[LG] LayoutDM: Transformer-based Diffusion Model for Layout Generation
[LG] LayoutDM: Transformer-based Diffusion Model for Layout Generation
- paper: https://arxiv.org/pdf/2305.02567
- github: X
- CVPR 2023 accepted (인용수: 22회, ‘24-05-27 기준)
- Downstream task: Layout Generation
1. Motivation
- Diffusion model의 근래 성공에 영감을 얻어 high-quality layout을 Transformer 기반의 encoder로 생성해보면 좋을 것 같다는 생각이 듬
2. Contribution
- User-specified attribute기반의 주어진 element를 Transformer + Diffusion 기반으로 layout을 생성하는 LayoutDM을 제안
- high-quality generation, better diversity, faithful distribution coverage, stationary training등 Diffusion Model의 특성을 반영함
- Backbone을 U-Net에서 Transformer로 바꾼 cLayoutDenoiser를 제안함
- 5가지 benchmark에서 SOTA
3. LayoutDM
-
Overall Architecture
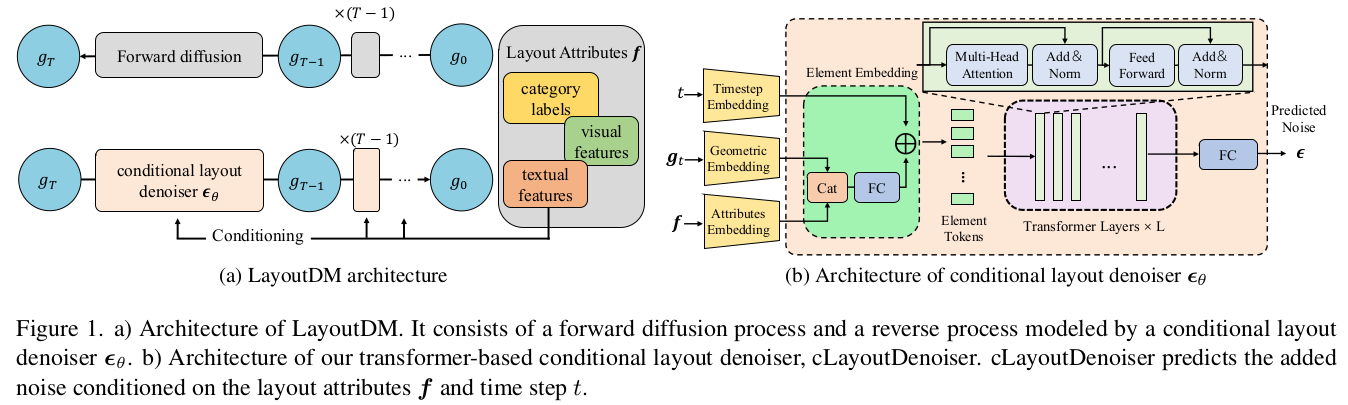
-
Preliminaries
-
Layout generation
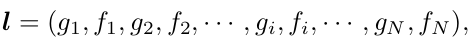
- N개의 layout element
- $g_1$: 1번째 layout geometry (x,y,w,h)
- $f_1$: 1번째 layout attribute
-
Forward process
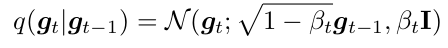
-
Reverse process
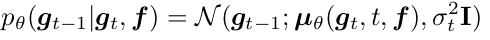
-
Reparameterized
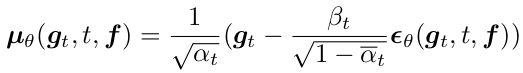
-
-
Conditional Layout Denoiser
-
layout geometry g, layout attribute f와 time step t를 입력받아 noise $e_{\theta}(g_t, t, f)$ 를 예측

- element order는 상관이 없으므로, positional encoding를 제외함
- Geometric embedding은 4차원 (x,y,w,h)에서 더 의미 있는 embedding을 생성하기 위해 fixed length로 embedding 수행
- TE: Sinusoidal time embedding
- Element Embedding: 주어진 hidden vectors $h_f, h_g$,TE(t)를 concat하여 FC통과 시켜 fusion 수행
-
-
Transformer Layer
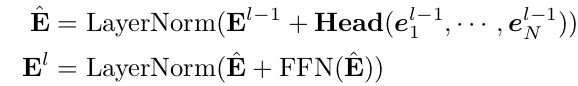
-
Training

