[MM] Dense Connector for MLLMs
[MM] Dense Connector for MLLMs
- paper: https://arxiv.org/pdf/2405.13800
- github: https://github.com/HJYao00/DenseConnector
- NeurIPS 2024 accepted (인용수: 7회, 24-11-25 기준)
- downstream task: Multimodal reasoning (VQA, Image Captioning etc)
1. Motivation
-
대부분의 MLLM은 마지막 vision encoder의 마지막 layer feature 값 (high-level feature)만 사용
$\to$ pretrained visual encoder를 fully 잘 사용중인걸까?
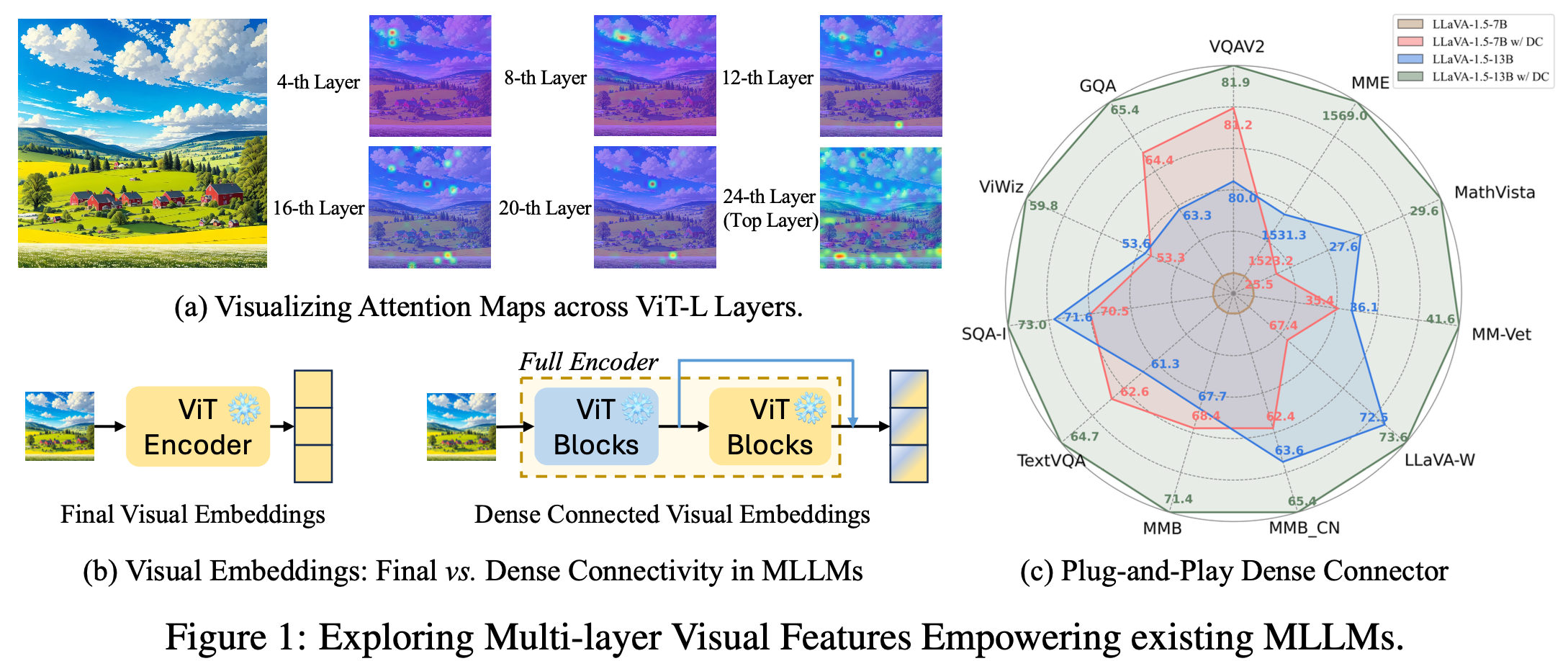
- 여러 layer의 feature를 고루 사용하는게 낫지 않을까?
