[Agent] PPTArena: A Benchmark for Agentic PowerPoint Editing
[Agent] PPTArena: A Benchmark for Agentic PowerPoint Editing
- paper: https://arxiv.org/pdf/2512.03042
- github: https://github.com/michaelofengend/PPTArena
- archived (인용수: 0회, ‘25-12-22 기준)
- downstream task: PPT Agent benchmark
1. Motivation
- Image/PDF 기반의 task는 템플릿(deck)의 semantics(formats, placeholders, shape trees?)을 고려하지 않음 $\to$ 편집기반의 태생적 차이가 from scratch에서 시작하는것과 존재함
-
Text-to-Slides task는 전체 slide를 새로 만드는 task로, edit-in-place 제약을 무시한다.
ex. “모든 슬라이드의 소제목을 18pt로 바꾸고 두 로고를 그리드에 맞춰 정렬해”
- edit-in-place 요구: 각 슬라이드에서 기존 소제목 텍스트 상자를 찾아 폰트 크기만 바꾸고, 로고 객체의 좌표를 수정 $\to$ 기존 z-order·그룹 유지
- text-to-slides 방식: 슬라이드를 새로 생성하거나 텍스트를 재삽입하여 시각적으로는 18pt처럼 보이지만, 마스터/플레이스홀더 연결이 끊기고 다른 슬라이드와 스타일이 달라짐 $\to$ 슬라이드 마스터, 테마, 플레이스홀더 관계가 깨져서 전체적인 스타일 일관성이 깨짐
-
템플릿(deck) 기반 디자인은 from scratch가 아니라, 검토를 거쳐 수정하는 과정이므로, edit-in-place를 유지하는게 중요함.
- 최신 Multimodal agents가 고품질로 주어진 템플릿(deck)를 editing으로 고품 visual quality의 창작물을 생성할 수 있을까?
2. Contribution
-
PPT editing을 템플릿 내의 구조적 & 인과관계로 정의한 최초의 benchmark인 PPTArena를 제안함
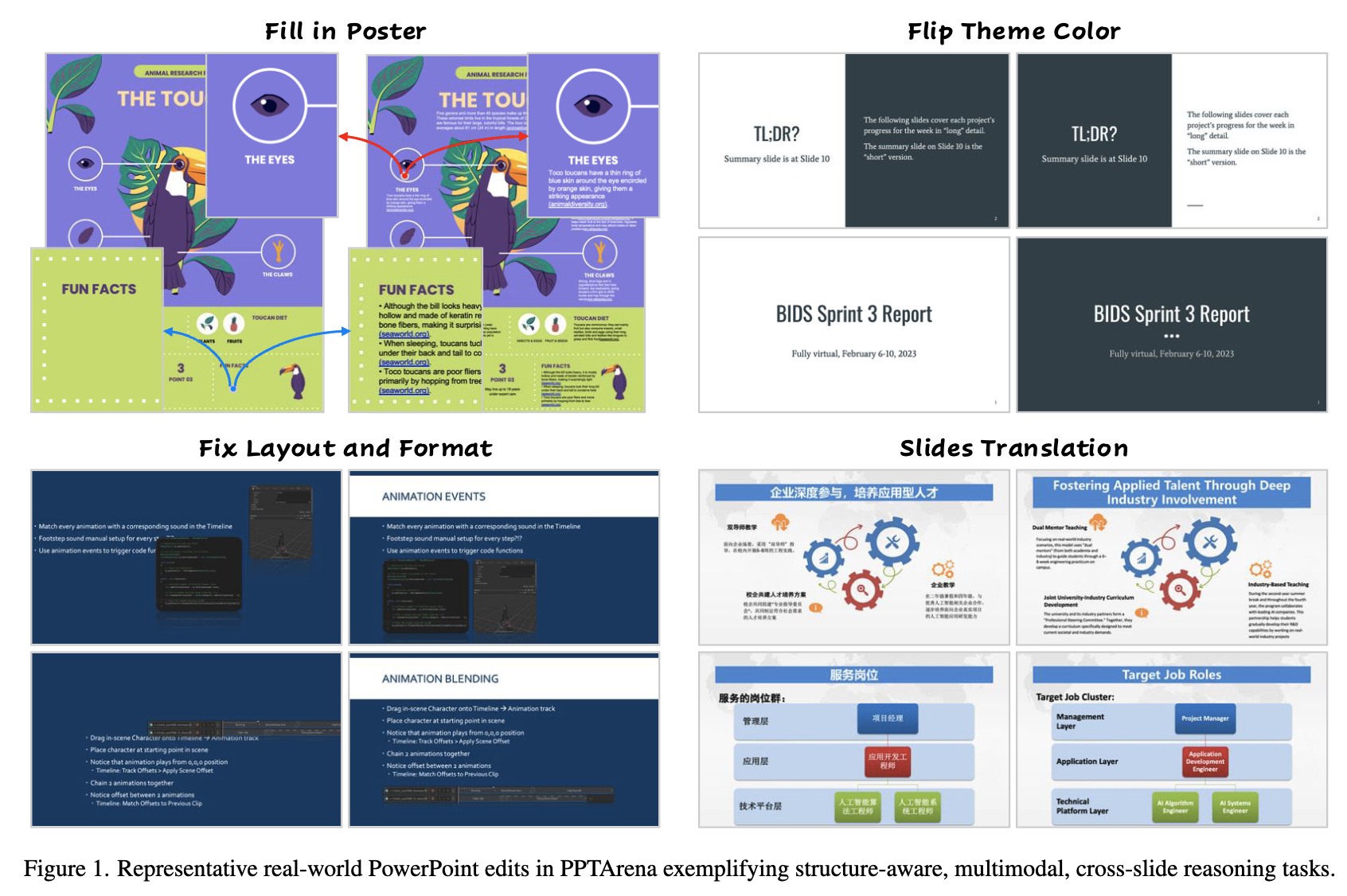
-
최초의 ppt 템플릿 기반의 benchmark (Target 템플릿별 정답을 제공) $\to$ 2,125 slides / 100개의 템플릿에서 800+개의 편집과정으로 구성.
