[MM] Interpreting CLIP’s Image Representation Via Text-based Decomposition
[MM] Interpreting CLIP’s Image Representation Via Text-based Decomposition
- paper:https://arxiv.org/pdf/2310.05916
- https://github.com/yossigandelsman/clip_text_span
- ICLR 2024 spotlight (인용수: 11회, ‘24-06-07 기준)
- downstream task: T2I retrieval, Zero-shot segmentation
1. Motivation
- CLIP을 더 잘 이해하기 위해 분석해보자!
- CLIP-ViT는 head별, image patch별, layer별 output의 합으로 구성되어 있음 $\to$ 해당 output을 decoupling해 보면 어떨까?
- Joint text-image space로 align되어 있음 $\to$ Base가 되는 Text로 각 output을 span할 수 있지 않을까?
2. Contribution
- CLIP의 성능에 영향을 미치는 layer들을 분석함 $\to$ 마지막 4개 layer 외에 다른 layer output은 mean-ablation (mean값으로 output을 대체)해도 성능에 영향을 안끼치는 것을 통해 확인함
- Chat-GPT3.5 기반으로 prompting하여 이미지별로 base text를 추출하여 만든 TEXTSPAN이라는 text caption dataset을 꾸림 $\to$ 이를 통해 CLIP-VIT의 layer별, head별, image patch별로 학습된 attribute을 text 형태로 분류함
- Spurious correlation 을 mean-ablation하여 제거함으로써 Zero-shot classification을 향상시키고, image patch별로 text에 따라 attention하는 weight를 visual하게 보임으로써 zero-shot segmentation 에서 SOTA를 보임
3. CLIP-Interpret
-
Preliminaries : CLIP은 contrastive learning기반으로 image & text를 학습함
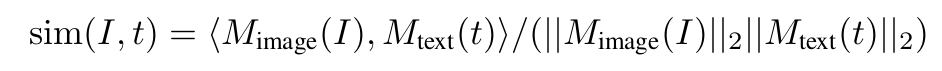
-
Image representation
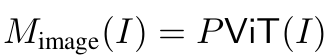

