[MM] LLaVA: Visual Instruction Tuning
[MM] LLaVA: Visual Instruction Tuning
- paper: https://arxiv.org/pdf/2304.08485
- github: https://github.com/haotian-liu/LLaVA
- NeurIPS 2023 accepted (인용수: 1278회, ‘24-04-25 기준)
- downstream task: VQA & Image Captioning
1. Motivation
-
Machine-generated instruction following data가 zero-shot capability가 상승한다는 기존 연구가 있음
-
하지만, Multi-modal 관점에선 연구가 없음 (Text-only)
$\to$ Visual feature를 사용하여 GPT-4와 유사한 성능을 내는 모델을 개발해보자!
2. Contribution
- Multimodal instruction following-data: GPT-4를 이용하여 machine-generated instruction을 생성하는 방법을 제안함
- CLIP-Vision encoder와 LLM decoder Vicunna를 활용하여 Science QA data에서 SOTA를 찍음
- Multi-modal instruction following data 공개: COCO와 Open-Wild 데이터를 선별하여 benchmark를 공개함
- Open-source: 학습코드, 모델 공개함
3. LLaVA : Large-Language and Vision Assistant
3.1 GPT-assisted Visual Instruction Data Generation
-
(Image, Text) pair opensource 데이터셋인 CC와 LAION을 활용하여 상세한 Image Caption을 GPT-4를 이용해서 생성함
- GPT-4 Input: 2가지 Context Type로 GPT에 입력 Prompt를 제공함
- GPT-4 Output: 3가지 Response를 생성함

- Few sample에 대해 manually Response를 생성하고, 이를 seed로 삼아 automatic하게 생성함
- 총 158K 의 visual instruction data를 생성함
- conversation (58K)
- Detailed description (23K)
- Complex reasoning (77K)
-
GPT-4에 입력하는 Prompt 예시

3.2 Visual Instruction Tuning
-
Visual Instruciton Tuning vs. Visual Prompt Tuning
- Visual Instruction Tuning : LMM모델이 (machine-generated) instruction과 같이 (세부적인 묘사가 가능한 수준=GPT-4 수준) 세세한 정보를 표현하는 Image Captioning & VQA task를 수행하는 능력을 기르는데 초점이 있음
- Visual Prompt Tuning: LMM모델이 학습할 때 parameter-efficient하게 학습하는데 목적이 있음
-
Overall Architecture

- Z$_v$: CLIP visual encoder의 latent vector
- W: Simple projection layer. Langauge token과 dimension 맞추려는 목적
- H$_q$: Instruction Language token
-
학습
-
Question & Answer type response에 대해서는 T번의 sequence (Q-A)에 대해 모두 생성하도록 학습
-
Qustion (Instruction)으로는 첫번째만 visual token과 langauge token에 대해 순서를 random하게 입력, 다음 turn부터는 quesiton만 입력
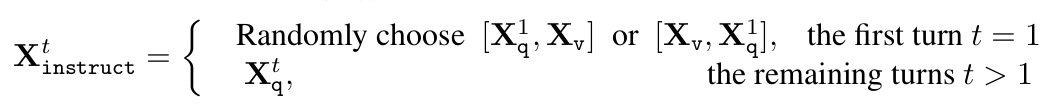
$\to$ random 입력을 통해 interface가 어떠한 입력이 나오든 대처 가능해지게 됨

-
L개의 Answer의 probability maximize하도록 학습
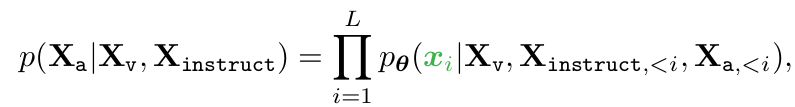
- $\theta$: projection weight (LLM, Clip-V는 pretraining시 frozen)
-
2-step으로 학습
- Pre-training
- projection weight (LLM, Clip-V는 pretraining시 frozen)
- CC3M 데이터 중 학습의 효율성을 위해 filtering하여 595K로 visual instruction data에 대해 학습을 수행
- Finetuning
- Visual encoder는 역시 frozen
- LLM과 Projection layer를 학습
- 데이터
- Multimodal chatbot : MS-COCO의 158K image에 대해 instruction을 활용하여 학습
- Science QA: 해당 benchmark로 학습 (Single-turn으로만 학습)
- Pre-training
-
4. Experiments
-
정성적 In-depth image understanding (vs. SOTA) 비교

