Glm 4.1v
[MM] GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
- paper: https://arxiv.org/pdf/2507.01006
- github: https://github.com/zai-org/GLM-4.1V-Thinking
- archived (인용수: 1회, ‘25-07-30 기준)
- downstream task: General VQA, STEM, OCR & Chart, Long Document, Visual Grounding, GUI Agent, Coding, Video Understanding
1. Motivation
-
Open-source community에서 multimodal reasoning model에 대한 연구가 부족했음
$\to$ MLLM의 reasoning 가능한 scalable RL framework를 제안해보자!
2. Contribution
-
General-Purpose Multimodal reasoning VLM, GLM-4.1V-Thinking을 제안함
- reasoning 중심의 framework
-
Pretrained foundation model GLM-4.1V-9B-Base, reasoning model GLM-4.1V-Thinking, 그리고 domain specific한 reward system을 공개함
-
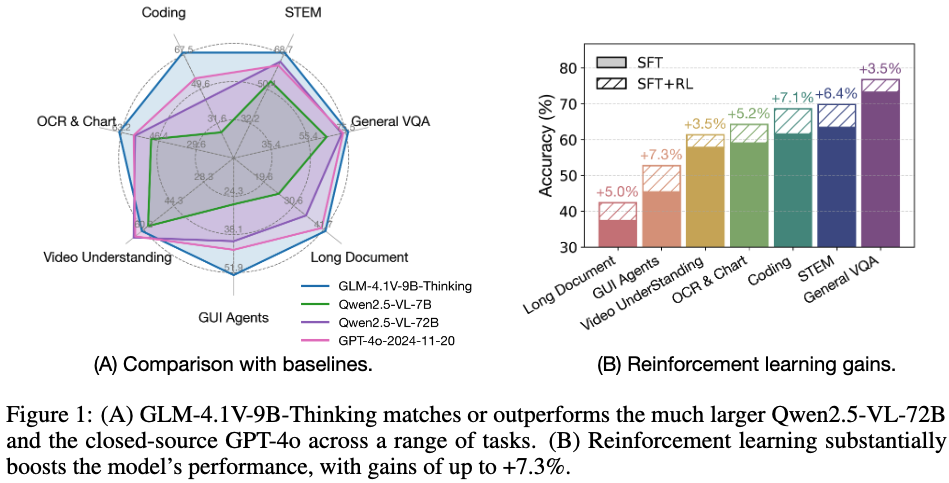
GLM-4.1V-9B-Thinking은 다양한 domain에서 SOTA 성능을 냄
3. GLM-4.1V
-
Overview

-
video input
- Qwen2-VL과 비슷하게 2D conv $\to$ video의 경우 3D conv로 변경하여 temporal downsampling
-
position embedding
-
$H_p \times W_p$로 normalize하여 patch의 grid를 sampling
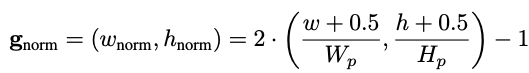
-
Bicubic interpolation 함수를 사용하여 adapted embedding $P_{adapted}$를 계산
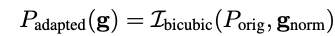
-
-
3.1 Pretraining
-
학계의 corpa, knowledge-rich, interleaved image-text data, 그리고 pure text data를 사용함.
