[SSL][SS] AllSpark: Reborn Labeled Features from Unlabeled in Transformer for Semi-Supervised Semantic Segmentation
[SSL][SS] AllSpark: Reborn Labeled Features from Unlabeled in Transformer for Semi-Supervised Semantic Segmentation
- paper: https://arxiv.org/pdf/2403.01818.pdf
- github: https://github.com/xmed-lab/AllSpark
- CVPR 2024 accpeted (인용수: 0회, ‘24-03-06 기준)
- downstream task: SSL for SS
1. Motivation
-
기존 SSL은 label data, unlabel data flow를 분리하여 학습함 $\to$ labeled data에 dominate되어 학습되다 보니, validation set, unlabeled set에서 성능저하 발생
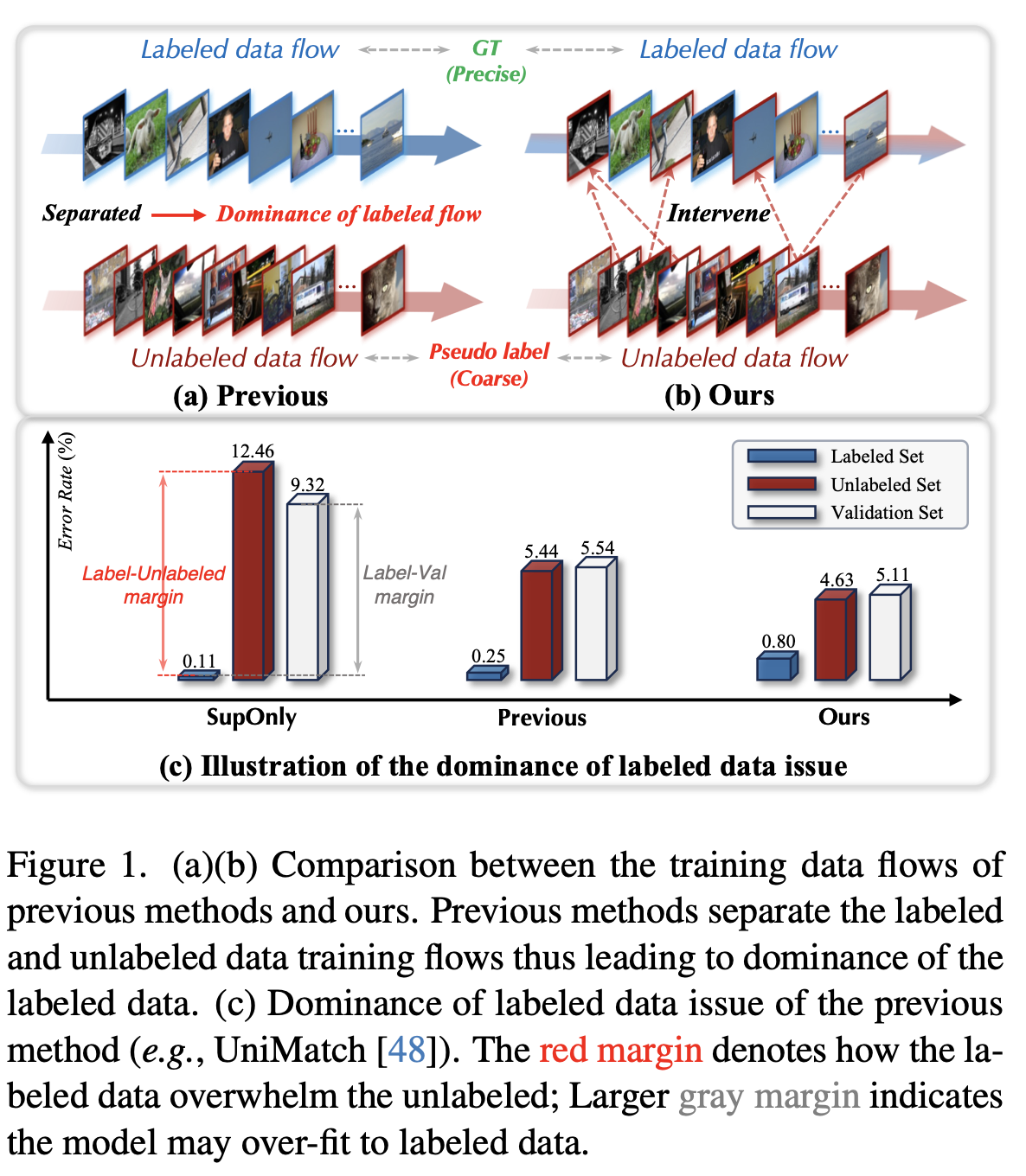
-
방대한 양의 unlabeled data의 feature를 기반으로 labeled feature를 reborn시키면 더 좋지 않을까?
