A Survey of WebAgents: Towards Next-Generation AI Agents for Web Automation with Large Foundation Models
[WebAgent] A Survey of WebAgents: Towards Next-Generation AI Agents for Web Automation with Large Foundation Models
- paper: https://arxiv.org/pdf/2503.23350
- KDD 2025 accepted (인용수: 5회, ‘25-05-18 기준)
- 3가지를 중점적으로 다루는 survey
- architectures
- training
- trustworthiness
1. Introduction
-
Webagent가 필요한 이유
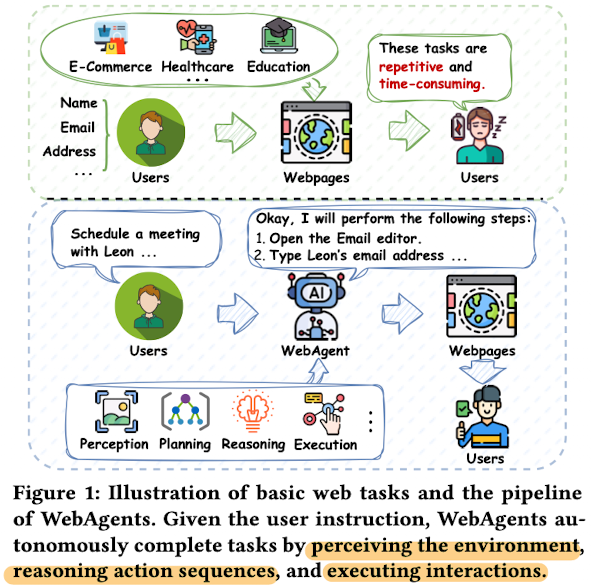
-
다양한 플랫폼에 계좌를 등록하거나, 지원 양식을 작성하는 등의 반복적, time-consuming한 일상 업무를 수행하고 있음.
$\to$ 요새 powerful해진 LFM (Language Foundation Model)을 힘입어, 단순 반복적인 일상의 task를 AI에게 수행하게 하면 어떨까?
-
-
Architecture
- Webagent의 3가지 과정 소개 (perception, planning, execution)
-
Training
- Webagent의 2가지 핵심 관점 소개 (data, training strategies)
-
Trustworthy
- safety, robustness, privacy, 그리고 generalizability에 대한 소개
-
Future research direction 소개
2. Background
- 다양한 domain에서 webagents가 두각을 나타내고 있음
- medicine, finance, education
2.1 RL-based Agents
- AI agents는 Environment와 상호작용을 통해 reward signal을 얻어 강화학습을 수행함
- value function optimization $\to$ Q-Learning
- policy optimization $\to$ Policy gradient
- policy(model)를 직접적으로 gradient update을 수행함 $\to$ continuous action spaces, high-dimensional complex task에 유리
2.2 LFM-based Agents
-
Large Foundation Model의 rich intrinsic knowledge를 활용하여 human-like intelligence + rich open-world knowledge를 달성함
ex. WorldCoder: environment과 상호작용하기 위한 code를 생성하는 ai agent
2.3 AI Agents for Web Automation
-
구성요소
- instruction T (“Please help me buy a T-shirt”)
- website S (e.g., an online shopping site)
- executable action space $\mathbb{A}={a_1,a_2,…,a_n}$
-
수식
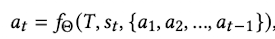
-
observation $s_t$: t step에서 관찰한 환경 정보 (ex. HTML, screenshot)
-
next action $a_t$: t step에서 수행할 action
-
${a_1, a_2, …, a_{t-1}}$: Short-term memory에서 in-context learning으로 넣어줄 이전 step들에서 수행한 action.
