[CLS][SC]SIFER: Overcoming Simplicity Bias in Deep Networks using a Feature Sieve
[CLS[SC] SIFER: Overcoming Simplicity Bias in Deep Networks using a Feature Sieve
- paper: https://arxiv.org/abs/2301.13293
- github: X
- ICML 2023 accpeted (인용수: 1회, ‘24-01-19 기준)
- downstream task: Tackling Spurious Correlation (Debiasing) for CLS
1. Motivation
-
Feature space와 label space 상에 Spurious correlation이 real world data에 종종 발생함
- ex. waterbird in water background / long hair for women, etc
-
이는 DNN이 simplicity bias때문에 발생한다고 가정한다.

- ex. Colored-MNIST dataset에서 문자의 shape를 보고 문자를 분류하는게 아니라, 색을 보고 분류하게 됨
-
어떻게 하면 spurious correlation & simplicy bias를 해결할 수 있을까?
2. Contribution
-
simplicity bias가 lower-layer에서 발생하고, higher-layer로 갈수록 bias가 증폭되는 것에 착안하여 이를 자동으로 인지하고, suppress해주는 개념인 “feature sieve (채질하다)” 를 제안함
- lower-layer에서 자동으로 feature의 simplicity bias를 자동으로 인지하고, suppress해주어 high-layer가 더 meaningful한 representation을 갖도록 만듦
-
제안한 방식이 simple-bias feature는 Suppress하고, complex feature의 decodability를 enhancing해줌을 보임
-
decodability
-
해당 feature에 대한 label을 가지고 학습된 weight를 freeze하고, auxiliary decoder만 학습시켜 decoder가 출력한 accuracy
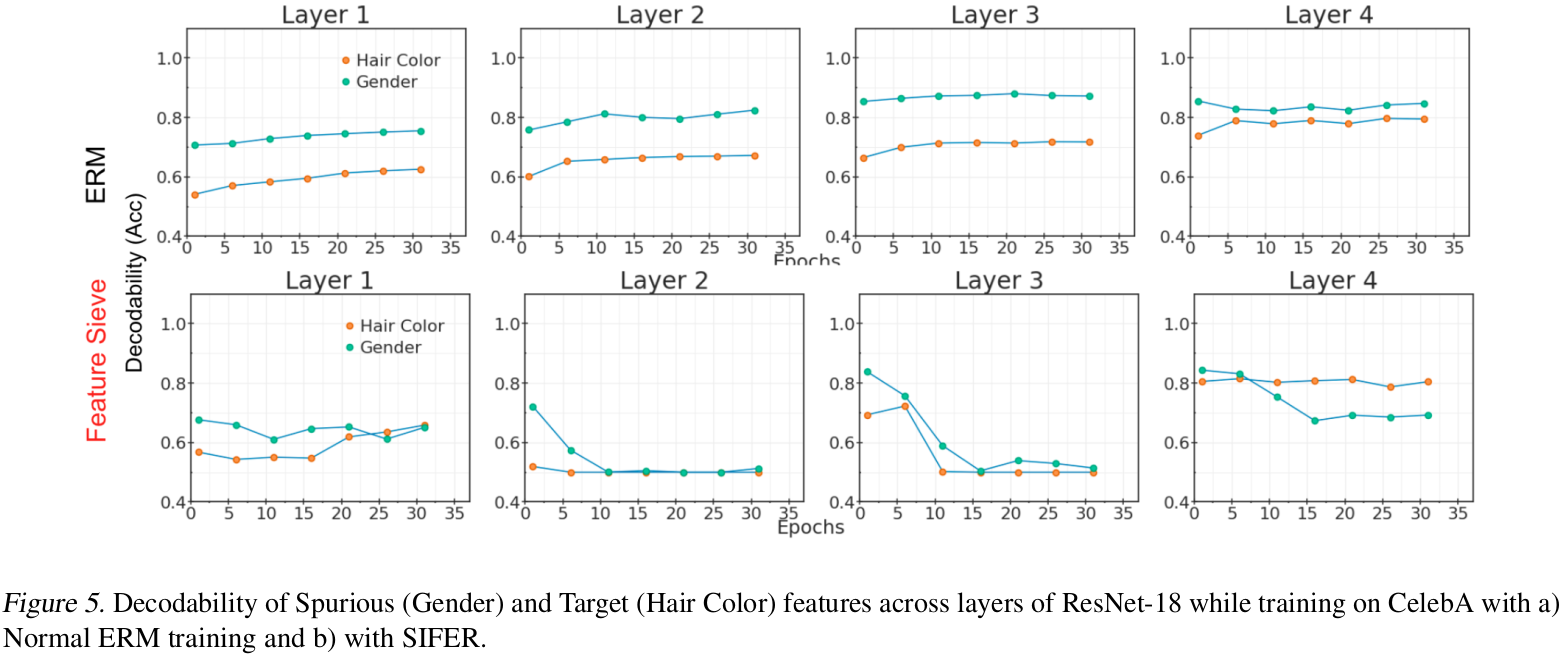
- CelebA 데이터는 “Blond” hair-color의 99%여 여자인 spurious correlated dataset임 (hair-color vs gender).