- Offline 추출하면 “free lunch”로 사용 가능
- simple & effective한 방식
2. Contribution
- Simple & Effective한 plug-and-play 방식의 “Dense Connector”를 제안
- MLLM의 visual feature를 향상시킴
- 추가 계산량 없음
- 다양한 scale (2B $\to$ 70B), visual encoders (Clip-ViT, SigLit-ViT-SO), image resolution (336px $\to$ 768px) , dataset scales, 그리고 LLM architecture (LLaVa-v1.5, LLaVa-NeXT, Mini-Gemini) 등에서 실험
- 11개의 MLLM benchmark + 8개의 video benchmark에서 최고 성능
3. Dense Connector
3.1 Overall architecture
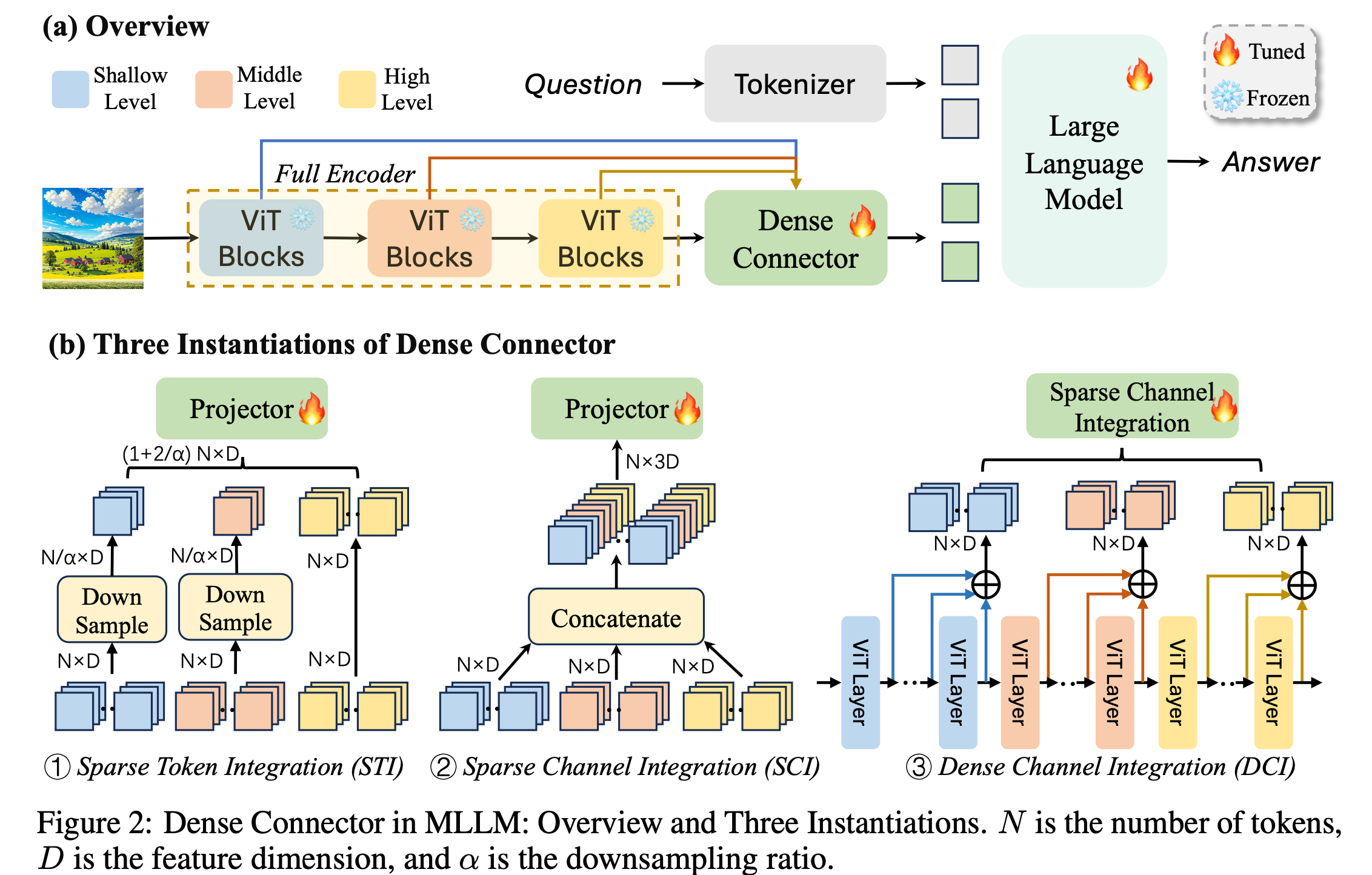
(a) LLaVa-v1.5 기반 구조.
(b) 3가지 conenctor 구조로 ablation study 진행 $\to$ 성능이 제일 좋은 3번 (DCI) 방식 채택
- 3가지 모듈
- Visual Encoder
- input: $X_i \in \mathbb{R}^{H \times W \times C}$
- output: $V \in \mathbb{R}^{L \times N \times D_v}$
- L: Number of layers
- N: patch token 갯수
- $D_v$: visual feature dimension
- Dense Connector
- 2개의 MLP, 1개의 GeLU activation layer로 구성
- LLM
- Visual Encoder
3.2 Dense Connector
-
