InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
[MLLM] InternVL3: Exploring Advanced Training and Test-Time
Recipes for Open-Source Multimodal Models
- paper: https://arxiv.org/pdf/2504.10479
- github: https://github.com/OpenGVLab/InternVL
- Technical report (인용수: 18회, ‘25-05-27 기준)
- downstream task: Multimodal Reasoning & mathematics, OCR & Chart & Document Understanding, Multi-Image Understanding, Real-World Comprehension, Comprehensive Multimodal Evaluation
1. Introduction
-
기존 MLLM은 LLM을 기반으로 하고 있기 때문에, LLM backbone을 freezing하고, alignment layer만 tuning하는 등 비효율적인 학습 패러디암으로 운용되었다.
-
본 논문에서는 Pretraining step에서 Vision+Text Interleaved dataset을 통해 native multimodal pre-training 전략을 사용한다.
-
추가로 최신 기술들을 반영한다.
- V2PE (Variable Visual Positional Encoding) 매커니즘: 더욱 긴 multimodal context를 encoding가능하도록 positional encoding을 간소화
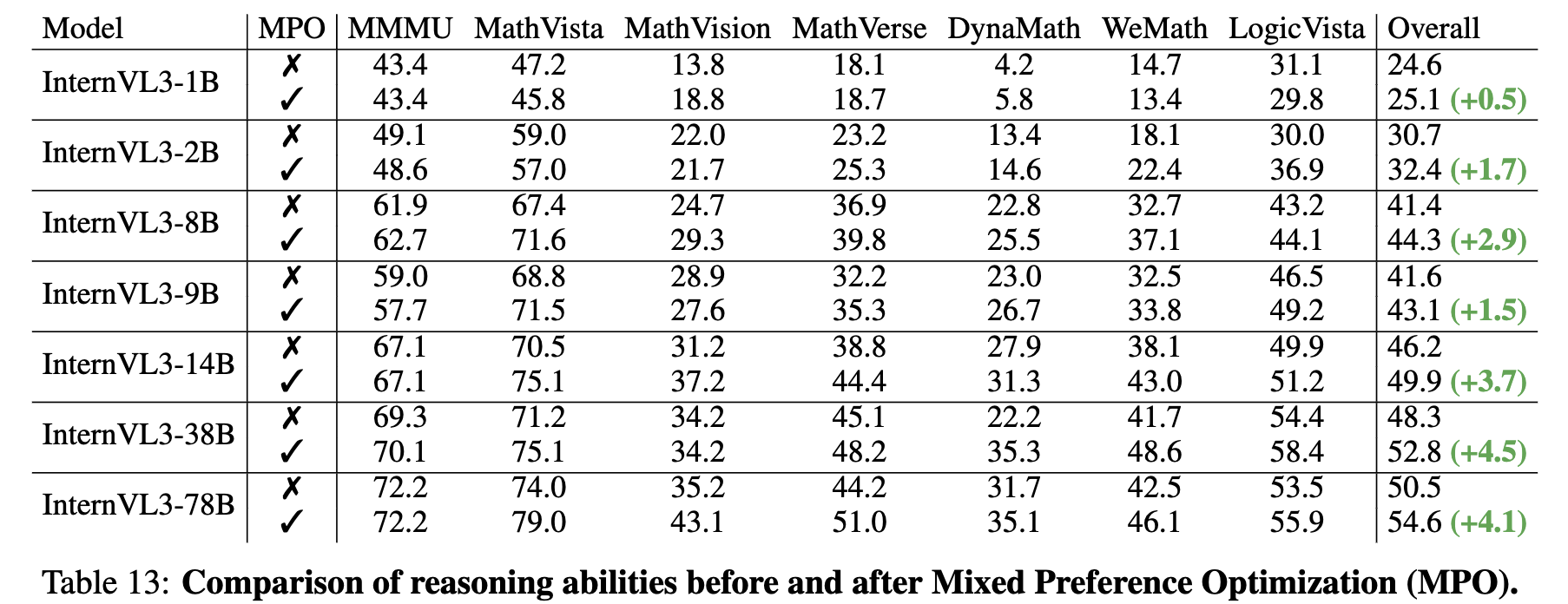
- SFT + MPO (Mixed Preference Optimization): Instruction Following뿐만 아니라, human preference alignment를 post-training시에 수행
- Test-Time Scaling (Best-of-N): N번 예측후, critic model(VisualPRM)이 평가한 제일 높은 score로 최종 output을 도출
-
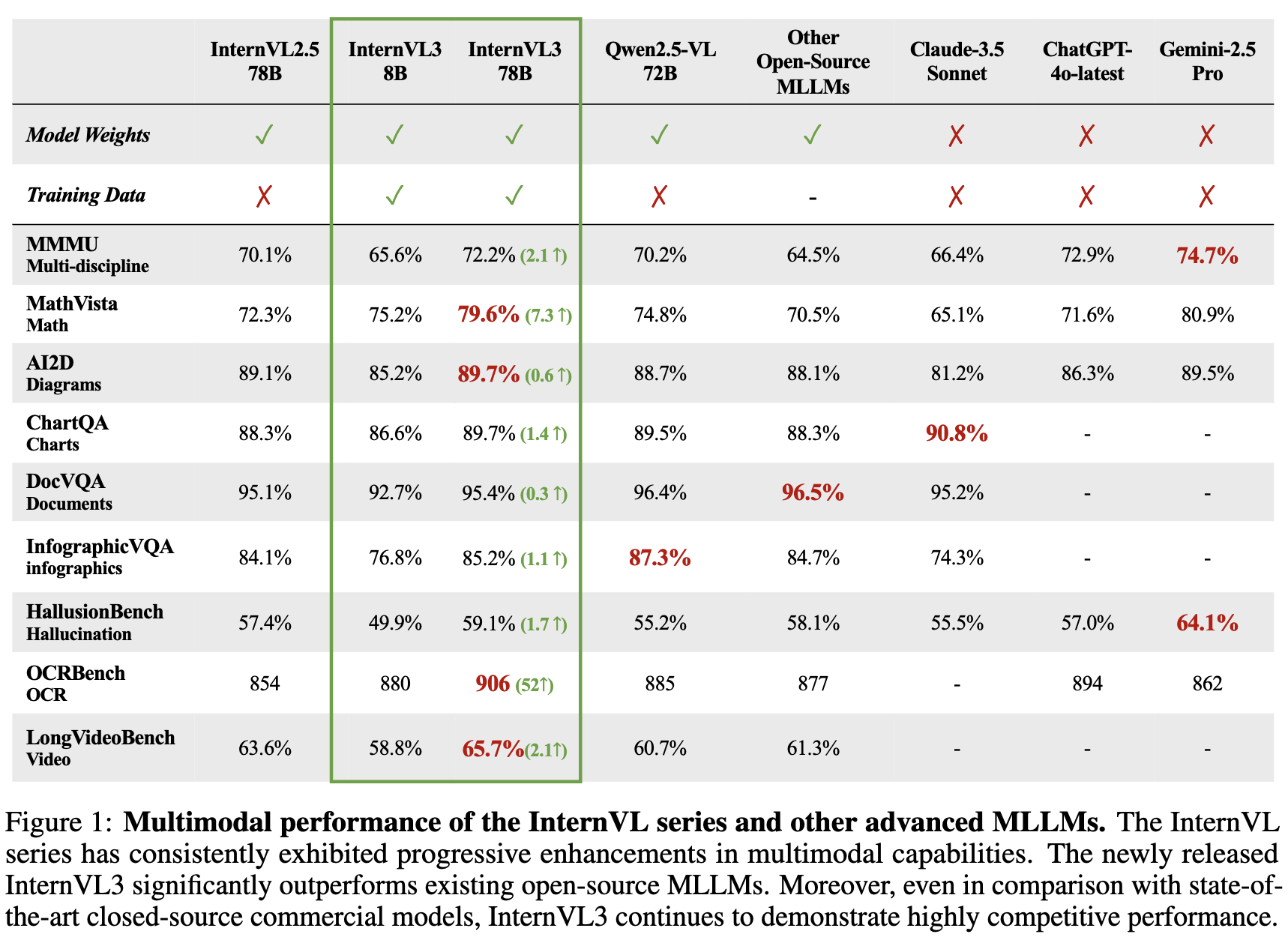
Open-source MLLM에서는 최고 성능, Proprietary model과 버금가는 성능을 보임 (MMMU benchmark - 72.2)
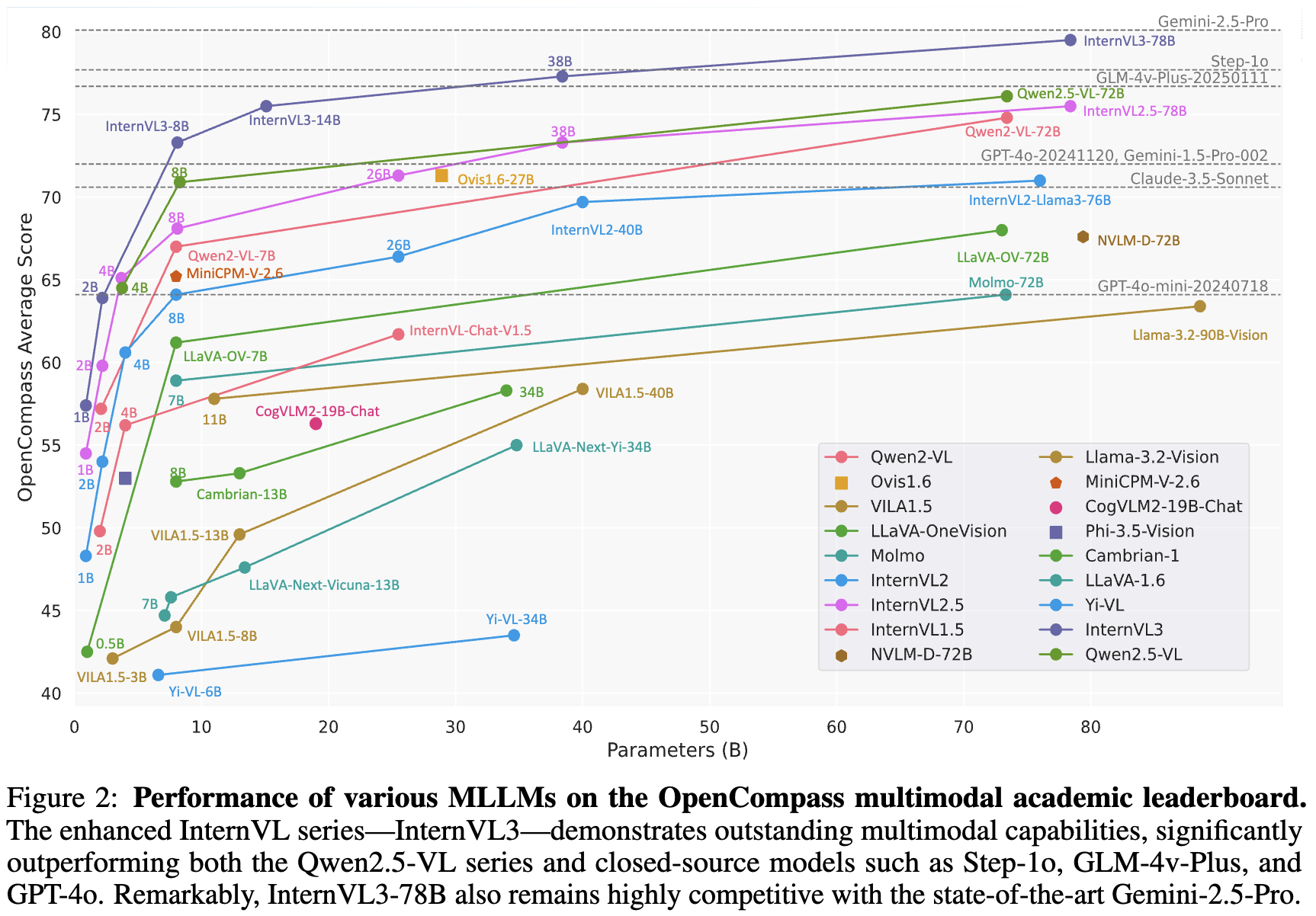
-
