[UDA][AL][SSG] STAL: Self-Training and Active Learning
[UDA][AL][SSG] STAL: Self-Training and Active Learning
- 원제목: Iterative Loop Learning Combining Self-Training and Active Learning for Domain Adaptive Semantic Segmentation
- 저자: Licong Guan, Xue Yuan (Beijing Jiaotong University)
- 날짜: 2023.02.09 Archived
- github: https://github.com/licongguan/STAL
Abstract
-
Self-training의 한계
- Pseudo label의 noise로 성능 하락
- Imbalanced unlabel data로 성능의 제약
-
Active Learning의 한계
- 방대한 양의 unlabel data를 활용하지 못함 → Sub-optimal
-
STAL = Self-Training Active Learning을 활용한 Iterative Learning Loop
-
Self-training + Active Learning = Semi-supervised Domain Adaptation
- Active Learning : 소량의 Target domain labeled data
- Self-training : 대량의 Target domain unlabeled data + Source domain labeled data
→ SSDA (Semi-supervised Domain Adaptation) : FireScout 컨셉에 부합!
-
Task : Semantic segmentation
-
Model : DeepLab v2, DeepLab v3+ (Res101)
-
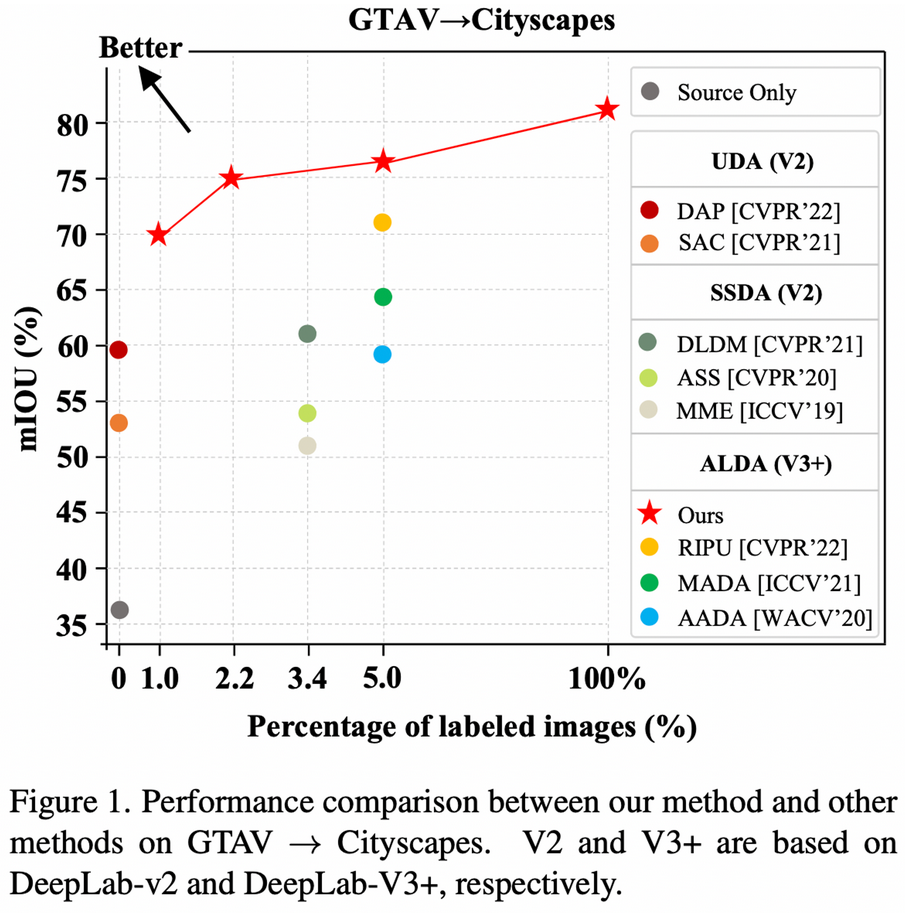
UDA / SSDA task 에서 SOTA
-
1. Introduction
-
Generalized Semantic segmentation 을 풀기 위해서는 엄청난 비용의 labeling cost가 든다.