-
$f_{\Theta}$: LFM model
$\to$ next action $a_t$를 통해 human-like behavior를 수행하고, 새로운 t+1 step의 환경으로 업데이트
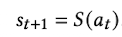
-
3. Webagent Architectures
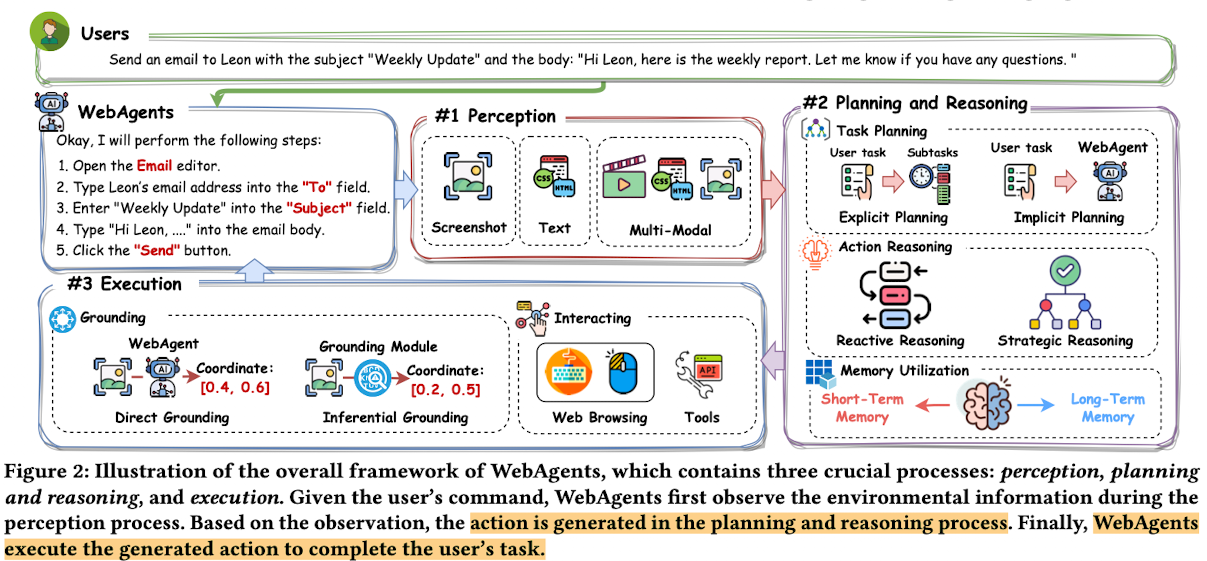
- User command를 성공적으로 수행하기 위해 AI agent는 3가지 과정이 필요함
- perception: 현재 환경을 정확하게 인지해야함
- planning & reasoning: 주어진 user command와 environment를 고려하여 합리적인 next action을 reasoning해야함
- execution: 해당 action을 통해 environment과 상호작용해야 함
3.1 Perception
-
User prompt에 따라 인식해야하는게 달라짐
ex. User prompt T=”Youtube를 열고, 비디오를 켜줘” $\to$ web browser의 address bar를 인지하고, www.youtube.com을 입력해서 비디오를 play해야함.
-
세 가지 카테고리로 논문들이 다루고 있음
- Text-based
- Screenshot-based
- Multi-modal
3.1.1 Text-based Webagents
- webpage의 metadata를 HTML 혹은 accessibility tree형식으로 다룸
- MindAct
- 2-stage approach
- finetuned Small LM + LLM $\to$ 효율적으로 large HTML document를 처리함
- HTML-T5
- self-experience로부터 학습하는 LLM-driven agent
- task-relevant snippets로 HTML document를 요약하여 environemtn information 추출 $\to$ user instruction을 subtask로 쪼개어 효울적으로 planning
- MindAct
3.1.2 Screenshot-based Webagents
- Web GUI (Graphic User Interface)가 본래 human cognitive process에서 visual한 특성을 지니도록 구현되었으므로, textual metadata만으로는 human-like 인지가 어려움
- Text metadata는 Web 환경에 따라 매우 다양하기 때문에 일반화 성능이 안좋고, 계산량이 증가함
- 강력한 VLM (Vision Language Model)의 등장으로 복잡한 visual interface에 대한 이해가 가능해짐
- OmniParser
- user interface screentshot을 효율적으로 추출하여 structured element로 바꾸어 GPT-4V의 ground actions on regions를 통해 action을 예측
- OmniParser
3.1.3 Multimodal Webagents
- Screenshot + Web의 textual content 이용
- WebVoyager
- Set-of-Mark prompting으로 webpage내 요소의 bbox를 그리어 agent의 decision-making 능력 & acition prediction 능력 향상
- WebVoyager
3.2 Planning and Reasoning
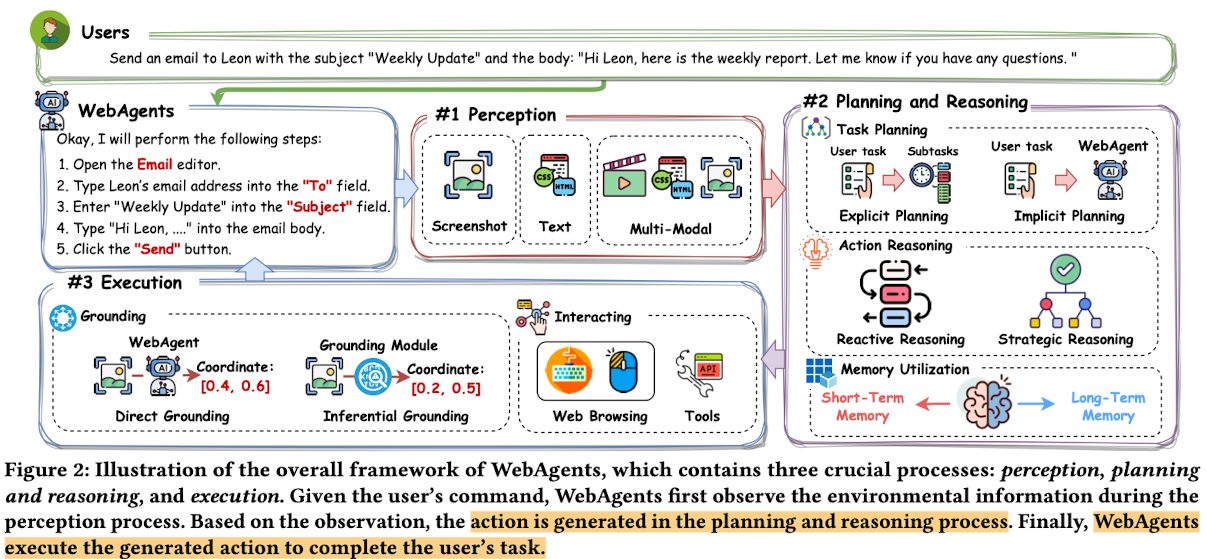
- User의 command에 합당한 action을 수행하기 위해 3가지 과정이 필요함
- Task Planning: User의 command를 reorganizing하여 sub-objectives를 구성하는 단계
- Action Reasoning: user의 command를 성공시키기 위해 적절한 action을 생성하도록 Webagent를 guide하는 단계
