[Agent] Mind2Web: Towards a Generalist Agent for the Web
[Agent] Mind2Web: Towards a Generalist Agent for the Web
- paper: https://arxiv.org/pdf/2306.06070
- github: https://github.com/OSU-NLP-Group/Mind2Web
- NeurIPS 2023 spotlight (인용수: 593회, 25-08-16 기준)
- downstream task: General Web Tasks
1. Motivation
-
임의의 website가 주어지면, 자연어 명령을 수행하는 general agent를 만들고 싶음
-
하지만 최신 websites는 다양한 기능들을 지원함으로써 복잡하고, learning curve가 높음
-
최근 연구들은 real-world website에 비해 너무 단순한 환경에서 테스트함으로써 general agent로서 부족함
$\to$ 복잡한 real-world website를 실제로 활용하여 다양한 도메인, 다양한 테스크 데이터셋을 제공해보자!
2. Contribution
-
2K task / 137 websites / 31 도메인에서 추출한 MIND2WEB dataset을 공개함
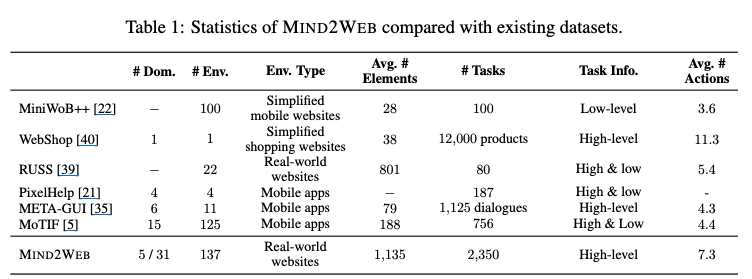
- 과거연구(simulated)와 달리 실제 website를 기반으로 데이터셋을 구축함
- 넓은 spectrum의 user interaction pattern을 포함하고 있음
-
HTML을 filtering하는 small LM $\to$ multi-choice QA task로보고, LLM이 action을 선택하는 2stage 방법을 제안
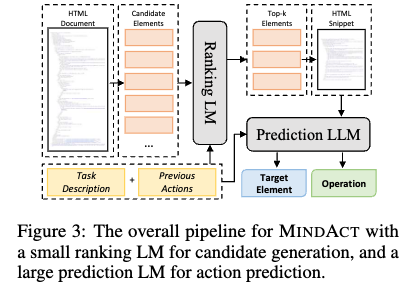
3. Mind2Web + MINDACT
3.1 Mind2Web
-
Task 정의
- Task Description: high-level goal of the task를 AMT를 통해 사람에게 만들도록 시킴
- Action sequence: 사람에게
(Target Element, Operation)pair를 라벨링하도록 시킴 - Webpage snapshot: raw HTML, DOM snapshot, rednered webpage의 screenshot, HAR file (network traffic)을 logging함
-
Data Collection
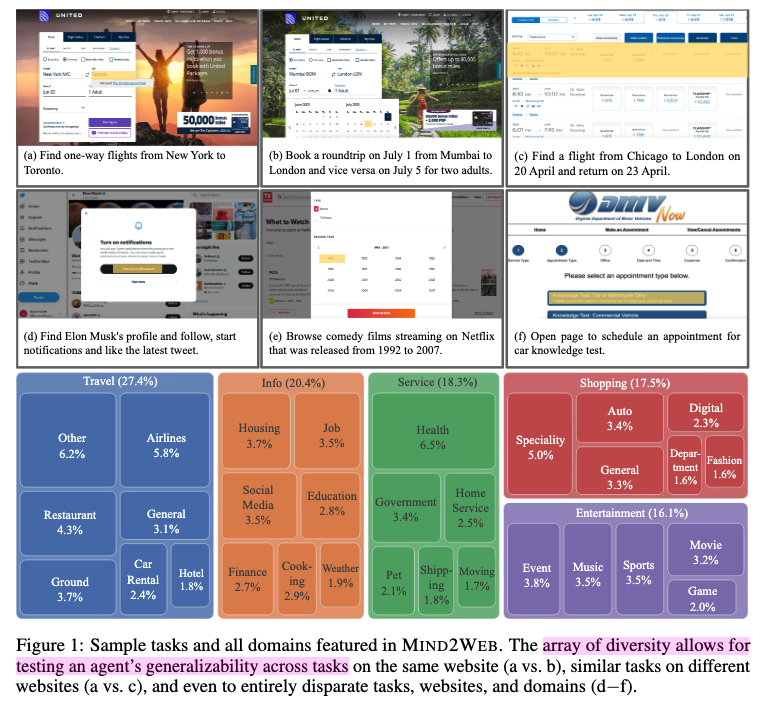
-
Playwright기반으로 annotation tool을 만듦
-
4단계로 이루어짐
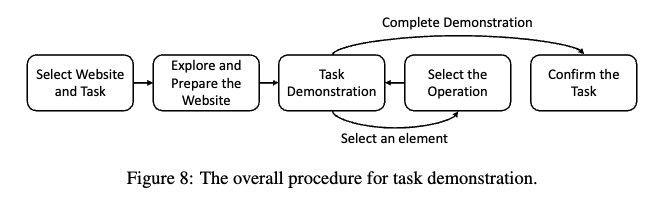
Website Selection $\to$ Task Proposal $\to$ Task Demonstration $\to$ Task Verification
$\to$ 1/4단계는 저자가, 2/3단계를 anntator가 수행
-
Website Selection
- US에서 인기 있는 사이트를 lanking하는 similarweb.com을 참고해서 websites를 선택
- 5개의 top-level domain + 31개의 domain으로 나눔 $\to$ 137개의 website를 선택
-
Task Proposal
- open-ended & realistic tasks를 만들도록 annotator들을 교육시킴
