[KD][AR] Unmasked Teacher: Towards Training-Efficient Video Foundation Models
[KD][AR] Unmasked Teacher: Towards Training-Efficient Video Foundation Models
- paper: https://arxiv.org/pdf/2303.16058.pdf
- github: https://github.com/OpenGVLab/unmasked_teacher
- ICCV 2023 accepted (인용수: 45회, ‘24-04-01 기준)
- downstream task: Video Classification, Video Detection
1. Motivation
- VideoMAE의 low-level reconstruction pretraining은 high-level cross-modality alignment에 수렴을 방해함
- 또한 pretraining 시간이 너무 많이 드는 이슈가 있음 (2,400 epoch in 160k videos)
- 뿐만 아니라, reconstruction을 위해 사용되는 global spatiotemporal self attention decoder는 computation cost가 많이 들어 scale-up이 힘듦
- IFM (Image Foundation Model)을 효율적으로 학습에 활요할 수 있는 방법은 없을까?
2. Contribution
-
IFM (CLIP)을 직접적으로 finetuning하기보다, unmasked token에 대해 Teacher로 활용하는 UMT (UnMasked Teacher) framework를 제안함
-
장점:VideoMAE의 data efficiency를 차용 + Video domain에 Vanilla ViT활용하여 multi-modal friendly하게 학습 가능
-
Stage 1에서는 scratch에서 VFM 모델을 Video data만 가지고 학습
-
Stage 2에서 vision-language data를 활용하여 cross-modal training 수행
$\to$ 둘 다 UMT를 통해 학습 속도 & 성능 boosting
-
-
다양한 downstream task에서 SOTA

