[Technical Paper] DINOv3
[Technical Paper] DINOv3
- paper: https://arxiv.org/pdf/2508.10104
- github: https://github.com/facebookresearch/dinov3
- archived (인용수: 2회, 25-08-30 기준)
- downstream task: Object Detection, Semantic Segmentation, I2T / T2I Retrieval, Video Classification, Video Segmentation Tracking, Unsupervised Object Discovery, Depth Estimation, 3D Correspondence Estimation
1. Introduction
-
Annotation이 필요 없이, 비정형 데이터(image) 기반으로 raw pixel data를 활용하는 SSL (Self-supervised Learning)의 장점이 대두되고 있음
- domain shift에 robust한 특성
- global & local features 동시에 strong한 특성
- 물리적 scene에 대한 이해를 향상할 수 있는 rich embedding
- web data의 자연스런 증가에 따른 lifelong learning에 적합한 특성
-
하지만 기존에는 SSL 연구를 위한 세 가지 필수조건에 대한 연구가 부족했음
-
유용한 데이터를 unlabled collections로부터 어떻게 취합해야 하는지
-
Cosine scheduling을 하기위해 사전에 optimization을 위한 사전지식이 부재
-
초기 학습 이후에 Features의 성능이 약해지는 특성
- Feauture 성능? patch간의 similarity map 기반으로 시각화한 결과
$\to$ 단순하게 데이터를 늘린다고 성능이 좋아지지 않음
-
$\to$ Frozen backbone으로 활용 가능한 다재다능한 Single visual encoder를 만들어보자!
Strong & Versatile Foundation Model
-
Foundation Model의 조건
-
Backbone을 Frozen하고도 SOTA specialized model과 준하는 성능을 낼것
-
Meta-data (labels)이 없는 SSL (Self-sup.)기반으로 학습하는 pipeline을 구성할것
-
다양한 이미지 데이터 활용 가능 (web image, 인공위성의 관측한 data, etc)

-
-
SSL의 약점, Dense Feature를 보완할것
-
Dense한 feature (semantic segmentation) 뿐만 아니라 Global feature (classification) 모두 잘 추출해야함
-
이 두 목적은 서로 상호배치되기 때문에 동시에 학습하기 어려웠음
-
Gram anchoring 전략을 통해 상충되는 목적을 보완함

가벼운~무거운 모델이 (family) 고루 제공될것
-
제일 무거운 모델 (7B)을 teacher로 두어 distillation하여 목적에 맞게 사용가능한 다양한 크기의 모델을 제공
-
Transformer / CNN 계열 모두 제공
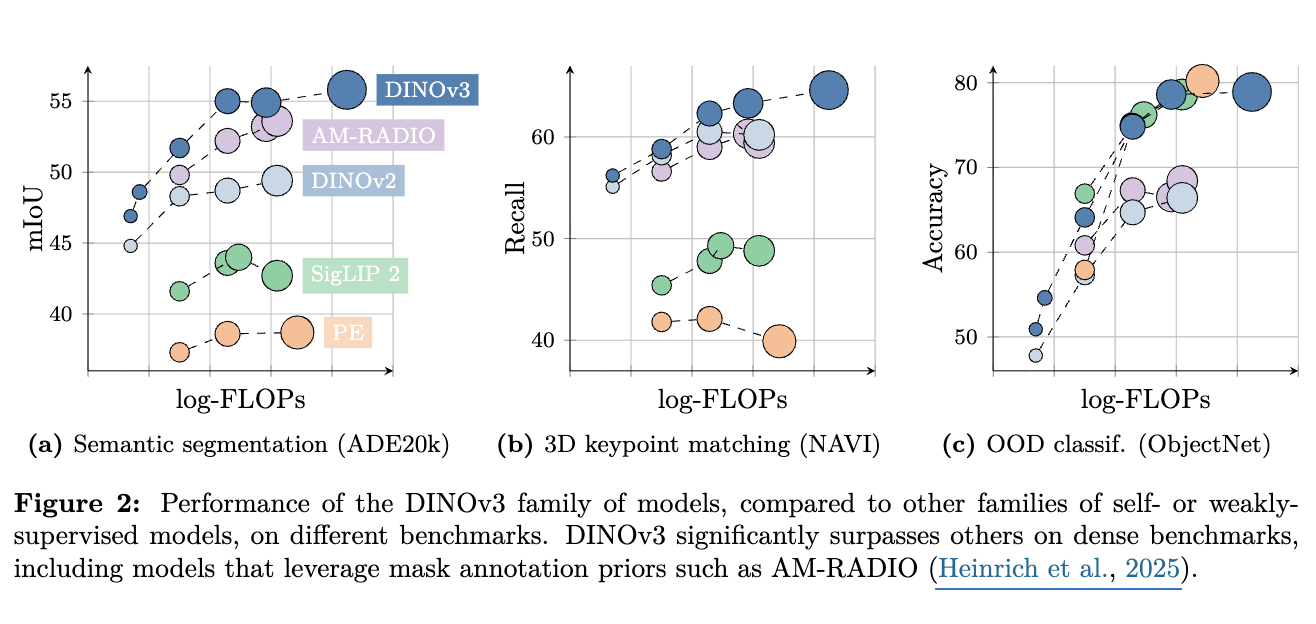
-
2. Contribution
-
학습용 데이터 curation을 통해 training data scaling을 효과적으로 수행함
-
최신기술 접목 (Modern position embedding (axial ROPE), regularization technique)을 적용하였고, 복잡한 multiple cosine schedule (DinoV2)가 아닌 constant hyperparameter schedule을 통해 사전지식 없이도 좋은 성능을 달성.
-
새로운 Gram Anchoring 기법을 도입하여 desnse feature를 효과적으로 학습시킴
-
고해상도 post-training, teacher-student distillation을 통해 효율적으로 작은 family 모델들을 학습시킴
-
해당 모델을 frozen한 채, head부분만 efficent tuning하여 다양한 Task에서 SOTA성능을 달성함
