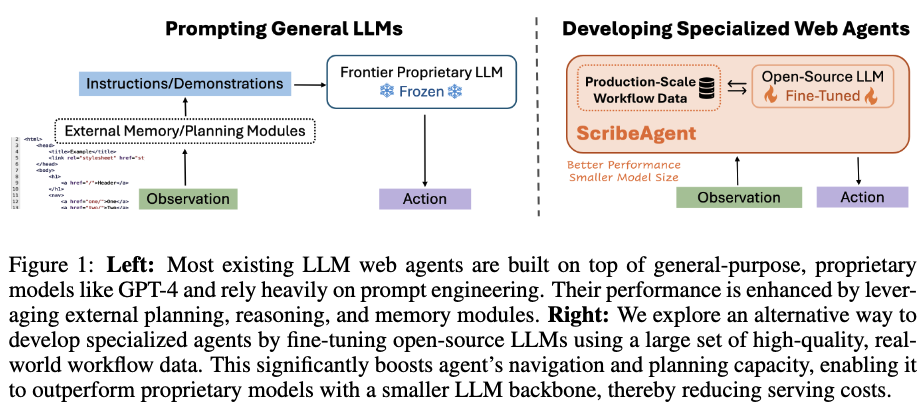
ScribeAgent: Towards Specialized Web Agents Using Production-Scale Workflow Data
[WebAgent] ScribeAgent: Towards Specialized Web Agents Using Production-Scale Workflow Data
- paper: https://arxiv.org/pdf/2411.15004
- github: https://github.com/colonylabs/ScribeAgent
- archived (인용수: 9회, 25-05-25 기준)
- downstream task: Web-based Task Automation(Mind2Web, WebArena, Scribe)
1. Motivation
-
복잡한 Web기반 task를 LLM Agent로 자동화하는 연구가 GPT-4와 같은 proprietary model을 기반 발전하고 있음
-
이러한 general-purpose LLM은 HTML 혹은 accessibility tree기반의 specialized web contexts를 이해하는데는 한계가 있음
$\to$ Opensource 기반 finetuning을 통해 HTML을 잘 이해하는 LLM agent를 만들어보자!
2. Contribution
-
여러개의 Opensource LLM을 가지고 real-world workflow dataset으로 finetuning
- Scribe 웹에서 real-world dataflow를 user의 data로 수집함
- 250 domains + 10,000 subdomains
- raw HTML-DOM (website)
- documentation of actions (+ 자연어 기반 설명)
- target HTML element
- 250 domains + 10,000 subdomains
- LoRA기반 next action prediction task로 해당 데이터셋을 reformatting $\to$ 6B tokens
- Scribe 웹에서 real-world dataflow를 user의 data로 수집함
-
Single-stage LLM agent인 ScribeAgent를 제안함
- inputs
- previous actions
- website의 DOM
- output
- next action
- inputs
-
여러 Web automation benchmark에서 SOTA
3. ScribeAgent
3.1 General Setup
- $h_t=H(o_{1:t-1}, a_{1:t-1})$: t-1 step까지의 action과 observation (html)을 history로 정의
- $a_t=L(q,o_t,h_t)$: t step의 history, observation, 그리고 user instruction q를 기반으로 next action을 예측
- $s_{t+1}=T(s_t, a_t)$: 환경에 action이 반영되어 상태가 변환(transform)됨 $\to$ 미리캔버스로 치면 html2xml
3.2 ScribeAgent: Specializing Web Agents Through Fine-tuning