-
기존에는 2가지 해결책이 존재했음
- Active learning → accurate model & practical selection strategy가 필요
- Self training → noisy pseudo label를 discover하고 false positive를 filtering 하는게 필요
-
제안하는 방식
-
Iterative loop learning 방식 : Self-training + Active Learning
→ Domain Adaption for Semantic segmentation
-
2. Related Work
2.1 Domain Adaptation
-
Domain Alignment
- Adversarial training기법을 적용하여 별도의 binary discriminator (class: target, source)와 generator (backbone)간의 minmax game을 풀며 target과 source feature간의 alignment를 진행하는 기법
- GRL (Gradient Reversal Layer)를 두어, loss term을 1개 학습
-
Domain translation
- Image to Image Transfer를 통해 Target-like source image 혹은 Source-like target image를 두고 학습하는 기법
-
Domain translation
- Image to Image Transfer를 통해 Target-like source image 혹은 Source-like target image를 두고 학습하는 기법
2.2 Semi-supervised Learning
Consistency Regularization
-
동일한 unlabeled image에 대해 다양한 perturbation을 주고, 같은 (consistent) 값을 예측하도록 제약을 줌으로써 perturbation에 강인한 특성을 학습하는 기법
- c.f.) Contrastive Loss : 같은 이미지에 대해서는 끌어당기고, 다른 이미지에 대해서는 밀어내는 학습
Entropy Minimization
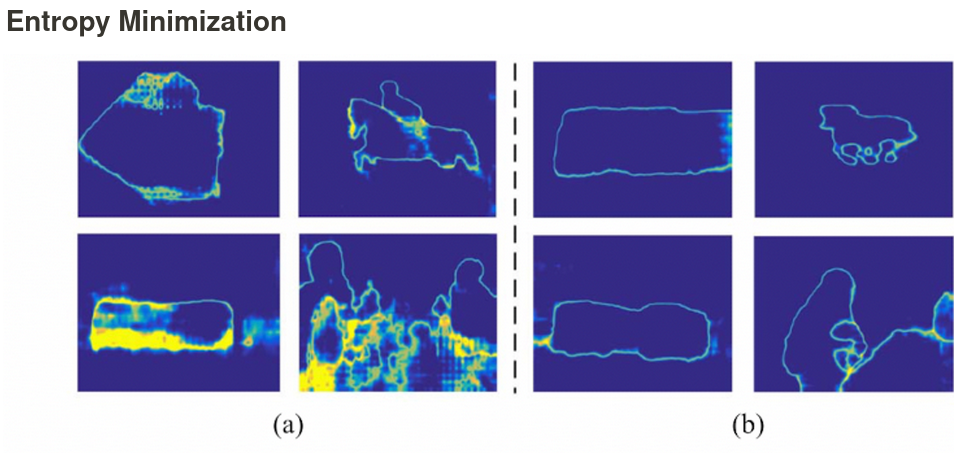
- Uncertainty를 Entropy로 계산하여, 이를 최소화하는 방향으로 학습
Self-Training
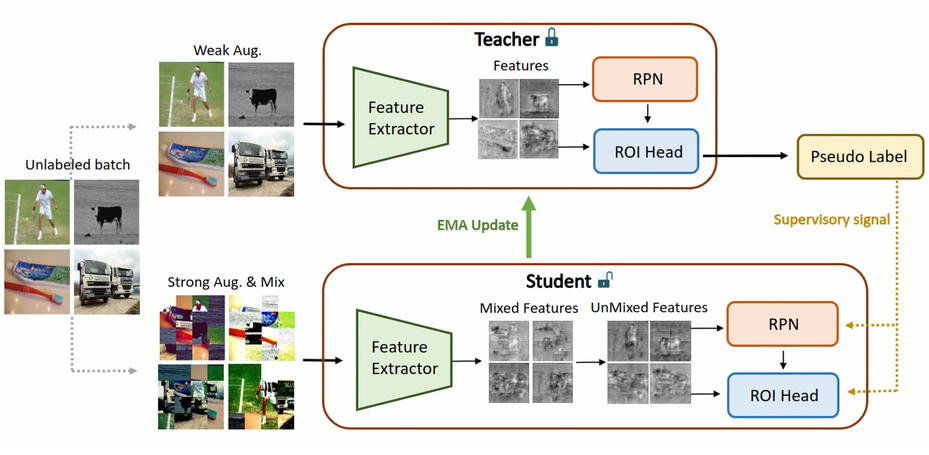
- Self-training pipeline을 이용하며, Pseudo label을 사용하여 학습
2.3 Active Learning
-
최소한의 labeling cost를 통해 model의 성능을 최대화하고자 하는 연구
-
때문에 적은 sub-dataset을 잘 고르는게 핵심! (core-dataset)
-
2가지 방식
-
Uncertainty-based method
불확실성 기반 액티브 러닝은 머신 러닝에서 활용되는 알고리즘 중 하나입니다. 이 방법은 모델이 가장 확실하지 않은 데이터를 라벨링하여 모델의 성능을 개선하는 방식으로 작동합니다. 즉, 모델이 불확실하게 예측하는 데이터를 사람이 직접 라벨링하고 이를 새로운 데이터로 모델 학습에 활용하는 것입니다. 이를 통해 모델이 새로운 데이터에 대해 더 정확한 예측을 할 수 있도록 합니다. 이 방법은 학습 데이터를 줄이면서 모델 성능을 개선할 수 있다는 장점이 있습니다.
