[UDA][SSG] PiPa: Pixel- and Patch-wise Self-supervised Learning for Domain Adaptative Semantic Segmentation
[UDA][SSG] PiPa: Pixel- and Patch-wise Self-supervised Learning for Domain Adaptative Semantic Segmentation
- paper: https://arxiv.org/abs/2211.07609
- github: https://github.com/chen742/PiPa
- ACM Multimedia 2023 accpeted (인용수: 12회, ‘23.12.17 기준)
- adownstream task : UDA for SS
1. Motivation
- 기존에 UDA for Semantic segmentation은 domain간의 discrepancy를 최소화하는 방향으로만 연구가 진행되었음
- 반면, 이미지 내의 context correlation과 같은 domain 내의 knowledge에 대한 연구는 under explored 됨. -> 본 논문은 도메인 내의 정보를 활용하여 domain-invariant한 정보를 학습하는 self-supervised framework를 제안하고자 함
2. Contribution
-
도메인 내의 correlation을 고려한 PiPa (Pixel-wise, Patch-wise) self-supervised learning framework를 제안함

- Pixel-wise: 클래스 내부적으로 compact하게 학습하며, 클래스간에는 separabilityassss를 키우게 학습함 (contrast-learning)
- Patch-wise: 동일한 patch에 대해서는 다른 context에서도 identical 하도록 학습하고 (regularization), 다른 patch는 멀어지도록 학습함
-
UDA SS dataset에서 SOTA
3. PiPa
-
overall framework
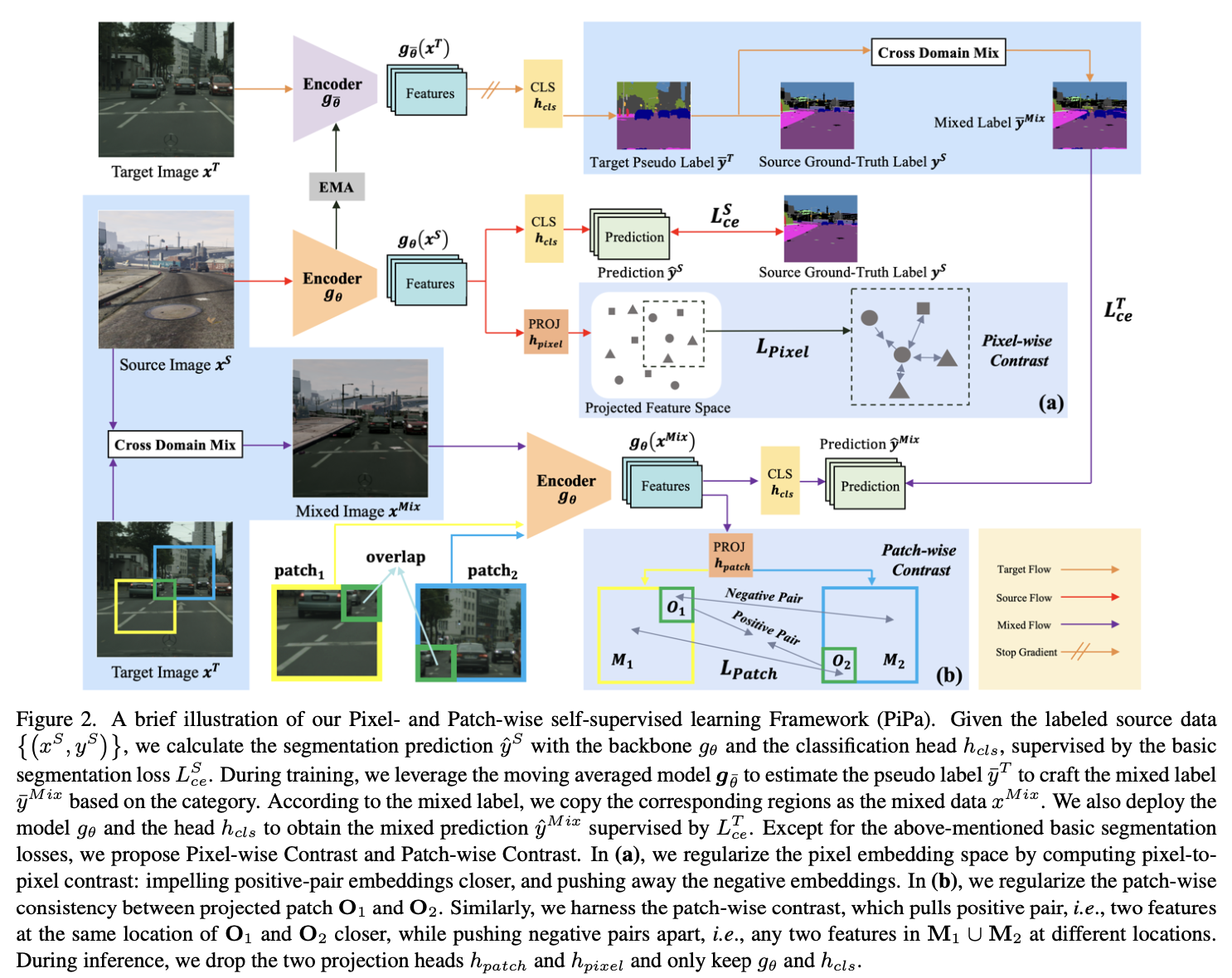
-
Basic segmentation loss
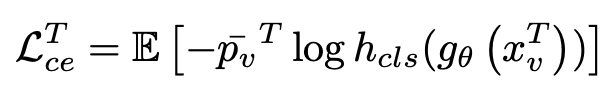
- $L_{ce}^T$: Target data의 cross entropy loss
- $p_v^T$: target domain의 pseudo label
