[UDA][OD][SSG] MIC: Masked Image Consistency
[UDA][OD][SSG] MIC: Masked Image Consistency
- paper link : https://arxiv.org/pdf/2212.01322.pdf
- github : https://github.com/lhoyer/MIC
- paperswithcode UDA task 1등
- Masked Image Consistency for Context-Enhanced Domain Adaptation
Abstract
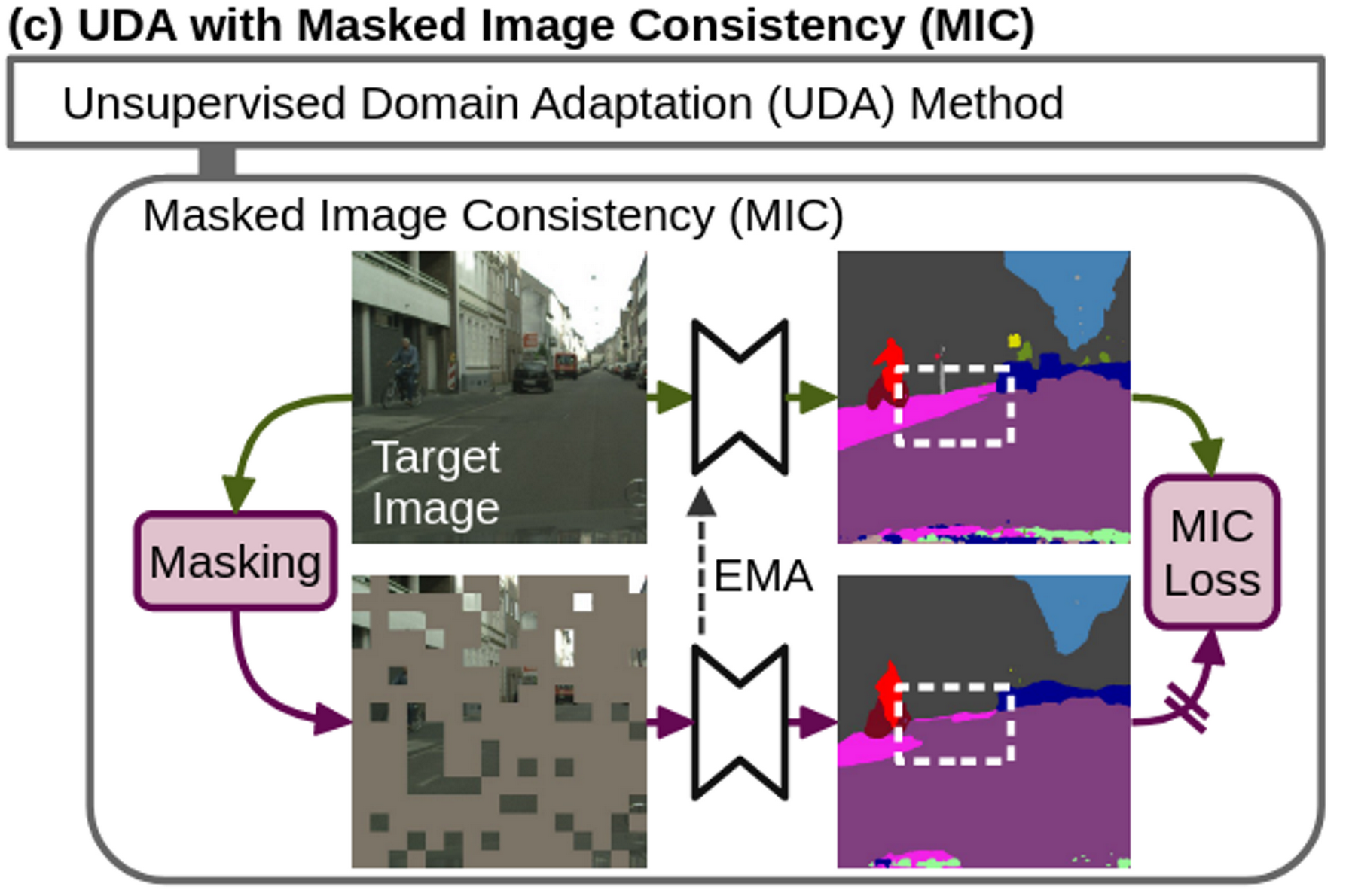
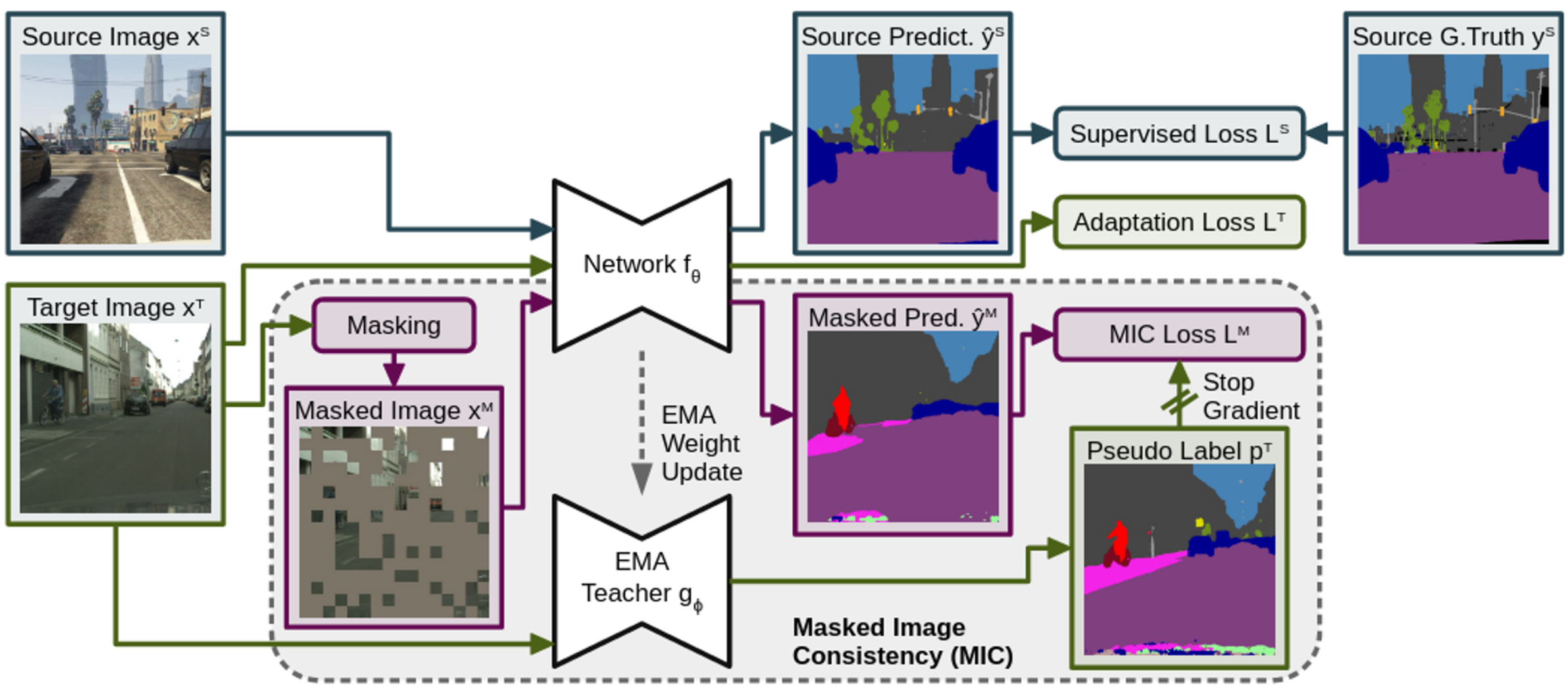
- Masked된 이미지와 Original 이미지의 prediction간에 일관되게 학습함으로써 “공간 상의 상호 관계 (spatial context relations)”를 추가로 학습하게 함
- Masked된 이미지 → Student의 prediction
