Learn-by-Interact: A Data-Centric Framework for Self-Adaptive Agents in Realistic Environments
[WebAgent] Learn-by-Interact: A Data-Centric Framework for Self-Adaptive Agents in Realistic Environments
- paper: https://arxiv.org/pdf/2501.10893
- github: X
- ICLR 2025 accpeted (인용수: 20회, ‘25-07-06 기준)
- downstream tasks: Web Automation / Code Automation / Code Automation
1. Motivation
-
LLM agent의 발전은 인간의 digital tasks를 보조하는데 괄목한 결과가 있어왔다.
- 이미지 편집, 데이터 분석, software engineering 이슈 해결, commercial platform navigation, etc
-
하지만, 고품질의 agent data의 부재로, 제약이 있어 왔다.
$\to$ human annotation 없이도, 주어진 환경에 적응하는 LLM framework를 제안해보자!
2. Contribution
-
환경에 대한 documentation만 참고하여, agent-environement interaction에 대한 new instruction을 생성하는 backward construction 방식을 제안함
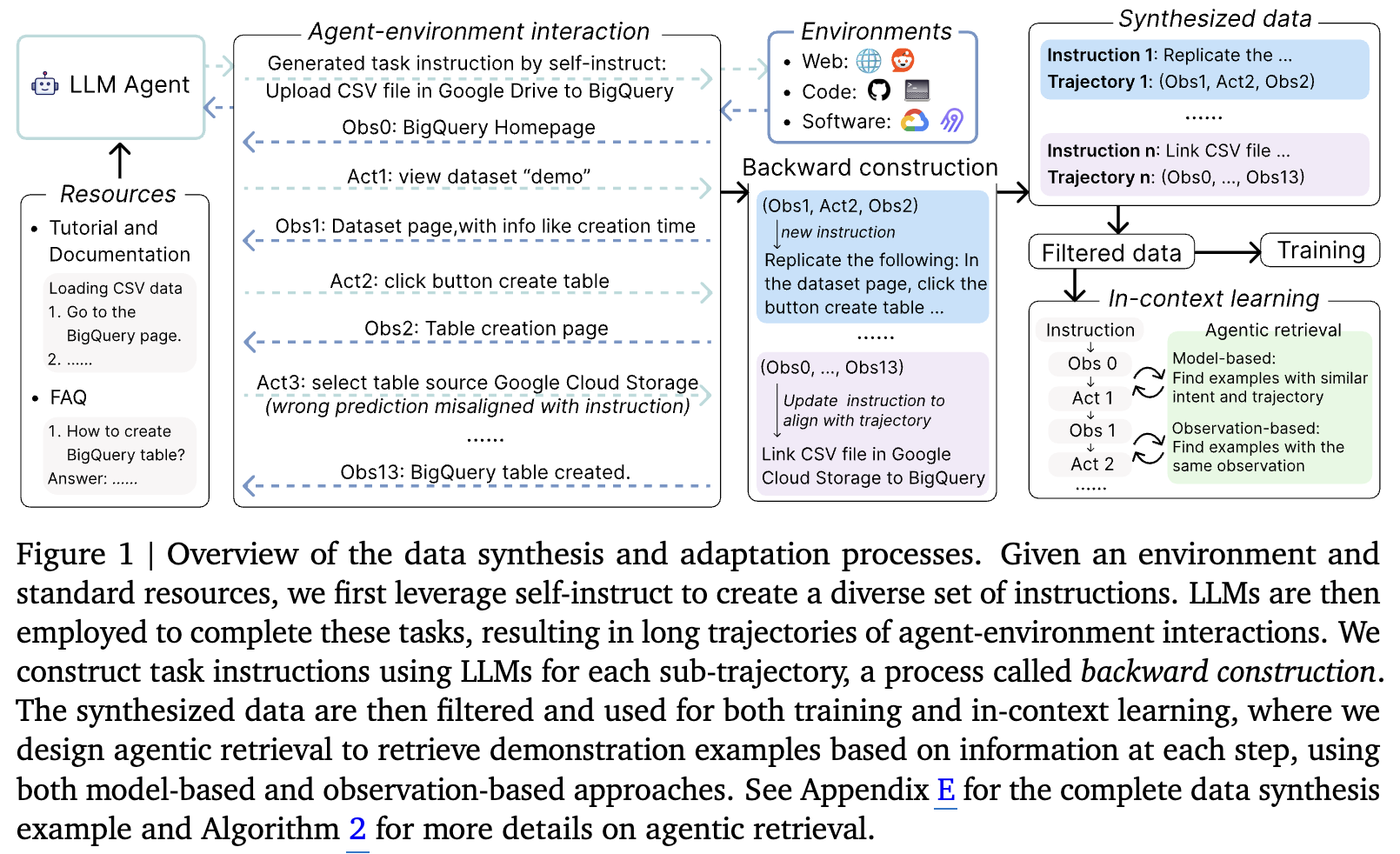
- Action이 환경에 미친 영향 (ex. 화면 이동)이 정보를 제공한다는 것에서 착안하여, 해당 환경에 대한 튜토리얼 / 문서를 통해 다양한 task instructions를 생성하기 위해 self-instruct를 사용함
- 초기 LLM이 해당 tutorial에 대한 결과가 안좋으므로, LLM의 요약 능력을 사용하여 backward construction을 진행 (주어진 action trajectory에 instruction을 transform 시킴)