- $g_{\theta}$: feature extractor
- $h_{cls}$: segmentation head
-
Mixed segmentation loss
-
source와 target domain간의 cutmix를 통한 domain alignment learning을 수행함
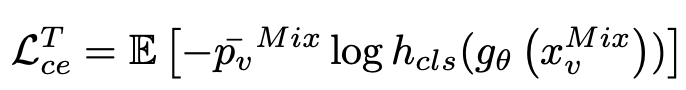
-
3.1 Pixel-wise Contrast
-
같은 Class pixel간에는 당기고, 다른 class pixel간에는 밀어내도록 학습함
- Self-supervised manner로 intra class내에서 domain invaraint한 정보를 추출하는 기법
- 별도의 MLP layer로 projection한 space에서 클래스간의 similarity를 계산함
-
목적: 같은 class끼리는 당기고, 다른 class끼리는 밀어내어 pixel-wise separability를 증가시키고자 함
- hard example간에 학습하기 위해 image내 뿐만 아니라, batch 내의 pixel들 중 hard example을 추출함
- positive : similarity 하위 10%인 동일 class pixel로 구성
- negative: similarity 상위 10%인 다른 class pixel로 구성
- hard example간에 학습하기 위해 image내 뿐만 아니라, batch 내의 pixel들 중 hard example을 추출함
-
Label이 있는 source domain에서만 수행함
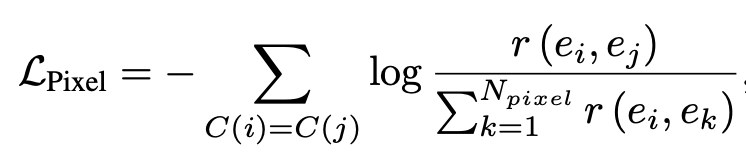
- $r$: simiarity matrix. 여기선 exponential cosine similarity로 계산함
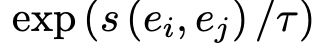
- $r$: simiarity matrix. 여기선 exponential cosine similarity로 계산함
3.2 Patch-wise Contrast
-
목적: 동일한 위치에 있는 Patch에 대해 당기고, 다른 위치는 밀어내도록 학습함
- positive : 같은 위치에 있는 patch 영역
- negative : 다른 위치에 있는 patch 영역
- hard negative를 만들기 위해 image내 뿐만 아니라, batch내에서 negative region patch를 추출함