- pretraining 학습이 매우 효율적임
- vs CoCa = 2,048 CloudTPUv4 x 5days $\to$ 32 A100(32GB) x 6days
- pretraining 학습이 매우 효율적임
3. UMT
-
overall diagram
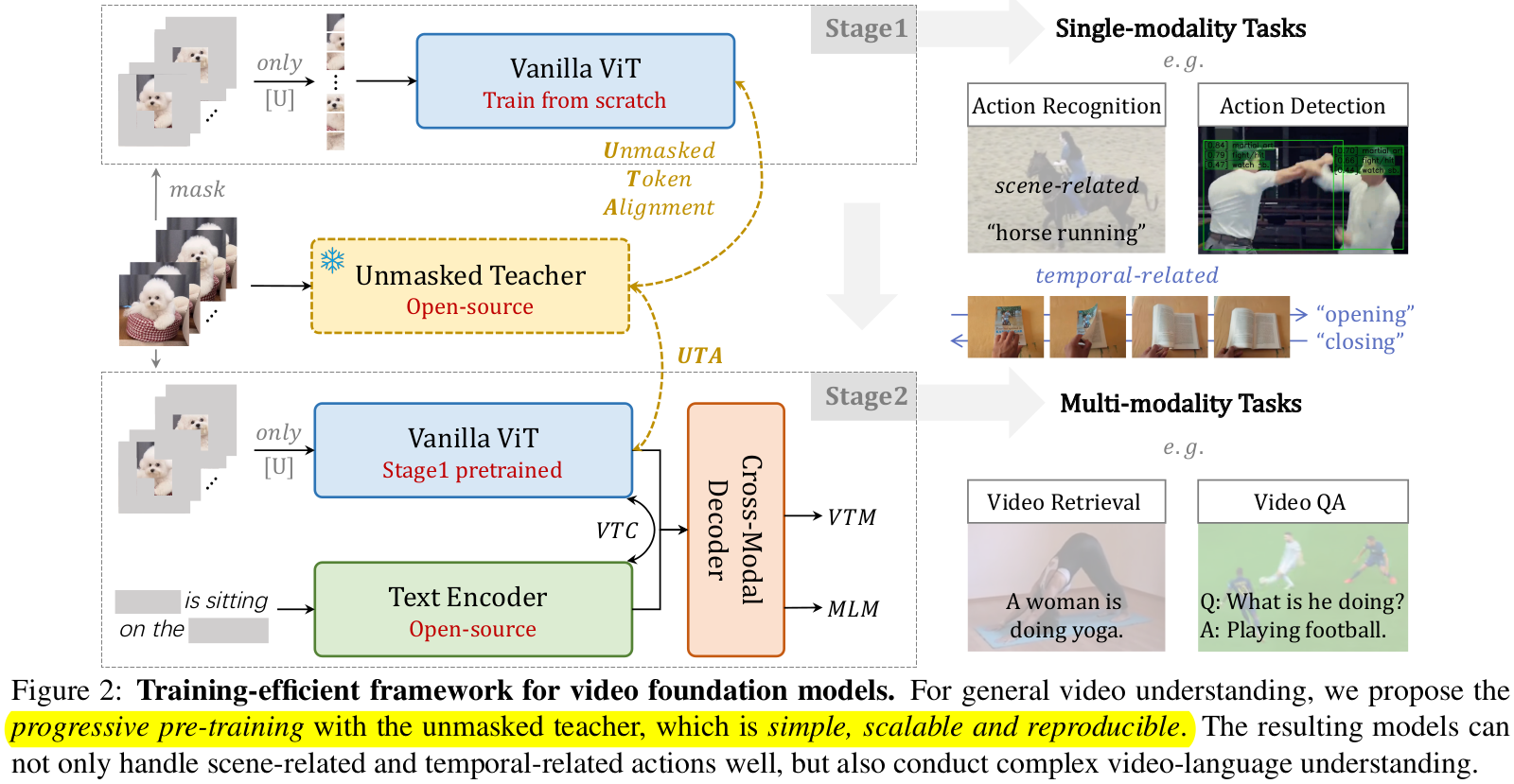
-
Architecture
- teacher의 knowledge를 가져오기 위해, student도 동일한 구조를 사용 (CLIP-ViT)
-
Masking
-
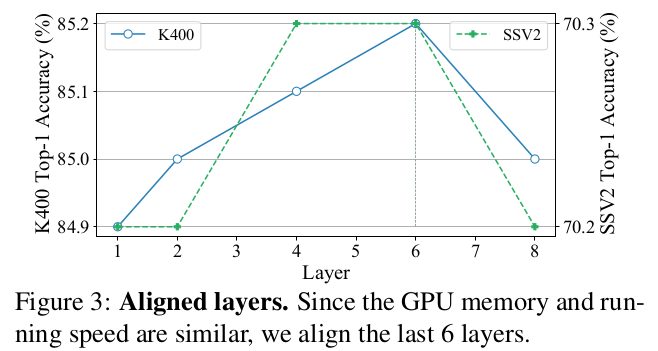
VideoMAE와 유사하게 high masking ratio (80%)채택
-
단, masking 영역을 random 하게 만드는 것은 정보가 적은 background영역을 masking하여 학습할 확률이 크므로, semantic masking을 통해 효과적으로 masking target을 선정
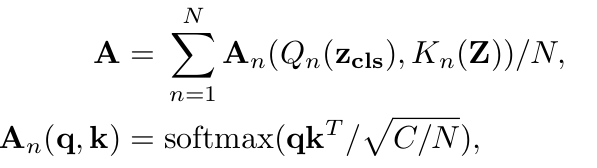
