UIShift: Enhancing VLM-based GUI Agents through Self-supervised Reinforcement Learning
[WebAgent] UIShift: Enhancing VLM-based GUI Agents through Self-supervised Reinforcement Learning
- paper: https://arxiv.org/pdf/2505.12493
- github: X
- archived (인용수: 0회, 25-05-24 기준)
- downstream task: GUI Grounding (ScreenSpot: Mobile, ScreenSpot-V2: Desktop, ScreenSpot-Pro: Web), GUI Task Automation (AndroidControl-Low (단계별 지침), AndroidControl-High (테스크 레벨 지침))
1. Motivation
-
Vision Language Models (VLMs)의 발전은 mobile GUI agent의 패러다임을 handcrafted heuristics $\to$ design vision-grounded policies로 바꿨음
-
VLM을 학습시키기 위해서는 GUI Trajectories 라벨 데이터 annotation이 필요로 함 $\to$ 15,283 task를 위해 1년간 라벨링 수행. $\to$ 고비용 data 수집은 VLM paradigm을 확장하기 어려웠음
$\to$ 쉽게 취득가능한 Unlabeled GUI trajectgories를 이용한 self-supervised training framework를 접목해보자!
-
Robotics & Biomechanics에서 as-is state, to-be state (k-step)을 보고, control command를 agent가 예측하게 해보자! (k-step UI Transition)
2. Contribution
-
Self-supervised (GRPO) UI Transition data를 기반으로 학습한 UIShft가 annotation-dependent baselines보다 GUI grounding & GUT Task Automation tasks에서 우월한 성능을 보임으로써, UI Transition이 효율적인 learning signal을 VLMs (Qwen-2.5VL 3B/7B)에 제공함을 입증함
-
Reasoning이 GUI 관련 task에서 효과가 없음을 입증함. (Perception-R1 / UI-R1)
-
k에 따른 성능을 비교 분석함. $\to$ GUI task에서 SOTA
-
k가 클수록 장기 계획 성능이 좋아짐 (AndroidControl-High)
-
Task-level Action 향상 or long-horizon planning 능력 향상 But Grounding 능력 감쇠
- ex. “Share the news article on Gmail”
-
‘공유 버튼 클릭’ $\to$ ‘Gmail 앱 선택’ $\to$ ‘받는 사람 주소 입력’ $\to$ ‘보내기 버튼 클릭’
-
-
k가 작으루록 단기 계획 성능이 좋아짐 (AndroidControl-Low)
-
Low-level action 예측 향상
ex. click, scroll, input_text, open_app, navigate_back
-
-
3. Related Works
3.1 Mobile GUI Agents
-
대량의 데이터셋 기반 SFT로 VLMs을 학습하는게 Mobile GUI Agent의 최근 진행되었음
-
Instruction과 GUI action을 instruction-following task로 mapping하도록 훈련됨 $\to$ 고품질의 human annotation이 필수적임
-
Uground [8] 논문에서는 1.3M screenshot로 visual grounding 모델 훈련
-
UI-TARS [19] 논문에서는 50B token으로 학습함
-
OS-Atlas [31] 논문에서는 13M UI element로 grounding pretraining을 수행함
-
MobileVLM [30] 논문에서는 action 예측 task를 pretraining에서 수행함 (1-step only) + downstream 일반화를 위해 annotation-heavy finetuning이 필수적
$\to$ 본 논문에서는 k-step inverse dynamics task 를 정의하여 해결함 (0-step screenshot, k-step screenshot, k개의 sequencial action)
-
-
3.2 Rule-based Reinforcement Learning
-
GRPO가 SFT의 훌륭한 대안임이 최근 입증됨 (DeepSeek)
-
Verifiable Reward [11] 논문에서는 verifiable answer를 강조함으로써 reward signal의 신뢰성을 높임
-
DeepSeek-R1 [9] 논문에서는 간단한 format & accuracy reward가 instruction-tuned 모델보다 우수한 성능을 보임을 입증
$\to$ GUI task는 Discretized action space + structured parameter로 구성되어, correctness를 검증하는데 수월함
-
GRPO to UI 적용된 최근 논문들도 있음
-
UI-R1 [18] 에서는 136단계 insturction samples에 대해 1 stage RL로 학습
-
GUI-R1 [32]은 1 stage SFT+RL pipeline만으로 3K task-instruction sample을 5개의 platform에서 취득함
-
InfiGUI-R1 [16]는 2 stage SFT+RL pipeline으로 GUI + non GUI domain에서 32K sample을 취득함
$\to$ 모두 annotation이 필요함 (SFT).
