DesignCoder: Hierarchy-Aware and Self-Correcting UI Code Generation with Large Language Models
[GUI] DesignCoder: Hierarchy-Aware and Self-Correcting UI Code Generation with Large Language Models
- paper: https://arxiv.org/pdf/2506.13663
- github: x
- archieved (인용수: 0회, ‘25-06-18 기준)
- downstream task: GUI(MockUp, ex. skethes, Figma) to front-end (react) code generation
1. Motivation
-
MLLM의 발전으로 GUI image만 제공해도 front-end code를 잘 생성해주고 있다.
-
하지만, industry-level code generation으로 도약하기 위해서는 한계가 있다.
-
Generated code의 visual consistency를 유지하지 못한다.
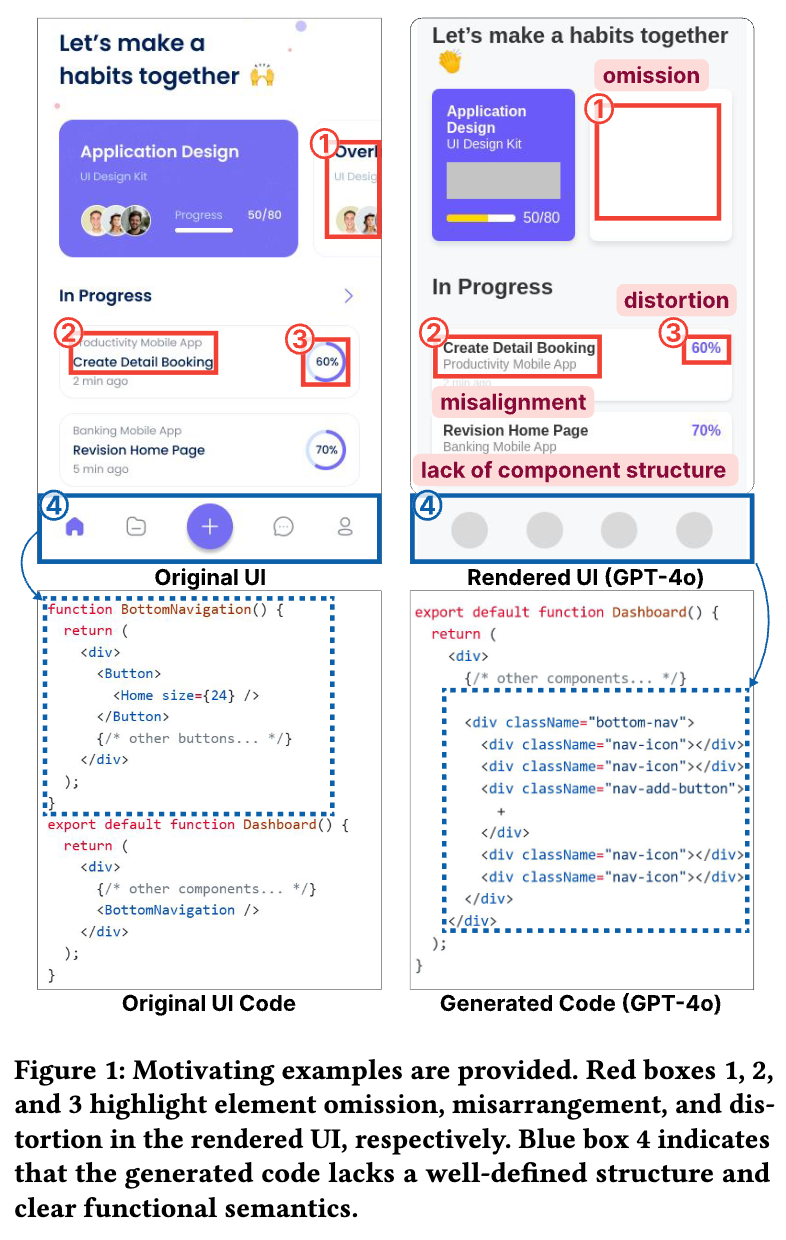
- missing elements
- misaligned layouts
-
왜 발생하나?
- MLLM이 세밀한 UI styles에 대한 이해가 부족하다 $\to$ 재구성(reconstruction)의 충실도(fidelity)가 낮다.
- MLLM이 복잡한 UI structure에 대한 이해가 부족하다 $\to$ missing elements & structural disorganization를 야기
- MLLM이 태생적으로 긴 코드(lengthy coe)를 생성할때 에러율이 늘어난다. $\to$ missing elements
-
해결책
-
요소간의 hierarchical structure를 인지시키면, MLLM의 생성된 code의 모듈성(modularity)가 향상되며, 요소의 반응성(responsiveness)가 향상되는 걸 발견
$\to$ MLLM 모델에게 요소간의 hierarchical structure를 인지능력을 향상 시켜주자!
-
2. Contribution
- MLLM에게 UI Chain-of-Though (CoT)를 활용하여 UI layout을 인지하기 위한 UI Grouping Chaing을 제안함
- visual processing & group reasoning 수행
- MLLM기반 GUI-to-code generation 모델 DesignCoder를 제안함
- input
- GUI mokup 이미지
- meta data (id, bbox, type, etc)
- output
- 구조화된 요소들을 생성함
- input
- Front-end 분야 (Figma community + leading internect company)에서 취득한 300여개의 high-fidelity mockup을 기반으로 SOTA보다 월등한 성능을 보임
3. DesignCoder
-
overall workflow
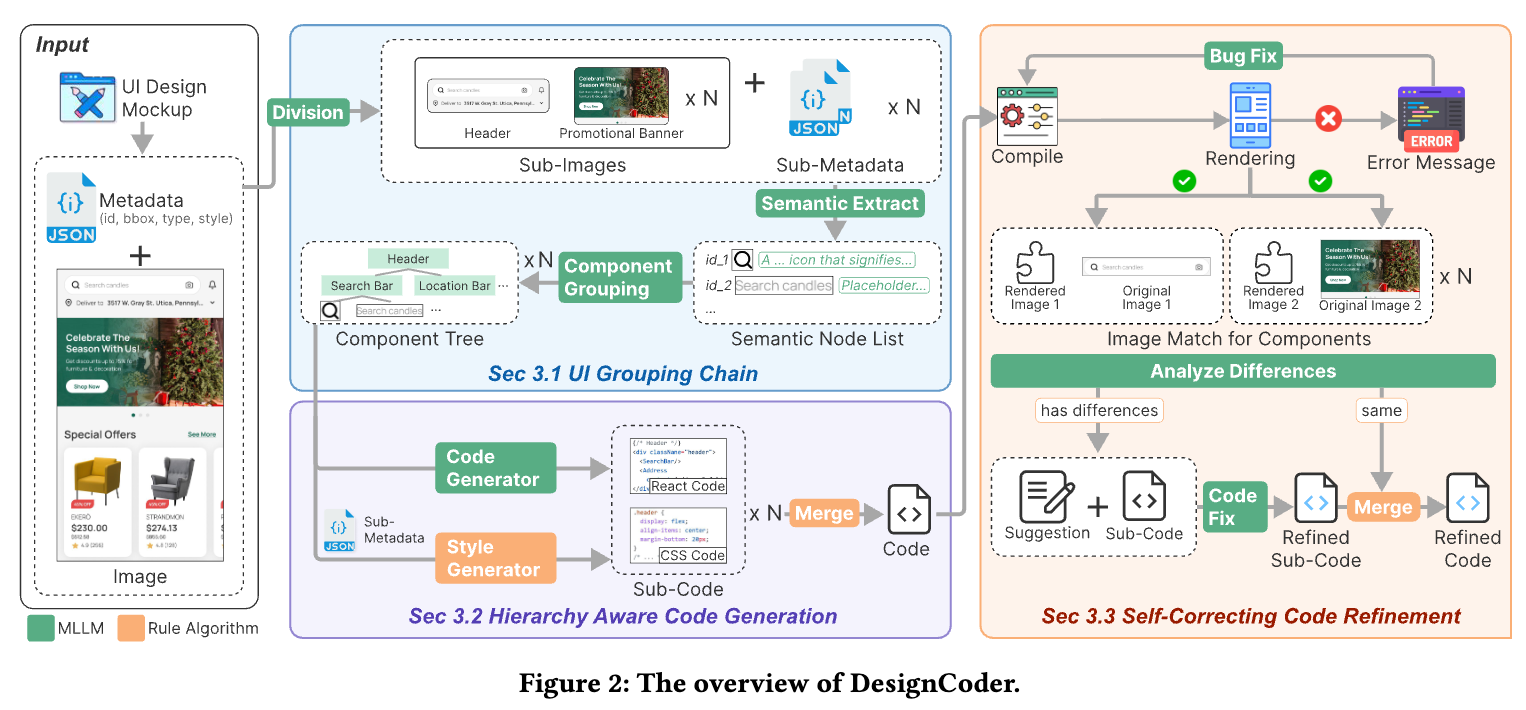
-
목적
- real-world industrial scenario에서 반복적인 front-end code 개발 과정을 가속하기 위함
- code 가 렌더링한 결과가 visual consistency (시각적 일관성 == 어울리는가?), code maintainability (유지관리가 편리한가?), usability (사용성이 편리한가?)를 만족해야함
-
세가지 모듈로 구성
-
UI Grouping Chain: 2가지 step으로 구현
-
Visual Processing: UI screenshot을 시각적 의미(visual semantics)을 기준으로 subregion단위로 그룹핑을 수행함 $\to$ “의그찾”
-
Grouping Reasoning: 2-stage prompting로 개별 subregion에 대한 의미를 분석함
$\to$ 두 정보를 통해 MLLM이 UI 요소를 계층적으로 묶어 UI component(여기서는 요소를 의미) sub-tree를 출력
-
-
Hierarchy Aware Code Generation
- MLLM-based: sub-tree를 분할정복 방식으로 독립적으로 code를 생성함 (React code)
- Rule-based: 입력으로 제공하는 design metadata를 가지고 CSS styles를 출력함 (CSS code)
-
Self-Correction code refinement
- visual comparison으로 correct해야할 영역 검출하고 code를 변경함
-
3.1 UI Grouping Chain
Design MockUp을 기반으로 정밀한 그룹을 생성하는 것을 어려운 작업이므로 관리 가능한(managable) 3가지 subtask로 세분화함
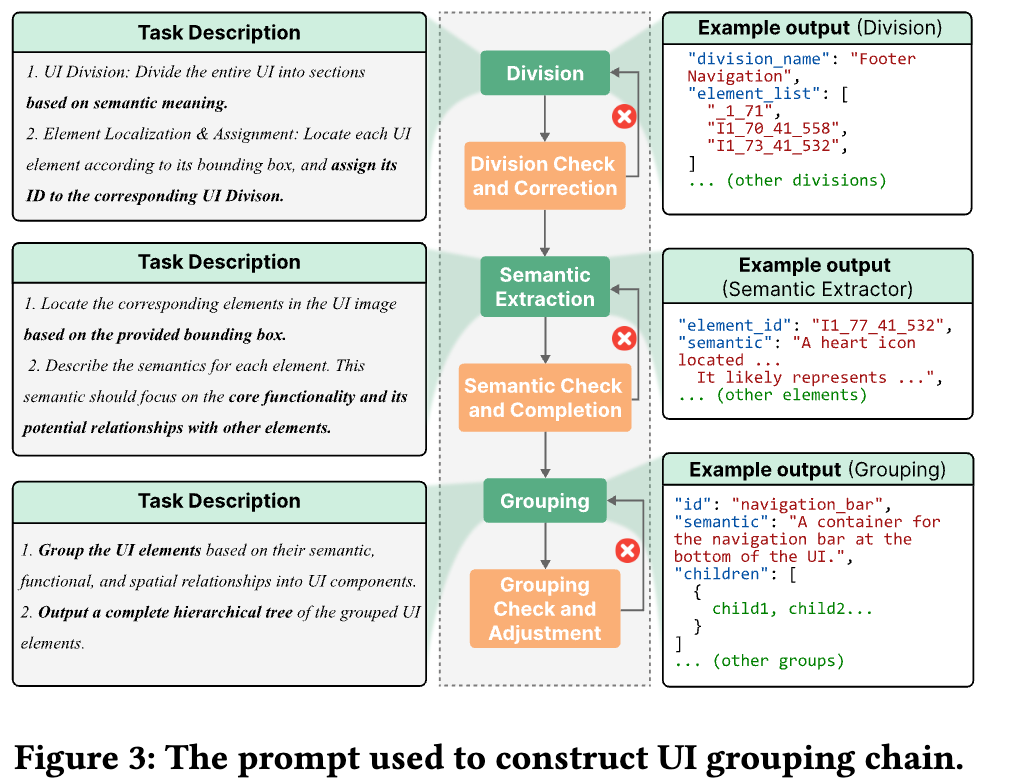
-
UI division
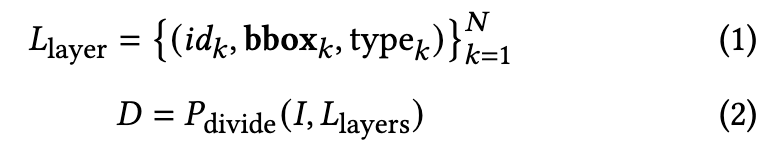
- input $L_{layers}$
- design file에서 meta data를 수집함
- id: component(요소)의 unique id
- type: component의 카테고리
- bbox: component의 위치 & 크기 정보
- design file에서 meta data를 수집함
- output $D$
- $D$: UI가 분할된 결과로, 각 영역의 위치와 크기를 정의하는 여러 요소 하위 목록(element sublists)을 의미함
- $P_{divide}$: 시각적 처리를 위한 프롬프트. MLLM(Multimodal Large Language Model)에게 UI 이미지와 레이어 정보를 입력으로 주어 UI를 여러 영역으로 분할하도록 지시하는 역할 수행
- $ I$: 입력 UI 디자인 목업 이미지
- input $L_{layers}$
-
Semantic extraction
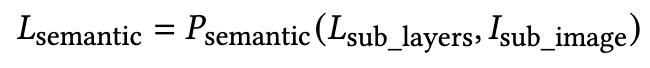
-
$L_{semantic}$: UI 하위 영역에서 추출된 레이어들의 Semantic Annotation 리스트. 각 요소에 대한 의미론적 정보가 포함됨 (image caption)
-
$P_{semantic}$: UI 레이어를 위한 특별히 설계된 Semantic Extraction Prompt. MLLM(Multimodal Large Language Model)이 UI 요소의 의미를 이해하도록 돕는 역할
ex. 검색 bar 내부에 존재하는 text요소인 경우:
“A placeholder text displaying ’Search for fruit salad combos,’ which suggests the intended search scope or example use case for the search bar.
-
$L_{sub_layers}$: 분할된 UI 하위 영역에 해당하는 레이어들의 리스트. 각 레이어는 id, type, bbox와 같은 메타데이터를 포함
-
$I_{sub_image}$: 그룹박스에 의해 분할된(crop된) UI 이미지. MLLM이 시각적 정보를 바탕으로 의미를 추출하도록 돕는 역할.
$\to$ 그외 후처리 로직을 추가하여 visual enhancement & correction을 추가수행함
ex. “challenging-to-identify” 요소를 annotation
-
-
Component grouping
중복 요소 제거 수행하여 계층적으로 구조화된 element list를 추출
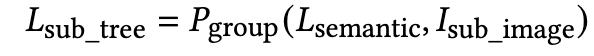
- $L_{sub_tree}$: UI 디자인 내에서 하위 영역에 있는 요소들이 구조화된 트리 형태로 그룹화된 결과.
- $P_{group}$: 구조화된 그룹화 프롬프트. MLLM (Multimodal Large Language Model)이 요소들을 계층적 구성 요소 트리로 구성하도록 안내하는 역할
3.2 Hierarchy-Aware Code Generation
-
완성된 프론트엔드를 위해서는 두 가지 step이 필요
-
Component code $\to$ UI grouping chain의 출력값을 입력으로 활용하여 code generation
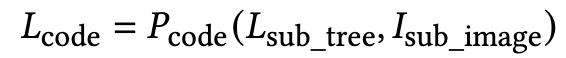
- $L_{code}$: 수식의 결과로 생성되는 컴포넌트 코드. DesignCoder는 UI를 여러 서브 영역으로 나눈 후, 각 서브 영역에 해당하는 코드를 독립적으로 생성. 그 서브 영역의 코드 조각
- $P_{code}$: 컴포넌트 코드 생성을 위해 다중 모달 대규모 언어 모델(MLLM)에게 제공되는 코드 생성 프롬프트.역할 지정(예: React 전문가), 작업 설명, 세부 요구사항, 예시 출력 등 네 단계로 구성됨
- $L_{sub_tree}$: UI Grouping Chain 단계를 통해 생성된, 특정 UI 서브 영역에 대한 계층적 UI 컴포넌트 서브 트리. 서브 영역 내 컴포넌트들의 계층 구조와 의미적 관계를 담고 있으며, 코드 구조 생성의 기반이 됨
- $I_{sub_image}$: 코드를 생성하려는 특정 UI 서브 영역에 해당하는 서브 이미지. MLLM은 이 이미지를 보고 시각적 정보를 이해하여 코드 생성에 활용함
-
CSS code
- Visual style을 제공함 (colors, layout, borders, spacing, etc)
- Leaf-node & Non-Leaf node간에는 상대적 coordinate로 정의됨
- text
- style, color, font, weight $\to$ 자동으로 relative size, spacing, line height은 계산됨
- padding, borders, shadows, corner styles $\to$ design metada에 의해 결정됨
- Visual style을 제공함 (colors, layout, borders, spacing, etc)
-
3.3 Self-correcting Code Refinement
-
기존 연구에서는 code의 parsing이 잘 수행되는지만 평가함 $\to$ correctly parsing된다는 것이 visually & functionally accurate한 것을 보장하지 못함
-
visual consistency & responsive layout인지 system적으로 판단하기 위해 Self-correctiong Code Refinement 을 추가함
-
구현
-
Appium (UI automation testing tool)로 rendering한 페이지의 screenshot을 캡쳐 & component attribute를 추출 (bbox, type, text content, herarchical structure, etc)
-
Component tree의 component ID를 기반으로 image를 추출하여 정답과 비교
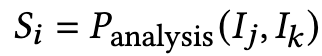
- $S_i$: i번째 컴포넌트에 대한 수정 제안. DesignCoder가 렌더링된 컴포넌트와 원본 디자인을 비교한 후, 오류를 식별하고 해당 컴포넌트 코드를 어떻게 수정해야 할지에 대한 제안을 담고 있음.
- $P_{analysis}$: 시각 분석 프롬프트. 이것은 두 개의 이미지(원본 이미지와 렌더링된 이미지)를 입력받아 분석하여 수정 제안을 출력하는 MLLM에 주어지는 명령어 또는 질의를 의미. 주로 이미지 간의 시각적 불일치(예: 요소 위치, 스타일 오류, 누락된 요소 등)를 감지하는 데 초점을 맞춤.
- $I_j$: 원본 컴포넌트 이미지. DesignCoder가 입력으로 받은 UI 디자인 모형에서 특정 j번째 컴포넌트에 해당하는 이미지 영역을 추출한 것. 코드 생성의 목표가 되는 기준 이미지.
- $I_k$: 렌더링된 컴포넌트 이미지. DesignCoder가 생성한 코드를 실행하여 화면에 렌더링한 후, 특정 k번째 컴포넌트에 해당하는 이미지 영역을 추출한 것. 원본 디자인$I_j$과 일치하는지 확인해야 함.
-
Repaired Prompt
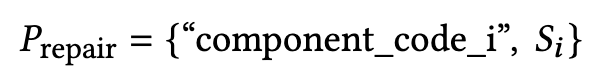
-
$P_{repair}$: 자체 교정을 위해 MLLM에게 주어지는 구조화된 코드 수정 프롬프트.
-
$component_code_i$, $S_i$: $P_{repair}$ 프롬프트의 내용
-
“component_code_i”: 수정이 필요한 i번째 컴포넌트의 코드 스니펫. 전체 페이지 코드 대신 특정 컴포넌트의 코드 부분만 제공함으로써 MLLM이 수정 작업에 더 집중할 수 있도록 함
-
$S_i$: i번째 컴포넌트에 대한 수정 제안. 시각적 분석 프롬프트 $P_{analysis}$를 사용하여 원본 컴포넌트 이미지와 렌더링된 컴포넌트 이미지를 비교하여 도출.
ex. 특정 요소가 누락되었거나 레이아웃이 잘못되었는지 등을 설명
-
-
-
Correction 전/후 비교
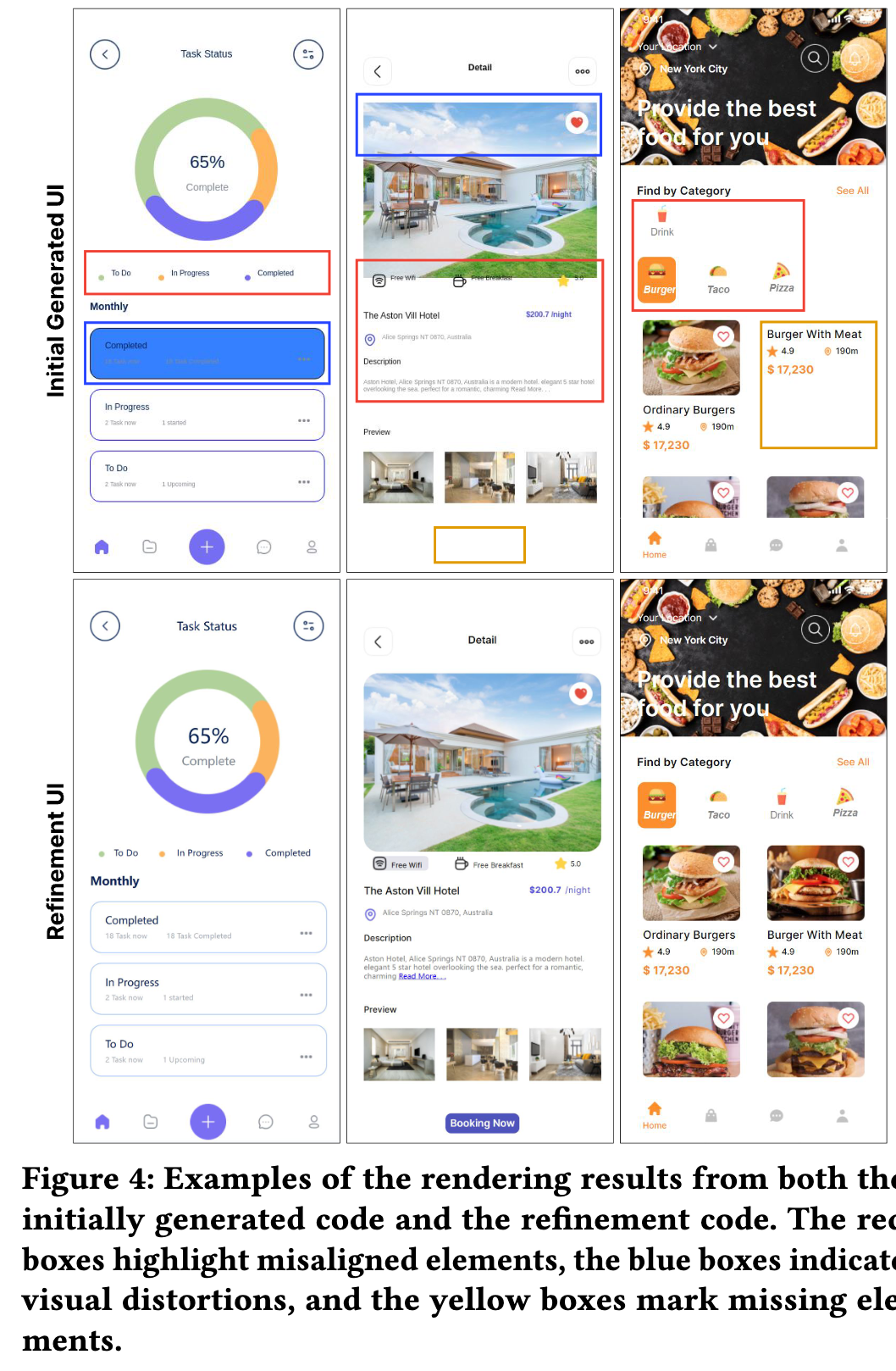
-
첫 번째 예시 (왼쪽): Task Status UI
- Initial Generated UI
- 빨간색 상자는 ‘To Do’, ‘In Progress’, ‘Completed’ 항목의 정렬 문제를 보여줍니다. 파란색 상자는 ‘Completed’ 항목 자체의 시각적 문제를, 노란색 상자는 각 항목 옆에 표시되어야 할 숫자(‘18 Task Completed’, ‘1 started’, ‘1 Upcoming’)가 누락되었음을 나타냅니다.
- Refinement UI
- 자체 수정 과정을 통해 빨간색 상자로 표시된 항목들이 올바르게 정렬되었고, 파란색 상자로 표시된 ‘Completed’ 항목의 시각적 문제도 해결되었습니다. 노란색 상자로 표시된 숫자들도 정확하게 표시되었습니다. 즉, 요소 누락과 레이아웃 불일치 오류가 수정되었습니다.
- Initial Generated UI
-
두 번째 예시 (중앙): Hotel Detail UI
- Initial Generated UI
- 파란색 상자는 상단 배경 이미지의 색상이나 필터가 왜곡되었음을 보여줍니다. 빨간색 상자는 ‘Free Wifi’, ‘Free Breakfast’, 별점 아이콘의 레이아웃이 올바르지 않게 정렬되었음을 나타냅니다. 하단의 노란색 상자는 ‘Preview’ 이미지 아래에 ‘Booking Now’ 버튼이 누락되었음을 시사합니다.
- Refinement UI
- 파란색 상자로 표시된 배경 이미지의 왜곡된 스타일이 수정되었습니다. 빨간색 상자로 표시된 요소들이 올바르게 정렬되었습니다. 노란색 상자로 표시된 ‘Booking Now’ 버튼이 추가되었습니다. 즉, 스타일 왜곡, 레이아웃 불일치, 요소 누락 오류가 수정되었습니다.
- 세 번째 예시 (오른쪽): Food Ordering UI
- Initial Generated UI
- 파란색 상자는 상단 배경 이미지와 텍스트 오버레이의 시각적 왜곡을 보여줍니다. 빨간색 상자는 카테고리 버튼(‘Burger’, ‘Taco’, ‘Drink’, ‘Pizza’)의 레이아웃과 정렬 문제를 나타냅니다. 하단의 노란색 상자들은 각 버거 항목 아래에 표시되어야 할 별점, 거리, 가격 정보가 누락되었음을 나타냅니다.
- Refinement UI
- 파란색 상자로 표시된 상단 배경 이미지의 왜곡이 수정되었습니다. 빨간색 상자로 표시된 카테고리 버튼들이 올바르게 정렬되었습니다. 노란색 상자로 표시된 각 버거 항목의 상세 정보(별점, 거리, 가격)가 추가되었습니다. 즉, 스타일 왜곡, 레이아웃 불일치, 요소 누락 오류가 수정되었습니다.
- Initial Generated UI
- Initial Generated UI
-
-
4. Experiments
- Research Questions
- Effectiveness: visual consistency & structural similarity가 기존보다 얼마나 향상되었는가?
- Ablation Study: 개별 제안 방식이 각각 얼마나 성능 향상에 기여하는가?
- User Study & Case Study: user관점에서는 인지된 quality가 어떻게 되는가?
4.1 Dataset
- 300개(250:Figma / 50:Sketch)의 mobile app. UI의 mockup을 활용하여 5가지 카테고리로 구축 $\to$ Figma에서 export해서 image / metadata 추출
- entertainment
- education
- health
- shopping
- travel
4.2 Experimental Setup
-
Baselines
- Prototype2Code: handcrafted semtaic group technique, element grouping을 사용하여 layout tree를 구성함. HTML skeleton code & CSS code를 MLLM이 생성함
- DeclarUI: SAM + GroundingDiNO를 사용하여 요소 검출 & Description을 생성함. 해당 Description은 MLLM에 입력으로 넣음 (GPT-4o)
-
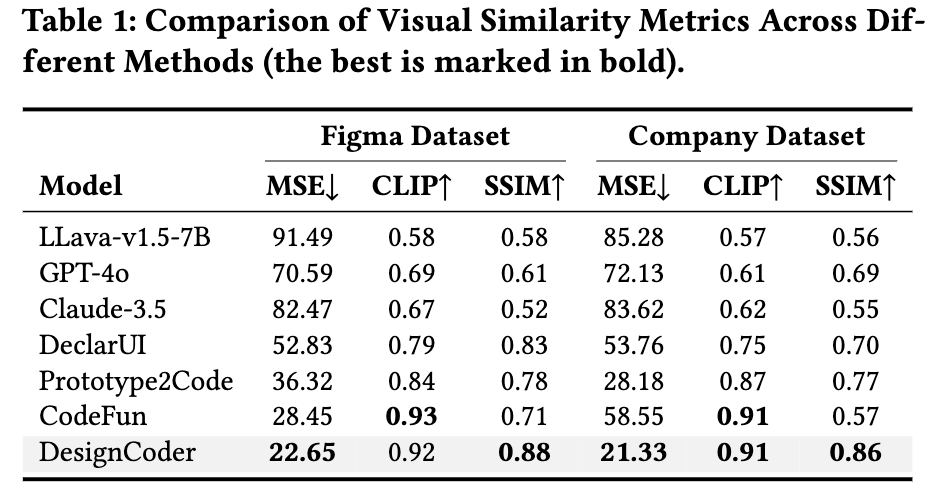
Evaluation Metrics
-
MSE: pixel-wise mean squared error. 낮을수록 좋음
-
CLIP Score: clip image encoder간의 유사도. 높을수록 좋음
-
Structural Similarity Index Measure (SSIM): layout, compositional 정확성, 공간적 배열의 유사도 등을 평가함. 높을수록 좋음
$\to$ Codefun이라는 상용 code generation platform을 통하여 생성된 코드를 기반으로 저자가 한번 검수 하여 GT를 생성.
-
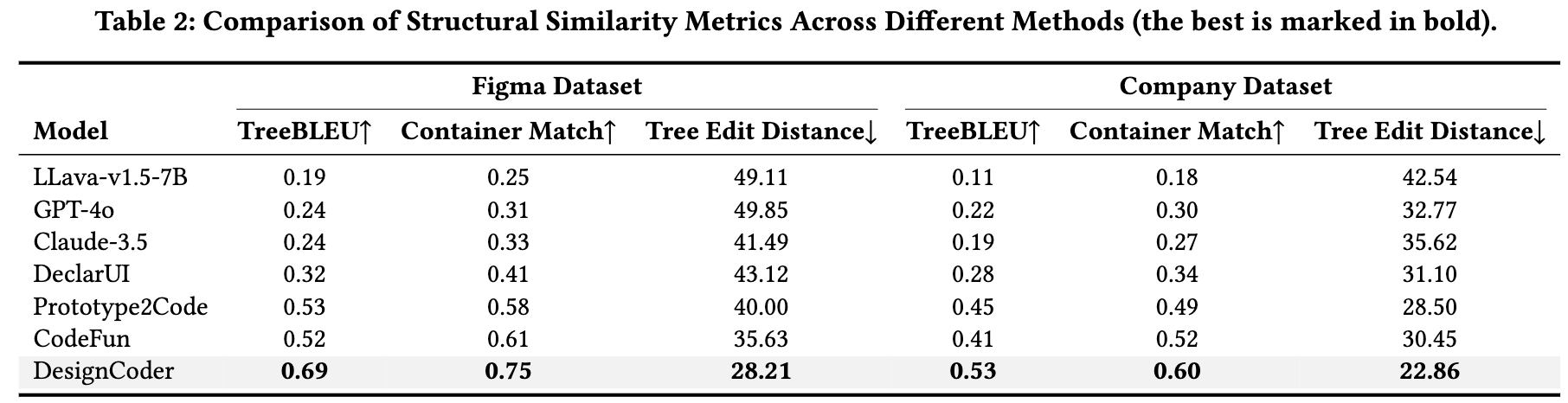
TreeBLEU: 생성된 HTML에서 height-1 subtree을 대상으로 DOM tree의 유사도를 비교함.
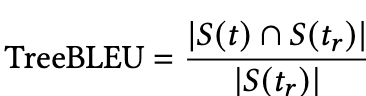
- $t$: 생성된 코드의 DOM 트리 (또는 해당되는 계층 구조 트리)
- $t_r$: 정답(Ground truth) 코드의 DOM 트리 (또는 해당되는 계층 구조 트리).
- $S(t)$: 트리 t에 포함된 모든 높이 1의 서브트리(subtree)들의 집합. 높이 1의 서브트리는 부모 노드와 바로 아래 자식 노드들로 구성된 작은 트리 조각임.
- $S(t_r)$: 정답 트리 $t_r$에 포함된 모든 높이 1의 서브트리들의 집합.
-
$ S(t) \cap S(t_r) $: 생성된 트리 t의 높이 1 서브트리 집합과 정답 트리 $t_r$의 높이 1 서브트리 집합의 교집합 크기. 즉, 생성된 코드와 정답 코드 모두에 공통적으로 나타나는 높이 1 서브트리의 개수. -
$ S(t_r) $: 정답 트리 $t_r$에 포함된 전체 높이 1 서브트리의 개수.
-
Tree Edit Distance (TED): 최소 요구되는 편집 수행 횟수
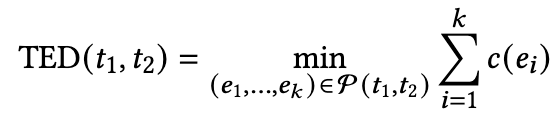
- $TED(t_1, t_2)$: 비교 대상인 두 트리 $t_1$과 $t_2$ 사이의 트리 편집 거리. 이 값이 낮을수록 두 트리의 구조가 더 유사하다는 의미.
- $t_1, t_2$: 비교 대상이 되는 두 개의 트리. 논문에서는 생성된 코드의 컴포넌트 트리와 실제 UI 코드의 컴포넌트 트리를 의미.
- $e_1, …, e_k$: 트리를 변환하기 위한 일련의 편집 작업 순서. 각 $e_i$는 하나의 편집 작업을 나타냄.