-
Training-based / Training-free (In-Context-Learning) 방식에서 제안한 synthetic data generation이 성능에 도움이 됨을 입증
- web (webarena), code (SWE-Bench), desktop (OSWorld)
- ICL / Training에 해당 paired data를 활용하여 혁신적인 retrieval pipeline을 제안하여 다양한 tasks에서 성능이 향상됨
- 다양한 task 성능
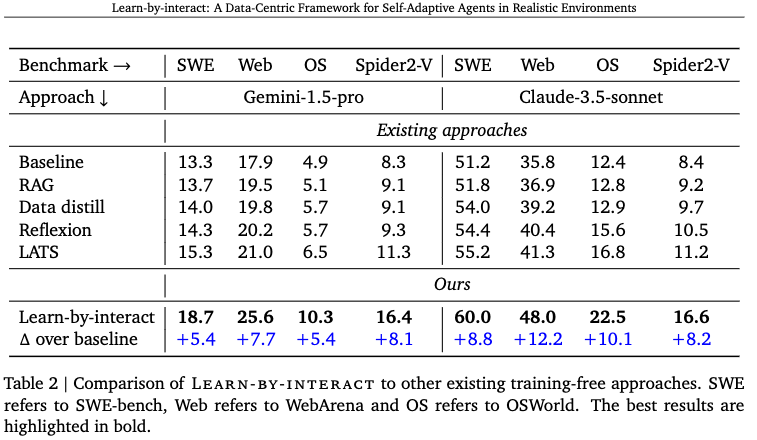
- Claud-3.5-sonnet (ICL): OSWorld 12.4% $\to$ 22.5%
- Codestral-22B (Training): WebArena 4.7% $\to$ 24.2%
- 다양한 task 성능
-
새로운 retrieval 방식 제안
-
retrieval pipeline
-
model-based approach: LLM이 instructions, interaction histories, 현재 observation을 토대로 요약된 query를 생성함. 해당 query는 retrieval model은 query를 통해 적절한 example을 검색함
-
Dense Retriever로는 google의 text embedding을 활용
https://cloud.google.com/vertex-ai/generative-ai/docs/embeddings/get-text-embeddings
-
-
observation-based approach: 현재 observation이 생성한 trajectories 중에 존재하는 examples를 검색함
-
-
3. Learn-by-Interact
- Agent data를 생성하는 LEARN-BY-INTERACT framework를 제안함
3.1 Agentic data synthesis
-
Algorithm