- step-by-step instruction보다는 high-level goal을 묘사하도록 교육시킴
- ChatGPT에게 website별 50개의 예시를 만들어 참고하도록 제공
- 너무 예시와 유사하면 reject함
-
Task Demonstration
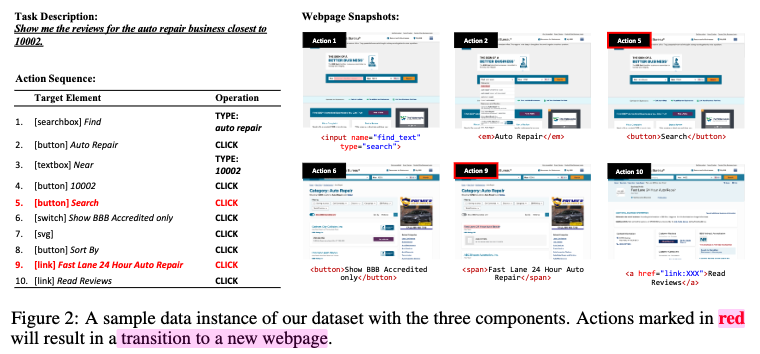
- Human annotator가 annotation tool을 활용해 element selection + operation selection
-
Task Verification
-
저자들이 검증을 수행
$\to$ 총 2,350 task가 취득됨
-
-
-
3.2 MINDACT
-
Raw HTML은 LLM입력으로 들어가기 너무 큼 $\to$ 비현실적인 비용
-
추론시
- small LM이 task에 적합한 top-5를 고르고, LLM이 그중 1개를 선택하도록 함
- LLM은 top-k개를 선택하여 iteration을 거쳐 최종 top-1이 나올때까지 반복 수행함.
-
학습시
-
small LM(DeBERTa)은 positive (target element)를 negative (random selected)로부터 예측하도록 훈련
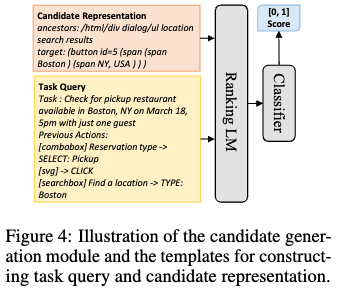
-
element는 DOM형식으로 textual representation이 표현되며, 3가지를 가지고 있음
- element tag
- textual content
- salient attribute value
-
LLM은 top-k 후보 중, 각 후보별 이웃하는 element를 prune해서 5지선다를 풀도록 학습됨
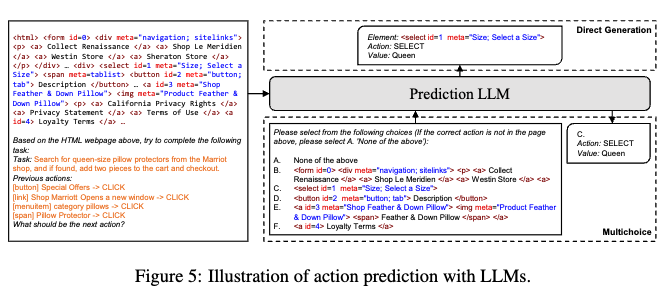
-
4. Experiments
-
Experimental Setup
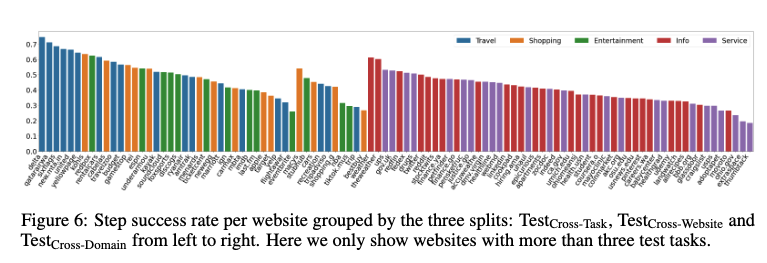
- Cross-Domain: Information / Service분야를 선택함. Web Agent 모델이 처음보는 domain의 task를 얼마나 general하게 잘 수행하는지 판단
- Cross-Website: top-level domain별 10개의 website를 선택. (177 tasks) similar task가 존재할수 있으나, 처음 보는 website에서 얼마나 general하게 잘 수행하는지 판단
- Cross-Task: random split 20%를 선택. 학습시 본 website일수 있으나, 처음 본 Task를 얼마나 잘 수행하는지 판단
-
Evaluation Metric
- Element Accuracy: target element만 잘 고르면 정답
- Operation F1: step별로 predicted operation의 token-level F1score
- Step Success Rate: step-level Element + predicted operation 모두 정답이어야 함
- Success Rate: 전체 trajectory에서 level Element + predicted operation 모두 정답이어야 함
-
정량적 결과
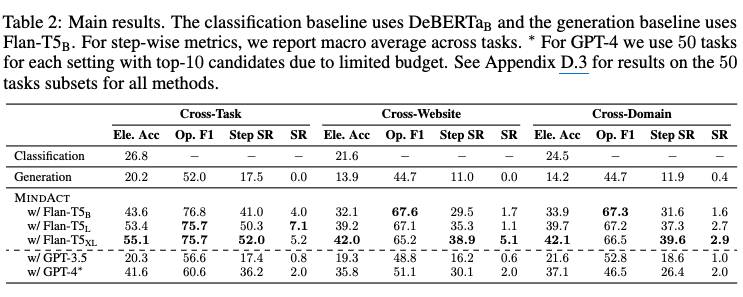
-
Cross-Task > Cross-Website, Cross-Domain $\to$ 처음 보는 website / domain에서 취약함. 발전가능성 높음
-
GPT는 3-shot in-context learning 결과임
-