CowPilot: A Framework for Autonomous and Human-Agent Collaborative Web Navigation
[WebAgent] CowPilot: A Framework for Autonomous and Human-Agent Collaborative Web Navigation
- paper: https://arxiv.org/pdf/2501.16609
- github: X
- NAACL 2025 accepted (인용수: 3회, ‘25-06-28 기준)
- downstream task: Real-world Web semi-Automation task
- video demo: https://oaishi.github.io/cowpilot.html
- Chorme extension: https://oaishi.github.io/static/files/cowpilot_final_build_2.zip
1. Motivation
-
WebAgent에 대한 많은 연구들이 비약적인 성능 향상이 되고 있으나, 여전히 real-world에서는 한계가 있음
-
기존에 human-agent interaction 연구들은 자연어 기반 명령 혹은 사람 단독 action recording으로 연구만 되었고, 동적으로 task session을 협력하여 해결하는 사례는 없었음.
$\to$ 사람의 개입을 최소화하되, 사람과 interaction이 가능한 web agent를 구축해보자!
2. Contributions
-
Human-Agent interaction이 가능한 light-weight framework인 COWPilot (Collaborative Web navigation)을 제안함
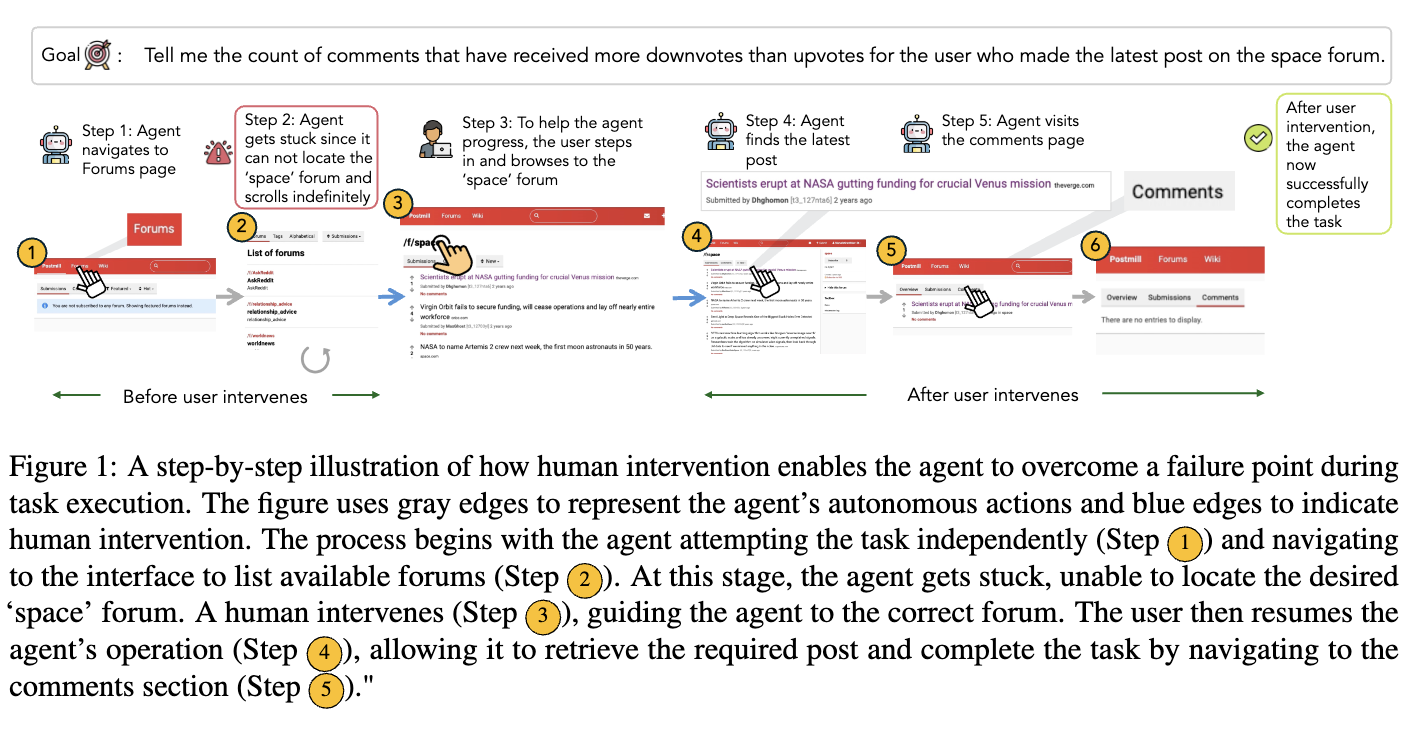
- Chrome extension으로 제공됨
- LLM이 next action을 proposing $\to$ Human이 go/stop을 판단 (5초내 무응답시 go) $\to$ pause 시 human action으로 task 수행 $\to$ resume하면 다시 LLM이 action을 propose
-
Human-agent collaborative process를 평가할 evalutation metric을 제안함
-
다양한 use-case에서 효과적임을 입증
- Web automation task에서 95% success rate (webarena, Copilot-GPT-4)
- Data collection for agent trajectories & user feedback & evaluation of single/multple agents
3. CowPilot
3.1 The Copilot System
-
Notations
-
$\pi_L$: LLM agent
-
$\pi_H$: Human agent
-
$o_t$: t step의 observation
