[TTA][CLS] Efficient Test-Time Model Adaptation without Forgetting
[TTA][CLS] Efficient Test-Time Model Adaptation without Forgetting
-
paper : https://arxiv.org/abs/2204.02610
-
github: https://github.com/mr-eggplant/EATA
-
ICML 2022 accpeted (인용수 : 115회, ‘24.01.29기준)
-
downstream task : Online Test-time adaptation for classification
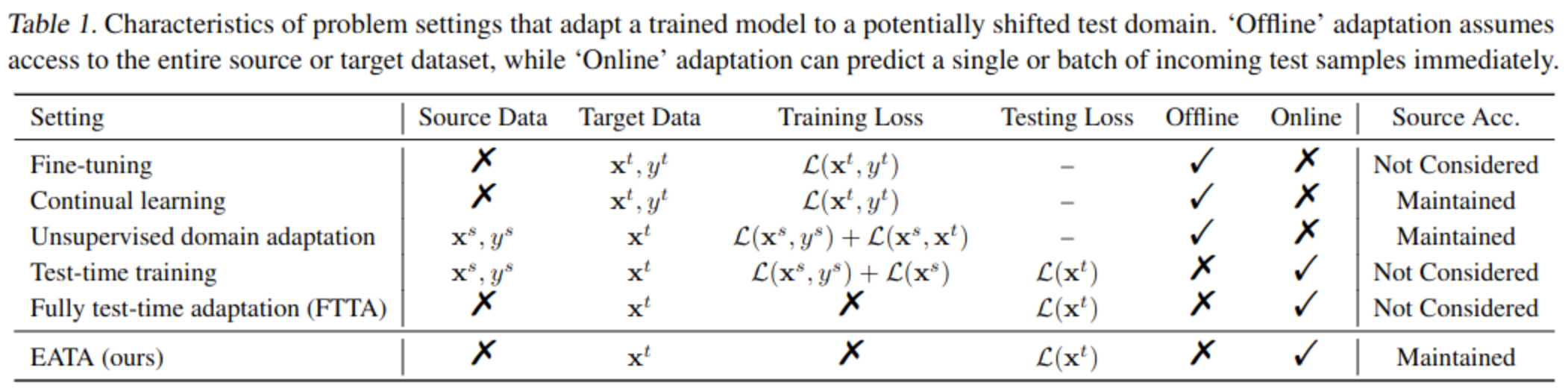
1. Motivation
- 기존 TTA 방식들은 모든 sample에 대해 adaptation을 수행하였음 $\to$ back prop.을 하기엔 너무 현실적으로 계산량이 많음 (efficiency)
- 모든 sample에 대해 back prop.을 하면 catastrophic forgetting이 발생함 $\to$ fisher regularizer를 통해 방지함 (forgetting)
2. Contribution
- Non-reliable 혹은 Redundant 한 sample에 대해서 model adaptation하지 않는 sample identification scheme 제안
- Catastrophic forgetting 방지를 위해 Fisher regularizer기반 regularization loss 추가 $\to$ important model parameter의 drastic change 방지
- subset of test sample로 Fisher Information을 산정
- EATA (Efficient Anti-forgetting Test-time Adaptation)을 제안 → life-long learning의 forgetting issue 해결
3. EATA
3.1. Sample-efficient entropy minimization
-
Sample이 reliable해야 한다
-
Entropy값이 작은 sample이 좋다.
