[OD][Omni] Omni-DETR: Omni-Supervised Object Detection with Transformers
-
Omni-DETR: Omni-Supervised Object Detection with Transformers
- paper: https://arxiv.org/pdf/2203.16089.pdf
- git: https://github.com/amazon-science/omni-detr
- CVPR 2022 accepted, (인용수: 36회, ‘23.12.05 기준)
- downstream task : Omni-OD
Contribution
-
Fully-labeled, unlabeled, weakly-labeled data를 모두 활용 가능한 Omni-Detection framework를 최신 Transformer기반으로 제안함
- Deformable DETR를 사용한 이유:
-
Heuristic한 요소가 없으므로 universal format 수용하는데 좋음
-
Bipartite matching problem으로 문제 정의 가능
-
- Deformable DETR를 사용한 이유:
-
Bipartite matching 기반의 새로운 pseudo label filtering 전략을 제안함
-
다양한 SSOD dataset에서 annotation-accuracy trade-off에서 SOTA를 찍음
-
annotation 의 경우 dataset마다 cost가 다르다

-
Omni-DETR
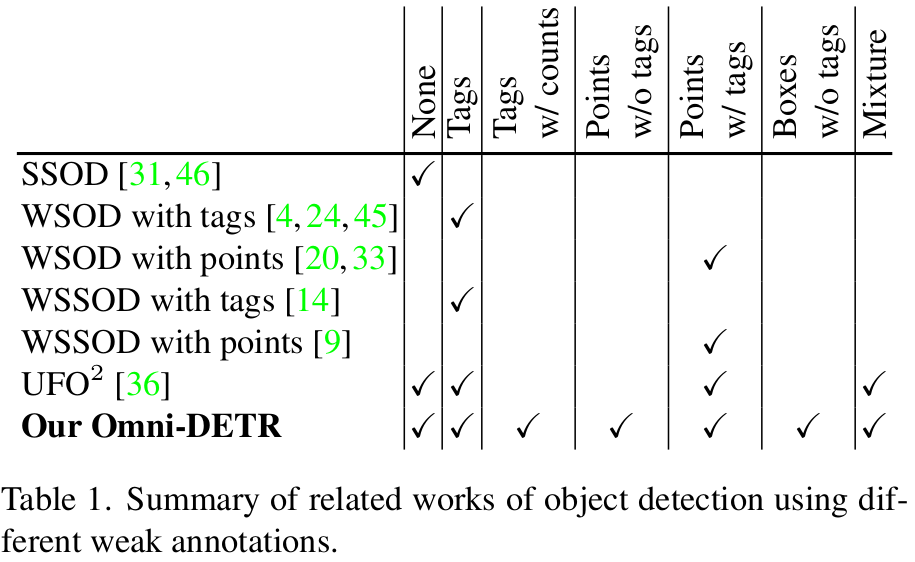
1. Omni-Labels
-
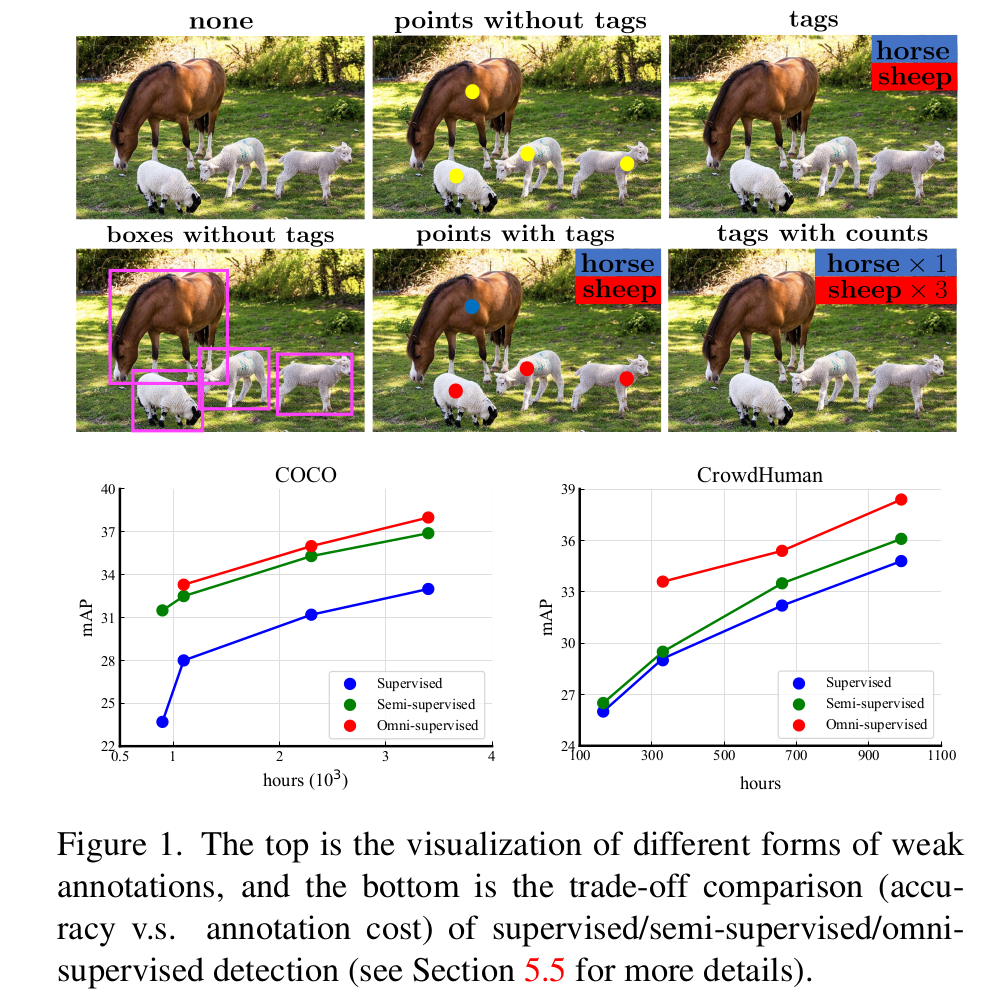
None
- unlabeled image
-
Tags(TagsU)
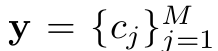
- $M$: 태그의 갯수
- ex. M=2, horse, sheep
- $M$: 태그의 갯수
-
Tags with Counts (TagsK)
