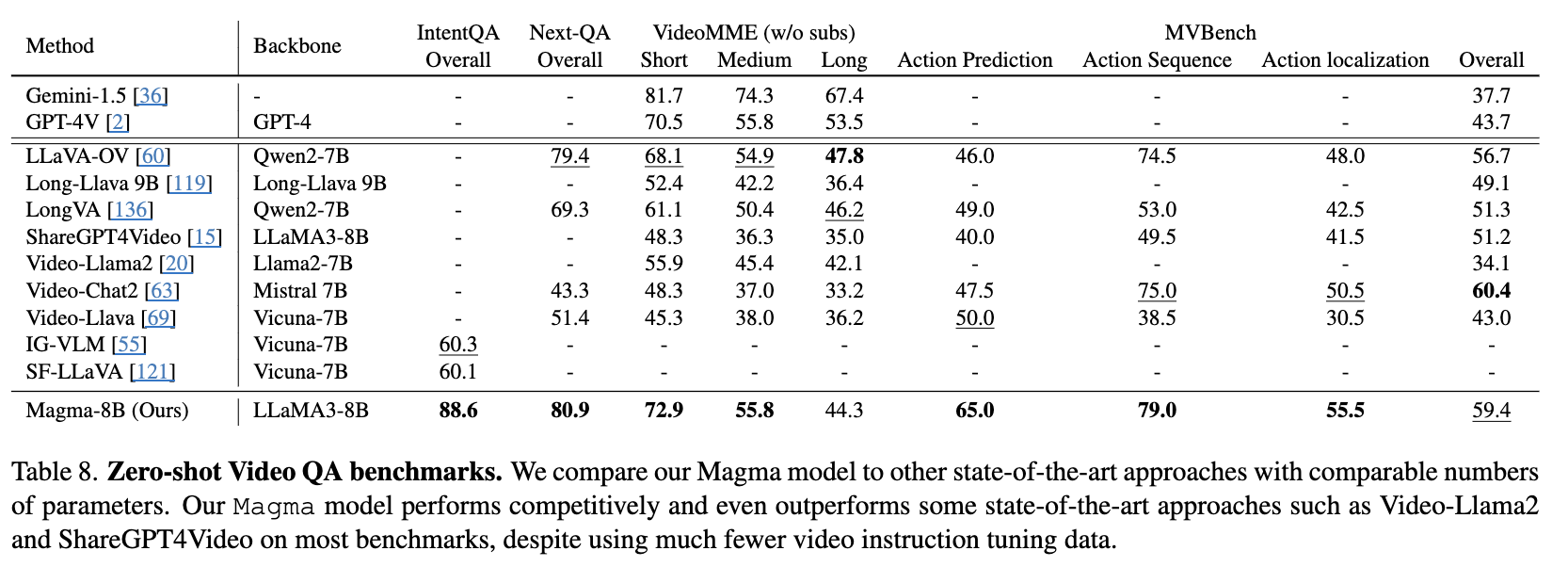
-
-
-