-
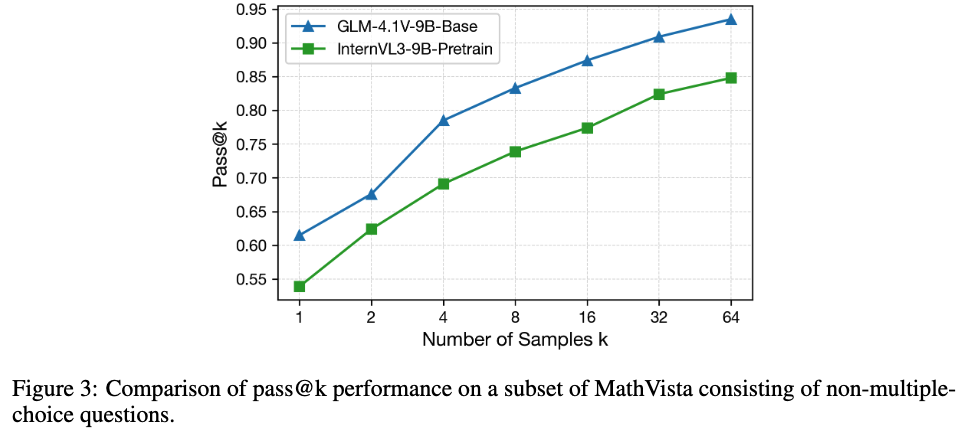
Base 모델의 MathVista passk 성능이 제일 좋음
3.1.1 Pre-training Data
-
Image Caption data
-
inital pool: 10B image-text pairs
- source
- public data: LAION, DataComp, DFN, Wukong
- web search engine
- source
-
Filtering
-
Heuristic-based filtering: 매우 저품딜 이미지 (minimum 이미지 해상도보다 작은 경우, solid color인 경우, caption length 제한보다 크거나 작은 경우, image-level dedeuplication)
-
Relevance Filtering: Clip score 0.3보다 낮은 pair는 제외
-
Concept balanced resampling: MetaCLIP처럼 visual concept에서 vocabulary rich한 proper noun일 경우, re-weight하여 balance를 맞추는 전략으로 web-scale data의 long-tail distribution 문제를 해결
-
Factual-centered recaptioning model: noisy caption을 정제하는 모델로 caption수정
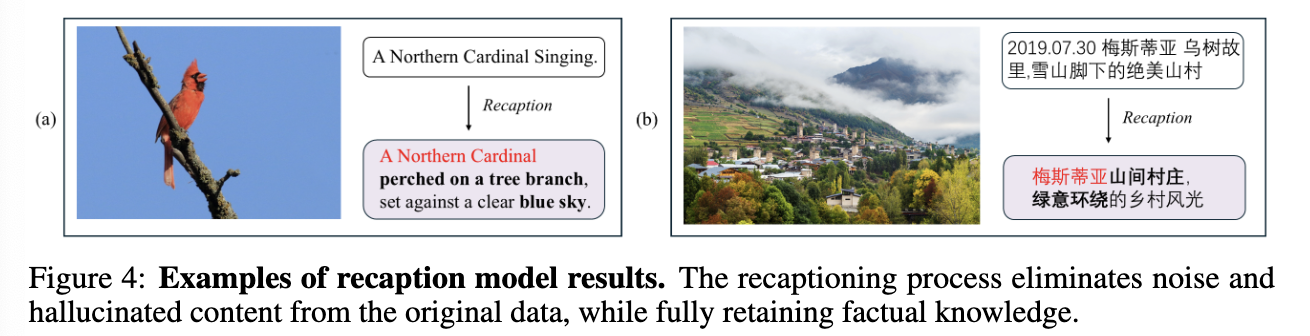
$\to$ 정제된 버전 + original 버전 섞어서 활용함으로써 world knowledge & descriptive depth 균형을 맞춤
-
-
-
Interleaved image-text data
- source: web page & books
- 원천 데이터는 image와 무관한 정보가 매우 많으므로 정제가 필요.
- web data processing pipeline
- CLIP-score threshold기준으로 filtering
- QR-code, advertisement는 해당 image classifier로 정제
- high density image & sparse textual content (ex. photo albums) 는 제외
- high-information-value content를 위해 “high-knowledge-density” image classifier 모델을 학습하여, 해당 이미지를 우선순위로 둠 (ex. academic charts, scientific illustrations, engineering schematics, instructional diagrams, maps, etc)
- academic book processing pipeline
- 100m digital books 활용
- PDF parsing tool활용함
- web data processing pipeline
-
OCR data
- source data: 220m images
- synthetic document images: 다양한 font, size, color, orientation을 corpora에서 render하여 LAION 데이터셋에서 다양한 background로 만들어냄.
- natural scene text images: text & bbox를 Paddle-OCR를 활용하여 추출함. 최소 1개이상의 bbox있는 valid image만 사용
- academic documents: LaTex source code를 LaTeXML tool를 활용하여 HTML format 변경, 이후 markup lanugage로 변경함. 이를 PDF page break 정보를 활용하여 rasterize.
