Geine1
[World Model] Genie: Generative Interactive Environments
- paper: https://arxiv.org/pdf/2402.15391
- github: X
- ICLM 2024 best paper award (인용수: 273회, 25-09-10 기준)
- downstream task: Interactive Video Generation (World Model)
1. Motivation
-
Genie 3: 실시간으로 탐색할 수 있는 역동적인 세계 만들기

-
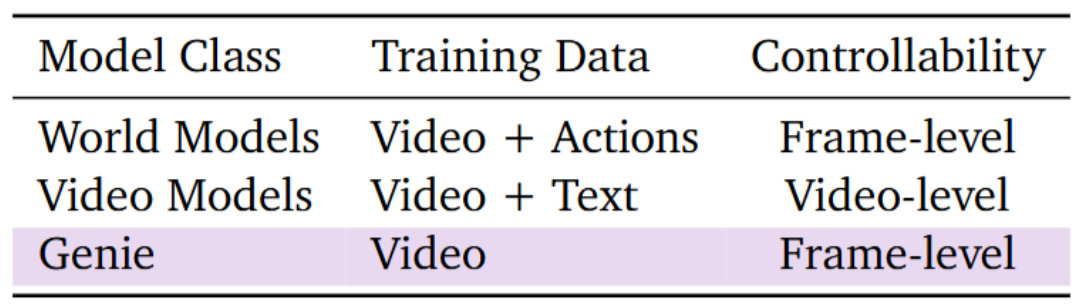
기존에 (Genie 1 당시에) World Model들은 Frame-level / Video-level로 controllable한 video를 생성하기 위해서는 video + action / video + text pair가 있어야 했음
$\to$ Internet video만 단독으로 사용하여 unsupervised training을 통해 frame-level로 controllable한 video를 만들어보자!