- $\mathcal{P}(t_1, t_2)$: 트리 $t_1$을 트리 $t_2로 변환하는 모든 가능한 편집 작업 순서 집합.
- $k$: 주어진 편집 작업 순서에 포함된 총 편집 작업의 개수.
- $c(e_i)$: i번째 편집 작업 $e_i$의 비용. 각 편집 작업(예: 노드 삽입, 삭제, 치환)에는 미리 정의된 비용이 할당됨. 일반적으로 각 작업당 비용은 1로 설정.
-
4.3 Effectiveness
-
Visual metric 결과
-
Structural Metric 결과
4.4 Ablation Study
-
UI Grouping Chain & Refining 유/무에 따른 성능변화

4.5 User Study & Case Study
-
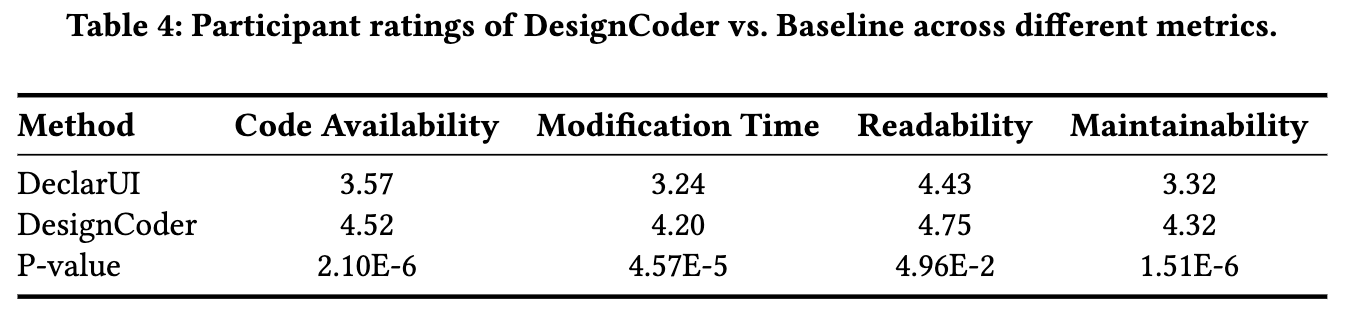
User study 평가 결과
-
정성적 결과
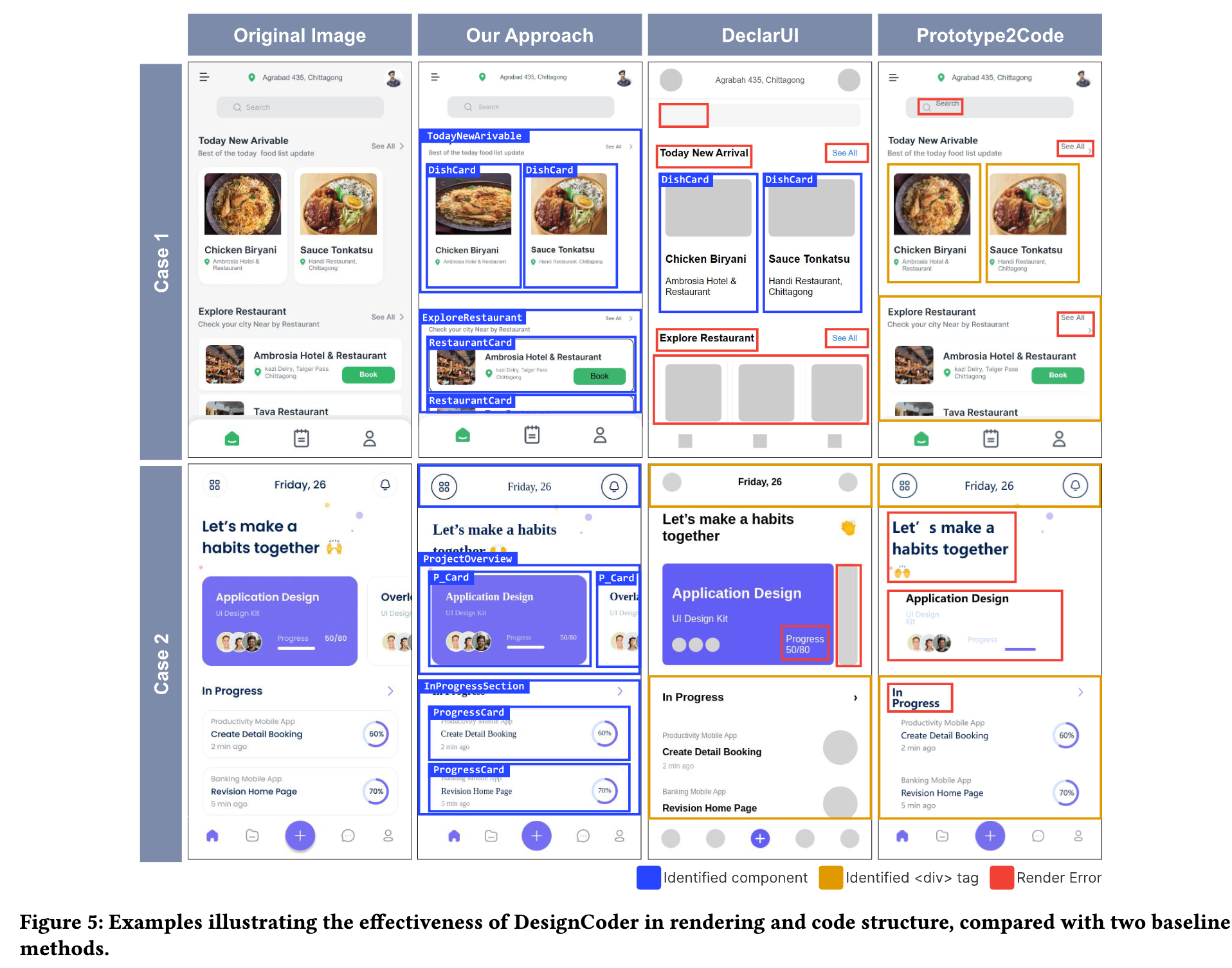
-
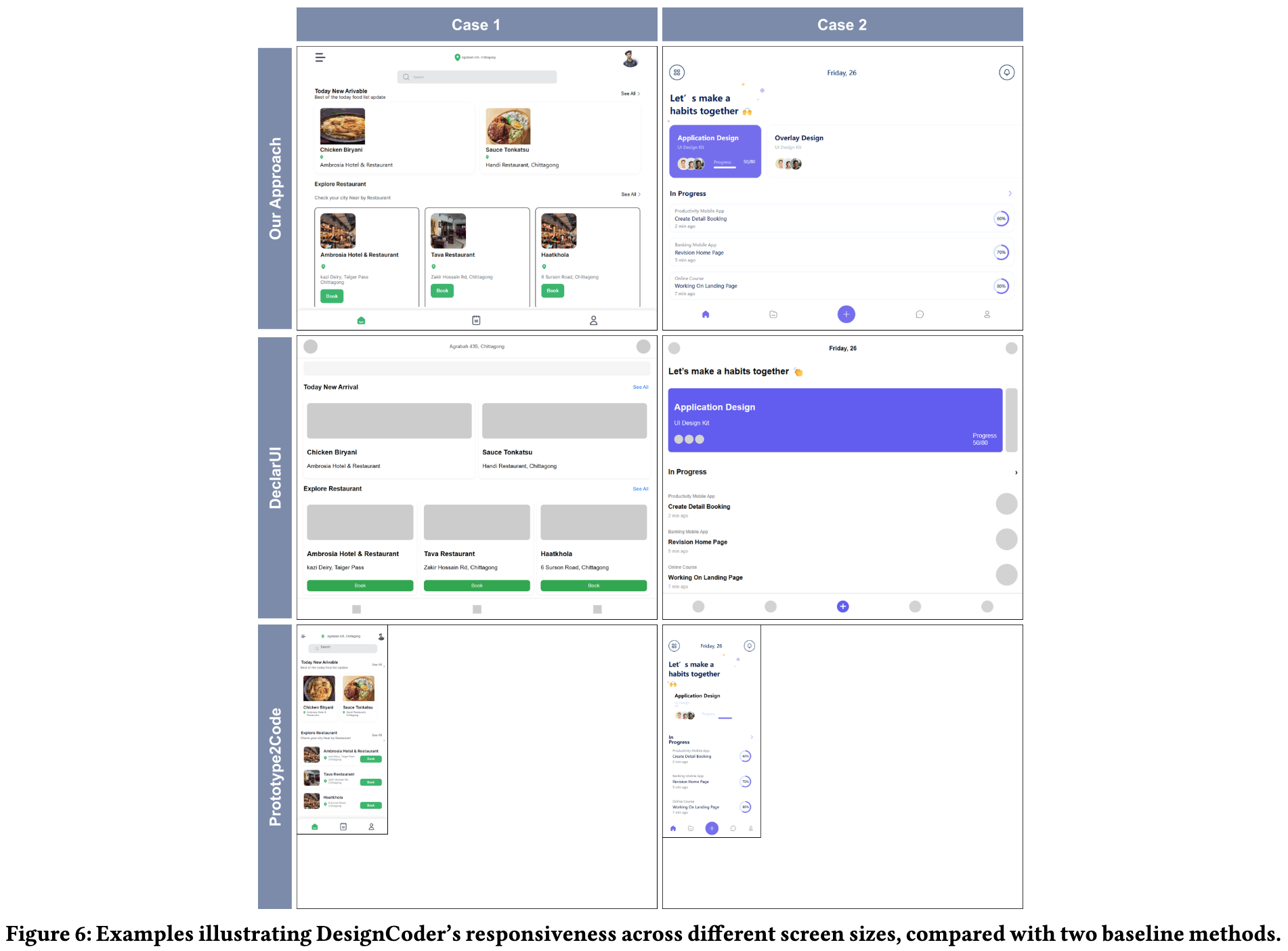
Window Size에 따라 좋은 성능(responsive behavior)을 보임