[VI-Re-ID] FMCNet: Feature-Level Modality Compensation for Visible-Infrared Person Re-Identification
[VI-Re-ID] FMCNet: Feature-Level Modality Compensation for Visible-Infrared Person Re-Identification
- paper: https://openaccess.thecvf.com/content/CVPR2022/papers/Zhang_FMCNet_Feature-Level_Modality_Compensation_for_Visible-Infrared_Person_Re-Identification_CVPR_2022_paper.pdf
- github: X
- CVPR 2022 accepted (인용수: 96회, ‘24-03-05 기준)
- downstream task: Visible-Infrared Person Re-ID
1. Motivation
-
기존의 VI-ReID 방식들은 Image를 기반으로 missing modality를 생성하였음 $\to$ RGB & IR의 이미지 domain discrepancy가 커서, 생성된 이미지는 iterfering information을 발생하곤 함 (ex. color-inconsistency, etc)
-
다른 방식은, Visible-Infrared domain간의 shared feature만 학습하여 Person-ReID에 사용하곤 함 $\to$ 해당 modality specific feature를 버리게 되므로 성능이 하락함
-
Semantic meaning을 포함한 feature-level에서 missing modality information을 생성하는 것은 어떨까?
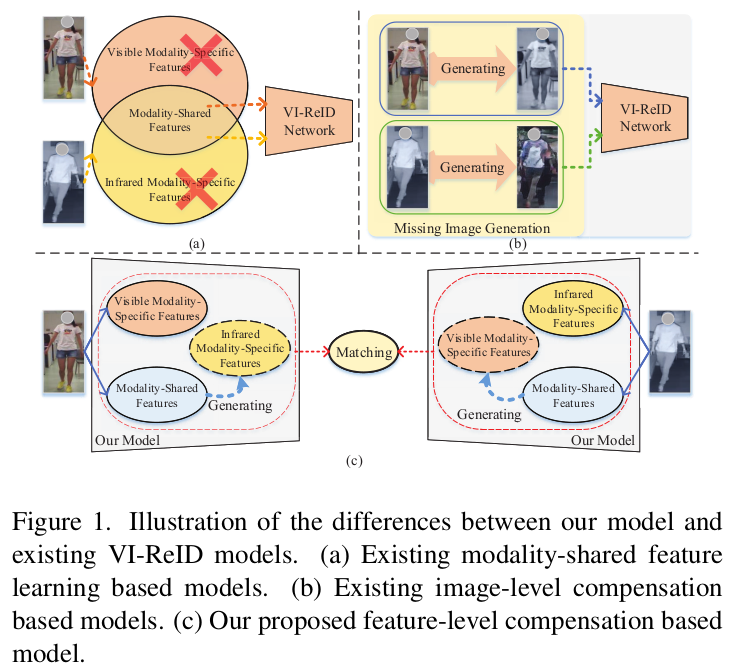
$\to$ RGB&IR을 함께 사용하여, 부족한 IR domain의 정보를 RGB로부터 추출할 수 있을까?
2. Contribution
- Feature-level modality specific information을 Compensation하는 FMCNet을 제안함
- End-to-end framework로 세 가지 module을 제안함
