[cTTA][CLS] MECTA: Memory-Economic Continual Test-time Adaptation
[cTTA][CLS] MECTA: Memory-Economic Continual Test-time Adaptation
-
paper: https://openreview.net/pdf?id=N92hjSf5NNh
-
Published on ICLR 2023 (인용수 : 8회, ‘23.10.04 기준)
-
downstream task : Continual Test-time Adaptation (CTA) for Classification
-
Contribution
-
Memory efficient한 CTA task를 제안함 (Practical) → Batch-norm의 affine parameter만 update하는건 Tent와 동일
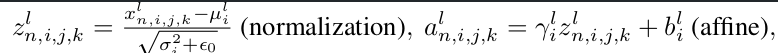
-
MECTA (Memory-Efficient Continual Test-time Adaptation) norm 을 제안함
-
CIFAR10-C / CIFAR100-C / ImageNet-C에서 좋은 성능을 냄
-
-
Overall Diagram
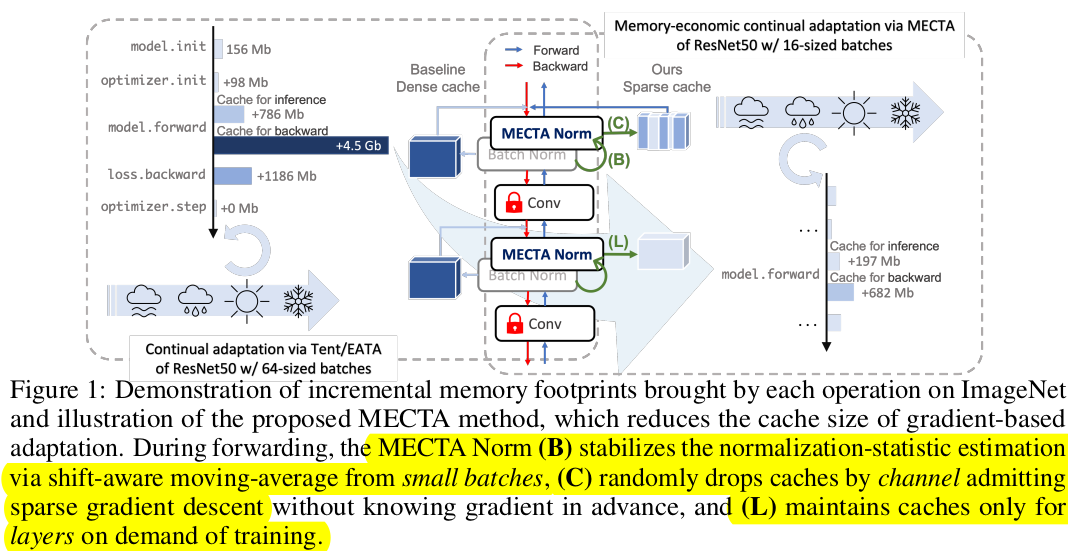
- Batch dimension : Batch statistics를 계산하기 위해 필요한 Large Batch 제약조건을 없애기 위해 EMA 사용
- Channel dimension :
- Forward-pass는 보존하되 (under-fitting issue)
- Backward-pass에서 (Gradient scale에 상관없이) Stochastic pruning 적용
- Layer dimension
- Domain Shift가 큰 경우에만 Backward process 적용
-
BatchNorm의 learning parameter Memory usage
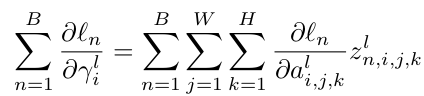
-
$\gamma_i^l$을 업데이트 하기 위해 $dl_n/da_{i,j,k}^l$을 계산하기 전까지 $z_{n,i,j,k}^l$을 caching하고 있어야 함.
-
Res50기준 5배 소요됨

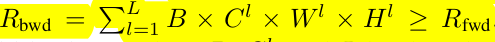
-
단순한 방법은 B,$ C^l$, L을 $z^l$에서 줄이는 것 → underfitting issue
-
-
Proposed Method
-
Batch-Dimension
-
Batch 의 통계치를 계산하기 위해 Large Batch가 요구됨
-
EMA를 업데이트함 → Streamed-Batch의 통계치를 암기하는 효과
-
EMA의 hyper-parameter beta를 dynamic하게 조정 → forget gate 역할
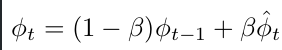
-
이전 step과 gap이 클수록 forget 비율을 높임 (vice-versa)
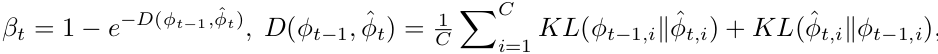
-
layer-by-layer로 beta를 계산함
-
-
-
Channel-Dimension
- OOD generalization을 위해 꼭 필요한 channel이 무엇인지 알지 못함 → Stochastic하게 pruning을 iteration을 돌며 진행
- 효과
- forward-pass는 기존과 동일하므로, inference result에 영향이 없음
- memory usage를 획기적으로 줄일 수 있음
- SGD / Adam 같은 modern Optimizer를 사용하면, missing gradient를 전가할 수 있음
- parameter 의 일부 subset만 학습되므로, catastrophic forgetting도 방지
-
Layer-wise
- domain shift가 크게 발생한 경우만 backprop진행
-
Overall Algorithm
