[OD][CLS][GM][RL] An Intriguing Failing of Convolutional Neural Networks and CoordConv Solution
[OD][CLS][GM][RL] An Intriguing Failing of Convolutional Neural Networks and CoordConv Solution
- paper: https://arxiv.org/pdf/1807.03247.pdf
- github: https://github.com/uber-research/coordconv
- NeurIPS 2018 accpeted (인용수: 841회, ‘24-01-14 기준)
- downstream task: supervised coordinate transformation, superivsed coordinate regression, supervised rendering, OD, CLS, and RL
1. Motivation
- Convolution layer가 totally fail하는 spatial transform task를 통해 문제를 제기한다. 제안한 toy-example dataset “Not-so-clever”를 통해 보인다.
- 그리고 이를 해결하는 단순한 방법인 “CoordConv”을 제시하고, toy-example뿐 아니라 다양한 downstream task (OD, CLS, RL, GM)에도 잘 되는가를 살펴본다.
2. Contribution
-
Supervised Classification / Regression 그리고 Rendering을 할 수 있는 “Not-so-Clever” toy-dataset을 제안한다.
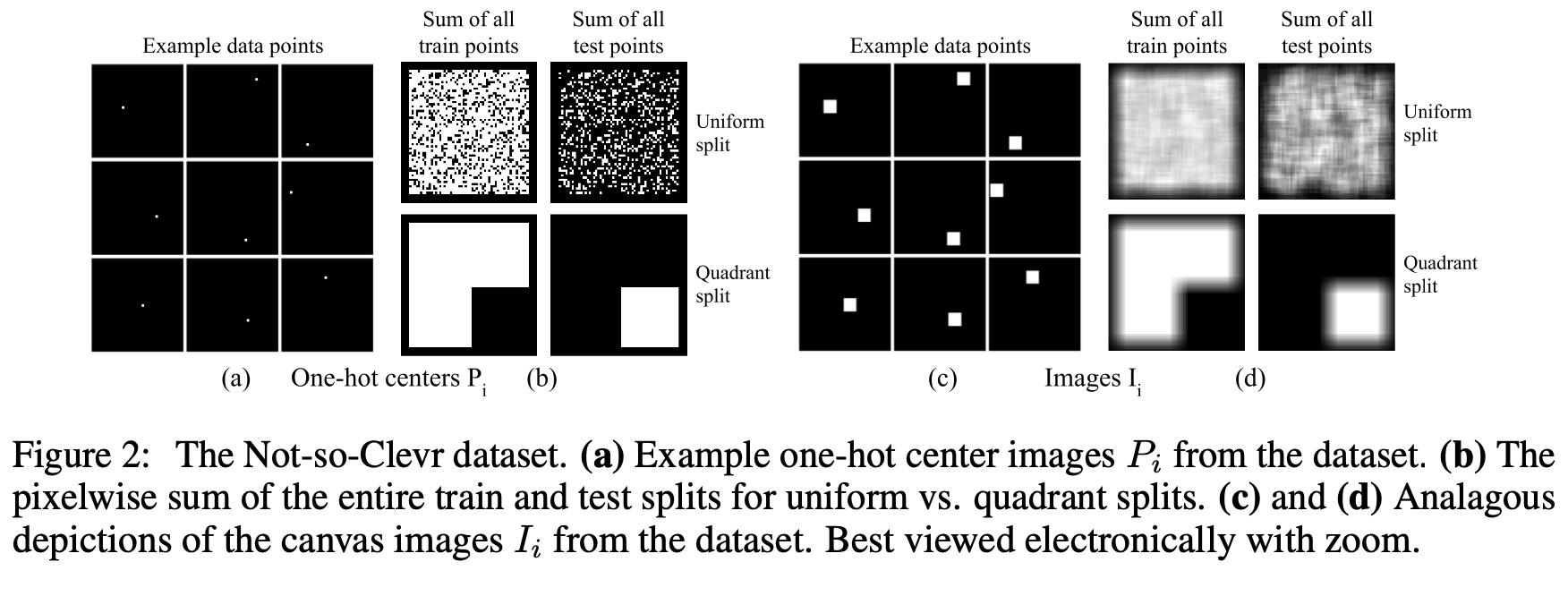
- uniform: train-test split을 random sampling으로 split한 protocol. 그림 (b) 1열
- quadratic: train-test split을 1~3 사분면을 train, 4 사분면을 test로 split한 protocol. 그림 (b) 2열 참고
-
코드 몇줄로 구현 가능한 convolution filter에게 pixel coordinate 정보를 제공해주는 “CoordConv” filter를 제안한다.


-
Simple task 들 (Supervised Classification / Regression / Rendering)부터 complex task (OD/CLS/GM)까지 CoordConv의 효과를 입체적으로 살펴본다.

- Supervised Classification task : 각 pixel 좌표를 class로 가정한 task
- input : (x,y) 좌표
- output : 각 pixel별 prediction score (gt: one-hot label vector)
- Supervised Regression task : Supervised Classification과 정확히 반대
- input: one-hot G.T. prediction vector
- output: (x, y) 좌표
- Supervised Rengering task : 주어진 좌표에 two-object (red, blue)를 생성하는 task
- input: (x, y) 좌표
- output: input에 해당하는 좌표에 object를 생성함
- Supervised Classification task : 각 pixel 좌표를 class로 가정한 task
-
OD / CLS / Rendering / Reinforcement Learning task에서 Conv $\to$ CoordConv 대체하면 성능 향상이 됨을 보인다.