-
MS-COCO 정량적 비교
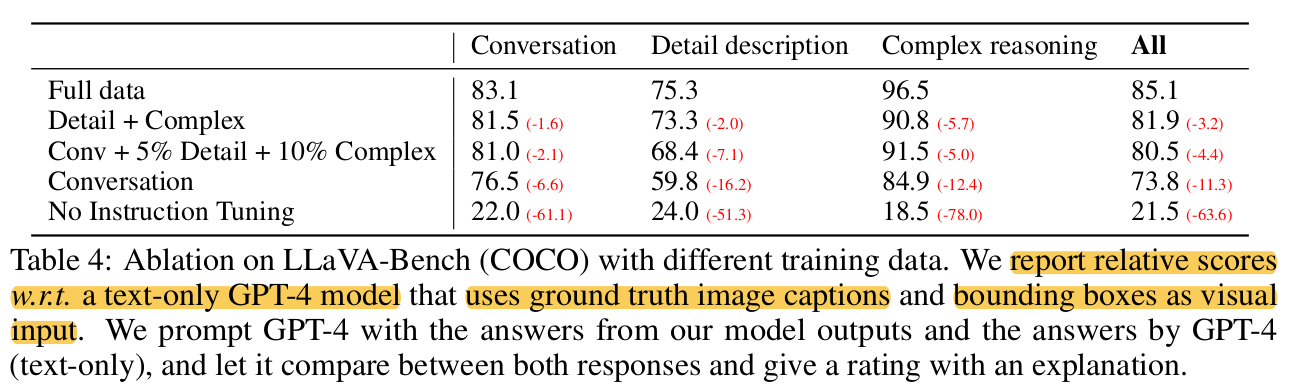
-
LLaVA-benchmark 정량적 비교
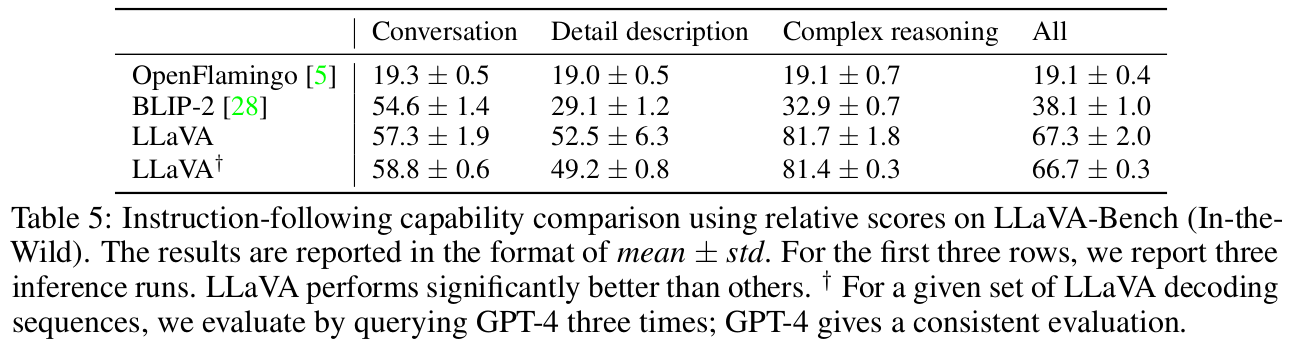
- GT : GPT-4
-
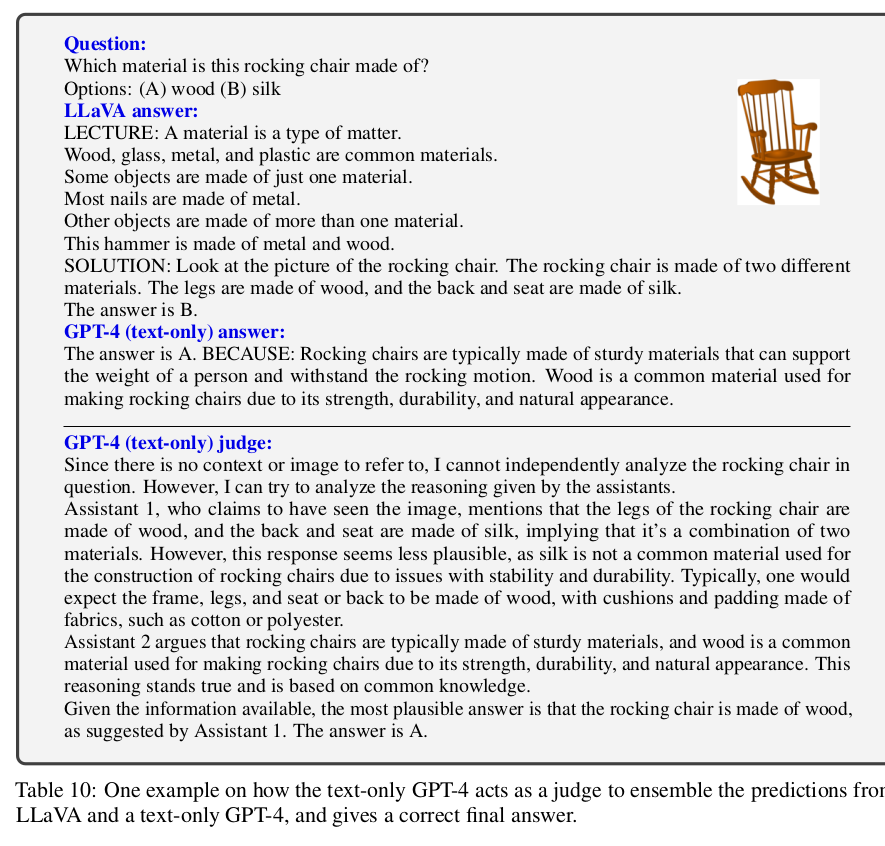
LLaVA-bench(In-The-Wild)의 challenging example (틀린 경우)