- source data: 220m images
-
Grounding data
- natural image: LAION-115M 데이터를 GLIPv2 model를 활용하여 image의 caption을 추출하고, noun에 대해 bbox를 추출함. 최소 2개이상의 valid bbox를 갖는 이미지만 추출. $\to$ 40M
- GUI grounding: CommonCrawl snapshot & web screenshot을 가지고 Playwright framework로 interact하여 visible DOM element도 추출함. (bbox)
- Referrence Expression Generation / Comprehension 140M Question-Answer pair를 생성
-
Video data
- fine-grained human annotation을 pipeline에 추가 (human-in-the-loop workflow)
- key cinematic elements (camera motion, shot composition 등)을 추가
- text, image embedding 유사도를 통해 deduplication 전략도 추가
-
Instruction tuning data
- task coverage & taxanomy: domain의 semantic structure & task objective를 고려하여 prompt을 변경할때 사용. (category-specific preprocessing & balancing sampling 전략에 활용)
- complex scenario augmentation: 인위적으로 생성한 데이터 (구조적 제약)로 GUI interaction, long-document comprehension 등에 활용
- data contamination check: public eval benchmark에 leakage check
$\to$ 다양한 domian의 50million samples 취득 (general perceptual understanding, multimodal reasoning, document-intensive context, GUI agent operations, UI coding)
3.1.2 Training Recipe (Pre-training)
- multimodal pre-training
- video data제외하고 학습
- max token: 8,192
- batch size: 1,536
- steps: 120K
- Long-context continual training
- 목적: 고해상도 이미지/비디오/등을 처리하기 위해 continual training stage를 추가
- max token: 32,768
- batch size: 1,536
- step: 10K
3.2 Supervised Fine-Tuning
- SFT를 바라보는 관점: Next step RL을 안정적이고, 효율적으로 학습하기 위한 bridge 역할
3.2.1 Supervised Fine-Tuning Data
-
Data Composition
- 검증 가능한 task (STEM, etc) 위주로 구성
- 검증 불가능한 task도 추가 (open-ended QA)
-
Response Formatting
- think: reflection, backtracking, retrying, 그리고 verification을 하는 부분
-
answer: 특수 토큰 ( .. )로 감쌓도록 훈련하며, bbox의 경우 (<begin_of_box >..< end_of_box >)로 감쌓이도록 훈련
-
Response curation
- cold start data의 quality가 매우 중요함. quality가 떨어지면 학습이 불안정하고, 발산하기도 함
- 엄밀한 data cleaning pipeline을 설계해야함
- mixed-language (영어+중국어) 혹은 redundunt한 thought pattern은 fitering
-
Iterative data enhancement
- RL checkpoint로 informative example를 sampling하여 cold-start data에 추가하여 SFT. 무한반복.
- RL학습중에 발견한 usful reasoning pattern에 model이 노출되도록 함
3.2.2 Training Recipe
-
Full finetuning 기반.
-
Text-only long-form examples를 통해 language understanding & 일반적인 reasoning ability 향상
ex. multi-turn conversation, agent planning, instruction following
-
cold-start data에 noisy reasoning이 있더라고, 연속적인 RL 학습에 효과적임 (?)
3.3 Reinforcement Learning: Whats Challenging and What Works
-
Reward System
-
RL with Verifiable Reward (RLVR) : STEM처럼 정답이 명확하여 reward 주기 좋은 경우 사용
- rollout output로부터 answer를 추출하여 reference answer와 exact match 수행하여 0/1 binary reward 제공
-
RL with Human Feedback (RLHF): model-based Reward를 제공
- rollout output을 그대로 reward model에 제공하여 reward를 계산
-
여러 domain을 통합해 학습할 때, 1개의 reward 시스템이라도 안좋으면 전체 성능을 깎아먹음 $\to$ 잘 tuning된 reward 시스템이 매우 중요.