-
Diversity-based method
Diversity-based method는 sub-dataset을 잘 고르기 위해 다양성을 기준으로 하는 Active Learning 방식입니다. 모델이 예측을 가장 불확실하게 하는 데이터를 우선적으로 labeling 하는 방식과는 달리, 다양한 데이터를 고르는 것이 핵심입니다.
-
3. Approach
3.1 overview
- 3 stage
- Self-training (Semi-supervised Domain Adaptation) or Warm-up Learning
- Active selection (Active Learning)
- Image labeling (Semi-supervised Domain Adaptation) or Incremental Learning
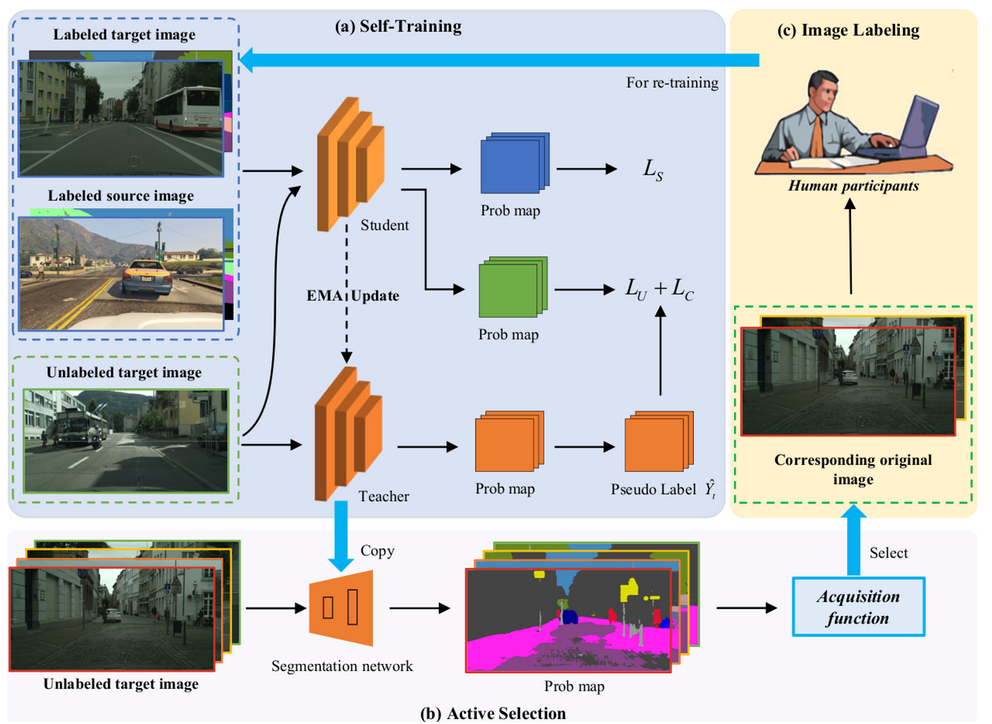
3.2 Self-Training Learning
-
Total loss
\[L=L_s+\lambda_uL_u+\lambda_cL_c\]-
$L_s,L_u$ : Cross Entropy Loss
\[L_s = \frac{1}{N_l}\sum_{i=1}^{N_l}\frac{1}{WH}\sum_{j=1}^{WH}l_{ce}(f\circ h(x_{i,j}^l;\theta), y_{i,j}^l) \\ L_u = \frac{1}{N_u}\sum_{i=1}^{N_u}\frac{1}{WH}\sum_{j=1}^{WH}l_{ce}(f\circ h(x_{i,j}^u;\theta),\hat{y}_{i,j}^u)\]- $l_{ce}$: standard cross entropy loss
- $f \circ h$ : h: feature-extraction → f : segmentation head
- $y_{i,j}^l$: i번째 이미지 j번째 pixel의 pixel-wise label (segmentation)
- $\hat{y}_{i,j}^u$: i번째 이미지 j번째 pixel의 psuedo label (segmentation)
- $N_l, N_u$: Mini-batch 내 labeled image & unlabeled image 갯수 (=256)
- $x_{i,j}^l$: i번째 labeled 이미지 j번째 pixel
- $x_{i,j}^u$: i번째 unlabeled 이미지 j번째 pixel
- $W,H$: width, height of segmentation label
-
$L_c$: Contrastive Loss
\[L_c=-\frac{1}{C \times M}\sum_{c=0}^{C}\sum_{i=1}^{M}log[\frac{e^{<a_{ci},a_{ci}^{+}>/w}}{e^{<a_{ci},a_{ci}^{+}>/w}+\sum_{j=1}^Ne^{<a_{ci},a_{cij}^{-}>/w}}]\]- $M$: total number of anchor pixels (=50)
- $a_{ci}$: total i번째 c class anchor samples