-
Entropy에 따른 성능 gain 실험
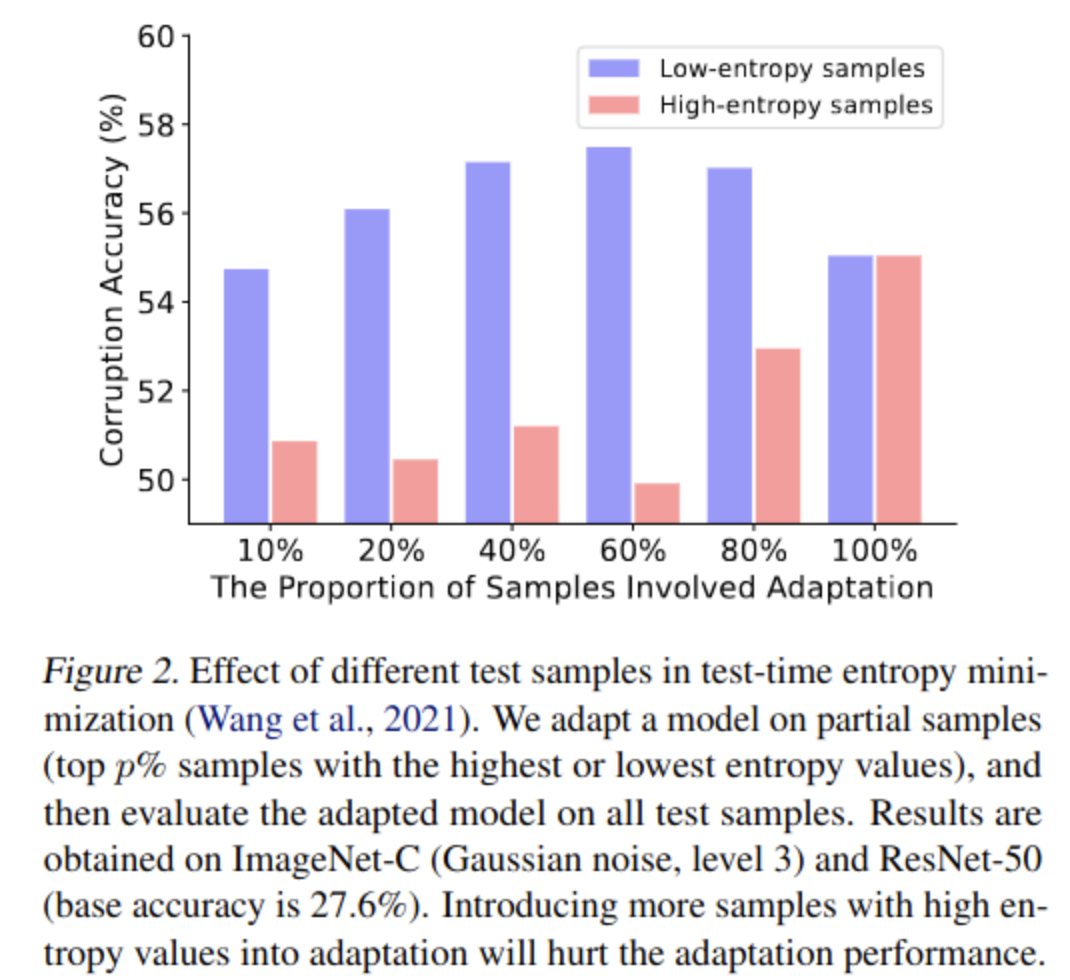
- Red : Entropy 상위 p%
- Blue : Entropy 하위 p%
- Entropy가 높은 sample은 uncertain하므로 gradient 산출 시 biased & unreliable함
-
Sample selection score
- 위 실험을 바탕으로, entropy와 반비례하는 weight sampling 방법을 제안함
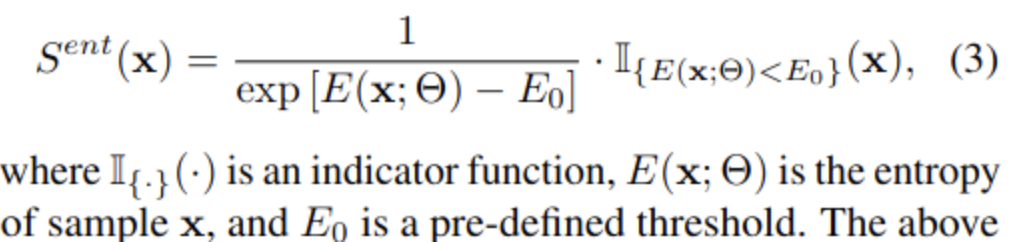
- S=0 ; non-active
- S=1; active
-
-
-
Sample이 Non-redundant해야 한다
-
Sequential frame이 들어오는 경우 (비록 entropy가 낮더라도) frame-by-frame으로 모두 backprop. 하는 것은 비효율적이다.