- Scribe: Web 기반 작업의 step-by-step 가이드를 생성하는 웹사이트. 해당 사이트를 통해서 독점적인 user의 record와 상호작용을 잘 라벨링된 instruction으로 변환하여 데이터를 수집함
- ex. Custermoer Relationship Management (CRM) tool (HubSpot, Salesforce), productivity tools (Notion, Calendley), social platforms (ex. Facebook, LinkedIn), shopping sites (ex. Amazon, Sopify), etc
3.2.1 Collecting Production-scale Data
- 각 데이터는 “high-level user task”가 잘 정의되어 있음
- ex. “Invite someone to manage Facebook ad accounts”, “add a user in a Salesforce”
- label
- web page’s URL
- raw HTML-DOM
- 수행된 action에 대한 자연어 기반 설명
- action의 종류
- mouse_click_action: 특정 element를 클릭
- keyboard_sequence_action: 특정 element에 sequence of characters를 타이핑
- keyboard_combination_action: 여러 key 조합을 동시에 누름 (ex. ctrl+c)
- 수행된 action의 target HTML element (CSS selector로 자동생성된다고 함)
- Non-english, Non css selected element는 제거됨
- 해당 데이터셋은 2개월간 취득하여 250 domain + 10,000 subdomain + 평균 11 steps로, 약 6B token만큼 취득됨
- User privacy이슈로 공개되지 않을 예정
3.2.2 Preprocessing
-
HTML-DOM은 page에 DropDown해야 보이는 요소에 대한 구조적 & 내용적 정보를 모두 포함하고 있어, ScreenShot에 비해 액션 예측에 더 풍부한 정보를 제공 가능함
-
하지만, HTML-DOM은 불필요한 정보가 많음 $\to$ 전처리하여 filtering된 정보를 LLM 입력으로 제공하자!
-
전처리
-
BeautifulSoup library 사용
-
input
-
output

-
-
White-list tag attribute를 정의해서, 해당 attribute 만 남기고 나머지는 제거
ex. whitelist
tag = [
botton, a, div, body, html] / attribute = [class, id, node]- input
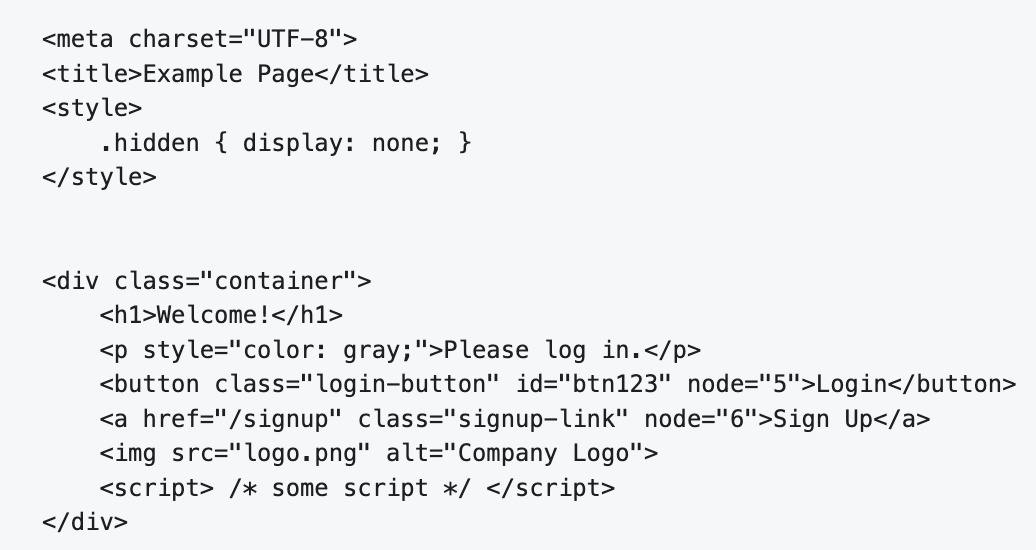
- output

- input
-
Character-to-token-ratio기반 random string 제거
\[\frac{len(s)}{len(tokenizer(s))}<2\] -
comments & whitespace 여백 제거
-
잔존하는 element에 대해 고유 ID 부여
-
Previous Action 예시

- 1.: 번째 step
- Description: previous action의 목적에 대한 설명.