Sparse Token Integration (STI)
-
Token 기준으로 concate를 수행 (Spatial-wise augmentation)
-
단점: token 수가 증가하여 LLM의 computational cost quadratically 증가
$\to$ 마지막 layer외에는 $\alpha=8$만큼 average pooling하여 token 수 조절
$\to$ $l_1, l_2, L=8, 16, 24$ 사용
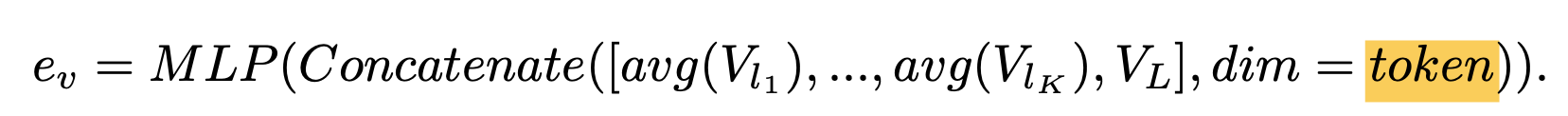
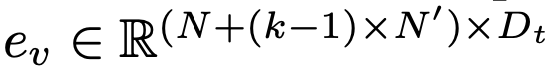
-
-
-
Sparse Channel Integration (SCI)
-
(Feature) Channel 기준으로 concate를 수행 (Channel-wise augmentation)
-
장점: visual token수가 그대로고, 추가 모듈이 없이 computational overhead가 적음
