[Retrieval] FinMTEB: Finance Massive Text Embedding Benchmark
[Retrieval] FinMTEB: Finance Massive Text Embedding Benchmark
- paper: https://arxiv.org/pdf/2502.10990
- github: https://github.com/yixuantt/FinMTEB
- EMNLP 2025 accepted (인용수: 10회, ‘25-10-03 기준)
- downstream task: Financial 도메인 특화 text embedding benchmark (STS, clustering, classification, retrieval, etc)
1. Motivation
-
금융 특화 adaptation이 LLM embedding 모델의 금융 응용 task에 도움이 될까?
- 동기 1. “liability(부채)” 금융 용어에서는 negative sentiment를 갖지만, 일반적인 용어로는 중립적인 sentiment를 포함함.
- 동기 2. BioMedical 분야의 BioMedLM, Financial 분야의 FinBERT의 domain specific한 모델들이 최적의 성능을 내고 있음. 그런 반면, opensource LLM기반 domain specific model이 없음
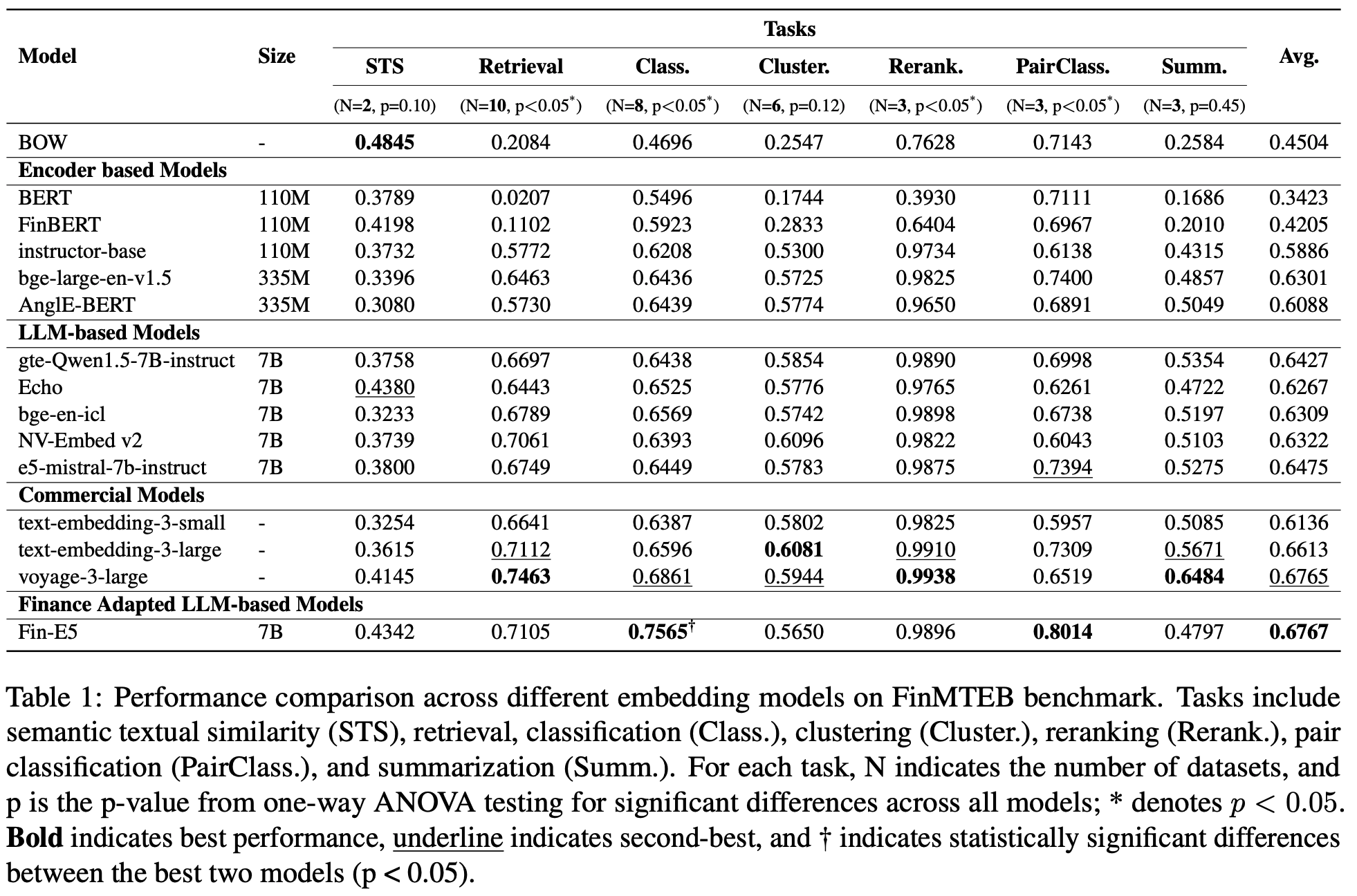
- 동기 3. 금융 NLP 도메인에 특화된 downstream task가 부재함. 일례로, 일반 NLP 도메인 (MTEB)에서 좋은 성능을 내는 모델이, Bag-of-Words (BoW)기반 검색 로직보다 FinMTEB STS task에서 성능이 나쁨 (Table 1 참고)
$\to$ Financial domain NLP task에 benchmark를 제안해보자!
2. Contribution
-
64개의 domain financial domain specific한 evaluation dataset FinMTEB를 제안함 (영어+중국어)
-
STS task
-
Retrieval task

-
Classification task
-
Clustering task
-
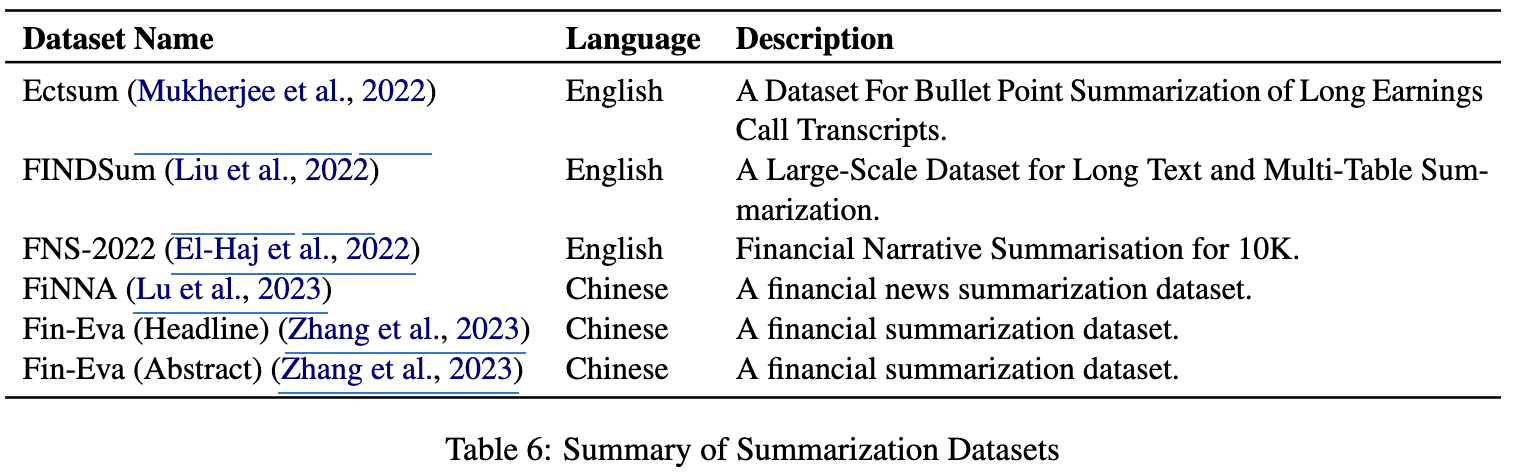
Summarization task
-
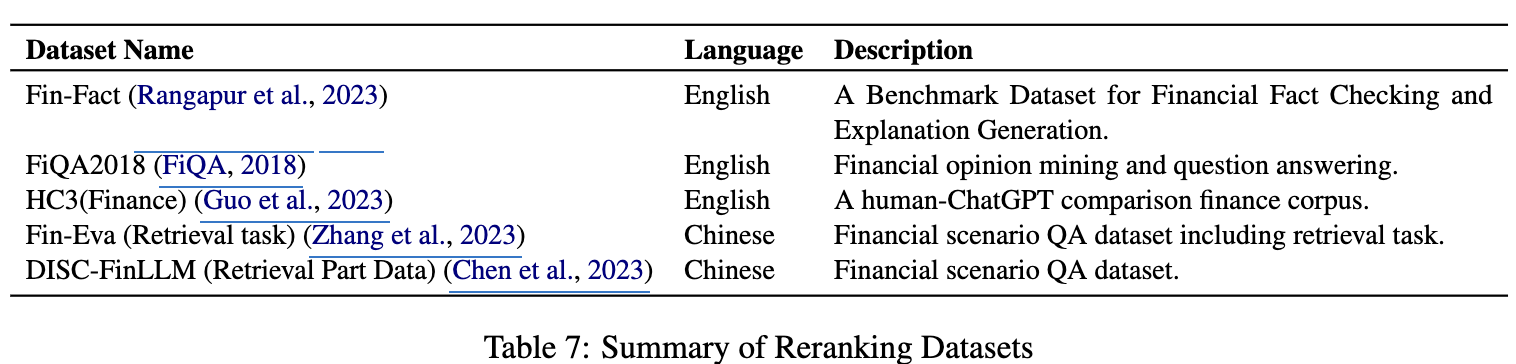
Reranking task
-
-
강력한 Baseline 모델인 Fin-E5를 제안함
- backbone LLM: e5-Mistral-7B-Instruct
- persona 기반의 prompt로 synthesized된 데이터로 학습
-
다양한 실험을 통해 3가지 통찰력을 제공함
- domain-specific LLM (ex. Fin-E5)가 일반 LLM embedding보다 성능이 좋음
- general domain의 성능은 domain specific 성능과 연관성이 낮음
- 전통적인 Bag-of-Words (BoW)방식이 STS task에서 dense embedding 모델을 기대치 않게 추월함. $\to$ 성능 향상해야할 영역임
3. FinMTEB
3.1 FinMTEB Tasks
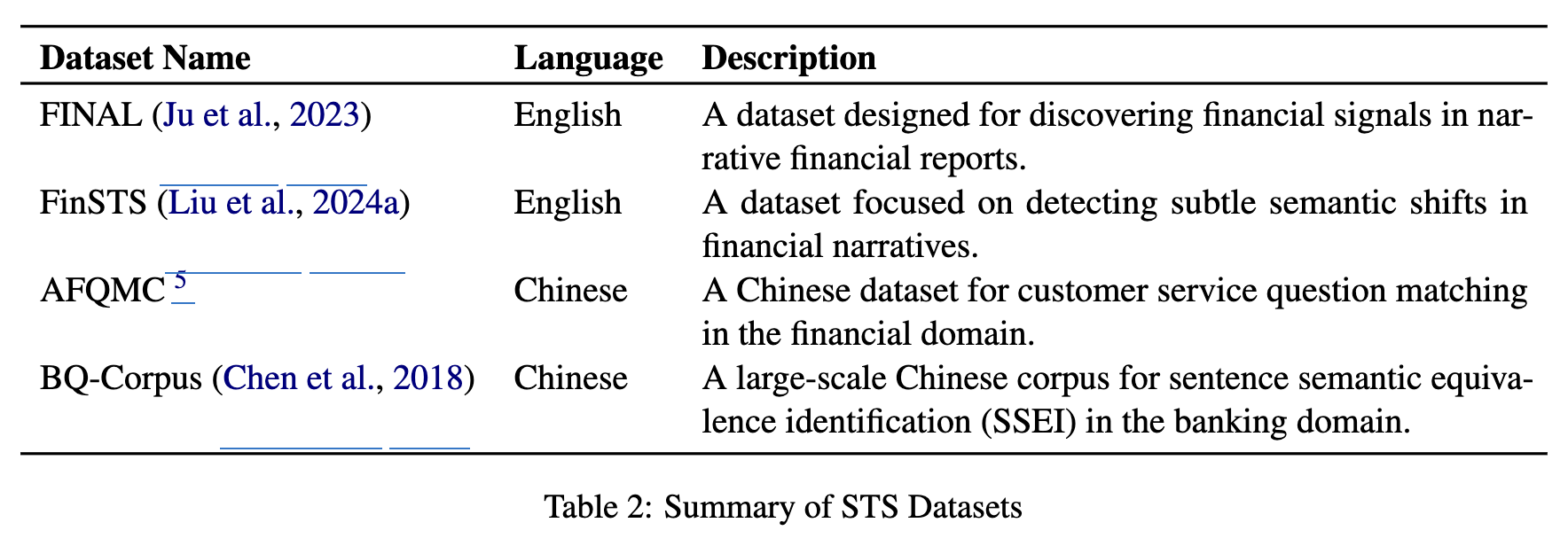
Semantic Textual Similarity (STS)
- financial text간의 의미적 유사도를 평가함
- 분기 보고서 상의 수익 발표에 대한 미세한 의미를 포착하는 것이 회사의 전략을 shift할수도 있을만큼 중요함
- Spearman’s rank correlation기반으로 human-annotated 유사도와 예측한 cosine similarity간의 상관관계를 기준으로 평가함
Retrieval
- 주어진 query에 연관된 금융 정보를 인지하고, 추출하는 task
- 복잡한 수치 분석, 시간적 상관관계 분석, 규제에 대한 이해 등이 요구됨
- NDCG@10을 기준으로 평가함
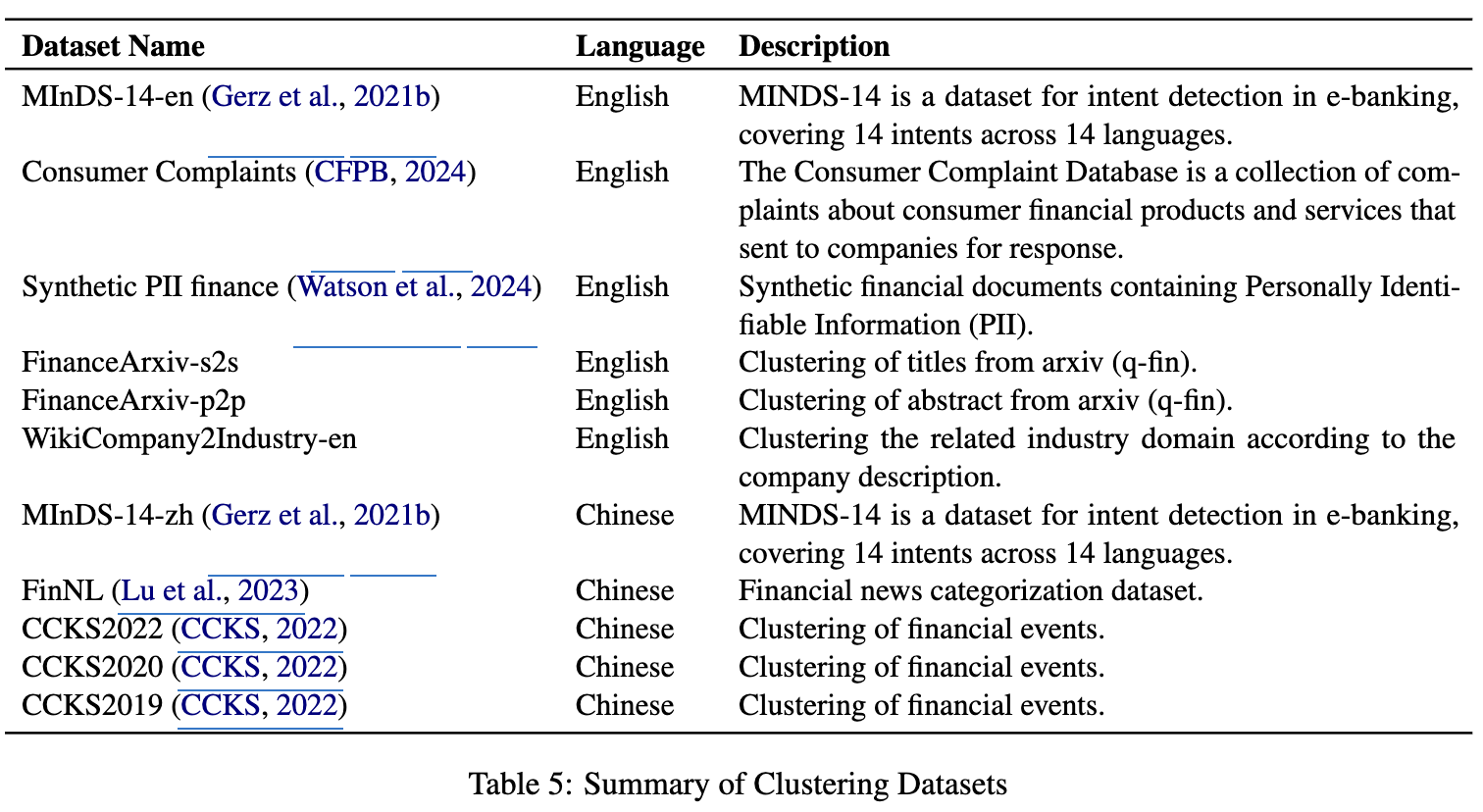
Clustering
- text의 내용을 기준으로 cluster를 묶는 task
- V-measure를 기반으로 측정
- completeness: 모든 멤버들이 동일 cluster에 속헀는지를 평가
- homogenity: 각 cluster가 single 멤버만 포함하는지
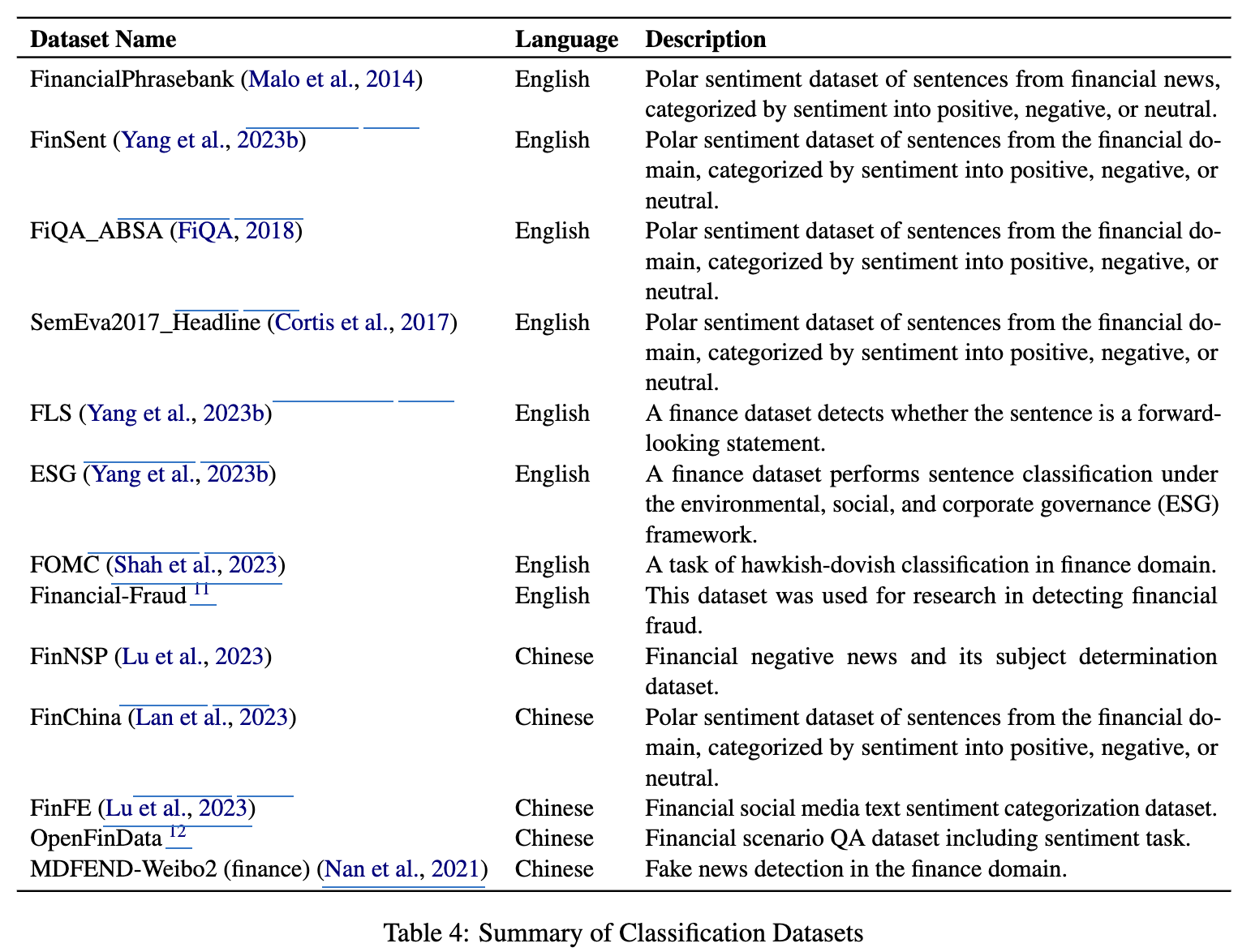
Classification
- text의 내용을 기준으로 pre-defined된 category로 매칭하는 task
- Mean Average Precision (MAP) 기준으로 평가 (ranking의 질 + confidence score)
Reranking
- text에 대한 정답과 함께 top-k개의 연관된 문서를 검색하는 task
- Mean Average Precision (MAP) 기준으로 평가
Pair-Classification
- text pair간의 의미적 연관성을 평가함
- Average Precision을 기준으로 평가
Summarization
- original text와 요약된 text간의 유사도를 평가함
3.2 Fin-E5: Finacne-Adapated Text Embedding Model
Data Formation
$(q, d^+,D^-)$
- $q$: query text
- $d^+$: positive document
- $D^-$: negative document
Training Data Construction
- Seed Data: expert-curated seed data기반으로 persona-based syntehtic data 를 생성
- 시장 분석, 투자 전략, 회사 재무 상태 등
- Persona-based Data Augmentation
-
Qwen2.5-14B-Instruct를 사용하여 “Who is linkely to use this text?”로 질문하여 구체적인 페르소나 묘사를 생성함
-
업종 관련된 task를 capture하여 persona를 생성함

-
-
Contextual Query Generation
-
Qwen2.5-72B-Instruct를 활용하여 Guess a prompt (i.e., instructions) that the follwoing persona may ask you to do:로 질문하여 “context”를 생성함
-
외부 document를 요구하는 queries를 필터링함 $\to$ “contextual query”
-
(query q, positive document $d^+$) 를 만듦

-
-
Synthetic Positive Document ($d^+$) Generation
-
Qwe2.5-VL-72B-Instruct를 통해 위 과정에서 생성 & 선별된 contextual query q를 가지고 “Synthesize context information related to this question: [Insert query q here]”로 연관된 positive financial document $d^+$를 생성

-
Training Pipeline
- (q, $d^+$, $D^-$) pair기반 contrastive learning으로 학습
- $D^-$: Hard negatives. 잠재적으로 query $q$와 연관되었으나, positive하지 않는 문서들. all-MiniLM-L12-v2를 통해 mining 수행하여 query q와 유사한 문서를 추출한 후 $d^+$와 distinct한 문서를 listup함
- e5-mistral-7b-instruct와 동일한 training recipe 활용
- last token polling method
4. Experiments
-
Evaluation Models
- Bag-fo-Words (BoW): word freqeuncy기반 sparse vector로 text representation을 설명
- Encoder-based: classical Bert, FinBERT, msmarco-bert-base-dot-v5, all-MiniLML12-v2, age-large-en-v1.5, AnglEBERT
- LLM-based: Mistral-7B-based, e5-mistral-7b-instruct, NV-Embed-v2, gte-Qwen1.5-7B-instruct
- Commercial Models: OpenAI’s text-embeddings, voyage-3-large
-
정량적 결과