- 본 task는 Gender를 예측하는 문제라 가정. (Gender의 decodability는 높고, hair-color의 decodability는 낮은게 좋은 것임)
- (1행): Original Method (ERM) 결과. spurious feature (Gender)의 decoability가 hair-color보다 높다.
- (2행): Feature Sieve의 결과. spurious feature (Gender)의 decodability는 낮고, hair-color의 decodability는 높다.
-
-
-
Baseline대비 debiasing benchmark에서 성능 향상을 보임
-
Debiasing Classification benchmark에서 추가적인 biased feature 를 사용하는 baseline보다 성능이 좋음을 보임
-
GradCAM을 통해 SIFER의 방식이 전경만 spurious correlated feature는 제거하고, comple feature만 제대로 바라보게 학습함을 보임

3. SIFER (Sieving Features for Robust learning)
- SIFER는 simple-biased feature는 빨리 학습되어, early-layer에서부터 시작되며, higher-layer에 가면 극도로 영향이 커져, 정작 학습해야할 complex feature를 학습시키지 못한다 가정한다.
-
SIFER는 이런 simplicity-bias를 추가 정보 없이 알아서 제거해주는 방법을 제시한다.
-
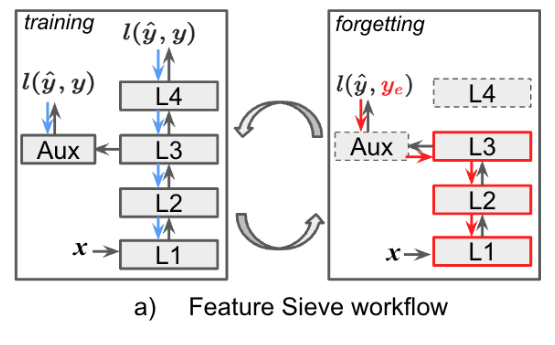
Overall Diagram
-
Forgetting Loss와 Training Loss을 번갈아가며 학습함
-
Forgetting Loss : Early-layer에서 simple-biased된 feature를 통해 label을 예측하게 함으로써, spurious-correlated feature를 학습한 L1~L3에서 제거해주는 과정
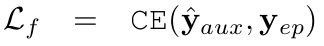
- $y_e$: erase-label. uniform probability vector를 활용함
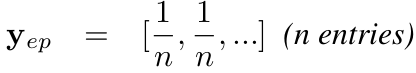
-
n: class의 갯수
-
$\hat{y}_{aux}$: Auxiliary classifier의 출력값. Forgetting Loss로 학습을 할 때, main network만 학습하고, auxiliary classifier는 frozen시킴.