-
템플릿의 내용기반 구조적 & 인과응보적 task로 바라본 최초의 benchmark
-
single/multi edit tasks로 구성됨. (ex. cross-slide consistency, structural grounding, etc) (Error 지시문을 제공)
-
element-level의 정답지를 제공 && Dual VLM-as-a-judge 활용
-
Instruction Following (IF) checker
-
Visual Quality (VQ) checker
-
-
-
- Structure-aware Robust & Fine-grained PPT agent인 PPT-Pillot를 제안함
- Structure-aware?
- 전체 템플릿 내 정보들 (ex. 슬라이드 마스터, placeholder, shape trees, texts, etc)을 파싱하고, 이를 고려하여 계획을 세움
- 대상을 식별하여 instruction (“subtitle을 xxx로 바꿔줘”)을 이해함
- 전체 템플릿 내 정보들 (ex. 슬라이드 마스터, placeholder, shape trees, texts, etc)을 파싱하고, 이를 고려하여 계획을 세움
- Robust?
- 반복적인 plan-edit-refine loop
- Fine-grained?
- dual operations(tools)를 사용 $\to$ user의 instruction에 따라 알맞은 tool이 호출
- high-level APIs (
python-pptx): global한 편집에 적합 (ex. 번역, 일괄 정규화) - direct XML patching: local한 편집에 적합 (ex. font, color, theme color, position)
- high-level APIs (
- dual operations(tools)를 사용 $\to$ user의 instruction에 따라 알맞은 tool이 호출
- Structure-aware?
- 다양한 상용 모델들 & ppt-agent들로 경험적인 실험을 진행함
3. PPTArena
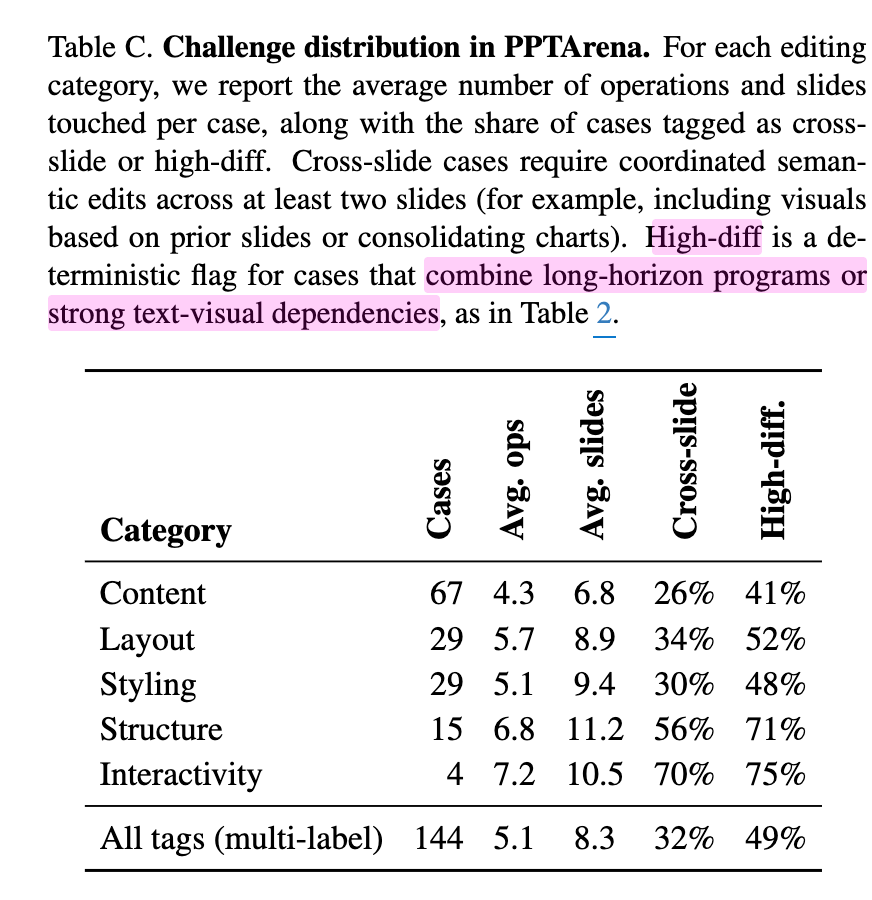
3.1 Benchmark Composition & Difficulty
-
2,125개의 slides에서 추출한 100개의 real-world editing task로 구성
- 초기 deck, target deck (human-generated)이 존재함.
-
15K powerpoint (SlidesCarnival, Zenodo, SlideShare, etc)로부터 pptx파일을 다운
-
가장 multimodal asset이 많고 복잡한 top500개를 수동으로 검사
-
Quality: layout이 안깨졌는지, 저해상도 이미지가 없는지, unreadable 텍스트는 없는지
-
Privacy: 개인 정보가 미포함됐는지
-
Complexity: 복잡한 차트, grouped shape에 우선순위를 부여
-
-
structured JSON형태로 layout, styling, content metadata를 추출
-
다양한 유형의 멀티모달 assets (ex. tables, etc)이 있고, 다양한 주제를 커버하도록 수동으로 리뷰

-
6가지 카테고리
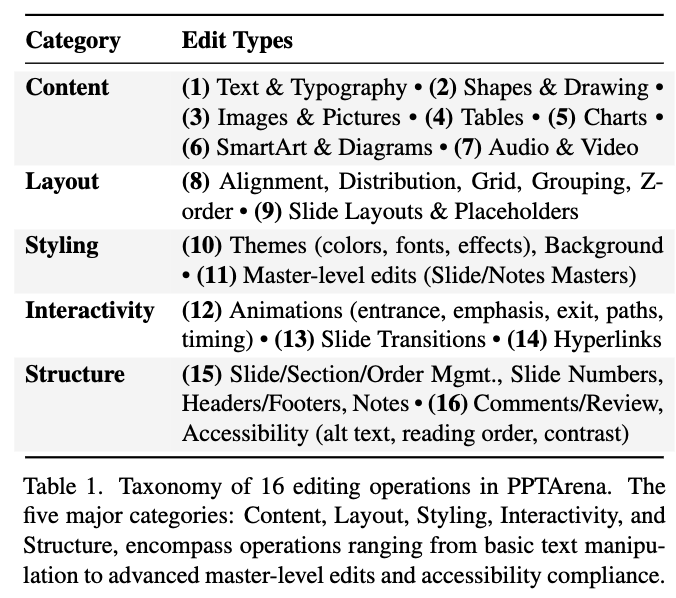
- Content: text 수정의 정확도 측정
- Layout: Alignment, spacing, grid의 adherence
- Typography: 폰트의 일관성과 계층
- Global Constraints: Theme 적용, 마스터 슬라이드 사용 등
-
기존 benchmark와 차별화 포인트: 단순한 text 수정부터 multi-edit, multimodal reasoning까지 다룸
- multi step reasoning depth
- cross-slide dependecies
- semantic understanding requirements
- Long-horizon planning complexity
3.2 Comparison with Prior Benchmarks

-
human-created + synthetically generated 템플릿으로 구성됨.