- Class token z$_{cls}$와 spatial token z간의 유사도를 비교하여 weighting matrix 계산 $\to$ masking 계산에 활용
- query : class token
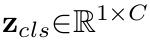
- key : spatial token
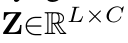
- value : spatial token
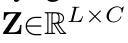
- query : class token
- Class token z$_{cls}$와 spatial token z간의 유사도를 비교하여 weighting matrix 계산 $\to$ masking 계산에 활용
-
-
Target
- teacher의 unmasked token을 학습하도록 student의 token을 linear projection시킴
- 이때 teacher는 전체 frame (L)에서 spatial token과 class token을 넣어주고, student는 unmasked token만 입력 (L(1-r)T)
- teacher는 pretrained visual projection을 생성하므로 multi-modality finetuning에 이점이 있도록 설계 (CLIP-VIT썼단 얘기)
-
Progression Pre-training
-
Stage 1 : UMA (UnMasked teacher Alignment) loss만 활용
-
Stage 2 : UMA
+VTC (Video-Text Contrastive learning): unmasked video token과 text간의 pool/push 수행
+VTM (Video-Text Matching): BCE w/ hard negative mining으로 video-text matching
+MLM (Masked Language Modeling) loss 활용
-
4. Experiments
-
Ablation Study
-
vs. VideoMAE

-
Masking type & sampling 방식
- T-down: Temporal dmension으로 downsize 여부
-
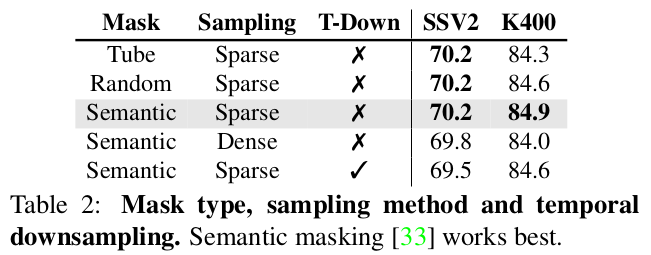
