[UDA][SS] ECAP: EXTENSIVE CUT-AND-PASTE AUGMENTATION FOR UNSUPERVISED DOMAIN ADAPTIVE SEMANTIC SEGMENTATION
[UDA][SS] ECAP: EXTENSIVE CUT-AND-PASTE AUGMENTATION FOR UNSUPERVISED DOMAIN ADAPTIVE SEMANTIC SEGMENTATION
- paper: https://arxiv.org/abs/2403.03854
- github: https://github.com/ErikBrorsson/ECAP
- archive (인용수: 0회, ‘24-03-10 기준)
- downstream task: UDA for SS
1. Motivation
- domain shift가 있는 상황에서 pseudo label 은 easy-to-use class에 dominant해짐
- 이를 해결코자 bridge domain을 cut-and-paste를 활용하는 기존 연구가 있음
- 여기에 memory-bank를 활용하여 reliable pseudo label을 늘리면 좋지 않을까?
2. Contribution
- pseudo-label의 noise를 줄이기 위한 UDA augmentation 새로운 방식인 Extensive Cut-and-Paste(ECAP)를 제안함
- 어떻게? 잘 맞추었다고 예상되는 (reliable) pusedo-labeled pixel의 비중을 늘려주는 cut-and-paste augmentation을 활용함으로써