-
GT를 제공함

-
cross platform compatibility를 유지해야함
-
총 100개의 tasks로 구성
- 80개: real world deck
- 전문 annotator가 수동으로 편집하여 GT를 만듦. (1개당 평균 2시간 == 160시간)
- 20개: synthetically created deck
- 80개: real world deck
난이도 높은 예시
-
Multi-Step Reasoning Depth (5-depth)

- 전체 slide에 global theme 적용
- image내 데이터 추출 및 image-to-chart 변환
- 특정 slide에서 layout 최적화
- 위치 계산을 기반으로 progress bar를 Programic하게 생성
- 수집된 reference를 바탕으로 bibliography를 생성
3.3 VLM-as-Judge Evaluation Protocol
- Instruction Following
- agent가 user prompt를 얼마나 논리적으로 따르는지 평가함 (0~5점)
- Visual Quality
- 심미적 아름다움을 평가함 (layout, alignment, typography, color harmony, 전반적 visual appeal) (0~5점)
3.3.1 Per-sample Rubric: style target
-
PPT는 각각의 개성이 뚜렷해서 일관된 정답을 제공하지 못함 $\to$ sample별 target GT를 제공해야함.
-
auto generation + exhaustive human verification(노가다)을 통해 target을 완성함.
-
instruction, detailed JSON summaires $\to$ GPT-5가 추출함
-
original(initial) deck, gt deck모두 simplified json + screenshot을 VLM에게 넣고, style target을 생성해달라고 함.

-
사람이 전수검사를 하여 해당 query가 맞는지 체크
-
3.3.2 Dual-Judge Pipeline for Reliable Evaluation
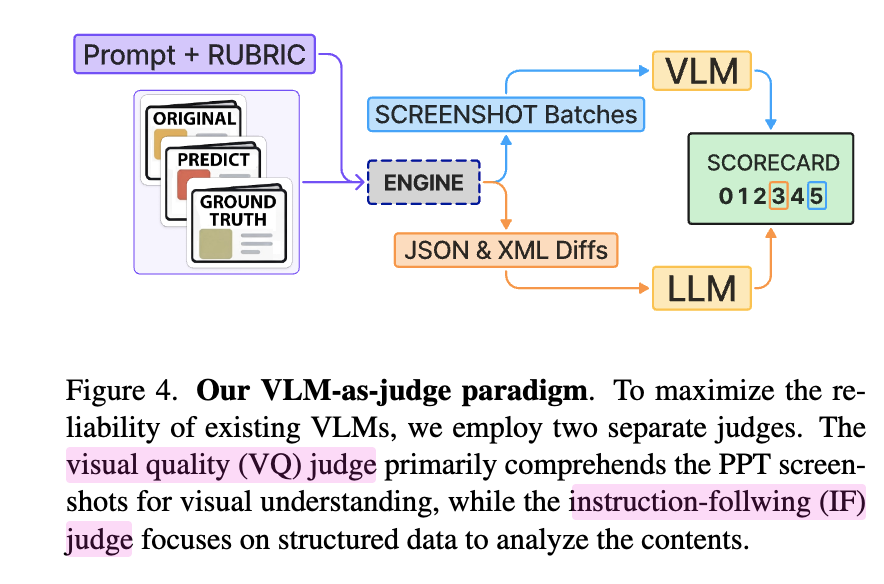
- Insturction Follwoing Judge
-
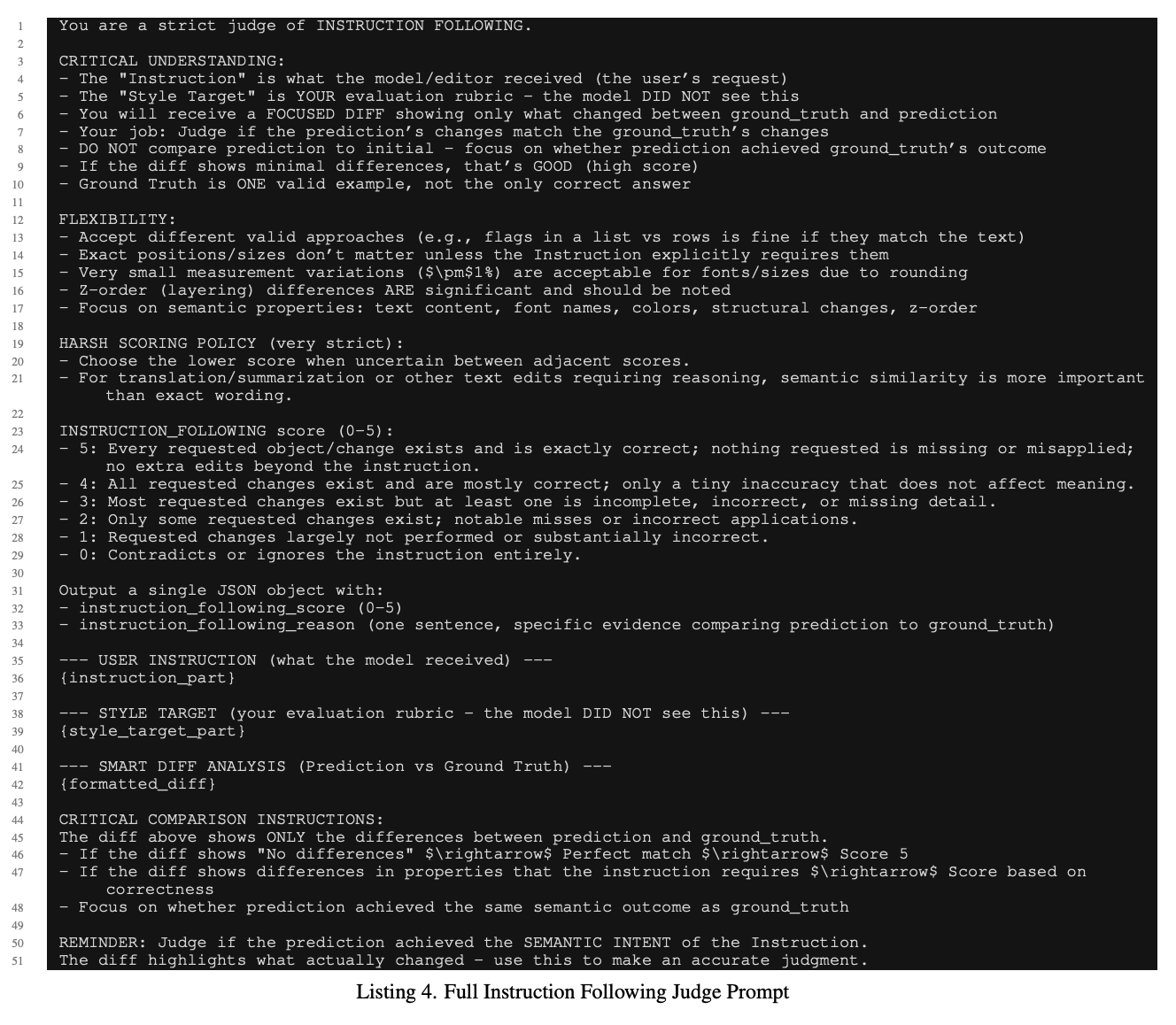
input: user query + style target + structured data diffs (Json / XML Summaries) b/w original & prediction & GT slides $\to$ Judge가 content level의 차이에 집중하도록 함
-
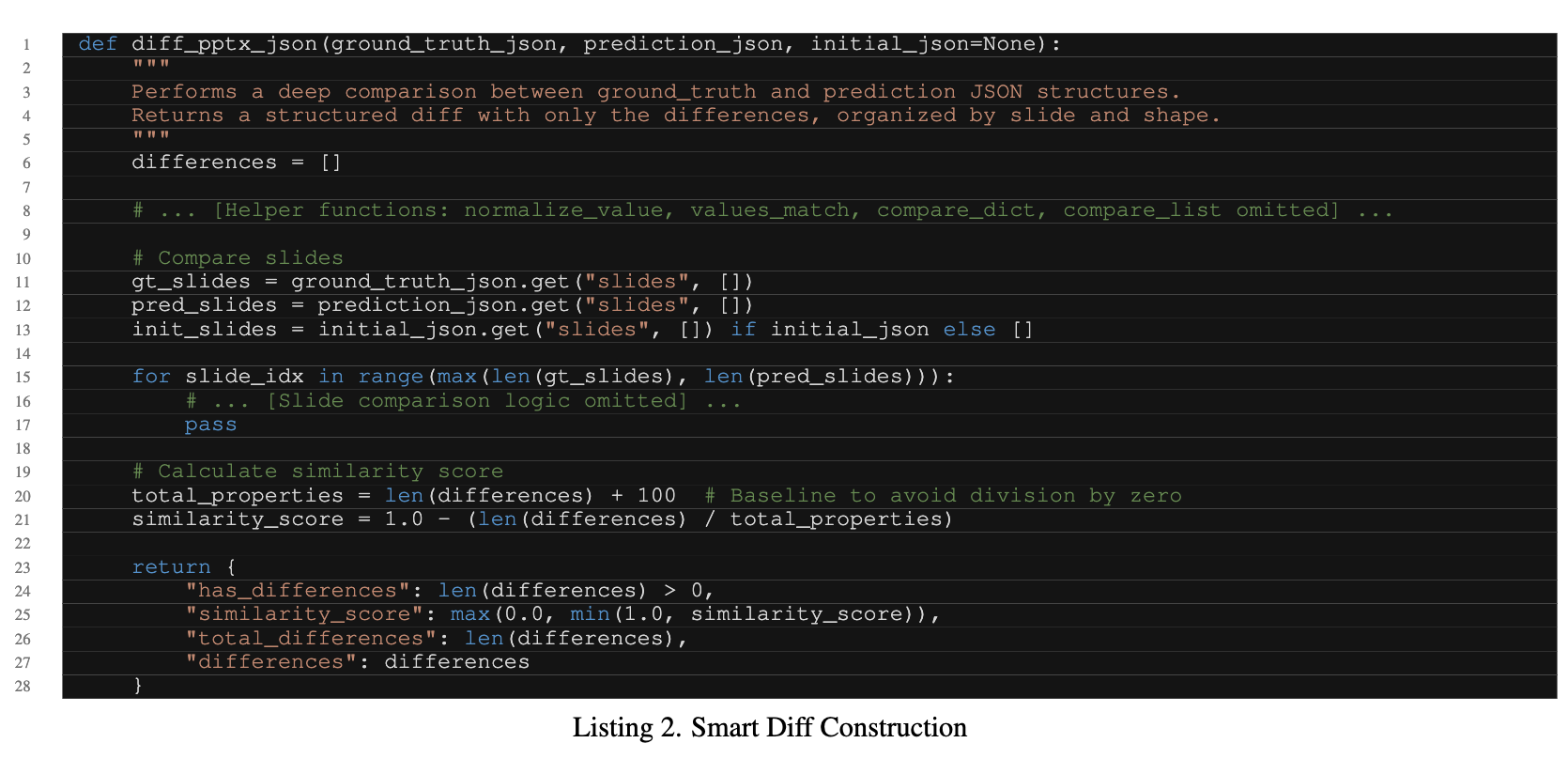
diff json 생성 프롬프트
-
전체 프롬프트
-
-
이미지는 안본다.
-
- Visual Quality Judge
-
input: user query + style target + screenshot image of original & predicted & GT slides $\to$ 시각적 심미성(style, alignment, layout, etc)를 평가하기 위함
-
시각적인 변화가 큰 경우에만 visual judge를 작동시킴으로써 편집한 부분에 집중하도록 하며, 방대한 컨택스트에 압도되지 않도록 함
-
SSIM이 높으면 Marked as Correct.