$\to$ CLIP기반의 global feature 성능을 유지한채, dense feature 성능을 향상시킨 Vision foundation model을 개발함
3. 비지도학습
-
자연어 처리 분야에서, 모델의 규모를 키웠을때 초거대 언어모델에 outstanding emerging property 능력이 생기는 현상이 있음
- (뇌피셜) 언어분야에서는 MTP 기반 비지도학습을 통해 data의 규모를 키울수 있었기 때문
$\to$ Computer Vision 분야에서도 SSL을 통한 패러다임 shift를 해보고싶다!
3.1 Data Preparation
-
Naive하게 학습 데이터를 키우는 것만으로는 모델의 quality & downstream task에서의 성능 향상을 보지 못함
$\to$ 조심스러운 data curation이 필수
- data diversity & usefulness간의 밸런스가 필수
- usefulness: common applications와의 연관성이 우수해야함 (ex. DINOv3-web vs DINOv3-sat)
- data diversity & usefulness간의 밸런스가 필수
Data Collection & Curation
-
유해한 데이터는 필터링되어 있는 Instgram의 web collected data를 활용 3가지 curation기법을 적용 $\to$ 17B images
-
DINOv2 embedding 기반 Hierarchical k-means clustering을 구축하고, balanced sampling algorithm을 적용 $\to$ 1,689 M images
-
Downstream task 별 seed dataset을 선택하고, retrieval system기반으로 연관된 visual dataset을 curation
-
ImageNet, Mapillary, etc 와 같은 Open dataset를 활용
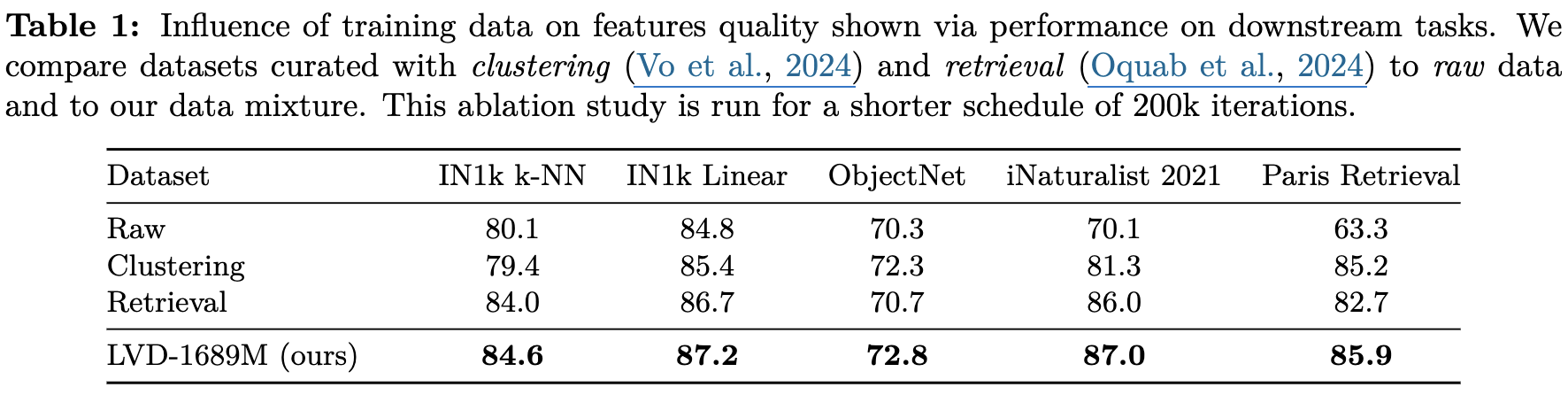
$\to$ 3개 모두 사용하는게 모든 benchmark에서 제일 좋았음
-
3.2 Large-Scale Training with Self-Supervision
-
Learning Objective
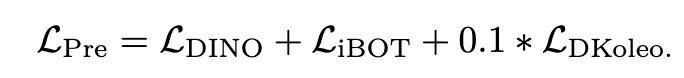
-
(DINOv2) Image-level objective $L_{DINO}$
-
(DINOv2) Patch-level latent reconstruction objective $L_{iBOT}$
$\to$ 두 loss의 centering(?)을 DINO에서 SwAV로 변경했음
$\to$ 두 loss 독립된 head / 독립된 normalization을 적용하여 loss를 계산
-
Koleo regularization을 적용(?) 하여 embedding 공간에 spread 되도록 유도함
-
-
Model Architecture
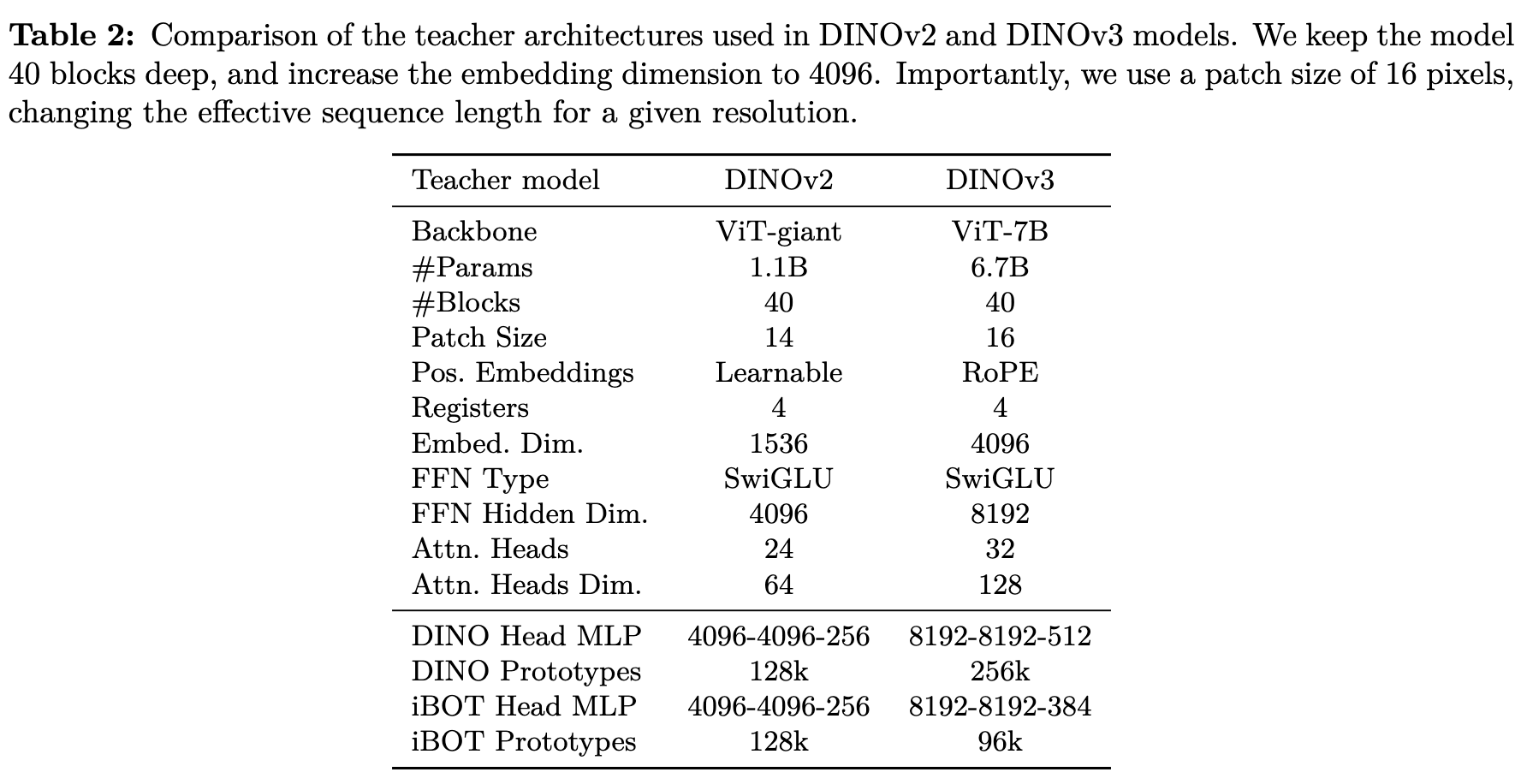
- base RoPE (DINOv2)에서 box jittering을 적용
- as-is: [-1,1]
- to-be: [-s, s], $s \in [0.5, 2]$
- base parameter 1.1B $\to$ 7B로 scale up
- base RoPE (DINOv2)에서 box jittering을 적용
-
Optimization
- data & trainable parameter가 scale-up됨에 따라, 최적의 hyperparameter를 사전에 알기는 어려움.
- 단순한 warm-up + constant lr을 적용
4. Gram Anchoring: A Regularization for Dense Features
4.1 Loss of Patch-Level Consistency Over Training
-
기존 방식의 문제점
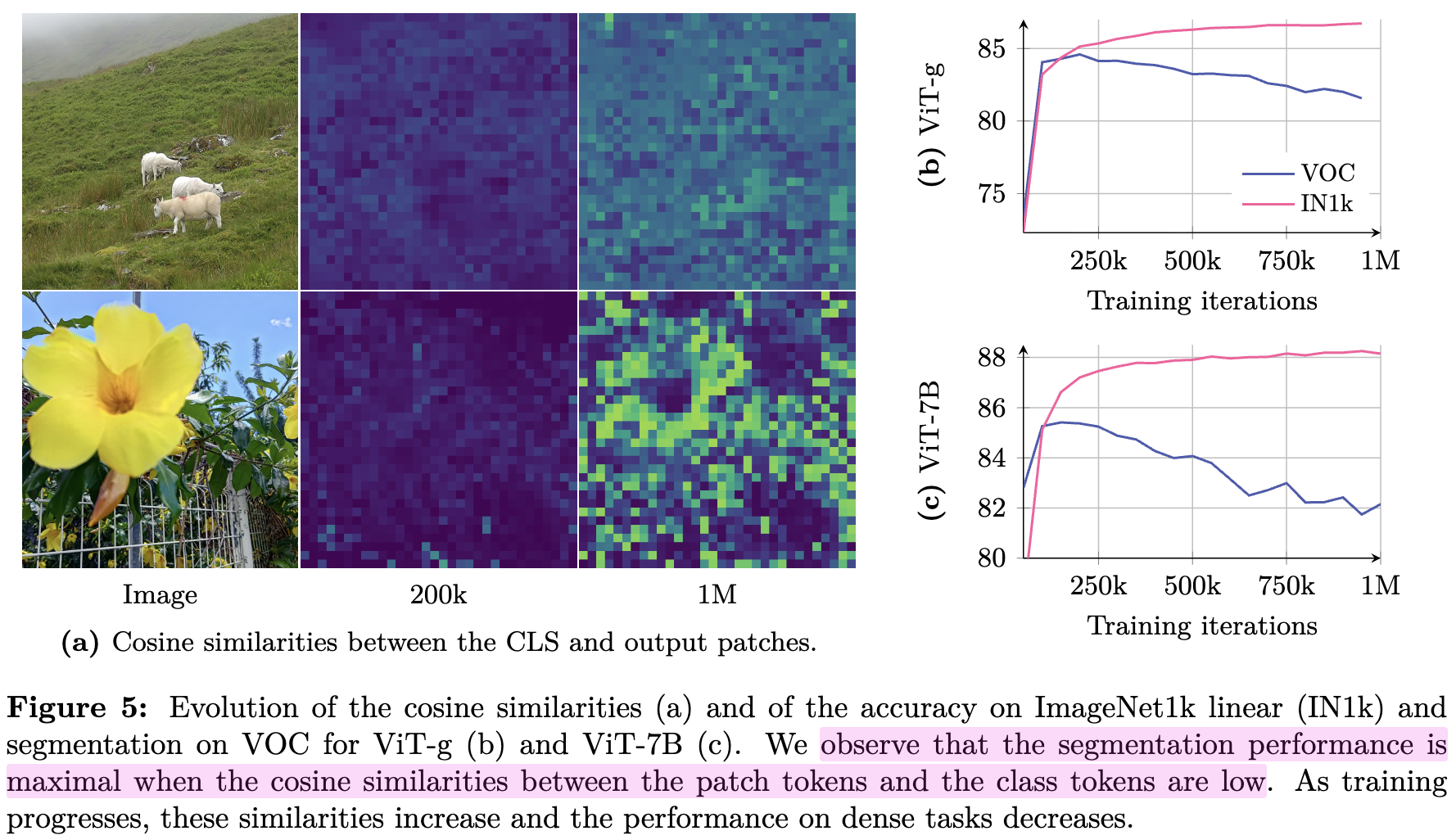
-
CLS token과 local patch간의 유사도가 학습이 진행될수록 증가함 $\to$ global feature만 남게됨
-
local feature를 요구하는 task (semantic segmentation) 성능이 저하함
$\to$ patch feature에 대한 regularization loss를 주입하여 patch-level consistency를 유지해보자!