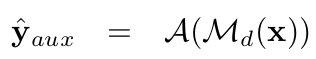
- A: Auxiliary Classifier
- $M_d$: Main network
-
Training Loss : Supervised Learning과 동일
-
-
-
Overall Algorithm

- 추가된 hyper-parameter
- $A_D$: Auxiliary network의 depth
- $A_P$: Auxiliary network의 position
- $F$: forget과 training의 비율
- 추가된 hyper-parameter
4. Experiments
4.1. Dataset
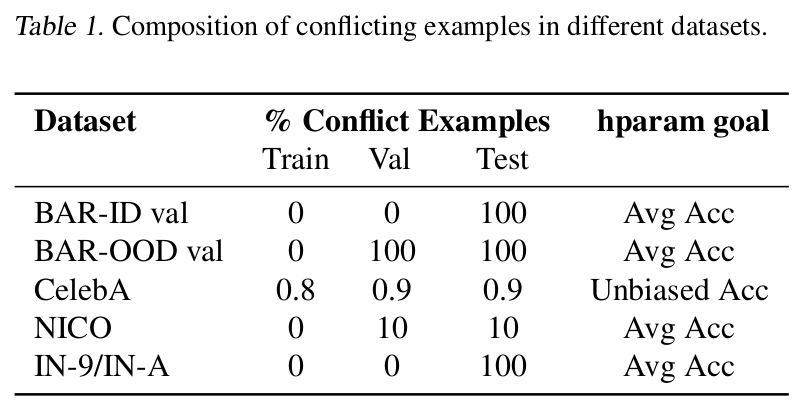
- BAR: Biased Activity Recognition dataset. (Spurious correlated : activity vs. background) Train set에만 S.C.된 이미지가 있음
- ex. rocks with climbing $\to$ trainset
- ex. ice with climbing $\to$ testset
- CMNIST : 2-class synthetic dataset (spurious correlated : color vs. digit)
- 0 class + red
- 1 class + green
- CIFAR-MNIST : 2-class real dataset (simplicity biased : MNIST vs. CIFAR)
- 0 class - MNIST (simple dataset)
- 1 class - CIFAR data (complex dataset)
- CelebA : hair-color 분류하는 목적으로 활용됨 (spurious correlated : gender vs. hair-color)
- blond-har 99%가 여자임
- NICO : 10개의 class로 구성된 animal dataset. out-of-distribution robustness 체크목적인 데이터.
- train data : 7class
- validation+test data : 10class
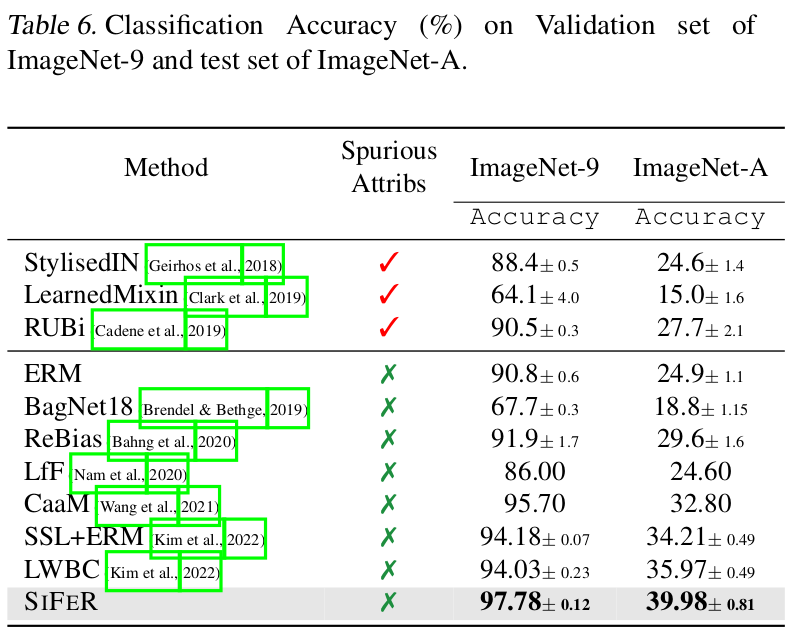
- ImageNet-9: 9개의 super-category로 묶인 Spurious correlated imagenet (Image texture vs. object labels)
- ImageNet-A: ImageNet으로 학습된 모델이 잘못 예측한 hand-picked dataset Spurious correlated data (color + texture vs. object labels)
4.2. Result
-
Layer-wise Decodability for MNIST-CIFAR dataset
- Simple vs. Complex에 대한 추가 label을 제공한게 아님.