Aligned layer 수 : Student layer와 teacher layer간의 alignment하는 layer 갯수 (평균값 활용)
-
Masking ratio
-
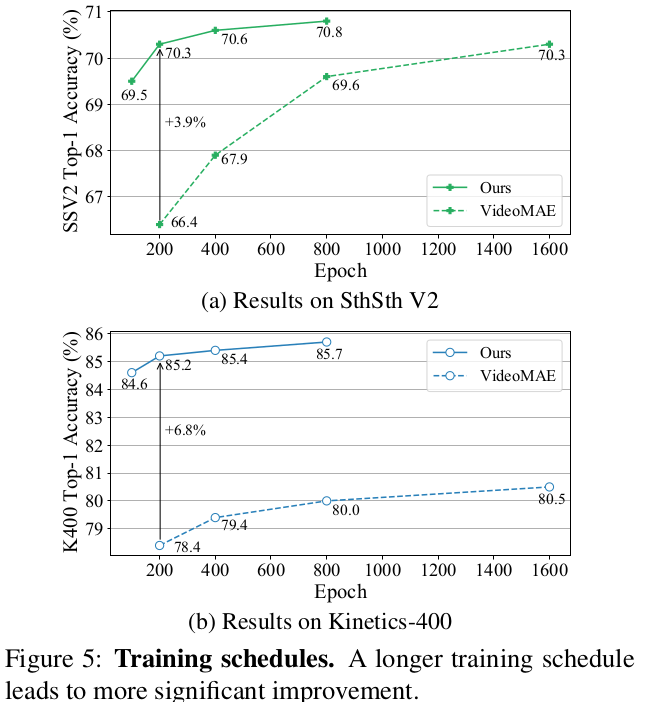
Training schedule : 길게 학습할수록 finetuning성능이 향상됨
-
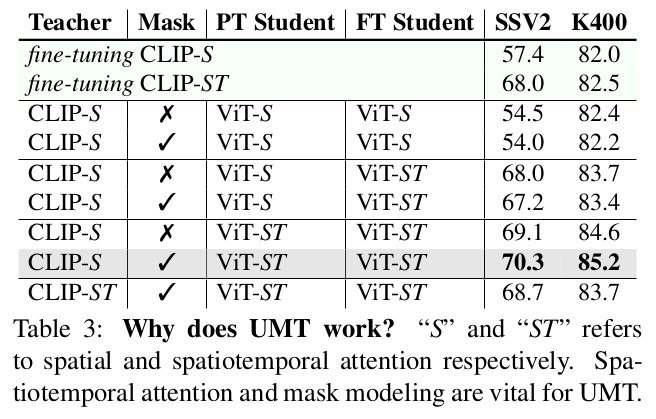
Pretraining / Finetuning Attention
-
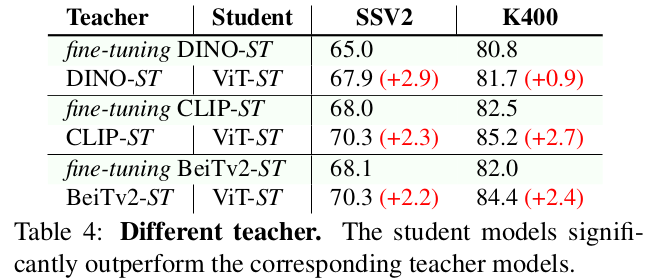
Different Teacher: 모두 Teacher보다 좋은 성능
-
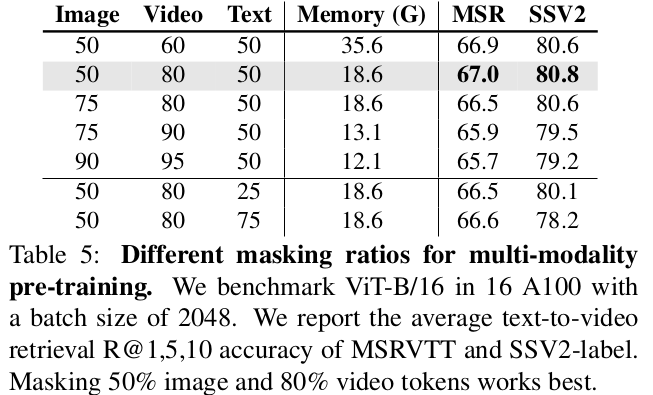
Image & Video masking ratio : 동일 memory을 갖도록 masking ratio 지정
-
Loss
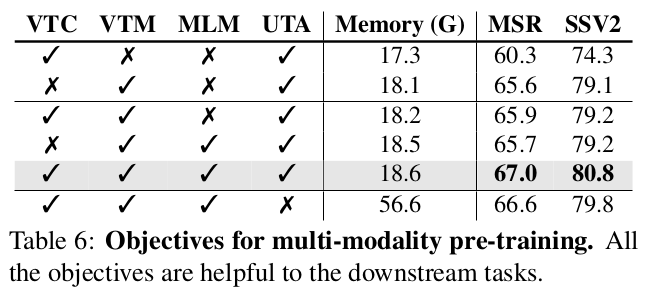
-
Multi-modality other method들과 비교

-
-
Single Modality