- $a_{ci}=g \circ h(x_{ic})$
- $x_{ic}$: class에 속한 i번째 anchor pixel
- $g$: representation space로 투영하는 layer
- $a_{ci}=g \circ h(x_{ic})$
- $a_{ci}^+$: anchor pixel $a_{ci}$와 동일한 class인 pixel (1개)
- $a_{cij}^-$: anchor pixel $a_{ci}$와 동일한 class인 pixel 중 j번째 pixel (N=256개)
- $N$: anchor pixel과 negative 관계를 갖는 pixel들 중, loss에 반영할 pixel의 갯수
- $<\cdot,\cdot>$: cosine similarity
- $C$: Number of Class
- $w$: hyper-parameter (=0.5)로, $<,>$값을 -1~1로 bound시키는 역할
-
-
Imbalanced Issue
-
Tail categories : instance 갯수가 적은 class (Cityscapes: wall, traffic-light, etc)
-
class별 confidence library를 EMA방식으로 갱신하며 사용 (classwise memory bank활용)
\[Conf^c=\frac{1}{N_l}\sum_{i=1}^{N_l}\sum_{j=1}^{N_i^c}(f \circ h(x_{i,j}^c;\theta)), c \in {1,..,C} \\ Conf_n^c=\alpha Conf_{n-1}^c+(1-\alpha)Conf_n^c, c \in {1,..,C}\]- $N_i^c$: category c에 해당하는 i번째 이미지의 pixel 총 갯수
- $n$: n번째 iteration
- $N_l$: labeled image의 갯수
- $\alpha$: ema update 상수 (=0.999)
-
sampling probability $s=Softmax(1-Conf)$
-
3.3 Active Learning
-
Pseudo Label의 Error는 ML model의 성능을 하락시킴 → Human (Operator)의 개입으로 label-correction이 필요
-
Sample acquisition strategy
-
Uncertainty 를 기준으로 높은 녀석들을 labeling 후보로 선정 (←→ EFL논문과는 반대인 이유?)
- input : warm-up model $\theta_w$ , unlabeled target image $x_t$
- output : sampled target image $\bold{S}$
- $\bold{P}_t^{i,j,c}$: c번째 channel(class) i번째 이미지, j번째 pixel의 prediction 결과
- $A$: active learning 시스템의 query 함수
- Target Image에서 사전에 정한 갯수만큼 Top K개를 uncertainty를 기준으로 상위 K개의 이미지를 query한다.