-
-
overall architecture
-
Fine-grained decomposition을 heads / positions에 따라 수행하면 위의 식은 아래와 같이 표기됨
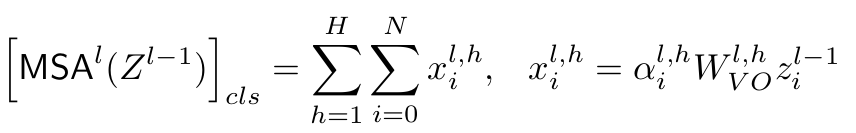
- H: head의 갯수
- N: image patch의 갯수
- $\alpha$: attention weight $\in \mathbb{R}$
- $W_{VO}$: transition matrix $\in \mathbb{R}^{d \times d}$
-
위 식에 Projection layer P를 곱해 Image output를 계산하면
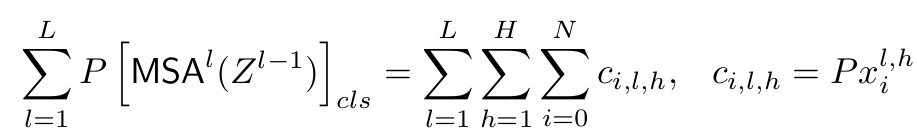
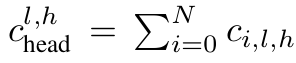
-
-
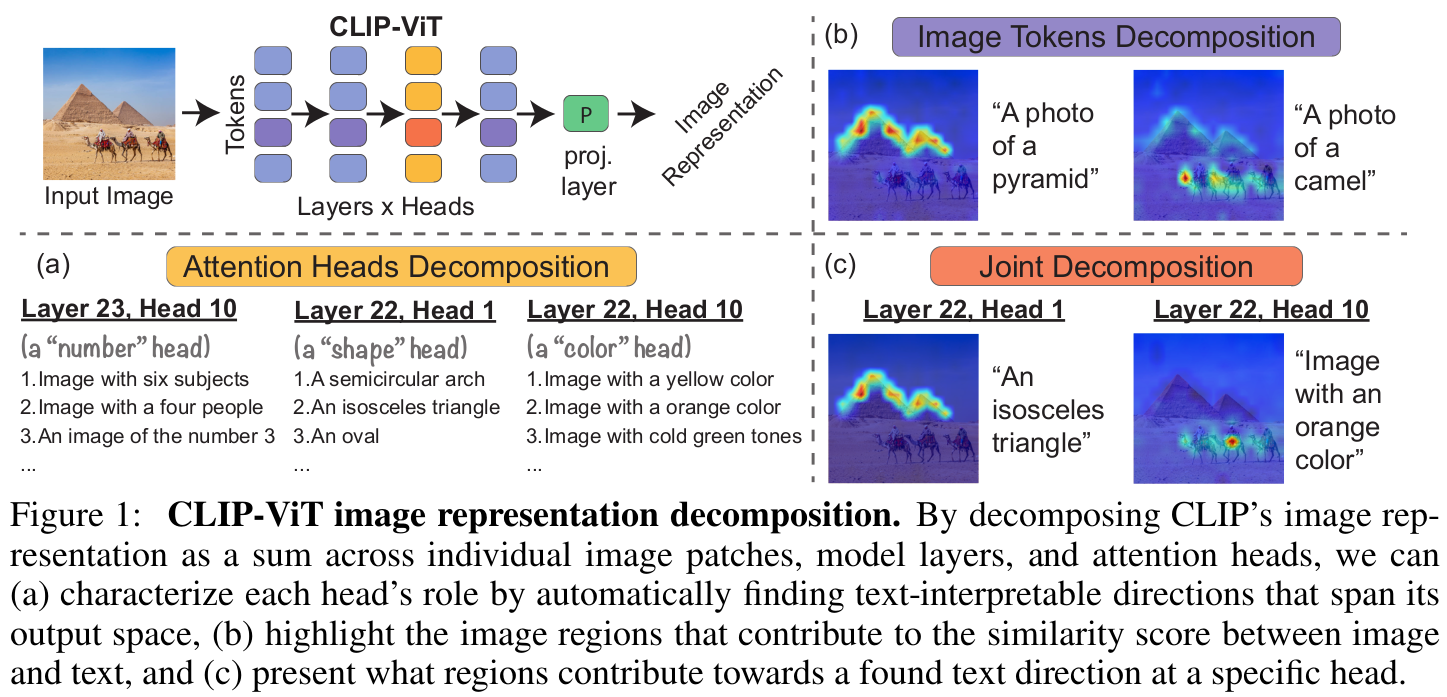
Attention head에 따라 decompose를 수행
-
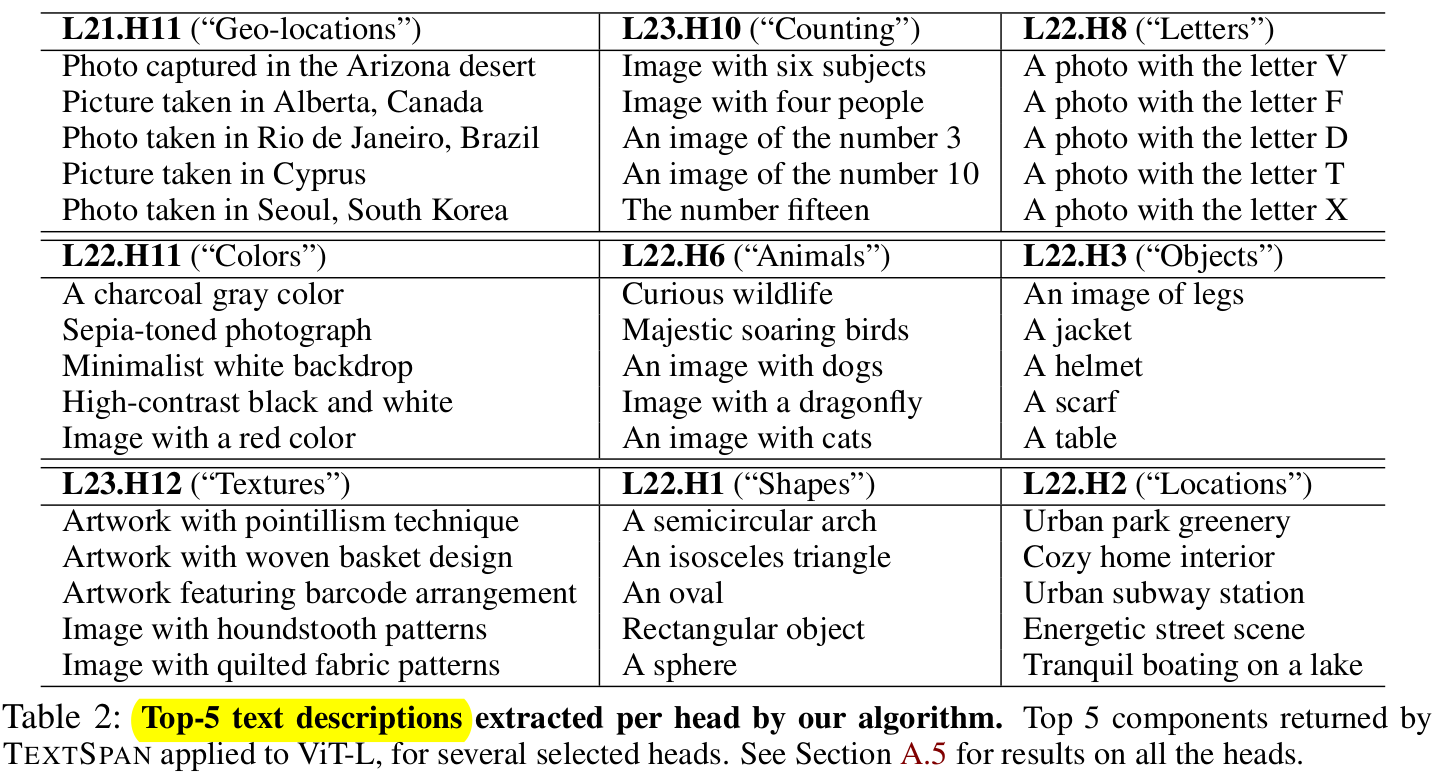
TEXTSPAN: Chat-GPT 3.5로 아래와 같은 prompt를 기반으로 3,498개의 caption을 image별로 생성한 뒤, 해당 caption과 CLIP-ViT의 layer별, head별 Top-5 similarity 를 계산하여 Top-5 base text를 추출한 결과임