- Node: 고유 ID
- Target: action이 적용될 target HTML item
-
-
-
action에 대한 description이 정보가 부족할 경우, Chatgpt로 action description을 생성
click here$\to$Click the submit button
-
최종 형태: previous action + user query + HTML-DOM, URL을 제공
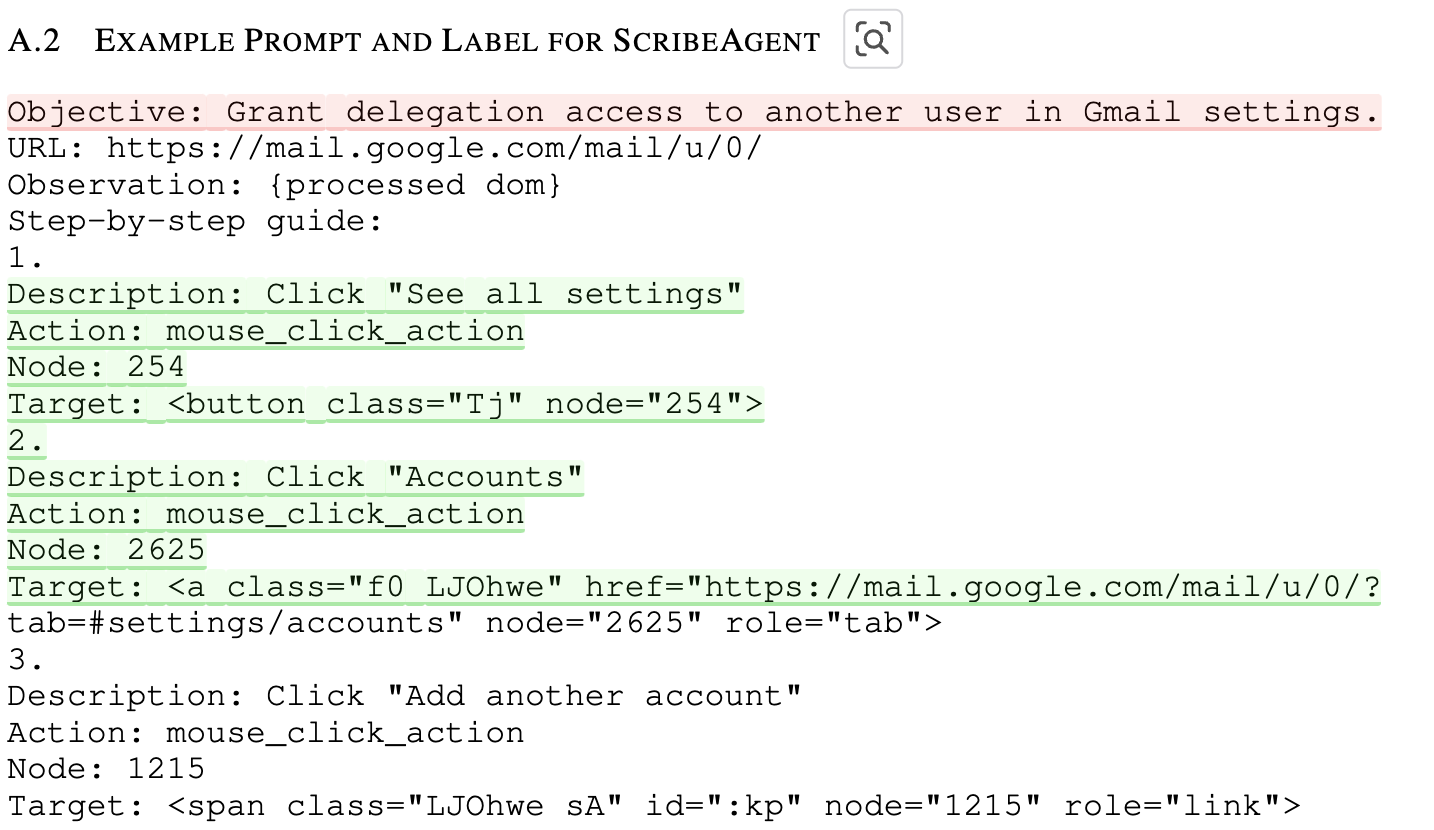
3.2.3 Exploring the Design Space
-
Pretrained LLM
-
Llama 3.1-8B
-
Mistral 7B / Mistral 8x7B
-
Qwen2 7B / Qwen2 57B
-
Qwen2.5 14B / Qwen2.5 32B
-
Codestral 22B
$\to$ 대부분 context length가 32K라 html을 chunking해서 입력. 따라서, chunk를 잘 선택했는가에 따라 성능이 좌우되므로, end-to-end Exact Match와, chunk가 선택되었을 때, Exact Match를 평가하는 Calibrated Exact Match를 제안