-
4.2 Gram Anchoring Objective
-
Gram Anchoring Objective
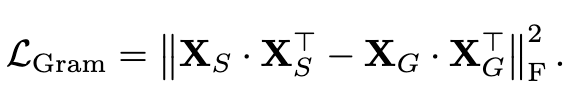
- local patch features를 직접 regularization하는 것보다, similarity matrix를 regularization함으로써, local features가 자유도를 갖고 학습하도록 유도함
-
1M iteration 이후에 적용하며, 10K step마다 Gram teacher를 갱신함
- Gram matrix: n x n local patch의 similarity score로 구성된 matrix
- Gram teacher: earlier model의 Gram matrix $X_G$
-
최종 Loss
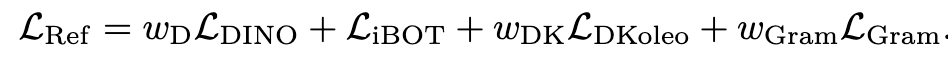
-
Gram Anchoring Loss 적용 직후 downstream task 성능 변화
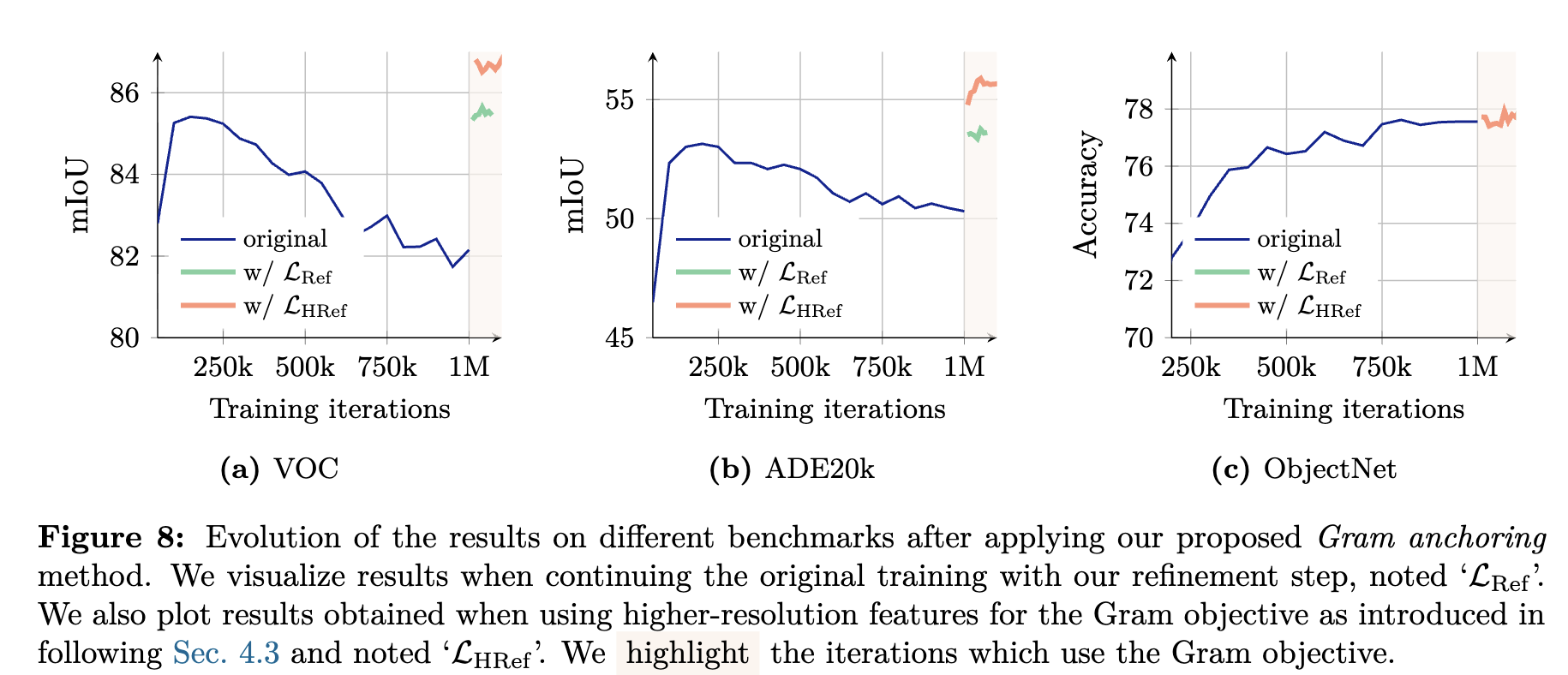
4.3 Leveraging Higher-Resolution Features
-
Gram Teacher 계산 전에 해상도를 2x 키우고, 뒤에서 1/2 x downsampling 적용한게 dense feature 학습에 좋음
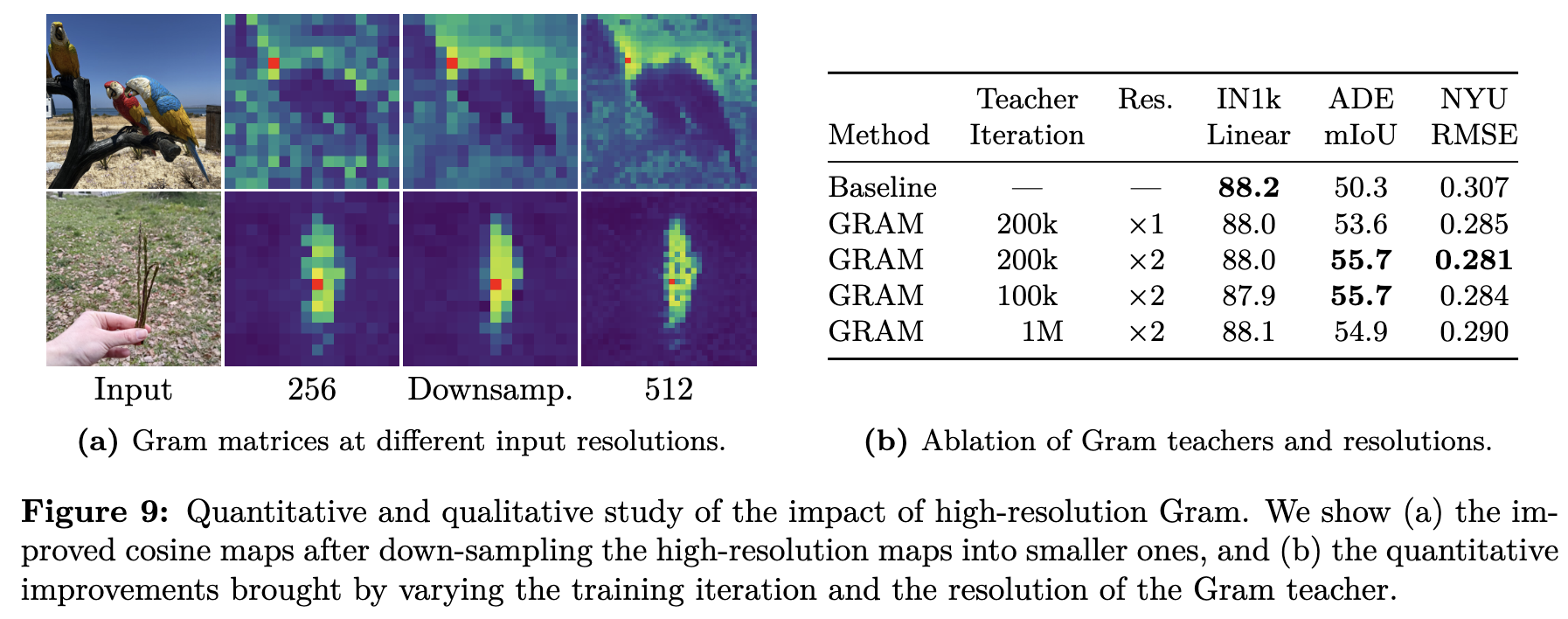
5. Post Training
5.1 Resolution Scaling
-
Global & local crops를 mixed batch에 넣고 추가 10k 학습
- global crop: {512, 768}
- local crop: {112, 168, 224, 336}
-
결과
-
정량적 결과
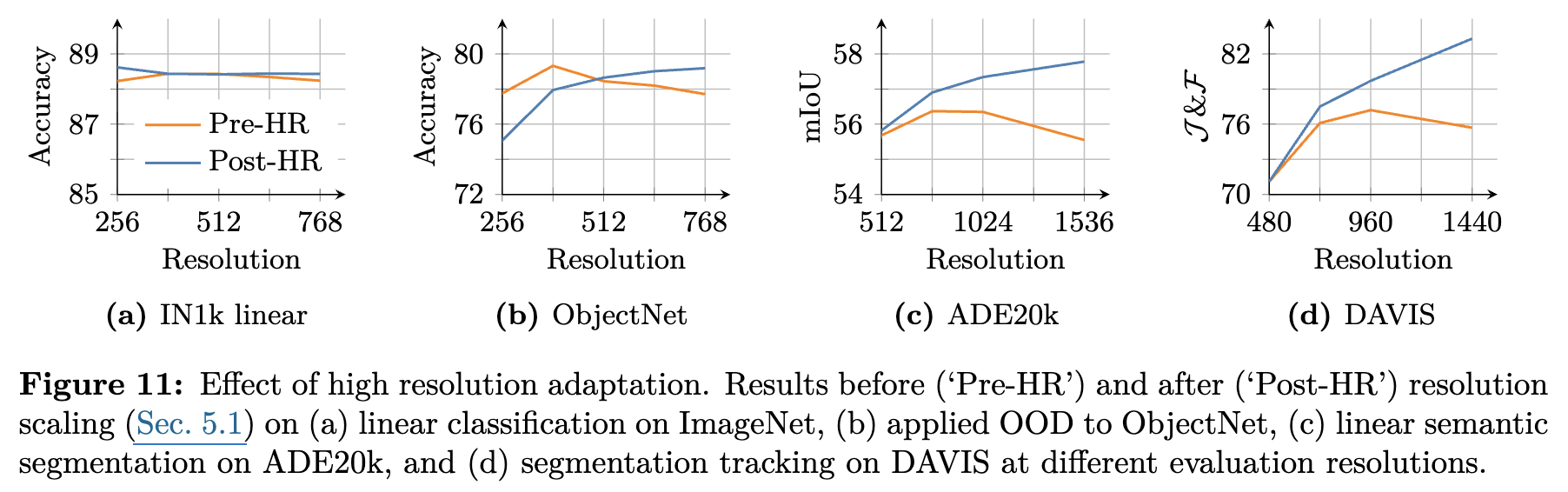
-
정성적 결과