-
(우측): Strawberry랑 요구르트가 있는 이미지. 하지만 Straberry 요구루트가 있다고 오인식함
$\to$ Image를 patch단위로 이해해서 발생한 오류로 생각됨
-
-
Science QA dataset 성능
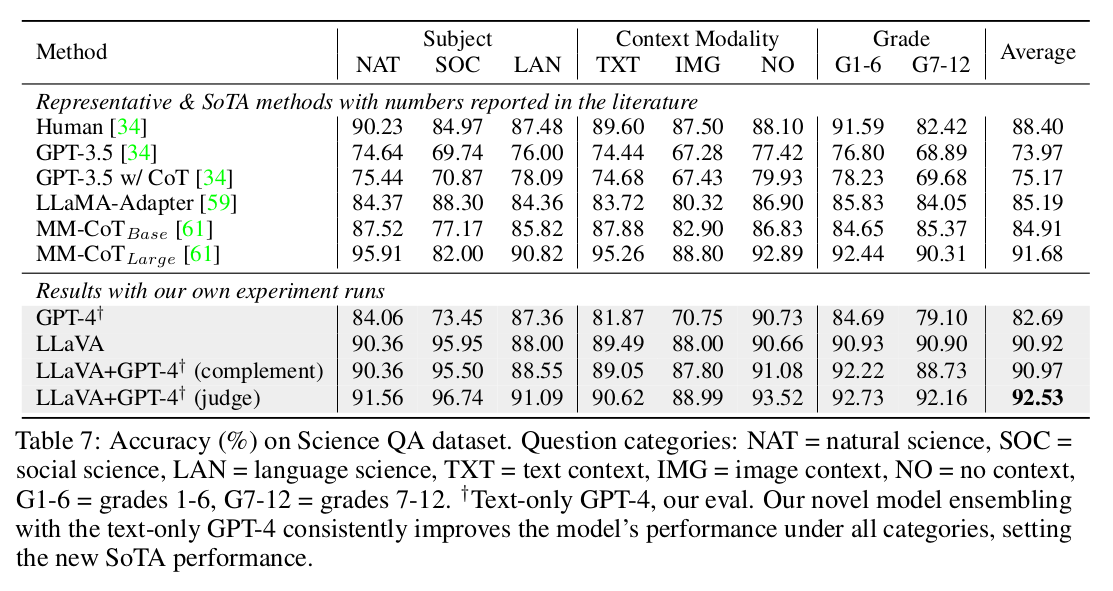
- LLaVA+GPT-4 (complement) : GPT-4 결과가 없을 경우, LLaVA로 대체
- LLaVA+GPT-4 (judge) : LLaVA와 GPT-4 결과가 다를 경우, 다른 것에 대해 GPT-4에게 재답변 요청하고, 이를 최종 값으로 활용 (ensemble)
-
Ablation
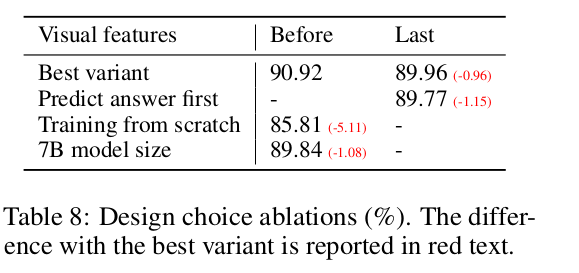
-
Best variant: CLIP image encoder의 마지막 vs. 그 직전 feature 사용
- 직전 feature가 더 localized specific image detail 정보를 많이 보유 (Last는 global 정보만 보유)
-
Answer-first vs. Reasoning-first
- Answer에 대한 Reasoning 후에 Answer를 답변하는게 성능이 좋았음
-
Scratch 보단 Pretraining하는게 좋았음
-
13B $\to$ 7B로 모델을 줄이면 성능이 하락함 (scalable)
-