-
4. Experiments
Dataset
- Synthetic Data
- GTAV :24,966장
- 1,914 x 1052
- 19 classes (Cityscapes와 공유)
- Synthia : 9,400장
- 1,280 x 760
- 16 classes (Cityscapes와 공유)
- GTAV :24,966장
- Real Data
- Cityscapes : 2,975장 (Train) + 500장 (Validation)
- 2,048 x 1,024
- Cityscapes : 2,975장 (Train) + 500장 (Validation)
Model Architecture
- DeepLabv2, DeepLab v3+ (Resnet101)
- pretrained in ImageNet
- SGD optimizer
- lr = 2.5e-3
- weight decay = 1e-4
- resize into 769 x 769
Annotation Budget
- 1st round :
- Labeled Data
- Source domain 전체 (100%)
- Target domain (Cityscapes)의 1% 를 라벨링 (30장)
- Unlabeled Data
- Target domain 99% (2,970장)
- Labeled Data
- 2nd round :
- Labeled Data
- Source domain 전체 (100%)
- Target domain (Cityscapes)의 2.2% (35장) or 5%(120장)을 라벨링
- Unlabeled Data
- Target domain 99% (2,965장 or 2,880)
- Labeled Data
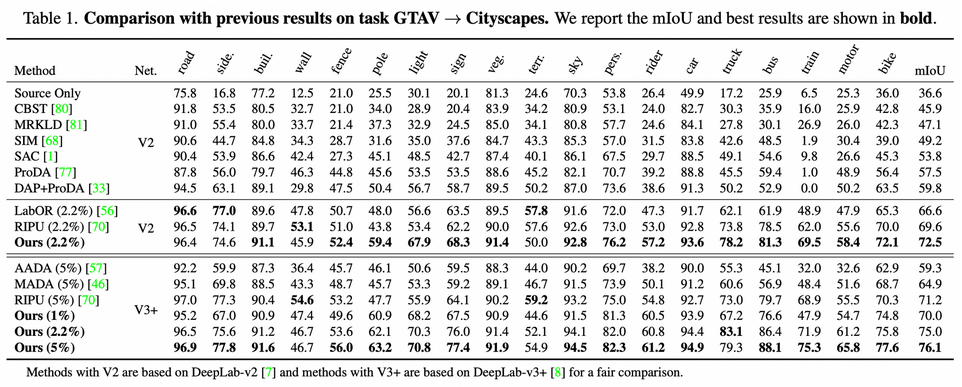
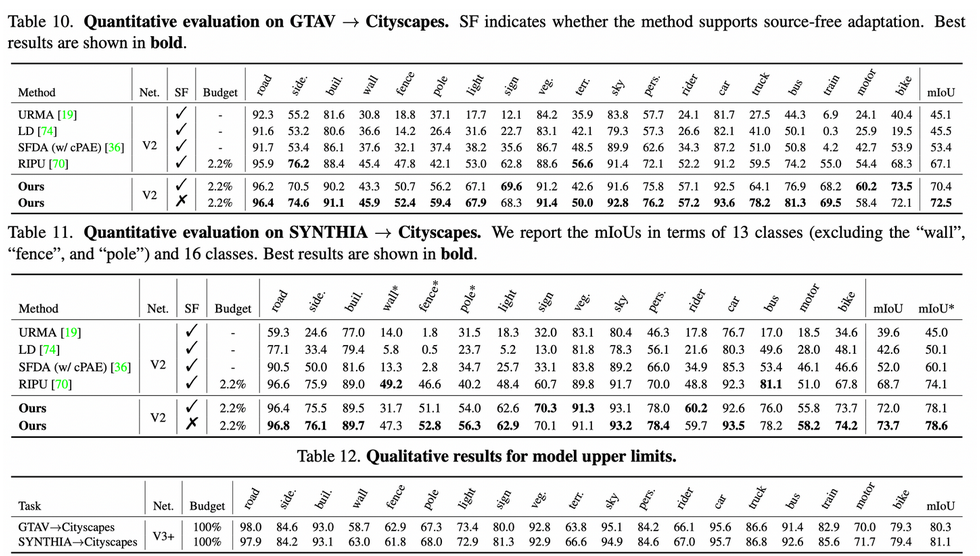
GTAV → Cityscapes.