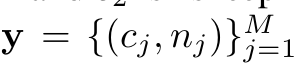
- $n_j$: class $c_j$의 instance 갯수
- $M$: 태그의 갯수
-
Points without Tags (PointsU)
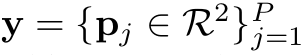
- $P$: Point의 갯수
-
Points with Tags (PointsK)
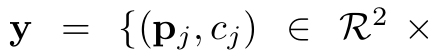
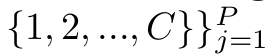
- $P$: Point의 갯수
- ex. P=3 for sheep, P=1 for horse
-
Boxes without tags (BoxesU)
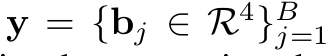
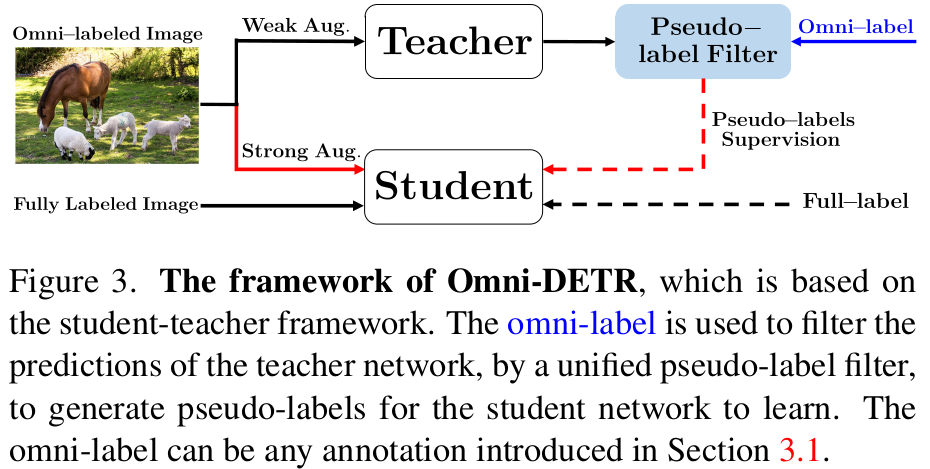
Unified Framework
-
Overall Diagram
-
Student’s Overall Loss
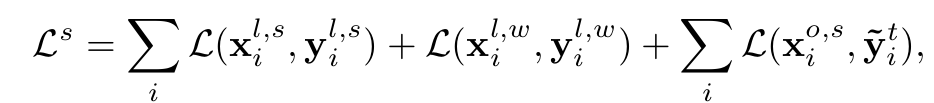
-
$\bar{y}_i^t$: pseudo label filter를 통과한 tacher의 pseudo label
-
$x^{o,s}_i$: omni-label strong augmented i번째 이미지
-
Loss
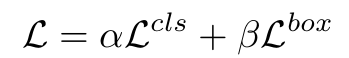
- box regression loss + classification loss
-
EMA teacher
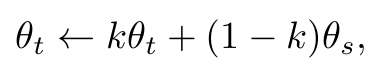
-
Unifired Psuedo-Label Filtering
-
$\bar{y}=T({\hat{y}, y^o})$
- $\bar{y}$: pseudo label filter 통과한 pseudo label
- $T$: pseudo label filter
- $\hat{y}$: teacher의 prediciton output
- $y^o$: omni-label
-
