[SSL][OD] Label Match : Label Matching Semi-Supervised Object Detection
[SSL][OD] Label Match : Label Matching Semi-Supervised Object Detection
-
paper: https://arxiv.org/abs/2206.06608
-
git : https://github.com/hikvision-research/SSOD
-
CVPR 2022 accepted (인용수: 42회, ‘23.11.15 기준)
-
downstream task : SSL for OD
-
Contribution
-
self-training 기반 SSL의 label mismatch 문제를 두 가지 해결 방식으로 접근
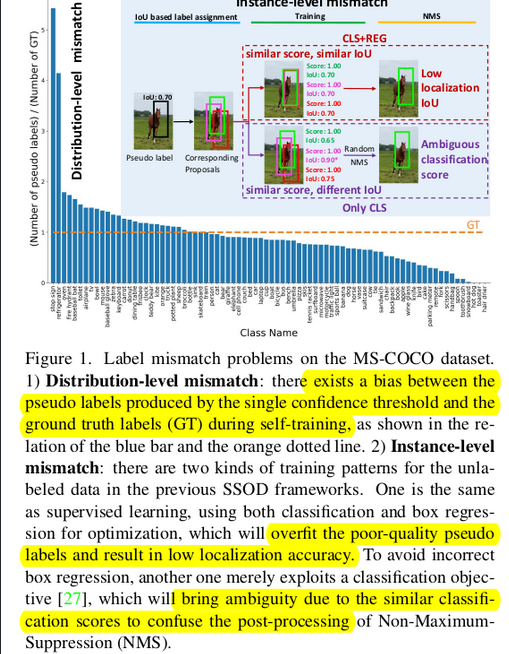
- distribution-level
- unlabeled data의 “class distribution” 분포가 labeled data의 그것을 따른다고 approximate함
- labeled data의 class distribution이란? 전체 instance 중에 해당 class에 gt box 의 비율 (class-dependent)
- “unbiased pseudo label” 을 만들기 위해 label-distribution-aware confidence threshold를 사용
- unlabeled data의 “class distribution” 분포가 labeled data의 그것을 따른다고 approximate함
- instance-level
- reliable pseudo label, uncertain pseudo label을 분리함
- reliable pseudo label은 기존 IoU based learning(Supervised learning)과 동일하게 one-hot vector로 학습
- uncertain pseudo label에 대해서는 NMS를 통과한 Teacher의 Pseudo label과 매칭된 (IoU > 0.5) student의 proposal로 teacher의 RoIHead를 통과시켜 teacher의 pseudo label을 re-calibration시킴 → Pseudo label로 활용
- distribution-level
-
mmdetection 기반으로 코드 제공, (당시) SSL for OD SOTA 달성
-
-
Overview