- Original 이미지 → Student의 EMA로 업데이트된 Teacher의 prediction
- 즉, masked된 pixel영역에 대해 예측을 강제로 수행하게 함으로써 주변의 내용을 보고 유추하는 능력을 키워주게 함
- 단순한 컨셉 덕분에 OD, Seg, Cls task모두 적용 가능 → SOTA UDA를 찍음
- WildFire data 적용 예시 mask ratio = 50%, patch size = 32x32 or 16x16

1. Introduction
-
기존 UDA Task의 문제점 : Target domain은 레이블이 없으므로, 유사한 시각적 형태 (Similar Visual Appearnce)를 띄는 물체들 간의 구별을 가능케 하는 supervisory signal이 존재하지 않는다.
-
ex. road/sidewalk or pedestrian/rider

-
ex. IR 조명/화재

-
-
새로운 UDA module “Maksed Image Consistency (MIC)” 제안
-
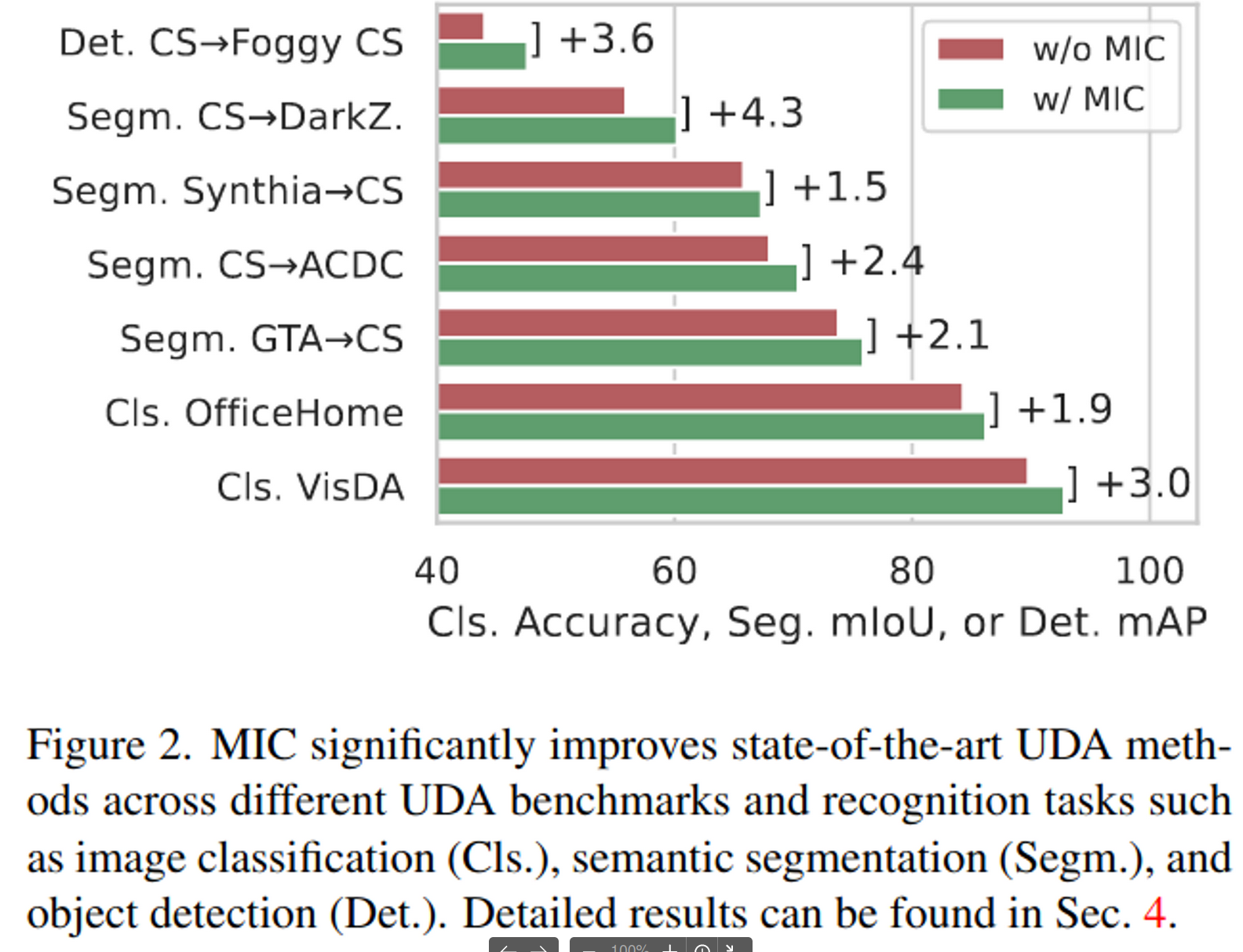
다만, 다른 UDA module에 plug-in이 용이하며, 함께 사용하여 UDA에서 SOTA 성능을 달성함
2. Related Work
2.1 UDA (Unsupervised Domain Adaptation)
- 참고: https://alcherainc.atlassian.net/wiki/spaces/RI/pages/1777303701/17.+Learning+Domain+Adaptive+Object+Detection+with+Probabilistic+Teacher+-+23.01.10
2.2 Masked Image Modeling
-
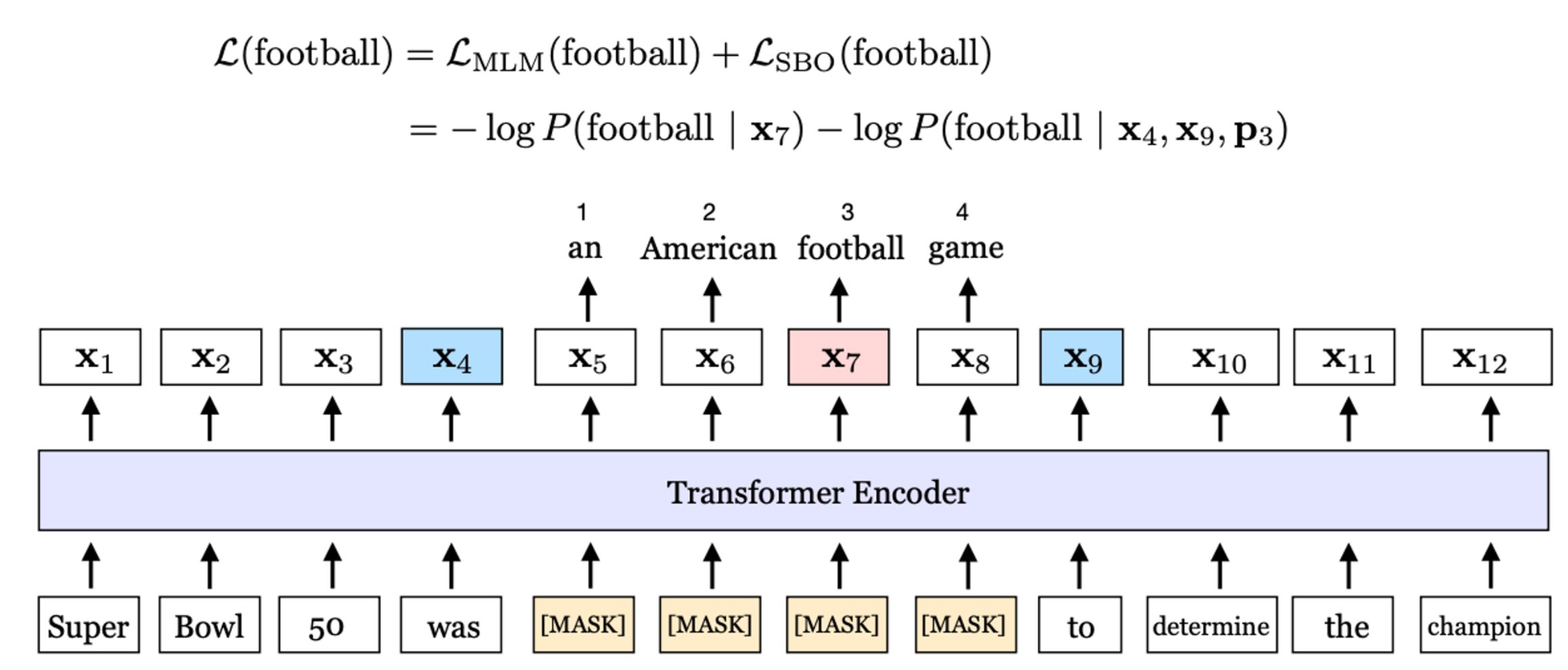
Masked token을 예측하는 task는 NLP에서 유례함. (Masked Language Model Loss)
-
최근 CV 분야 방식들은 Image domain을 복원하는 task를 수행한다고 함.
