[DM] DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
[DM] DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
- paper: https://arxiv.org/pdf/2208.12242.pdf
- github: https://dreambooth.github.io/
- CVPR 2023 accepted (인용수: 1,072회, ‘24-03-23 기준)
- downstream task: Image Generation
1. Motivation
-
기존 생성AI에서는 Given sample의 identification을 보존하면서 생성하지 못하는 한계가 있어왔다.
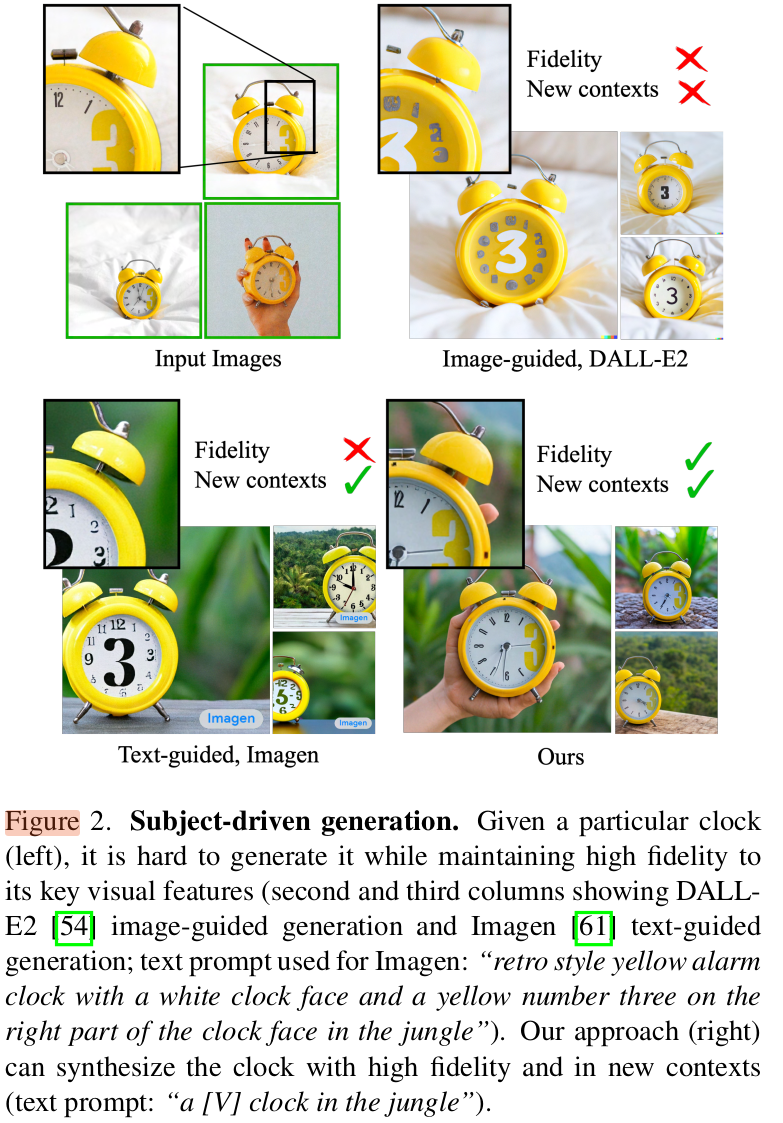
-
Few-shot의 reference-set만 가지고, 해당 set의 personalization은 유지하면서 주어진 text prompt에 따라 이미지를 다양하게 생성할순 없을까?