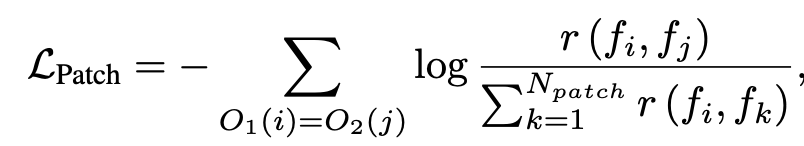
- $f_i, f_j$: i,j 번째 patch head에서 출력한 feature
- $O_1, O_2$: 두 patch 1,2 중에 overlapping하는 영역
-
Total Loss
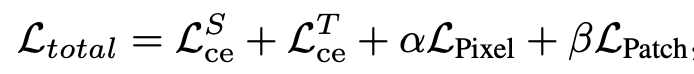
-
Overall Algorithm

4. Experiment
-
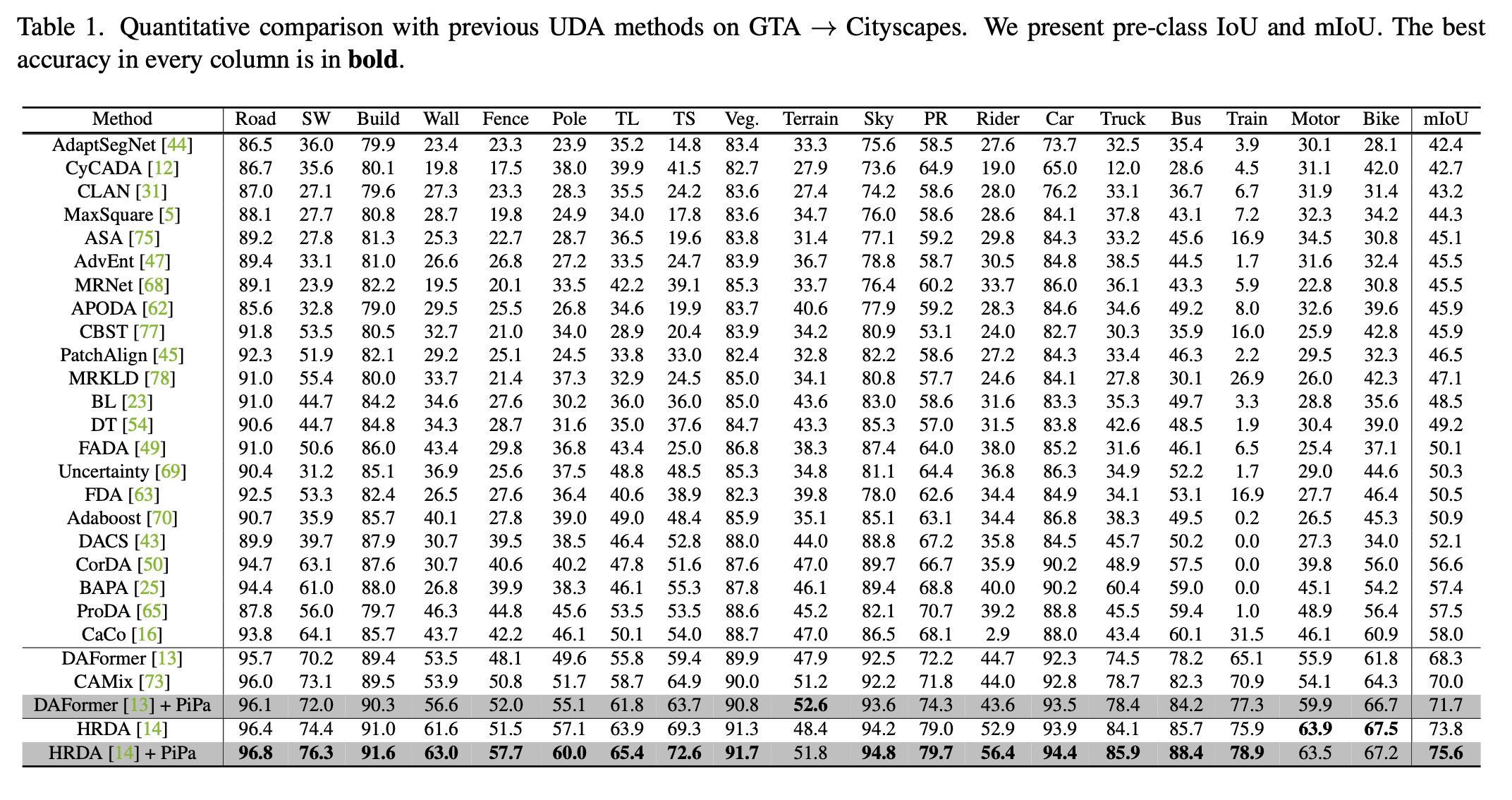
GTA2Cityscapes
-
Quantitative Result
-
Qualitative Result

-
-
Synthia2Cityscapes
-
Quantitative Result
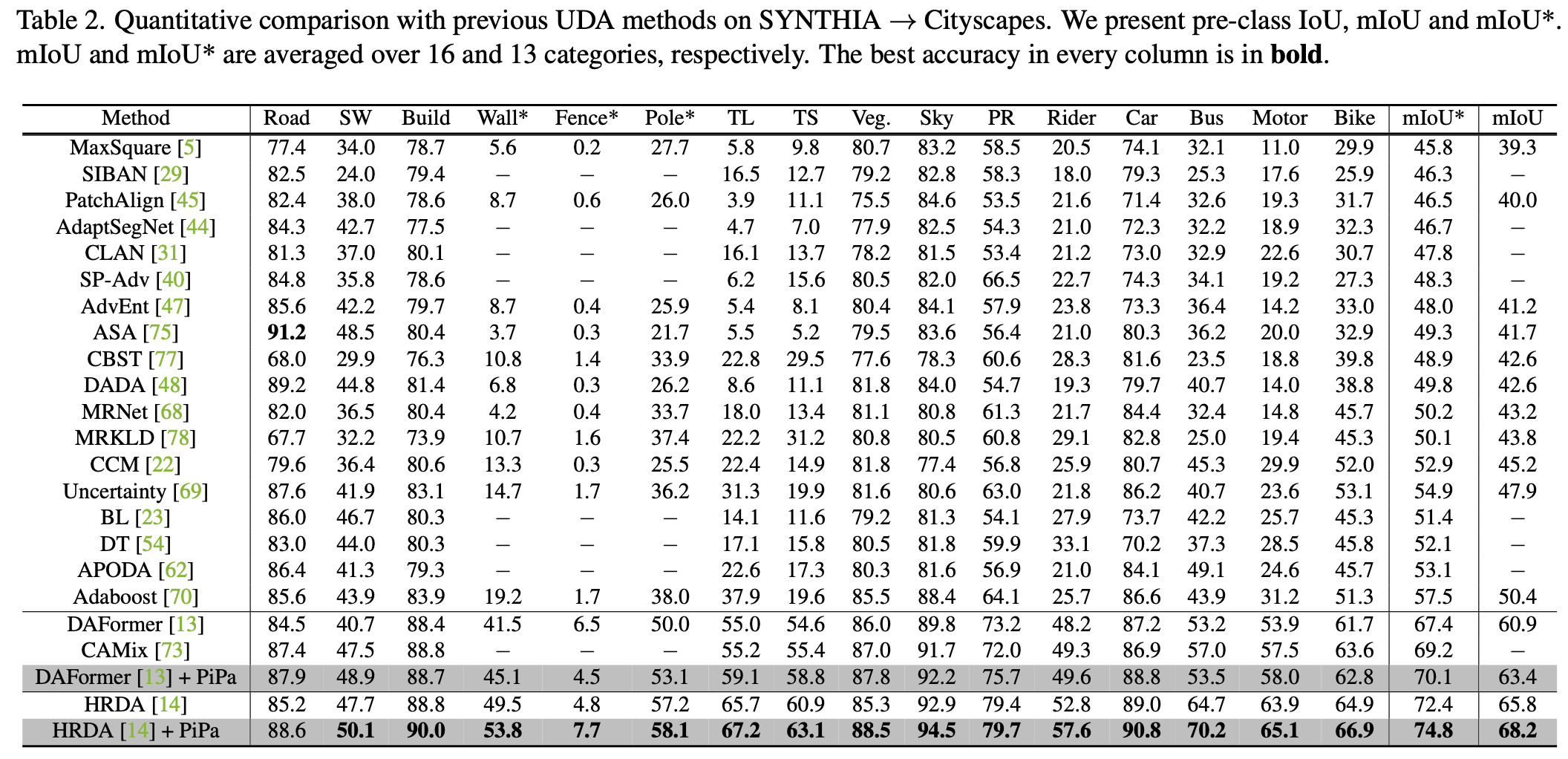
-
-
Ablation Study
-
$\alpha, \beta$
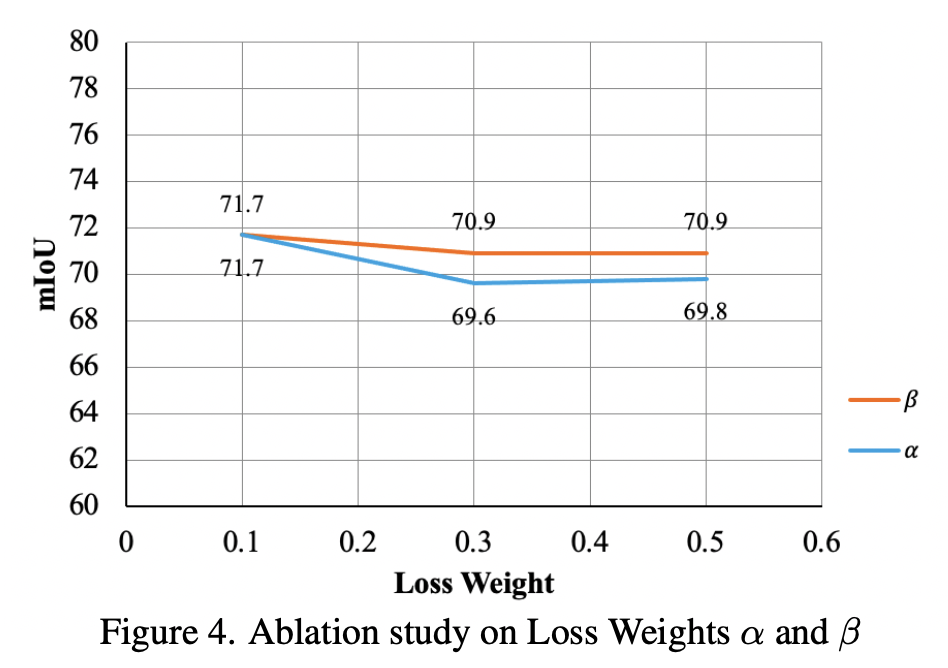
-
Module에 따른 성능 차이 & patch size에 따른 성능 차이
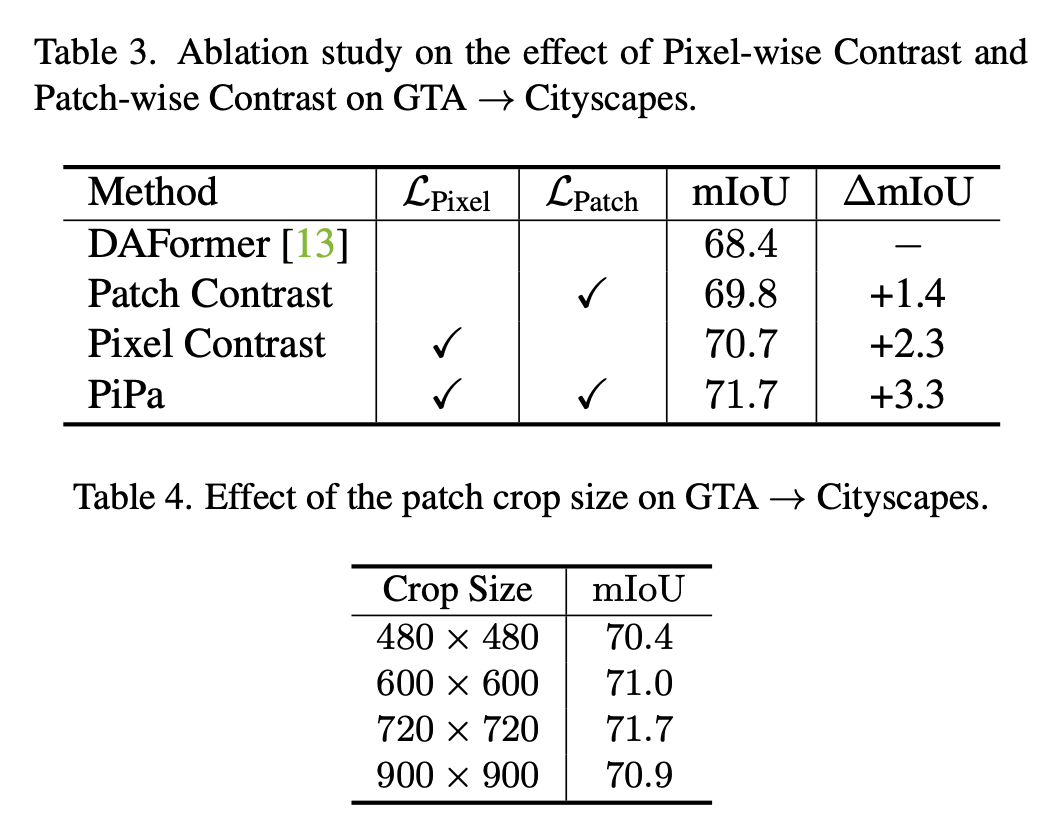
-