- 4k 이상 고해상도 이미지의 segmentation 성능을 매우 크게 향상시킴
-
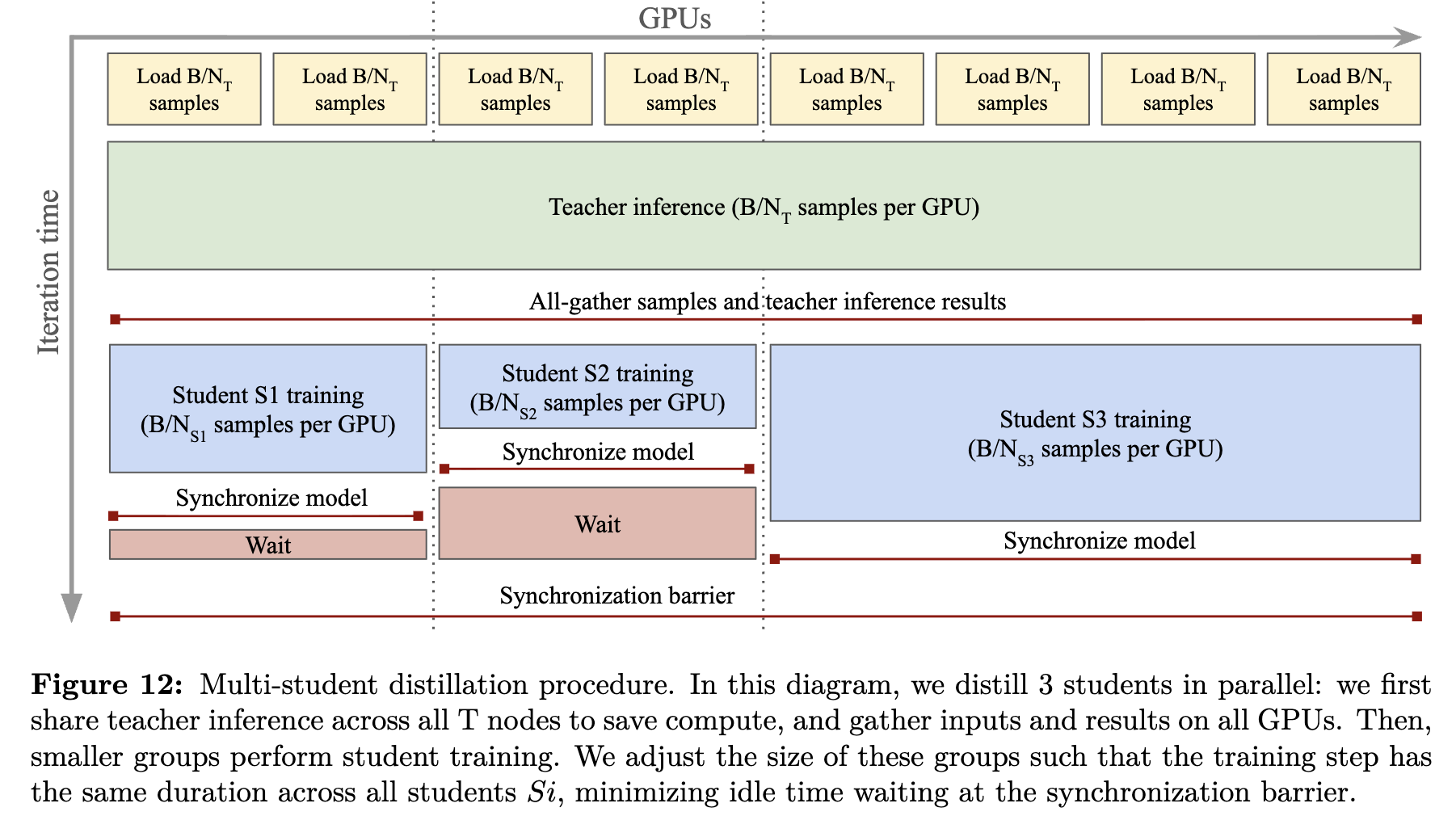
5.2 Model Distillation
-
Distillation
- Teacher : ViT-7B
- Student: ViT-S, ViT-B, ViT-L
-
patch-level consistency issue가 없으므로, Gram Anchoring은 미적용
-
Teacher의 forward pass가 오래걸리므로, Parallel distillation pipeline을 적용
5.3 Aligning DINOv3 with Text
- Text representation을 scratch로 DINOv3와 align되도록 CLIP처럼 학습
- Visual encoder: DINOv3(freeze) + 2-transformer layers만 학습
- DINOv3의 CLS token과 text representation의 average patch embedding을 CLIP처럼 학습
6. Results
-
Frozen DINOv3-7B을 기반으로 downstream task를 평가
-
정성적 결과
-
PCA (patch-level consistency)

-
-
Linear Probling
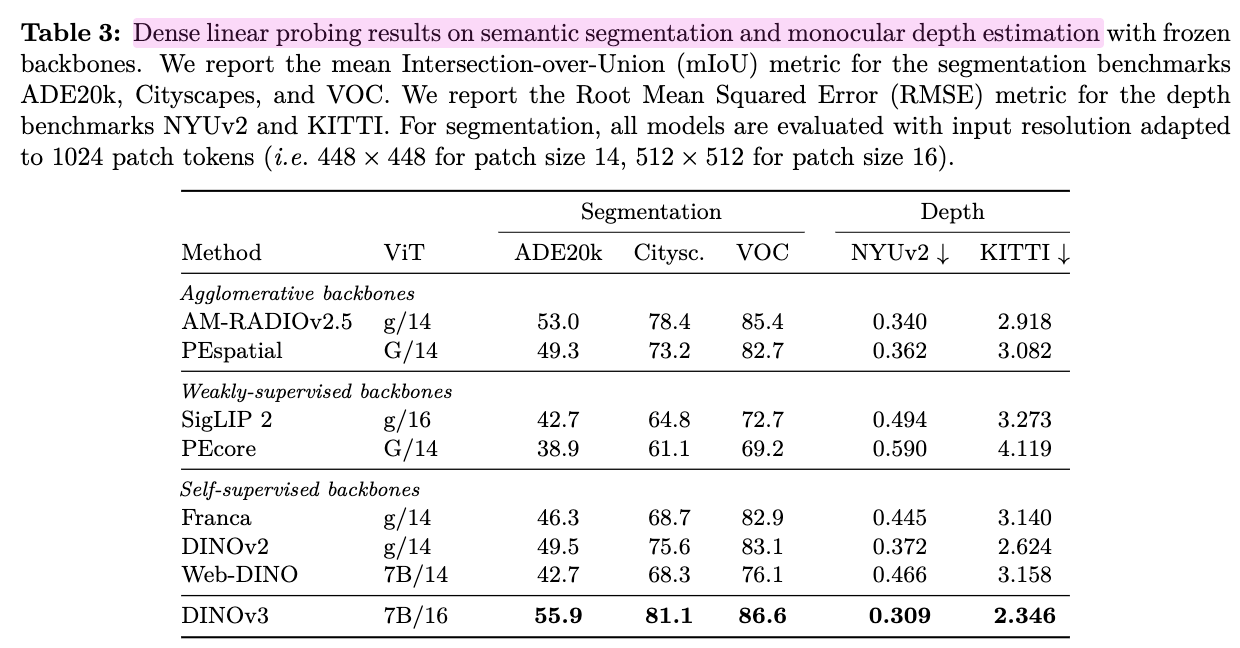
-
3D Correspondense Estimation (Multi-view consistency)
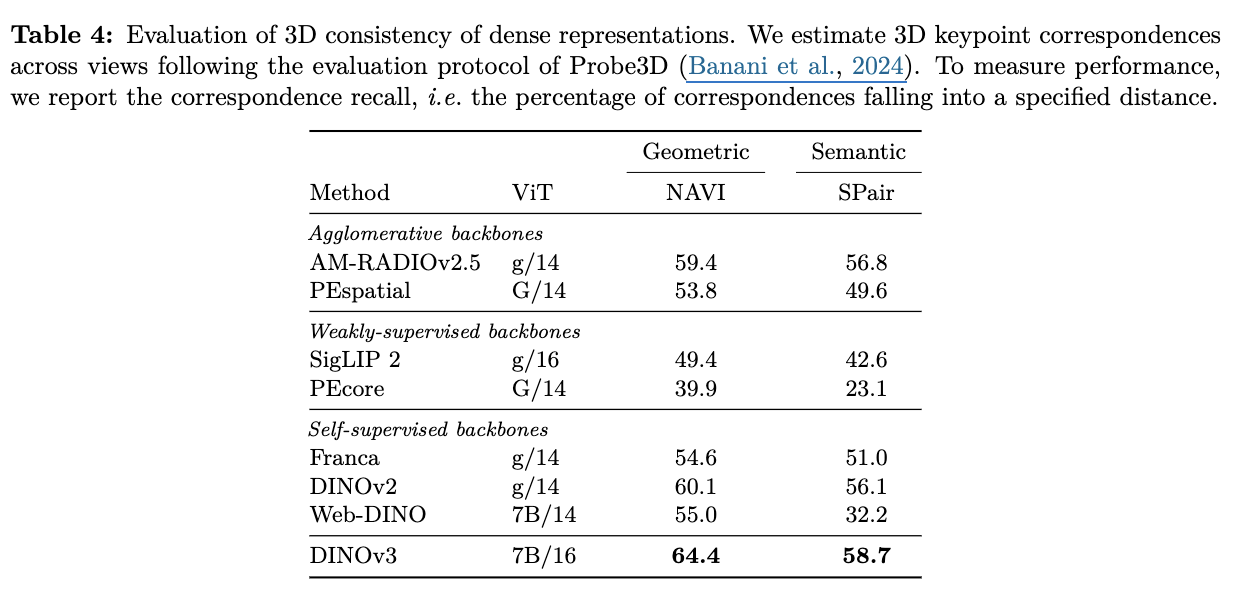
-
Unsupervised Object Discovery
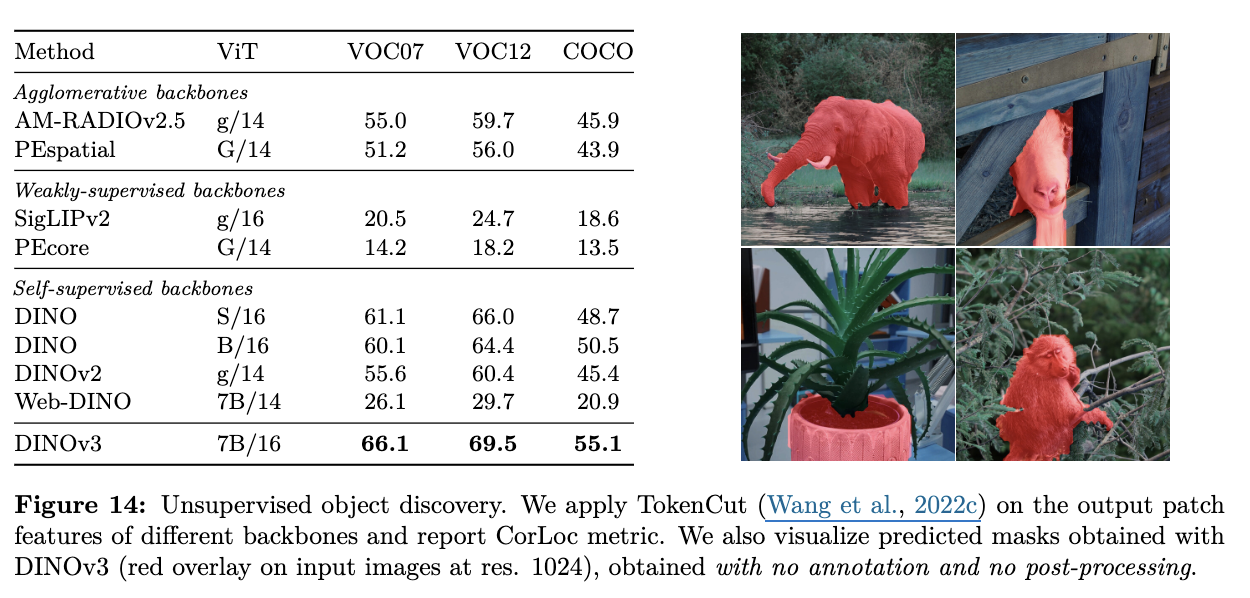
-
Video Segmentation Tracking