Dataset + Model 모두 공개
2. InternVL3
2.1 Model Architecture
- Initial Weight
- Vision encoder: InterViT (300M/6B)
- LLM: Qwen2.5 series or InternLM3-8B (not instruction tuned)
- MLP: random initialization

-
Viariable Visual Position Encoding
-
Visual token의 position encoding 시에 1보다 작은 $\delta<1$만큼 increment하여 encoding하는 기법
-
Position window를 확장하여 긴 multimodal context를 핸들링할 수 있게됨
-
tokens
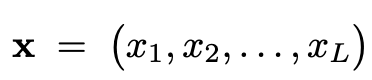
- $x_i$: text or visual token
-
position index (for any tokens)
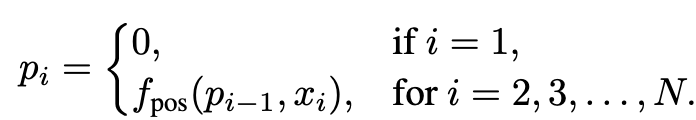

-
같은 이미지 내에서는 $\delta$ 값이 고정

-
-
2.2 Native Multimodal Pre-Training
-
기존에 Pretraining + finetuning을 분리했는데 이를 통합하여 pretraining부터 LLM + Vision + MLP 동시에 학습함
-
Multimodal Autoregressive Formulation
-
Original loss

-
text token에 대해서만 loss를 부여함
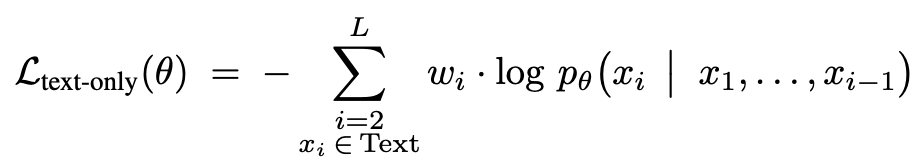

-
-
Joint Parameter Optimization
-
Full-finetuning 진행
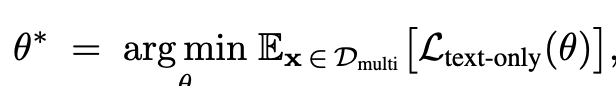
-
-
Data
- Language-only : Multimodal = 1:3 ratio가 제일 최적의 성능을 도출함을 실험적으로 밝힘
- SFT: 2.5 $\to$ 3.0 : 16.3M $\to$ 21.7M
- MPO: 300K
2.3 Post-Training
-
InternVL-2.5 대비 좋아진 것은 학습 데이터 뿐임
- tool use, 3D scene understanding, GUI operations, long context tasks, video understanding, scientific diagrams
-
Mixed Precision Optimization
-