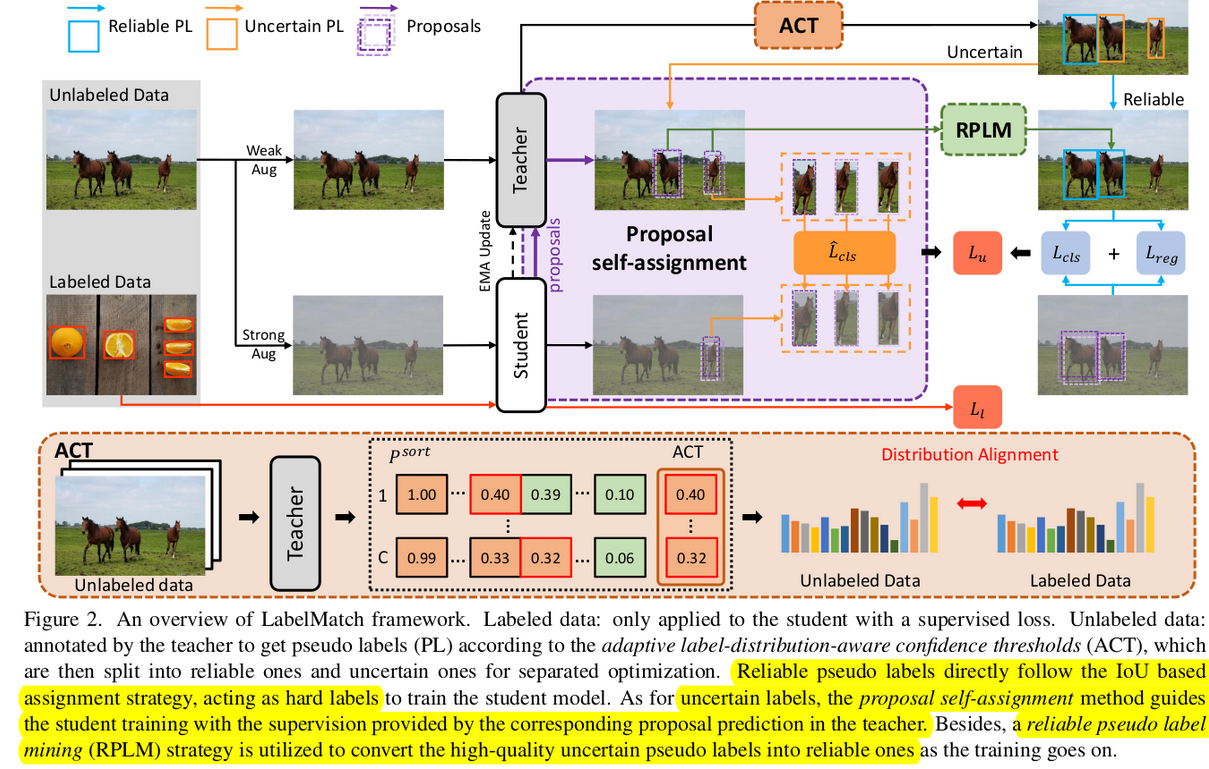
-
Baseline : mean teacher
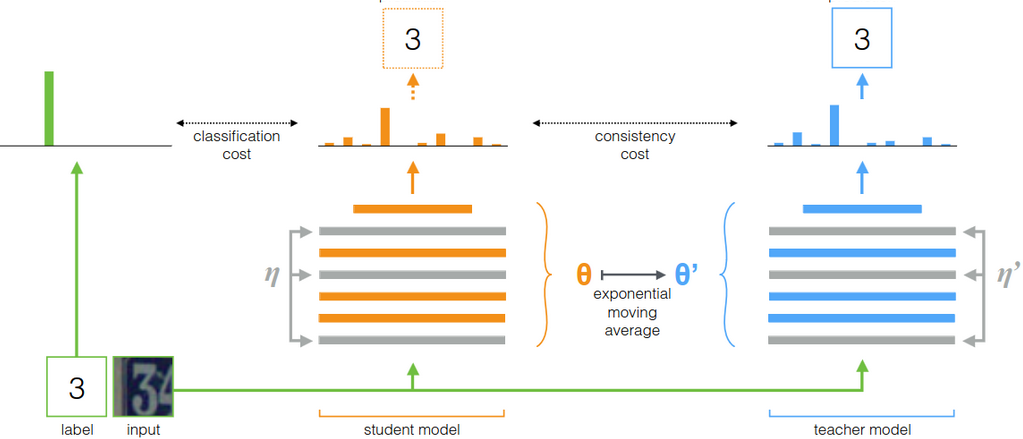
-
-
Label Match
-
Re-distribution Mean Teacher : labeled data내의 instance 분포와 유사하도록 threshold를 tuning (ACT : Adaptive label-distribution-aware Confidence Threshold) → distribution-level
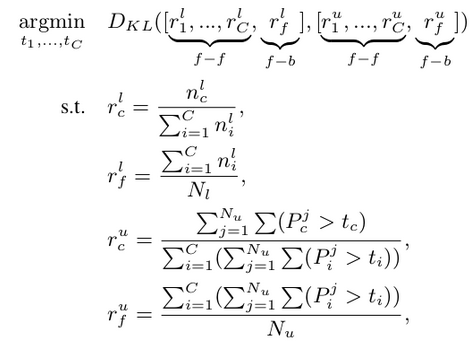
-
$n_i^l$ : i class의 labeled data 내 bbox 갯수
-
$C$: Class 갯수
-
$P_i^j$ : i class의 j unlabeled image에 대한 prediction score
-
$f-f$ : forground-forground 분포
-
$f-b$ : forground-background 분포
-
$t_c$ : 최적화 대상. dynamic threshold라 생각. $n_c^l*N_u/N_l$번째 prediction score
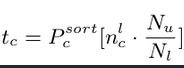
- $P_c^{sort}$ : c lass의 prediction score를 내림차순으로 정렬한 list
- unlabeled data의 subset (약 10k images)로 구성
- K iteration마다 threshold를 변경해줌 → unlabeled의 class분포가 labeled의 class 분포와 유사해지도록 threshold를 조절함
- $P_c^{sort}$ : c lass의 prediction score를 내림차순으로 정렬한 list
-
-
Proposal Self-Assignment → instance-level
-
Reliable pseudo label : 기존 Supervised learning과 동일하게 IoU based matching으로 one-hot vector로 학습
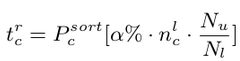
- $\alpha$ : reliable한 pseudo label의 비율을 hyperparameter로 setting (0.6)
-
Uncertain pseudo label : $t_c^r$보다 낮은 prediction score의 pseudo label. 일반적으로 location quality도 떨어짐.
-
Teacher의 uncertain pseudo label과 매칭된 student의 proposal을 teacher의 RoIHead에 다시 넣어서 refine시킨 값을 최종 pseudo label로 활용
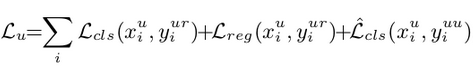
- $y_i^{uu}$ : teacher의 uncertain pseudo label
- $y_i^{ur}$ : teacher의 reliable pseudo label
-
Classification loss만 학습
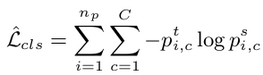
- $n_p$ : uncertain teacher pseudo label과 매칭된 student의 proposal 갯수
- $C$: class 갯수
- $p_{i,c}^t$ : student의 i번째 proposal이 teacher의 RoIHead 통과하여 refined된 pseudo label의 prediction score
- $p_{i,c}^s$ : student의 i번째 proposal
-
-
Reliable Pseudo Label Mining
-
Self-training을 통해 student, teacher 모두 점진적으로 성능이 향상됨 → uncertain pseudo label중 high quality을 선별하여 localization loss에 추가하고 싶다!가 동기
-
teacher의 proposal (잠재 pseudo labels) 중에 NMS 통과 전 proposal들의 mean score, mean IoU를 계산하여 threshold (0.8)이상이면 uncertain loss → reliable loss로 변경
-
regression loss 추가되고, one-hot label로 변경됨
-
NMS 통과 후 teacher의 prediction (pseudo label)을 기준으로 IoU 계산
-
higher mean score, higher mean IoU가 high quality임을 실험적으로 입증
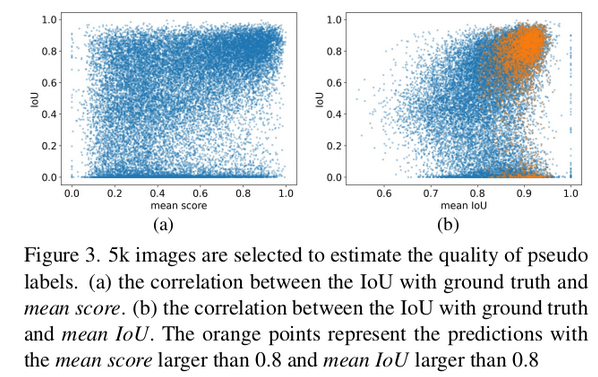
-
-
-
-
-
Experiments
-
COCO
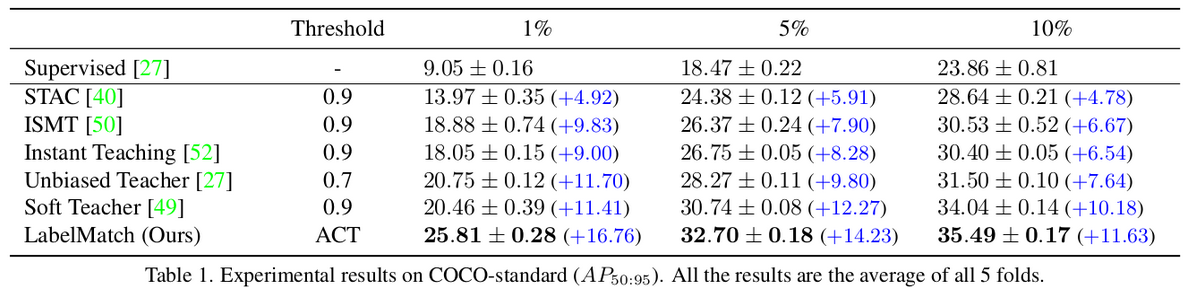
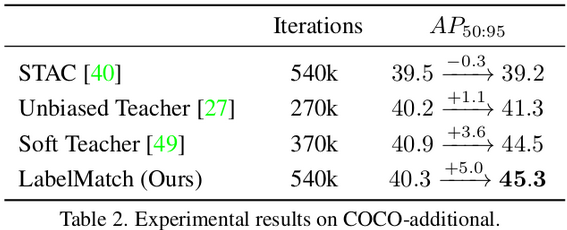
-
Pascal VOC
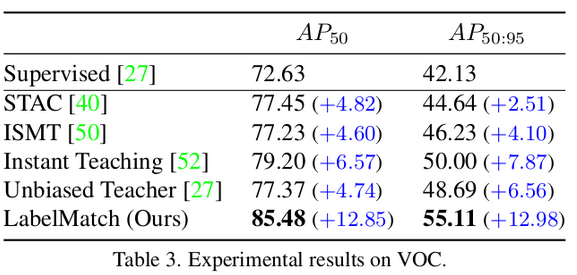
-
-
Ablations
-
Quality of Pseudo labels
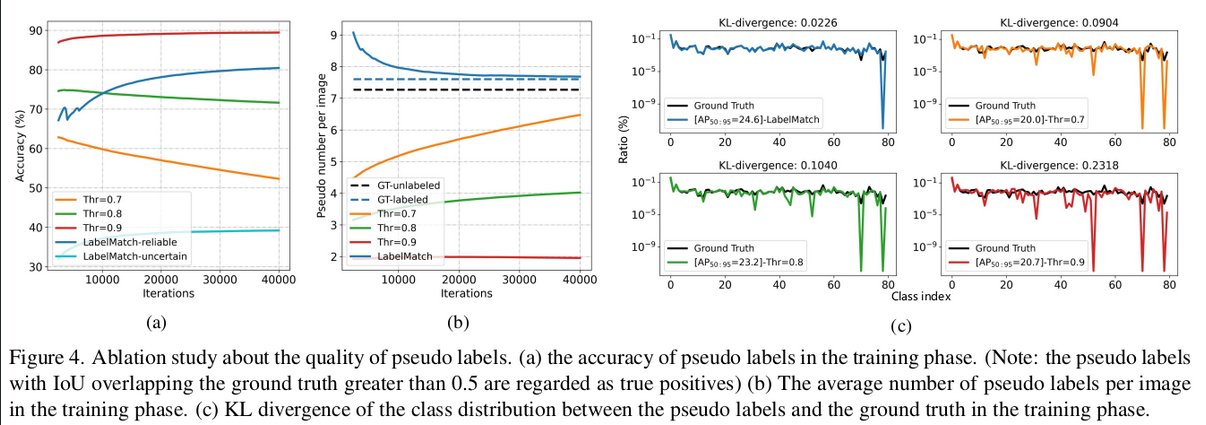
- (a) 고정 threshold (0.7, 0.8)은 iteration 경과후 accuracy drop. But ACT는 향상됨
- (b) 고정 threshold (0.9)는 GT와 다르게 recall이 매우 안좋음. But ACT는 GT에 수렴
- (c) KL Divergence가 GT와 비교해서 ACT > 고정 threshold임.
