[DG][MM] USING LANGUAGE TO EXTEND TO UNSEEN DOMAINS
[DG][MM] USING LANGUAGE TO EXTEND TO UNSEEN DOMAINS
- paper : https://arxiv.org/pdf/2210.09520.pdf
- git : https://github.com/lisadunlap/LADS
- Published as a conference paper at ICLR 2023 (‘22.10, 인용수 : 5회 (‘23.08.14 기준))
- Downstream tasks: Domain Generalization for classification
- Contribution
- Vision-Language Model (CLIP)을 이용해서 unseen domain에 대한 text description만 가지고 latent space에서 augmentation하는 network 제안
- Linear probing을 통해 backbone fine-tuning 없이 head만 학습시켜 DG task에서 SOTA
- 데이터셋에 존재하는 거짓 편향 (spurious correlation bias)을 다룸
- ex. waterbird on land vs. landbird on water
-
Latent Augmentation Using Domain Descriptions
-
Domain Extension with Language
-
Training Dataset & label
\[\{x_i, y_i\}_{i=1}^n\] -
class name : $t_y$
-
training domain written description : $t_{training}$
-
unseen domain written description : $t_{unseen}$
\[\{t_{unseen}^i\}_{i=1}^k\]
-
-
LADS (Lantent Augmentation using Domain descriptionS)
- Linear probing으로 classification head만 학습
- Input :
- image embedding (by CLIP Image encoder)
- class labels
- text description of class
- text descriotion of domain
-
Two-stage Training approach

-
Augmentation network training
-
$f_{aug}$ : 2-layer MLP with input and output dimensions of 768 and a hidden dimension of 384
-
Train Domain의 image embedding을 Unseen Domain으로 transform
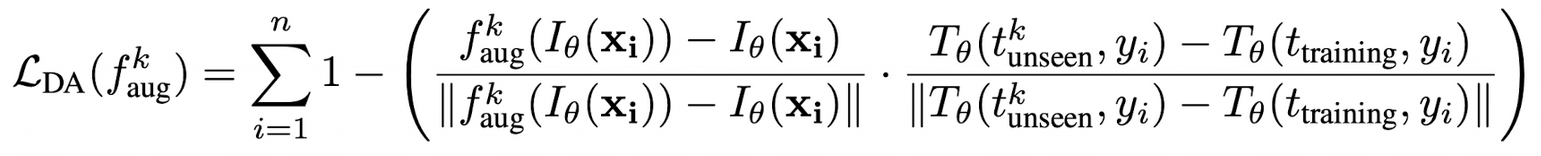
-
그러면서 class의 semantic은 보존
-
CLIP loss를 적용

-
-
LADS 최종 Loss
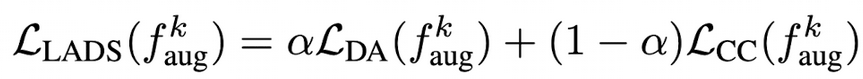
-
-
Fine tuning
- Linear probing: Original image와 함께 Augmented image도 함께 head 만 학습
- CLIP의 backbone까지 학습하는건 overfitting 우려가 있으므로 head만 학습
- Linear probing: Original image와 함께 Augmented image도 함께 head 만 학습
-
-
Dataset Bias
-
CLIP을 활용해서 source domain의 배경이 water이면 augmented domain을 land로, vice-versa

-
-