- CIFAR dataset의 경우 randomize을 하더라도 accuracy drop이 없었음 $\to$ complex feature를 지님. (simplicity-biased되어 있지 않다는 얘기)
- MNIST dataset의 경우 randomize을 하면 accuracy drop이 생김 $\to$ simple feature를 지님.
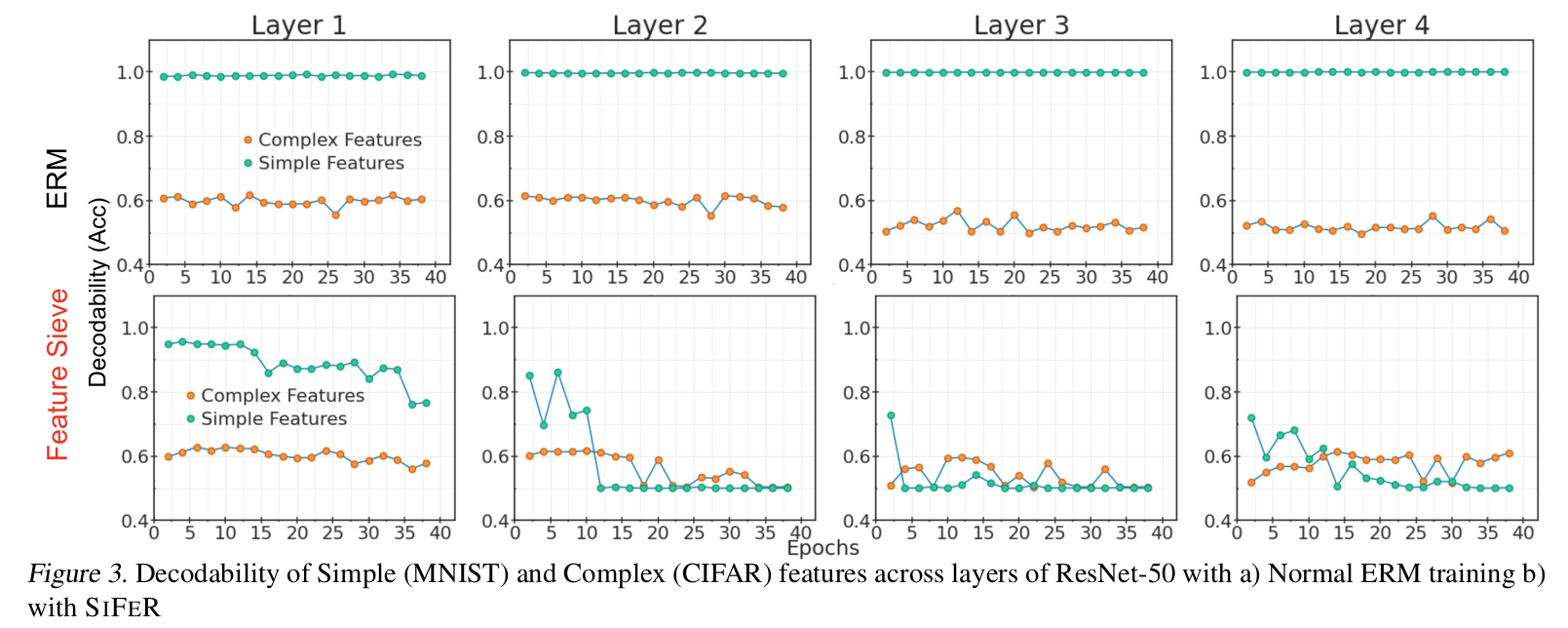
- 1행: ERM의 경우, Layer가 거듭될수록 complex feature (CIFAR)의 decodability가 줄어듦 $\to$ simplicity-biased
- 2행: SIFER는 Higher layer에서 Complex feature의 성능이 좋아짐
-
Feature Controllability of SIFER
-
domain-shfit된 validation set을 가지고, suppress혹은 enhance하고자 하는 feature를 통제할 수 있음을 보임
-
enhance하고자 하는 feature 선정 방법 : 그외 feature와 “non-relavant”한 feature를 randomizing시킴
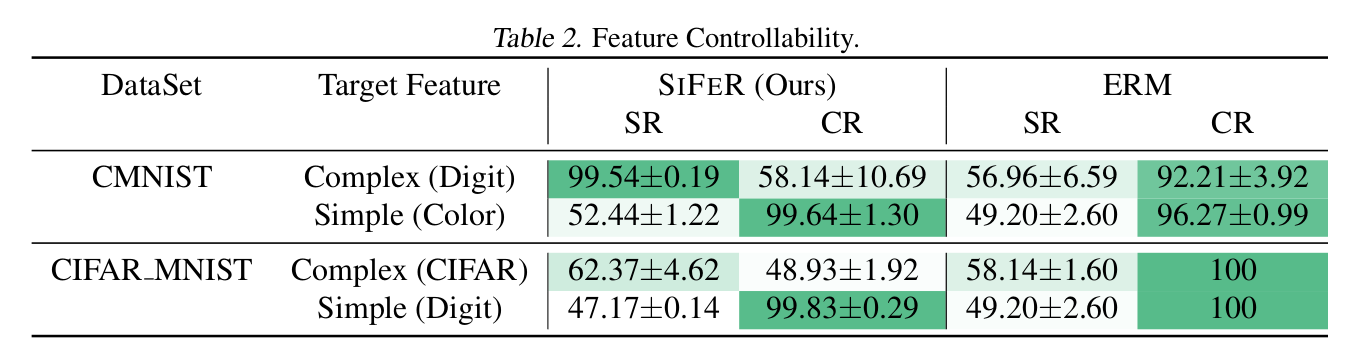
- Target Feature : enhance하고자 하는 feature
- SR: Simple randomized
- CR: Complex randomized
-
-
Debiasing in Real-world Dataset
-
NICO, BAR, CelebA
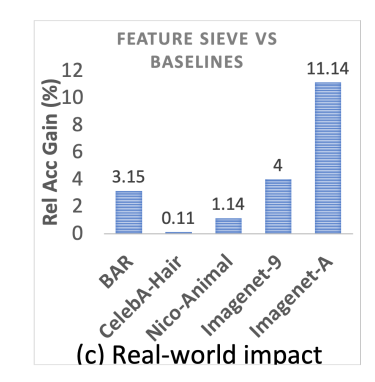
-
-
BAR dataset