Teacher forcing으로 이전 step의 GT를 보고 예측하는 학습과정과 달리, 전체 token을 예측하는 추론과정간의 괴리로 인해 CoT결과가 안좋다. 이를 해결코자 InternVL-2.5-MPO에서 MPO loss를 제안
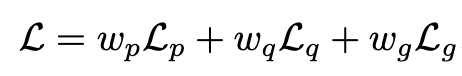
- $L_p$: DPO loss (preference loss). chosen response ($y_c$)의 확률은 높게, rejected response ($y_r$)의 확률은 낮아지게 학습
- $L_q$: BCO loss (Binary Classification loss). 절대적인 quality를 측정하는 이진분류기의 score를 기준으로 loss를 메겨 학습
- $\delta$: reweard shift로, 이전 reward의 moving average를 사용. 학습의 안정성이 목적
- $L_g$: Generation loss. 기존의 NTP loss와 동일
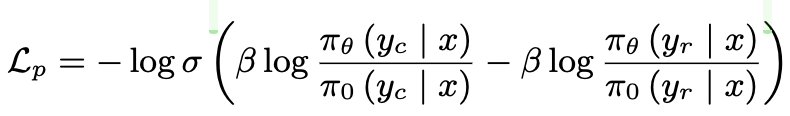
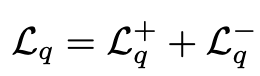
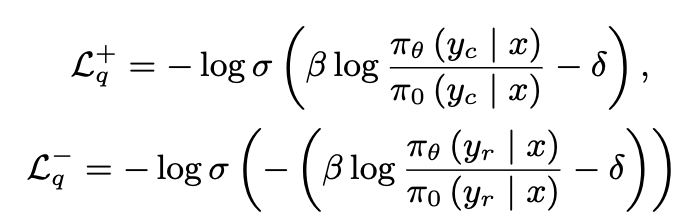
-
2.4 Test-Time Scaling
-
Best-of-N evaluation 전략 사용
-
Critic 모델: VisualPRM (Visual Process Reward Model-8B)
-
매 i번째 step마다 주어진 solution(prediction)에 대해 quality score를 산출함
-
전체 step의 평균으로 해당 solution의 quality score를 계산함.
-
Multi-turn 방식으로 구성됨
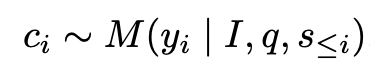
- $c_i$: i번째 step이 correct이면 +, incorrect면 -를 산출
-
-
Data: VisualPRM400K dataset로 학습
-
2.5 Infrastructure
- InternEVO framework로 학습하여, 2.5보다 50~200% 학습 속도 향상
- data, model, pipeline등을 병렬처리
3. Experiments
- VLMEvalKit를 기반으려 평가를 진행
3.1 vs. Other MLLMs
3.2 Multimodal Reasoning & Mathematics
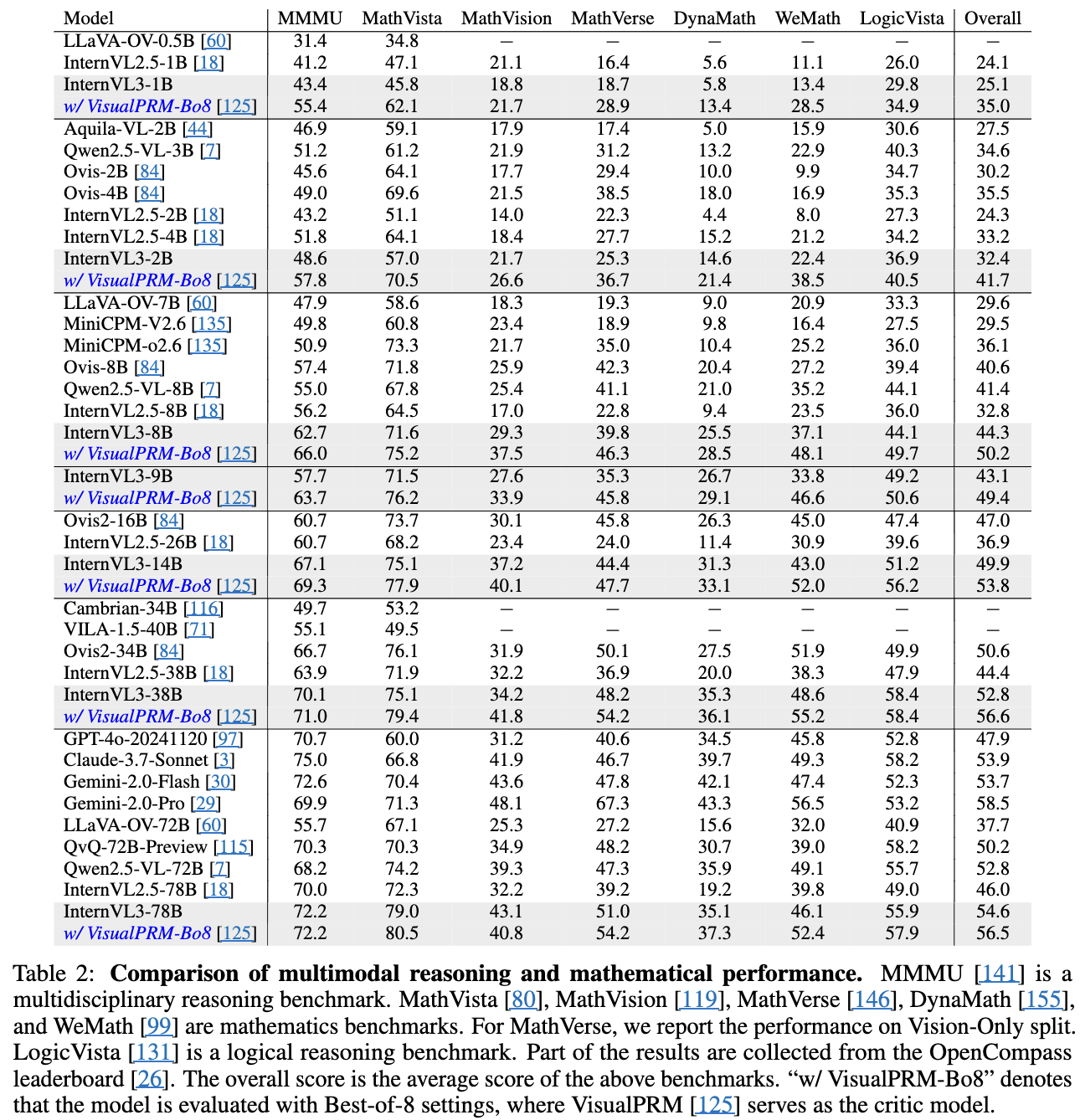
3.3 OCR, Chart, Document Understanding

- Qwen2.5VL에 비해 InternVL3가 더 안좋은데..?