-
Loss
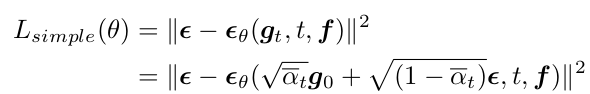
-
-
Inference

4. Experiments
-
Quantitative Result
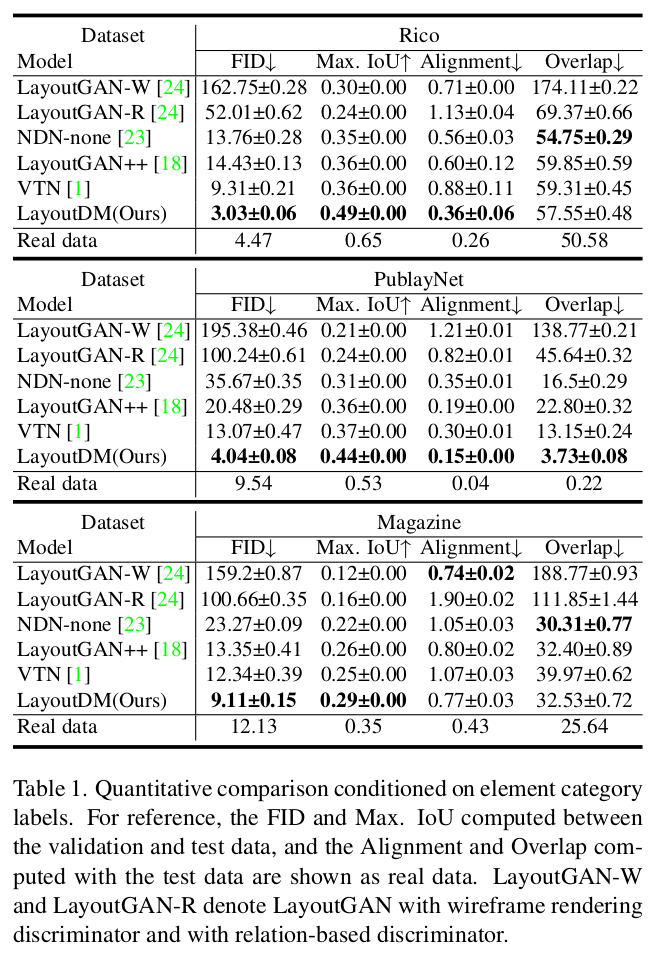
-
Extended results for PubLayNet

-
Qualitative Result
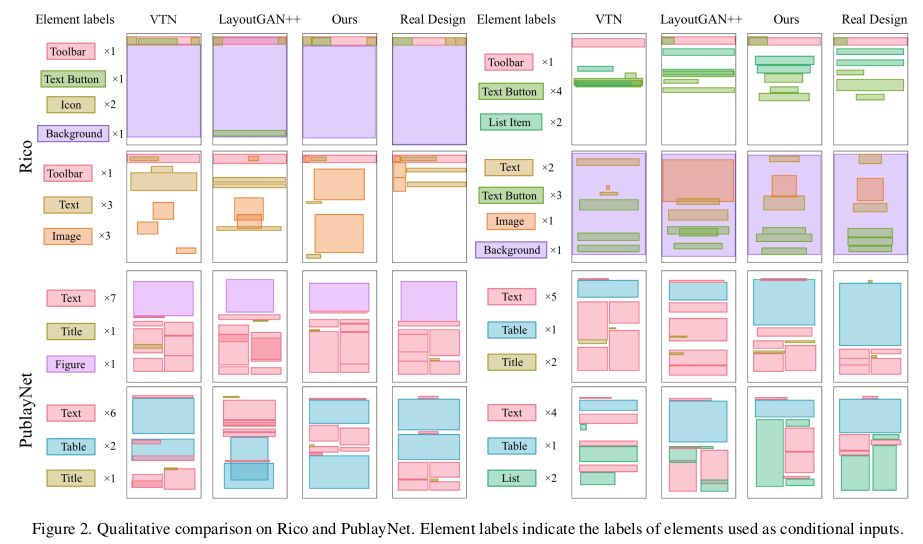
-
Ablation
-
Transformer Layer vs. FC Layer로 대체
-
Quantitative Result
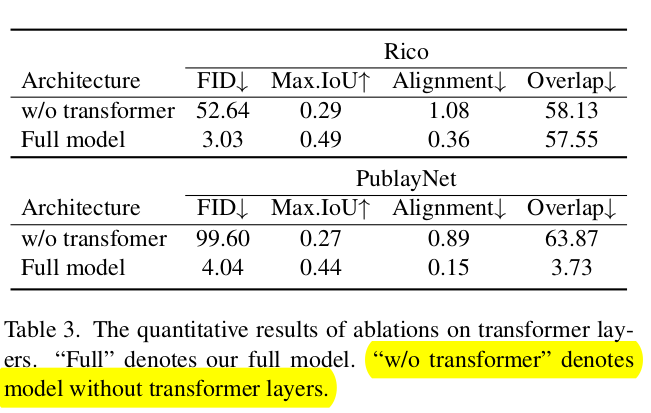
-
Qualitative Result
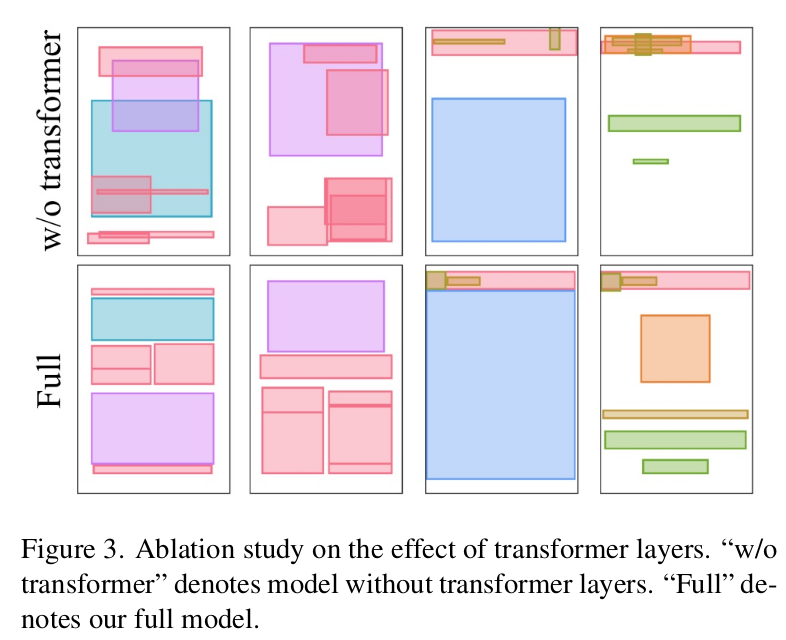
-
Diversity Comparison

-
-
-
Rendered Result