No Annotation
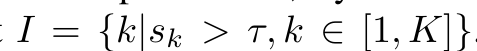
- $s_k$: teacher의 예측한 score 중 제일 높은 score
- $\tau$: fixed threshold
-
Weak Annotation
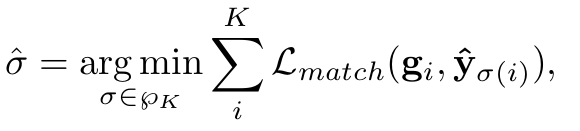
-
$g_i$: Omni-label $\in G$
-
$K$: teacher prediction의 갯수 ($G<K$)
-
Match Loss
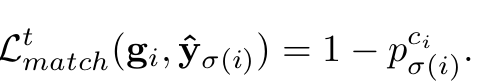
-
TagsU
- Image-level Tag만 알고, instance 갯수는 모르므로 prediction을 수행
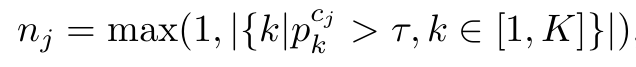
- 최소 1보다 큰 것은 tag GT가 있기 때문
-
TagsK
- instance 갯수는 알고 있으므로, 위 match Loss를 바로 계산에 활용함
-
PointsU
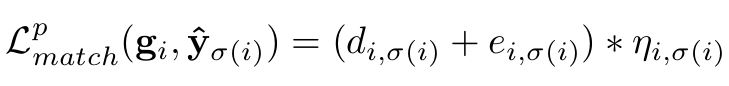
- $d_{i,\sigma(i)}$: L2 distance between omni-GT & predicted center point
- $e_{i,\sigma(i)}$: $1-s_{\sigma_i}$
- $s_{\sigma_i}$: $\sigma_i$번째 box의 prediction score
- $\eta_{i,\sigma_i}$: i번째 gt가 predicted box 안에 있으면 1, 아니면 +무한대
-
PointsK
-
PointsU와 TagsU의 Loss의 선형조합
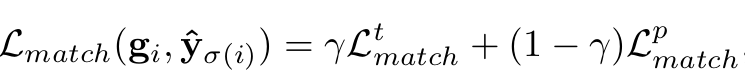
-
-
Boxes
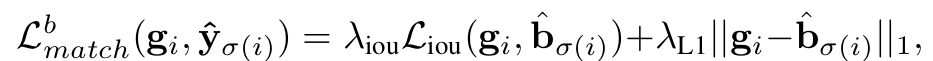
- Regression Loss만 활용
Experiment
- Dataset
- mscoco-1%,5%..
- 1%,5%만 fully annotated
- 나머진 omni-label
- mscoco-1%,5%..