$\to$ Calibrated Exact Match라는 지표는, 정답이 존재하는 Chunk를 뽑는 가능성을 배제한 EM이라고 보면 됨
-
Context Length
-
32K $\to$ 65K로 늘렸을때 성능
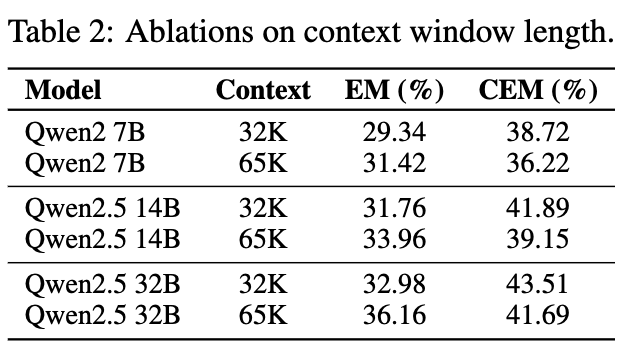
- EM이 증가한 이유: 전체 평가셋 중에, context length가 길어짐으로써 기존에 truncated되어 잘려져 나가, 정답을 못보아 틀린 경우가 사라지면서 성능 향상
- CEM이 감소한 이유: 정답이 존재하는 chunk 자체의 길이가 길어져, LLM의 rotary position embedding이 길어지고, target HTML element를 뽑는 난이도가 어려워짐
-
-
Data Size
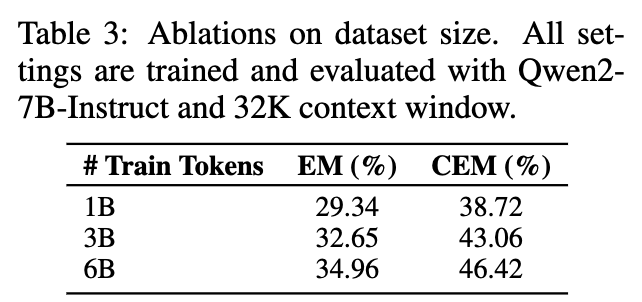
- 다다익선.
4. Experiments
-
Proprietary Dataset 정량적 결과 (1,200 samples)
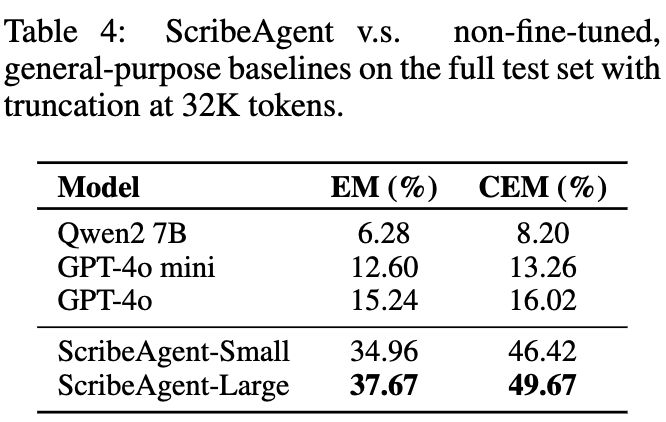
-
데이터 유형별 상세 결과
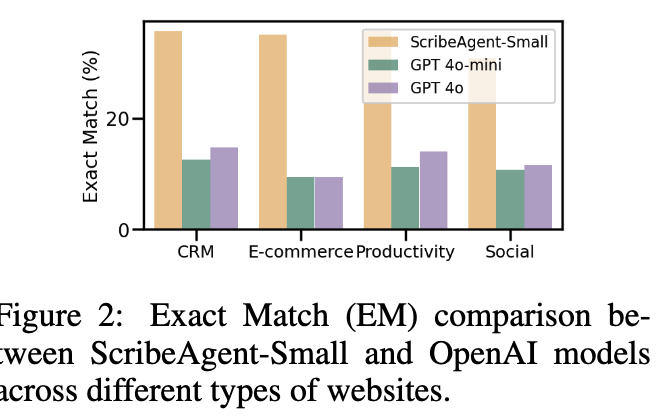
-
-
Proprietary Dataset vs. gpt-o1 (500 samples)
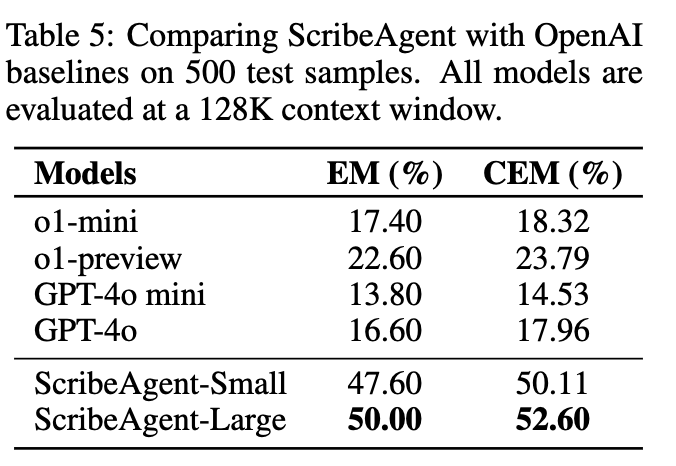
$\to$ finetuning이 효율적임을 시사.
-
Mind2Web
-
human demonstration workflow를 기반으로한 데이터셋
ex. AirBnB에서 예약.
- Evaluation Metric
- Element accuracy: target HTML element가 잘 선택되었가?
- action F1 score: text 입력 등의 작업이 잘 수행되었는가?
- success rate: target element + operation모두 잘 수행되었는가?
- Baselines
- Multi-stage, multi-choice QA agents (MindAct family)
- 전체 DOM에서 pretrained element-ranking model이 50개의 후보요소를 선택
- 별도의 LLM이 반복적으로 1개의 action이 선택될때 까지 5개의 action중 1개를 선택하고, multi-choice QA를 수행.
- Single-stage, generation-based agent (Flan-T5$_B$)
- 직접 operation + target을 생성
- Multi-stage, multi-choice QA agents (MindAct family)
-
정량적 결과
-
Multi-stage
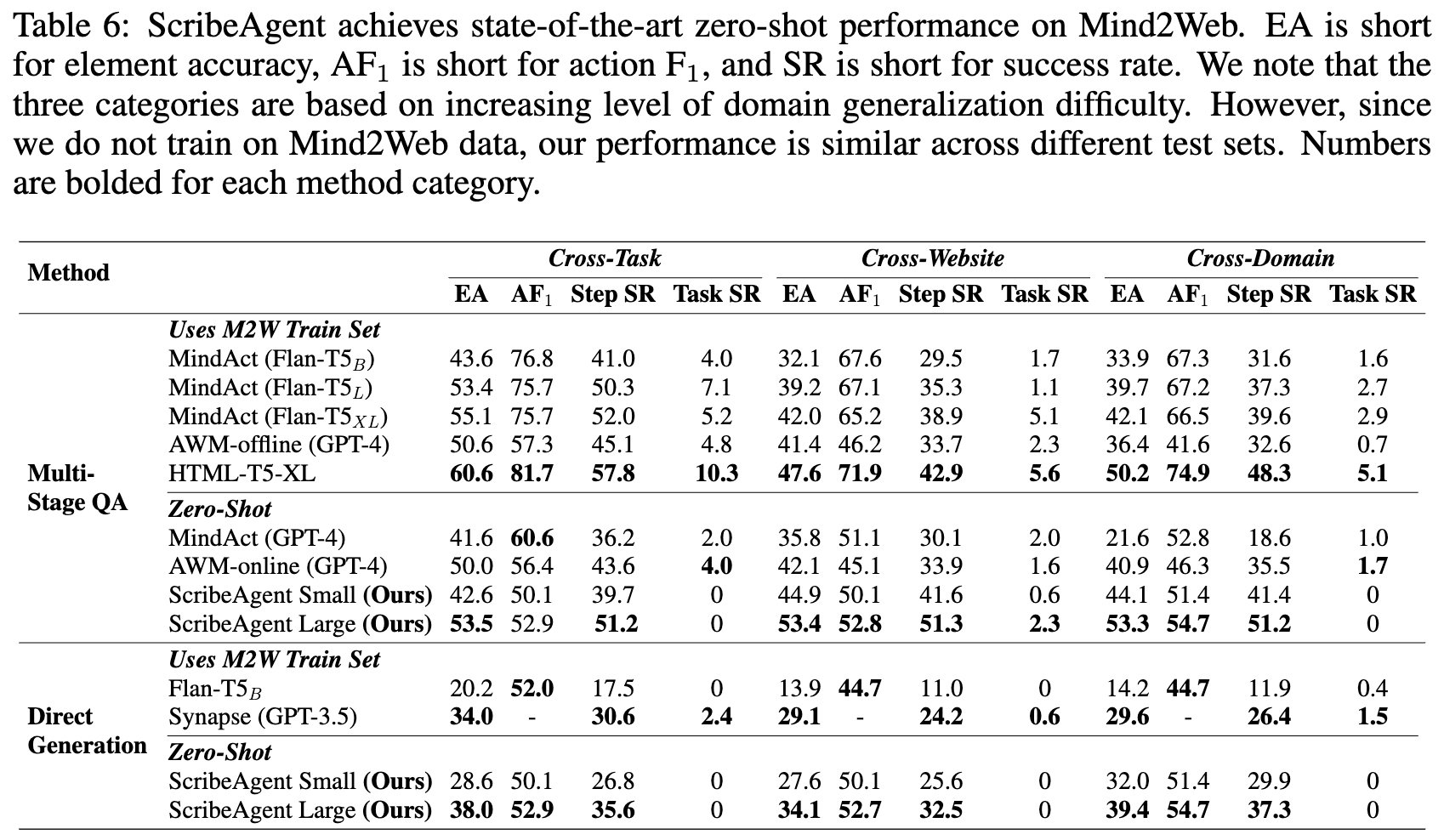
-
-
-
WebArena
-
Mind2Act같은 static, text-based benchmark는 1개의 목적 달성을 위해 오직 1개의 action trajectory만 맞다고 함.
-
하지만, 같은 목적을 다른 action trajectory로 달성할 수 있음
ex. “book a flight” :
enter destination$\to$enter departuredate` or vice versa.$\to$ dynamic benchmark인 WebArena가 필요
-
E-commerce (OneStopShop), social platform (Reddit), software development (GitLab), content management (CMS), online map (OneStreetMap)기으로 agent가 환경과 interaction을 수행하게 해줌
-
ScribeAgent는 HTML-DOM으로 학습되어있어, WebArena의 accessibility tree형태와 다른 format으로 출력함.