3.4 Multi-Image Understanding
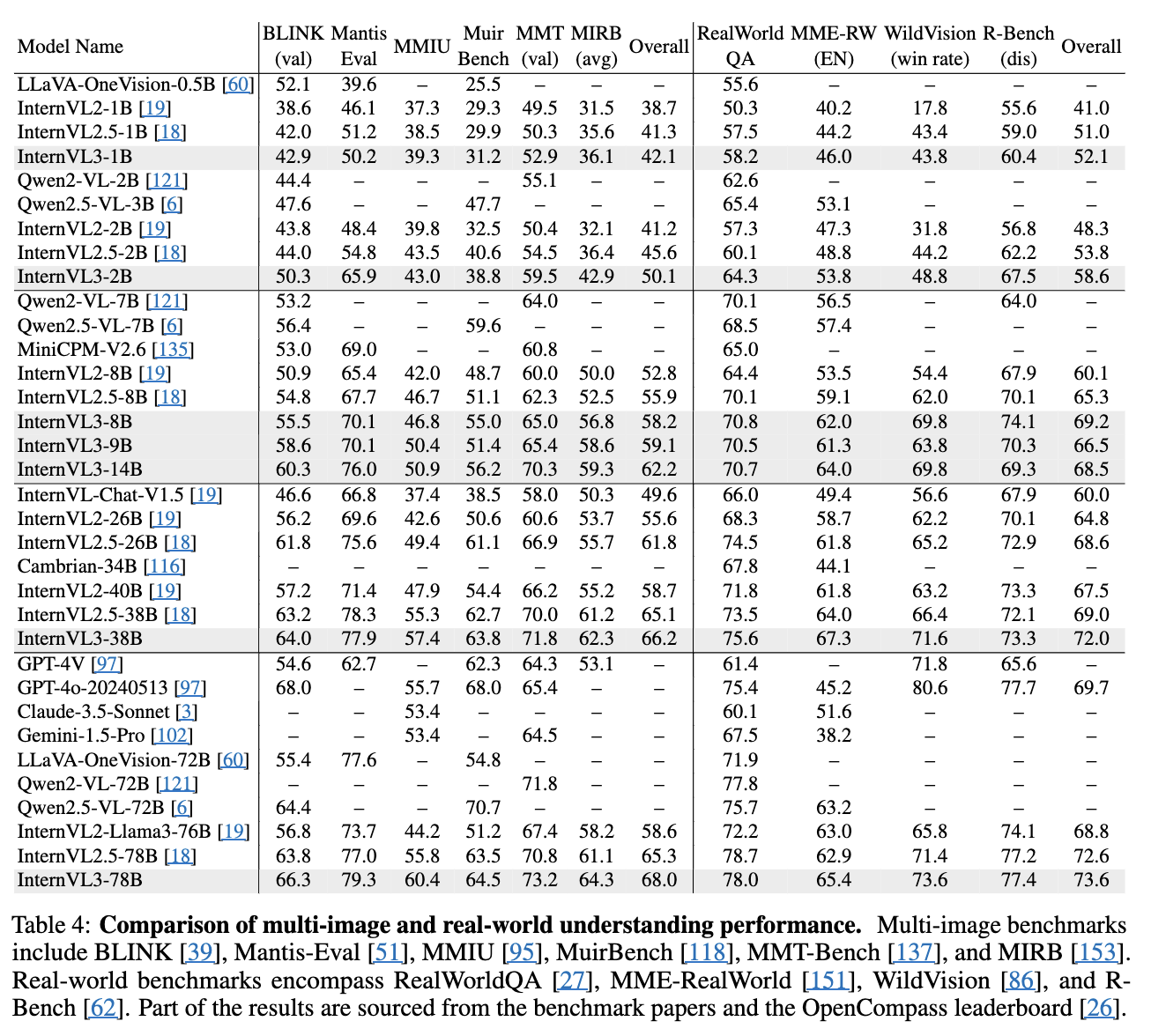
- Qwen2.5VL에 비해 InternVL3가 더 안좋은데..?