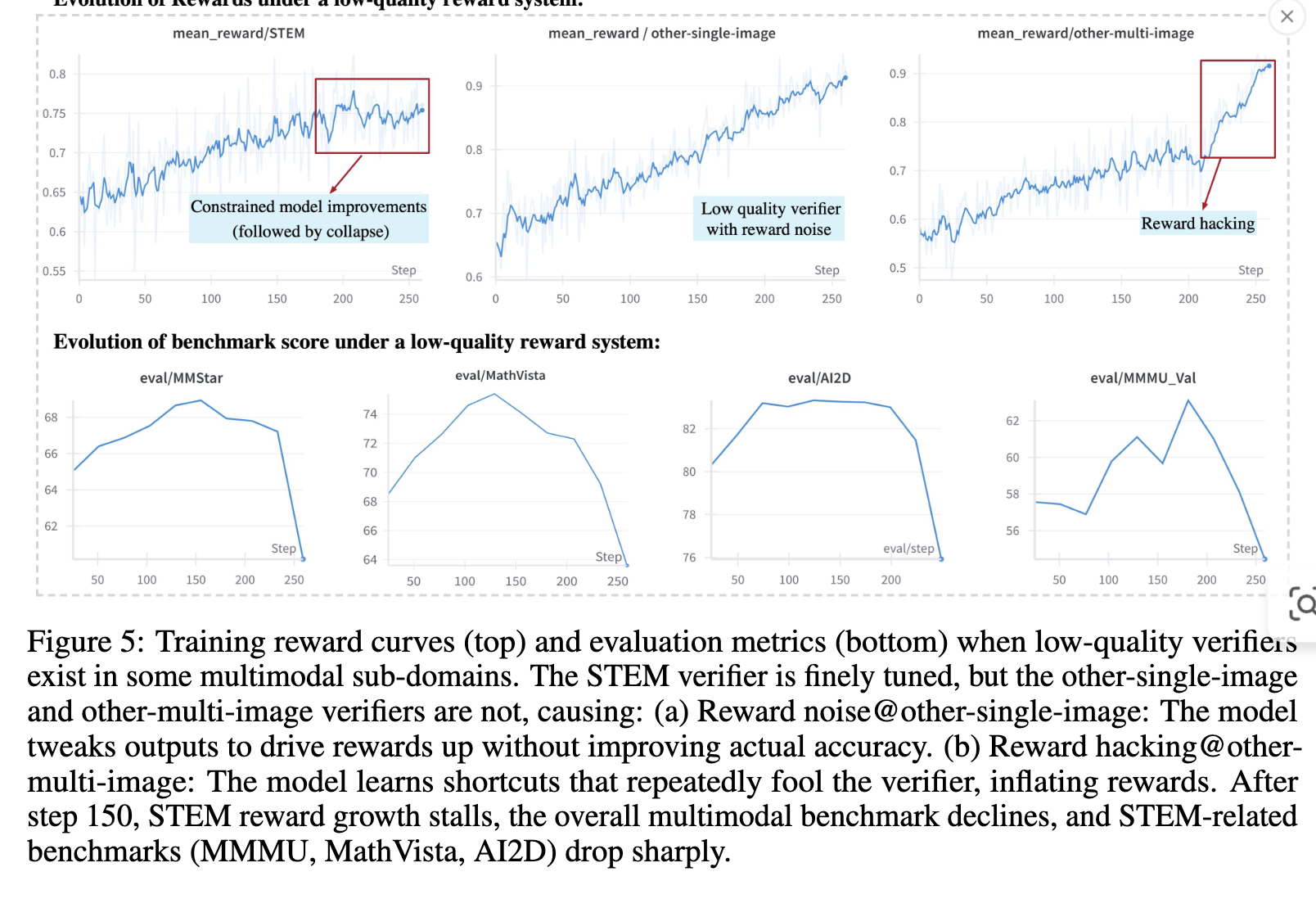
-
정교한 reward의 중요성
ex. “a correct number from 0 to 10”, “a velocity very close to the speed of light”이라고 모호하게 답변하여, LLM reward hacking하는 사례
-
-
Domain specific reward 시스템
- “43” vs. “43.0”
- ocr에서는 서로 다른 결과임
- math problem에서는 같은 결과임
- branching workflow, functional evaluations, model-based judgement (w/ custom judge prompt & hyperparameters)
- “43” vs. “43.0”
-
Shared reward system
- format checking:
, <|begin_of_box|> 에 정답이 감싸여 있는가로 reward 여부를 판단 - style checking: 영어/중국어가 동시 사용되었는가? 혹은 larger block이 반복되는가? 여부로 reward를 판단
- format checking:
-
각 subdomain별 reward verifiers를 둠 (공개)
-
-
Data preparation
-
task identification
-
broad coverage되도록 domain을 선정하며, 각 subdomain별로 RLVR / RLHF 둘중 뭐가 suitable한지 결정하여 data curation
ex. video captioning $\to$ open-ended. temporal grounding이 clear correctness judgement에 좋음
-
-
data curation
-
question-answer pair를 생성하여, verifier가 명확한 답에 대해 reward 줄수 있도록 구현
ex. multiple choice question & answering $\to$ fill-in-the-blank format
-
-
quality validation and offline difficulty grading
- thorough correctness check를 거침 (자세한건 생략됨)
- 기존의 RL model의 pass@k evaluation를 통해, 기존 모델들이 얼마나 틀리는지를 파악해서 difficultiy를 파악함
- 해당 pass@k 결과와 함께 human dfficulity label을 활용하여 difficulity를 grading
-
-
Training
-
GRPO인 경우, group sampling된 결과가 모두 win이면, reward 산출이 안됨 $\to$ valid batch size 줄어듦.