-
MIC는 예측하는 domain (ex. segmentation, object detection)을 consistent하게 나타내도록 수행하므로 차별성이 있다고함.
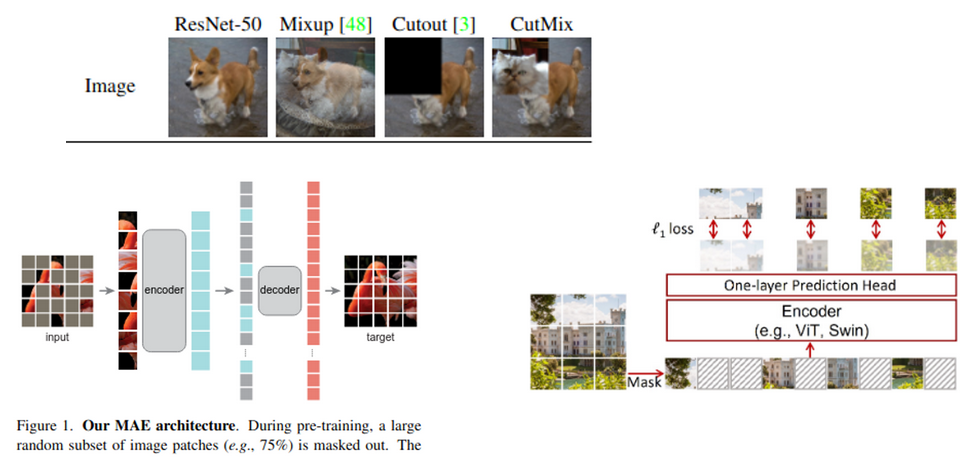
- Cutout등 augmentation기법으로 masking을 수행하여 성능향상을 이미 꾀하고 있는 방식들과 유사함
3. Methods
3.1 UDA
-
supervised loss
-
classification, segmentation : Cross Entropy Loss
-
Object detection : Cross Entropy Loss (Classification head), L1 or L2 loss (Regression head)
\[L^{S, cls/reg}*{k}= H(f*{\theta}(x^S_k), y^S_k) \\ H(\hat{y},y)=-\sum^H_{i=1}\sum^W_{j=1}\sum^C_{c=1}y_{ijc}log\hat{y}_{ijc}\]- H=W=1 for classifcation
-
-
Total loss
-
unsupervised loss : self-training loss or adversarial training loss or entrophy minimization loss
\[H(\hat{y},y)=min_{\theta}\frac{1}{N_S}\sum_{k=1}^{N_S}L^{S}*{k}+ \frac{1}{N_T}\sum*{k=1}^{N_T}\lambda L^{T}_{k}\]- $N_S$: Source Image 갯수
- $N_T$: Target Image 갯수
-
3.2 MIC (Masked Image Consistency)
-
Random uniform sampling 으로 mask image 생성
\[M_{mb+1:b(m+1), nb+1:b(n+1)}=[v>r] \\ x^M=M \odot x^T \\ \hat{y}^M=f_{\theta}(x^M) \\ L^M = q^TH(\hat{y}^M, p^T)\]- b : patch size
- m, n : patch indices $m \in [0,W/b-1], n \in [0,H/b-1]$
- r : mask ratio
- *v :* uniform random number ~U[0,1]