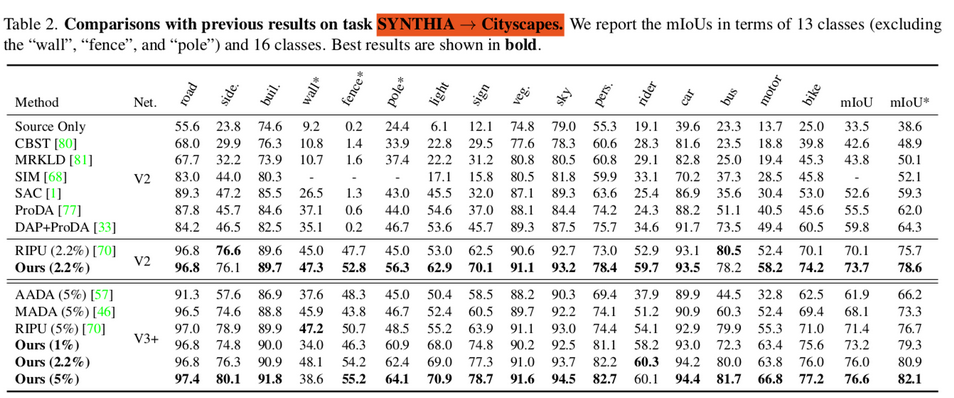
SYNTHIA → Cityscapes.

Ablation Study
-
Data_aug : Copy_and_paste + Cutmix
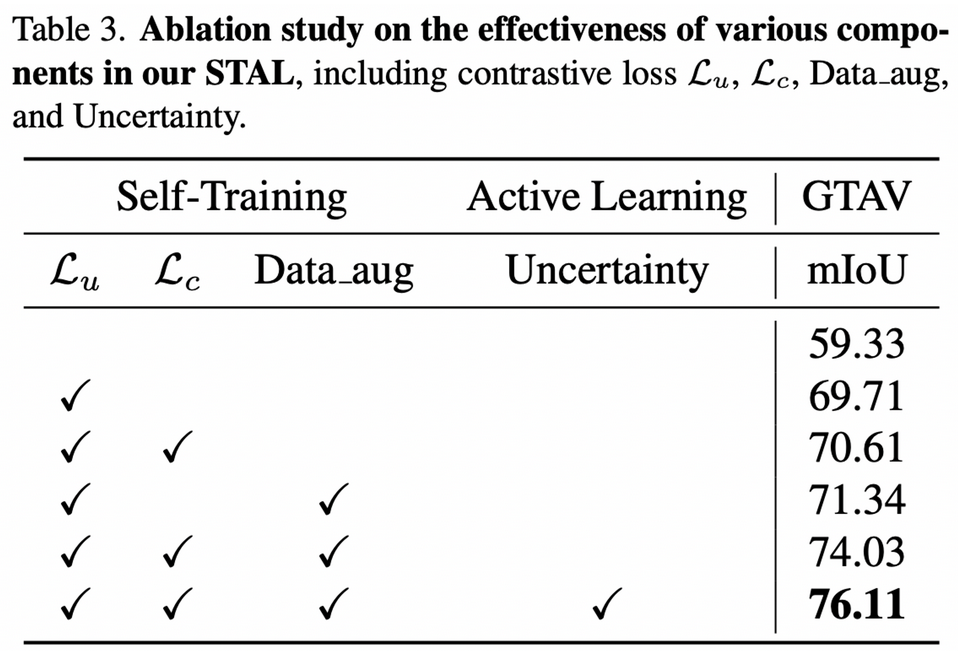
Extension to open set domain adaptive.