-
TEXTSPAN을 추출할 때 사용한 prompt

-
TEXTSPAN 알고리즘

-
Var: Text description T collection 중, K개의 image들의 output similarity score의 분산
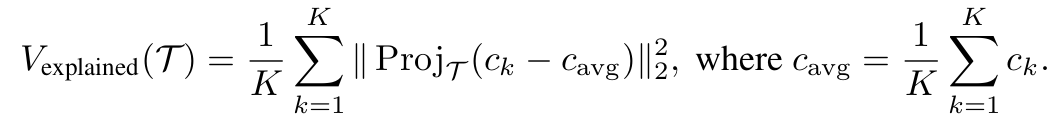
-
$c_k$: k번째 이미지의 해당 head, attention head의 CLIP-ViT output
$\to$해당 분산 값을 maximize하는 m개의 description을 T에서 추출
-
Variance가 max가 되는 text에 대해 orthogonal한 방향으로 image output C, $C’$가 움직이도록 업데이트
-
-
-
-
4. Experiments
-
CLIP-ViT의 representation에 영향을 주는 layer를 뽑기 위해 60개의 description을 head별로 할당하고 accuracy를 측정함

$\to$이를 random text와 가장 많이 쓰이는 단어로 similarity score를 추출한 결과와 비교해도 성능이 좋았음 $\to$ TEXTSPAN이 유효함
-
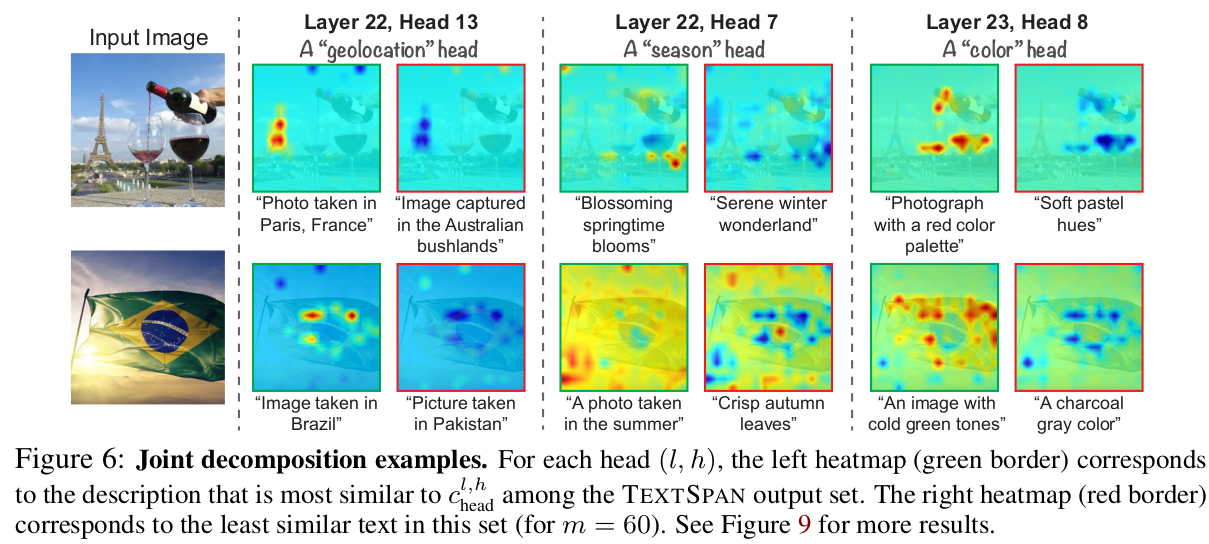
TEXTSPAN으로 뽑은 attention head 별, layer별 Top-3 image

-
Applications
-
Spurious correlation 제거 후 Waterbird dataset zero-shot classification 성능
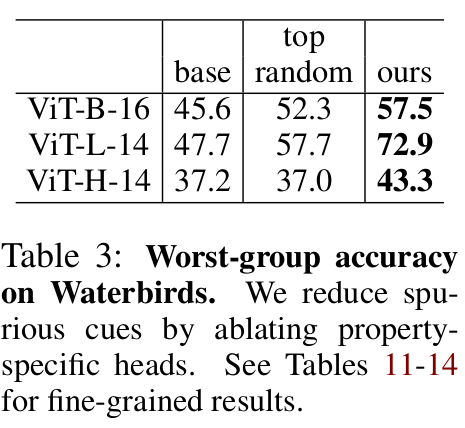
-
Property 기반 image retrieval

-
-
Image token기반 decomposition $\to$ XAI 효과
-
ImageNet의 zero-shot segmentation
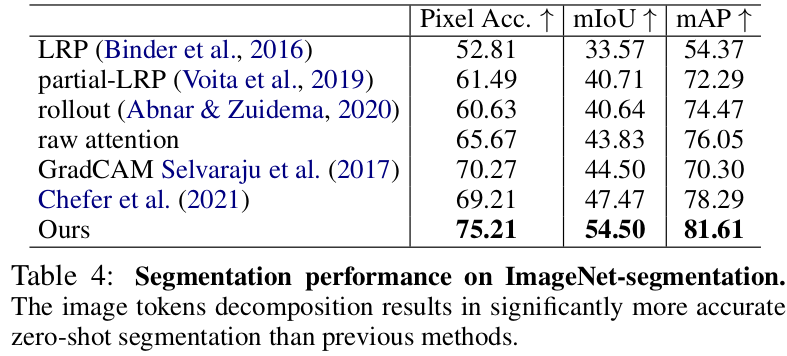
-
-
Image patch + property 별 joint decomposition 결과