3.5 Real-World Comprehension
3.6 Comprehensive Multimodal Evaluation
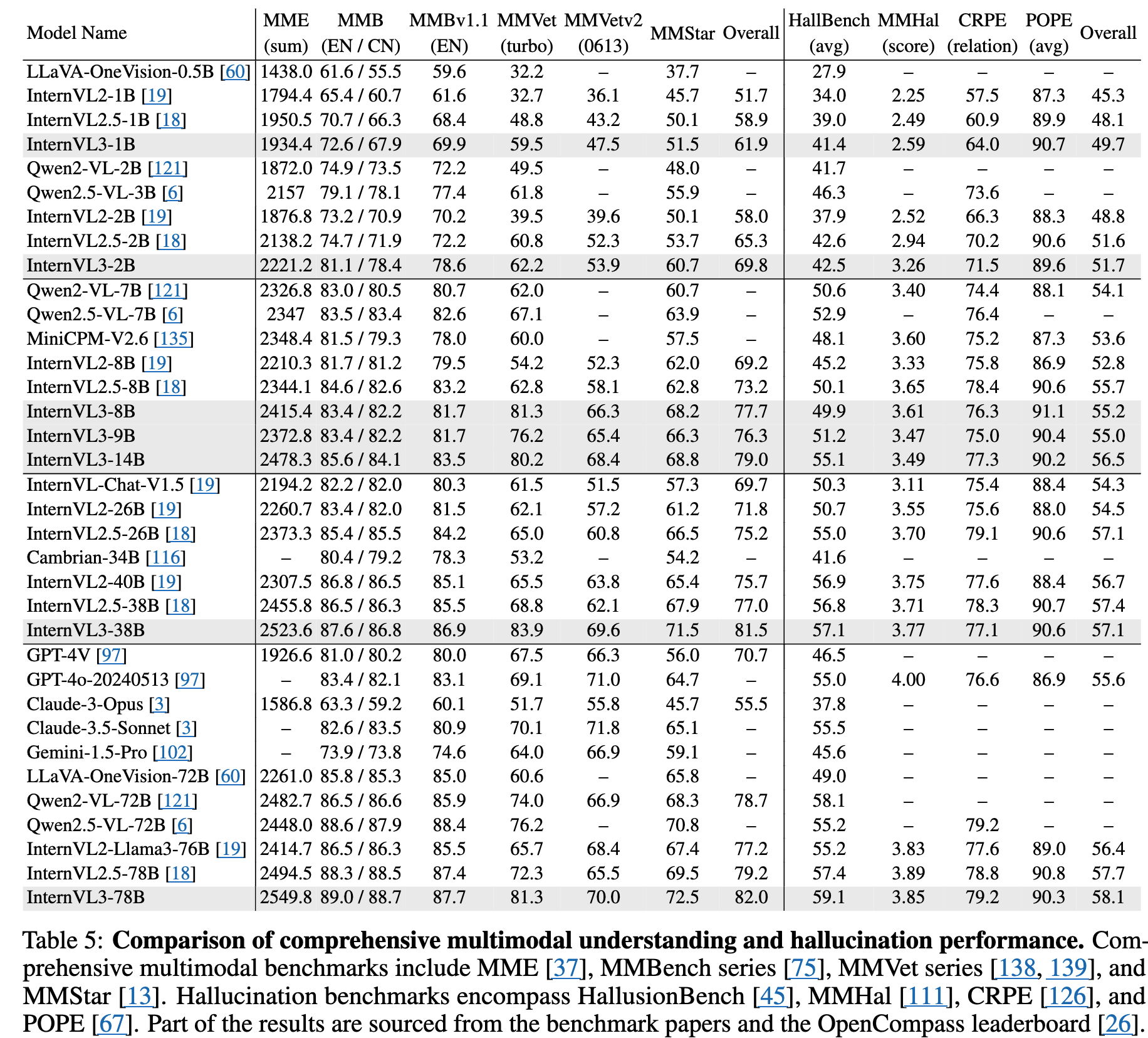
3.7 Multimodal Hallucination Evaluation
3.8 Visual Grounding