-
line 5: self-instruction을 통해 new instruction을 생성함
-
self-instruct: Tutorial, Documentation 등의 환경 문서를 통해 LLM이 다양한 작업 지시 (instruction)을 생성을 자동화하는 방법
$\to$ 대부분의 환경문서는 사용자들에게 유용한 정보를 제공하므로, 비효율적인 지시사항을 방지하는 효과가 있음
-
-
line 9~14: long trajectory 생성
- self-instruct로 생성한 instruction I에 대해 LLM이 예측한 action (a) & observation (o) pair를 추출하는 과정.
-
line 15~22: backward-construction을 통해 unpaired (I, a, o) $\to$ paired (I’, a, o)를 생성하는 과정
- line 9~14의 LLM은 해당 task에 특화된 모델이 아니다 보니, 틀릴 수가 있음.
- action & observation은 그대로 두고, instruction만 고치는 방향으로 update
- 각각의 sub-trajectory별로 2가지 새로운 instruciton을 생성
- trajectory steps의 요약 결과
- trajectory의 목적 추출
- input: $(Obs1, Act2, Obs2)$
- output: $Act2$가 출력되기 위해 필요한 instruction I’
- 무엇을 해결하는가?
- Instruction과 예측된 trajectories의 misalignment
- 생성된 trajectory의 utility를 향상함 (학습에 / RAG에 활용함으로써)
3.2 Filtering
-
생성된 데이터의 품질을 향상시키기 위해 도입함
-
중복되는 states는 제거 $(a_i, o_i) = (a_{i-1}, o_{i-1})$
-
LLM committee check
-
instruciton-trajectory pair를 여러 LLM에 넣고, 만장일치로 해당 pair가 연관되었고, 자연스러우며, reasonable하며, instruction과 정렬되었다고고 하지 않으면 필터링
-
prompt

-
-
3.3 Adaptation
-
생성된 데이터는 ICL & training에 활용
-
Multi-round interaction의 특성을 반영한 새로운 agentic retrieval을 제안함
 **
**-
line 6: observation-based retrieval
-
현재 관측 결과 (o)가 example의 sub-trajectory에 포함되었으면, 도움이 되는 example이라 판단하여 검색해옴
즉, *o=$o_i$ for i in range (0, n)인 $i$가 $e=[I’, [o_0,a_1,o_1, …, o_n,a_n]]$ 중에 있으면 검색해옴
-
-
line 8~9: model-based retrieval
-
$m_1=5, m_2=5$: upper-bound retrieval 갯수
-
LLM이 instruction I, Trajectories H, observation o를 기반으로 query(new instruction)를 생성
-
write query prompt (line 8)

-
external knowledge가 없을때 prompt (line 9)

-
external knowledge가 있을때 prompt (line 9)

-
-
생성된 query q까지 추가해서 Dense Retrieval Model에게 example이 검색
-
-
-
4. Experiments
4.1 Baselines
-
Prompt-based 방식
-
Instruction I, interaction history H, state observation o를 사용한 vanilla prompt
-
SWEBench: CodeAct (Accessibility Tree)
-
WebArena: WorkArena (Accessibility Tree)
-
OSWorld(Accessibility Tree) & Spider2-V (Set-of-Mark): Benchmark에서 제안한 prompt
-
Spider2-V의 경우, accessibility tree를 사용하면 많은 정보가 손실되어 SoM을 사용

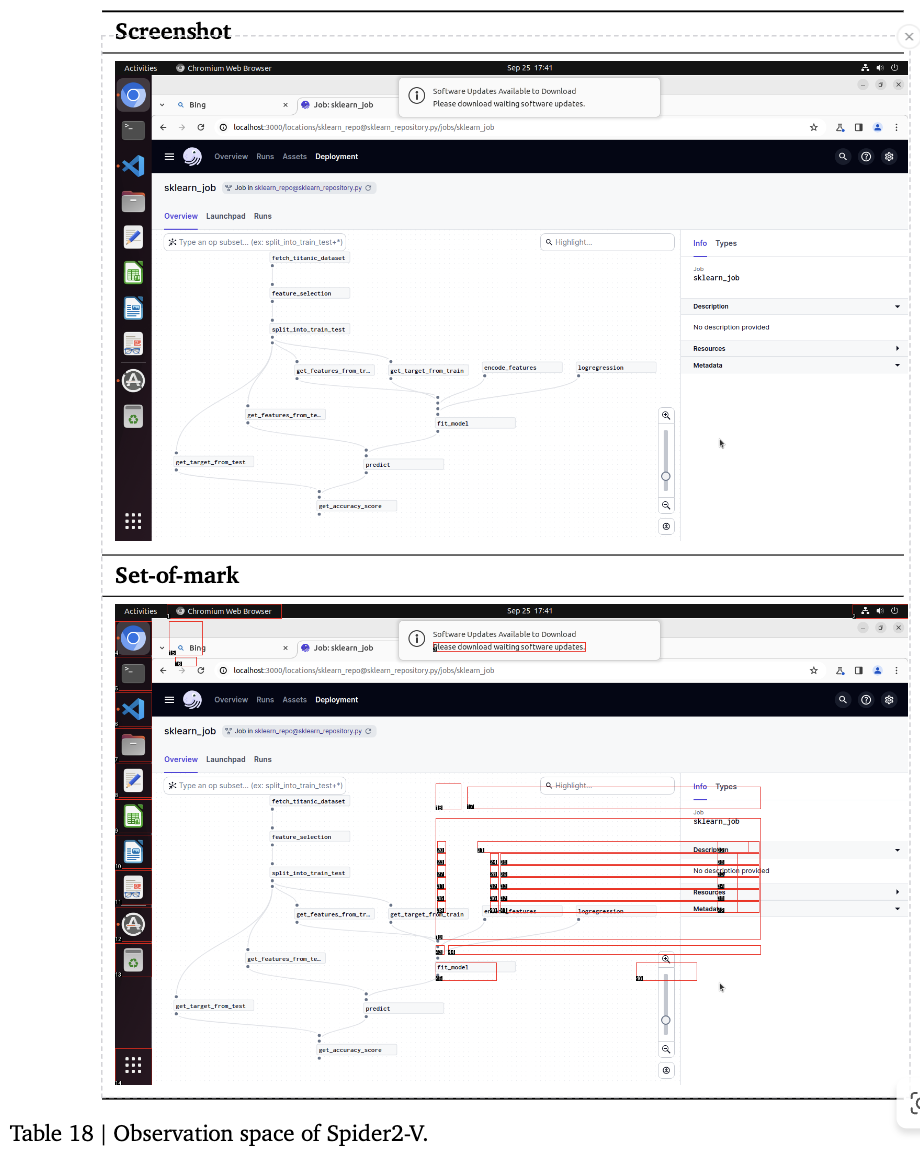
-
-
-
RAG: conventional RAG처럼 instruction 기반으로 document에서 document를 추출하여 LLM에 augment하는 방식
- upper-bound for Retreival: 50 documents or maximum length of LLMs
-
Data Distill: back-construciton을 제외한 algorithm 1 pipeline으로 data synthesize + algorithm 2 (agentic retrieval)한 방식
-
Reflexion: exector & LLM에게 언어적 feedback을 받는 방식
- maximum trials: 3번
-
Language Agent Tree Search (LATS): ReACT의 진화된 버전으로, Online으로 reasoning, acting, planning을 trajectory 내내 진행한 방식 (paper와 동일한 hyper-parameters 사용)
- generated action의 수: 5번
- depth limit: 15
- value function weight: 0.8
-
-
Training-based 방식
- data-distillation 방식
- pretrained LLM
4.2 Datasets
-
SWE-Bench
-
WebArena
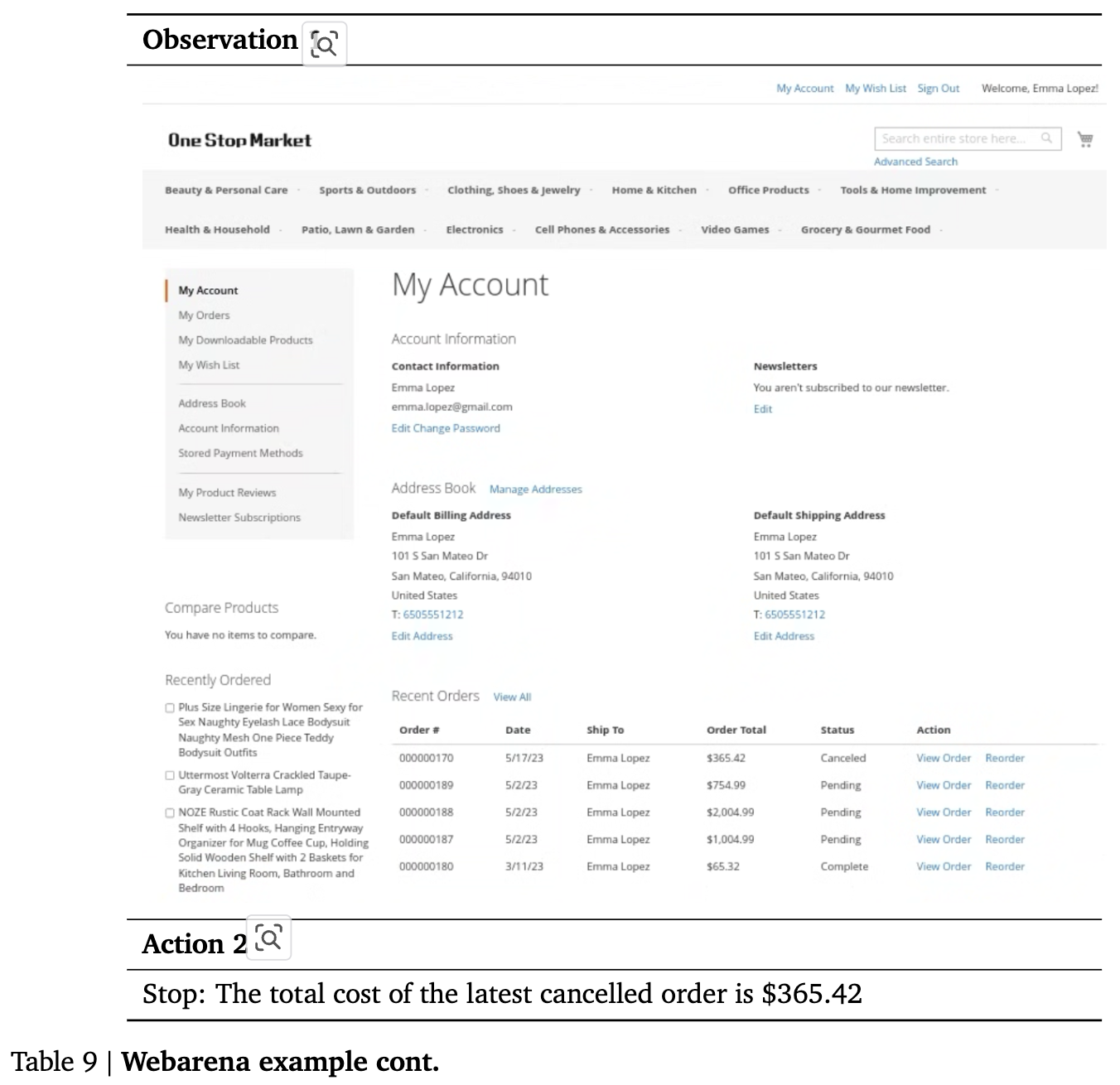
-
OSWorld
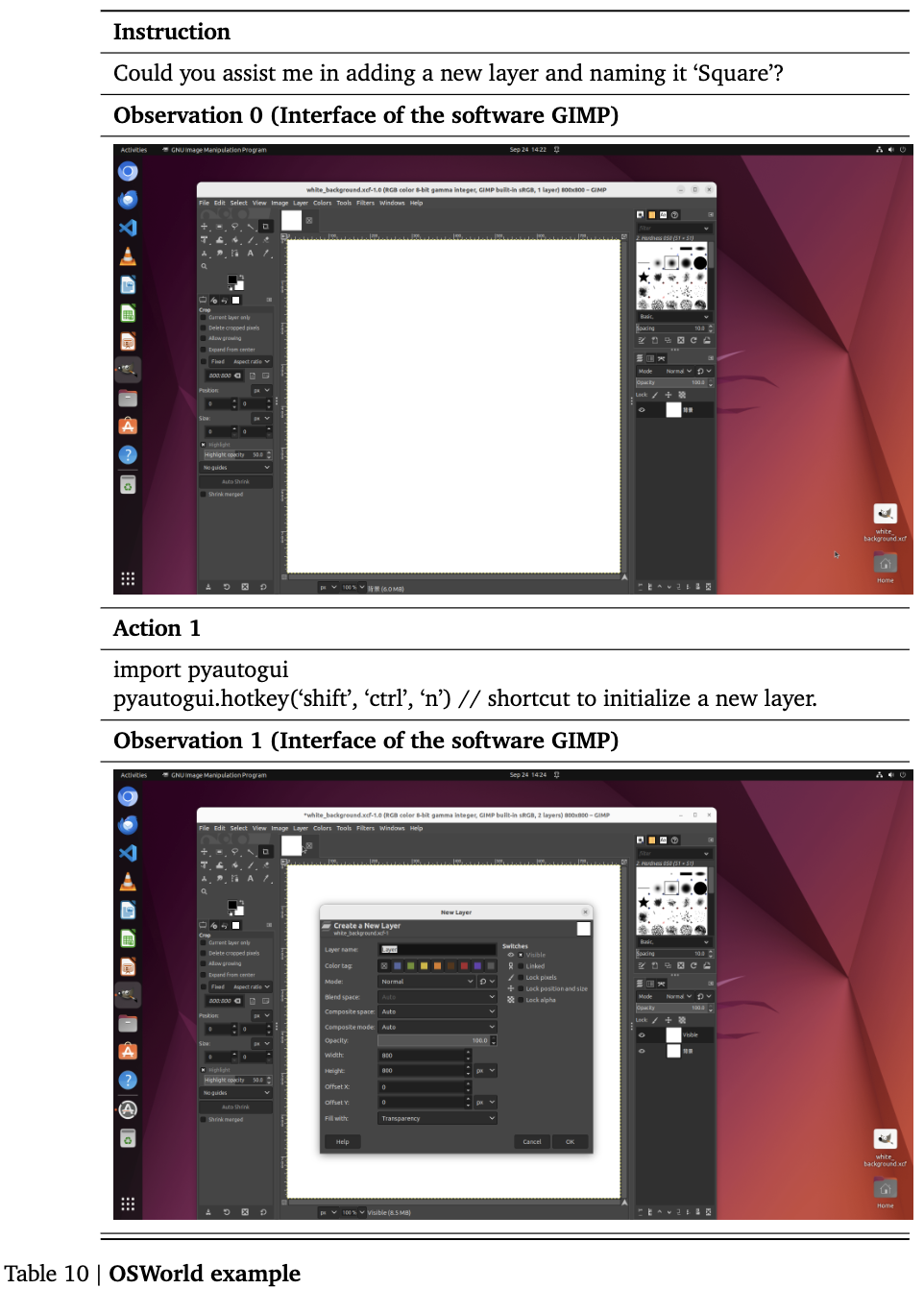
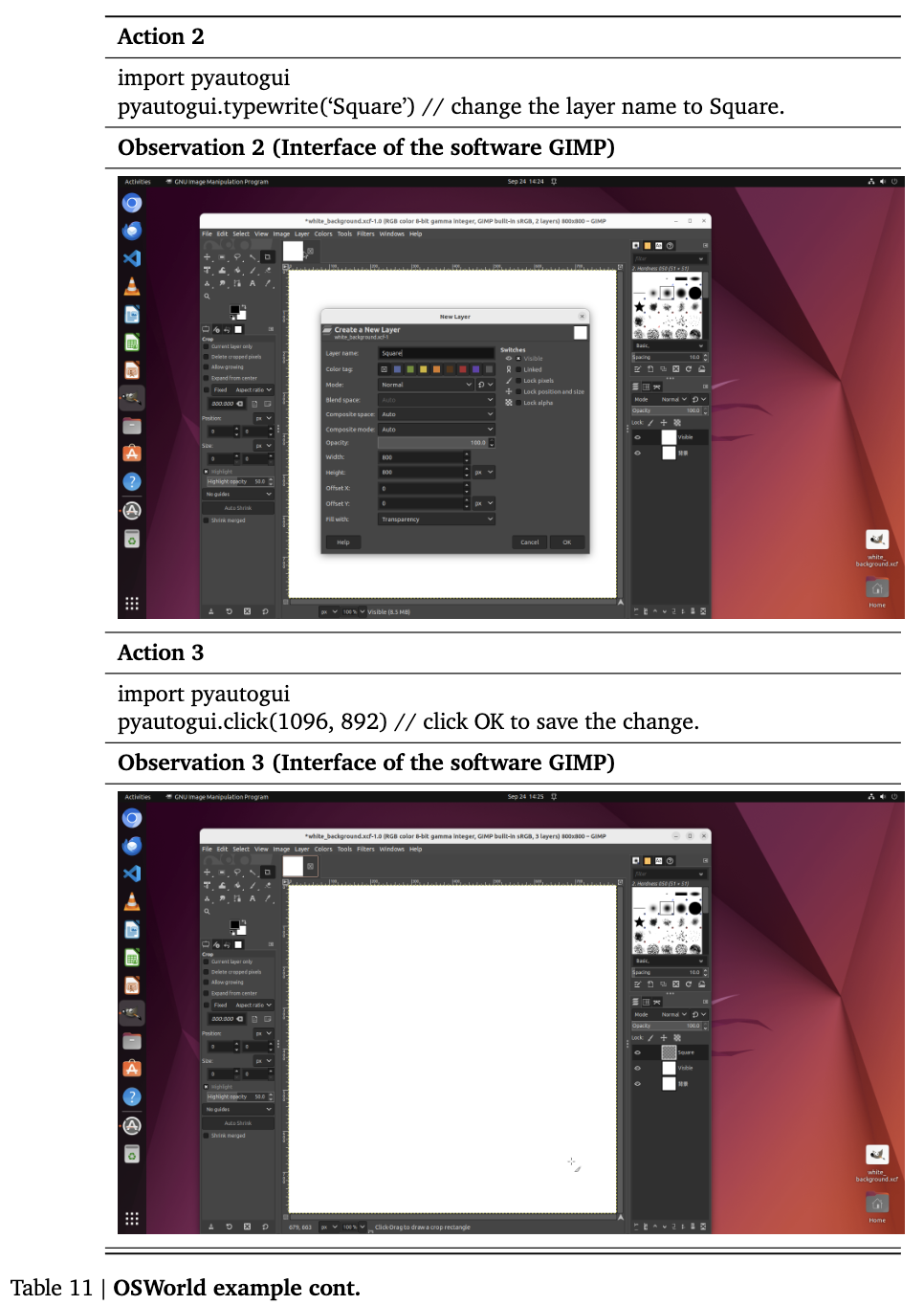
-
Spider2-V: Airbyte, BigQuery와 같은 Engineering workflow benchmark

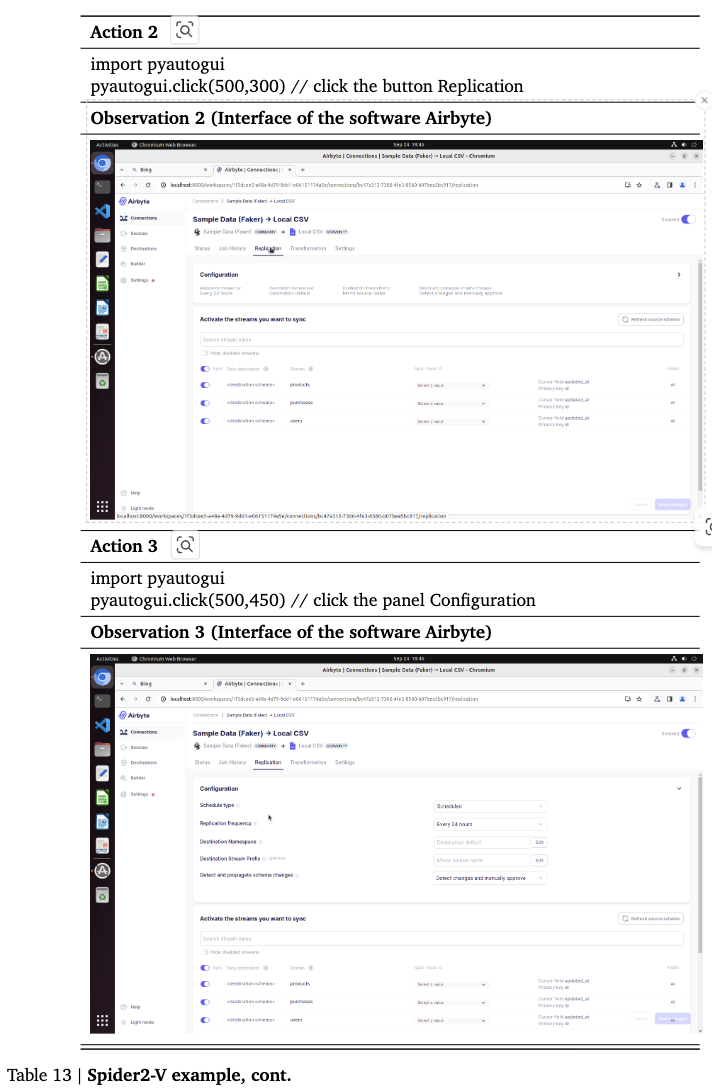
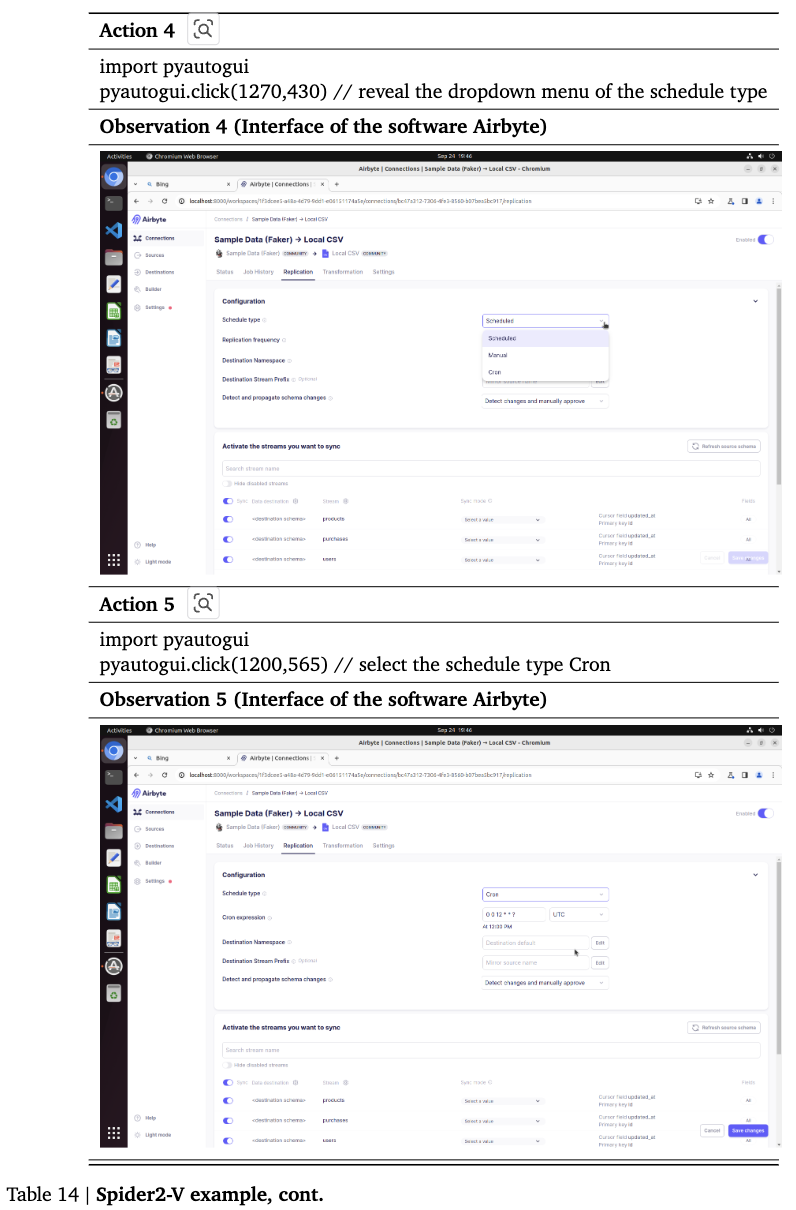
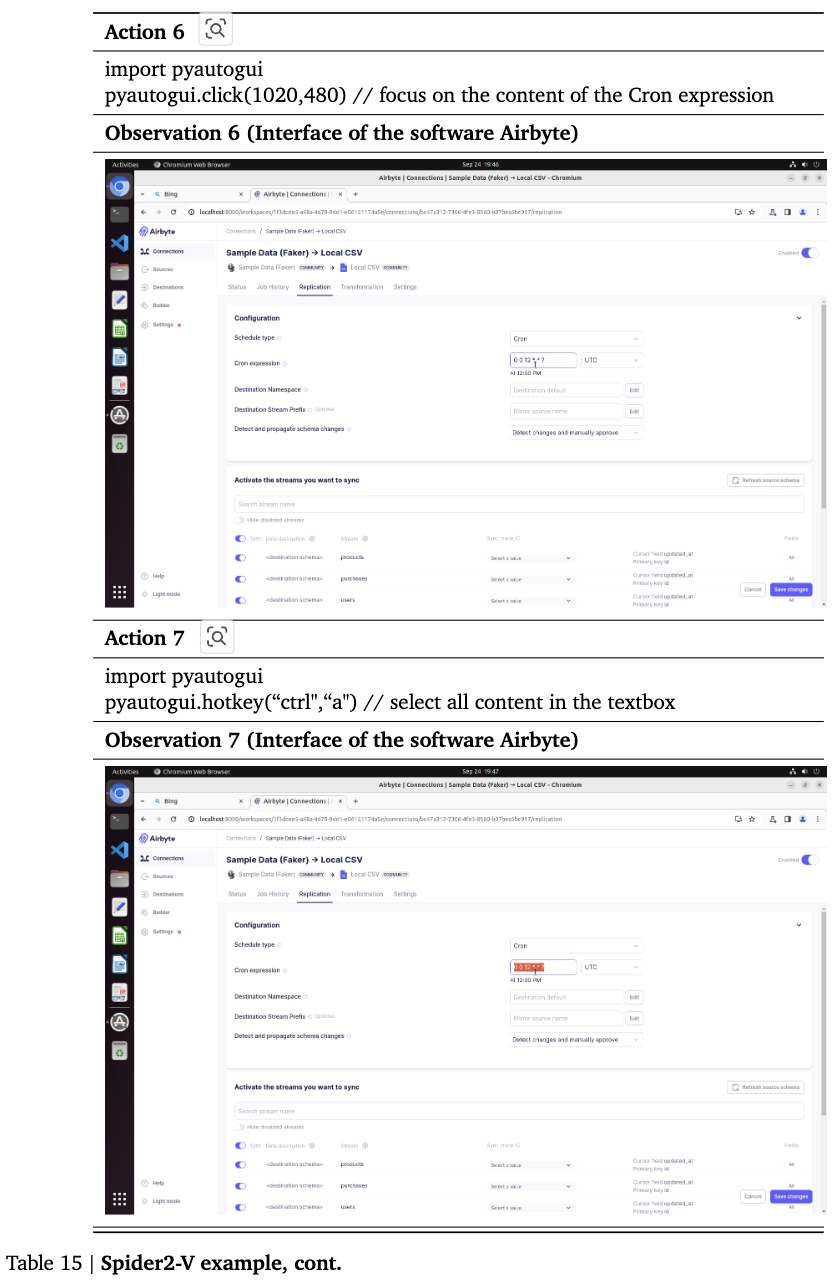
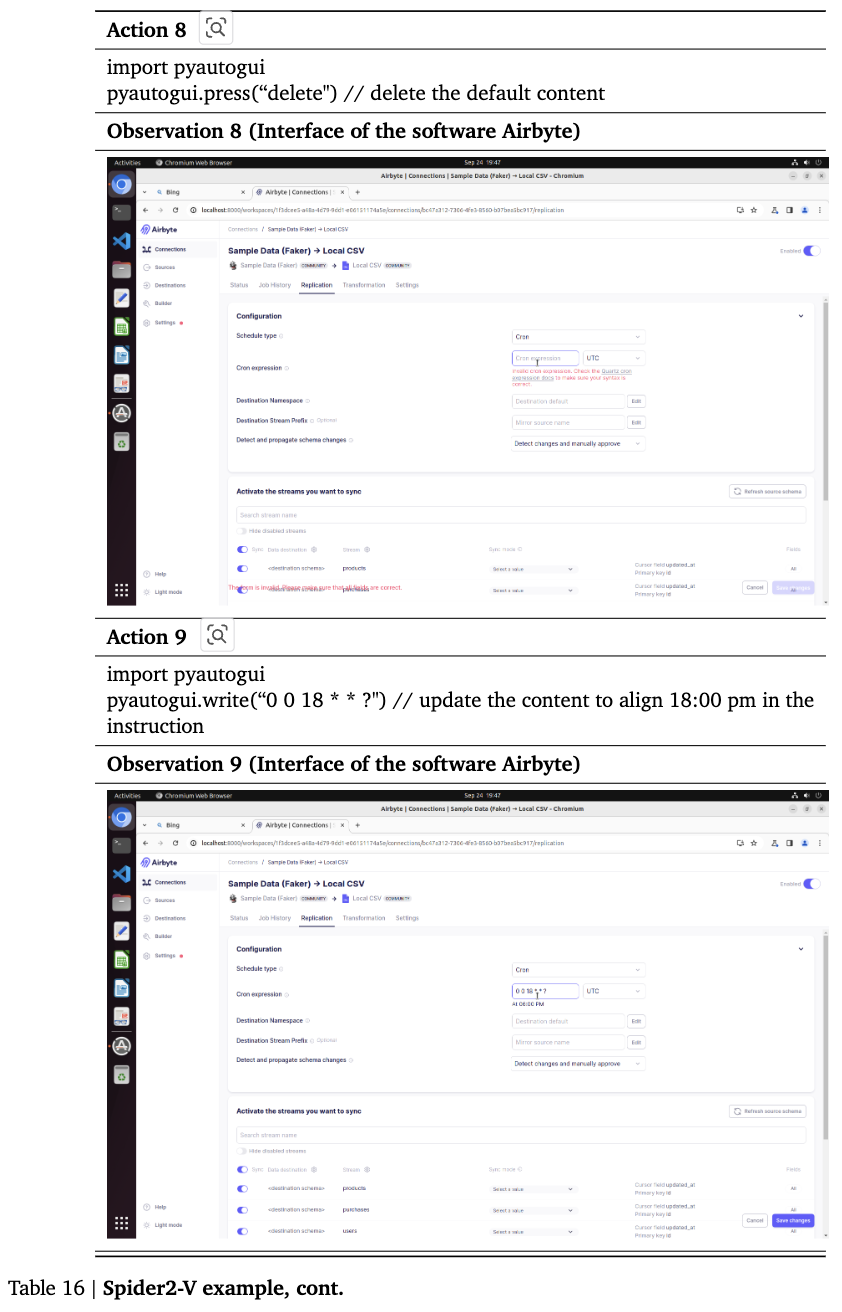
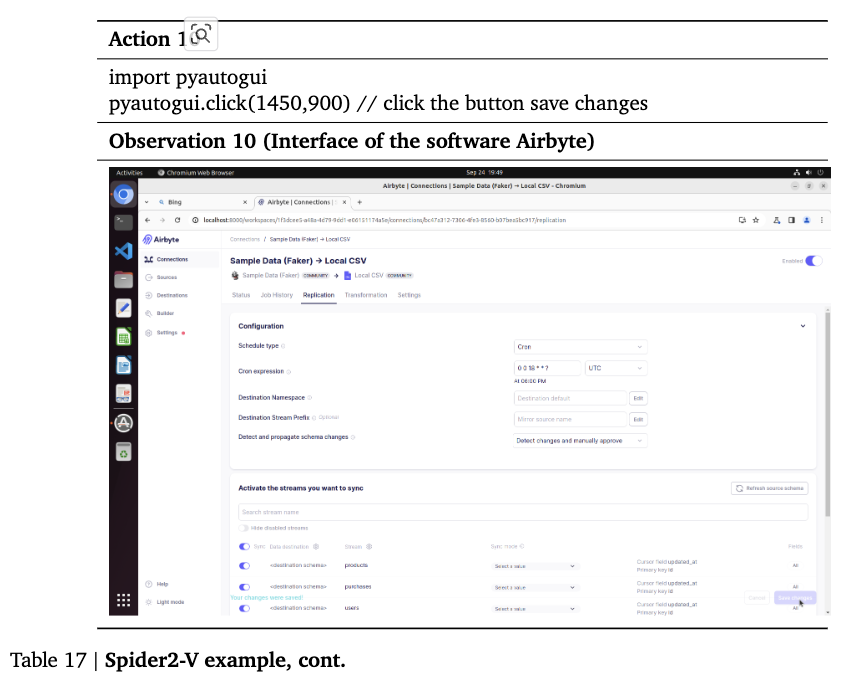
4.3 Settings
-
Data sythesis: Claude-3.5-Sonnet
- document별로 3개의 instruciton을 생성
-
LLM Committee: Claude-3.5-Sonnet, Gemini-1.5-pro
-
Document Sources
-
SWE-Bench
- SWE-bench-Verified benchmark
-
WebArena
• https://docs.gitlab.com/ee/tutorials/ • https://support.google.com/maps • https://www.amazon.com/hz/contact-us/foresight/hubgateway • https://support.reddithelp.com/hc/en-us/articles
-
OSWorld
• https://support.google.com/chrome/?hl=en • https://www.gimp.org/tutorials/ • https://books.libreoffice.org/en/CG72/CG72.html • https://books.libreoffice.org/en/WG73/WG73.html • https://ubuntu.com/tutorials/command-line-for-beginners • https://support.mozilla.org/en-US/products/thunderbird • https://wiki.videolan.org/Documentation:Documentation • https://code.visualstudio.com/docs
-
Spider2-V