- SOTA at UDA for SS
- 다양한 분석 시도함
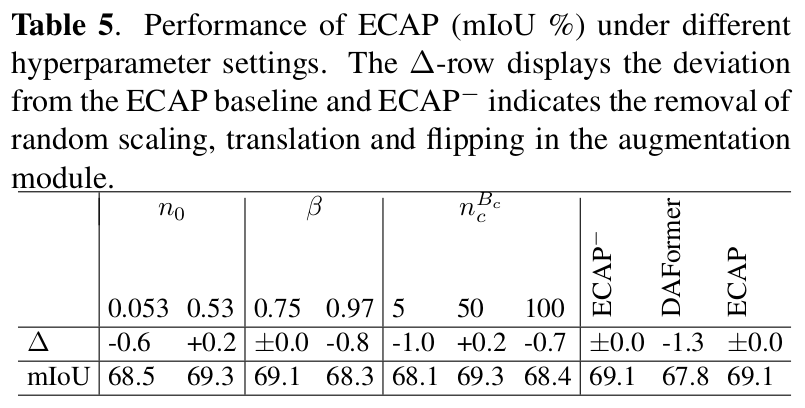
3. ECAP
-
overview
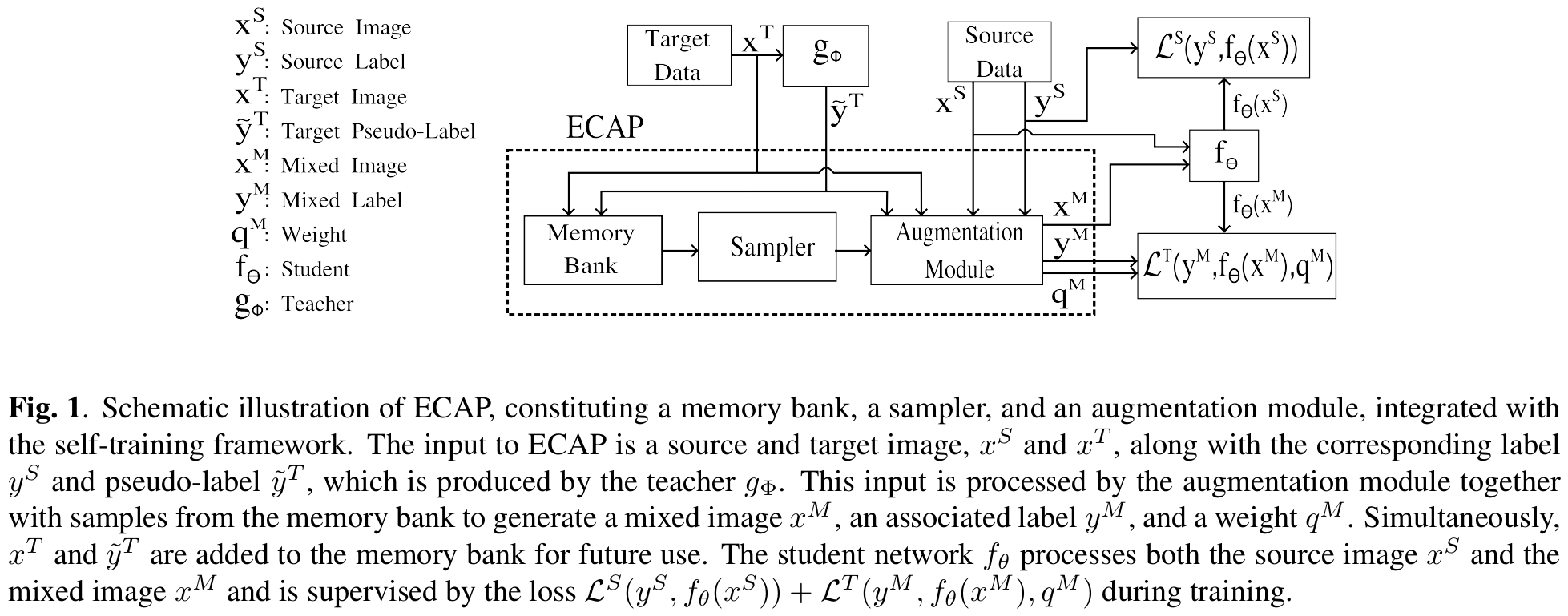
-
Mixed Image

-
Target domain Loss
- Weighted Cross Entropy Loss 활용
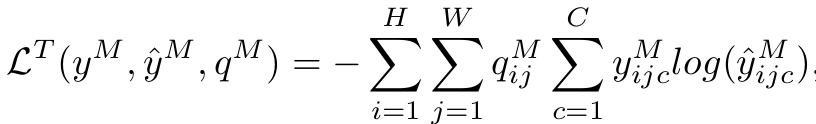
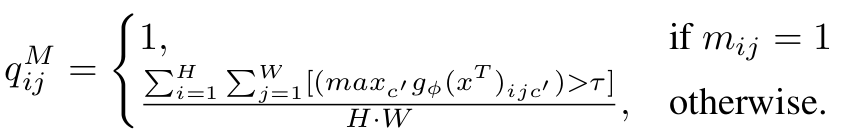
-
Total Loss
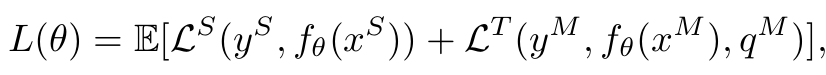
-
Memory Bank
-
Target image와 pseudo label, class index를 저장하고 있음
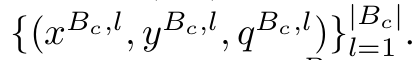
- $B_c$: memory bank의 크기
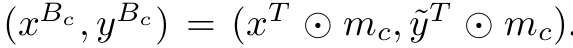
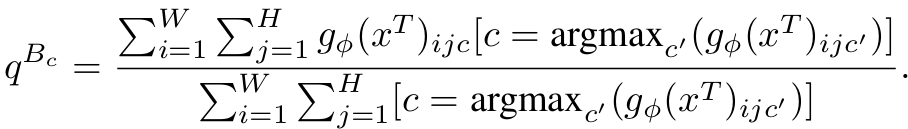
- $g_{\phi}$: teacher network의 (i,j)번째 pixel의 class = c 의 output
-
-
Sampler
-
Memory bank 내에서 top $n^{B_c}$개의 prediction 중 random sampling
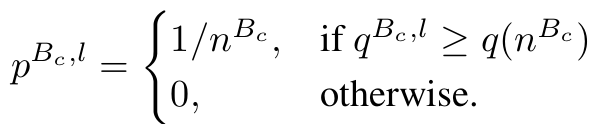