- unimodal feature decomposition : modality-specific, modality-shared feature를 분리
- modality-specific feature를 compensation함 (generation을 통해서)
- feature fusion for re-id
- VI-ReID에서 SOTA를 찍음
3. FMCNet : Feature-level Modality Compensation Network
-
Overall Architecture
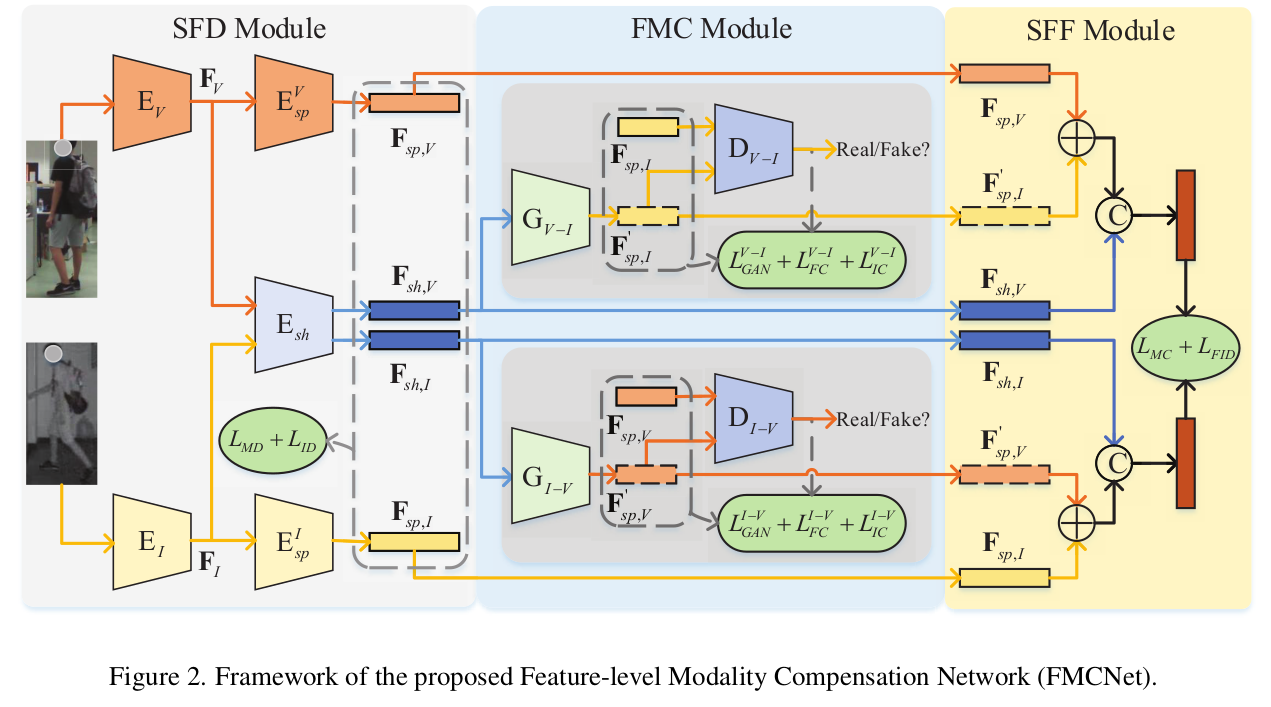
- Single-modality Feature Decomposition (SFD) Module : modality-specific, modality-shared feature를 분리
- Feature-level Modality Compensation (FMC) Module: modality-shared feature를 사용해서 modality-specific feature를 생성 (V2I, I2V)
- Shared-specific Feature Fusion (SFF) Module: modality shared, modality-specific, generated-modality specific feature를 활용해서 Re-ID
3.1 SFD Module
-
Network
-
feature
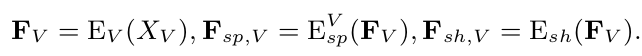
- $E_{sp}^V$: Visible-specific encoder
- $E_{sp}^I$: Infrared-specific encoder
- F$_V$: Visible feature
- $E_{sh}$: modality-shared encoder
-
output
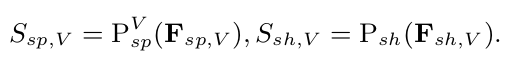
- $S_{sp,V}$: visible-specific identity score
- $S_{sh,V}$: visible-shared identity score
-
-
Modality Decomposition Loss (MD Loss)
-
Unimodal (visible or infrared) data에서 shared / specific feature 를 분리하는 모듈
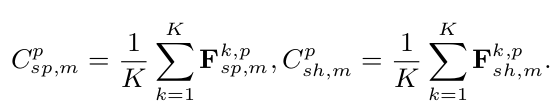
- $C_{sp,m}^p$ : p번째 identity가 갖는 modality-specific feature (m: infrared or visible)
- $C_{sh,m}^p$ : p번째 identity가 갖는 modality-shared feature (m: infrared or visible)
- K: p번째 identity의 sample 갯수
-
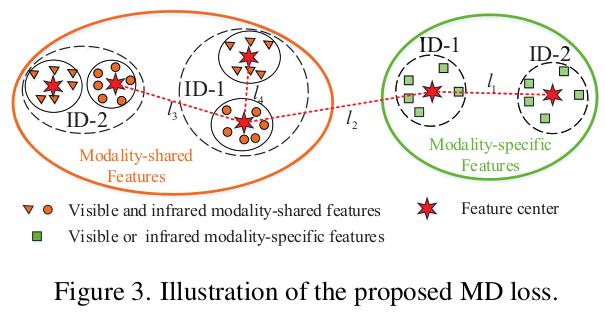
Modality shared feature: Modality간 (Visible/Infrared)의 같은 사람 (identity)에 대해 같은 feature로 mapping되도록 유도학습된 feature ($E_{sh}$의 출력)
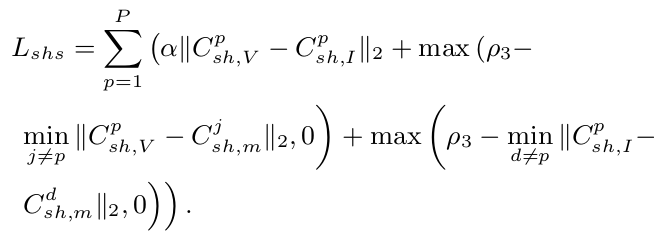
-
$L_{shs}$: modality-shared feature separation loss
$\to$ 위 그림에서 $l_4$는 가까워지고, $l_3$이 멀어지도록 학습
-
-
Modality specific feature: Modality간 (Visible/Infrared)의 다른 사람 (identity)에 대해 멀어지도록 유도학습된 feature ($E_{sp}^V, E_{sp}^I$의 출력)
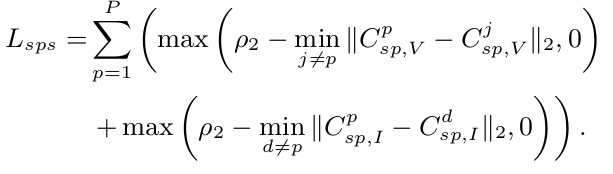
-
$L_{sps}$: modality-specific feature separation loss
$\to$ 위 그림에서 $l_1$이 멀어지도록 학습
-
-
Decorrelation loss : 다른 identity에 대해 modality-specific feature간의 maximum 거리가 다른 identity에 대해 modality specific feature와 modality shared feature의 minimum 거리보다 가깝도록 학습을 유도하는 Loss $\to$ modality-specific, modality-shared feature간의 decorrelation이 목적
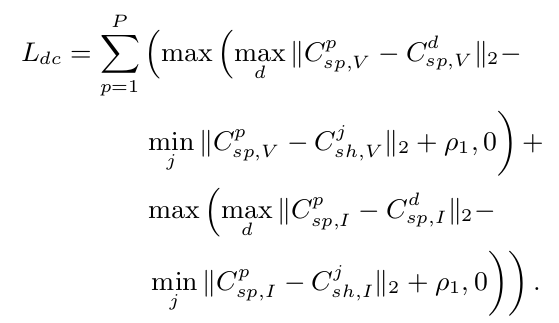
-
MD Loss
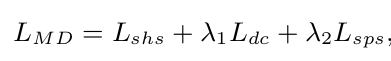
-
-
Identity Classification Loss
-
Person identity를 분류하는 Loss
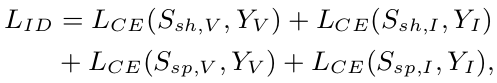
-
$Y_I, Y_V$: Infrared, Visible image가 어떤 identity(어떤 사람)인지 해당 id의 정답
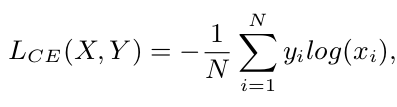
-
-
-
SFD Loss
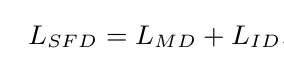
-
MD Loss 적용 전/후 비교
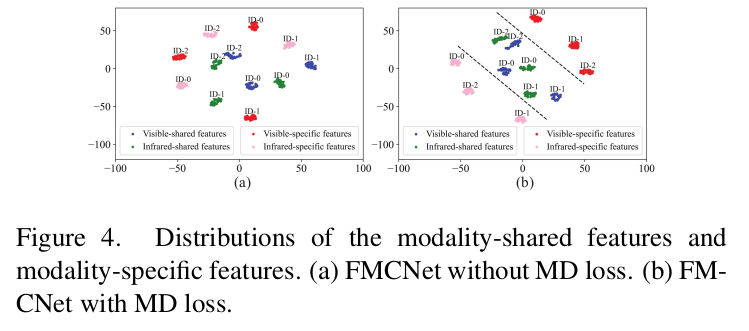
- (a) modality shared / specific feature가 뒤섞여 있는데 반해
- (b) modality shared / specific feature가 분리되어 있음
3.2 FMC Module
-
SFD Module에서 unimodality 내에 modality-shared / specific feature로 분리한 것을 활용함
-
Input : modality-shared feature
-
Output: (missing) modality-specific feature
-
How? Adversarial Training
-
Generator
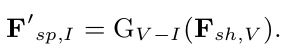
- Missing specific feature가 Infrared 일 경우, $G_{V-I}$가 visible shared feature (F${sh,V}$)를 활용해서 F$’{sp,I}$를 생성
- Vice versa로 $G_{I-V}$는 Missing specific feature가 Visible일경우 F$’_{sp,V}$를 생성함
- 3-MLP layer로 구성
-
Discriminator
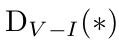
- 1-MLP + Sigmoid로 구성
-
Adversarial Loss
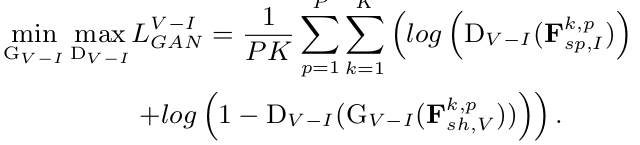
-
Feature consistency Loss
-