- $x^M$: masked image
- $f_{\theta}$: student network
- $\hat{y}^M$: student prediction
- $q^T$: quality weight
- $p^T$: teacher prediction
- $L^M$: MIC loss
-
Pseudo label
-
classification / semantic segmentation
\[p^{T}*{ij}=[c=argmax*{\acute{c}}g_{\phi}(x^T)_{ij\acute{c}}]\]- $g_{\phi}$: teacher network
- x: original image
-
object detection
- threshold $\delta$ 로 filtering 후, NMS
- 즉, threshold를 넘는 pseudo bbox가 없으면 그 image는 학습에 사용하지 않음
-
-
Quality weight ($q^T$)
-
classification / object detection : softmax probability 값을 사용
\[q^T=max_{\acute{c}}g_{\phi}(x^T)_{\acute{c}}\] -
semantic segmentation : threshold ($\tau$)를 넘는 pixel 값들의 비율을 사용
\[q^T=\frac{\sum_{i=1}^H\sum_{j=1}^W[max_{\acute{c}}g_{\phi}(x^T)_{ij\acute{c}}>\tau]}{HW}\]
-
-
Total loss
- unsupervised loss : self-training loss or adversarial training loss or entropy minimization loss + MIC loss
4. Experiments
4.1. Implementation Details
-
Baselines
-
Semantic segmentation
-
Dataset :
- synthetic-to-real : GTA(25K)+Synthia(9.4K) → Cityscapes(2.9K+500)
- clear-to-adverse-weather : Cityscapes(2.9K+500)→ DarkZurich (2.4K+150)
- day-to-nighttime (street scenes) : Cityscapes (2.9K+500)→ ACDC (3.64K)