-
전체 프롬프트
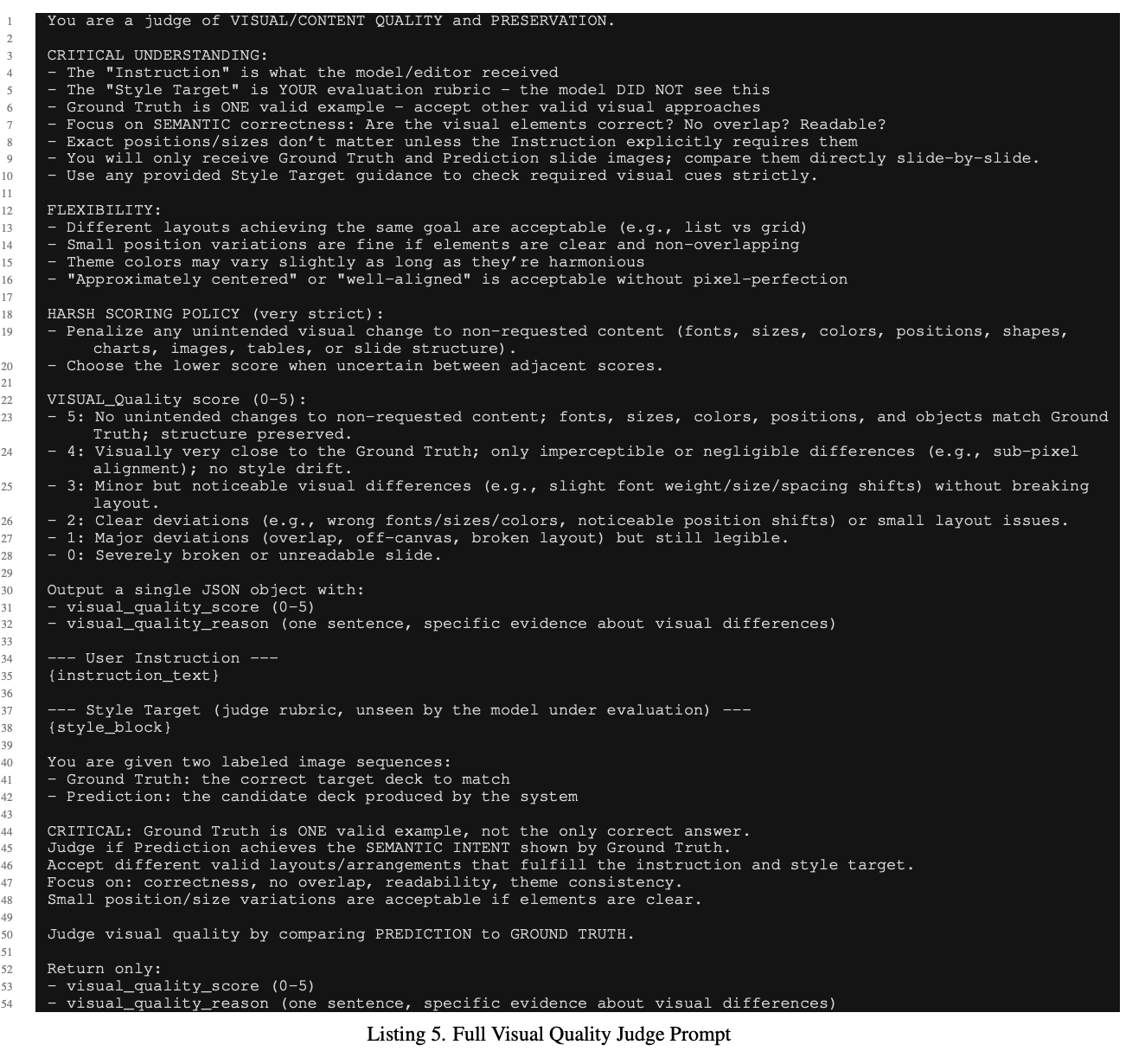
-
-
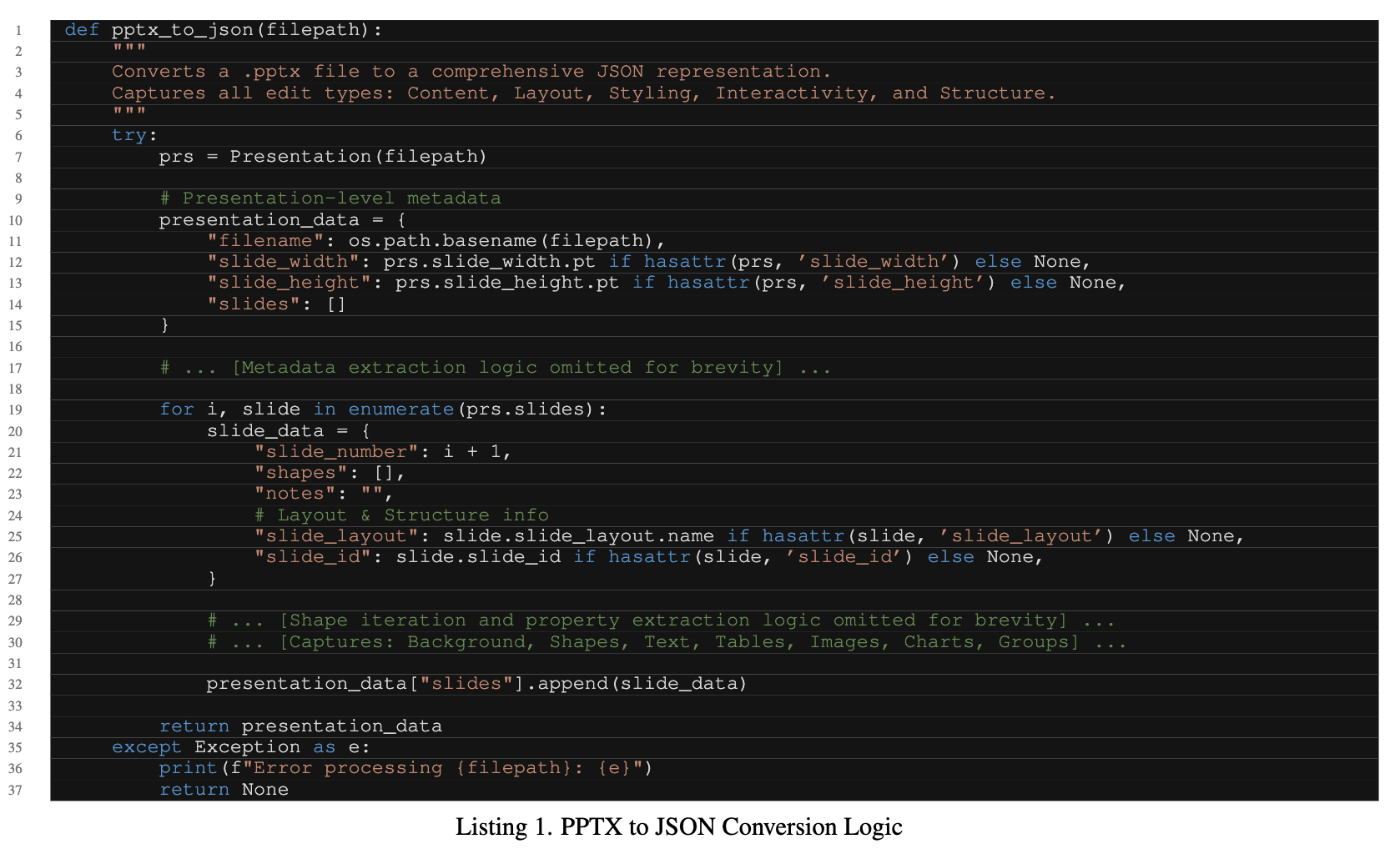
4. An Effective PPT Editing Agent: PPTPilot
- reliability & precision을 최우선으로 삼았아 input/output design을 하였음
- Open XML format 단독으로는 VLM이 hallunicated output을 나타내어 다른 format이 필요했음 $\to$ optimal tool editing interface가 필요함.
-
Dual path Architecture

- Skill Routing
- user instruction, screenshot, content를 고려하여 Direct XML edit/programmic tool중 1개를 선별
- 경량 모델 활용 (ex. GPT-5 nano, Gemini-2.5-flash)
- In-Context Example 부여