-
Straightforward method
- 모든 sample에 대해 model output 계산하여 frame별 similarity 계산 → Test-Time에 너무 비효율적
-
제안 방식 : EMA
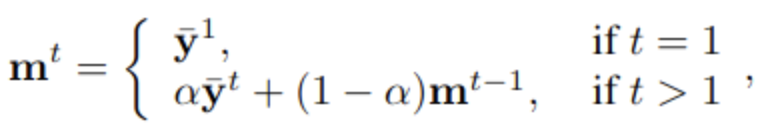
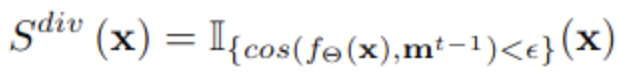
- EMA update된 이전 step (t-1) output과 현재 step (t) output의 유사도가 낮을 경우만 select
-
Overall sample-selection score (eq.6)
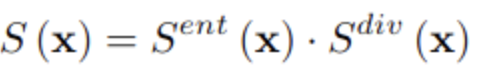
-
-
Total Loss
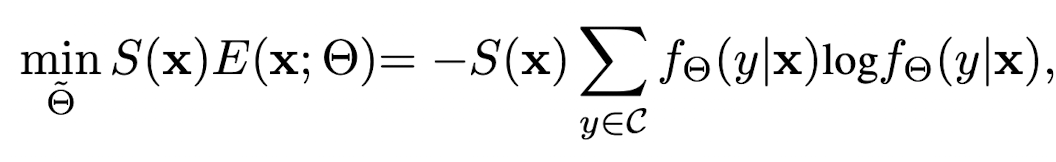
3.2. Anti-forgetting weight regularization
-
Anti-forgetting Fisher Regularization
-
ID (In-Distribution) sample에 대해 중요한 Weight에 대해 adaptation을 덜 되게 regularization을 줌
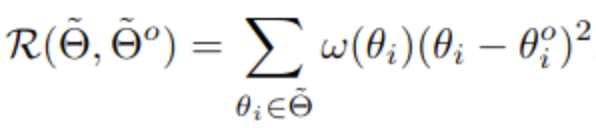
-
Weight Importance (w)