-
RL with Curriculum Sampling (RLCS)를 제안하여, 처음에는 쉬운 task부터 선별하고 점차 어려운 task 선별하기 위해 개별 sample마다 pass@k evaluations를 prior RL model로 수행하여 추출하고, human annotation도 활용함
-
해당 difficulty를 참고하여 sampling re-weighting함
-
너무 쉬운 task / 너무 어려운 task는 downsampling하고 적당히 어려운 task만 추출해서 valid batch size를 키움. $\to$ 학습 속도 효율뿐 아니라, 성능도 올라가더라.
-
Improving Effectiveness
-
Large batch size를 기반으로 해야 성능도 좋음
-
GRPO에서 전체 group의 결과가 correct면 해당 sample은 useful gradient를 못뽑음
$\to$ oversampling ratio를 EMA로 dynamic하게 조절하는 방안을 제안 $expansion_ratio=\frac{1}{1-not_valid_sample_rate}$ 즉, 더 많이 rollout을 해보면, 더 높은 확률로 valid sample이 뽑힐수 있으니까 많이 뽑아보자는 말임
-
Forcing Answer
- 긴 정답의 경우, 중간 reasoning이 valid한데 truncation되어, reward를 0으로 잘못 산정되는 경우가 존재함.
- </think> 뒤에
token이 강제로 오도록 함으로써 해결
-
Discard KL Loss: Multimodal인 경우, text에 비해 비효율적이라 제거함.
-
Clip higher: importance sampling ratio의 clipping boundary를 높이면 성능 향상에 좋음
- importance sampling ratio: Offline으로 데이터를 수집한 행동 정책과 현재 학습하려는 목표 정책 간의 확률 분포 차이를 보정하기 위해 사용되는 가중치
+$\alpha$
- RL phase의 peak performance와 initial performance간의 상관관계가 없었음.
- RL 학습 결과가 cross-domain generalization 성능이 (sft보다) 좋았음