$\to$ 본 논문은 1stage RL pipeline으로 2K UI Transition samples을 취득함
-
-
4. UIShift
-
Overall Diagram
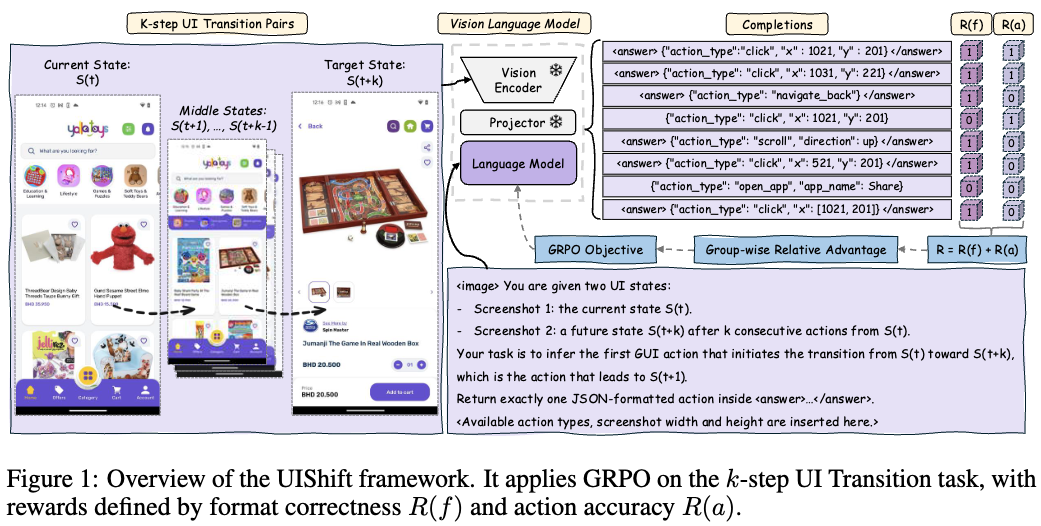
4.1 Preliminary: GRPO
-
GRPO는 action-critic기반의 RL framework인 Proximal Policy Optimization (PPO)보다 비용효율이 우수한 대안 RL framework임
- PPO: value-function을 별도의 critic model이 예측
- GRPO: 직접적으로 reward signal을 group-wise advantages $A_i$ reward 모델이 예측함 (rule-based)
- format: 포맷이 문제가 없는가? (with reasoning:
... +... / wo reasoning:... ) - accuracy: 정답 action과, action의 parameter와 정확히 일치하는가? (ex. scroll + direction “up”)
- format: 포맷이 문제가 없는가? (with reasoning:
-
수식
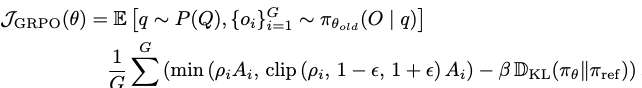
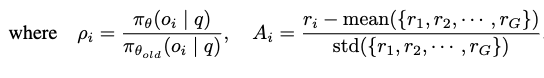