- Memory Utilization: internal information (ex. previous action)과 external information (ex. web search)를 통해 적합한 action을 예측하는 단계
3.2.1 Task Planning
-
Explicit Planning
-
user instruction T를 여러 sub-tasks로 쪼개어 action들이 step-by-step으로 수행하도록 함
ex. ScreenAgent는 1) describe the screenshot 2) function-call format으로 next action을 생성 3) reflection phase에서 proceed/retry/reformulate the plan 여부를 결정
ex. OS-Copilot은 1) user instrcution T를 통제가능한 subtask로 쪼개고 2) external information에서 필요한 정보를 검색 3) DAG graph 형태로 plan을 구조화하여 병렬처리함으로써 multi-task를 효율적으로 처리함
-
-
Implicit Planning
-
직접적으로 user instruction T + environment observation 를 LLM에 집어넣음. (no task decomposition)
ex. WISE는 filtered DOM (Document Object Model) elements를 집어넣어 action을 생성함
ex. OpenWebAgent는 Web Processing Module을 통해 HTML element를 simplify + OCR engine + interactive element를 annotate하여 Action Generation Module에서 next action을 예측함
-
3.2.2 Action Reasoning
-
Reactive Reasoning
-
추가적인 operation을 하지 않고, 단순하게 input instruction에 대한 반응 (next action)을 예측
ex. ASH는 full webpage를 요약하는 SUMMARIZER prompt를 처음으로 도입하여 action-aware observation을 수행. Action reasoning phase에서는 해당 관측값을 토대로 ACTOR prompt을 사용하여 next action 예측
-
-
Strategic Reasoning
-
추가 operation을 소개하는 경우가 많음
-
exploration process
ex. WebDreasomer는 후보 action에 대해 simulation을 수행하고, 예측된 outcome을 탐험하여 매 step별 최적의 action을 선택하도록 함
-
in-context information
ex. Auto-intent는 previous action + observation에서 비지도학습 기반 여러개의 target domain demonstrations로부터 compact intent를 추출함. Top-k predicted intent를 통해 in-context hint를 얻어 action generation에 사용
-
-
3.2.3 Memory Utilization
-
Short-Term Memory
- previous actions $\to$ 반복적인 operation을 방지하여 task completion efficiency를 보증함
-
Long-Term Memory
-
이전 step에서 수행한 execution tasks의 action trajectories
-
online search 결과, 등
ex. Agent-S는 success/fail trajectory를 저장하여 sub-tasks 생성에 참고함. 유사한 sub-task experience가 검색되어 action generator에도 사용됨.
ex. Synapse는 raw web state를 concise task-relevant observation으로 처리 후, Trajectory-as-Exemplar (TaE) prompting 전략을 통해 유사 trajectory를 검색해서 next action generation에 사용함.