-
$s_t$: t step의 environment state
-
$a_t$: t step의 예측된 action
$a_t = t(t, o_t, a_{0:t-1})$
-
-
action space
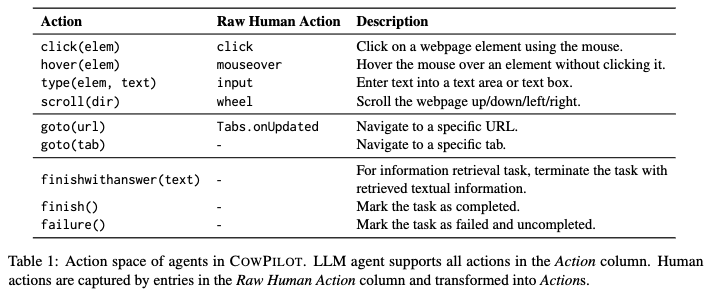
-
Suggest-then-Execute under Human Supervision module

3.2 Evaluation Metrics
- End-to-end task accuracy
- task의 목적이 달성되었는가로 평가함
- Human-Agent Collaboration
- Agent step count: task당 LLM agent가 수행한 step count
- Human step count: task당 Human agent가 수행한 step count
- Total step count == Agent step count + Human step count
- Human inutervention count: Human이 얼마나 pause를 했는지 count (LLM agent의 능력과 직결)
- 1번의 intervention이 여러 step이 될수도 있음 (resume 누를때 까지)
- Agent driven completion accuracy: terminating step에 LLM agent가 예측한 action으로 종결된 task count
3.3 Use Cases of CowPilot
- Web Automation
- LLM call 제외하고 50MB이하의 소규모 storage만 요구됨 $\to$ CowPilot은 Chrome extension으로 제공 가능함
- Personal API key를 통해 4번의 클릭만으로 사용 가능
- Backend LLM: LiteLLM proxy server
- COWPILOT은 GPT와 같은 클로즈드 소스 모델뿐만 아니라 LLAMA와 같은 오픈 웨이트 모델까지 LiteLLM을 통해 접근 가능한 다양한 모델을 지원함.
- 2가지 버전을 지원함
- Fully autonomous mode: no asking mode
- Copilot mode: human / agent가 협력하여 task를 수행
- LLM call 제외하고 50MB이하의 소규모 storage만 요구됨 $\to$ CowPilot은 Chrome extension으로 제공 가능함
- Data Collection from Websites
-
Chrome browser를 통해 작업하는 임의의 website에서 data annotation tool로 활용 가능
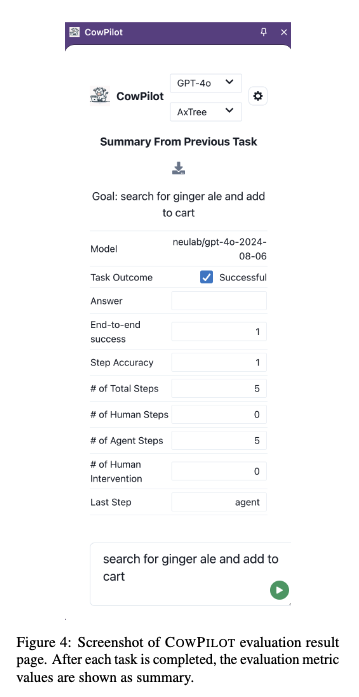
- 추가적인 self-hosted website가 불필요 $\to$ Miricanvas Designer들에게 해당 extension을 설치하여 log를 쌓는다면 대박이겠다!