-
-
mscoco-10% omni-label에 따른 성능 비교
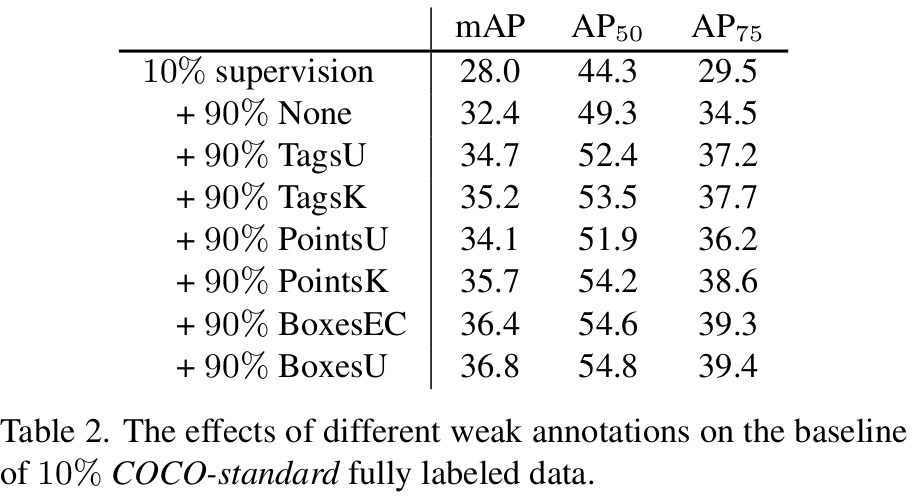
-
Omni-OD vs. 기존 SOTA SSOD
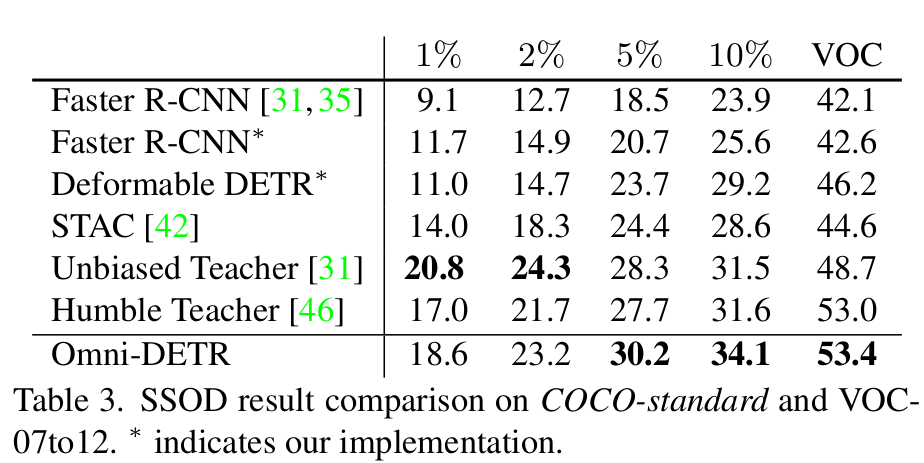
-
Omni-DETR vs. 기존 SOTA WSSOD

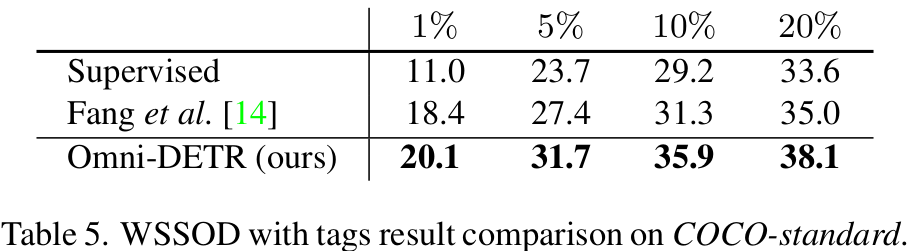
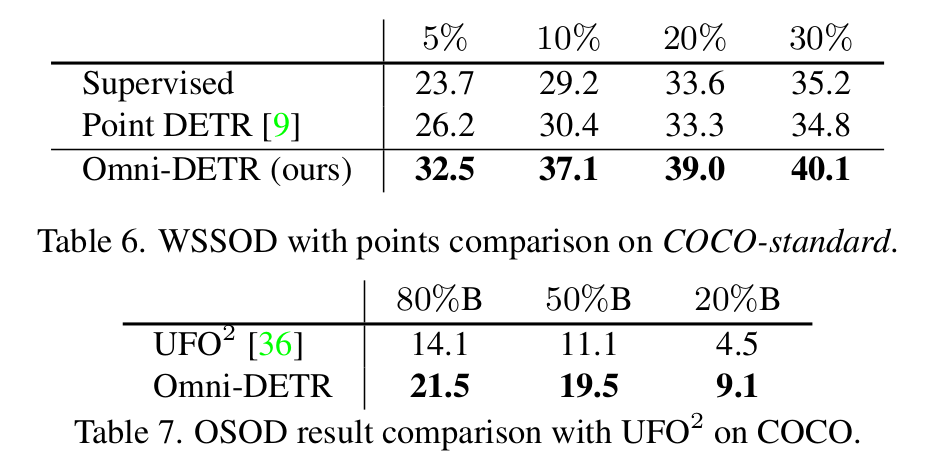
-