2. Contribution
-
Generative Interactive Environment인 Geine 1을 제안함
-
input: (single/multi) text / (single/multi) image
- training data: 200,000 hours video (w/o action, text annotations) $\to$ 30,000 hours video를 필터링하여 학습에 활용

-
model: 11B parameter 모델
-
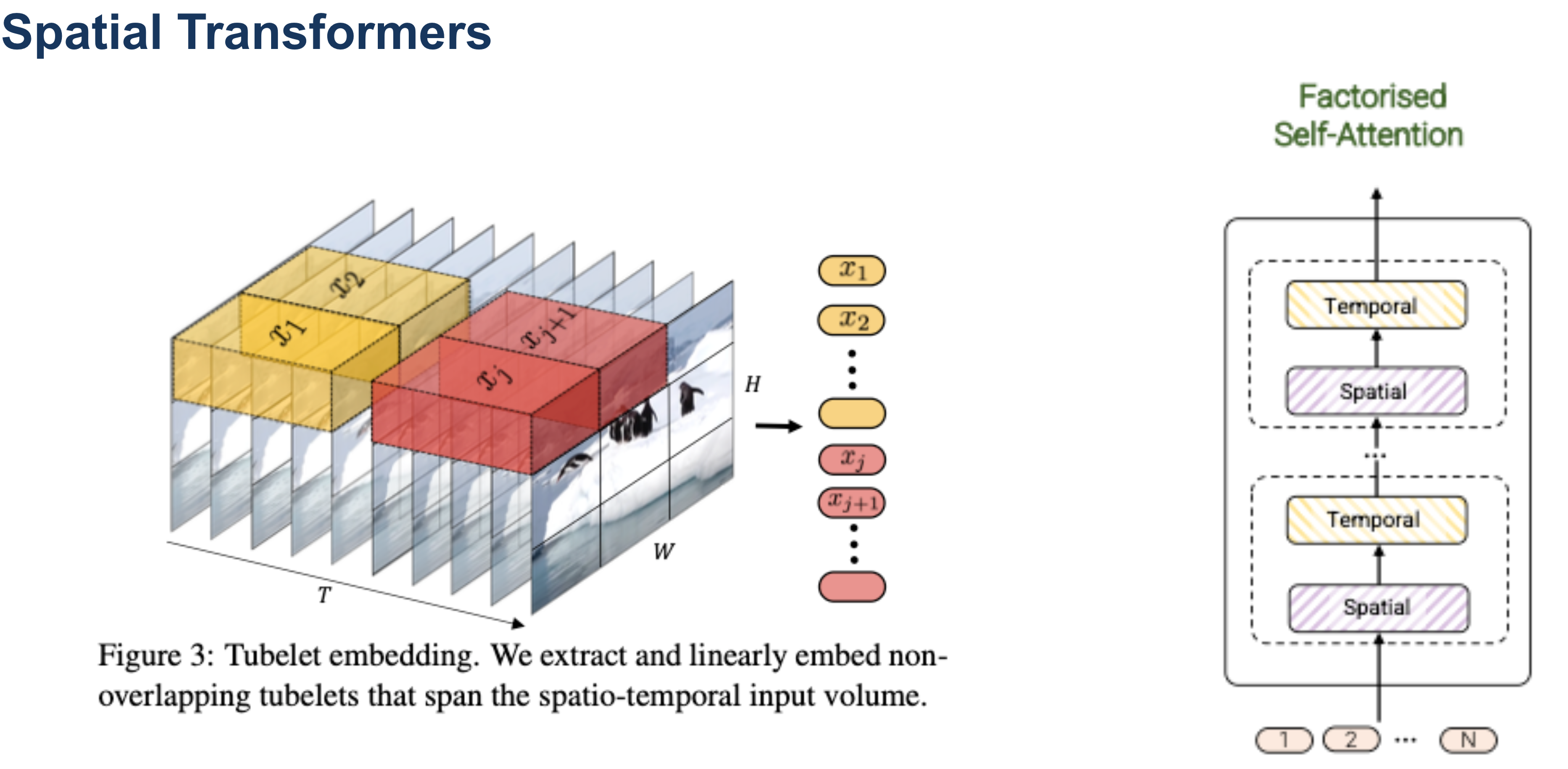
SpatioTemporal Transformers / Tokenizer
-
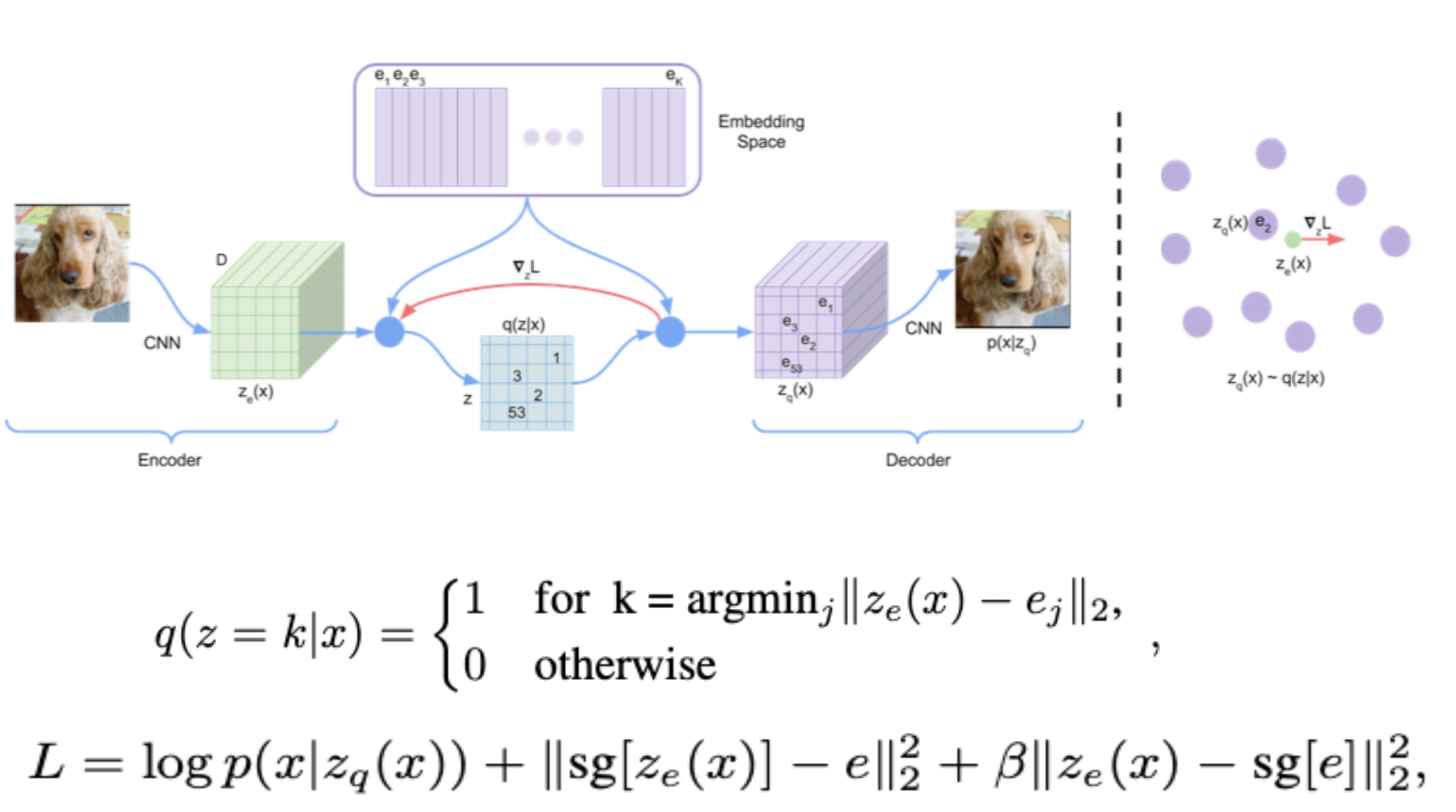
Laten Action Model (LAM) : VQ-VAE 기반
-
Autoregressive dynamics model (GIT)
-
-
Generalibility를 고려하여 robot videos (action-free)에서 별도로 학습 수행하여 제안한 방식의 유효성을 입증