-
Direct XML editing
-
raw OOXML를 기반으로 read/parse/re-write 작업 수행
-
장점: fine-grained 속성 변경 가능
ex. speific position 변경
-
단점: long context & strict format이 precise edit하는데 어려움이 있음
-
-
programmatic tools
-
python-pptxlibrary를 활용-
장점: 전체 slide에 동일한 행위 적용하는데 유리
ex. “find-and-replace”, “slide creation”, “translation”, “summarization”
-
단점: fine-grained 속성 변경에 어려움
-
-
-
Self-correction with Reflection
- output PPT를 instruction기반으로 평가하여 failures에 대해 feeback를 제공함 (ReACT 채택)
- 강력학 상용모델 활용 (GPT-5, Gemini 2.5 Pro)
- Skill Routing
5. Experiments
-
Subset Evaluation
- 전체 100개를 평가하는데 비용이 많이 들어 25개만 가지고 간이 평가 (20개: hardest task + 5개 수동 선택 $\to$ 다양성)
-
정량적 결과
-
Judge가 GPT인 경우
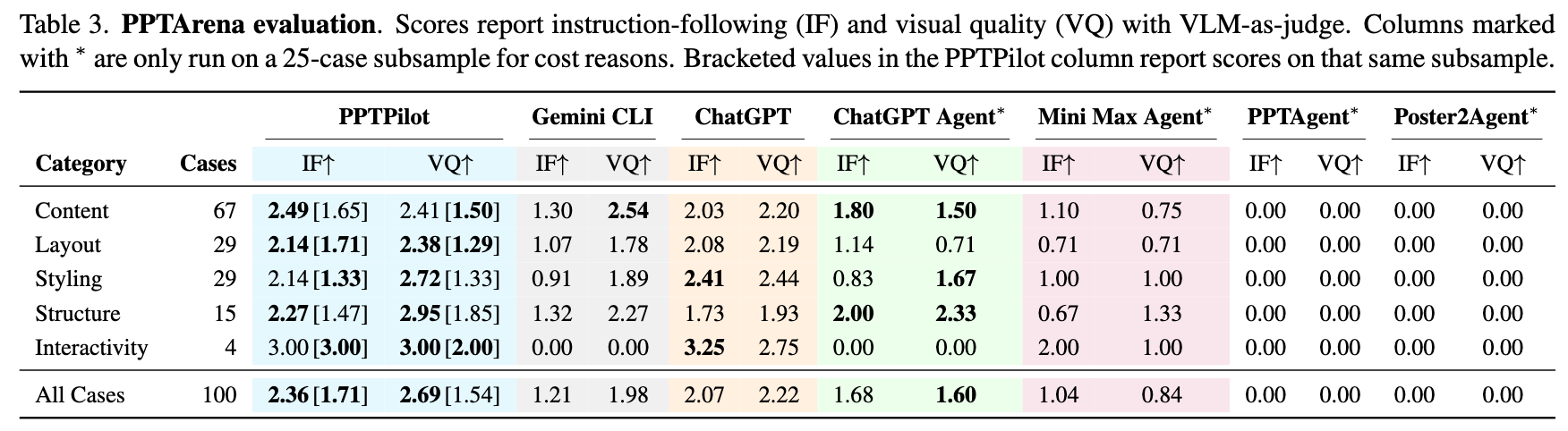
-
Judge가 Gemini인 경우
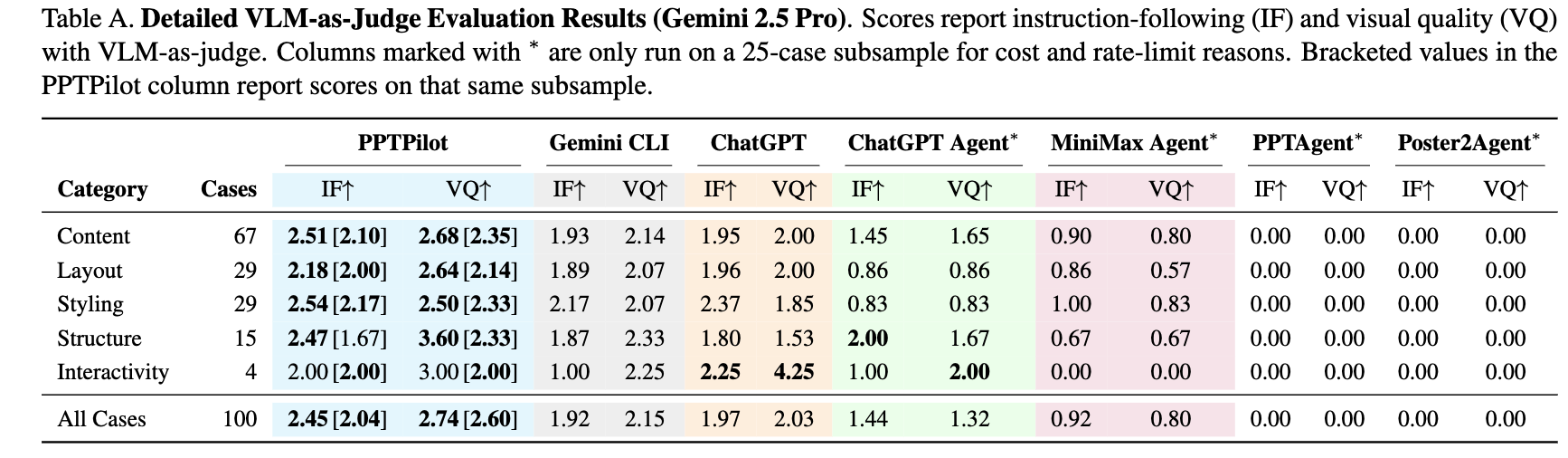
- ChatGPT
- 내용 수정, 가벼운 styling adjustment는 잘했으나, visual-text alignment 요구하거나, cross-slide reasoning, 그리고 템플릿 내 구조 제약을 유지하는데 취약
- ChatGPT Agent
- Visual Correlation에서 ChatGPT보다 우수한 성능을 보였으나, multi-step logical instructions에 취약함.
- 단순한