2. Contribution
-
Label/Unlabel을 분리하여 학습하는 기존 방식의 SSSS (Semi-supervised Semantic Segmentation)이 labeled data의 dominate issue로 인인해 validation set, unlabeled set에서 성능하락이 발생함을 발견함
-
label data dominate issue를 해결하는 AllSpark 방법을 제안함
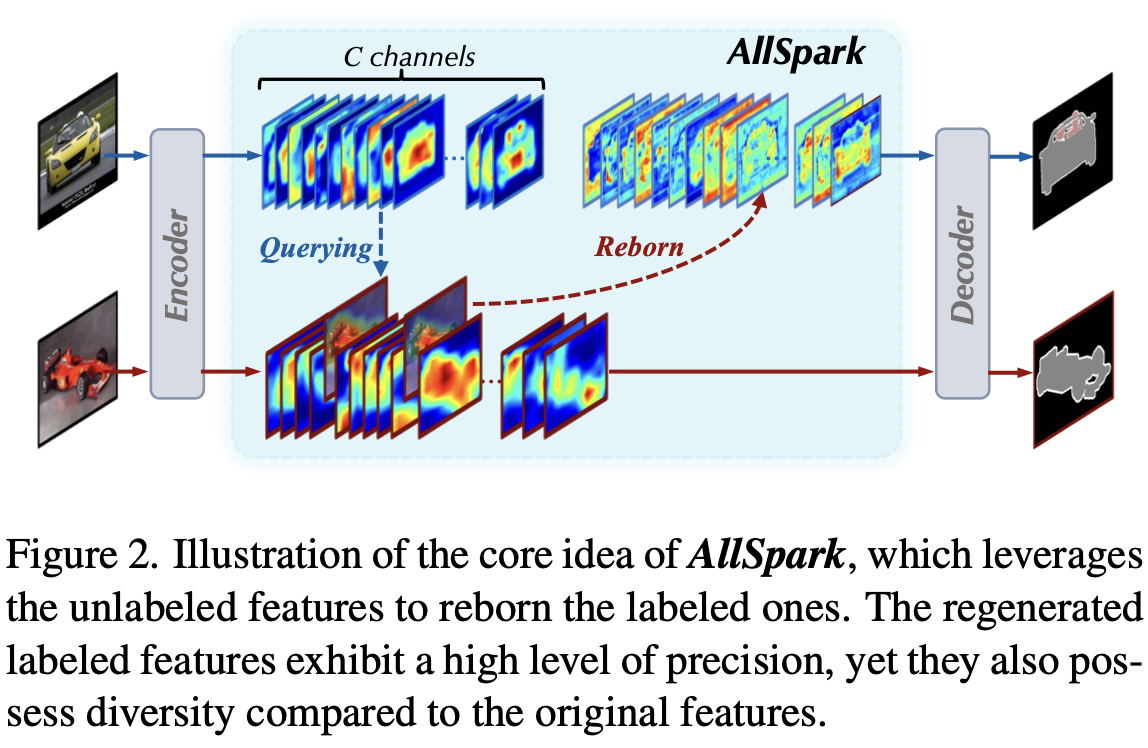
- SAM, Transformer계열에 Unlabeled feature와 labeled feature간 Channel-wise Cross-Attention 을 이용해서 labeled feature를 reborn시킴 (CNN계열은 RoI가 작아 안됨)
- query: labeled feature
- key, value: unlabeled feature