- $J_{GRPO}$: 목적함수로, 최대화하는게 목표
- $A_i$: G개의 후보중 i번째 sampling된 output ($o_i$)이 예측한 상대적 reward (advantage)
4.2 Reward Design in UIShift
-
Reward
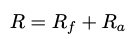
4.2.1 Format Reward
- DeepSeek-R1에서 영감을 받음
- Reasoning based
- 중간 reasoning은
... 안에 있고, 최종 answer는... 안에 있으면 $R_f=1$, 아니면 $R_f=0$
- 중간 reasoning은
- Reasoning free
- 최종 answer가
... 안에 있으면 $R_f=1$, 아니면 $R_f=0$
- 최종 answer가
- Reasoning based
4.2.2 Accuracy Reward
- 5개의 action types별로 structured JSON object로 출력되도록 학습 & 추론시 response format을 통일함
click:(x,y)target element UI의 중간 좌표- 해당 element bbox 내로 예측하면 $R_a=1$, 아니면 $R_a=0$
scroll: (up, down, left, right) 방향- exact match하면 $R_a=1$, 아니면 $R_a=0$
open_app, input_text: string for app name or text to be entered- exact match하면 $R_a=1$, 아니면 $R_a=0$
navigate_back: no parameter- exact match하면 $R_a=1$, 아니면 $R_a=0$
4.3 K-step UI Transition Task & Training
-
K-step UI Transition Task
- input
- $S_t$: current step (t)의 상태 (screenshot image)
- $S_{t+k}$: k step 이후 (t+k)의 상태 (screenshot image)
- output
- action sequence (k개)
- input
-
효과
-
robotics에서 inverse-dynamics처럼 제어 신호를 예측하는 능력을 길러줌
-
구체적으로, 주어진 환경간에 “무엇이 변했는지”랑 “어떻게 변했는지”에 집중하게 함으로써 GUI context와 actionable region에 집중함으로써 action sequence와 mapping 능력을 향상시킴
-
m개의 후보 액션에 대해 reward signal을 계산하여 format / accuracy reward기반 GRPO로 학습을 수행함