generated specific feature가 해당 modality의 specific feature centroid와 가까워지도록 학습
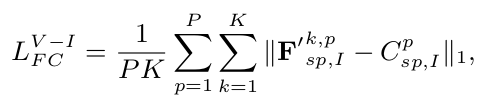
-
-
Identity Consistency Loss
-
generated specific feature로 identity classification loss를 계산
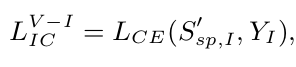
-
-
3.3 SFF Module
-
modality specific / shared feature와 generated specific feature를 사용하여 person-reid를 수행
-
specific fusion feature
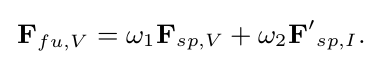
- $w_1, w_2$ : learnable parameter
- F${sp,V}$, F$’{sp,V}$: modality specific feature, generated modality specific feature for Visible
- F$_{fu,V}$: fused modality specific feature for Visible
-
final fusion feature
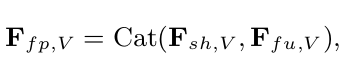
-
Identity classification Loss
- 위의 final fusion feature를 identity classifier $P_{fp}$에 통과시켜 학습
-
최종적으로 사용하는 Loss
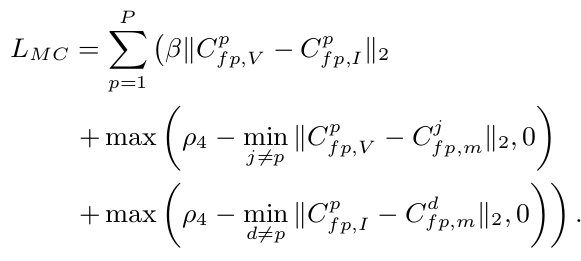
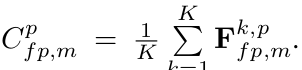
4. Experiments
- Compared to SOTA
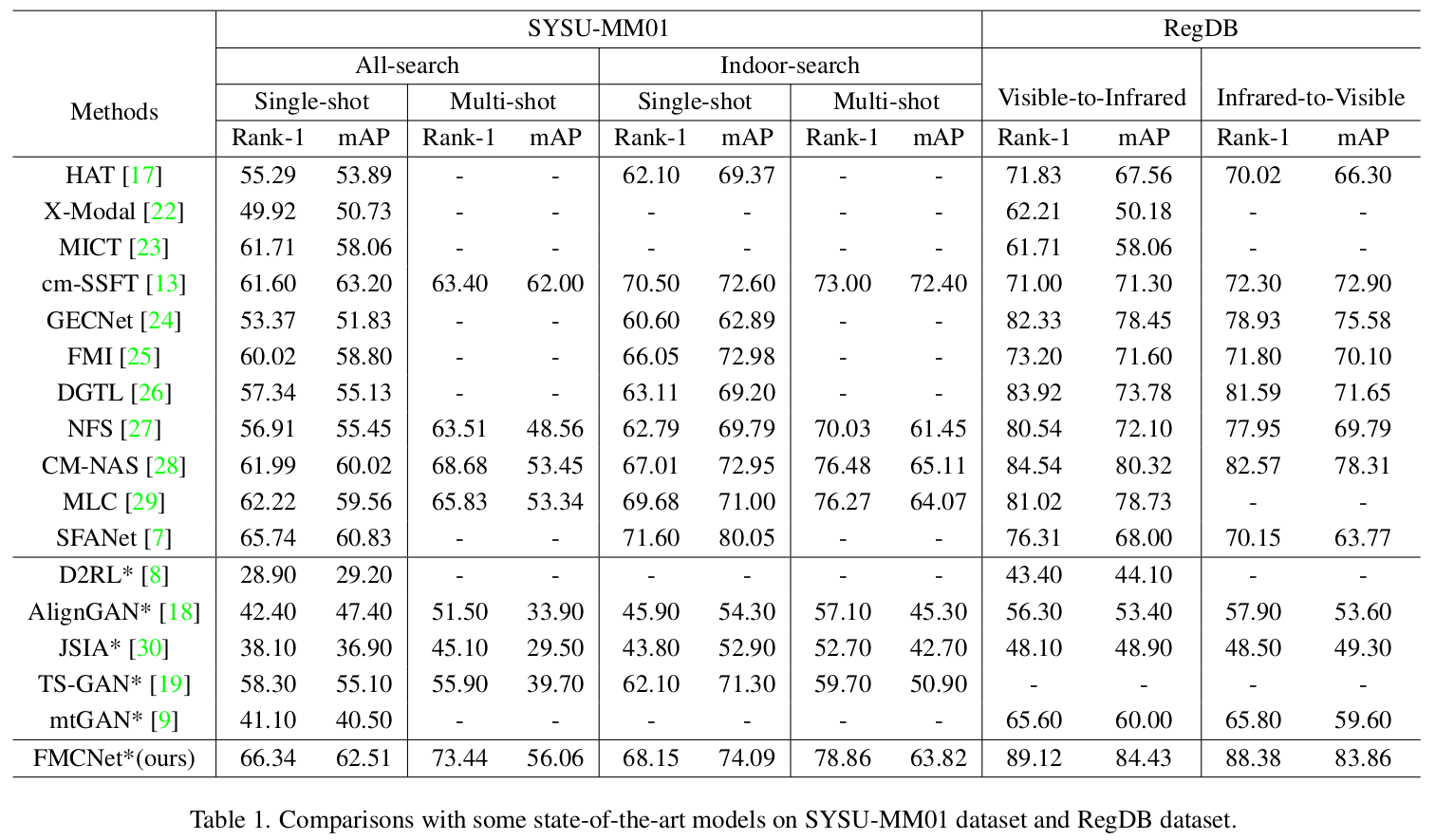
-
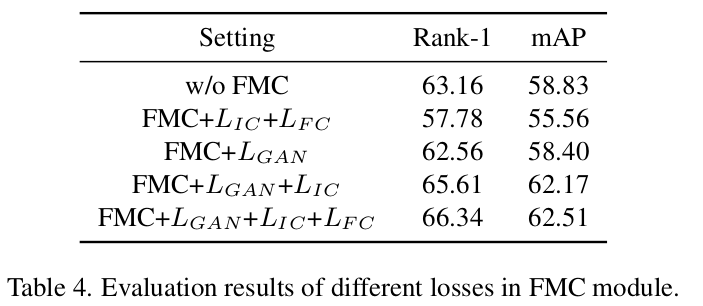
Ablation
- Module에 따른 ablation
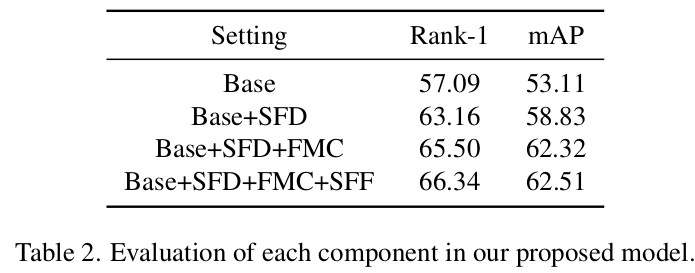
-
MD Loss ablation
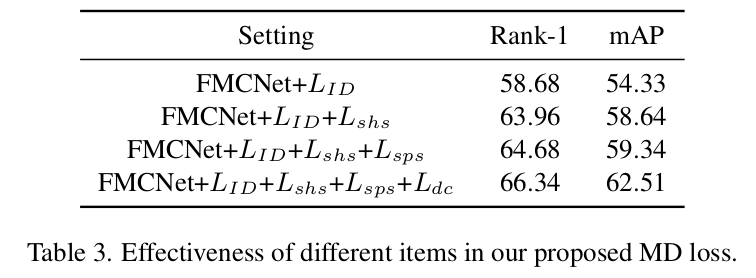
-
Loss ablation