-
Kinetics
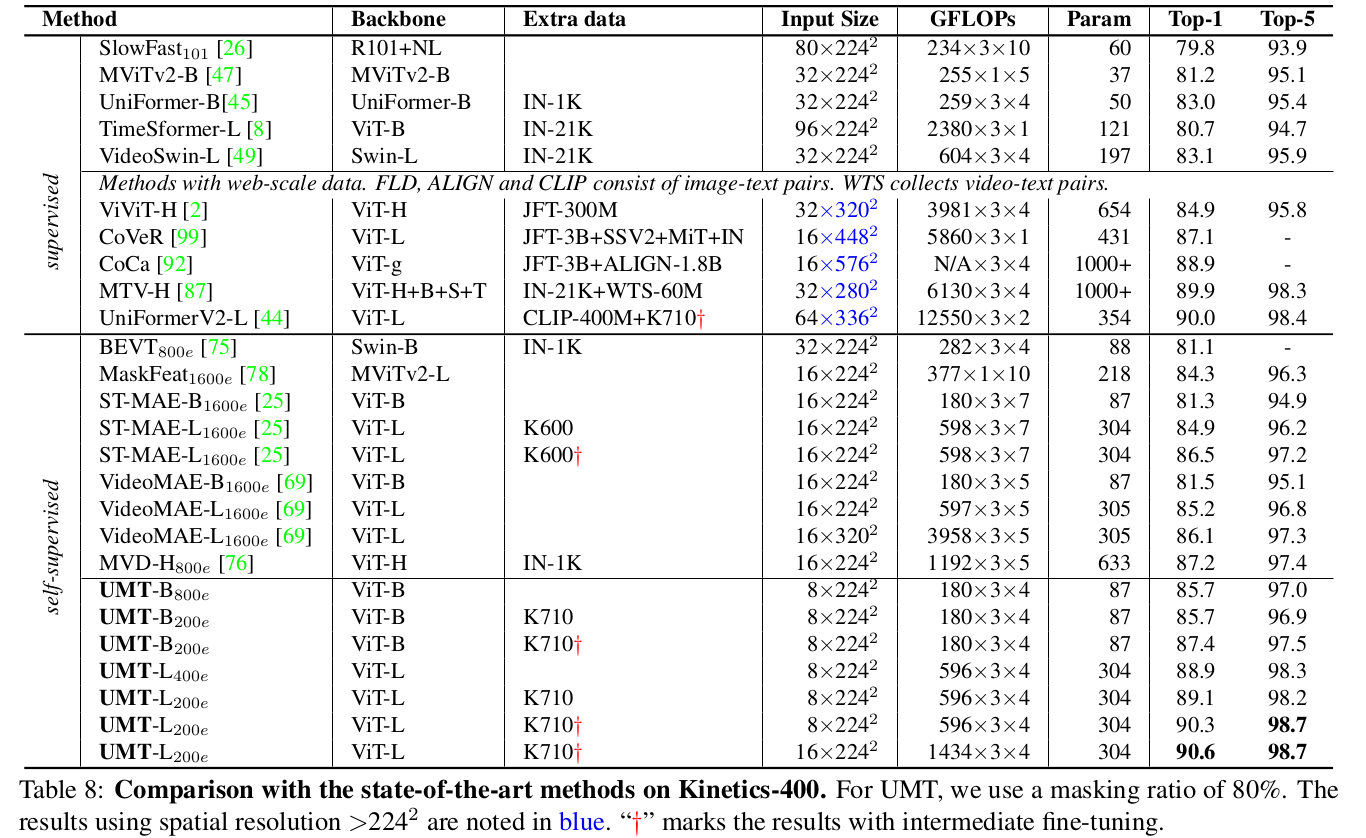
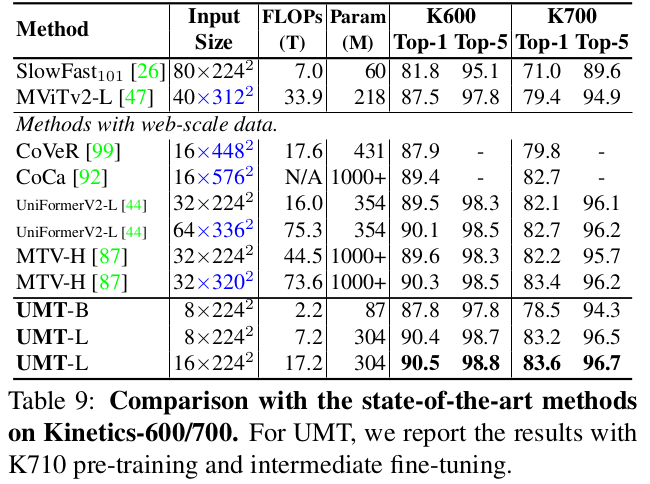
-
Moments in Time : K400에 비해 class갯수가 많아 더 어려운 data
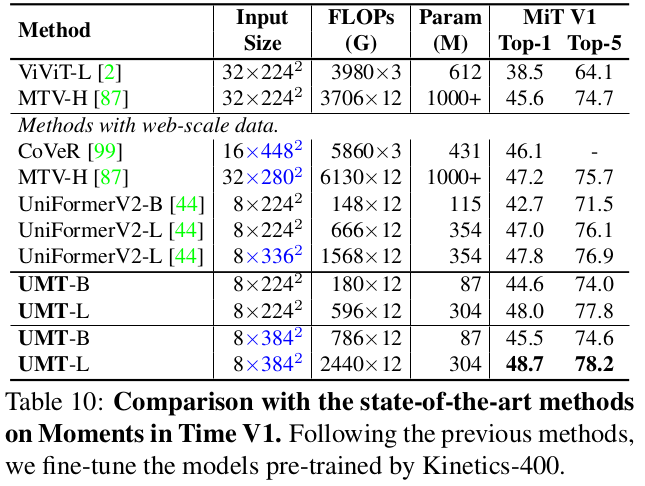
-
Something-SomethingV2
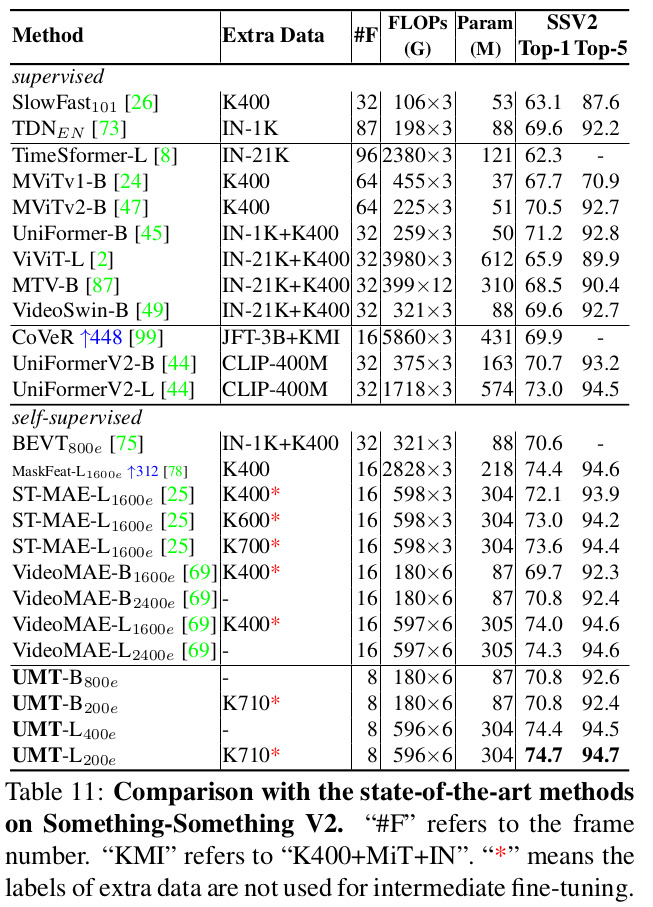
-
AVA : Action Detection
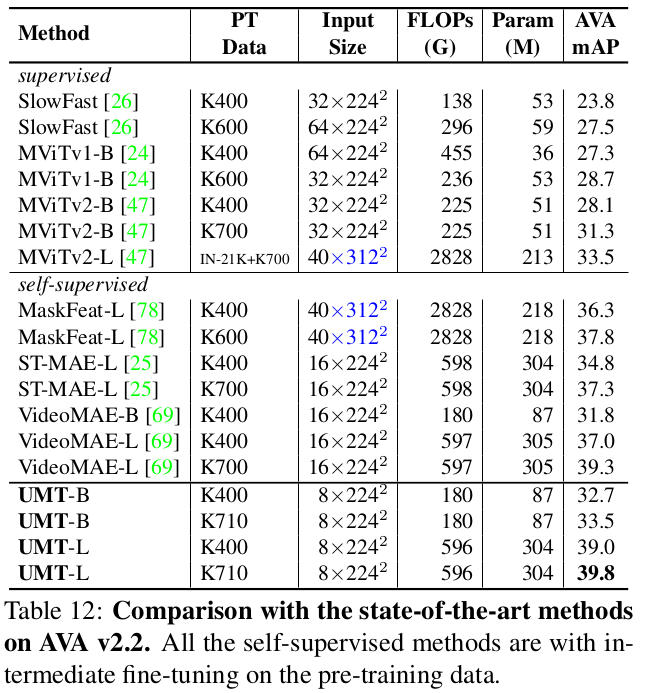
-
-
Cross-Modality
-
Zero-shot text-to-videl retrieval
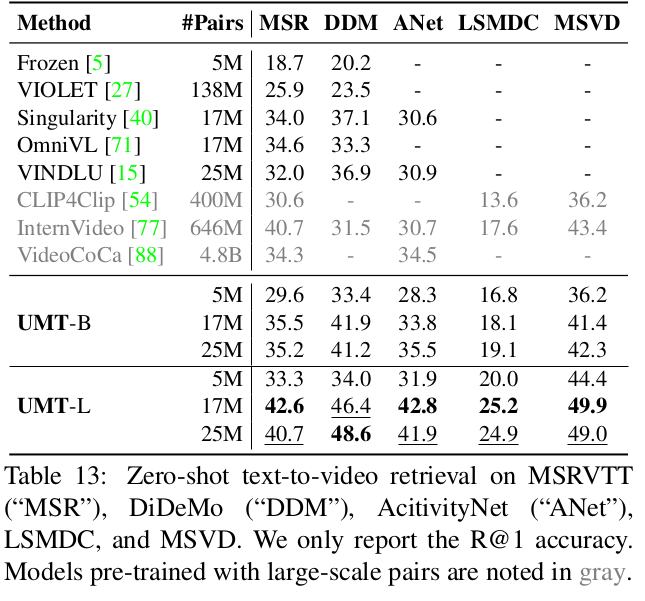
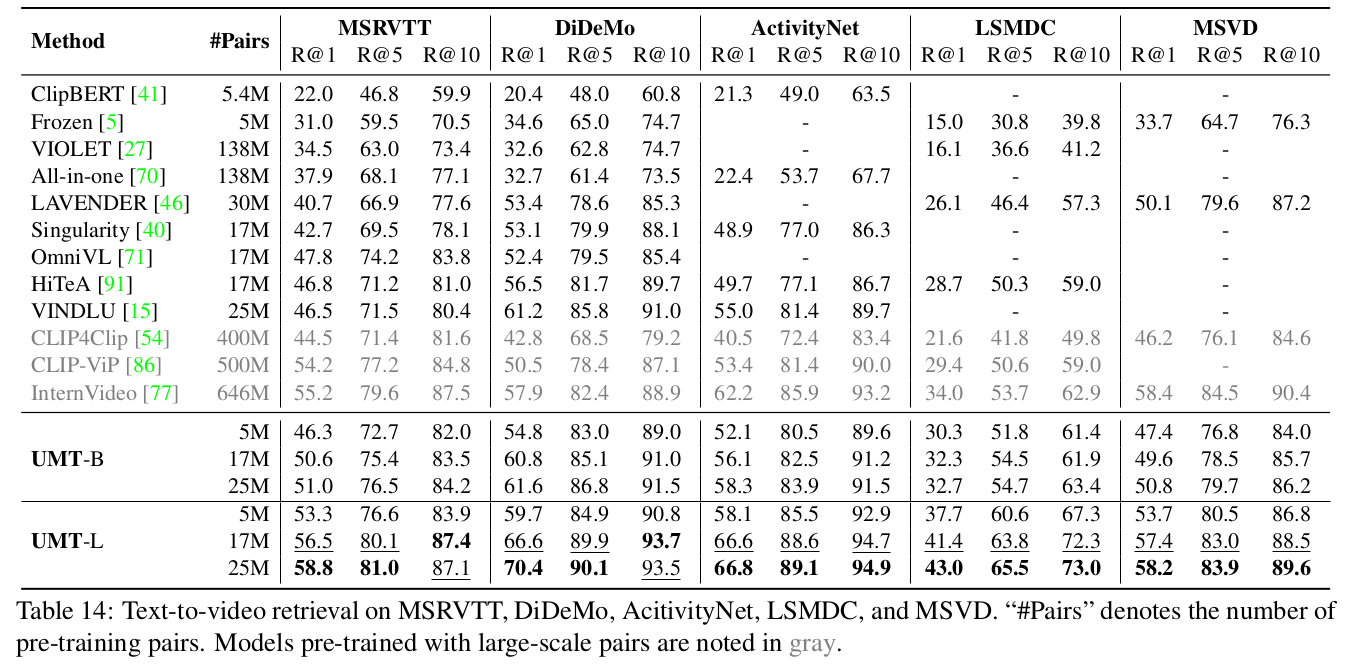
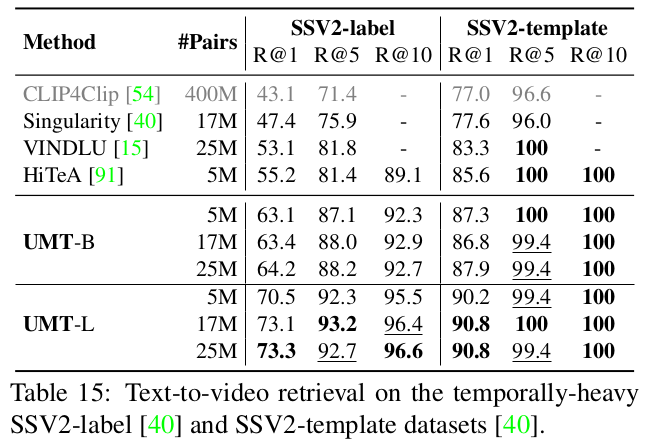
-
Video VQA
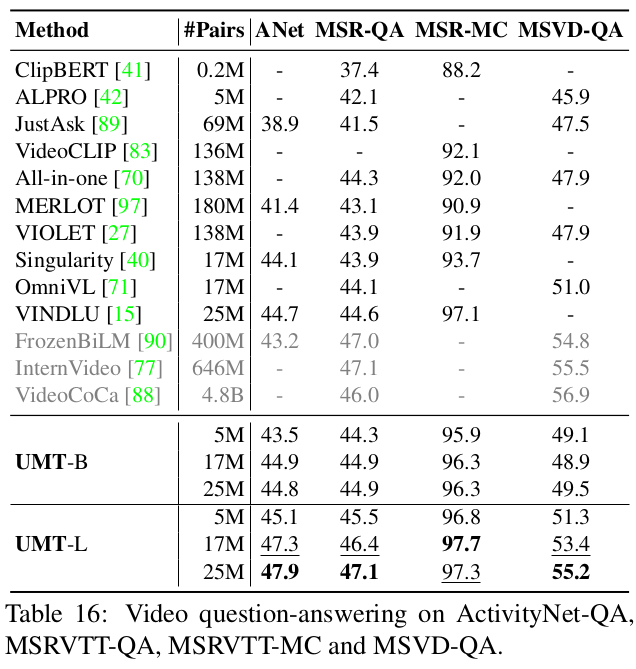
-