- 이를 reformatting해주기 위해 Chatgpt-4o를 사용
-
결과
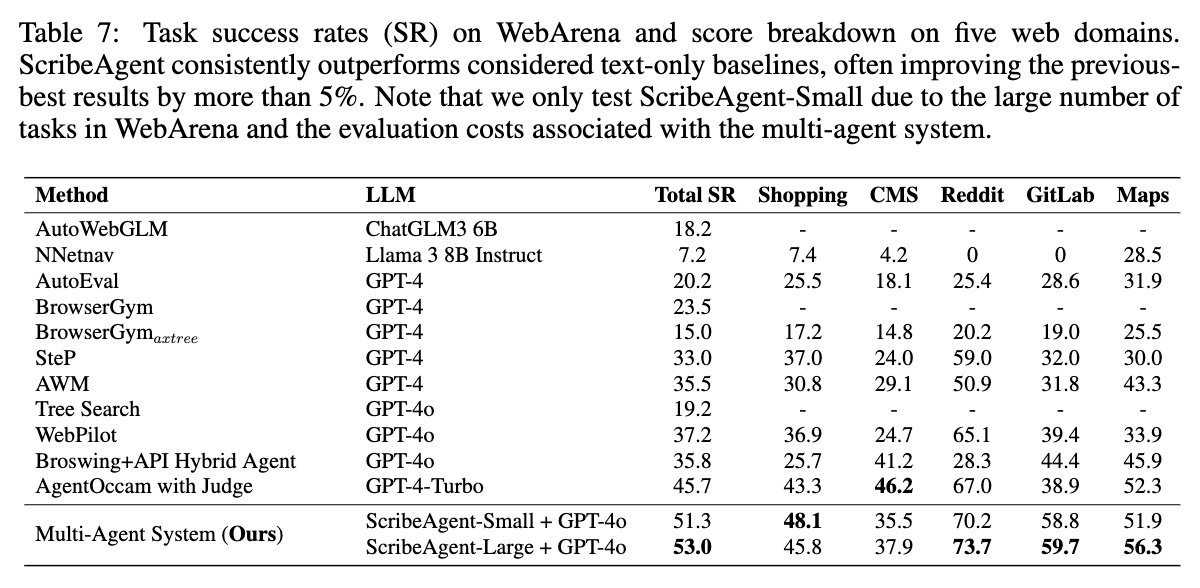
-
-
Ablation Study
-
WebArena에서 GPT-4o / ScribeAgent 유무에 따른 성능 변화
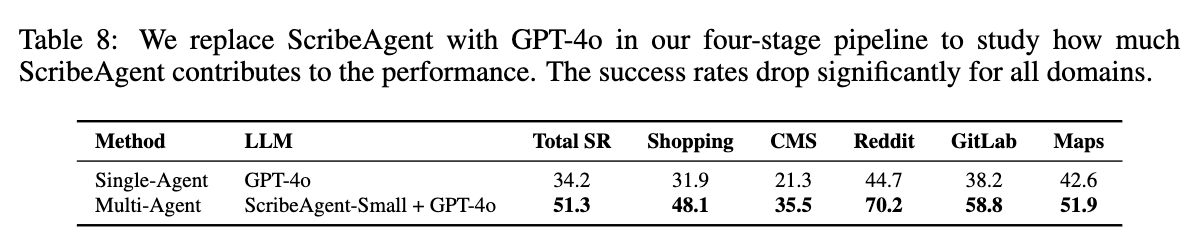
-
LLM backbone & Traning token 에 따른 Proprietary dataset 평가 결과
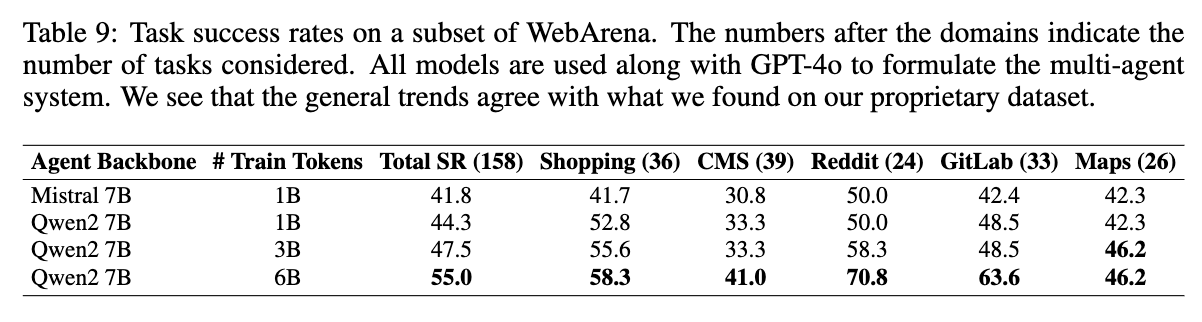
- Qwen2 > Mistral
- Training token 많을수록 좋아짐
-