-
3.3 Execution
- 두 가지 process
- Grounding
- LLM agent가 interaction해야하는 webpage 내 인식할 요소의 좌표를 찾는 과정
- Interaction
- 특정 action을 선택된 element에 수행하는 과정
- Grounding
3.3.1 Grounding
-
Direct Grounding
-
screenshot을 보고 후보 요소들의 coordinate를 직접 생성
-
HTML에서 interaction 해야할 element를 선택
ex. ShowUI는 action (ex. [CLICK])를 생성하고, 해당 좌표값을 직접 생성함
ex. AutoIntent는 HTML 요소를 in-context example로 활용하여 target element를 LLM이 action을 수행할 요소를 잘 선택하도록 가이드함
-
-
Inferential Grounding
-
extra auxiliary module를 통해 target lement의 위치값을 반환하도록 함
ex. Ponder & Press는 MLLM을 통해 high-level user instruction을 detailed action description으로 묘사하게 하고, 해당 description을 토대로 Screenshot 내의 target GUI element를 정확하게 선택함
ex. OSCAR는 visual & semantic grounding을 수행함. Visual grounding은 accessibility tree에 있는 bbox를 Set-of-Mark prompt로 추출함. Semantic grounding은 descriptive label로 key elements를 annotation함.
ex. MindAct는 finetuned small LM로 webpage element를 rank+filter하고, LLM으로 selected element와 action을 예측함
-
3.3.2 Interacting
-
Web Browsing based
-
website를 human이 navigate할때 전형적으로 수행하는 action (ex. clicking, scrolling, typing) 사용함
ex. NaviQAte는 Click, Type, Select를 정의함
ex. AgentOccam은 반복적이고 저품질의 embodiment-dependent action을 제거하고, Note, Stop과 같이 high-level command를 제안하여 interacting efficiency를 향상시킴
-
-
Tool based
-
APIs (Application Programming Interfaces)를 통해 webpage와 interaction
ex. Infogent는 Google search API를 통해 web navigation을 수행
-
4. Training of Webagents
4.1 Data
- 두가지 과정
- Data Pre-processing
- data 구조화 $\to$ Usability & Quality 향상
- Data Augmentation
- Quantity & Diversity 향상
- Data Pre-processing
4.1.1 Data Pre-processing
-
Modality Alignment
-
Multi-modal web data간의 정렬 (text + image)
ex. UIX [90] 논문에서는 screenshots + augmented accessibility tree를 활용
ex. UGrounds [36] 논문에서는 <screenshot, referring expression, coordinate> triplet으로 구축. referring expression은 HTML로부터 추출
ex. LVG [109] 논문은 UI screenshot + free-form language expression pair를 사용
-
-
Format Alignment
-
Platform-specific discrepancies를 다룸 (ex. naming conflicts,action tap, etc)
ex. OS-Atlas [158] 논은 cross-platform 데이터셋 간에 action space를 align하게 함
-
4.1.2 Data Augmentation
-
Data Collection
-
Public dataset 혹은 real-world dataset로부터 데이터를 수집
ex. Lexi [7] 논문에서는 114K UI image + caption을 curate.