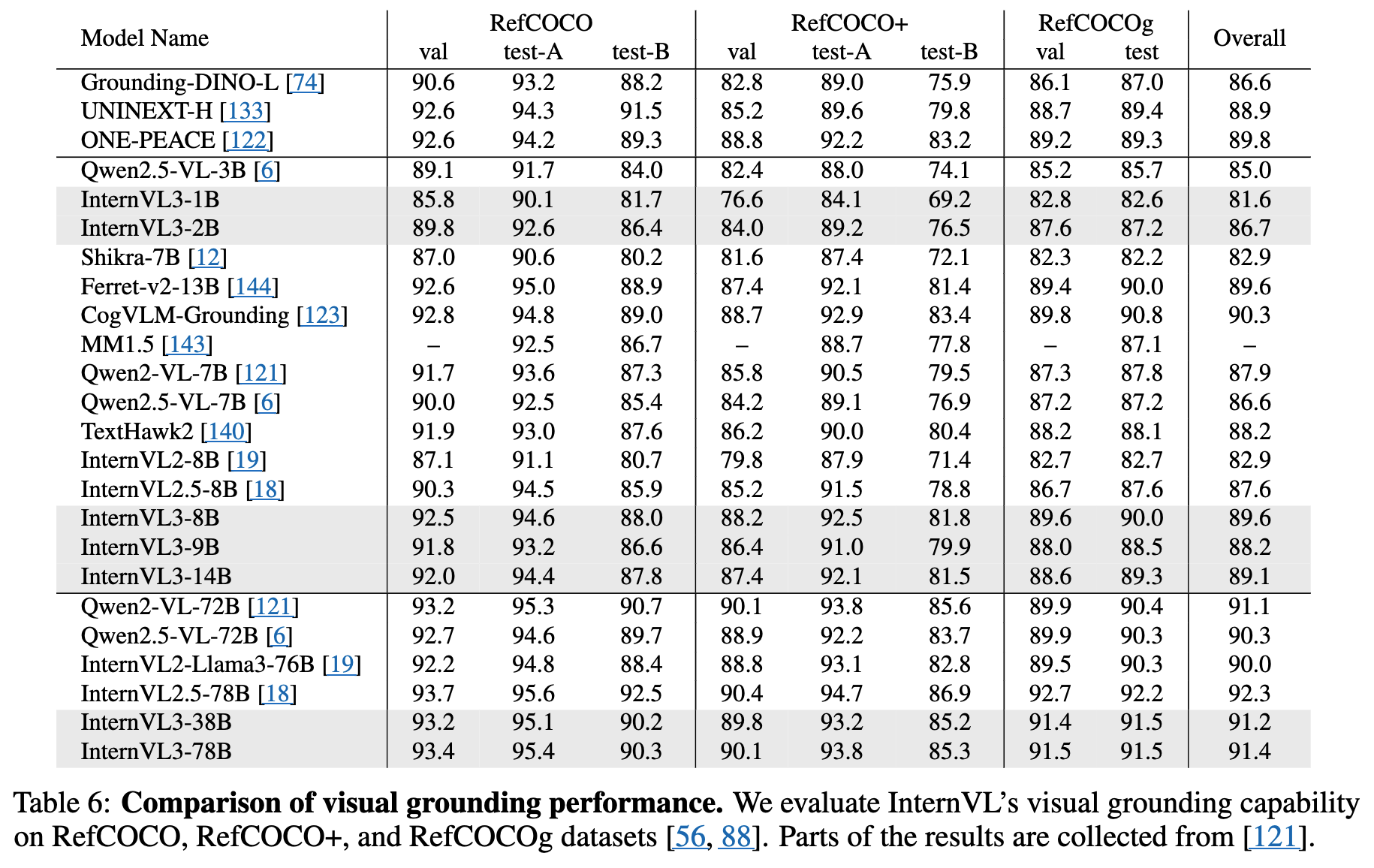
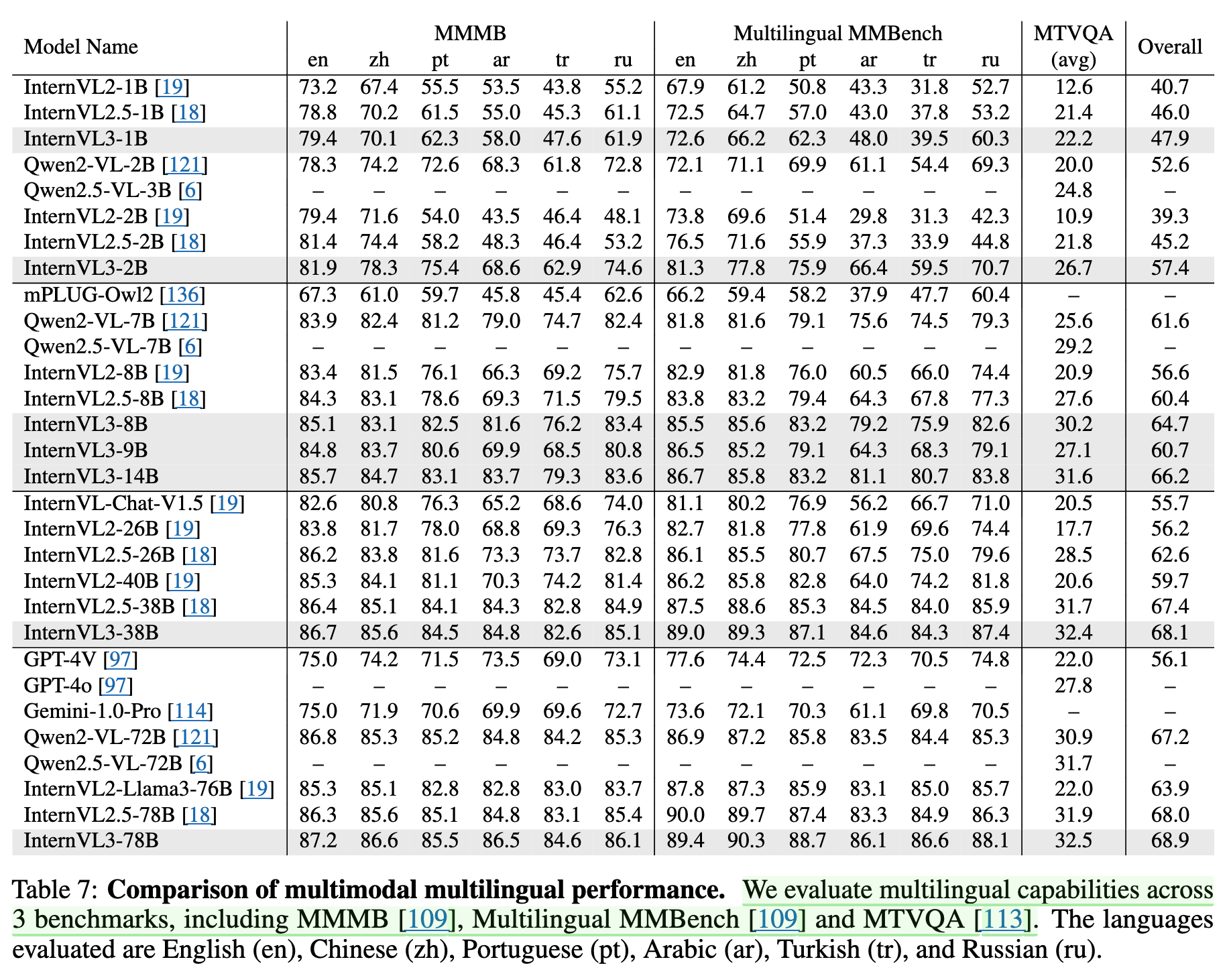
3.9 Multimodal Multilingual Understanding
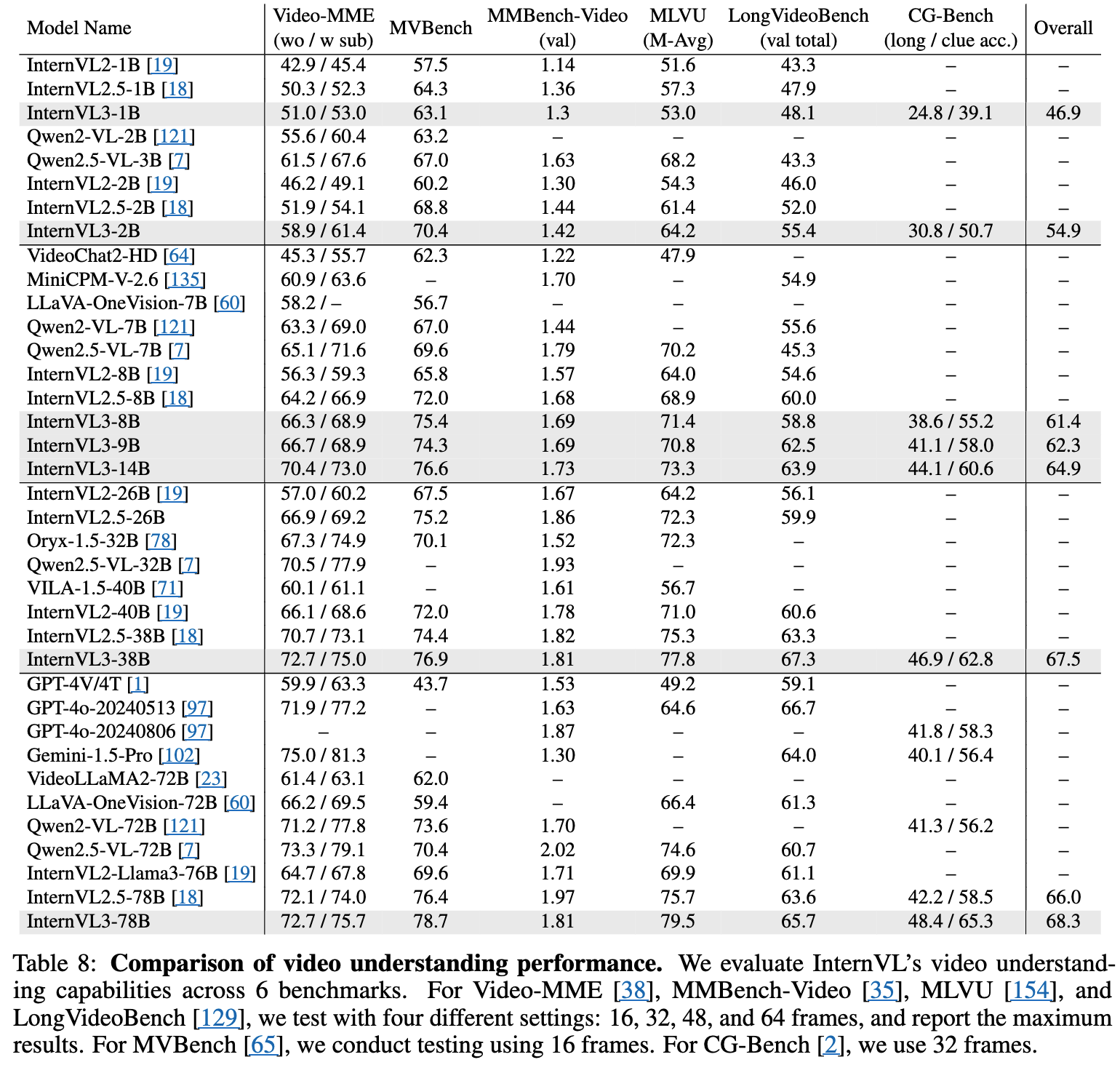
3.10 Video Understanding