2. Contribution
- Text-to-Image Diffusion기반 personalization을 수행하는 DreamBooth를 제안함
- 사용자가 원하는 specific subject로 personalization을 수행한 new word를 binding하여 이미지를 생성함
- model의 output domain에 unique identifier로 해당 subject를 implant시키는 것이 목적
3. DreamBooth
-
preliminaries
-
Diffusion Model 학습 시 Gaussian distribution noise를 denoising하도록 모델을 학습함
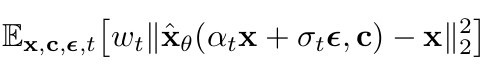
- $\alpha_t, \sigma_t, w_t$: noise scheduling parameter 및 sample quality $t \in U([0,1])$
- c: text encoder $\Gamma$로부터 text prompt를 통해 만들어진 text embedding
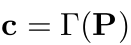
- P: text prompt
- $\epsilon$: gaussian noise
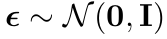
- x: image
- $\hat{x}$: generated image
-
-
overall digaram
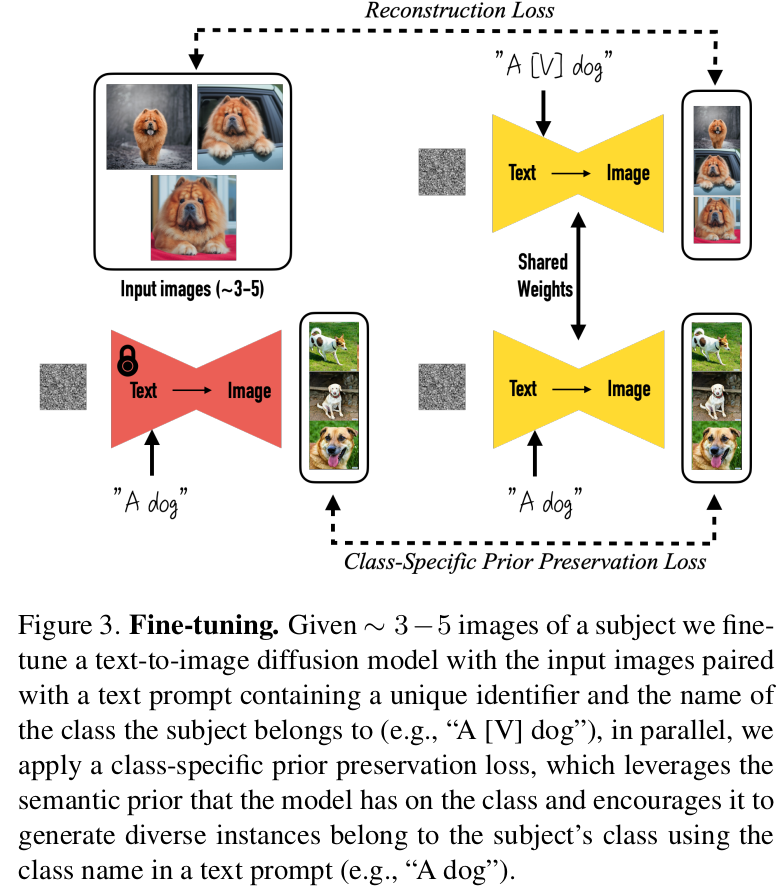
3.1 Personalization of Text-to-Image Models
1. Design Prompts for Few-shot Personalization
- 새로운 unique identifier를 diffusion model의 dictionary에 implant하는게 목적
- “a [identifier] [class noun]”로 구성
2. Rare Token Identifier
- Text encoder는 text identifier (ex. “xxy5syt00”)를 입력받아 tokenizer를 거쳐 각각의 letter를 개별적으로 이해하는데, 기존에 사용하는 패턴의 identifier가 들어가면 diffusion model은 해당 token을 강하게 (strong) 우선순위를 주게됨
- rare-token을 학습시켜, 강한 우선순위를 갖지 않게하는 identifier를 입력시키는게 핵심임
- T5-XXL Tokenizer의 {5000~10,000}째 range를 3개 이하의 Unicode로 입력하는게 효율적이었음
3.2 Class-specific Prior Preservation Loss
-
실험 결과 모든 layer를 fine-tuning하는 것이 생성된 이미지의 fidelity가 가장 좋았음 (text encoder 포함)
-
하지만, few-shot의 특성상, 두 가지 문제가 발생함
- language drift: few-shot identifier에 overfitting되어 syntactic & semantic knowledge of langauge를 훼손시킴
- reduce output diversity : few-shot에 overfitting되어 novel view point, pose, articulation가 생성되지 않음
-
두 가지 문제를 해결코자 class preservation loss부여
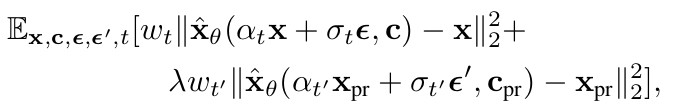
-
x$_{pr}$: freezed Diffusion model이 생성한 이미지
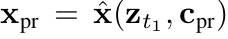
-
c$_{pr}$: “[class noun]” text prompt를 text encoder가 받아서 생성한 text embedding
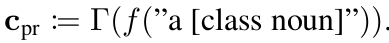
-
freezed Diffusion model로 “[class noun]” text prompt를 condition으로 넣어 생성한 이미지와 동일 text prompt condition으로 넣고 fine-tuning된 모델이 출력하는 이미지가 같아지도록 학습 $\to$ Diffusion Model의 해당 class에 대한 knowledge를 최대한 따르도록 학습함으로써, 그 knowledge를 leverage하기 위함
-
-
학습은 약 5분 소요 (A100 GPU)
4. Experiments
4.1. Datasets & Evaluations
1. Dataset
-
30개의 subjects (21개 objects, 9개 생물)로 구성