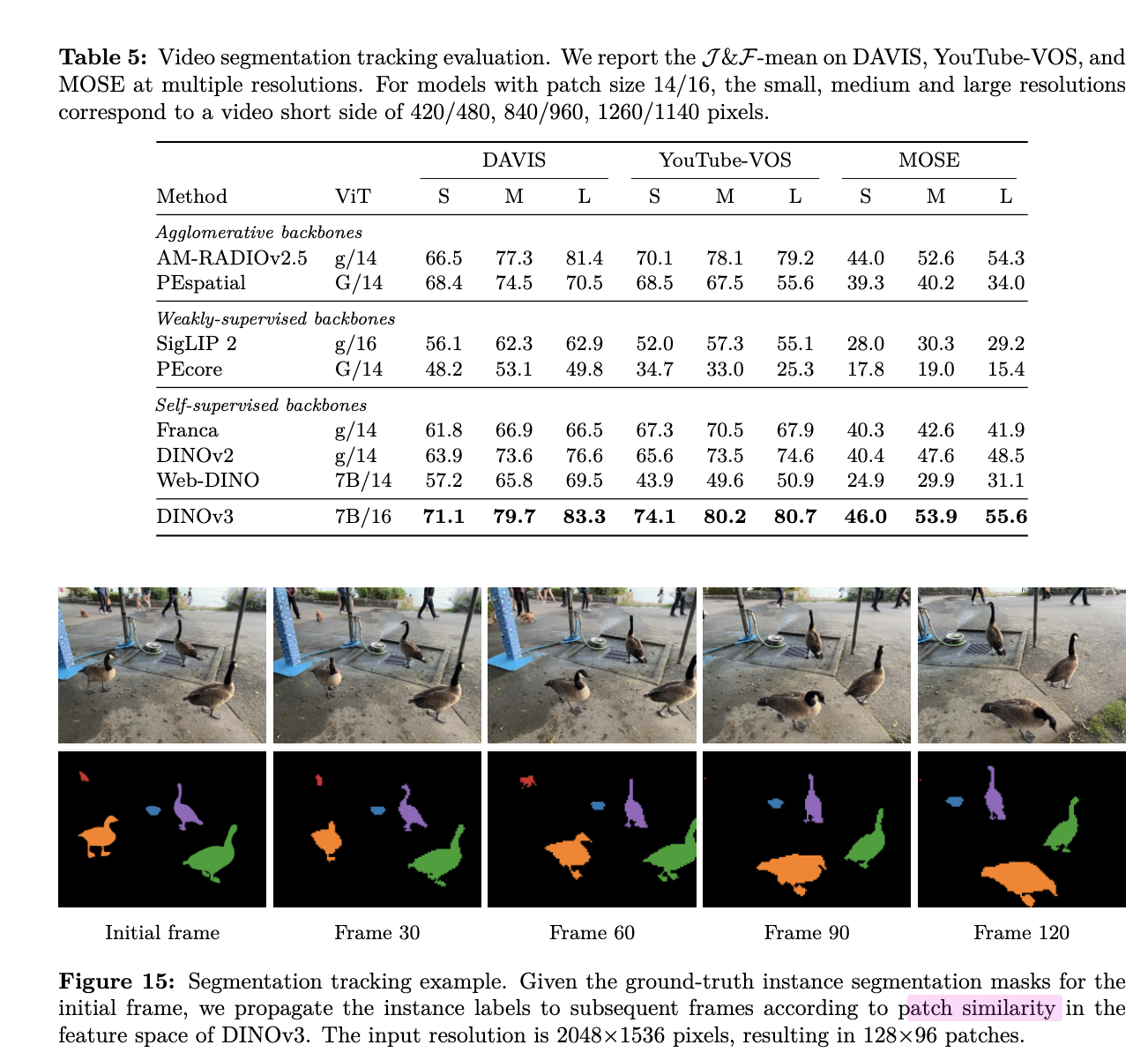
-
Video Classification
-
4-layer-transformer만 tuning한 결과 $\to$ global feature 특화된 SigLip2보다는 안좋음.
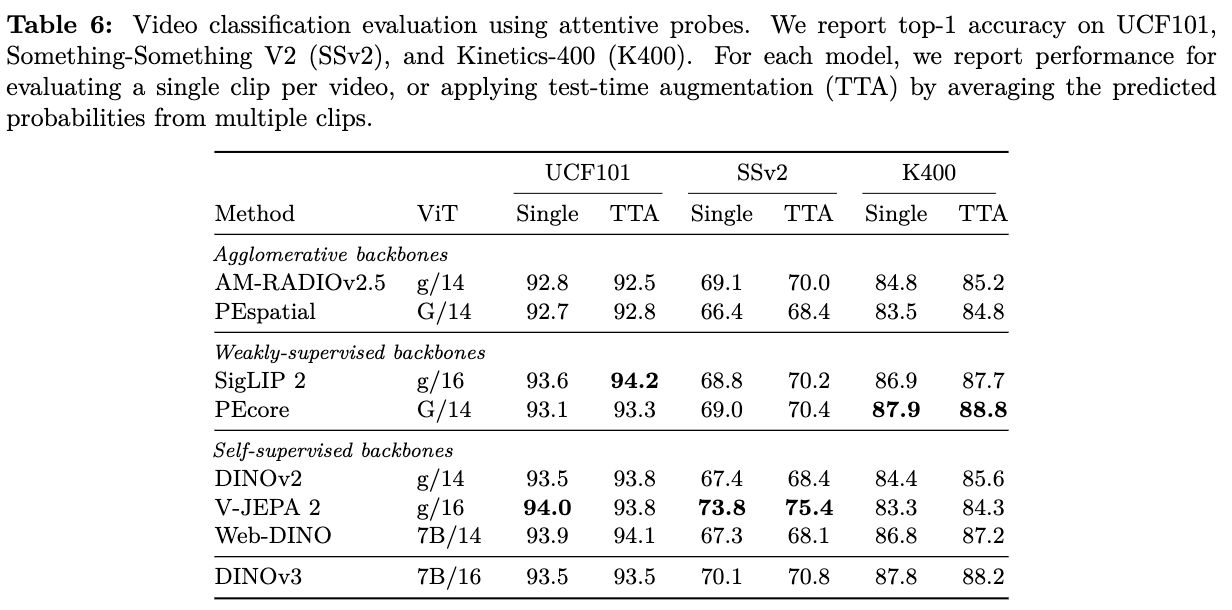
-
-
Image Classification (Linear Probling)
-
Domain Generalization
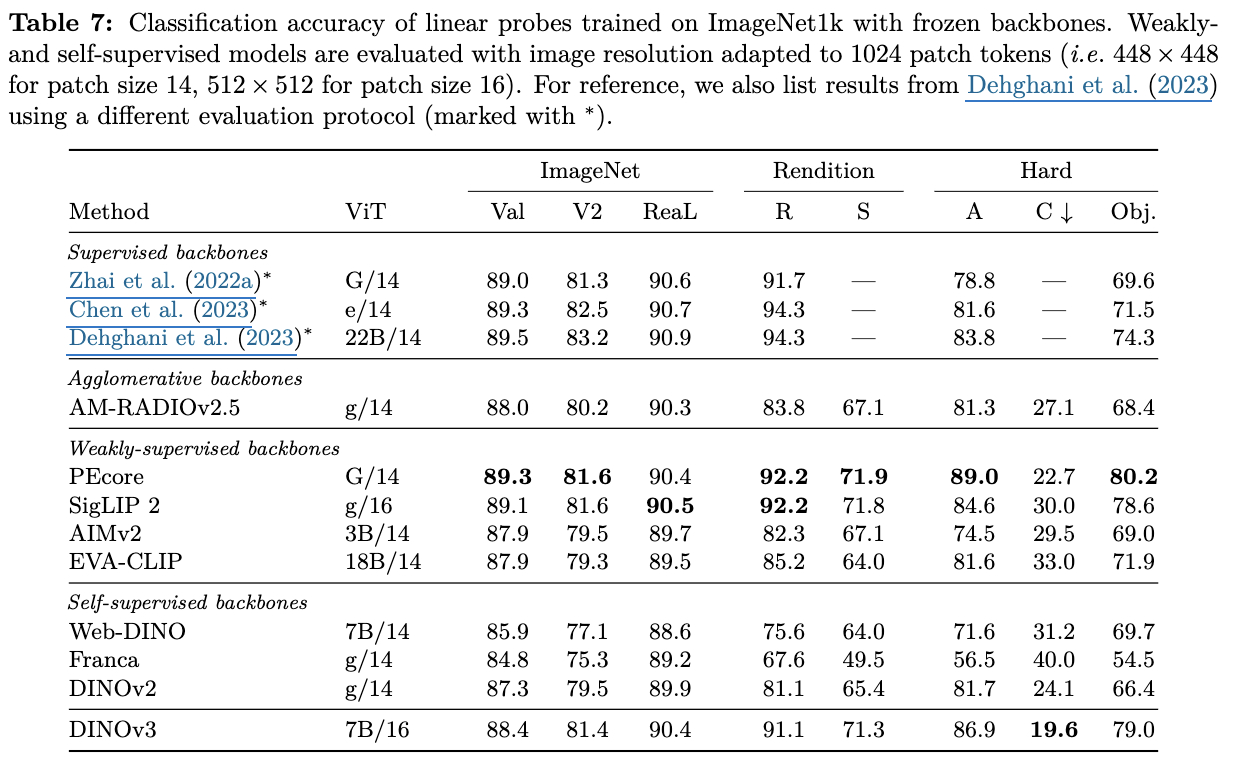
- global feature 특화된 SigLip2/PEcore 보다는 안좋음
-
Finegrained classification
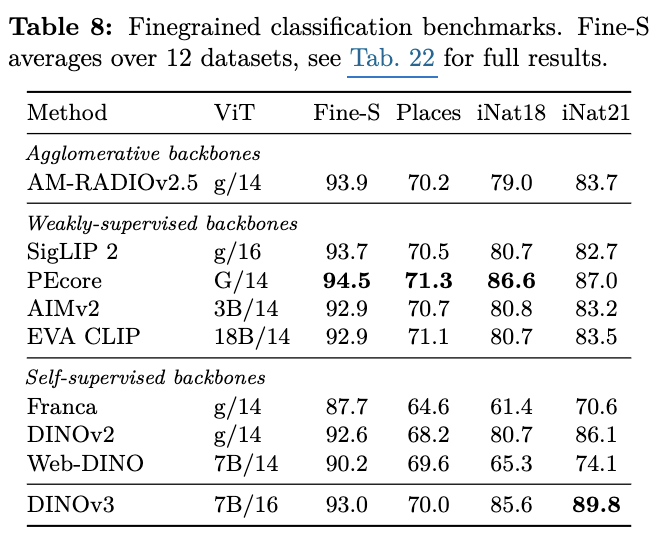
- global feature 특화된 SigLip2/PEcore 보다는 안좋음
-
-
Instance Recognition
-
Landmark datasets
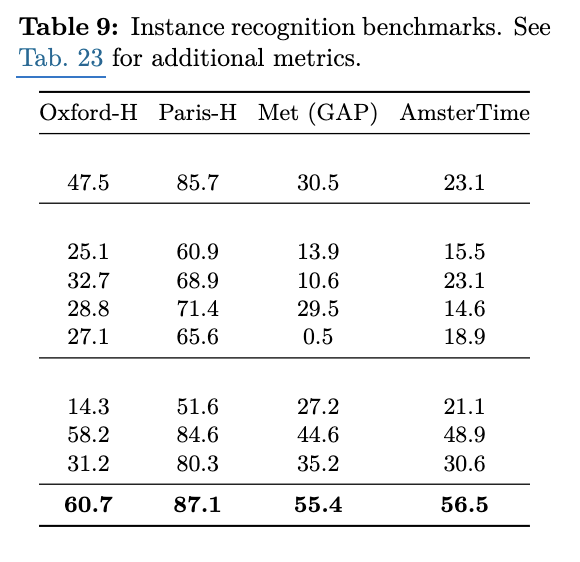
-
Art & Historical image retrieval
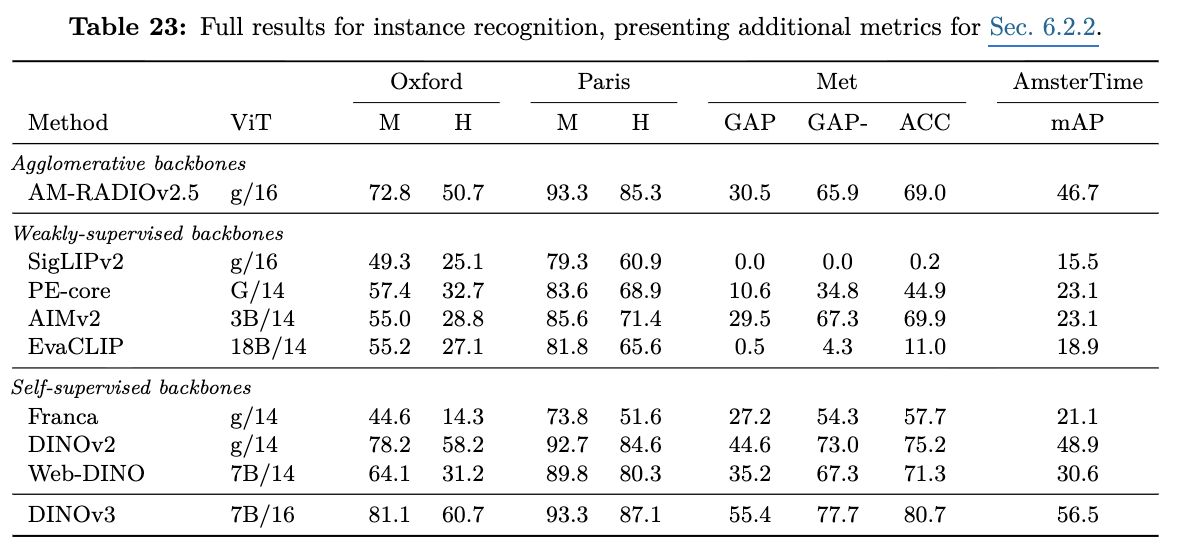
-
-
Object Detection
-
lightweight Decoder만 학습
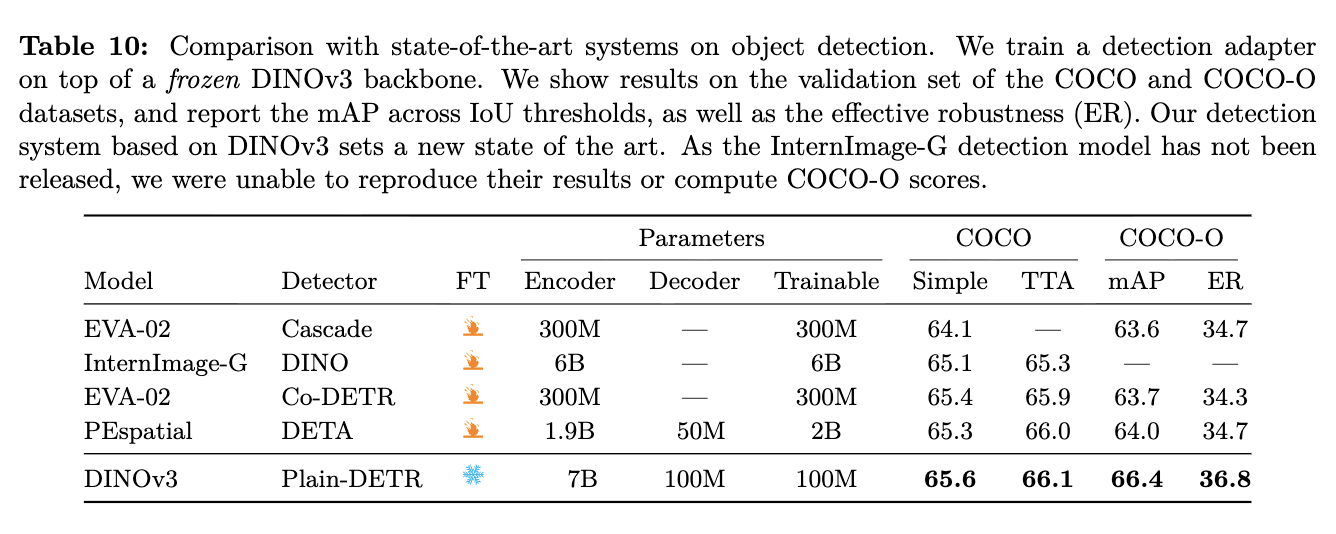
-
-
Semantic Segmentation
-
OD와 마찬가지로 ViT-Adapter + Mask-Former만 학습
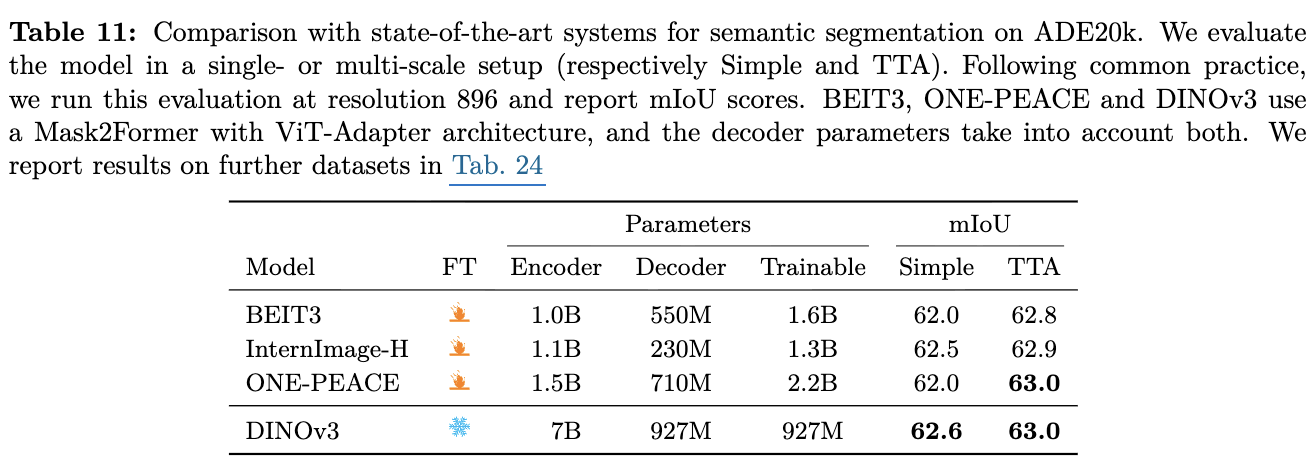
-
-
Monecular Depth Estimation
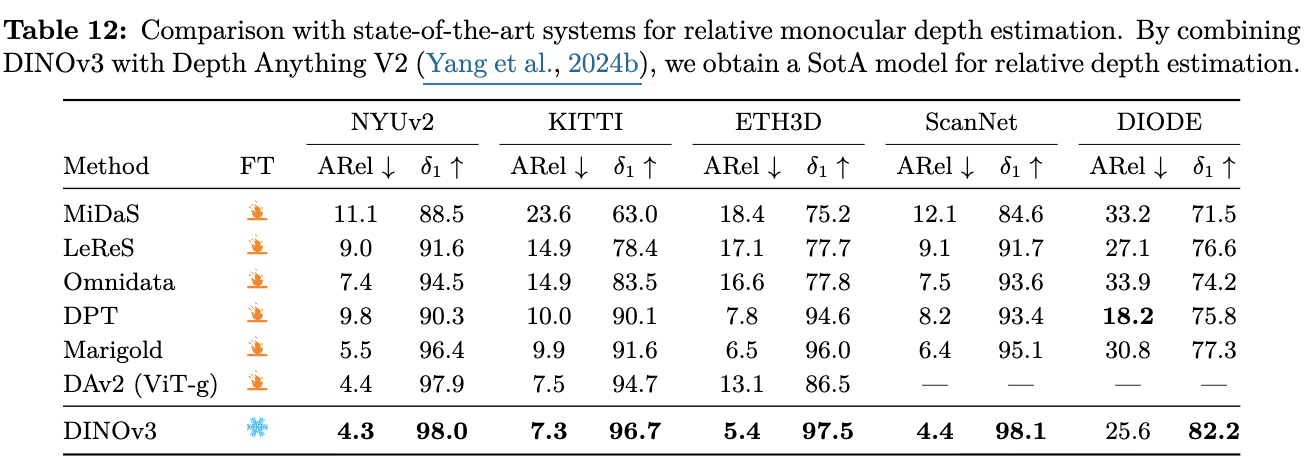
-
Visual Grounded Geometry Transformer with DINOv3