-
단점: 모든 layer의 feature를 사용할 경우, 계산량이 증가함
$\to$ $l_1, l_2, L=8, 16, 24$ 사용
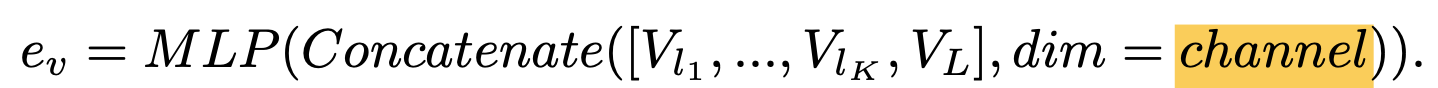
-
-
-
Dense Channel Integration (DCI)
-
SCI를 근간으로 하되, 모든 layer의 feauture를 사용하며 computation cost를 유지하는 방법 고안
-
L개의 layer를 D개의 group으로 쪼갬
$\to$ (1-13, 14-26)
-
각 D개의 group은 이웃하는 M개의 layer의 조합임 $\to$ M개의 이웃하는 feature의 합으로 표현. 즉, M배 차원 축소
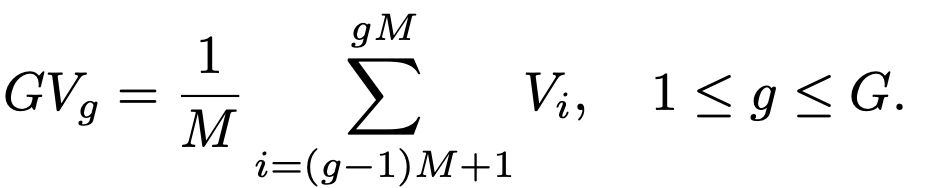
- $GV_g$: g번째 visual feature group