2. Evaluation
- CLIP-I : Clip Image Encoder가 encoding한 real & synthetic image간의 similarity
- DINO : DINO Self-sup learning으로 학습한 ViT-S/16이 encoding한 real & synthetic image간의 similarity
$\to$ 자기 자신 이외 다른 이미지에 대해서는 (같은 class라 할지라도) 밀어내도록 학습한 DINO metric이 본 evaluation 결과로 더 적합함
4.2. Results
- DINO & CLIP-I
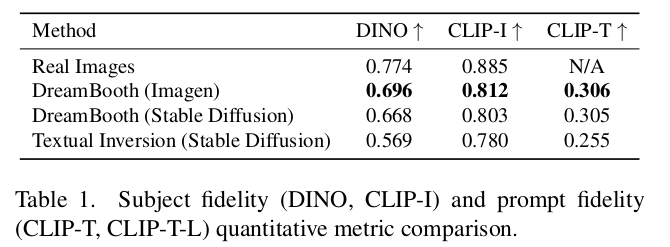

-
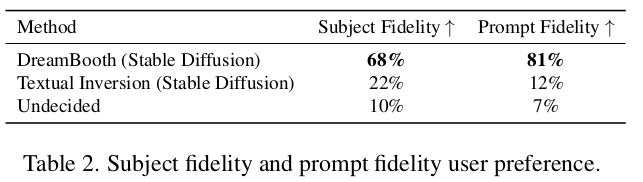
User Preference * 72명에게 질문
4.3 Ablation Studies
-
Prior Preservation Loss
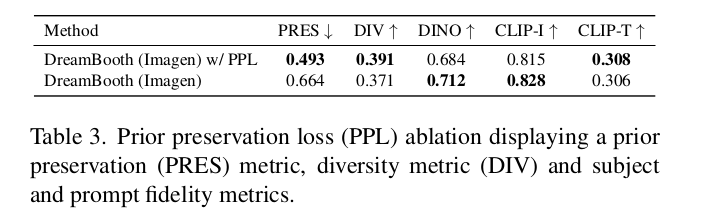
- DINO가 낮아지고 (fidelity가 약간 낮아졌음), 대신 diversity가 높아짐 (DIV)
-
Class Noun 에 따른 ablation
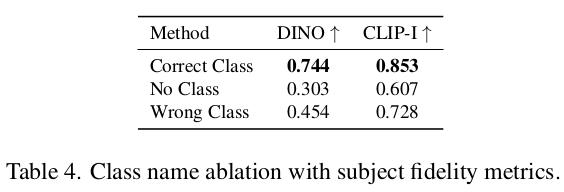
- class noun이 없는 것보다 있는것 (잘 준 것/잘 못준것)이 낫고, 잘 준게 제일 낫다
- Diffusion Model의 pretrained knowledge덕에 subject학습에 도움이 됨
4.4 Application
1. Recontextualization

2. Art Renditions & Novel View Synthesis & Property Modification

4.4 Limitations

- (a) rare case text prompt를 입력한 경우
- (b) 환경이 subject에 영향을 미치는 경우
- (c) 학습 데이터와 유사한 text prompt인 경우 (overfitting)