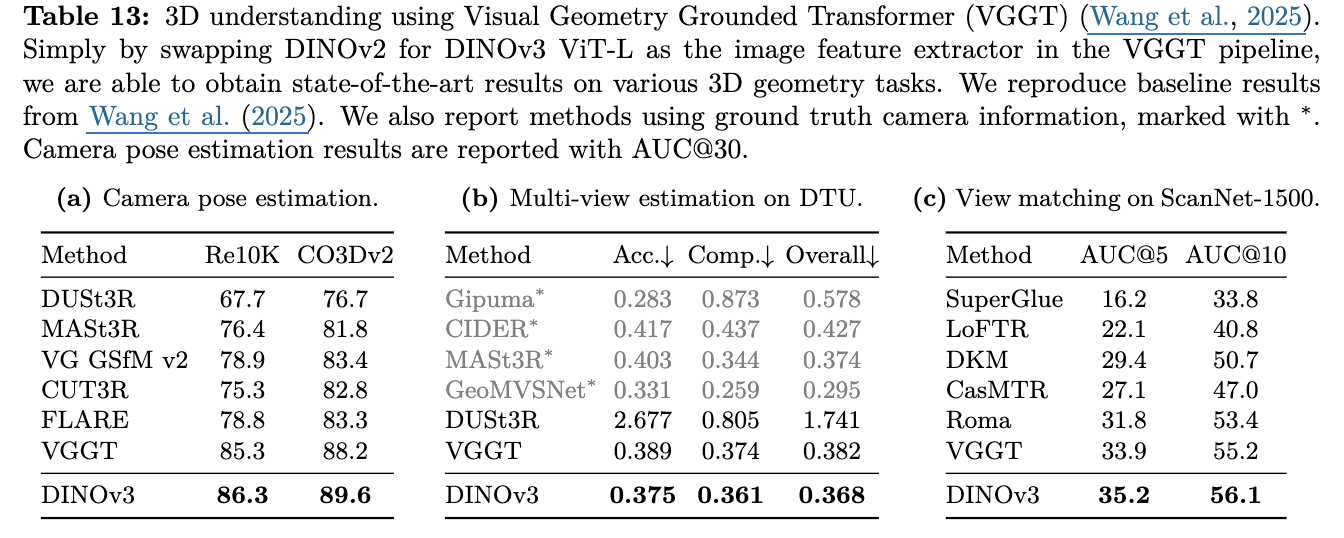
-
Distillation의 효과
-
ViT & ConvNexT Family
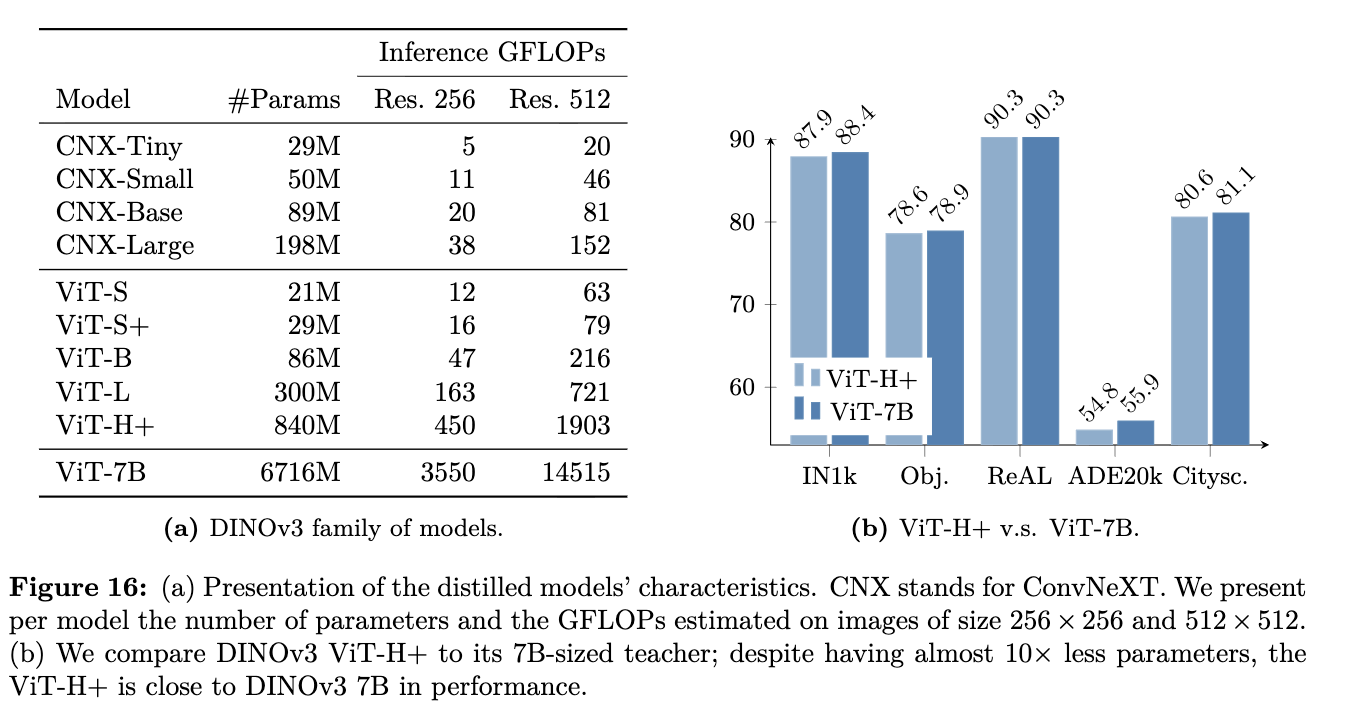
-
Downstream Tasks
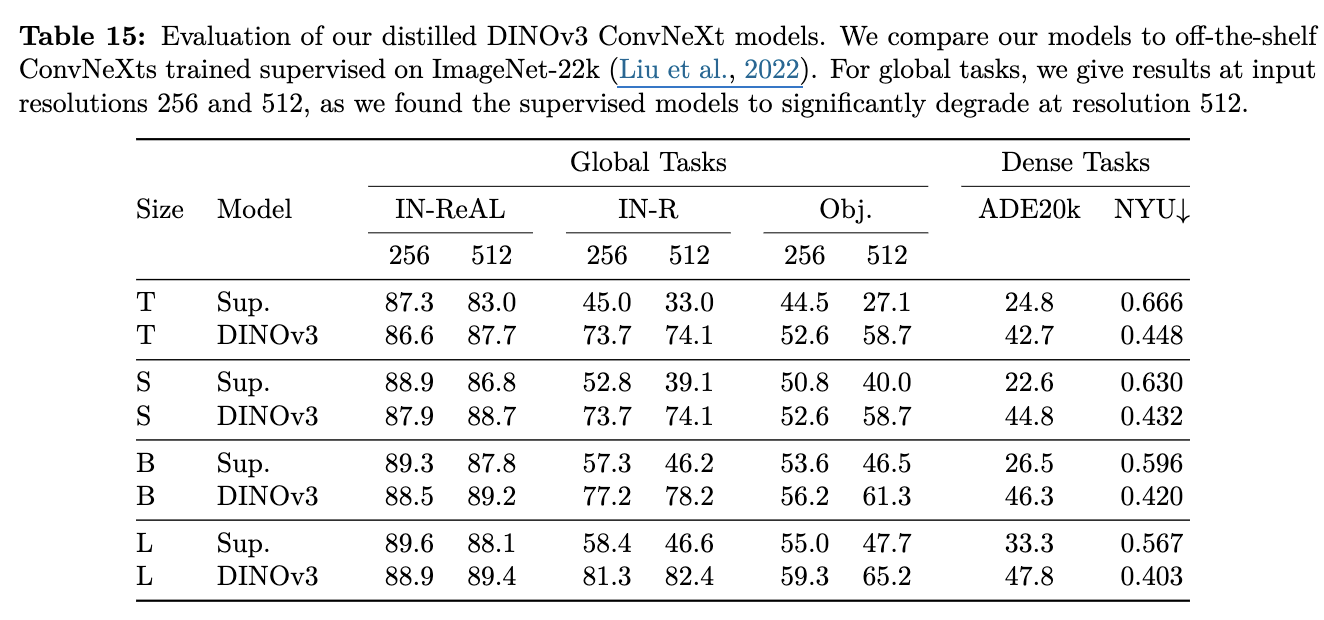
- Classification + In-Distribution: Supervised Learning > DINOv3 distillation
- Classification + Out-of-Distribution: Supervised Learning < DINOv3 distillation
- Dense tasks: Supervised Learning < DINOv3 distillation
-
Zero-shot T2I/I2T Retrieval
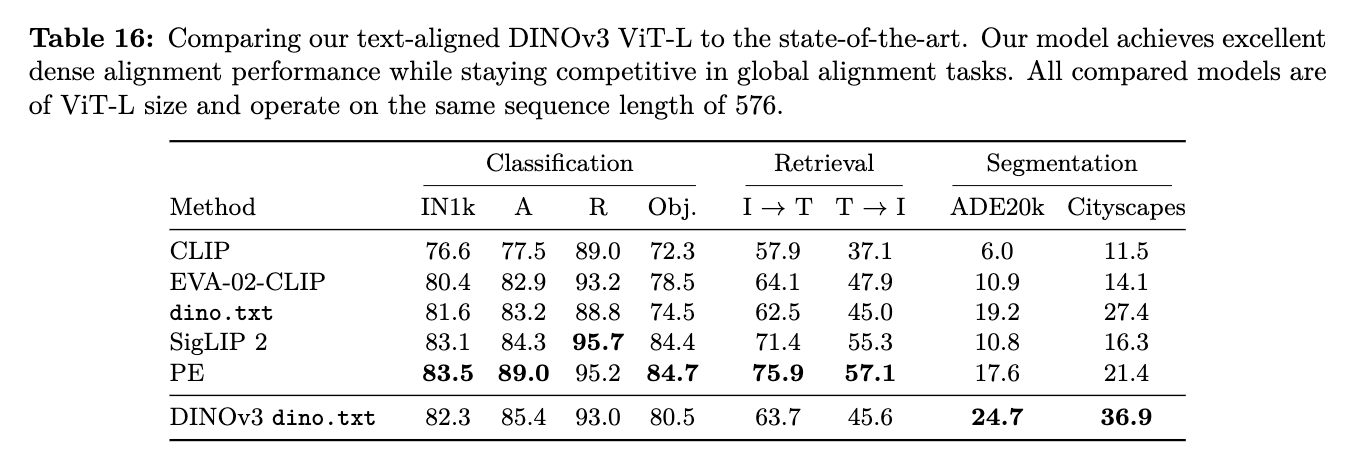
-
-
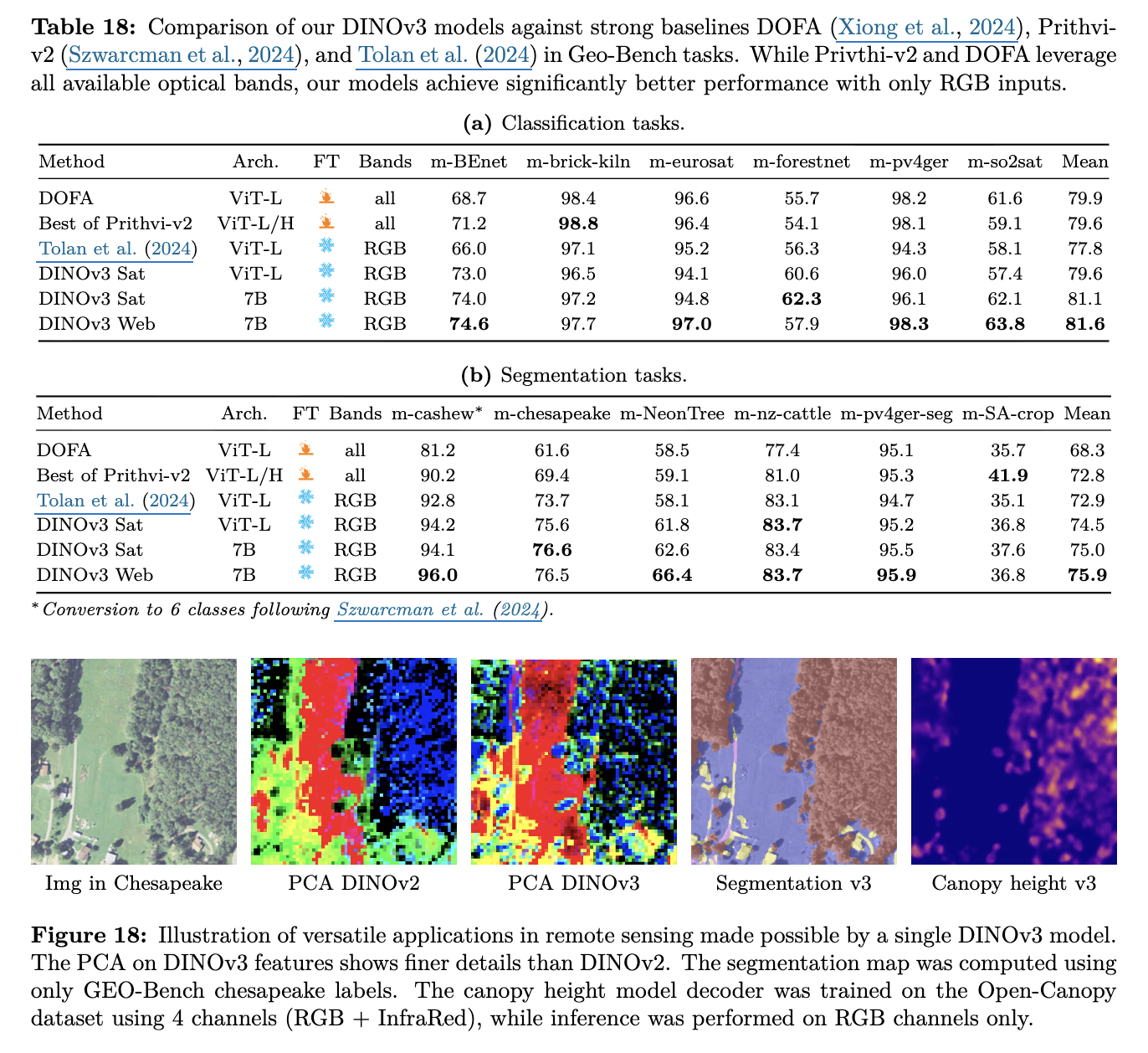
DINO in GeoSpatial Data
-
Pretraining을 SAT-493M 데이터셋을 기반으로 Gram anchoring, high-resolution fine-tuning 적용함 (DINOv3-SAT)
-
Canopy Height Estimation
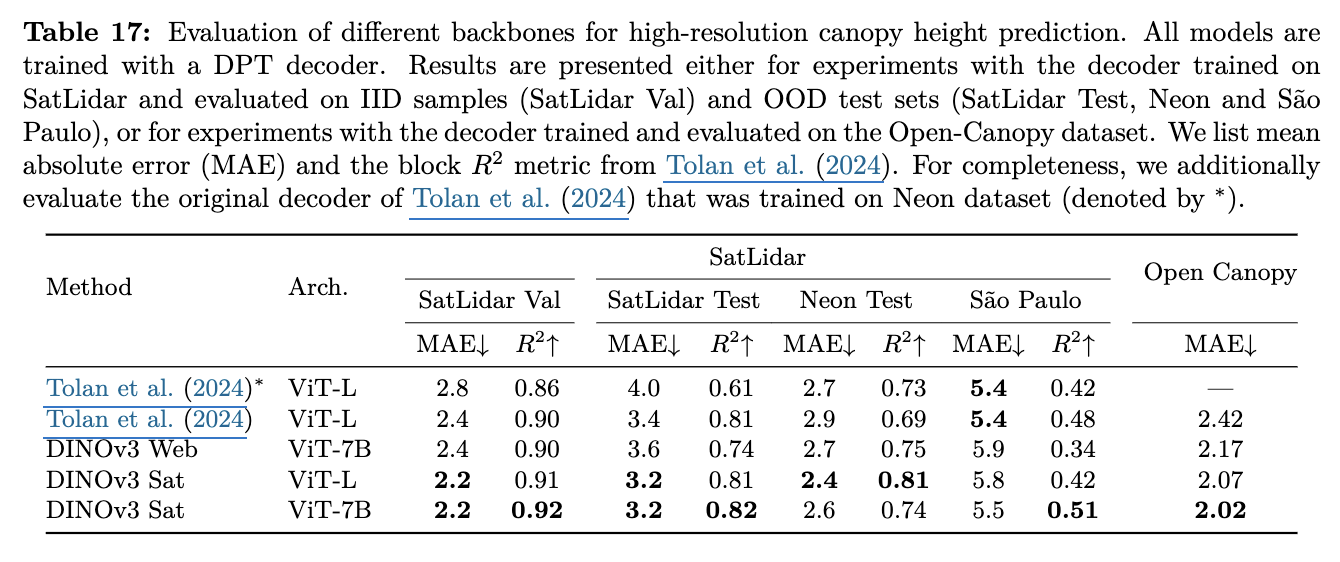
- DINOv3-Sat > DINOv3-Web : Domain Specific Pretraining의 중요성을 뒷받침
-
Earth Observation

-