-
3. Genie
-
ST-transformer architecture를 도입 $\to$ frame 수에 따라 제곱에 비례하는 기존 transformers 구조에 비해, 선형으로 증가함 $\to$ 메모리 효율성 증대
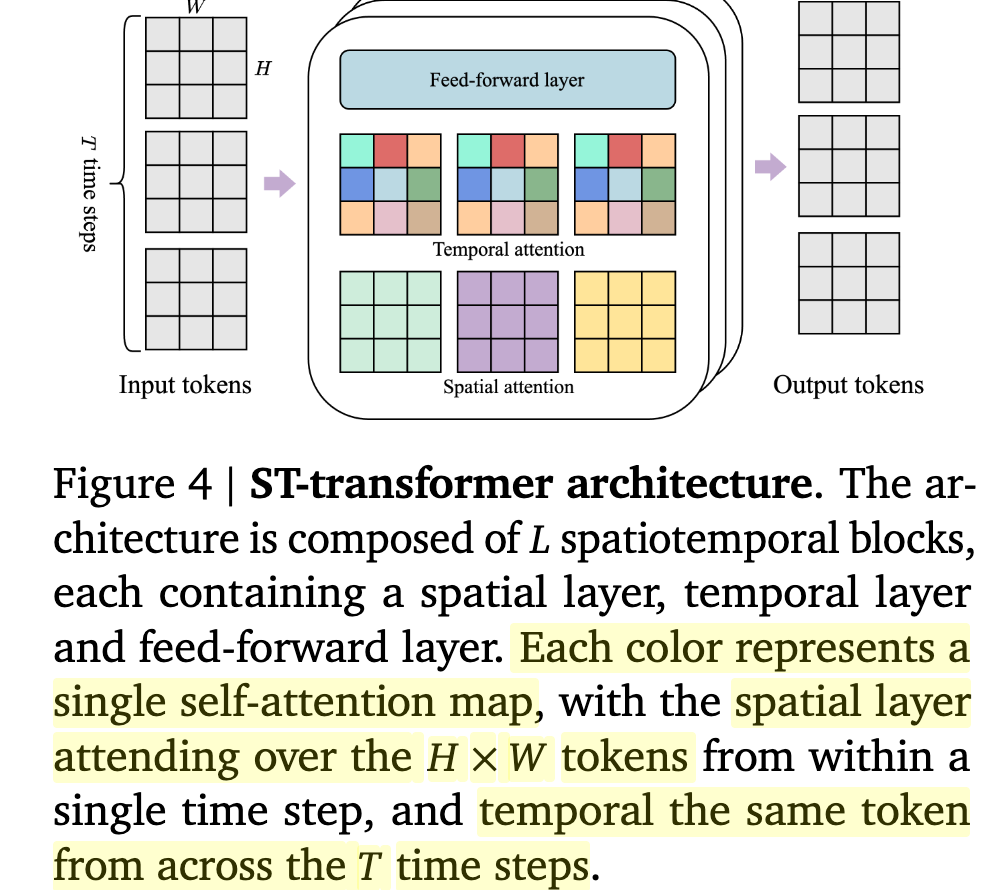
- Spatial attention : $ 1 \times H \times W$
- Temporal attention : $T \times 1 \times 1$
3.1 Model Components
-
Overall Architecture
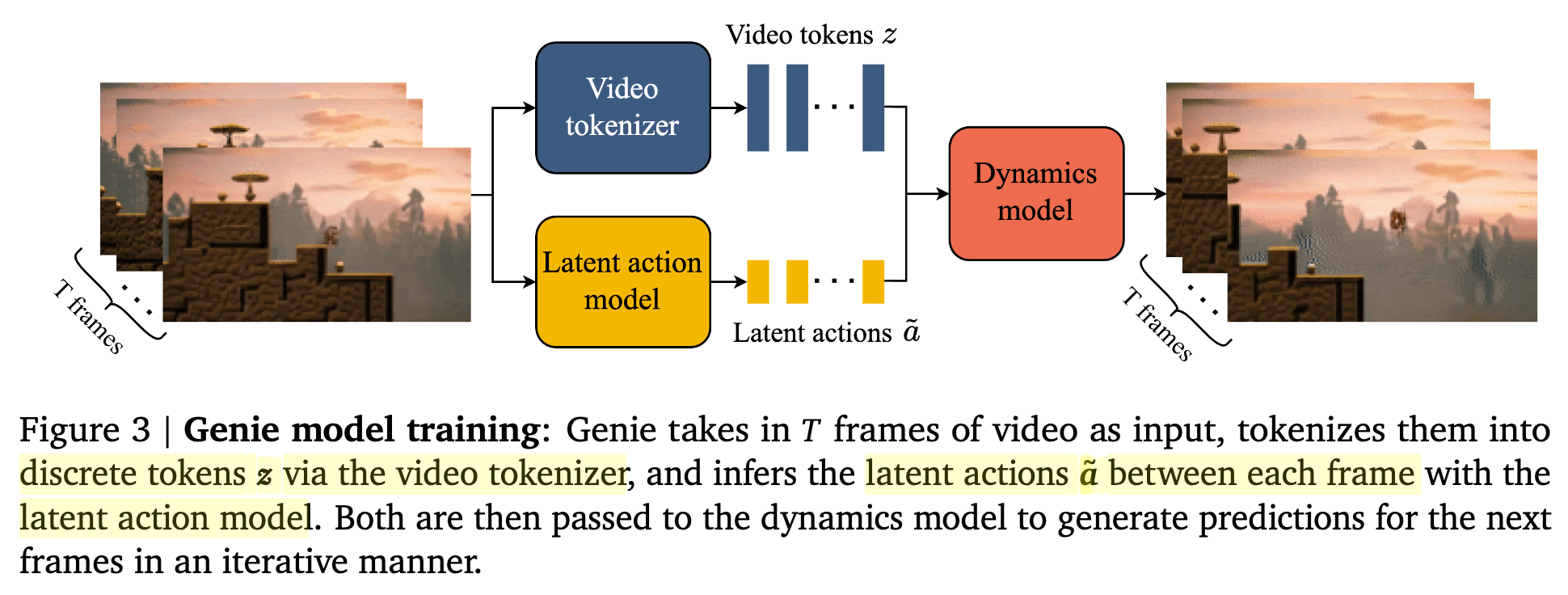
Latent Action Model (LAM)
-
기존에는 next frame prediction을 위해 previous frames + action을 입력받음
-
하지만, action이 pair로 존재하는 video는 구하기 어려움
-
대신, latent actions을 unsupervised manner로 학습함으로 이를 극복함