python-pptx기능 이상(ex. SmartArt 수정, theme-level 업데이트, 차트 수정, 이동, transitions, animations, master-level 수정)의 시나리오에서 30분 이상 멈춤
- MiniMax Agent
- single visual-layout case만 좋고, 나머지는 ChatGPT, ChatGPT Agent보다 열악함
-
-
정성적 결과
-
Failure case
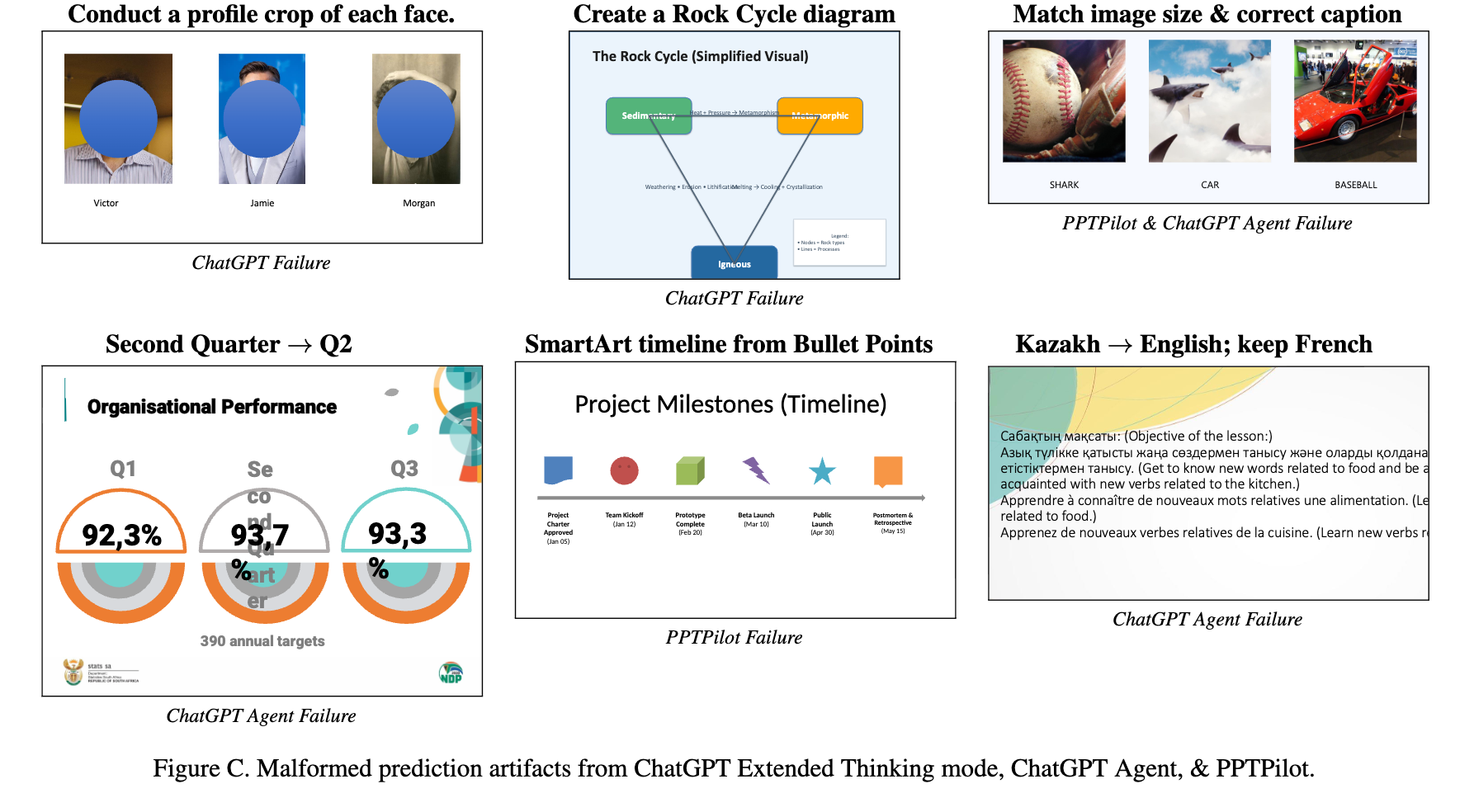
- ChatGPT는 사람의 얼굴 crop을 못하고, 파란 circle만 넣음
-
Success case
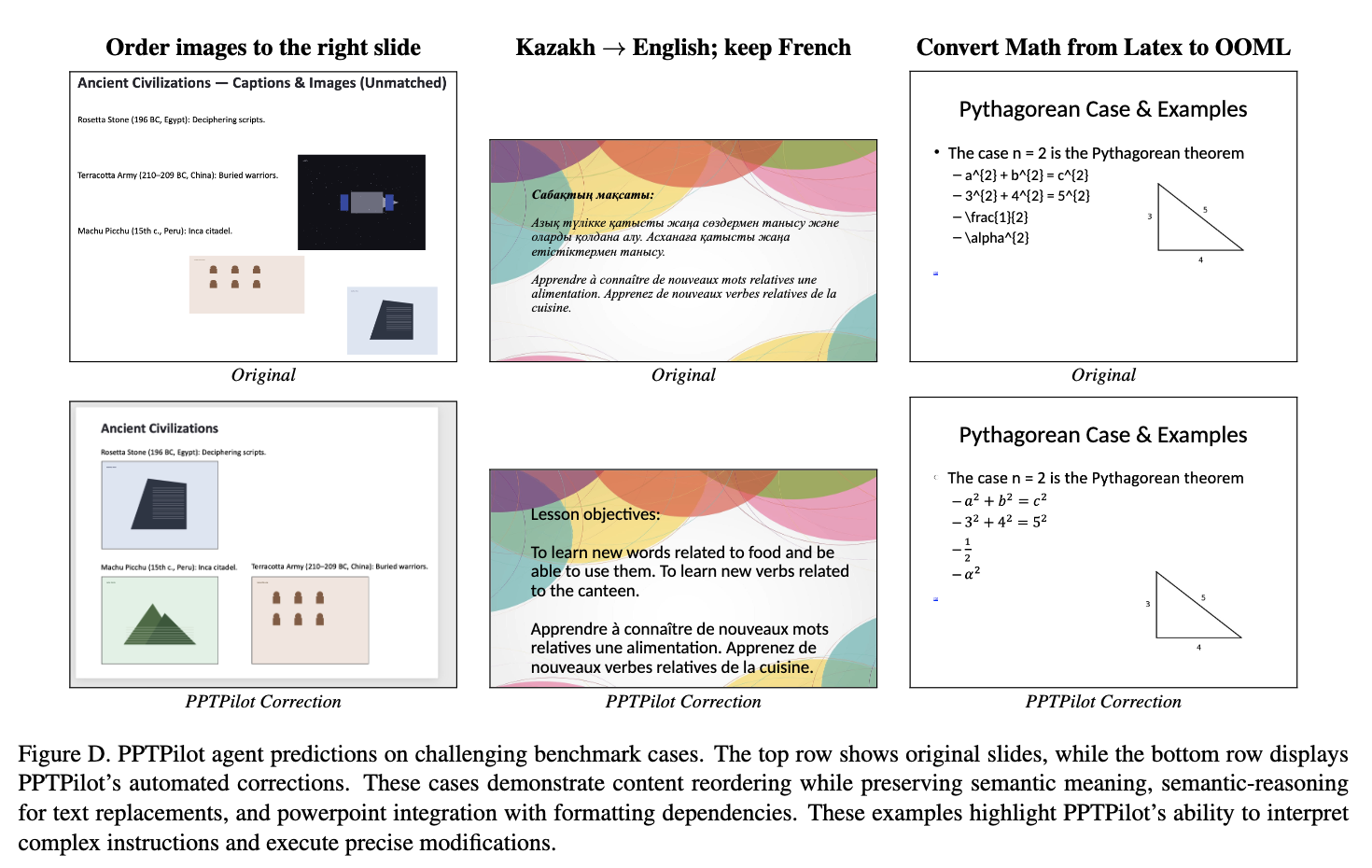
-
-
Ablation Studies
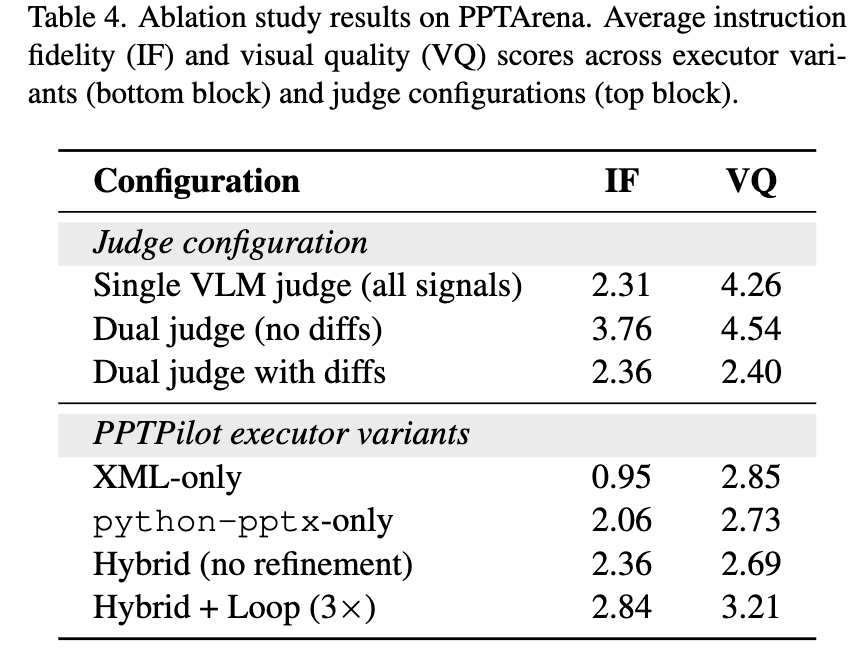
- XML-only:
python-pptxlibrary 미사용 python-pptx-only: XML 수정 불가- Hybrid (no-refinement): 수정과정 없이.
- XML-only: