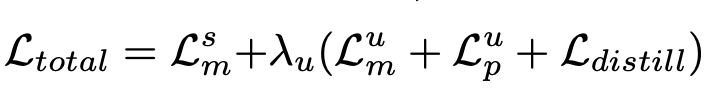[SSL][OD] LSM: Low-Confidence Samples Mining for Semi-supervised Object Detection
[SSL][OD] LSM: Low-Confidence Samples Mining for Semi-supervised Object Detection
- paper: https://arxiv.org/pdf/2306.16201.pdf
- github: x
- archived (인용수: 0회, ‘23.12.08 기준)
- downstream task : SSL for OD
1. Motivation
-
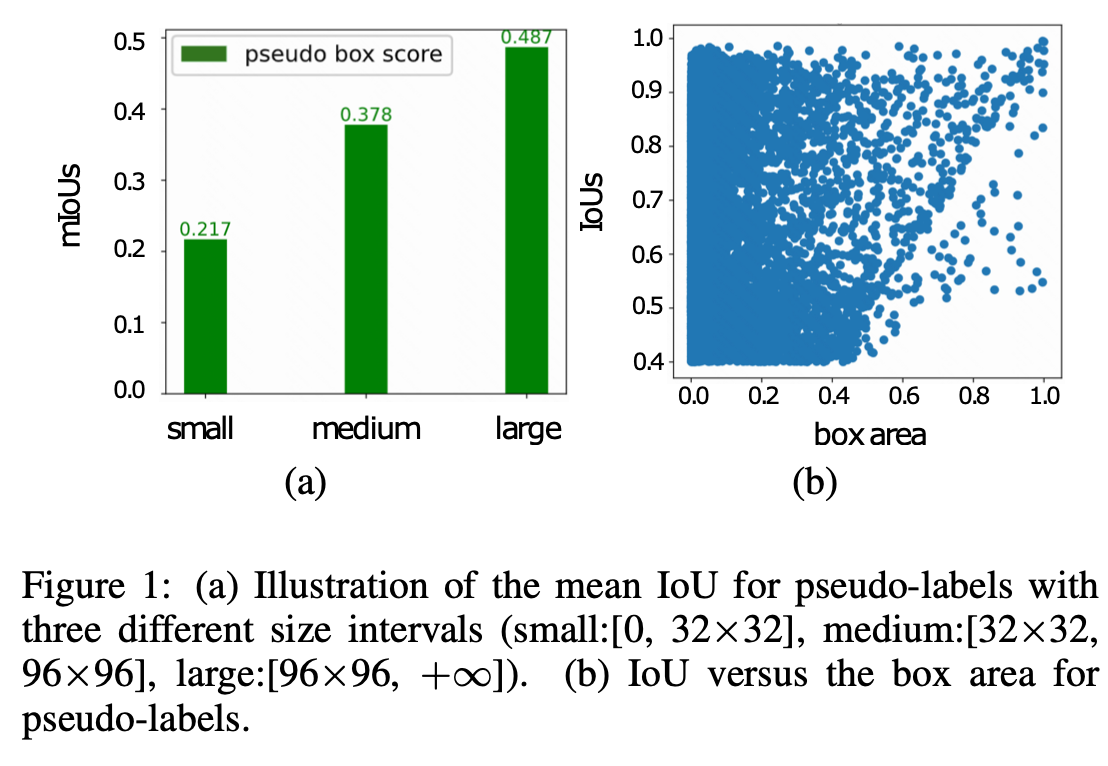
Size에 따른 pseudo label의 quality를 IoU로 정의하고, 살펴본 결과 large object일수록 quality가 좋음을 확인
-
같은 classification score에서 큰 물체일수록 IoU가 높음 (pseudo label quality가 좋음)을 정성적으로도 보여줌
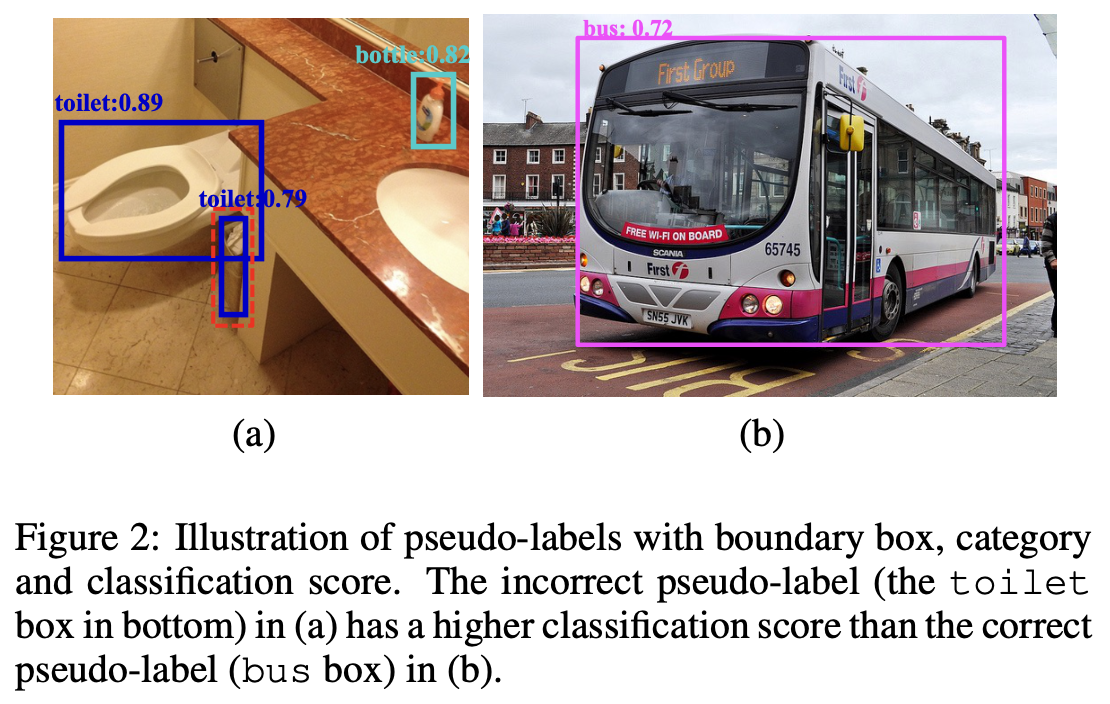
-
Low classification score의 pseudo label에 대해 기존 연구들은 학습에 활용하지 않았는데, 물체의 scale 정보를 leveraging하여 low-confidence pseudo-box도 학습에 활용할 수 있지 않을까?
2. Contribution
- 물체의 scale에 따른 confidence distribution을 살펴봄. 또한, 물체의 크기와 IoU의 양의 상관관계가 있음을 밝힘
- Low confident Pseudo Information Mining(PIM) branch와 이를 기존 main branch의 Self-Distillation 하는 Low-confidence Samples Mining(LSM)을 제안함
- Deformable DETR을 SSOD에 적용하였으며, unlabeled-data로 classification set을 활용하여 denoise capability를 입증
3. Low-confidence Samples Mining
-
Baseline: Mean-Teacher를 사용
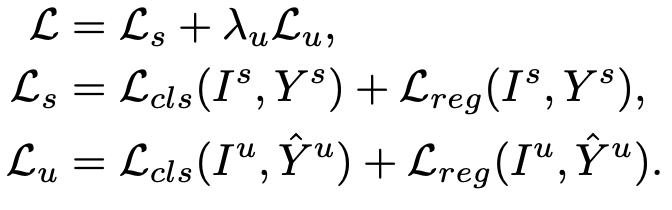
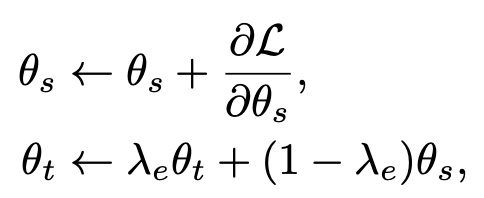
-
Overall Diagram
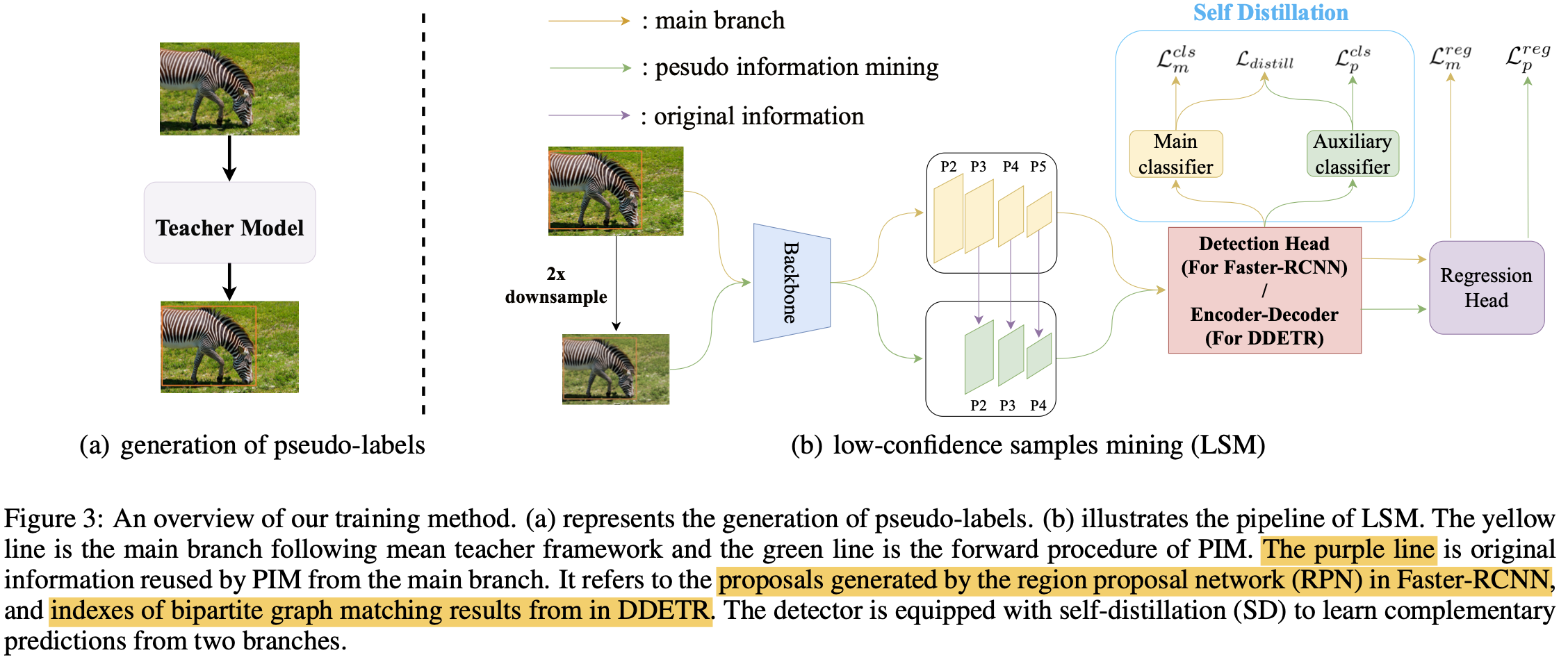
3.1. Pseudo Information Mining (PSM)
-
Large object에서 low confidence bbox에서도 informative한 정보가 있을 수 있다는 통찰력을 바탕으로 downsample한 이미지를 PSM branch에 입력으로 넣어줌
- 더 낮은 resolution의 이미지에서 extracted된 box feature는 large-area candidate가 후보로 뽑히는 경향이 생김 (?)
- 이는 noisy small-area pseudo label로 학습되는 경향을 막아주는 효과도 있다고함
- PSM의 weight를 줄여줌으로써 noisy label에 의한 효과를 적게 가져감 (positive pseudo label도 덩달아 영향력이 적어질듯..)
-
main branch보다 낮은 threshold $\alpha$를 적용하여 학습에 활용함
-
PSM Loss
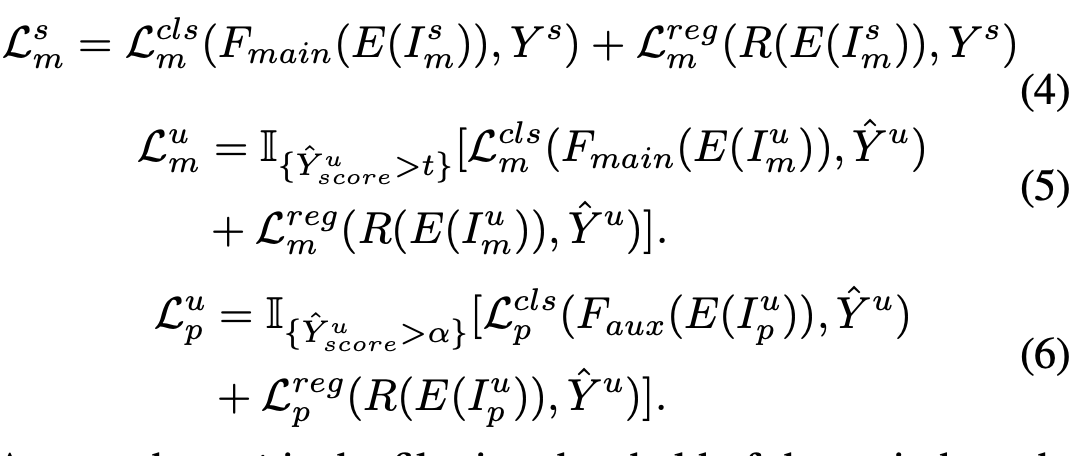
- $E$: Backbone feature extractor
- $F_{main}$: main classifier
- $F_{aux}$: auxiliary classifier
- $R$: regression head shared with PIM & main branch
3.2. Self-Distillation
-
auxiliary classifer에서 [$\alpha$, $t$]사이의 categorical prediction을 main branch의 그것과 KL Divergence로 학습시킴
-
단, 이떄 noisy label이 있을 수 있으므로, auxiliary classifier의 gradient는 freeze시키고, main branch만 학습시킴
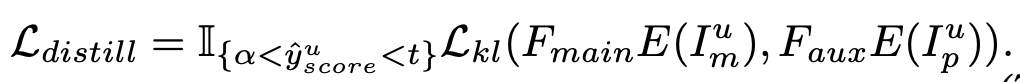
-
Total Loss