• https://docs.getdbt.com/ • https://release-1-7-2.dagster.dagster-docs.io/ • https://docs.astronomer.io/ • https://docs.airbyte.com/ • https://airbyte.com/tutorials/ • https://airbyte-public-api-docs.s3.us-east-2.amazonaws.com/rapidoc-api-docs.html • https://superset.apache.org/docs/ • https://www.metabase.com/docs/v0.49/ • https://www.metabase.com/learn/ • https://docs.snowflake.com/en/ • https://cloud.google.com/bigquery/docs/ • https://jupyterlab.readthedocs.io/en/4.1.x/
-
-
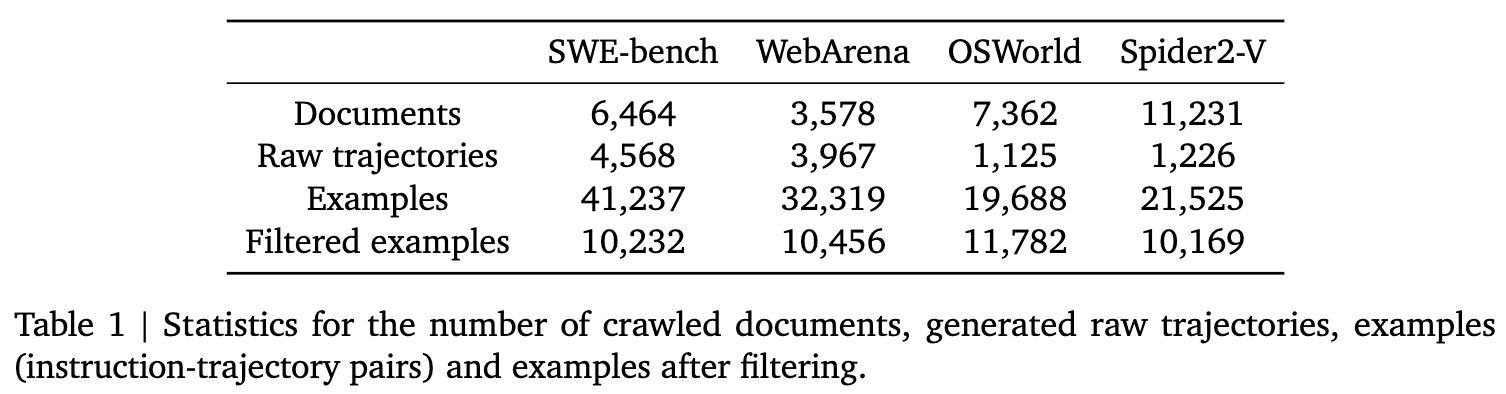
LLM filtering 전후 생성된 데이터 분포
-
Models
- ICL evaluation: Gemini-1.5-pro, Claude-3.5-sonnet, Codegemma-7B, Codestral-22B
- tuning for data quality filtering: Codegemma-7B, Codestral-22B w/ LoRA
-
4.4 Evaluation
- SWE-bench: executaion accuracy (pass@1)
- WebArena: fuzzy-match & string match with Claude-3.5-sonnet 기반의 success rate
- OSWorld: sample-specific evaulation scripts 기반 functional correctness로 평가
- Spider2-V: file-based comparison, information-based validation, execution-based verification
4.5 Results