-
-
Improving Stability
- Quality of cold-start SFT: thinking path에 무의미한게 많으면 학습 안정성이 떨어짐
- Entorpy loss를 주어 다양성을 학습하려했으나, 학습 안정성을 헤침
- 일반적인 (0.9) 것보다 randomness를 높이는 방식 (rollout hyperparameter인 $top_p$=1)이 학습 성능에 좋았음
- per-sample / per-token average는 큰 차이를 안보임
- 비록 format reward가 있어 학습이 가능할 지라도, cold-start에서 이미 format output은 학습이 되었어야 RL의 학습 안정성이 좋음
-
-
-
4. Experiments
-
Evaluation benchmark
- General VQA: MMBench-V1.1, MMStar, BLINK, MUIRBENCH
- STEM: MMMU, MMMU-Pro, VideoMMMU, MathVista, WeMath, AI2D
- OCR & Chart: OCRBench, ChartQAPro, ChartMuseum
- Long Document: MMLongBench-Doc
- Visual Grounding: RefCOCO-avg (val)
- GUI Agents: OSWorld, Android World, WebVoyager Some, Webquest-QA
- Coding: Design2Code, Flame-VLM-Code
- Video Understanding: VideoMME, MMVU, LVBench, MotionBench
-
결과
-
정량적 결과
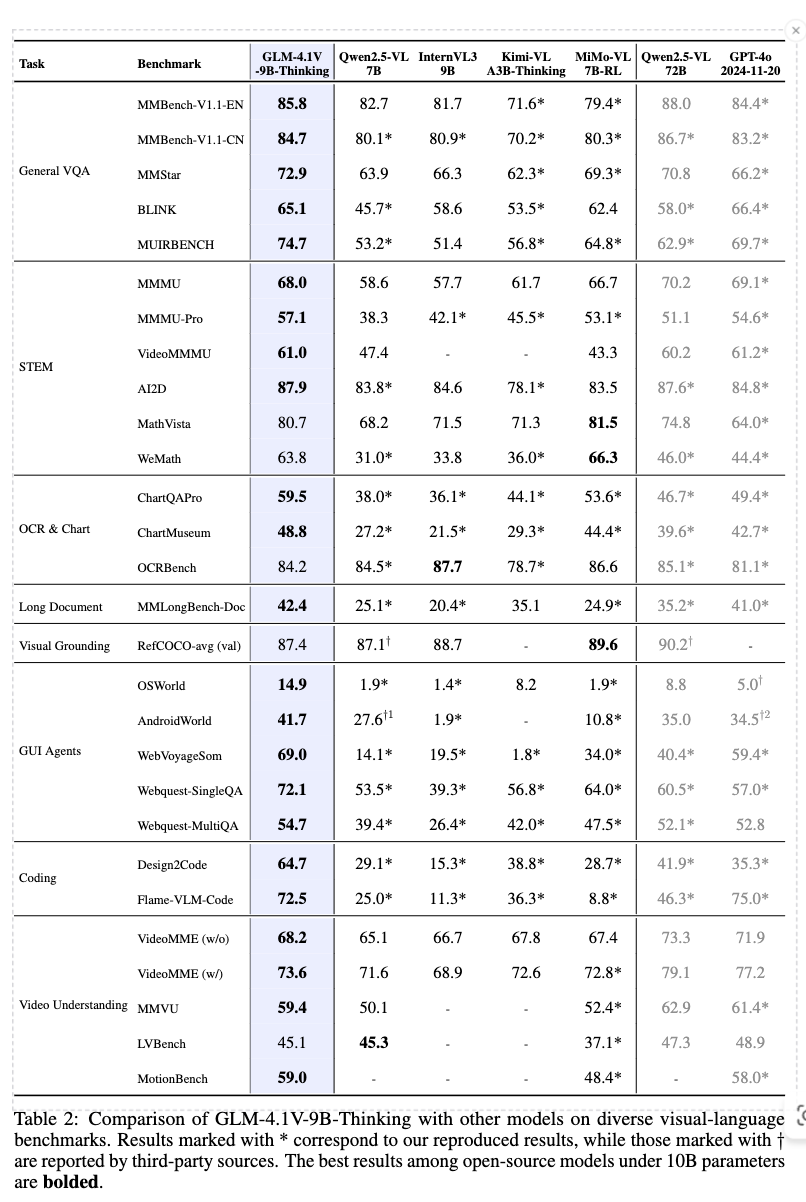
-
-
Ablation Studies
-
Cross-domain 성능 향상폭
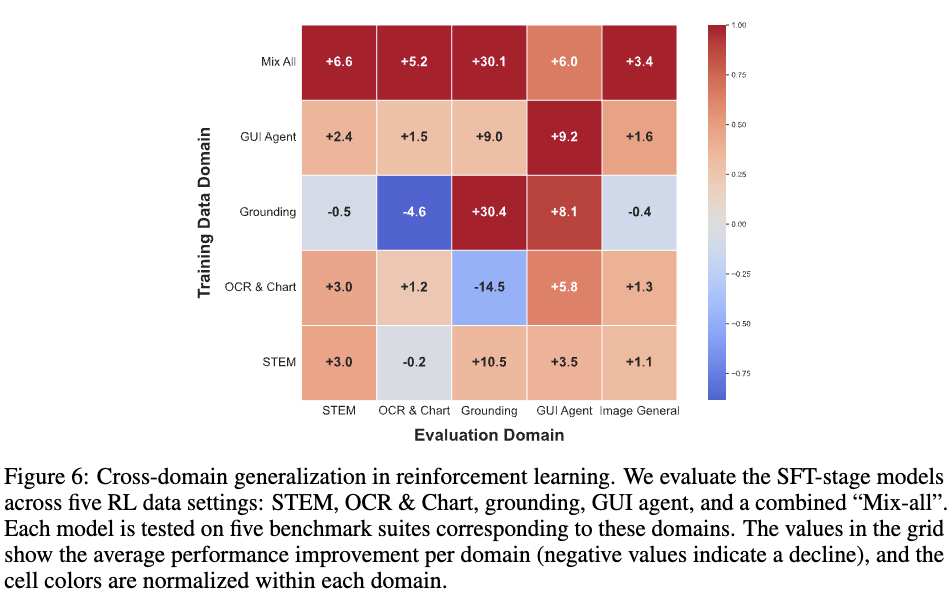
- 1열: Mix-All이 sft방식보다 rl학습 후 향상된 정도가 전 domain에서 골고루 향상됨
- 2열: GUI agent RL만 학습한게 GUI domain에서는 제일 좋았음. 단, Grounding 및 OCR & Chart 성능도 좋아지는걸로 미루어 3 domain의 연관성이 높음을 알수 있음
-