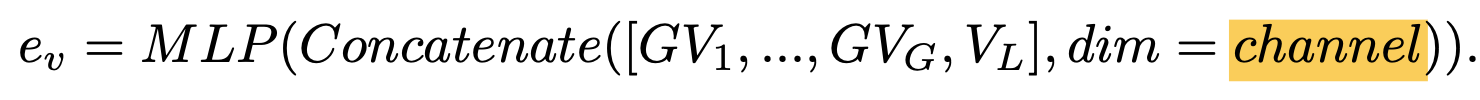
-
-
-
Efficient Dense Connector for Visual Token Optimization
- 목적: 이미지당 수백~수천개의 visual token 발생 $\to$ parameter-free (average pooling)을 사용하여 visual token을 downsampling하여 약 3배 inference speed를 향상
-
Training-Free Extension from Image $\to$ Video Conversational Models
-
FreeVA를 따라 video를 T 개의 frame으로 uniform sampling으로 쪼개어 process 수행
$\to$
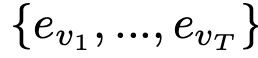 embedding vector 추출
embedding vector 추출
-
4. Experiments
-
환경: LLaVA-v1.5기준 A100 GPU 40GB x 8대로 학습
-
학습
- pretraining: Dense Connector만 학습 (random initialized)
- finetuning: DC + LLM 학습
-
정량적 결과
-
Image MLLM Benchmark
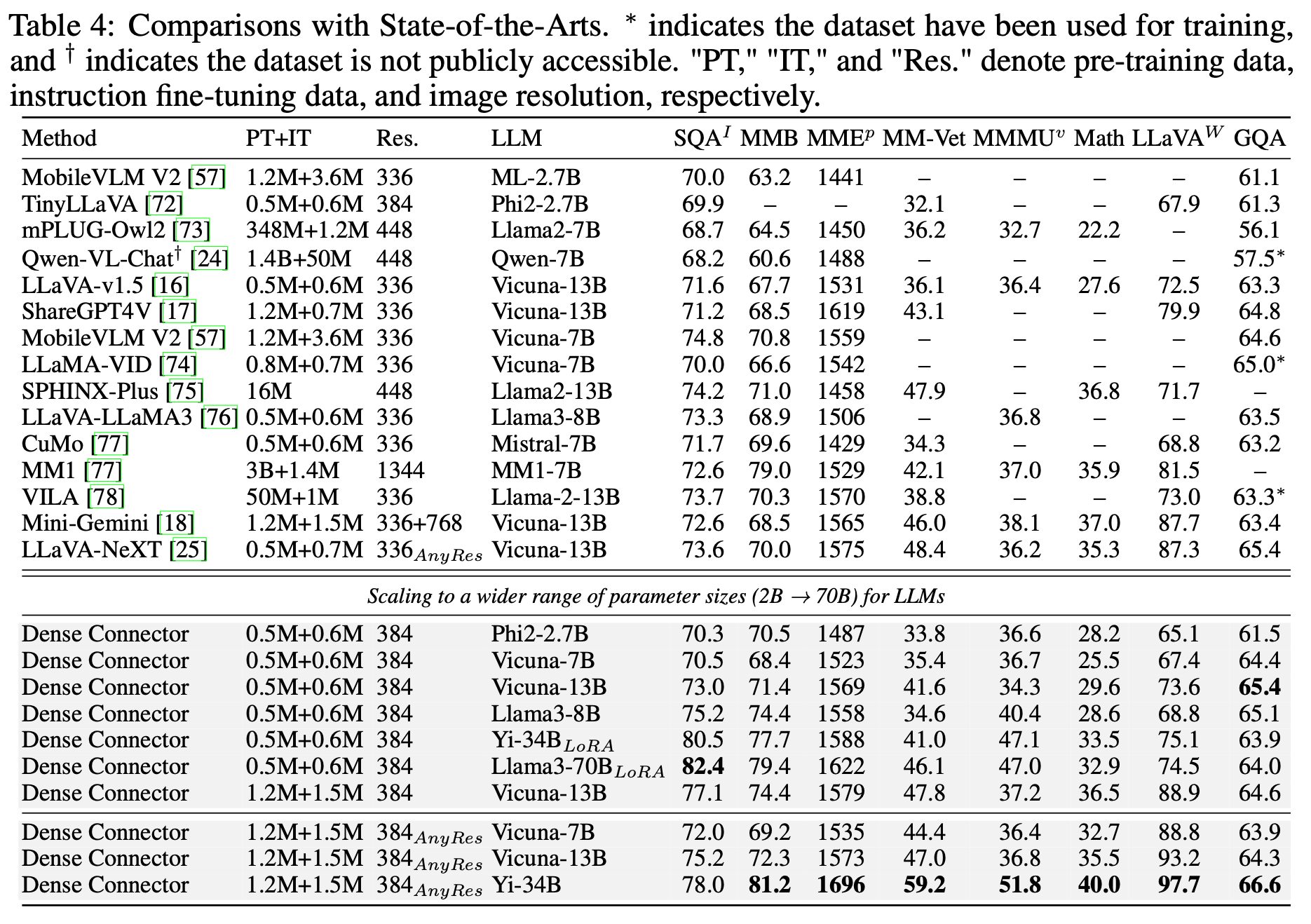
-
Video Benchmark
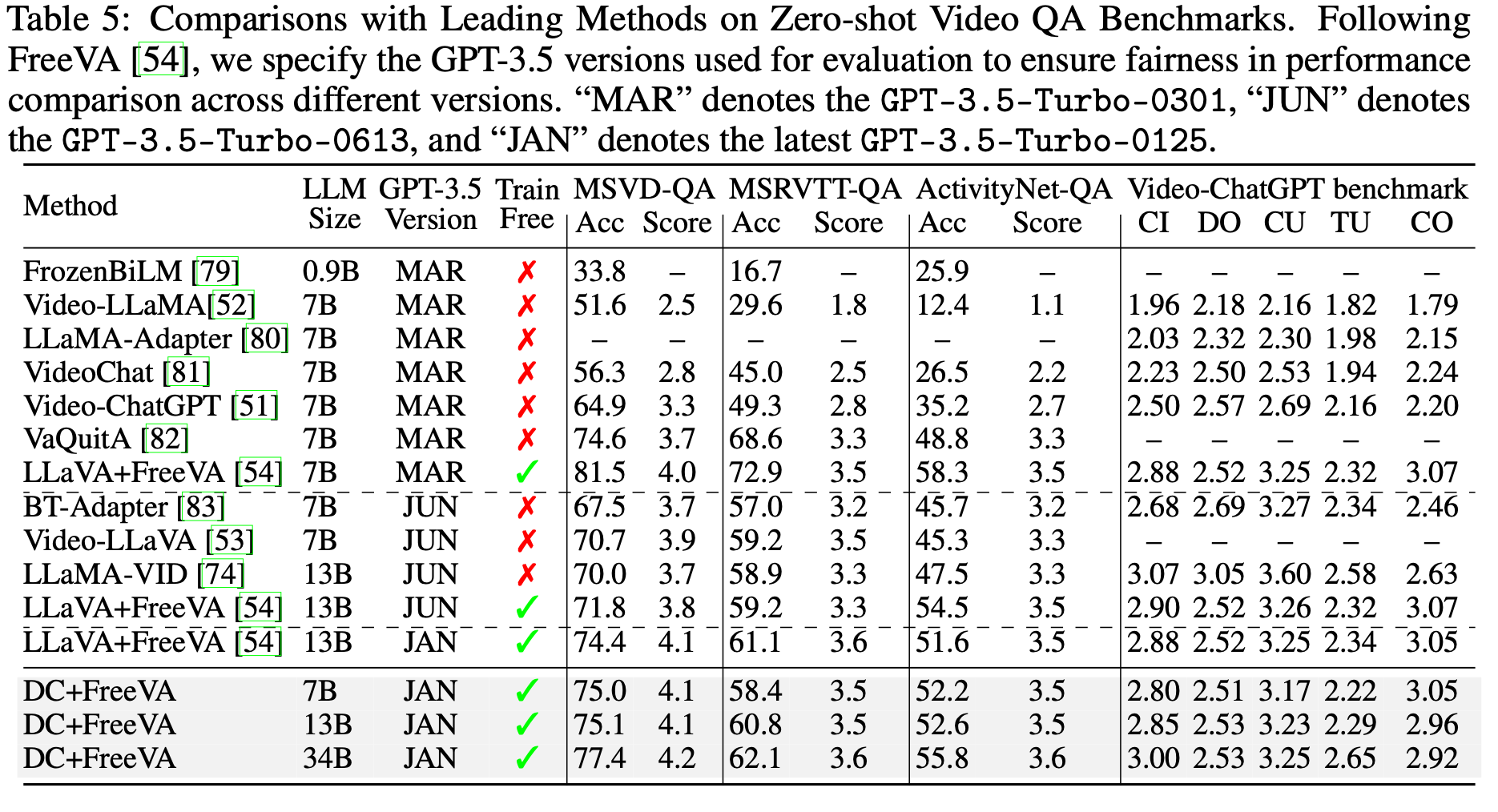
-
-
정성적 결과
-
Image & Video VQA

-
Flowchart understanding
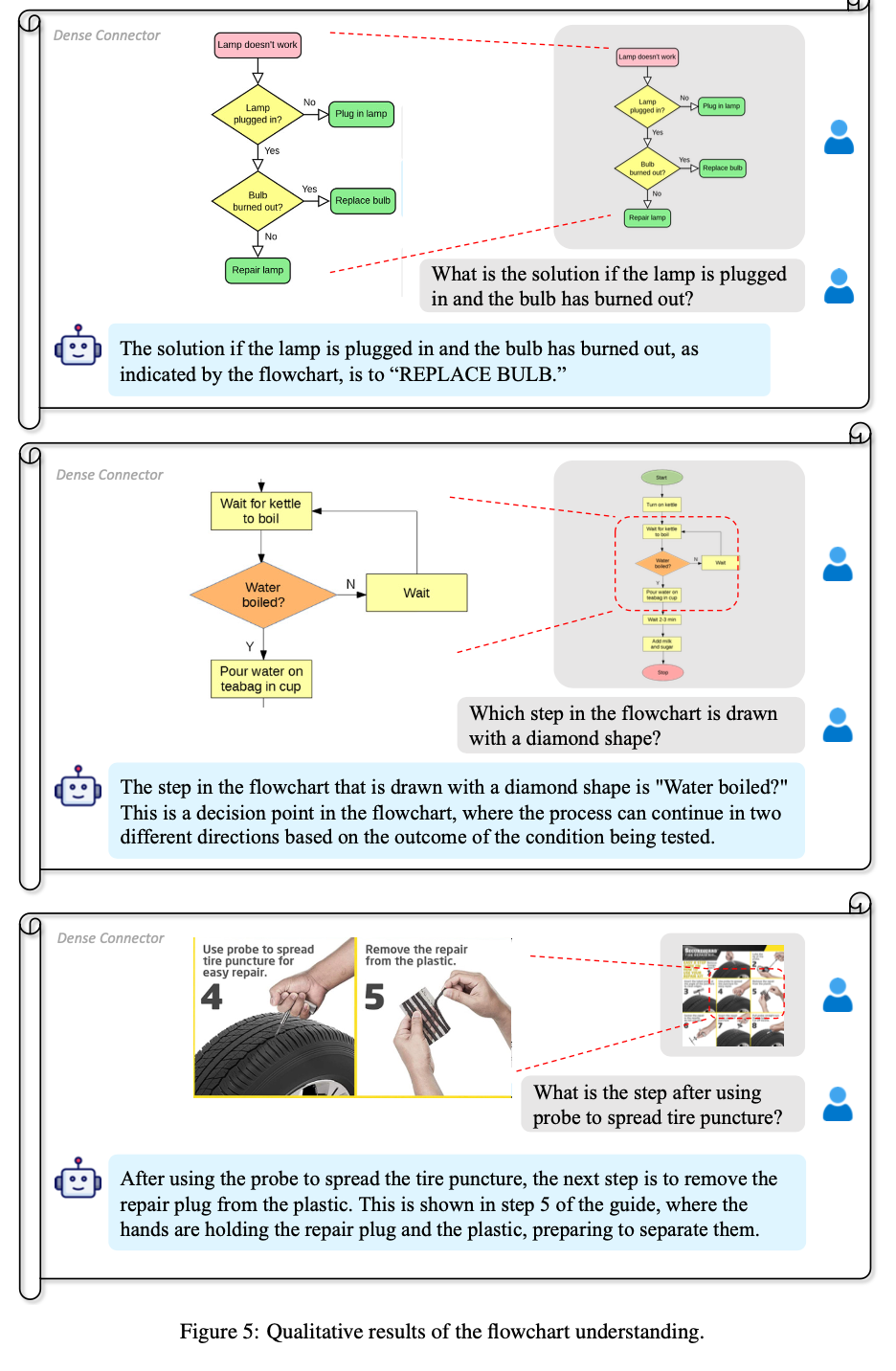
-
수학 문제 풀이

-
-
Meme 이해

-
섬세한 이해

-
영화 이해

-
비디오 이해


-
-
Visual Token 수
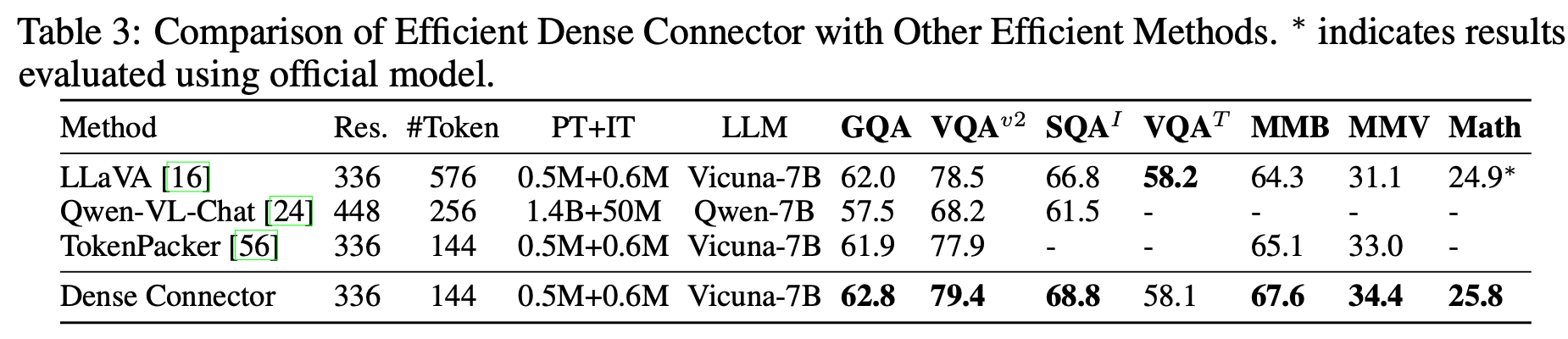