4.5.1 Training-free Evaluation
-
정량적 결과
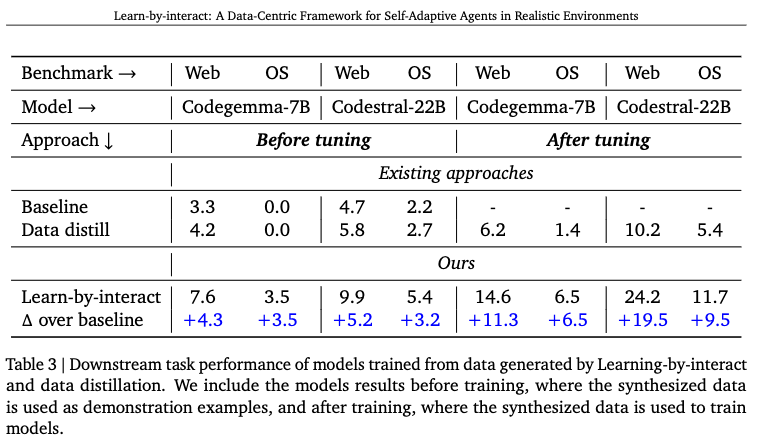
4.5.2 Training-based Evaluation
-
정량적 결과
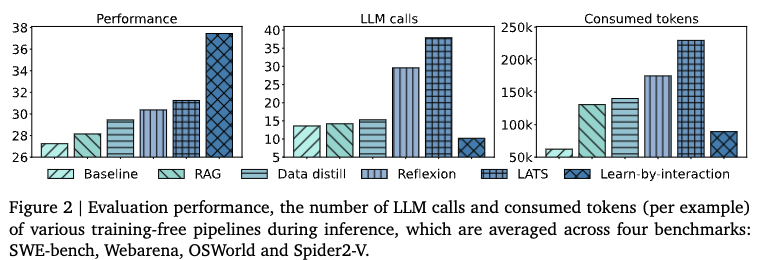
4.5.3 Analysis
-
Inference Efficiency
-
The Impact of Retrieval (ICL-setting): 2가지 retrieval 유/무에 따른 성능 분석 (model-based / observation-based)
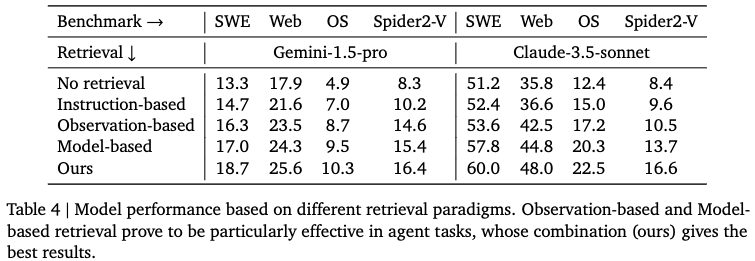
- Instruction-based: conventional RAG 기법으로, instruction 기반의 document retrieval을 의미함.
- Observation-based: observation 기반의 document retrieval을 의미함 (Agentic workflow에 이게 더 도움이 됨)
- Model-based: Instruction + interaction history + current observation 기반의 retireval (이게 제일 좋음)
-
Data granularity
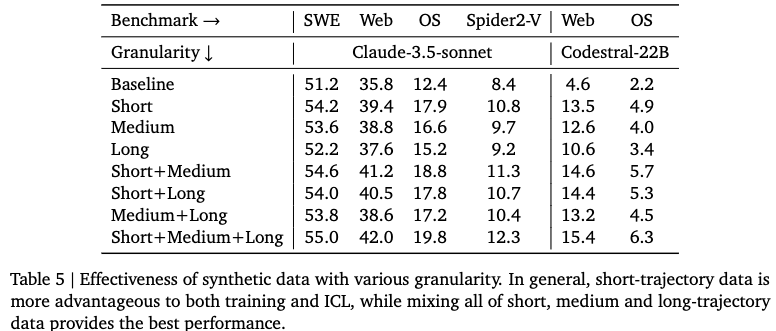
- Data의 trajectory step 수에 따라 3가지 그룹으로 분류
- short: trajectory steps < 5
- medium: 5 $\leq$ trajectory steps < 10
- long: 10 $\leq$ trajectory steps
- 각 그룹별로 섞어 쓰는게 성능에 도움이 됨 $\to$ 다양한 데이터 본연의 특성
- Data의 trajectory step 수에 따라 3가지 그룹으로 분류
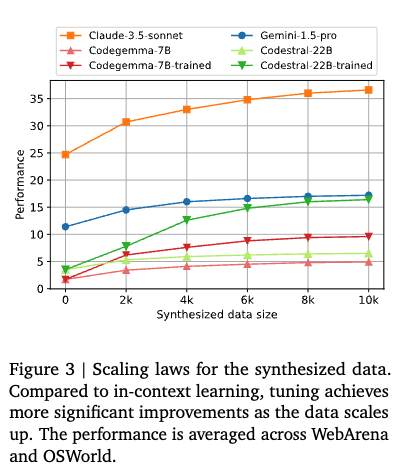
4.5.4 Scaling Laws
-
Synthesized data의 양에 따른 성능 분석