-
Source domain(Synthia data)에 없는 3개의 클래스에서 적은 수의 target label dataset으로 성능 향상이 확연히 보임 → Active learning이 효과적임
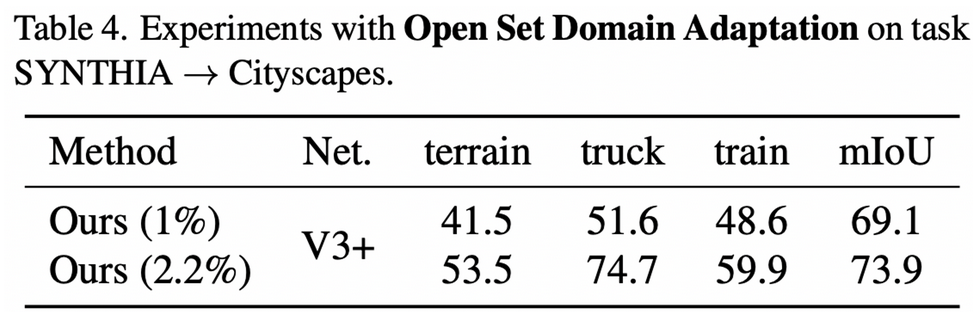
Compare with SSDA
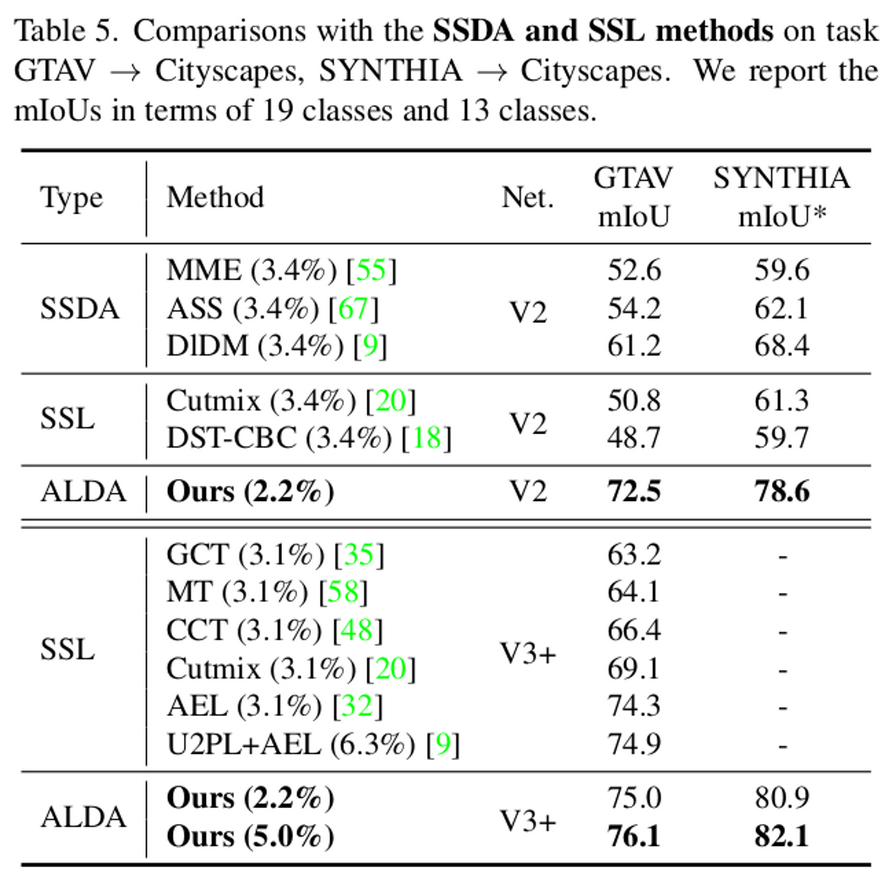
Source free DA
Qualitative Analysis
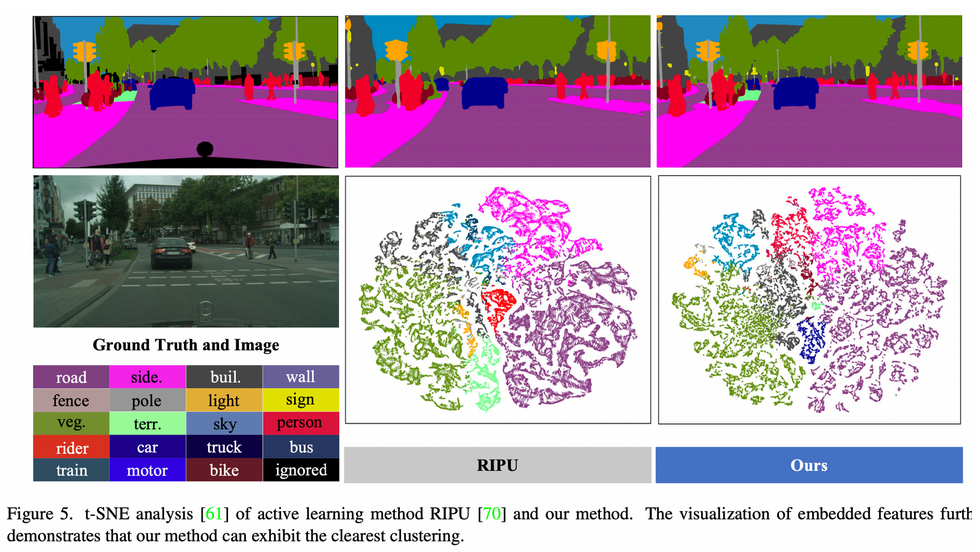
References
[66] Semi-supervised semantic segmentation using unreliable pseudo-labels.https://arxiv.org/pdf/2203.03884.pdf : Contrastive Loss 관련 논문으로 읽어봐야함
[70] Binhui Xie, Longhui Yuan, Shuang Li, Chi Harold Liu, and Xinjing Cheng. Towards fewer annotations: Active learning via region impurity and prediction uncertainty for domain adaptive semantic segmentation. In CVPR, pages 8068– 8078, 2022. 3, 5, 6, 7, 8, 12, 13, 14, 15, 16 : Active Learning SOTA라서 봐야함 & Active Learning concept를 많이 인용해서 봐야함