-
300M parameters / patch-size 16 / codebook embedding 32 / 8 unique codebooks
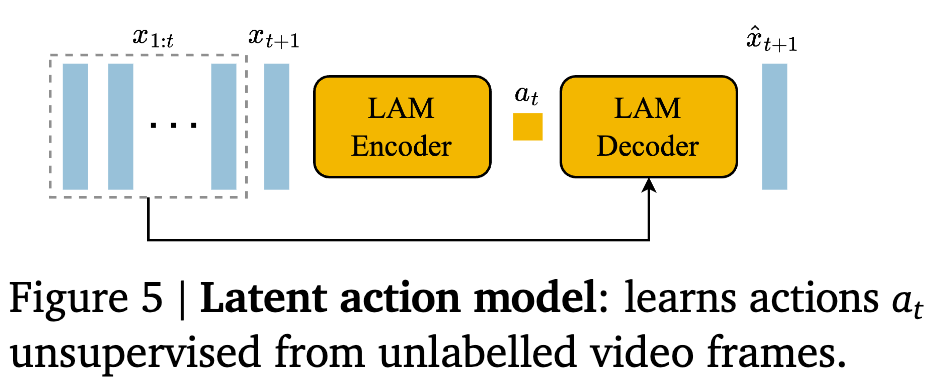
- LAM Encoder (ST-transformer + causal mask)
- input
- previous frames $x_{1:t}$
- next frame $x_{t+1}$
- output
- latent actions $\tilde{a}_{1:t}$
- input
- LAM Decoder
- input
- previous frames $x_{1:t}$
- current latent action $\tilde{a}_{t}$
- output
- next frame $\hat{x}_{t+1}$
- input
-
vocabulary size A =8개의 VQ codebook으로 구성된 VQ-VAE로 학습 -
사람의 playability (up right left down jump no-op etc..) - Decoder는 previous frames ($x_{1:t}$)와 latent action $a_t$만 보고 next frame $x_{t+1}$을 예측해야 하므로, latent action $a_t$는 next frame로 변환하기 위해 유의미한 정보를 저장하도록 훈련됨
-
- LAM은 training signal을 제공할 뿐, 실제 추론할때는 user의 actions로 대체됨
- LAM Encoder (ST-transformer + causal mask)
Video Tokenizer
-
마찬가지로 VQ-VAE + ST-Transformer구조 $\to$ frame수에 linear하게 computation이 증가하므로, 메모리 효율이 좋음 (vs. ST-ViViT)
-
200M parameters / patch-size 4 / codebook embedding 32 / 1024 unique codebooks
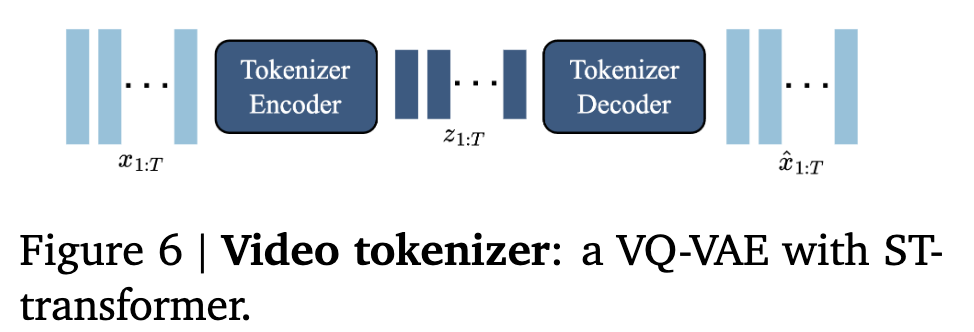
- input
- input frames $x_{1:T}$
- output
- descrete encoding $z_{1:T}$
- input
Dynamics Model
-
Decoder-only MaskGIT tranformer (bfloat16 / QK-norm)
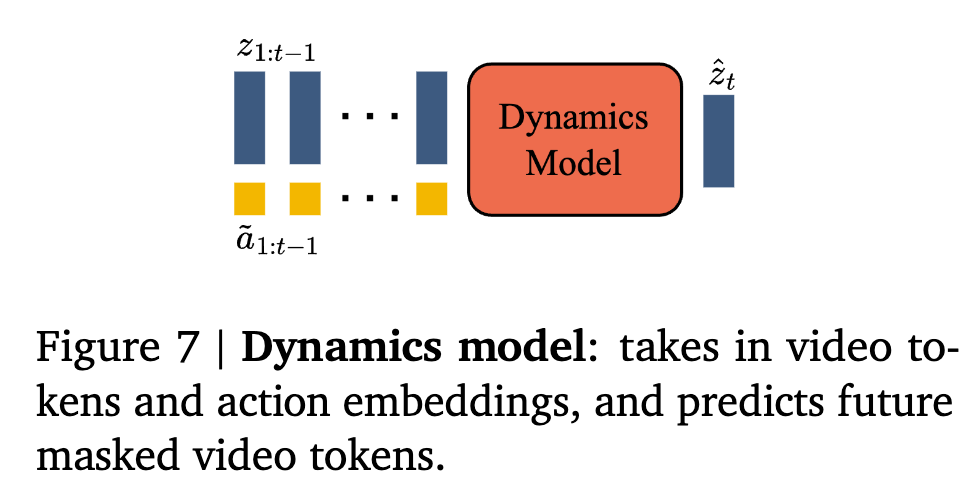
- input
- tokenized video $z_{1:t-1}$
- stopgrad laten actions $\tilde{a}_{1:t-1}$
- output
- next frames tokens $\hat{z}_{2:t}$
- Loss
- Cross Entrophy between ground truth $z_{2:t}$ and prediction tokens $\hat{z}_{2:t}$
- Random masking으로 $z_{2:T-1}$에서 지우고, 복원하며 학습
- Laten action 은 concat보다 더하는게 controllability가 좋아서 더하는걸로 최종 채택
- input
3.2 Inference: Action-Controllable Video Generation
-
overview
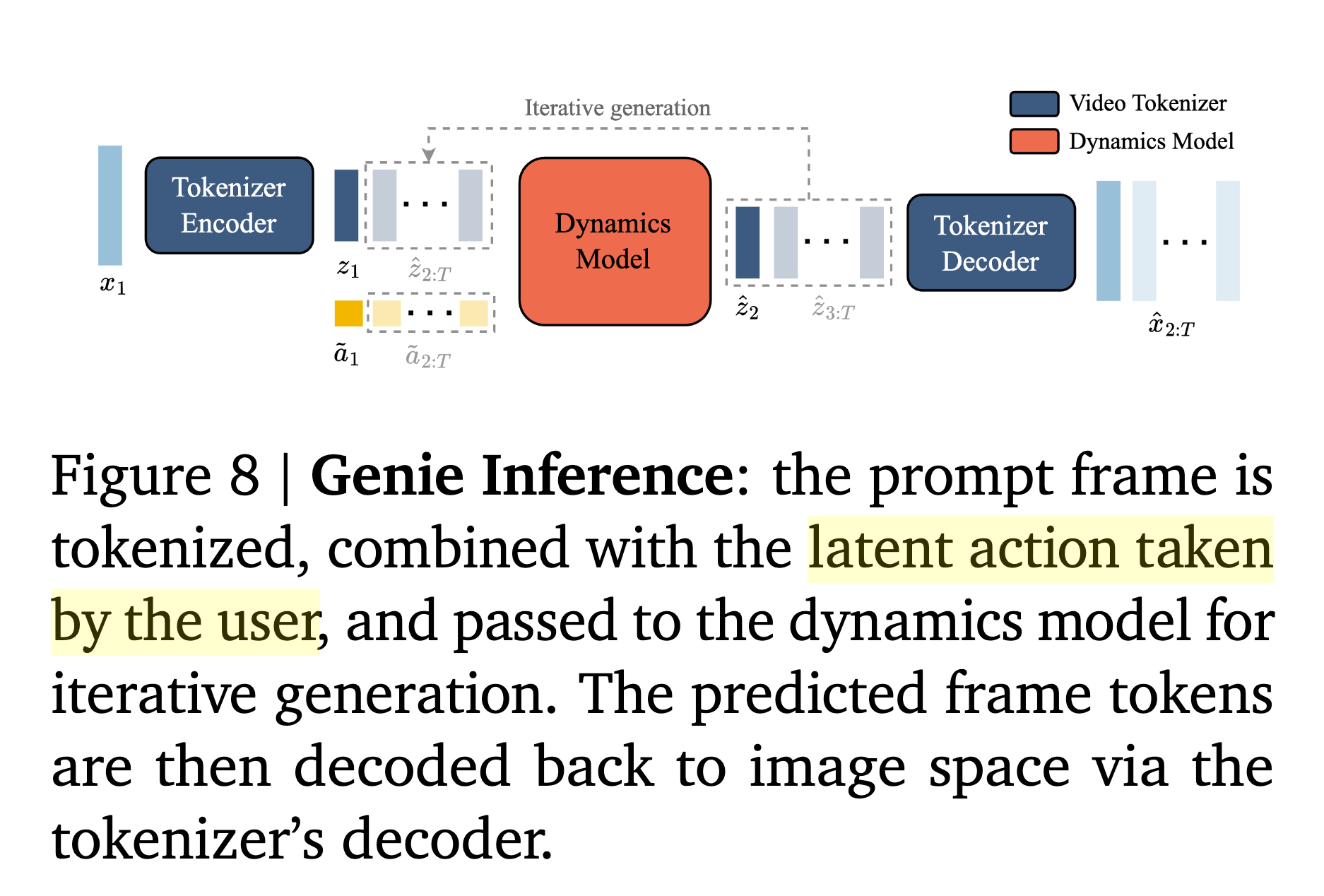
-
input
- prompt로 사용할 single frame image $x_1$
- user의 action $a_1$
- VQ codebook의 index가 각각 어떤 action을 의미하는지는 처음에는 user가 모르므로, next frame을 보고 추측하여 알수 있음
- 일관된 결과를 제공함
-
output
- video frames
4. Experiments
-
Datasets
- 2D Platformer games (55M 16s video clips / 10 FPS / 160x90 resolutions)
-
Models
- 11B param.
-
Metrics
- Frechet Video Distance (FVD)
- PSNR
-
3D scene understanding

- 멀리있는 물체는 적게 움직이고, vice-versa
-
정성적 결과
-
OOD sample 결과

-
Robotic-trained model (2.5B)

-
-
Training Agents
-
Ginie가 예측한 frame에 대한 action trajectory를 모아서 small dataset을 생성
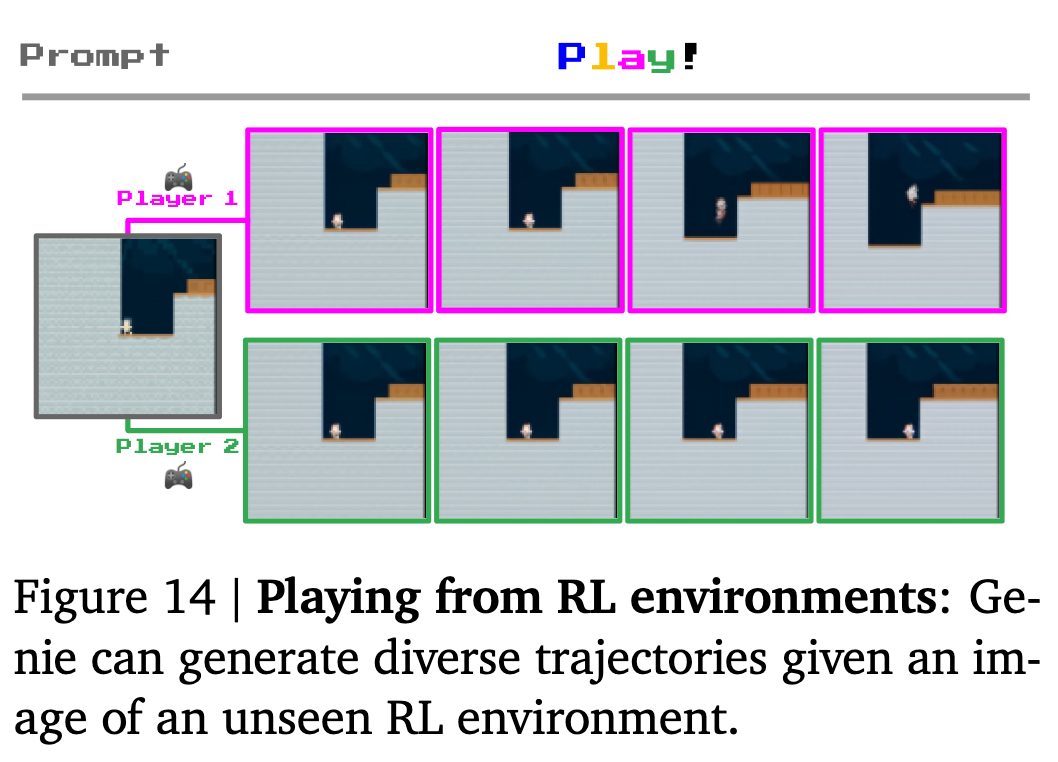
-
policy 모델을 학습
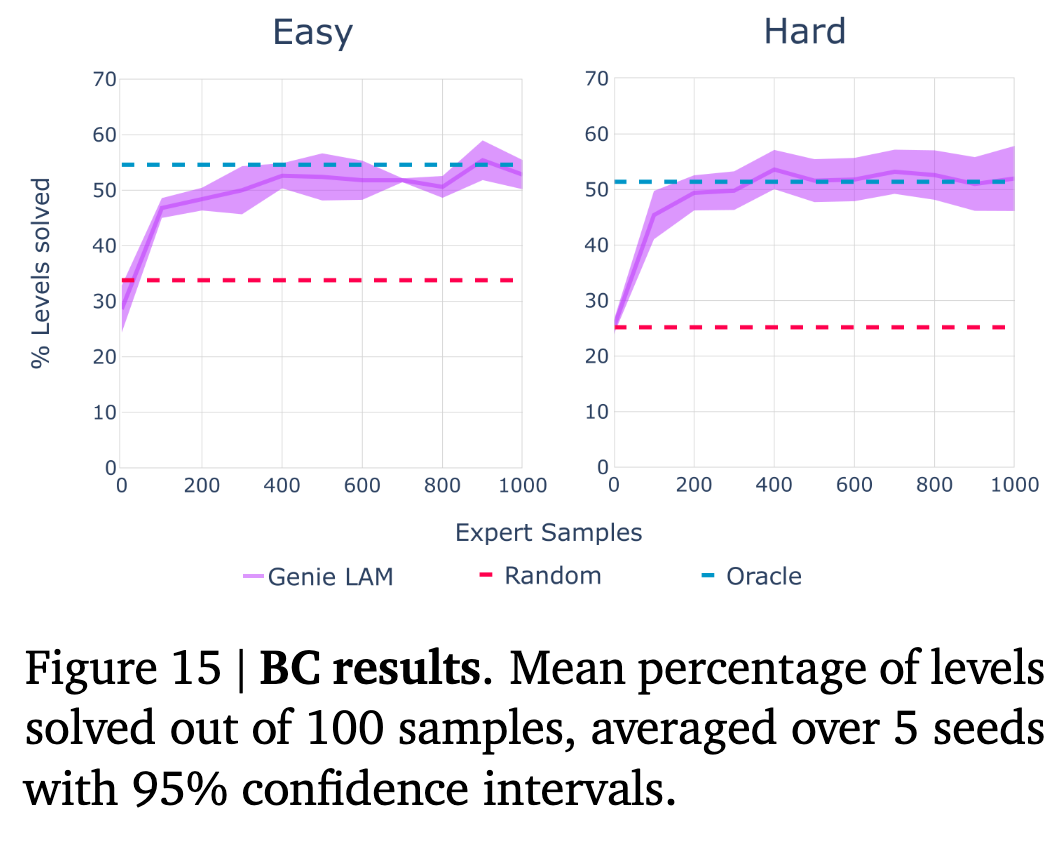
- Upper-bound: 생성한 정답
- Lower-bound: Random action prediction
-
-
Ablation Studies
-
Model parameter & batch-size scale에 따른 분석
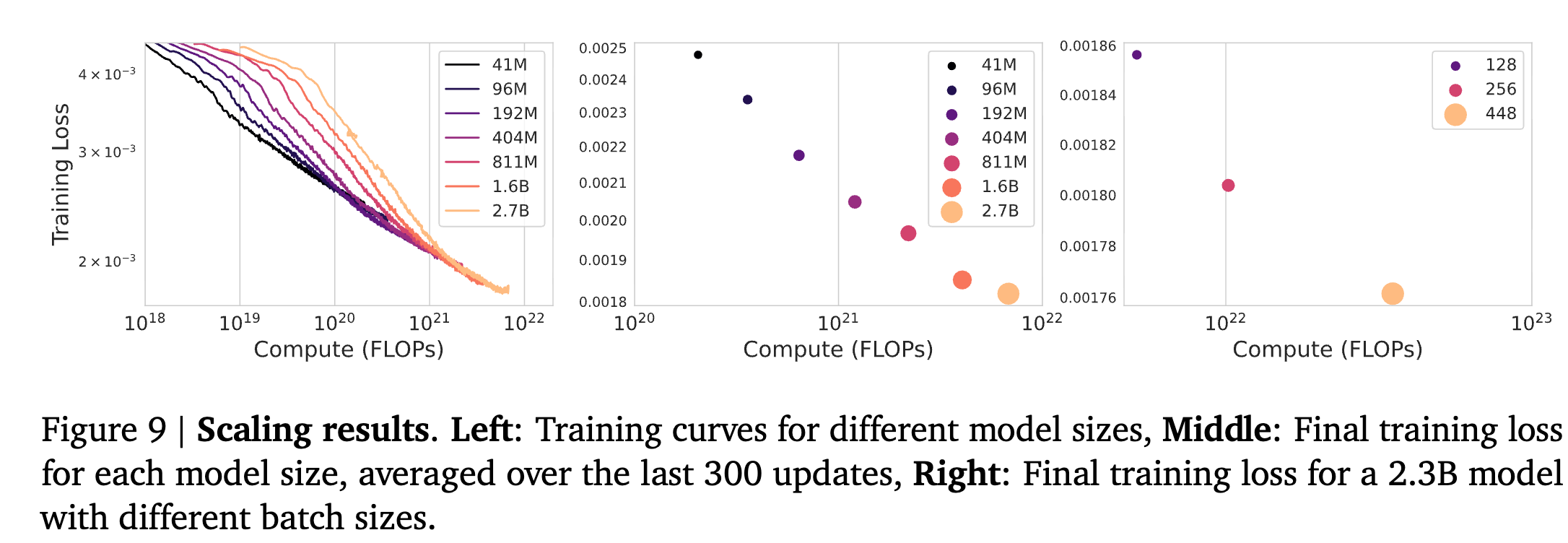
-
LAM의 input별 성능 분석
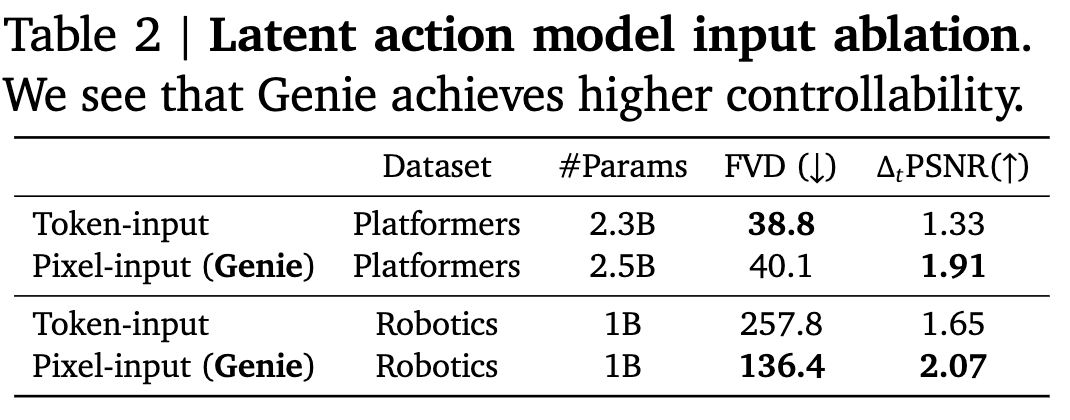
- input이 pixel일떄 controllability가 우수함 (PSNR)
-
Tokenizer architecture별 성능 분석
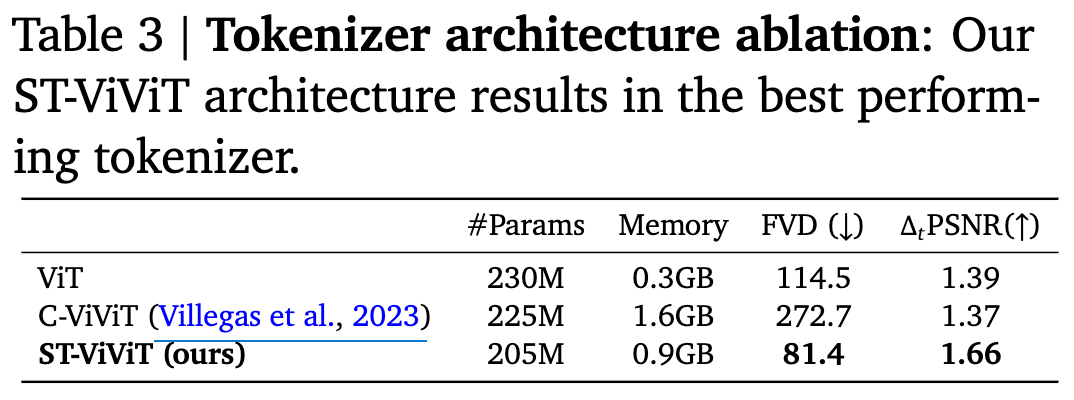
-