-
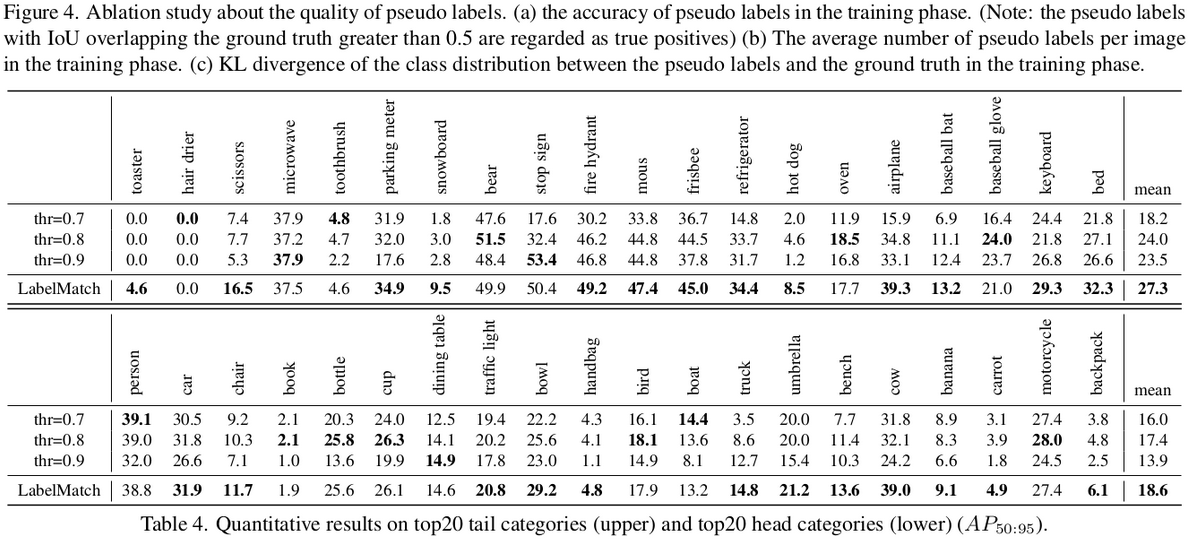
ACT adaptation이 head, tail class에 특히 효과가 좋음

-
-
Hyperparameter에 따른 성능 실험
-
K iteration, alpha, PSA (Proposal Self-Assignment)
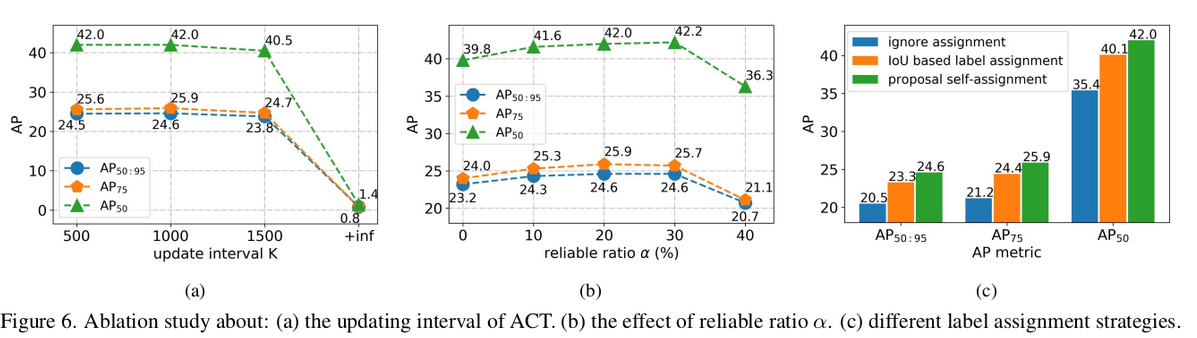
-
PSA vs. IoU based matching

-
-
RPLM (Reliable Pseudl Label Mining)
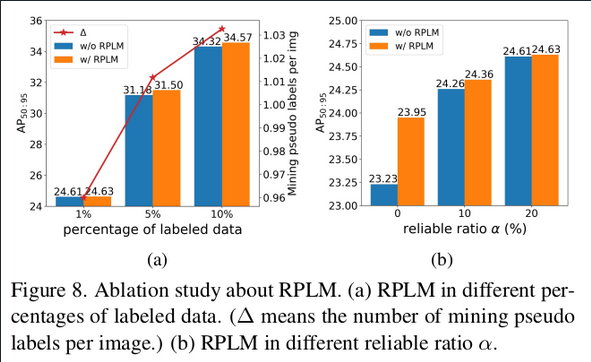
- Uncertain pseudo label 중 mean prediction, mean IoU가 높은 녀석들을 reliable loss로 대체하는 module
- 성능 미세 상승