- channel-wise cross attention: class별 similarity가 높은 channel에 가중치를 주어 labeled feature를 reborn
- Semantic Memory를 활용하여 unlabeled data의 mini-batch space를 확장시킴
- First In First Out (FIFO)구조로, 클래스간 균일하게 unlabeled feature를 저장 (channel-wise semantic grouping strategy)
- SAM, Transformer계열에 Unlabeled feature와 labeled feature간 Channel-wise Cross-Attention 을 이용해서 labeled feature를 reborn시킴 (CNN계열은 RoI가 작아 안됨)
-
SSSS benchmark에서 SOTA
3. AllSpark
-
Overall Architecture
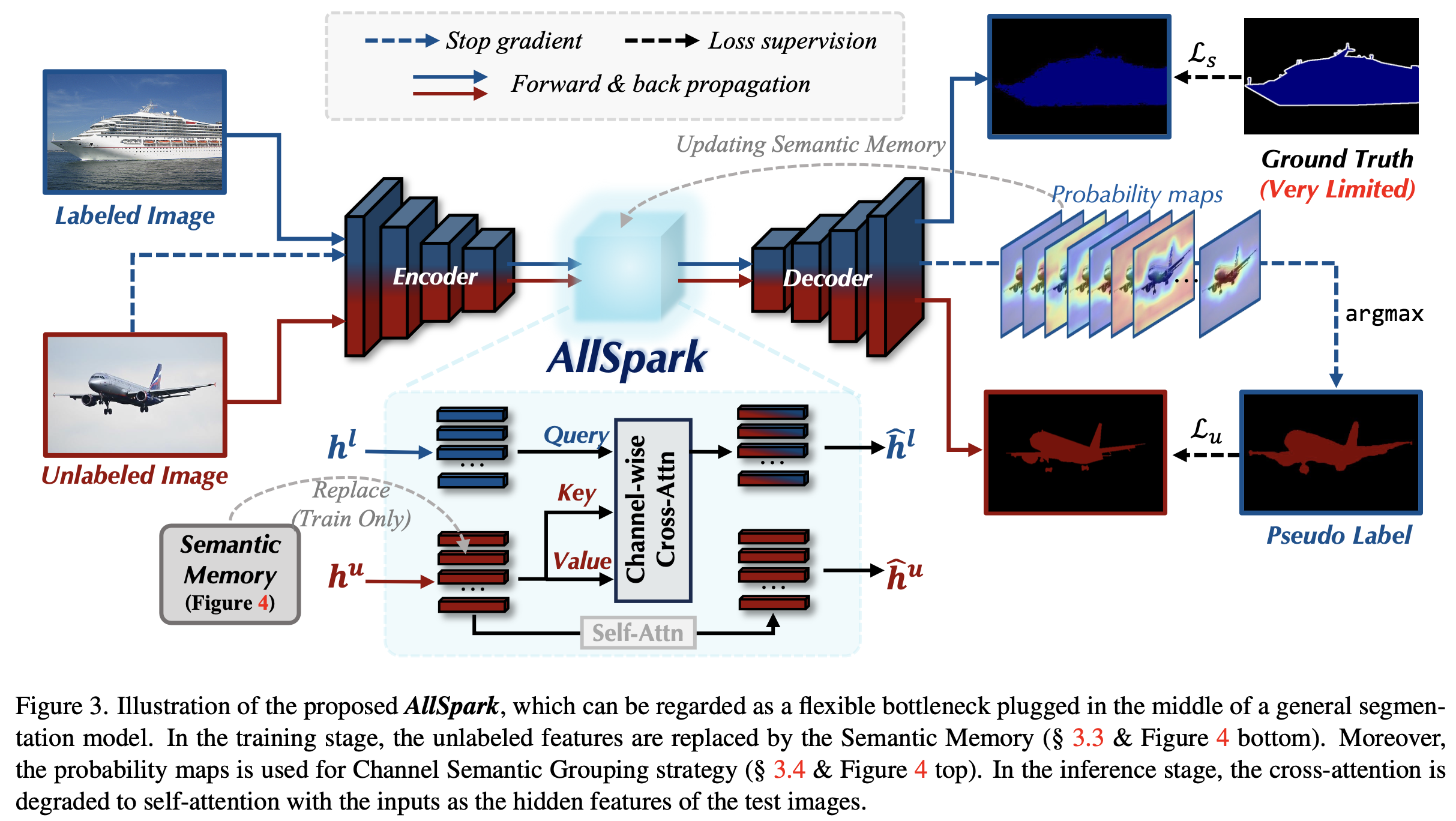
-
baseline
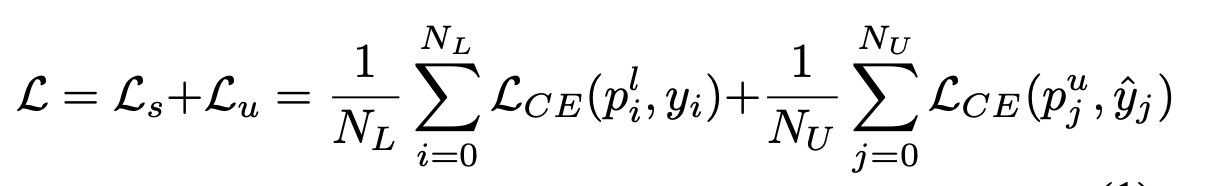
-
Channel-wise Cross-Attention
-
가정: feature는 channel별로 different semantic을 저장함
-
channel-wise feature는 contextual information을 가지고 있음

- image당 highlight된 영역이 1개의 특정 channel의 feature를 의미함
-
unlabeled feature중 유사한 contextual information을 갖는 channel에 가중치를 주어 labeled feature를 reborn시킴
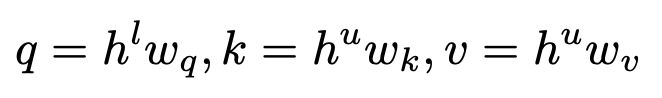
-
query: labeled feature (h: hidden)