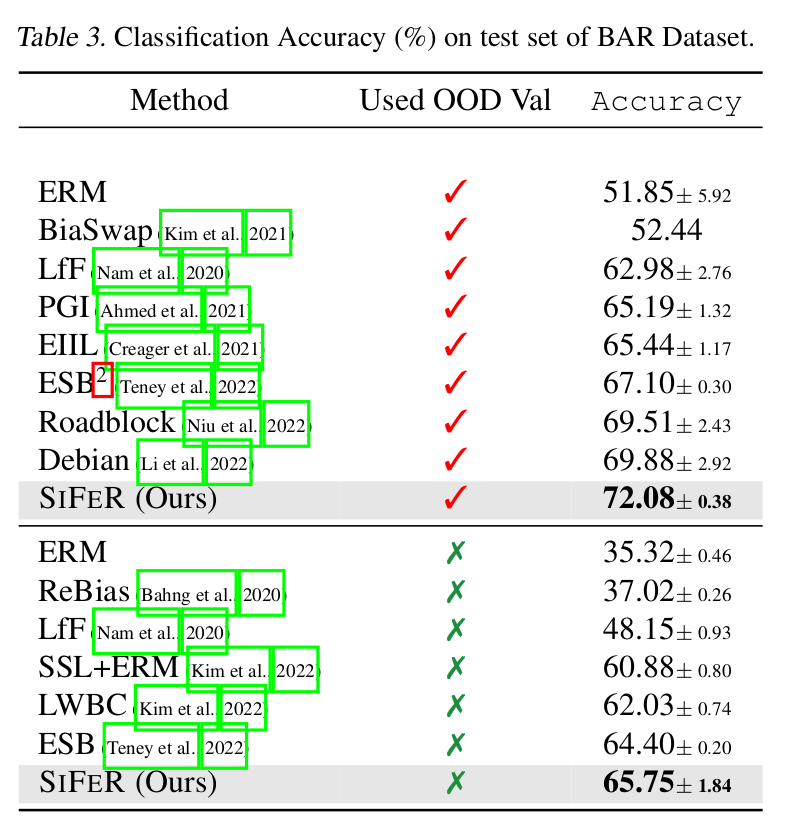
-
CelebA Hair dataset
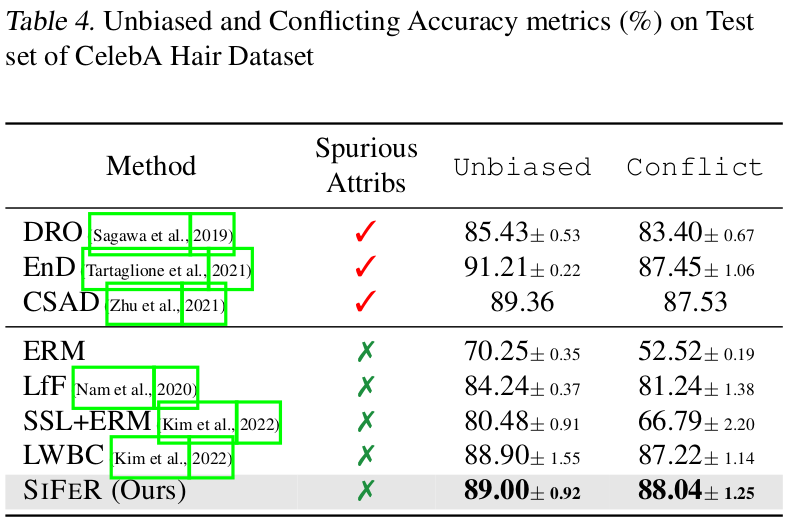
-
Decodability
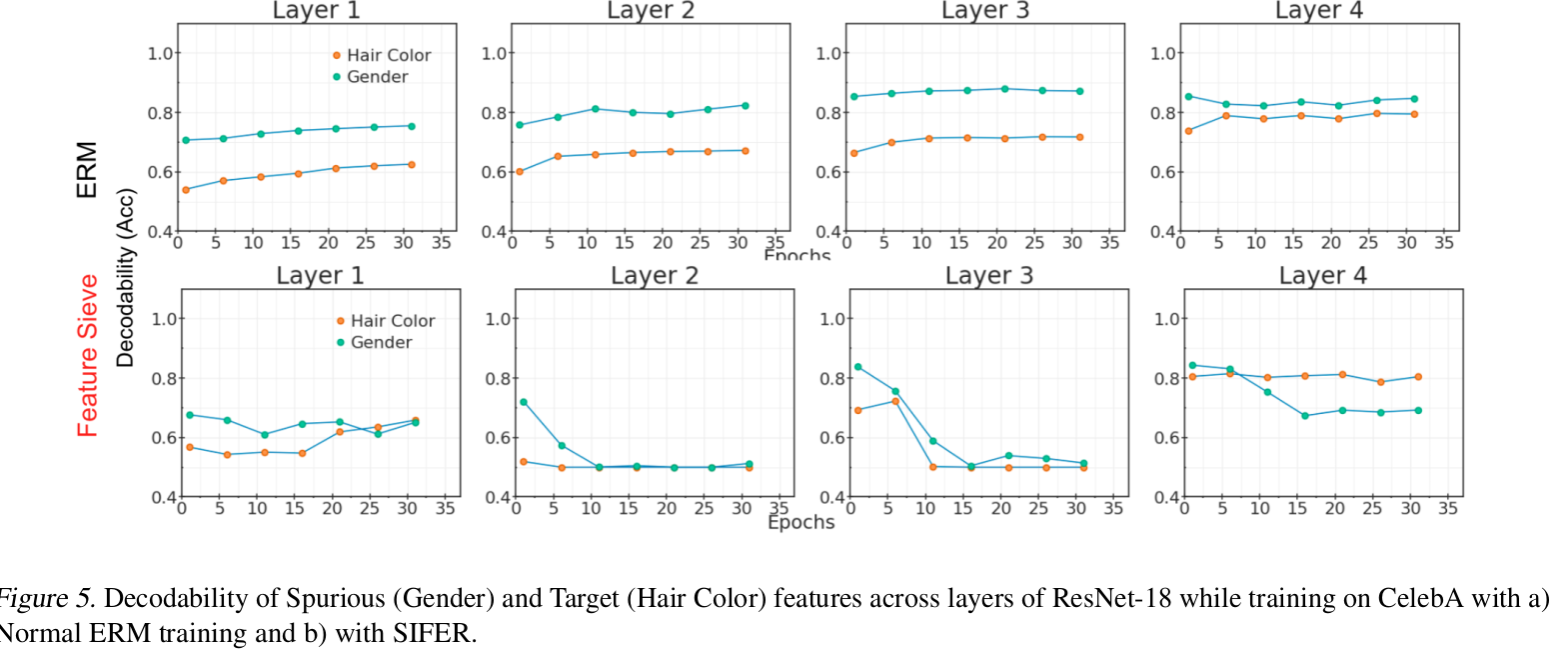
-
-
Domain-shift (Label-shift) Generalization (NICO) 에 robust
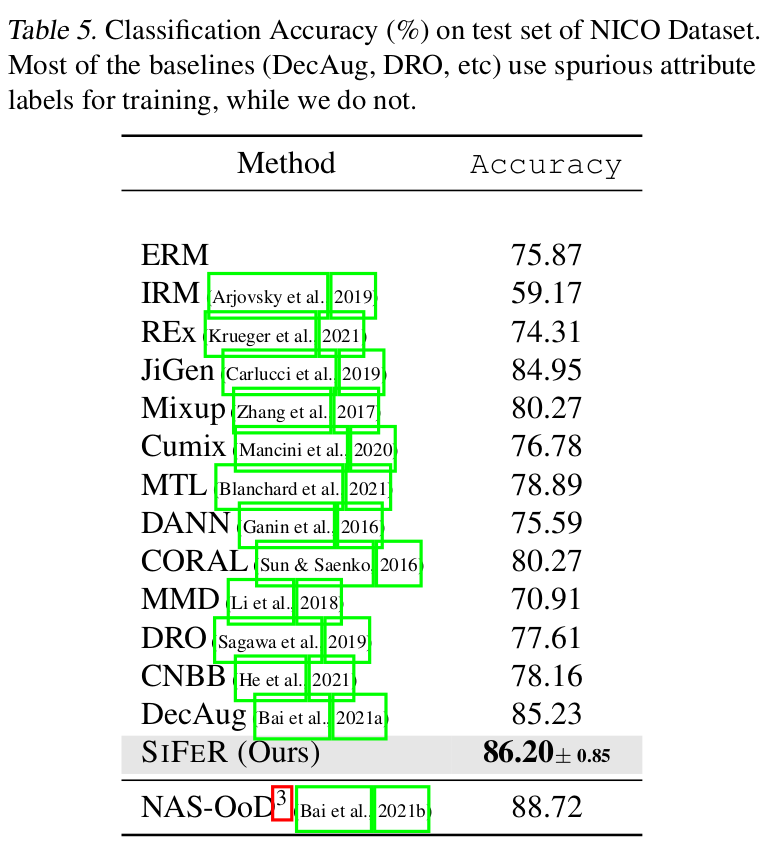
-
Texture-bias (ImageNet-9) 에 robust