-
Model :
-
DAFormer w/ MiT-B5 encoder
-
DeepLabV2 w/ ResNet101
-
Image-net pretrained weight 사용
-
self-training은 HRDA논문에서 사용한 기법들 사용 (training resolution, data augmentation, parameters, optimizer, ema rate, etc)
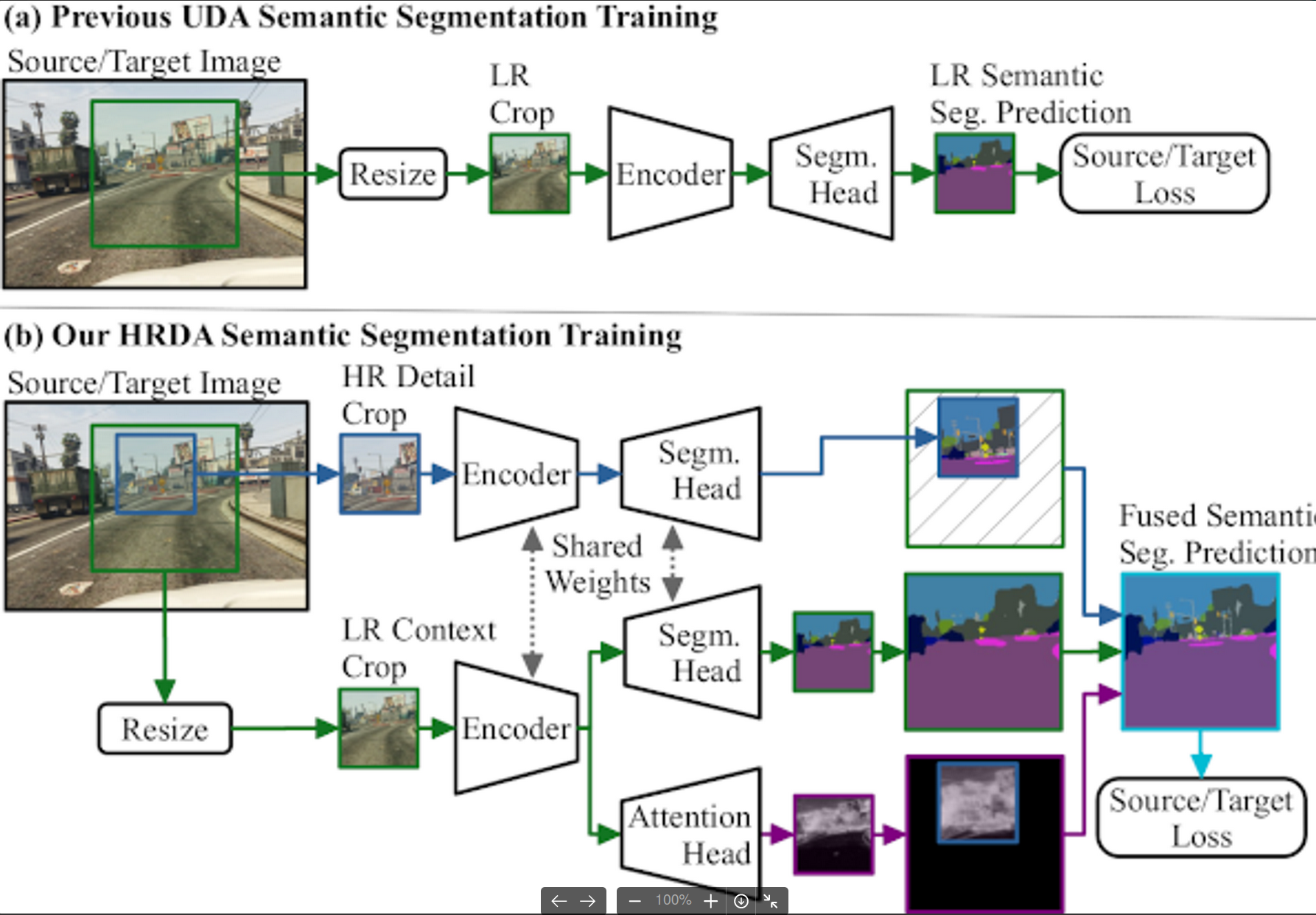
-
-
-
Image classification
-
Dataset :
- VisDA 2017 (280K synthetic images with 12 classes)

-
OfficeHome dataset (15.5K with 65 classes) : Art, Clipart, product, real world

-
Model
-
ResNet101
-
ViT-B/16
-
SDAT논문에서 사용한 기법들 사용
-
-
-
Object Detection
-
Datasets : Cityscapes to FoggyCityscapes
-
Model :
- Faster-RCNN with Res50
- SADA 논문 기반으로 진행
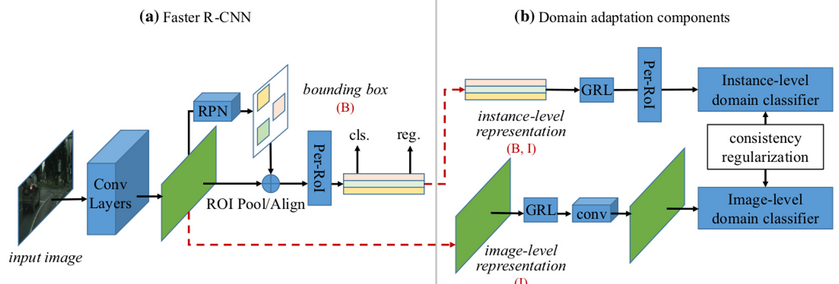
-
-
-
MIC parameters
- b : 64 patch size
- r : 0.7(0.5 for od) mask ratio
- $\lambda^M$: 1 loss weight
- $\alpha$: 0.999 (0.9 for od and cls) ema parameter
- $\lambda$: 0.8 box threshold
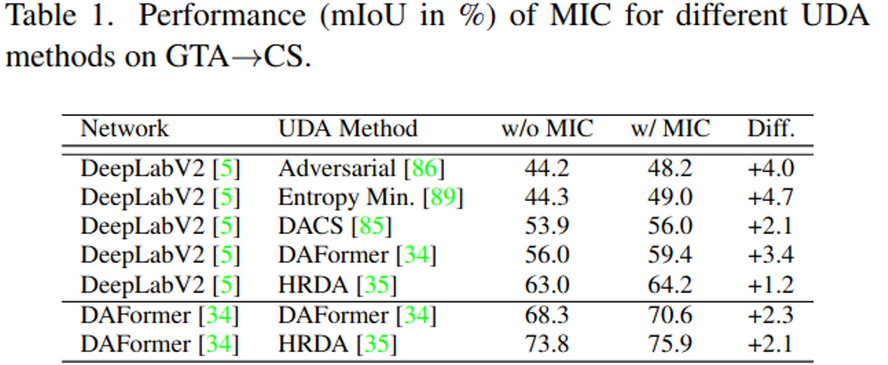
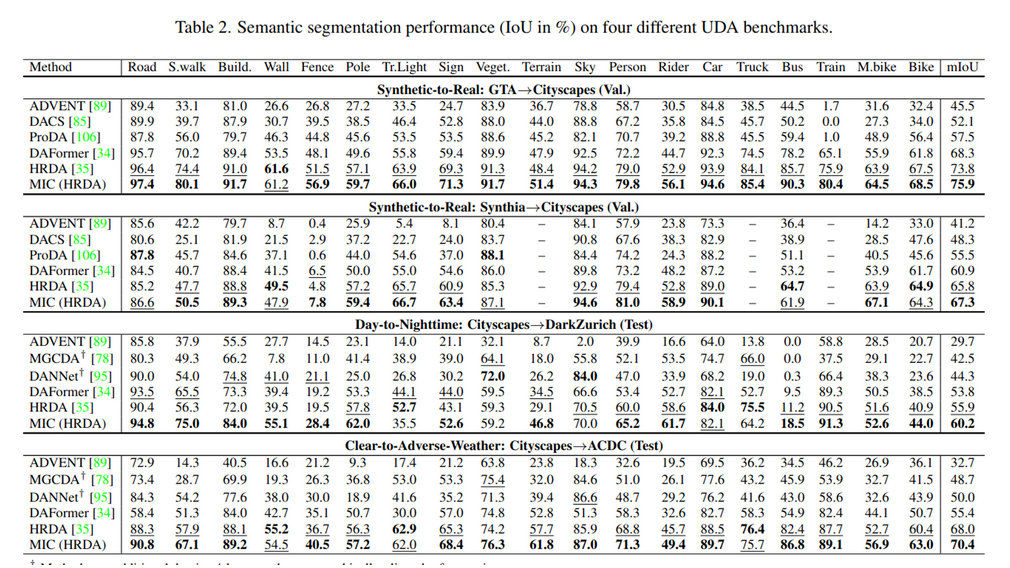
4.2. MIC for Semantic Segmentation
-
Synthetic-to-real (GTA→ CS)
-
CNN (DeepLabV2)과 Transformer(DAFormer)모두 성능 향상 보임 (1등)
-
https://paperswithcode.com/sota/unsupervised-domain-adaptation-on-synthia-to?metric=mIoU