3.11 GUI Grounding

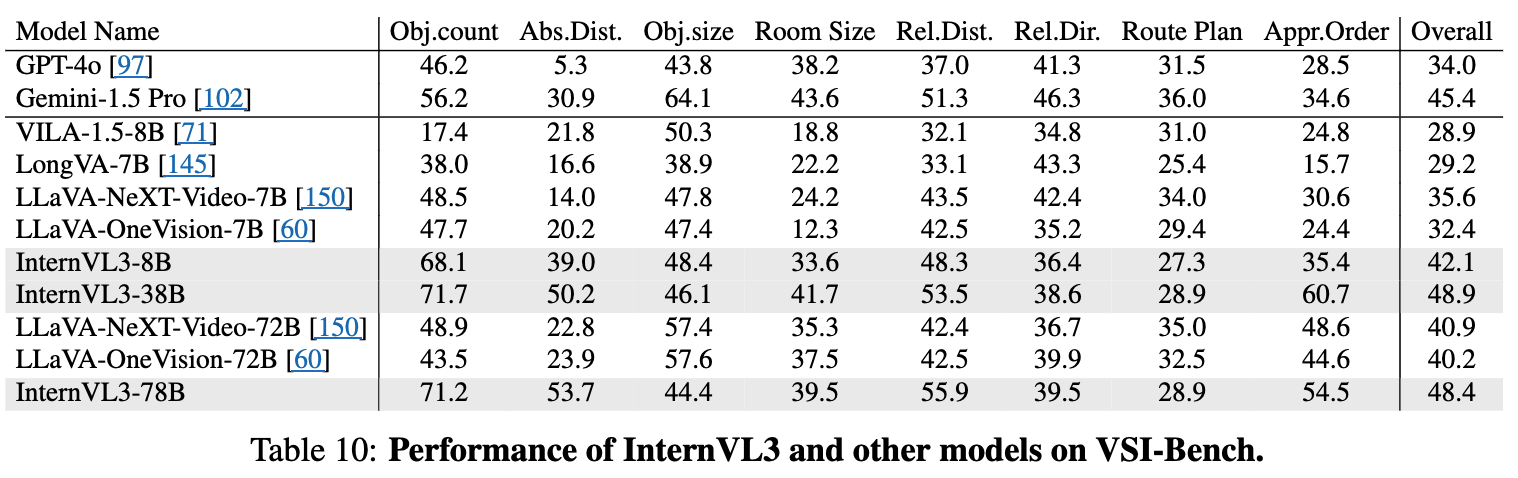
3.12 Spatial Reasoning
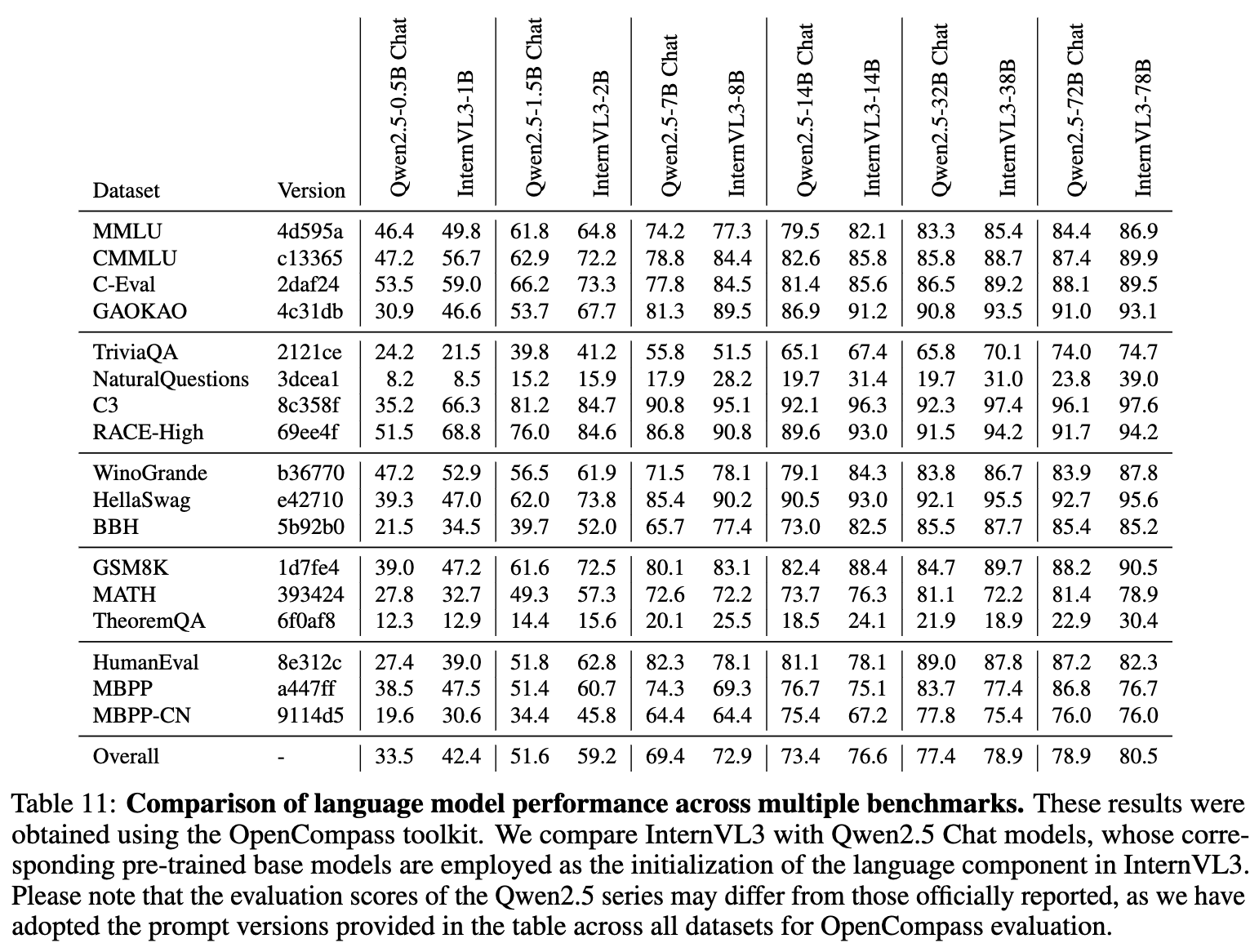
3.13 Evaluation on Language Capability