+——————————-+———————-+————————————————————+——————————————–+ | Downstream task | 권장 모델 | 근거 | 실무 권장사항 | +——————————-+———————-+————————————————————+——————————————–+ | 이미지 분류 (global) | DINOv3-web | 대규모 자연/웹 이미지 분포에서 학습 → 전역적 표현 우수 | 일반 웹/사진 도메인에 기본 사용 | +——————————-+———————-+————————————————————+——————————————–+ | 인스턴스 검색 / retrieval | DINOv3-web | 글로벌 CLS 토큰 임베딩과 광범위 데이터로 인스턴스 특성 포착 | 박물관/랜드마크/상품 검색 등 자연 이미지용 | +——————————-+———————-+————————————————————+——————————————–+ | 일반 물체 검출 (COCO류) | DINOv3-web | 전역+지역 특징의 균형, 다양한 자연 이미지에 강함 | frozen backbone으로도 높은 성능 기대 | +——————————-+———————-+————————————————————+——————————————–+ | 고해상도 세그멘테이션 (자연) | DINOv3-web / DINOv3-sat* | web도 좋으나 입력 해상도·도메인 특성에 따라 달라짐 | 자연 사진이면 web 우선, 매우 고해상도이면 sat 고려 | +——————————-+———————-+————————————————————+——————————————–+ | 항공/위성 세그멘테이션 | DINOv3-sat | 고해상도·반복 텍스처 특성 → Gram anchoring+HR 적응 효과 큼 | 도로/건물/토지피복 등 원격탐사 전용으로 권장 | +——————————-+———————-+————————————————————+——————————————–+ | 정밀 패치 매칭 / 3D 대응 | DINOv3-sat (고해상도) | Gram