[22] Yarin Gal, Riashat Islam, and Zoubin Ghahramani. Deep bayesian active learning with image data. In ICML, pages 1183–1192. PMLR, 2017. 2 : Active Learning 중 Diversity based라서 봐야함
[4] WilliamHBeluch,TimGenewein,AndreasNu ̈rnberger,and Jan M Ko ̈hler. The power of ensembles for active learning in image classification. In CVPR, pages 9368–9377, 2018. : Active Learning 중 Uncertainty based라서 봐야함
Appendix
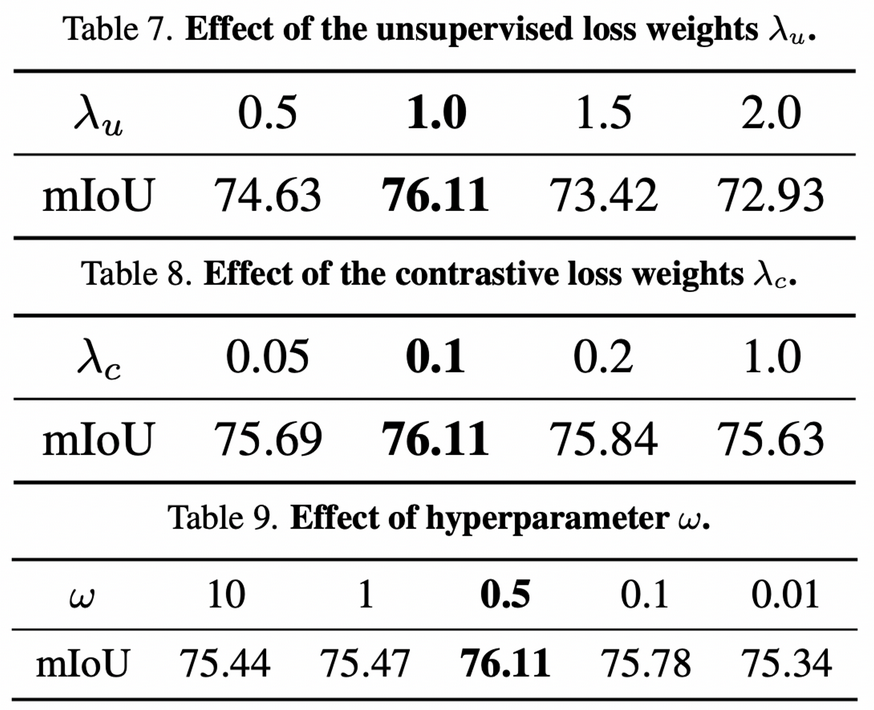
Hyperparameter Tuning
Source-free DA(SFDA) & Upper bound (Oracle)
Robustness (Catastrophic Forgetting)

Expected Questions
How to get pos, neg anchors?
- Pseudo label에서 각 class별로 reliable한 pixel에 대해 positive anchor를 설정함
- Unreliable한 pixel에 대해 memory bank를 만들어 contrastive loss를 계산