$\to$ one-shot 라벨보다 그럴듯한 액션에 대한 순위를 메겨 학습함으로써 풍부한 피드백을 제공. 이는 CE Loss처럼 Exact Match하는 능력에 비해 자연스럽게 탐색하는 능력을 키워주기에, GUI task에 더 적합함 (레이아웃 생성도 좋을듯)
-
5. Experiments
5.1 Experiment Setup
-
Tasks
- instruction mapping
- GUI grounding
-
Training
-
Framework = VLM-R1
-
full-parameter training reinforcement fine-tuning
-
GPU
- A800 x 8 GPUs
-
Hyperparameter
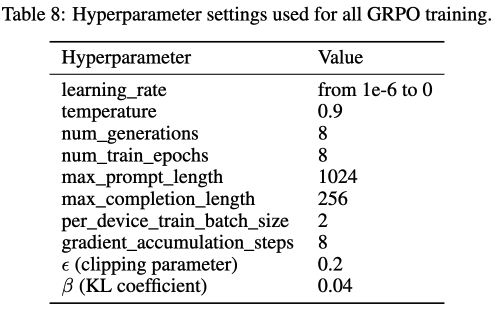
- 8 epoch (26 hours using 2K UI Transition samples)
-
Models
- Qwn2.5-VL-3B/7B
-
Training Datasets
- AndroidControl: UI Trajectories를 포함함 (screenshots + instructions)
- 학습 데이터의 다양성을 위해 다른 episode로부터 데이터를 추출
- AndroidControl: UI Trajectories를 포함함 (screenshots + instructions)
-
Evaluation Datasets
- GUI grounding