- $n_{B_c}$: hyper-parameter.
- $q(n^{B_c})$: $n_{B_c}$번째 sample의 prediction score
- $q^{B_c, l}$: memory banck $B_c$에서 l번째 sample의 pseudo prediction score
- $p^{B_c,l}$ l번째 sample이 sampling될 확률
-
-
최종 sampling equation
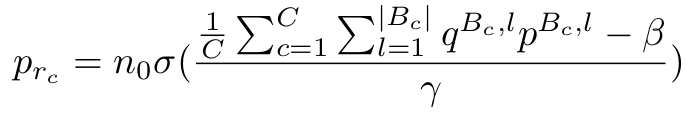
$\beta, \gamma, n_0$: hyper-paramter
$\sigma$: sigmoid
-
Augmentation Module
-
Mixing하기 전에 random augmentation수행 $\to$ 실험적으로 성능 향상에 기여하진 않음

- $\alpha$: augmentation method
- DACS: baseline이 되는 방식
-
4. Experiments
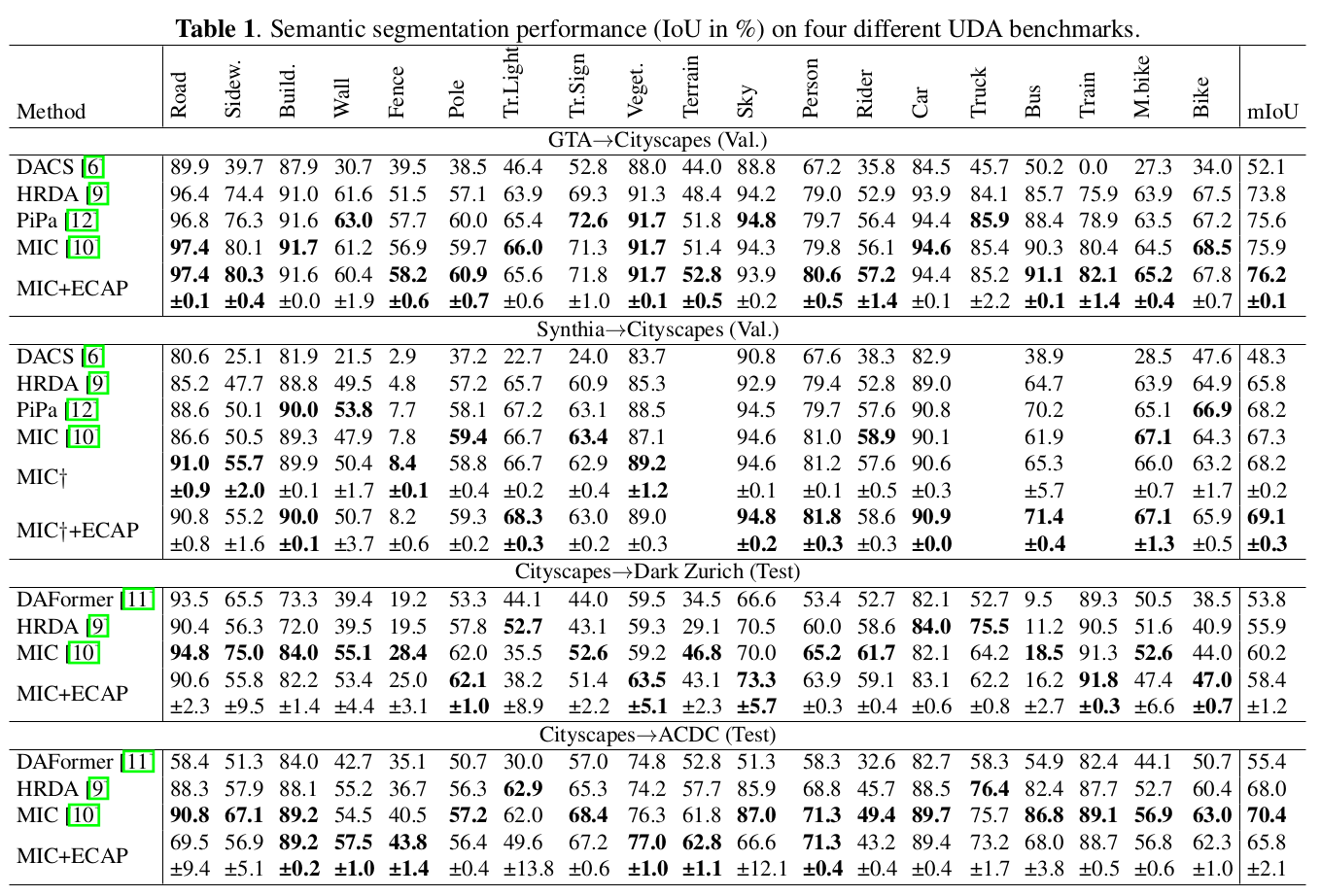
-
Ablation
-
with and without ECAP
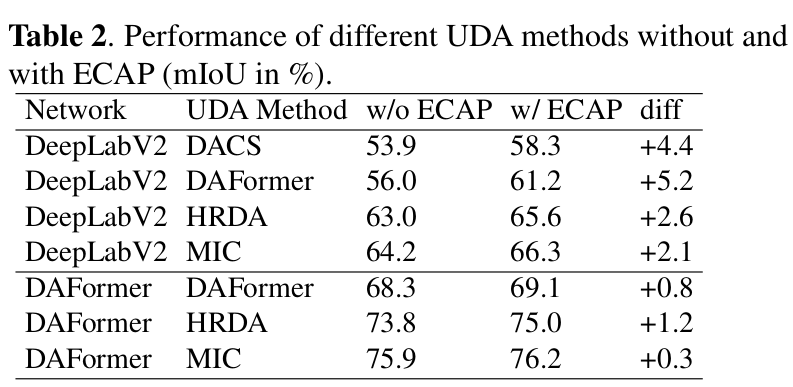
-
Upper-bound

- denoise: Target GT를 활용해서 틀린 부분은 loss에 반영 안하도록 함
-
-
Memory bank의 pseudo GT quality

- Thihgs class는 좋은데 Stuff Class는 별로 안좋음
-
Hyper-parameter sensitivity