-
-
-
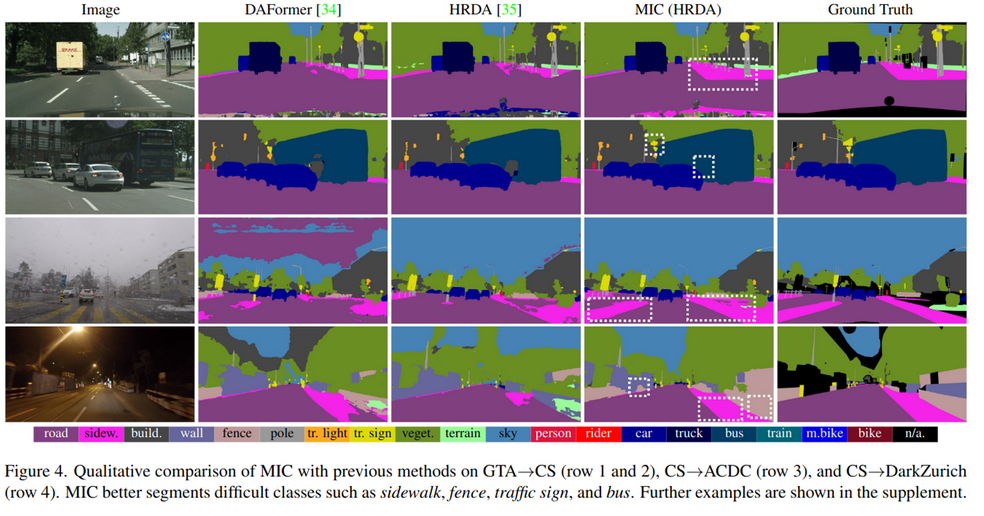
Total
4.3. MIC for Image Classification
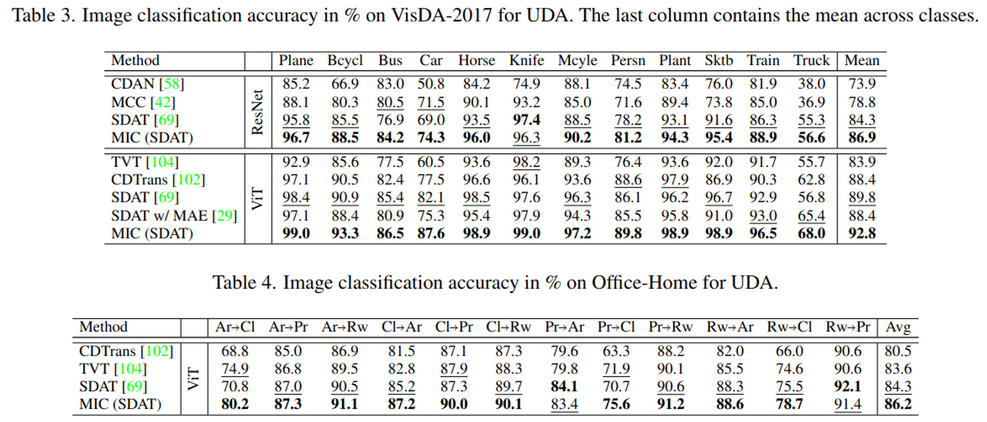
- Baselines
- Classification
- Dataset : VisDa2017, Office-home
- 어려운 domain adaptation에서 성능 향상이 더 큼
- Art → Clip
- Product → Clip
- 어려운 domain adaptation에서 성능 향상이 더 큼
- Model : SDAT
- MIC가 성능 향상을 대체적으로 보임
- 반면, MAE pretraining(unsupervised)은 UDA task에서 image-net pretraining (supervised) 성능 하락을 발생시킴
- Dataset : VisDa2017, Office-home
- Classification
4.4. MIC for Object Detection
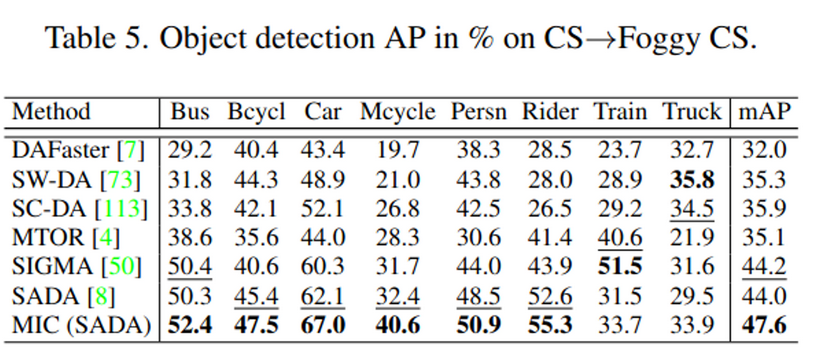
- Baselines
- Object Detection
- Dataset : CS → Foggy CS
- Model : Faster-RCNN w/ Res50
- Paperswithcode 현재 1등
- https://paperswithcode.com/sota/unsupervised-domain-adaptation-on-cityscapes-1
- Object Detection
- Paper vs. Experiment
| Bus | Bicycle | Car | Mcycle | Persn | Rider | Train | Truck | mAP(50) | |
|---|---|---|---|---|---|---|---|---|---|
| paper | 52.4 | 47.5 | 67.0 | 40.6 | 50.9 | 55.3 | 33.7 | 33.9 | 47.6 |
| experiment | 50.7 | 47.5 | 66.8 | 36.3 | 50.9 | 53.7 | 31.2 | 28.9 | 45.8 |
4.5. In-Depth Analysis for MIC
-
Masked Image(MI)를 어디에 어떻게 적용해야 하는가?