Ablation Study
-
Pseudo-label Filter vs. Simple Heuristic Filter

-
$\tau$, $\gamma$에 따른 성능 비교
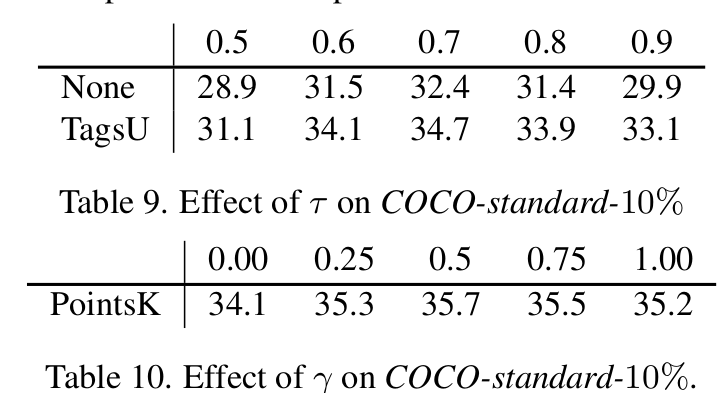
-
-
Accuracy & label-cost Trade-off
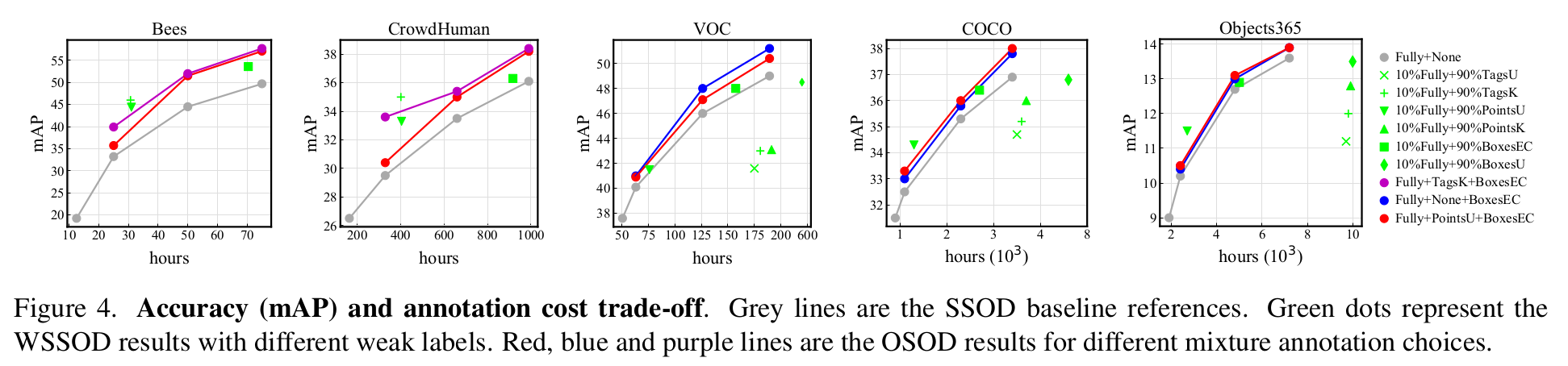
-
Label cost 기준
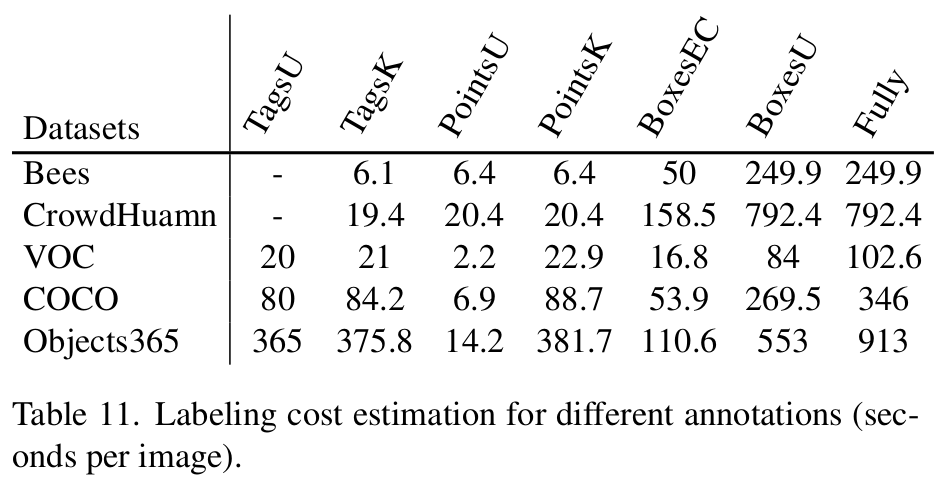
-