3.14 Ablation Study
-
Multimodal Pretraining 유무에 따른 성능비교
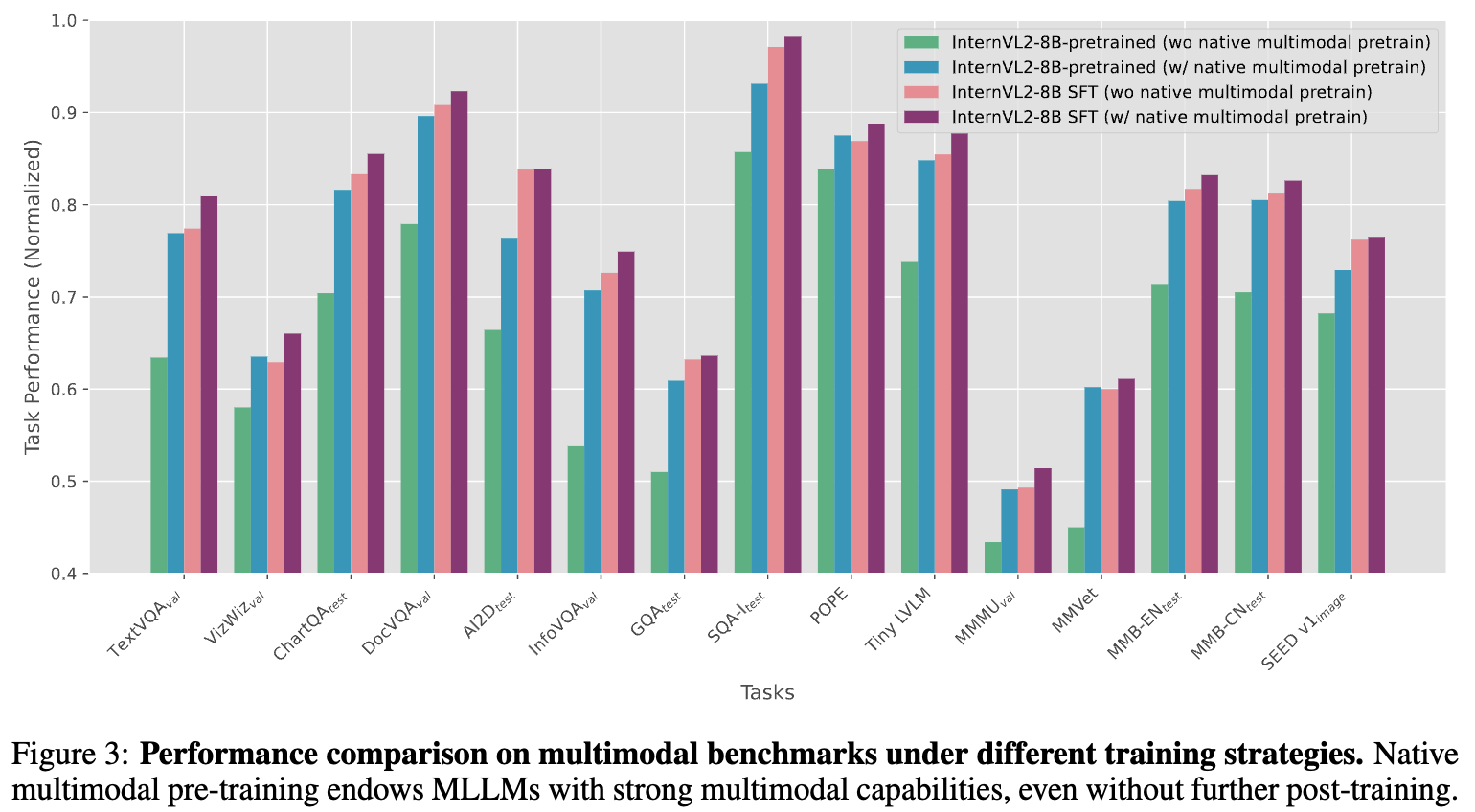
-
V2PE 유무에 따른 성능비교
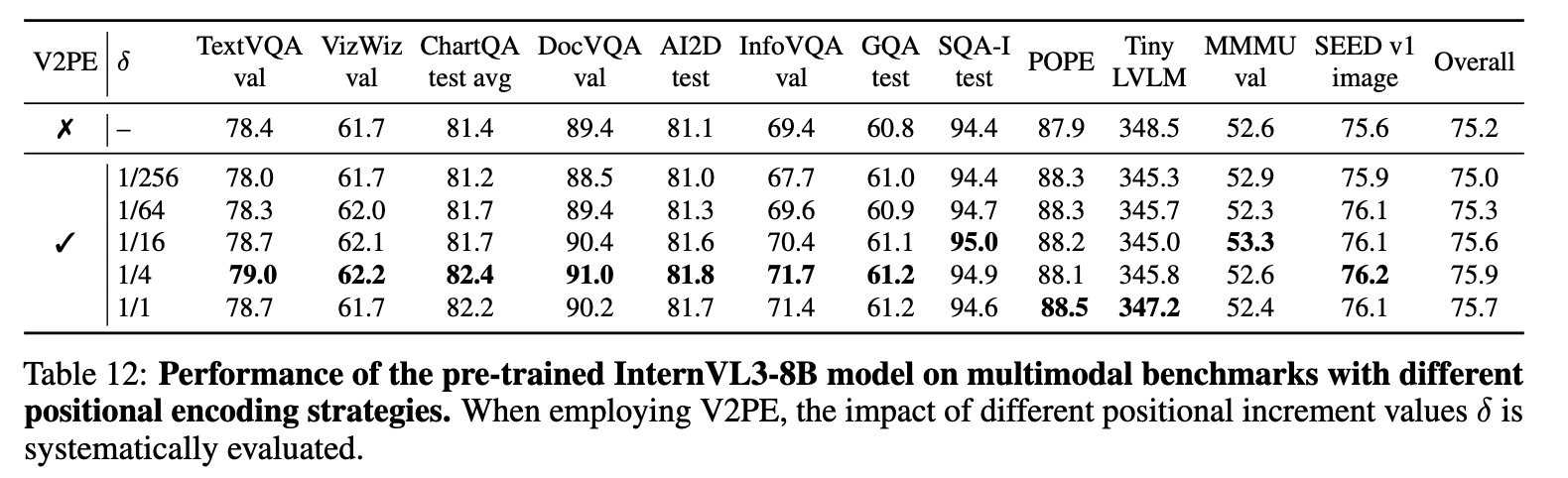
-
MPO 유무에 따른 성능비교