-
key, value: unlabeled feature
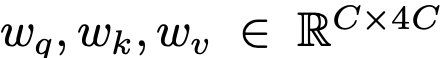
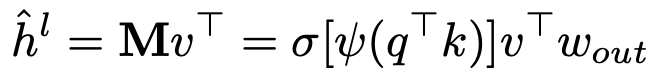
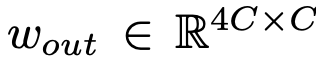
-
$\psi$: instance normalization
-
$\sigma$: sigmoid
$\to$ channel-wise attention은 long-range dependencies로 잡을 수 있음
-
-
-
-
Semantic Memory
-
mini-batch단위로 unlabeled feature를 추출하면, 효율적으로 labeled feature를 reborn시키기에 불충분한 정보를 갖게됨
-
Semantic meaning을 갖는 memory를 활용함
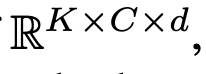
- K: class 갯수
- C: channel dimension
- d: patch갯수
-
-
-
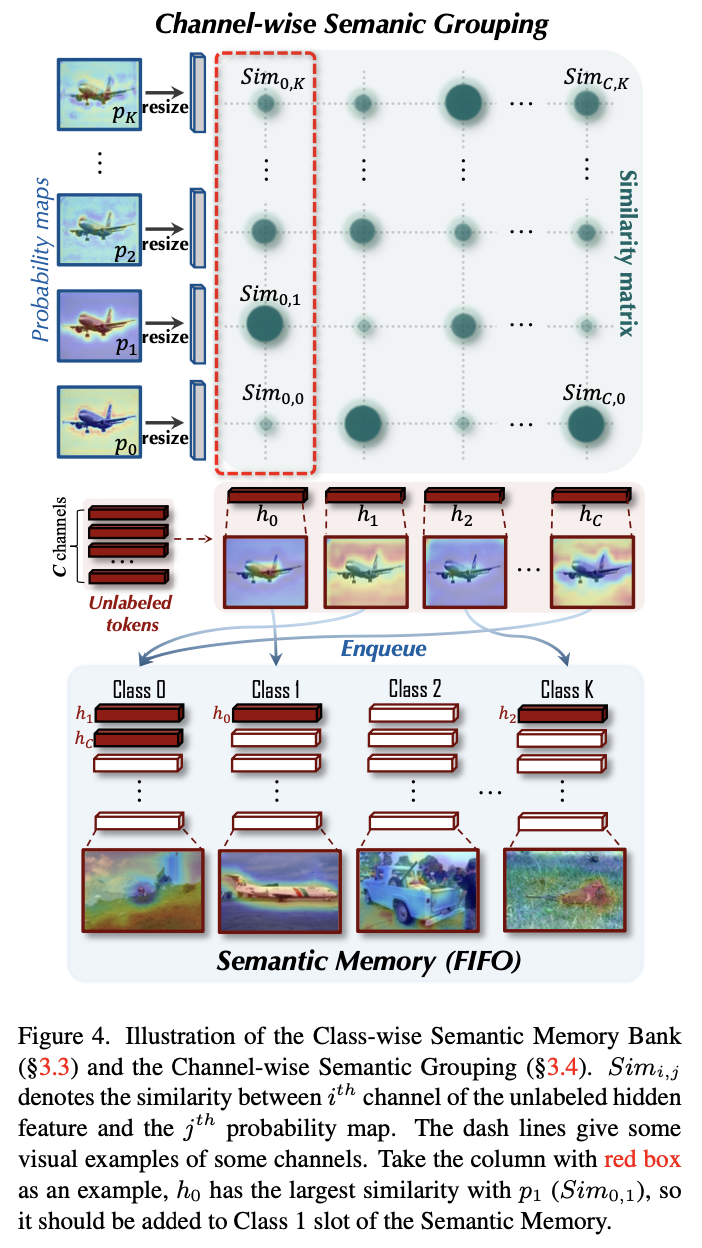
Channel-wise Semantic Grouping
-
unlabeled feature $h^u \in \mathbb{R}^{C \times d}$ 와 probability map $p \in \mathbb{R}^{K \times H \times W}$ 을 resize시킨 probability token $\hat{p} \in \mathbb{R}^{K \times d}$ 간의 Similatiry map $Sim \in \mathbb{K \times C}$를 기준으로 grouping
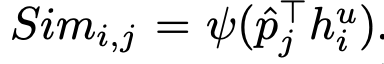
- $\psi$: instance normalization