- ScreenSpot, ScreenSpot-V2: mobile, web, desktop platform
- ScreenSpot-Pro: high-resolution desktop에서 추출한 fine-grained UI components
- GUI task automation
- screenshot & instruction을 제공하며 next action을 요구하는 데이터셋으로 구성
- AndroidControl-Low
- AndroidControl-High
- screenshot & instruction을 제공하며 next action을 요구하는 데이터셋으로 구성
- GUI grounding
-
Evaluation Metrics
- action type accuracy(Type) : 5가지 중 action의 type에 대한 정확성
- grounding accuracy(Grounding):
clickaction일 경우, 예측한 좌표(x,y)가 target element bbox에 놓여있는지 체크 - successrate (SR): action type + 연관 parameters가 exact match한 비율
5.2 정량적 결과
-
AndroidControl
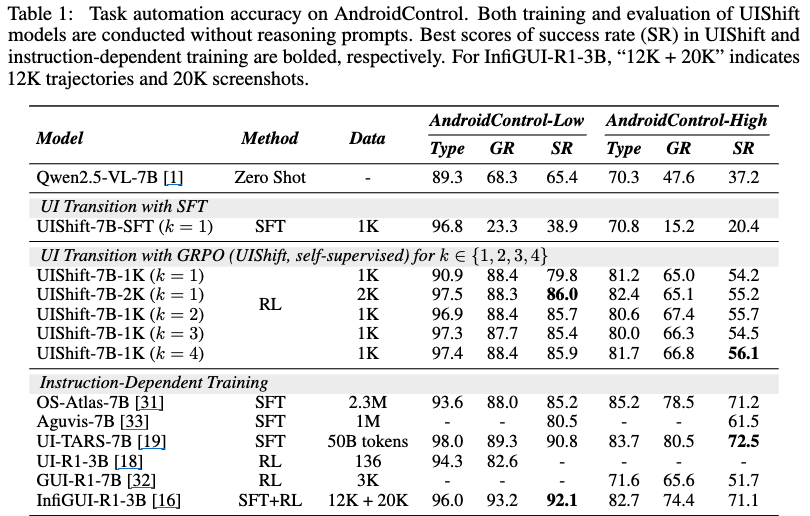
-
GUI Grounding
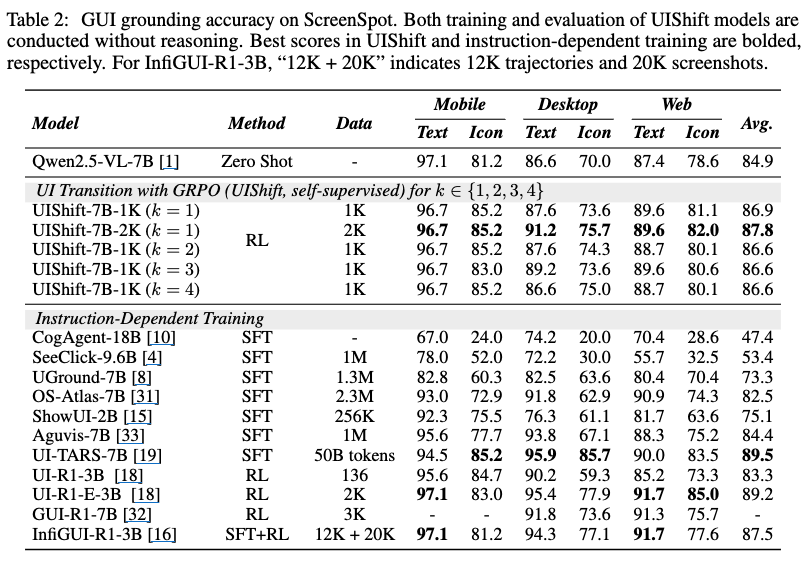
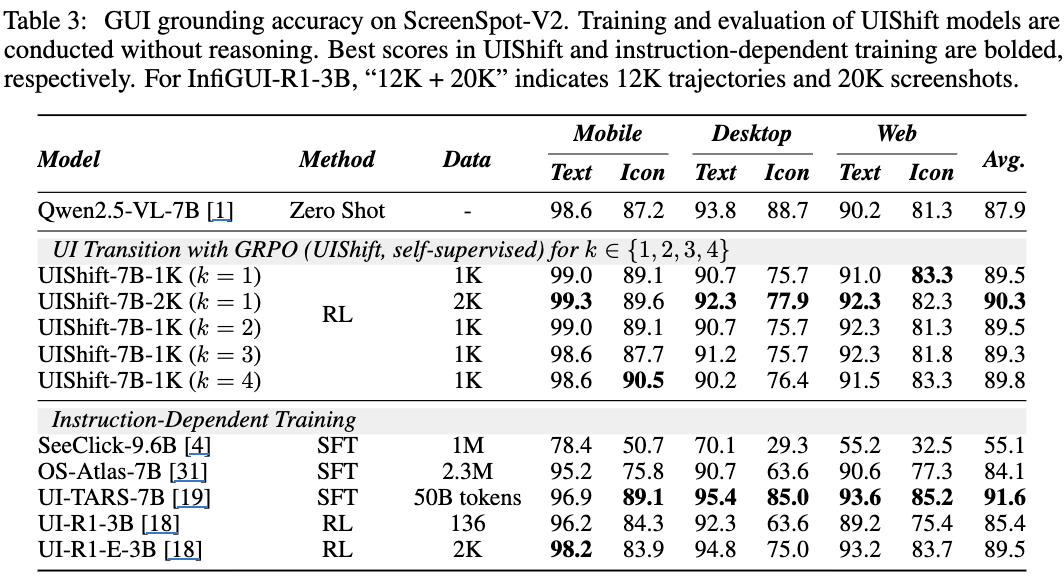
-
5.3 Ablation Studies
-
Reasoning 유무에 따른 성능 비교
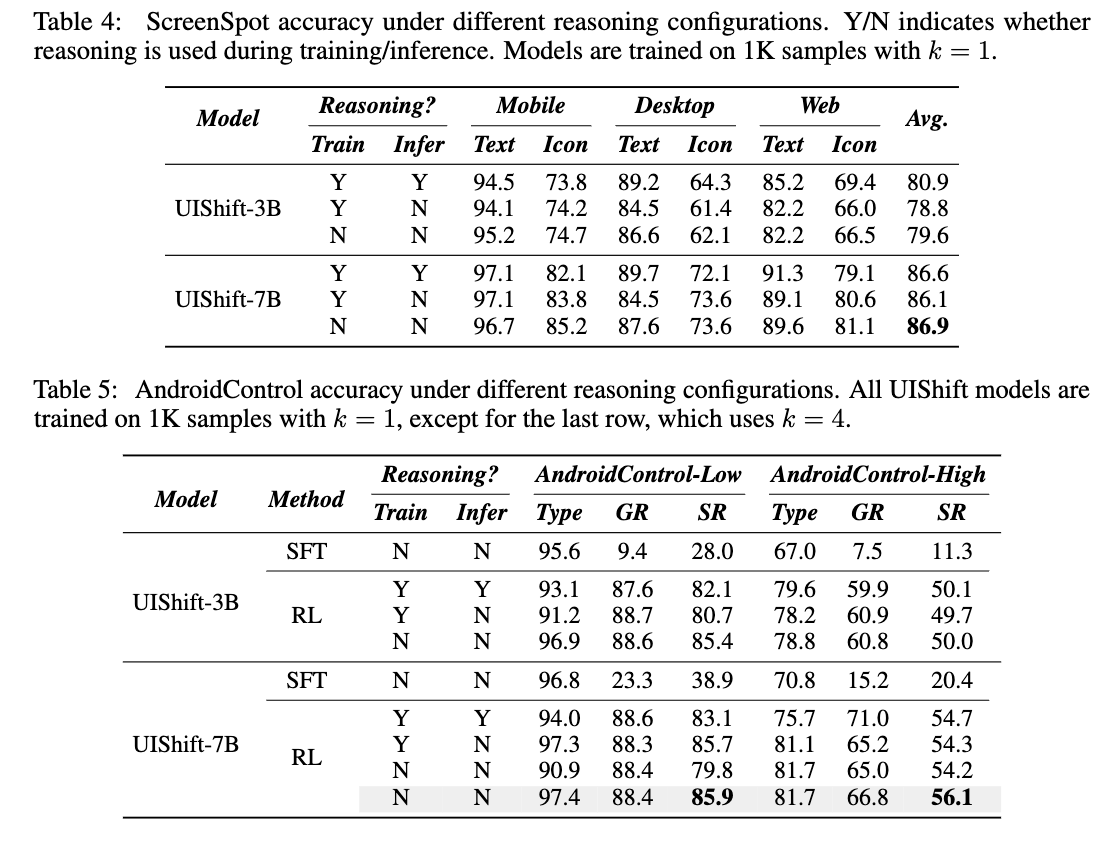
- 학습/추론 모두 Reasoning 없이 학습하는게 성능에 도움
-
SFT-only vs. GRPO-only
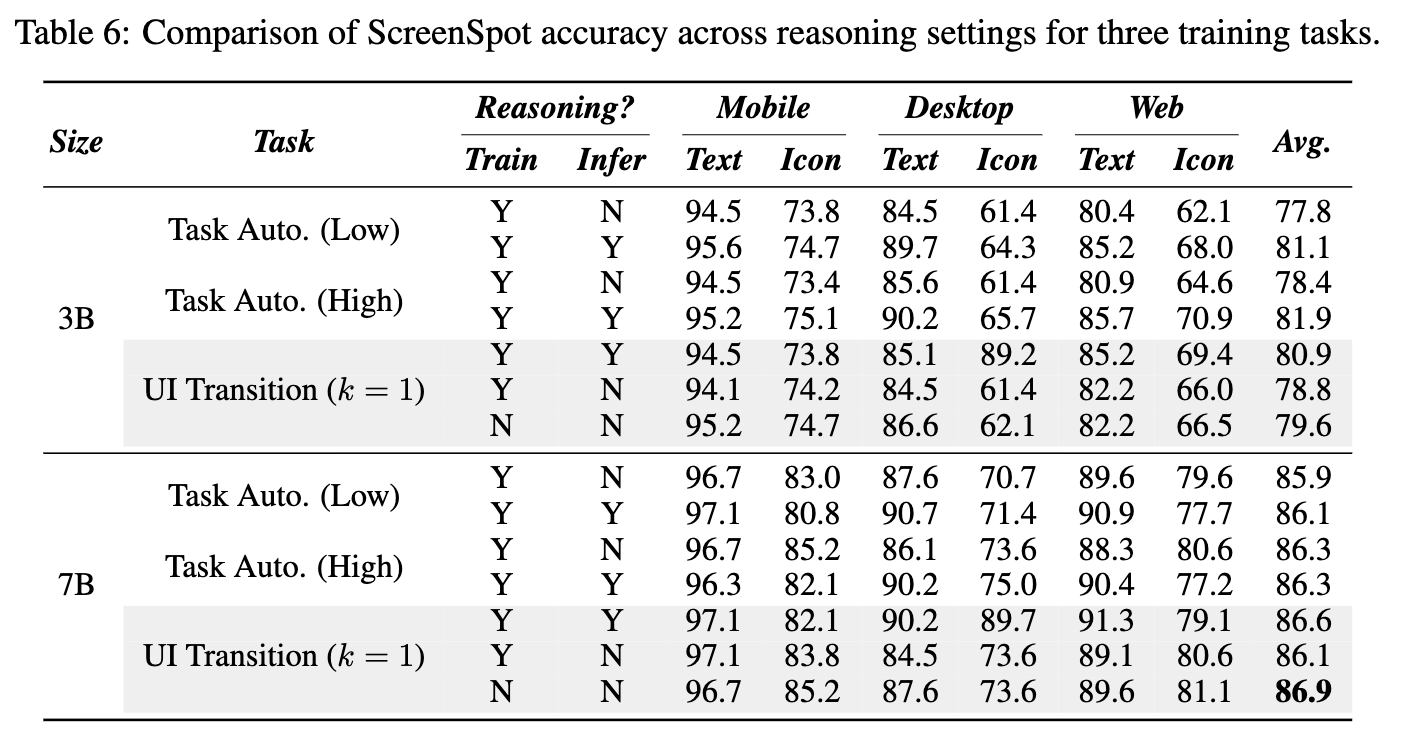
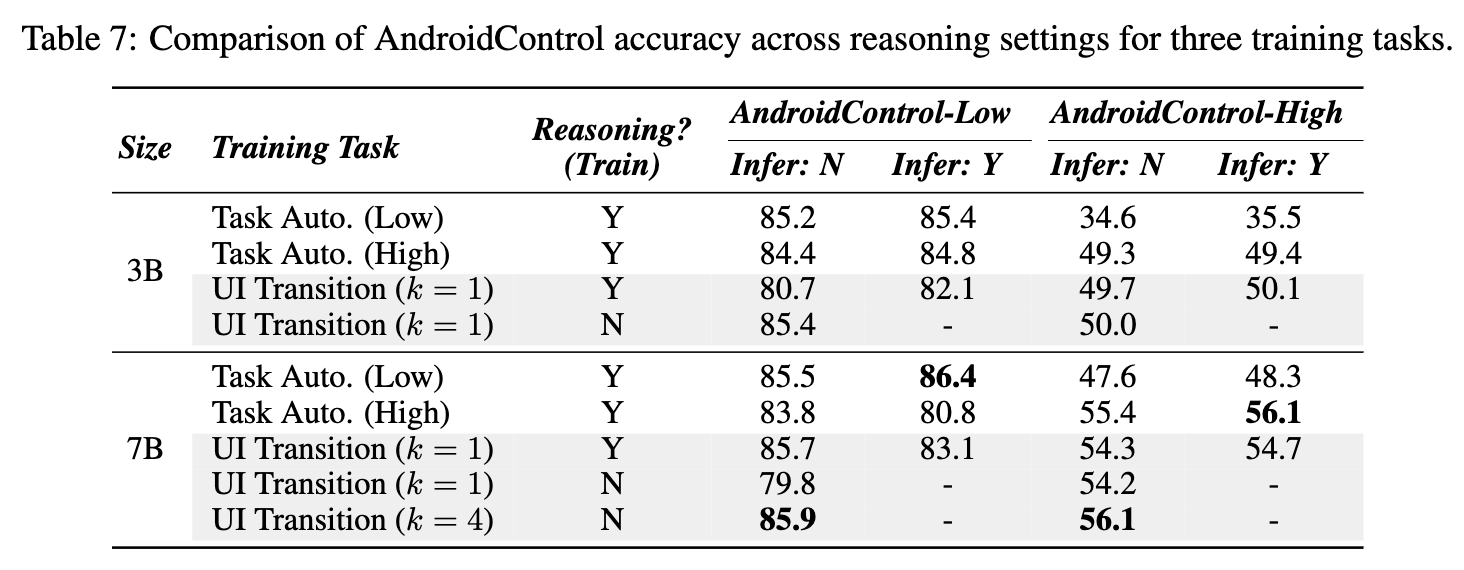
- GRPO가 SFT보다 동등이상 성능
- SFT는 In-domain에서는 좋은 성능을 내지만, Out-domain은 성능이 열악함
- GRPO는 general 성능이 좋아짐 $\to$ UITransition이 screenshot과 text간의 정렬이 되도록 학습되기 떄문
-
k값에 따른 성능 분석 (Table 1)
- k=4일때 제일 좋은 성능을 냄. 하지만, Screenspot-pro benchmark에서는 k=1보다 열악
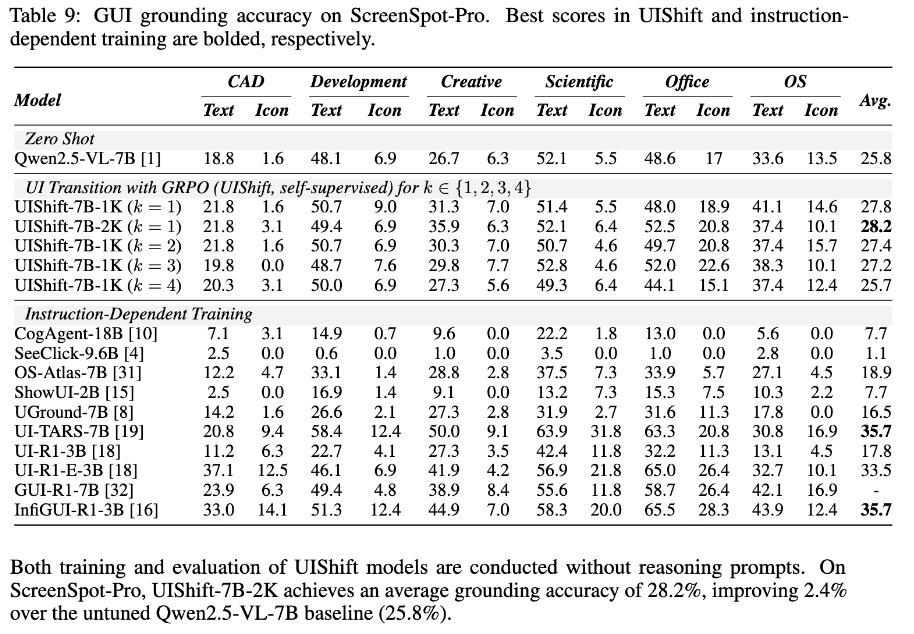
- k=1일때 grounding benchmark에서 제일 좋음
5.4 Future Works
- 정적인 benchmark (AndroidControl)을 사용했으나, 동적인 환경을 고려한 benchmark(AndroidWorld) 사용할 예정