-
LLM/Human agent의 모든 action history를 tracking 가능함
- step-level: 매 step이 task 성공에 기여했는지 human의 판단
- task-level: 전체 trajectory가 task에 성공했는지 판단
-
- Evaluation & Comparative Analysis of Agent Performance
- LightLLM framwork을 통해 다양한 open/closed-source model에 접근이 쉽도록 구현됨
4. Experiments
- Dataset: WebArena
- 27 task에서 평가를 진행 (easy, medium, hard levels)
- Top-performing agent의 step count를 기준으로 난이도를 부여함
- easy: <2
- medium: 2-4
- hard: >4
- 2 mode에 대해 실험
- fully autonomous
- gpt-4o-2024-08-06
- Llama-3.1-8B-instruct
- copilot-mode
- gpt-4o-2024-08-06
- Llama-3.1-8B-instruct
- fully autonomous
- Top-performing agent의 step count를 기준으로 난이도를 부여함
- 27 task에서 평가를 진행 (easy, medium, hard levels)
-
Prompt
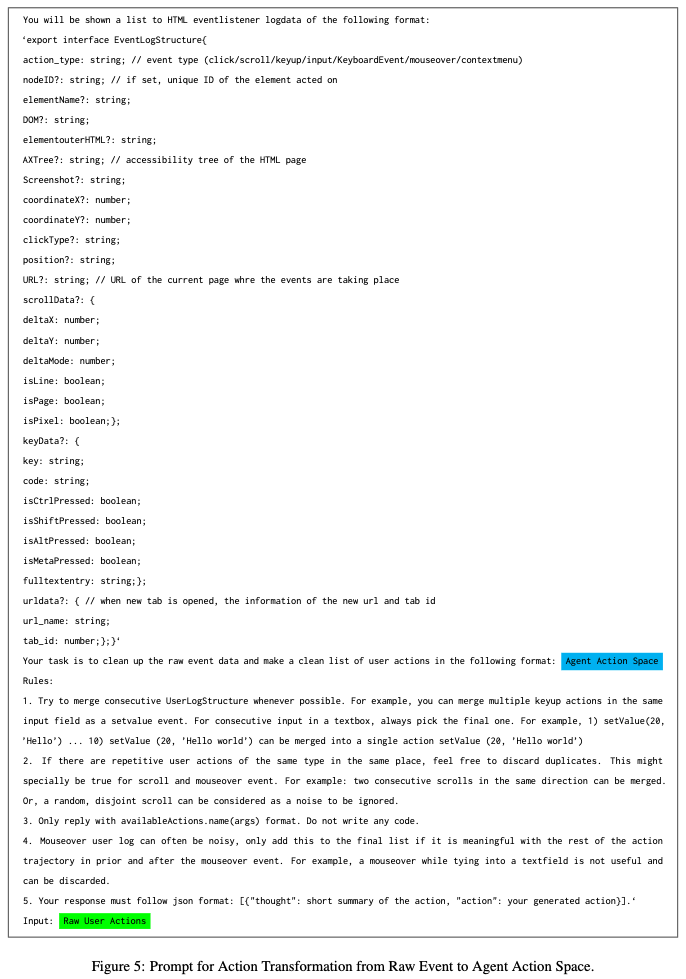
-
정량적 결과
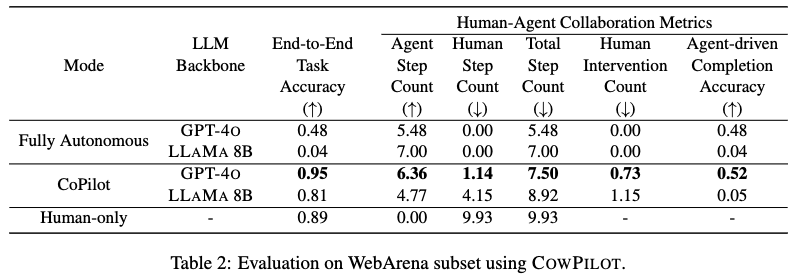
- Mode (모드): 에이전트가 작업을 수행한 방식
- Fully Autonomous (완전 자율): 에이전트가 인간의 개입 없이 단독으로 작업을 수행.
- CoPilot (코파일럿): 인간과 에이전트가 협력하여 작업을 수행. 에이전트가 다음 단계를 제안하고, 인간은 필요에 따라 개입하거나 에이전트에게 제어권을 다시 넘겨줌.