- $\hat{p}_j$: j번째 class index에 해당하는 probability token $\in \mathbb{R}^{K \times d}$
- $h_i^u$: unlabeled feature중 i번째 channel
- $Sim_{i,j}$ : i,j번째 similarity score. 해당 channel의 similairty score가 K개중 j가 제일 높을 경우, 해당 memory로 enque.
-
-
Algorithm

4. Experiments
-
pascal voc
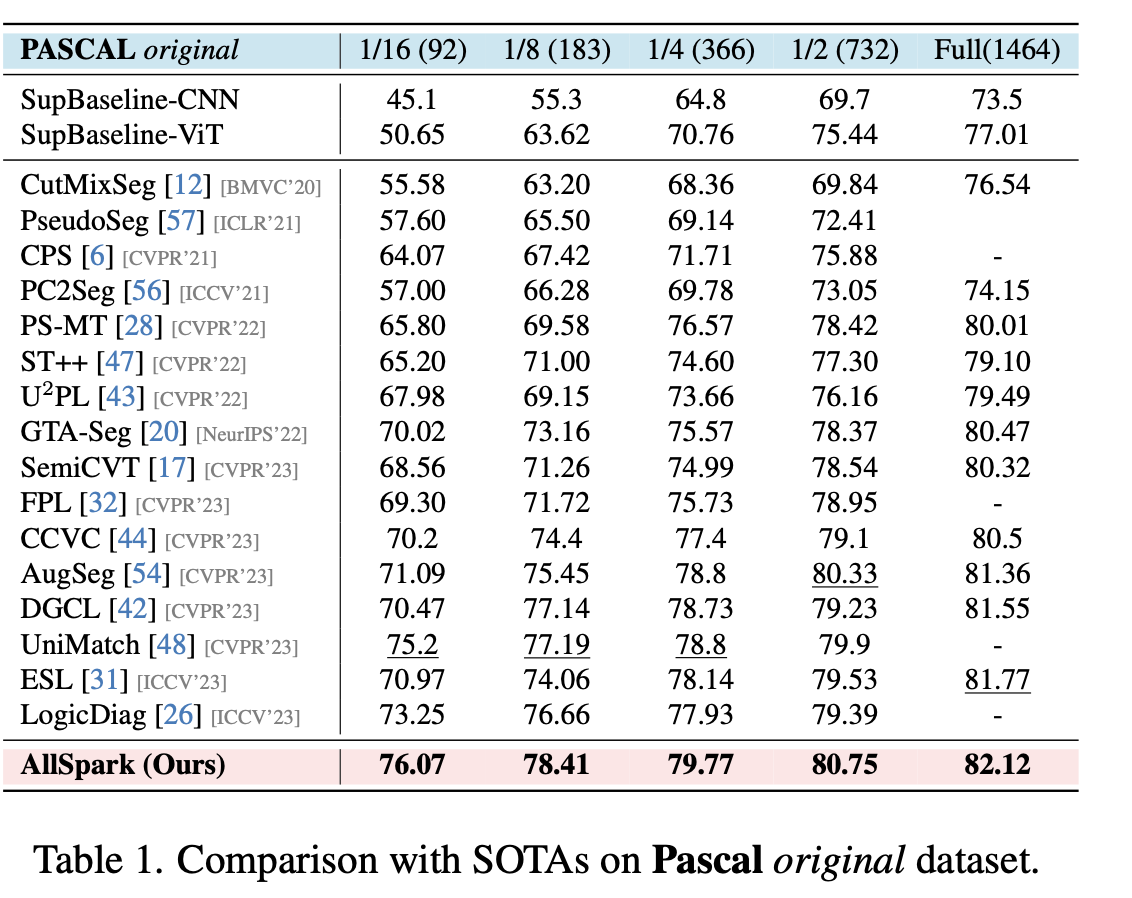
-
cityscapes
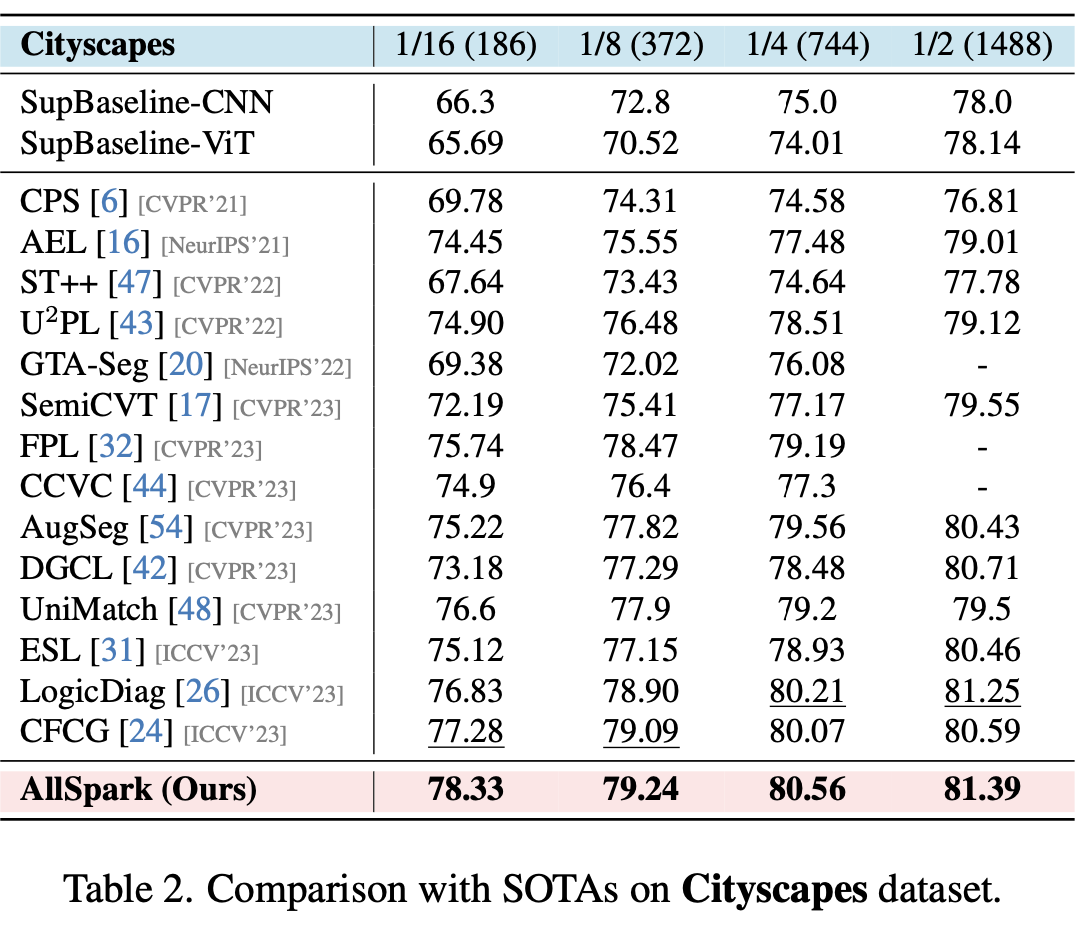
-
augmented pascal
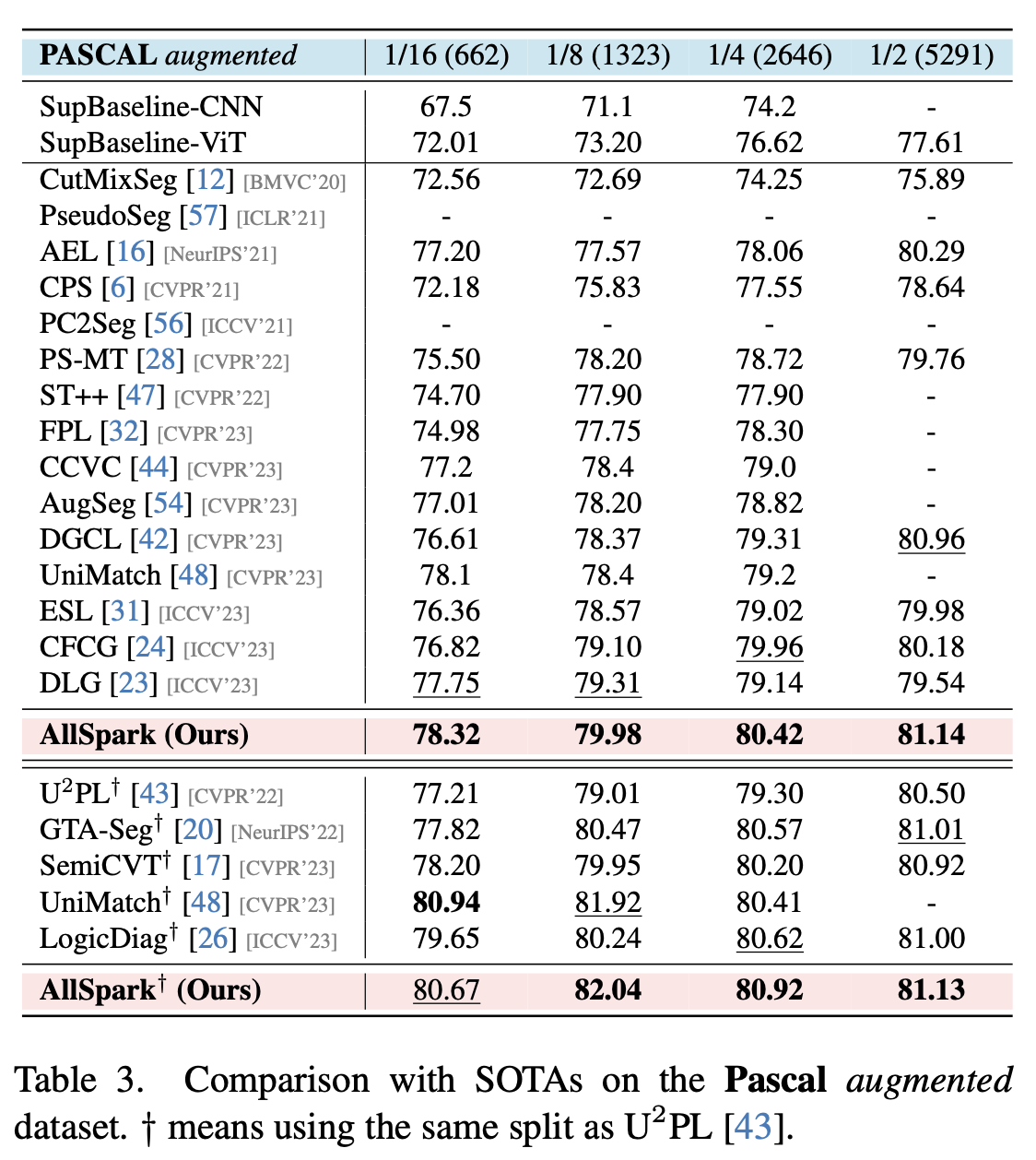
-
ms-coco
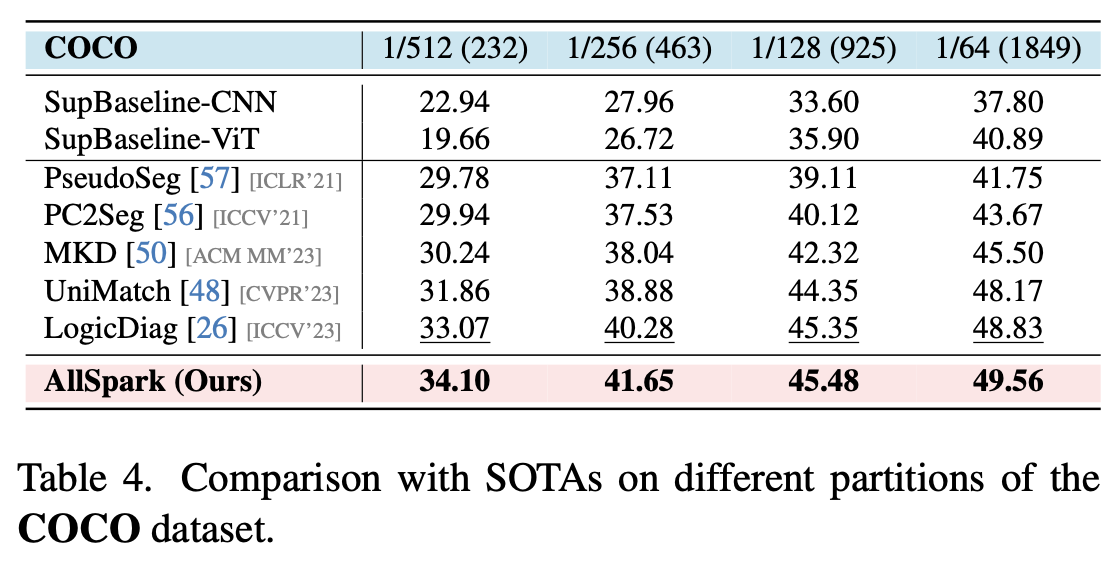