anchoring으로 패치 수준 consistency 보존 → 고해상도 매칭에 유리 | 고해상도 포인트 매칭/정합 시 sat 권장 | +——————————-+———————-+————————————————————+——————————————–+ | 모노큘러 깊이(일반/실험실→실세계) | DINOv3-web | DAv2 연계 결과: sim→real 전이 능력 (자연/실내/도로 등) | 합성 데이터 기반 학습 파이프라인과 결합 권장 | +——————————-+———————-+————————————————————+——————————————–+ | 원격탐사 대상 깊이/높이 추정 | DINOv3-sat | 해상도·스케일 특화 표현이 중요 → sat이 유리 | DEM/표고 관련 원격탐사 작업에 권장 | +——————————-+———————-+————————————————————+——————————————–+ | 비디오 세그멘테이션/트래킹 | DINOv3-web | 시공간적 일반화 능력과 웹 비디오 특성에 강함 | 영상 일반(유튜브, 대중 영상)엔 web 우선 | +——————————-+———————-+————————————————————+——————————————–+ | 위성 시계열/변화 탐지 | DINOv3-sat | 도메인 특화된 텍스처·스펙트럼에 민감 → sat에서 더 잘 포착 | 시계열 안정성 필요한 서비스엔 sat 권장 | +——————————-+———————-+————————————————————+——————————————–+ | 혼합 도메인(예: 도시 모니터링) | 둘의 앙상블 또는 라우팅 | 서로 강점이 달라 앙상블/도메인 감지 후 라우팅이 실용적임 | 입력 도메인 자동감지 + 모델 선택 권장 | +——————————-+———————-+————————————————————+——————————————–+