-
Ablation Study
-
다양한 Visual Encoder & Resolution & Training Dataset
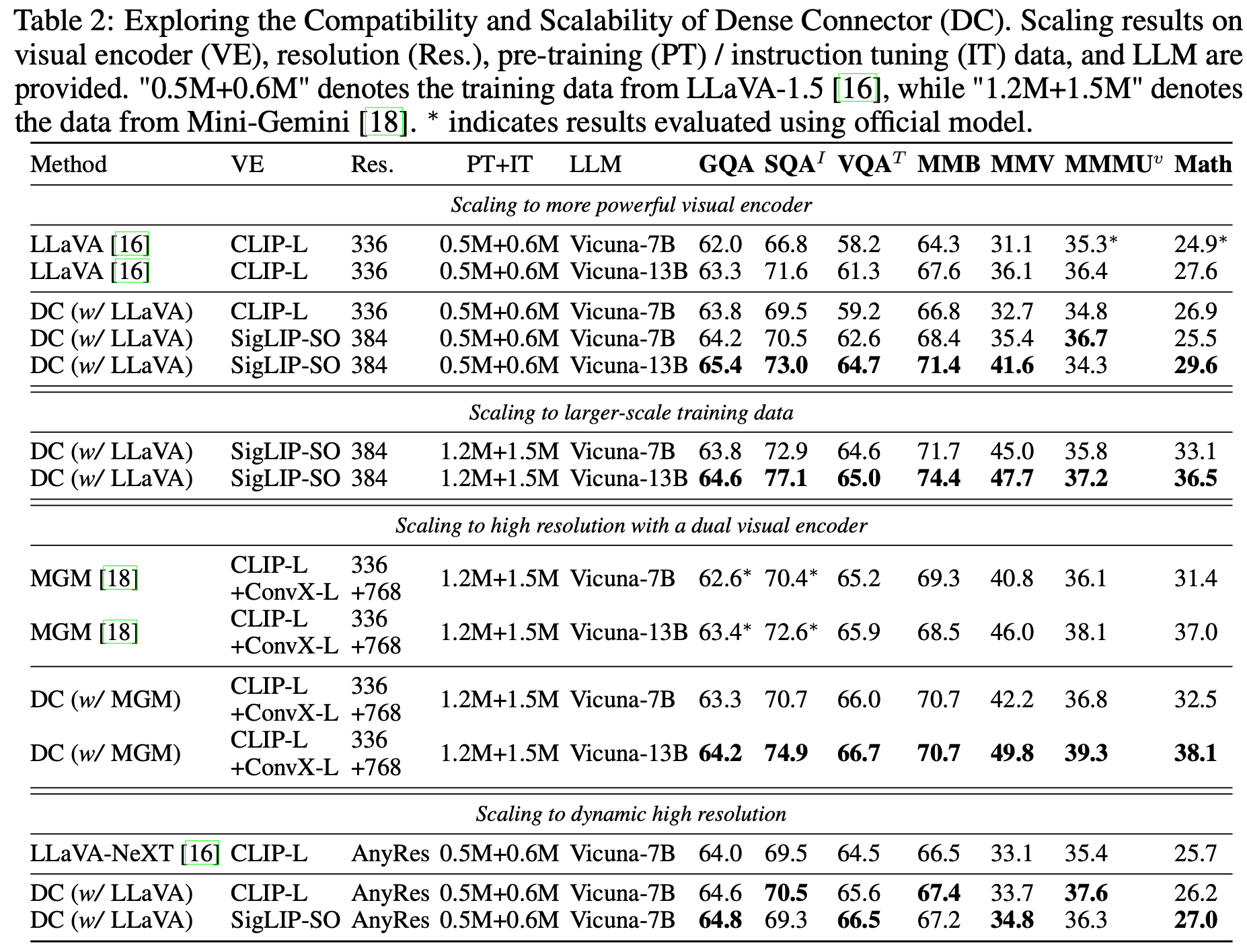
-
DC layer 구조
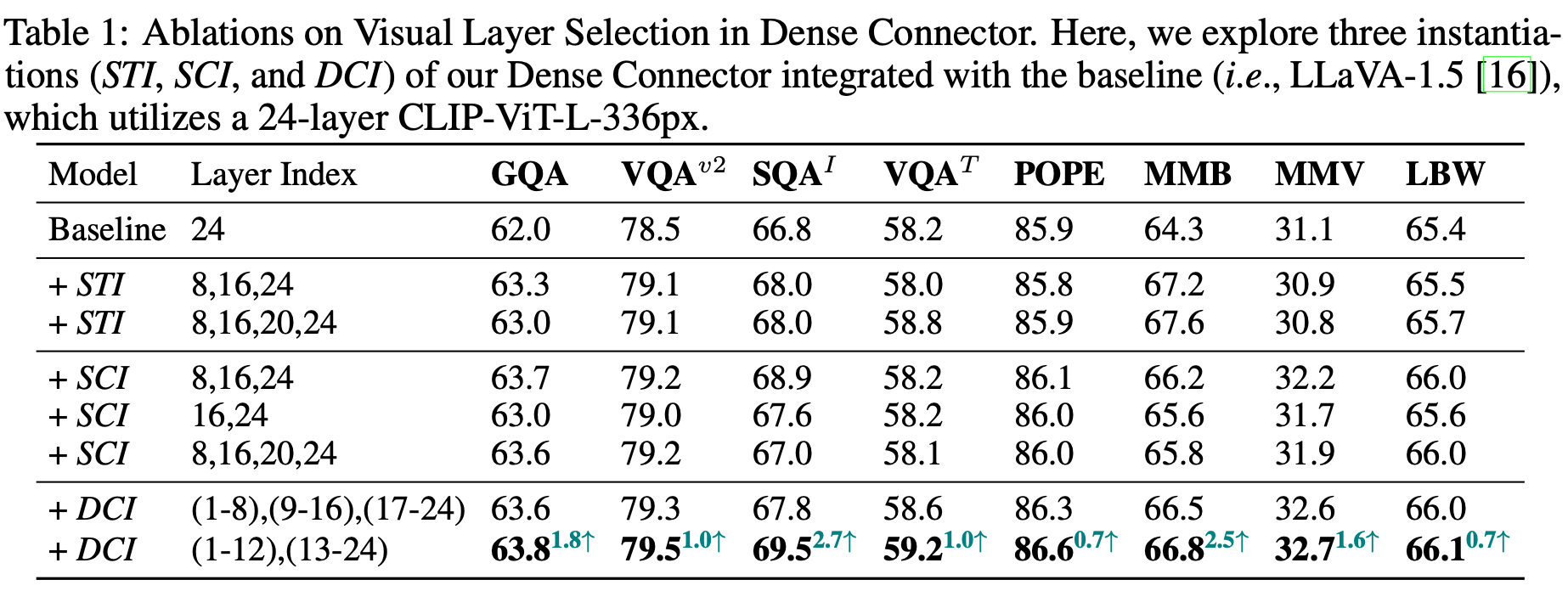
-
Learnable Parameter 추가시 성능이 향상되지 않아, 뺐다고 함
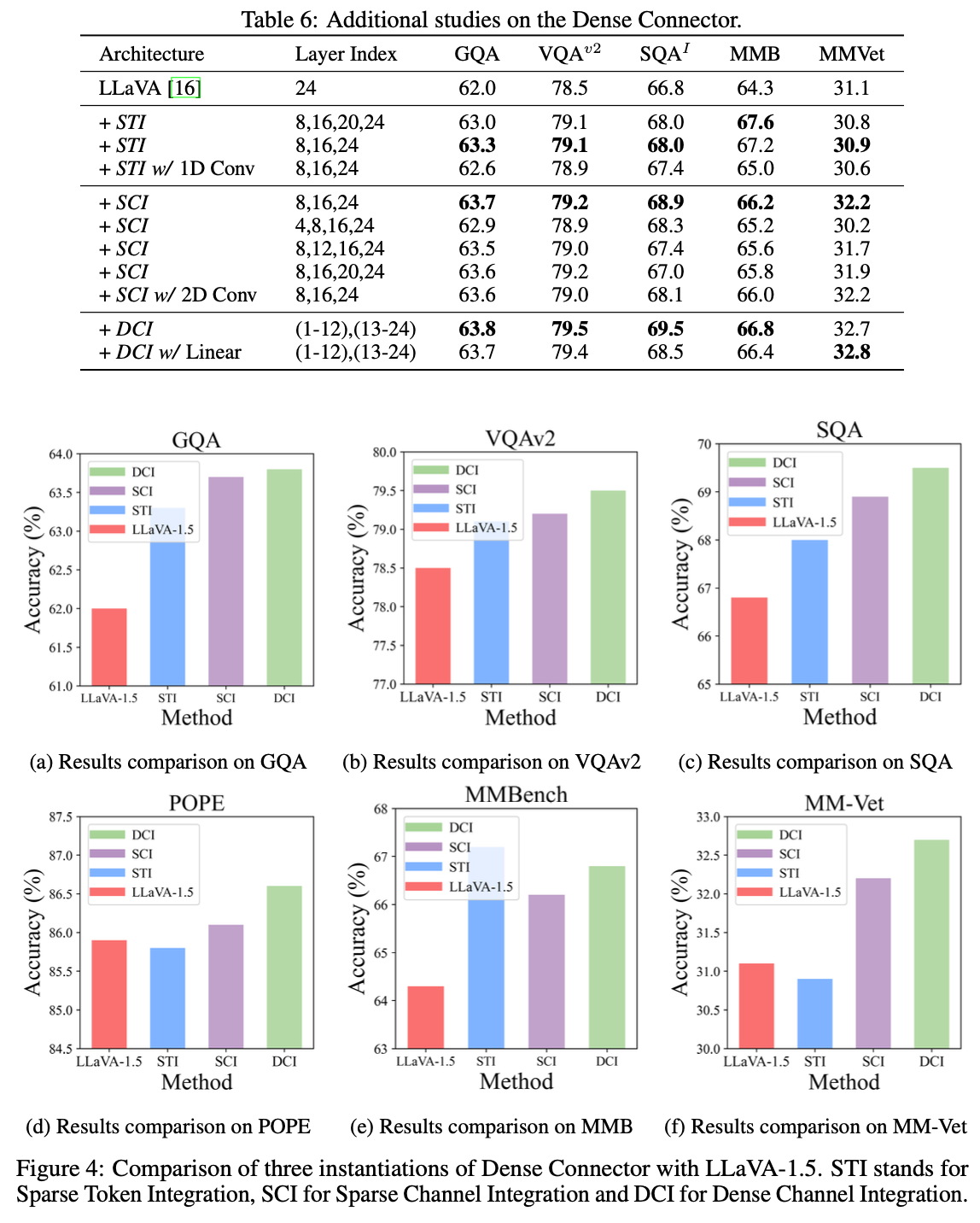
-
Finetuning Visual Encoder
- Clip의 경우, freeze가 좋았고, SigLip의 경우 10배 작은 lr로 학습시 미세하게 성능이 향상되었다고 함
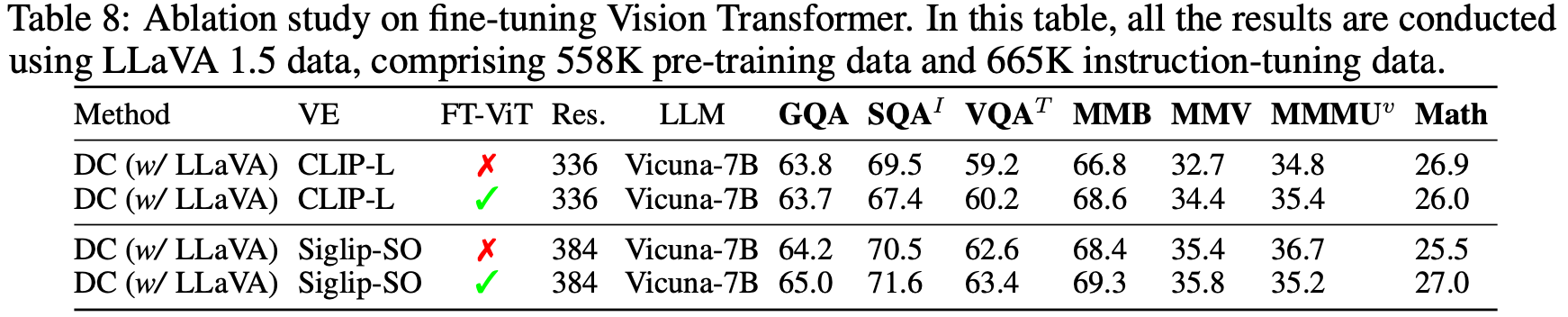
-
다른 LLM에 따른 성능 변화
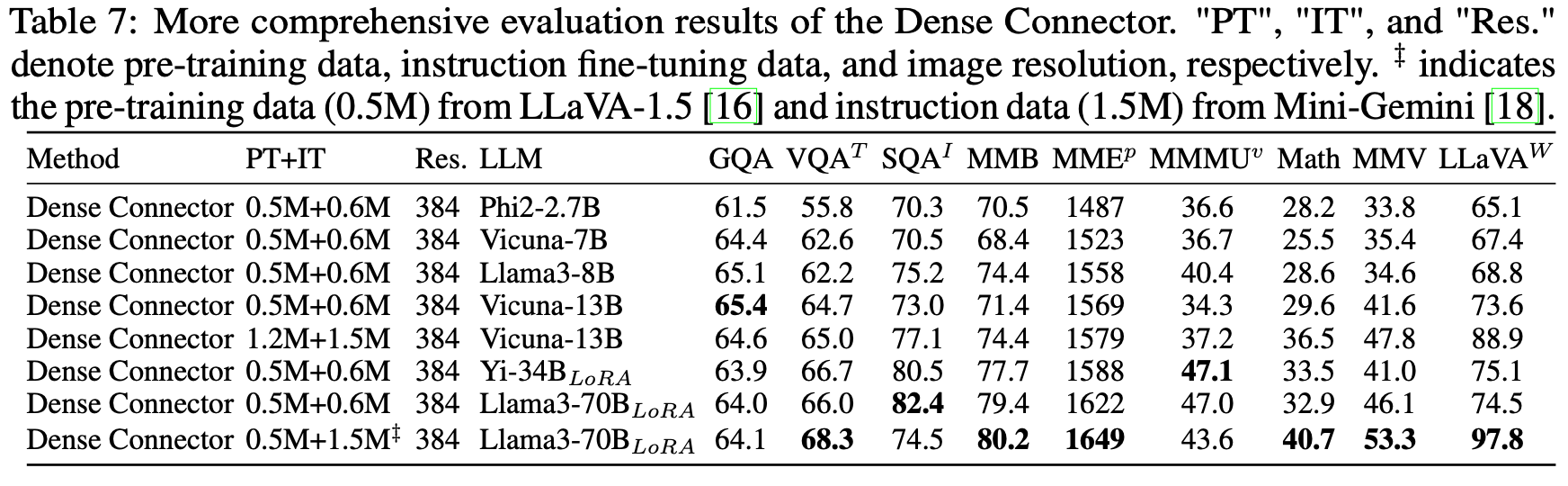
-