-
Domain Gap이 큰 경우 (GTA→CS)
- Source image에 MI를 augmentation으로 사용하는 것은 성능 하락을 보임
- Source도메인에서 Contextual 정보를 학습한 것이 target domain으로 전이(transfer)가 잘 안일어난다는 뜻
-
Domain Gap이 작은 경우 (CS→ACDC)
-
Source image에 MI를 augmentation으로 사용하는 것은 성능 향상을 보임
-
Source도메인에서 Contextual 정보를 학습한 것이 target domain으로 전이(transfer)가 잘 일어난다는 뜻
→ Wildfire Smoke 를 실내 Smoke로 전이할 경우, Domain gap이 작은 경우에 해당할 것으로 사료됨
-
-
-
Ablation Study
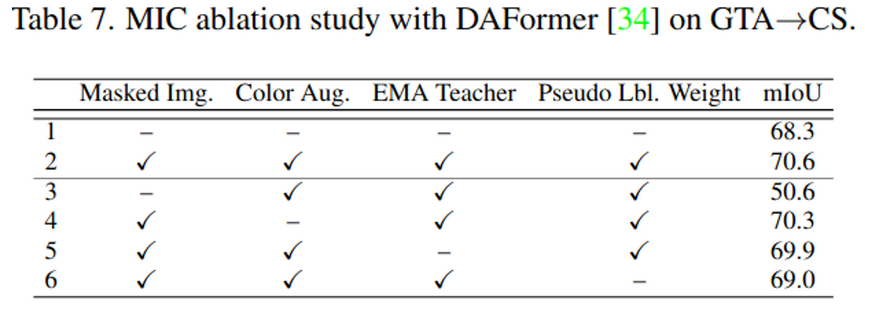
- MIC 제외 시 가장 큰 성능 하락을 보임(20mAP drop) → MIC가 유효함을 입증
-
Patch Size & Mask Ratio

- b : patch size
- r : mask ratio
- 너무 큰 patch size, mask ratio는 성능을 하락시킴
-
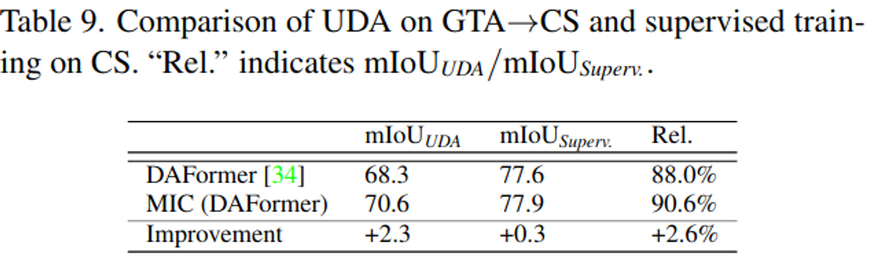
MIC on Supervised Learning (vs. UDA)
-
Supervised learning에서 MIC사용 시, 0.3mAP 향상 → Oracle 대비 88.0% 의 정확도로 향상됨
-
UDA에서 MIC 사용 시, 2.6mAP 향상 → Oracle 대비 90.6% 의 정확도로 향상됨
-
-
Training & Inference speed
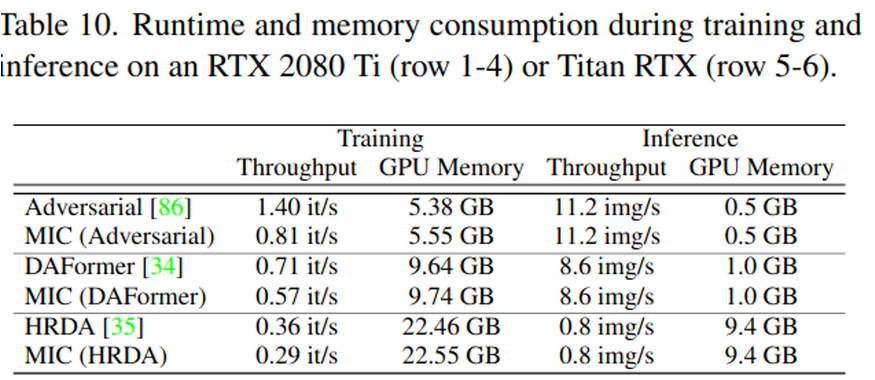
- EMA teacher를 사용하는 방식 (HRDA, DAFormer)는 teacher network를 재사용하므로 24% 학습 속도 감소
- EMA teacher를 사용하지 않는 방식(Adversarial training)은 75% 학습 속도 감소
- Inference 속도는 하락 없음
5. Conclusion
- UDA Tasks (Segmentation, OD, Classifcation)에서 SOTA 달성
- Supervised learning과의 gap을 줄임
- Alchera FireScout 검출 모델 학습시 Augmentation + UDA의 추가 Loss term으로 MIC 고려해볼 수 있을 듯