- Human-only (인간 단독): 에이전트의 도움 없이 인간이 단독으로 작업을 수행. 이 모드는 비교 기준 역할을 수행.
- LLM Backbone (LLM 백본): 에이전트에 사용된 대규모 언어 모델.
- GPT-4O와 LLAMA 8B 두 가지 모델이 사용.
- End-to-End Task Accuracy (종단 간 작업 정확도) (↑): 작업의 최종 목표를 성공적으로 달성했는지 여부를 나타내는 지표. 높을수록 좋음.
- CoPilot 모드에서 GPT-4O 백본을 사용했을 때 0.95로 가장 높은 정확도를 보임. 이는 완전 자율 모드(0.48)나 인간 단독 모드(0.89)보다도 높은 수치.
- LLAMA 8B는 완전 자율 모드(0.04)에서는 매우 낮은 정확도를 보였지만, CoPilot 모드(0.81)에서는 상당한 정확도 향상을 보임.
- Human-Agent Collaboration Metrics (인간-에이전트 협업 지표): 인간과 에이전트 간의 상호작용을 측정하는 지표들.
- Agent Step Count (에이전트 단계 수) (↑): 에이전트가 작업을 완료하기까지 수행한 단계 수. 높을수록 에이전트가 많은 작업을 처리했음을 의미할 수 있으나, 비효율적인 반복으로 인해 높을 수도 있음.
- CoPilot 모드의 GPT-4O(6.36)와 LLAMA 8B(4.77) 모두 완전 자율 모드(GPT-4O 5.48, LLAMA 8B 7.00)와 인간 단독 모드(0.00, 해당 없음)에 비해 에이전트가 수행하는 단계 수가 다름. 특히 CoPilot GPT-4O에서 에이전트가 더 많은 단계를 수행.
- Human Step Count (인간 단계 수) (↓): 인간이 작업을 완료하기까지 수행한 단계 수. 낮을수록 좋음.
- CoPilot 모드에서 GPT-4O(1.14)는 LLAMA 8B(4.15)나 인간 단독 모드(9.93)에 비해 인간의 개입 단계 수가 현저히 적음. 이는 GPT-4O가 인간의 노력을 크게 줄여준다는 것을 시사함.
- Total Step Count (총 단계 수) (↓): 인간과 에이전트가 수행한 총 단계 수의 합. 낮을수록 좋음
- GPT-4O의 경우 CoPilot 모드(7.50)가 완전 자율 모드(5.48)보다 총 단계 수는 많지만, 작업 정확도는 훨씬 높음.
- LLAMA 8B의 경우 CoPilot 모드(8.92)가 완전 자율 모드(7.00)보다 총 단계 수가 많음.
- 인간 단독 모드(9.93)는 모든 단계가 인간에 의해 수행.
- Human Intervention Count (인간 개입 횟수) (↓): 인간이 에이전트의 작업을 중단시키고 직접 개입한 횟수. 낮을수록 좋음.
- CoPilot 모드에서 GPT-4O(0.73)는 LLAMA 8B(1.15)보다 인간 개입 횟수가 적음. 이는 GPT-4O가 LLAMA 8B보다 오류가 적어 인간이 개입할 필요성이 낮았음을 시사.
- Agent-driven Completion Accuracy (에이전트 주도 완료 정확도) (↑): 에이전트가 작업의 최종 완료 단계(finish action)를 수행하여 성공적으로 작업을 마친 비율. 높을수록 인간의 도움 없이도 에이전트가 스스로 복구하고 작업을 끝낼 수 있는 능력이 높음을 의미.
- CoPilot 모드에서 GPT-4O는 0.52로, 작업 성공의 절반 이상을 에이전트가 스스로 완료.
- LLAMA 8B는 0.05로 매우 낮음. 완전 자율 모드에서의 값은 End-to-End Task Accuracy와 동일한데, 이는 개입이 없으므로 에이전트가 성공했다면 에이전트가 완료했음을 의미.
- Mode (모드): 에이전트가 작업을 수행한 방식
5. Related Works
5.1 Web Agent Plugin
-
Docker image 요구하는 경우
- API: MultiOn, Anthropic
- Chromium borwser instance: BrowserGym, AgentLab, WebArena
-
Crome extensions
-
WebCanvas, WebOlympus, OpenWebAgent, Taxy

-
5.2 LLM Agents for Web Automation
- HUML structures & Accessibility trees기반
- Visual-based System 기반: WebShop, WebArena, WebLINX