-
ID (In-Distribution)에서 test sample (약 500장) 에 대한 prediction 으로 Loss 계산

-
original model ($\theta_0$)와의 차이를 loss로 두고, 미분한 값을 사용
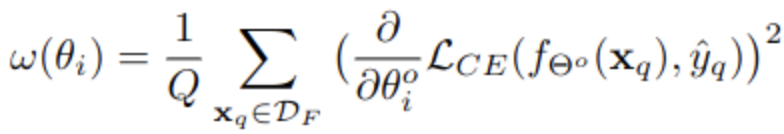
-
Adaptation process 이전에 딱 1번만 수행
-
Total Loss (eq. 8)
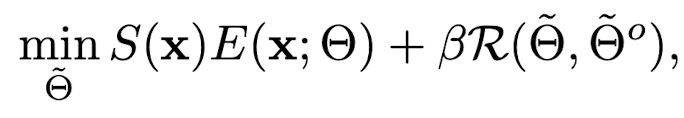
-
-
-
overall algorithm

4. Experiments
-
ImageNet-C
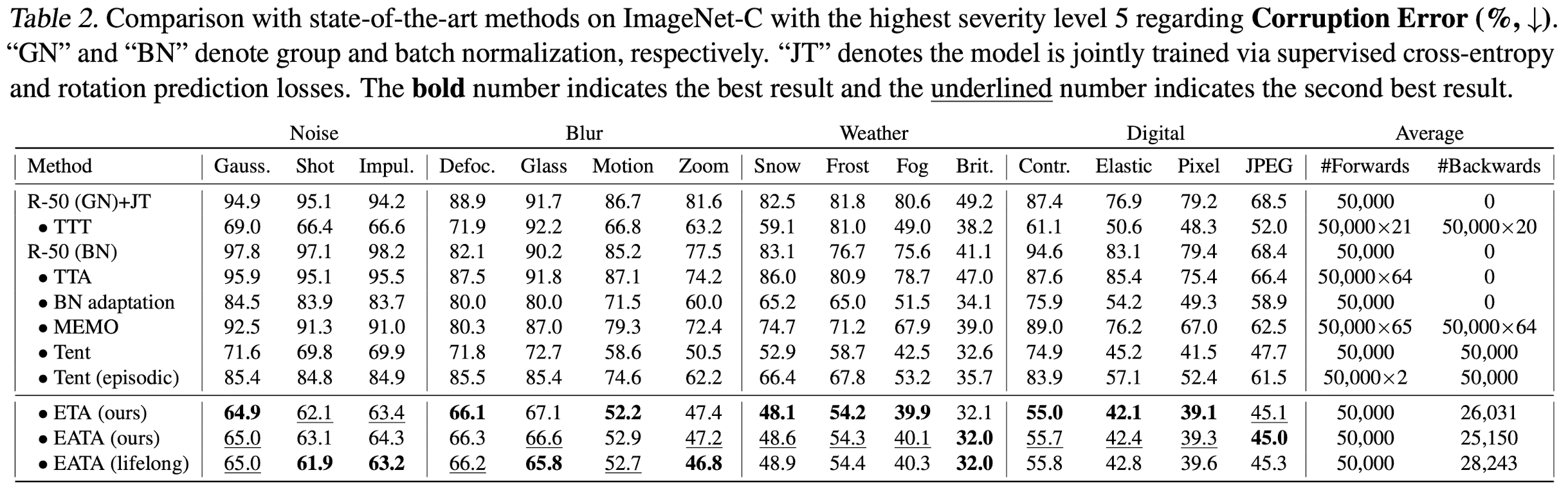
-
ImageNet-R
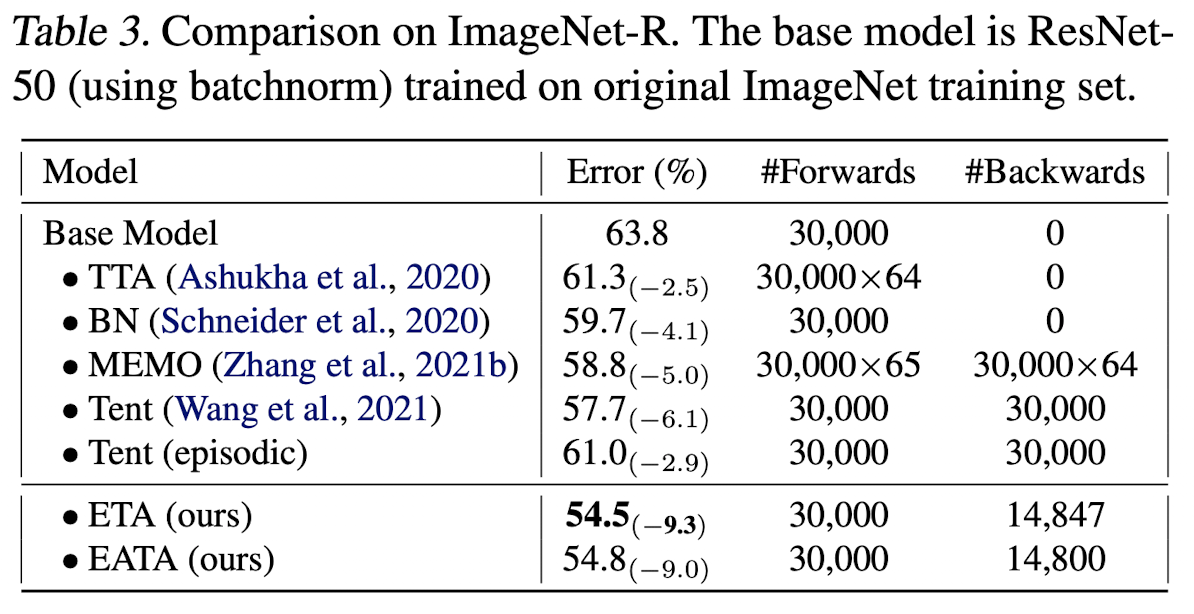
-
Anti-Forgetting Ablation
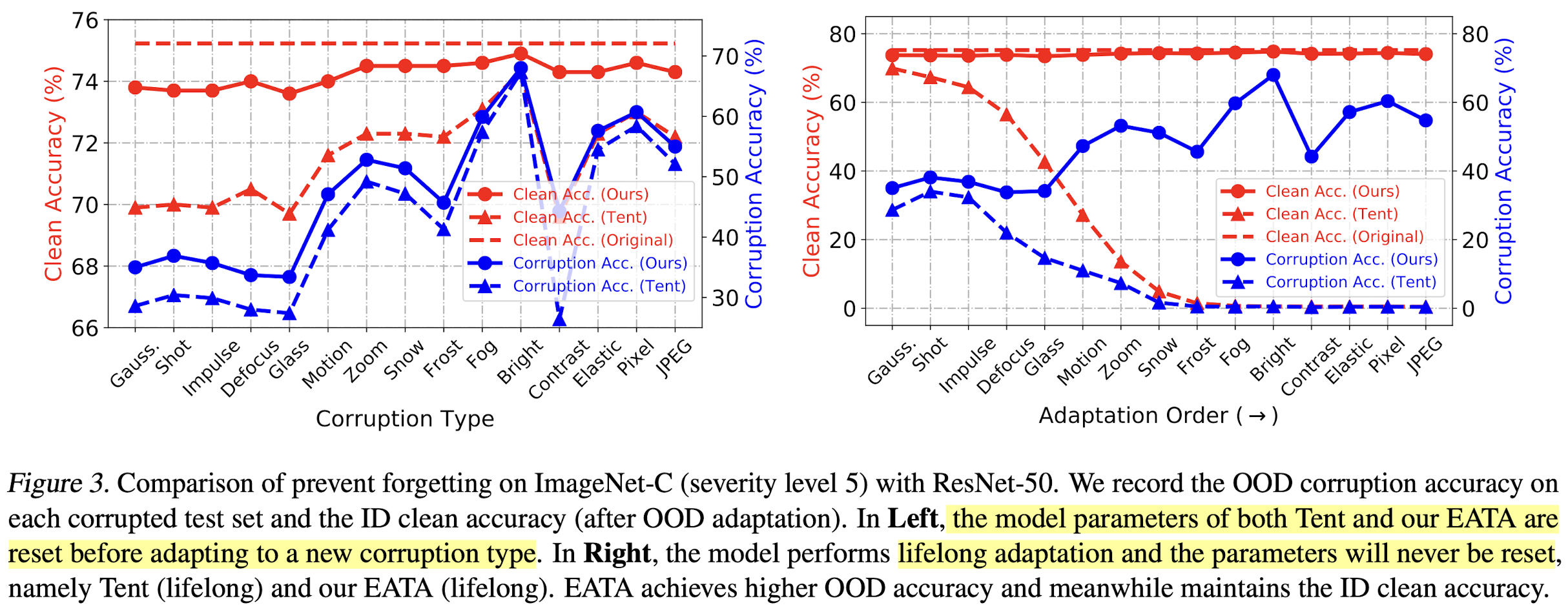
- (a) 매 corruption 전에 source로 update
- (b) life-long learning
-
Ablation study (# of samples calculating Fisher & $E_0$)
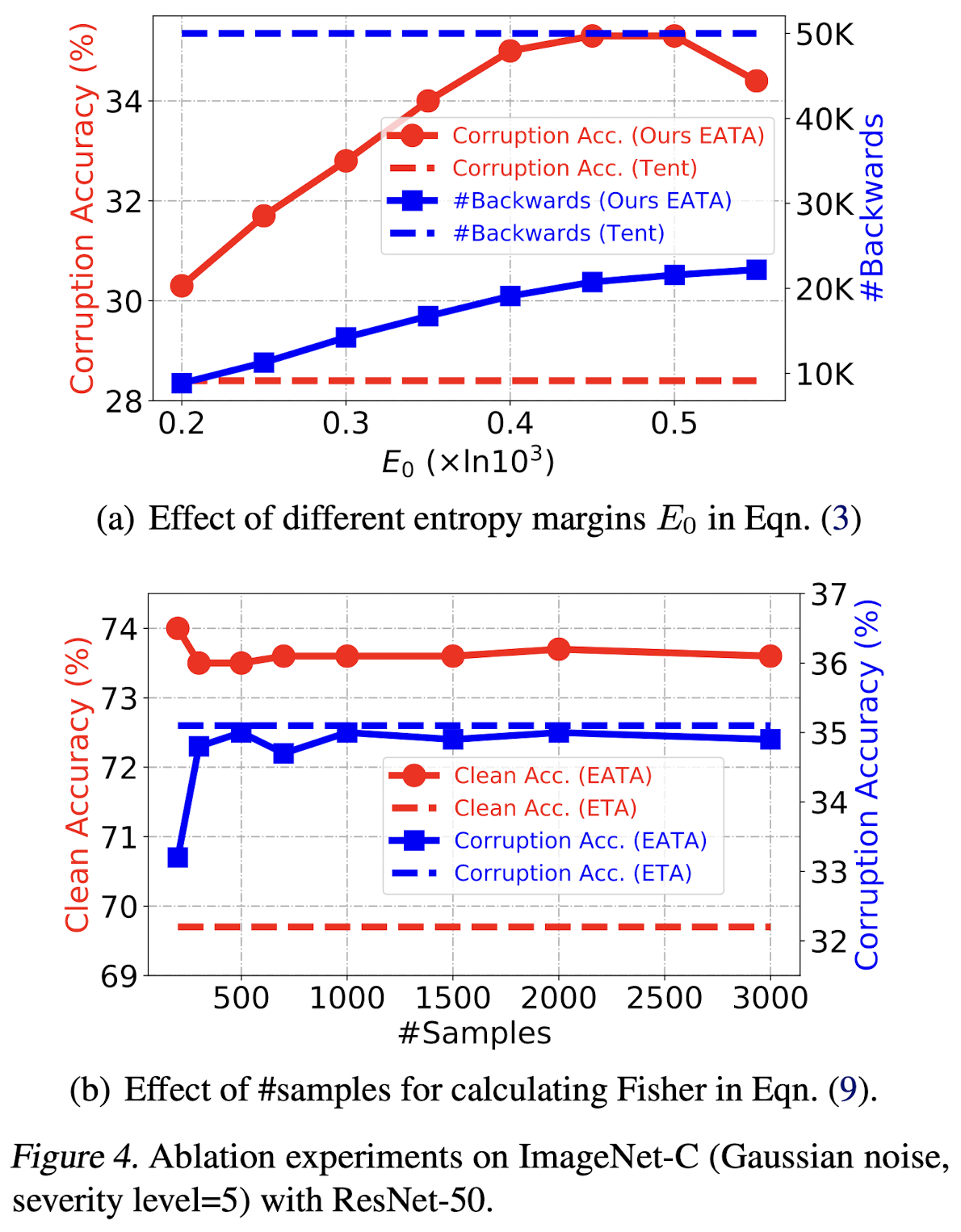