-
ablation
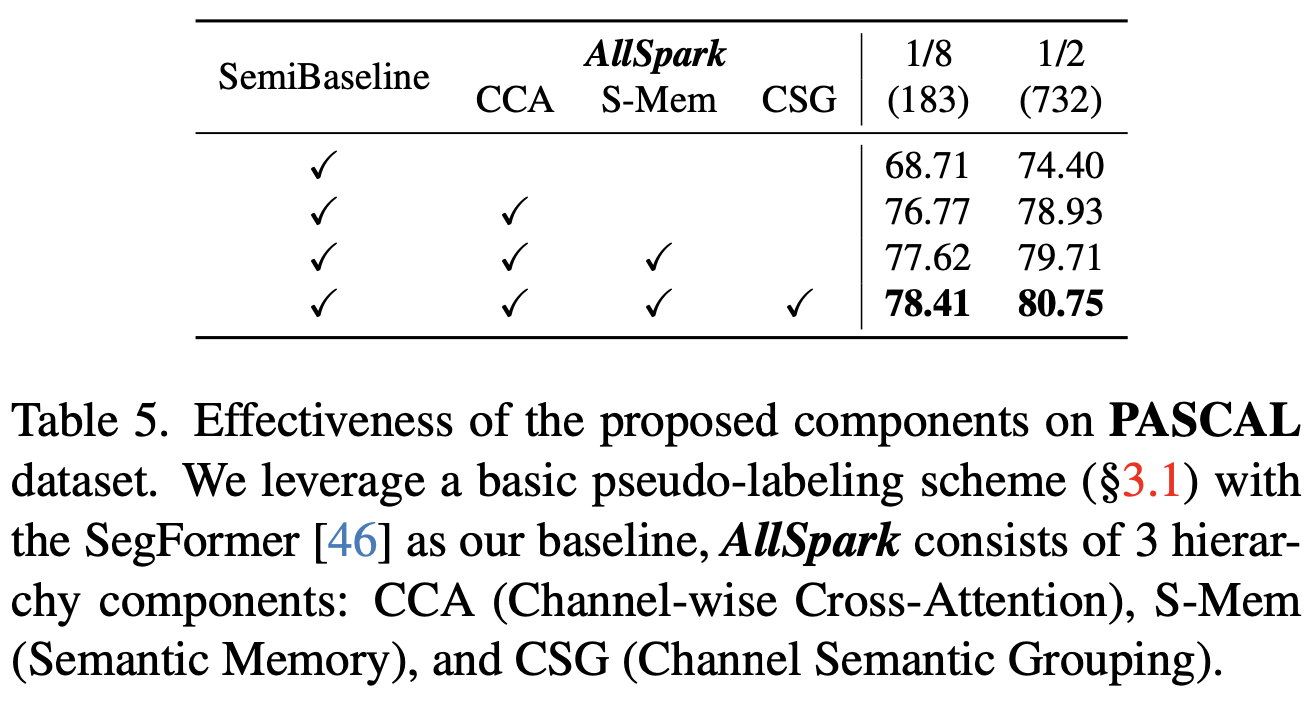
-
before/after allspark Visual result

- Allspark 적용한 것이 channel별로 동일 context(object)간에 구분이 잘되어 있음
-
channel-wise semantic grouping의 유효성
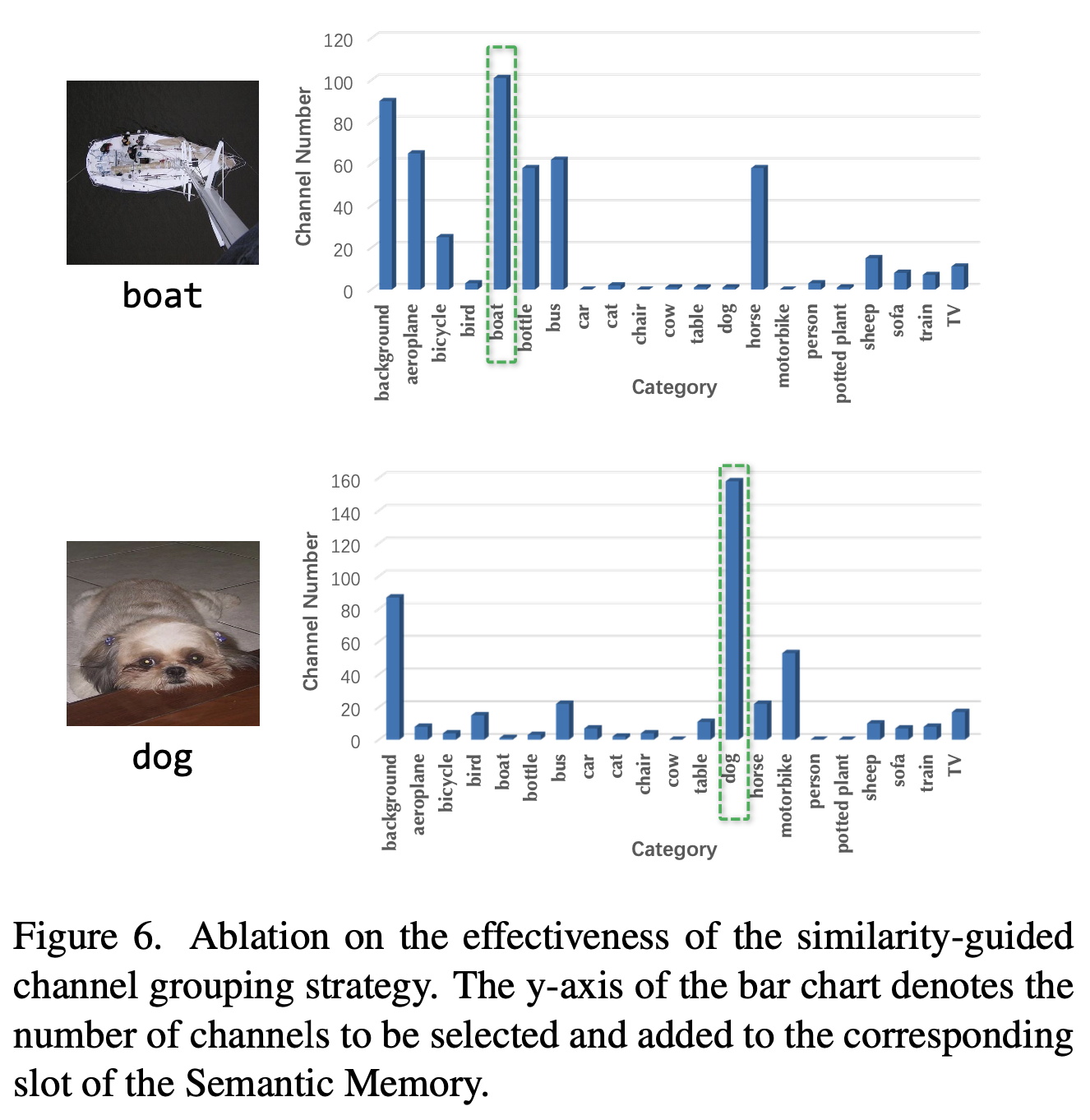
- 채널별 고르게 selected되었으므로, channel-wise semantic grouping strategy가 유효함
-
Different backbone에도 적용
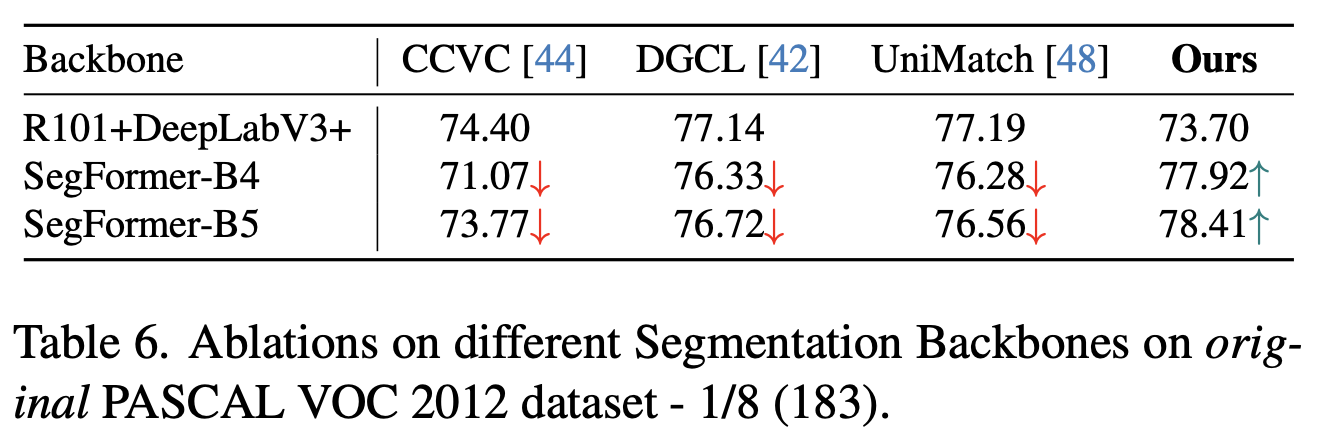
-
CNN계열 빼곤 모두 오름

- CNN계열은 RoI가 적기에 Channel-wise attention이 유효하지 않게됨
-
-