ex. ShowUI [85] 논문에서는 public dataset에서 고품질/대표할 데이터를 조심스럽게 sampling
-
Human expert label의 고비용을 해결하고자 cost-effective dataset을 VLM을 이용하여 구축
ex. Falcon [120] 논문에서는 publicly available webpages로부터 multi-step cross-platform screenshot을 OCR annotation을 통해 생성한 Insight-UI 데이터셋을 제안
ex. ScribeAgent [121] 논문에서는 다양한 website에서 실제 Scribe 사이트 사용자의 action sequence data를 통해 구축
ex. UINav [80]에서는 UI element의 secondary attribute를 randomize하여 학습 데이터 증강을 수행
-
-
Data Synthesis
-
고품질 QA (Question-Answering) data를 생성하여 학습용으로 활용. 특히 sequential interaction을 캡쳐한 데이터
ex. AgentTrek [162] 논문에서는 web tutorial을 step-by-step instruction을 시뮬레이션하여 execution trajectory를 생성
-
4.2 Training Strategies
- 학습 전략은 4가지로 구분됨
- Training-free
- GUI Comprehension Training
- Task-specific Fine-tuning
- Post-Training
4.2.1 Training-free
- AutoGUI [180] 논문에서는 action history와 future action plans를 chain-format prompt기반 synthesize
- CoAT [172] 논문에서는 더욱 효과적인 navigation 능력을 위해 action과 thought을 통합함. (ex. screen description, 이전 action과 그 결과로 next action을 reasoning, 이어지는 step을 묘사하도록 함)
4.2.2 GUI Comprehension Training
-
Training-free방식의 LFM은 screen understanding, OCR이 떨어짐
ex. decorative icon이나 background text에 집중하고, key item을 외면할수 있음
-
OS-ATLAS [158] 논문에서는 <screenshot, referring expression, coordinates> triplet으로 학습 $\to$ vision centric GUI understanding
-
MM1.5 [171] 논문에서는 text-rich OCR을 기반으로 image, text interleaved data를 활용하여 학습 $\to$ E-commerce에 특화
-
LVG [109] 논무에서는 layout-guided contrastive learning으로 학습하여 UI 요소 개개인의 semantic을 학습
-
Spotlight [75] 논문에서는 Region Summarizer를 도입하여 핵심 region을 screenshot에서 추출
-
ScreenAI [5] 논문에서는 visual 요소를 연관된 HTML과 mapping하는 Pix2Struct [73]의 patching strategy를 활용
4.2.3 Task-specific Fine-tuning
- User task를 기반으로 next step을 정확하게 reasoning하고 generating하는건 매우 어려움
- HTML-T5 [42] 논문에서는 scripted planning dataset으로 finetuning한 LLM-driven agent를 제안함. 자연어 instruction을 제어 가능한 sub-instructions로 분할하고, HTML document를 task-relevant snippet로 요약.
- LCoW [72] 논문에서는 Contextualization module을 통해 contextualized 관찰을 수행하여 decision-making 능력을 향상. 해당 모듈은 자신의 output중 optimized output을 통해 iteratively finetuned되어 학습됨.
- NNetNav [101] 논문에서는 language instruction을 계층적으로 구성하여 finetuning하여 검색 과정을 통제가능하도록 구현.
- WebGUM [32] 논문에서는 web navigation task를 instruction following task로 변환하여 data-driven offline supervised finetuning 패러다임을 열었음
- LLMPA [39] 논문에서는 e2e finetuning framework를 구현하여 instruction 분해, action 예측을 수행함. 예측한 action을 꼼꼼하게 Controllable Calibration을 수행함
4.2.4 Post-training
- Web의 인터페이스가 지속적으로 변하고, user의 요구사항도 변화함에 따라 배포후 realtime adaptation은 필수적임
- AutoGLM [91] 논문에서는 progressive reinforcement learning framework를 통해 지속적으로 self-evolving learning 패러다임을 제시
- AutoWebGLM [71] 논문에서는 multi-stage training 전략으로 planning, reasoning, interacting 능력을 향상시킴.
- RUIG [179] 논문에서는 visually semantic metric을 기반으로 token sequence를 guide받아 reinforcement learning을 수행함.
6. Future Directions
6.1 Trustworth Webagents
-
Fairness: 편향없이 perception, reasoning, execution을 수행해야함
ex. 간호사에 대한 성적 편향성
-
Explainability: action에 대해 정당화 할수 있어야 함
6.2 Datasets and Benchmarks of WebAgents
- PersonalWAB [10]은 1,000개의 다양한 user-profile과 40,000개의 web behavior기반 real world data로 구성
- Webcanvas [107] framework는 realistic web-based interactions를 모방하여 어떻게 agent가 dynamic, unpredictable setting에서 작동하는지 연구원들에게 관찰할 놀이터를 제공함
- 향후에는 fluncating internet speed, adapting to varied web layout등 realworld 이슈를 고려해야함
6.3 Personalized WebAgents
- Generalized LLM을 personalized finetuning하기란 어려움 $\to$ RAG system으로 구현
- 즉각적인 contextual cue에 적응하는 realtime prompt를 short-term memory로 구현