- ETA: EATA without Regularization
-
Batch size = 1 results
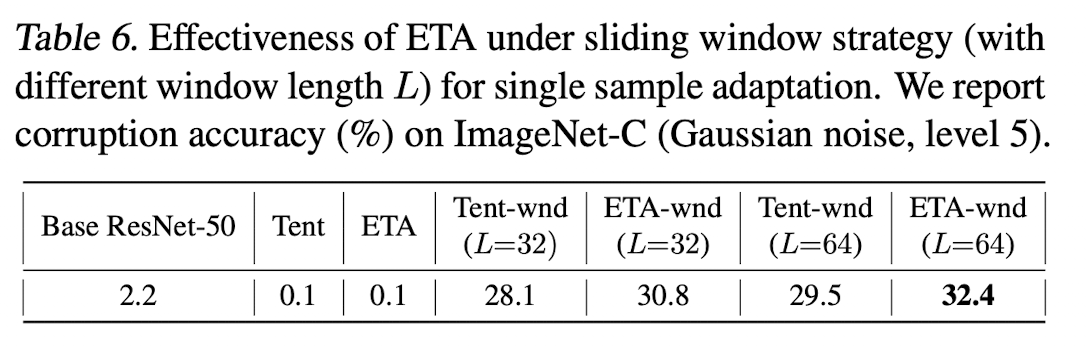
- TENT, EATA모두 잘 안됨
- sliding window를 통해 해결
-
Mixed Corruption accuracy

-
Large Models
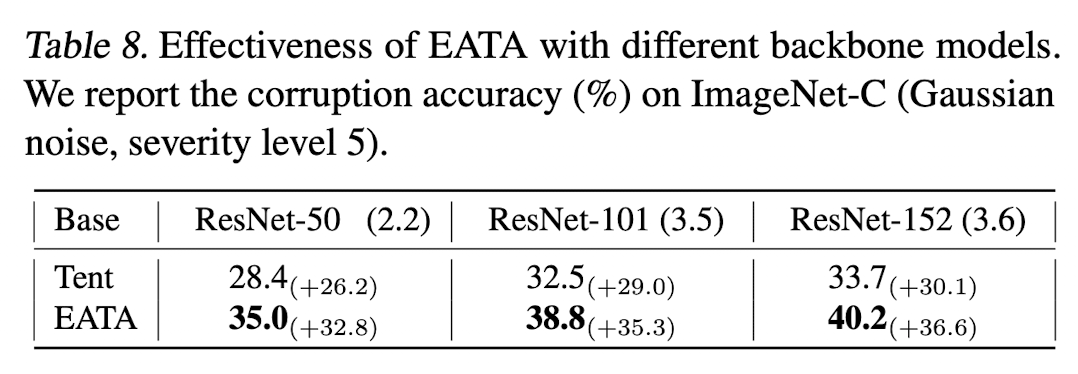
-
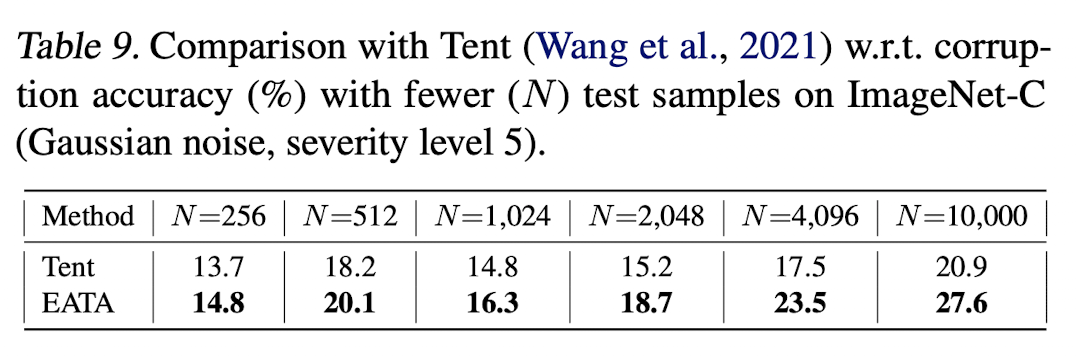
Total test sample의 갯수에 따른 ablation study
-