3. CoordConv
-
overview
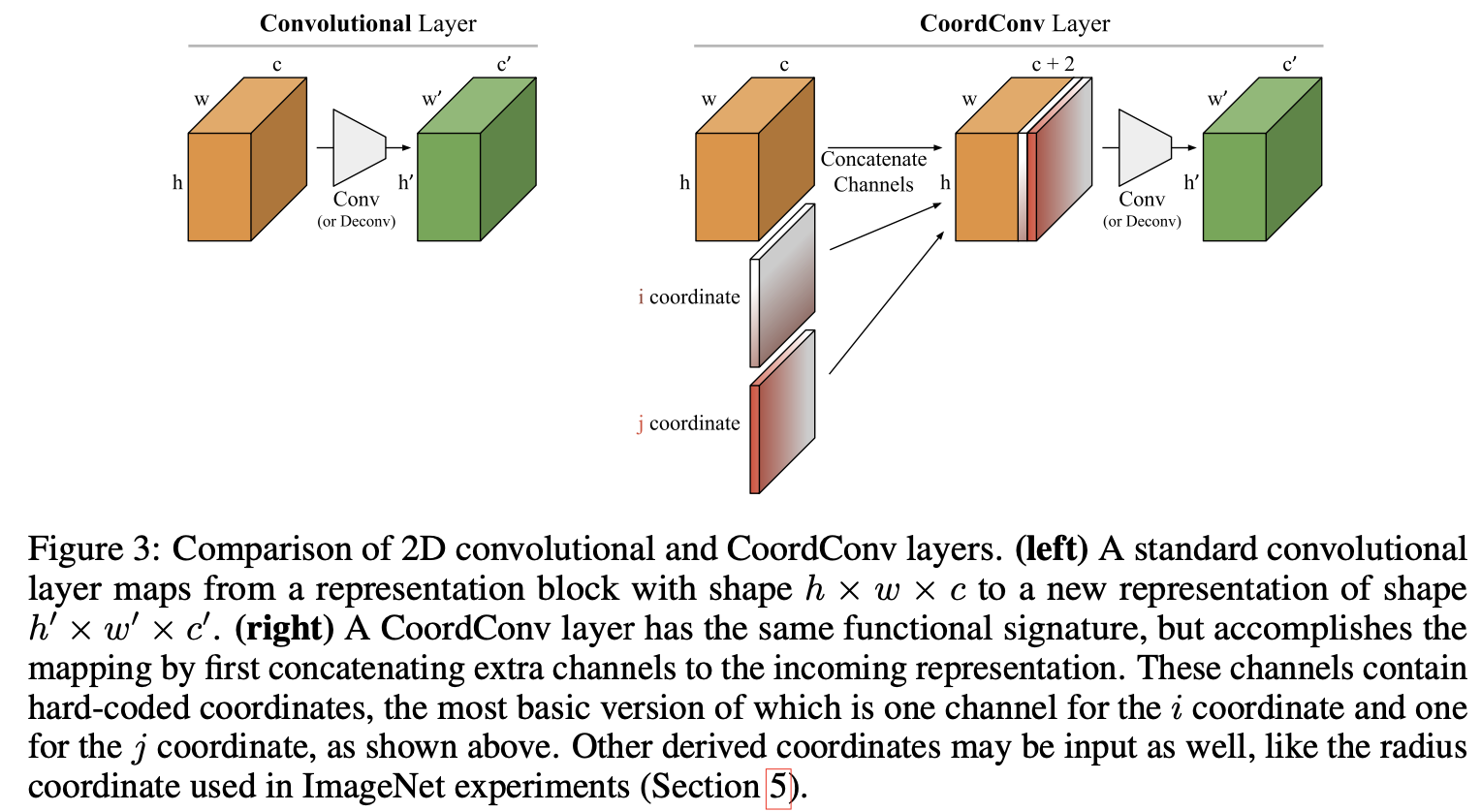
-
downstream task에 따라 기존 Convolution layer처럼 Translation invariance하게 학습할 수도 있고, translation variance하게 학습할 수 도 있는 “CoordConv”를 제안함
-
translation invariance : 추가된 channel (+2/+3)의 kernel weigh가 모두 “uniform”하거나 “zeros”이면 original conv. layer와 동일한 효과
-
translation variance : 추가된 channel(+2/+3)의 kernel weight가 not uniform, not zero이면 transaltional variance 효과
$\to$ translation variance한 특징을 통해 더 generalize한 trainable model을 만들 수 있다고 제시함
-
+3의 경우 x, y뿐 아니라 r을 추가함
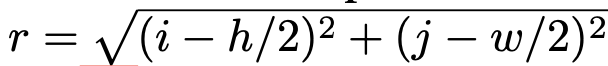
-
특징 1. 현존하는 gpu architecture에서 computationally efficient함 (왜? original conv. layer와 동일한 연산이기 때문)
특징 2. (conv. layer 처럼) few parameter로 spatial variance한 특성을 지닐 수 있음
특징 3. (Fully Connected Layer)와 같이 spatial variance한 특성을 지닐 수도 있음
-
-
Relation to Other work
- seqeuence to sequence learning : positional embedding을 추가한 형태로 spatial 정보를 학습함
- spatial transformation network : Generative model에 적용한다고 함. (OCR에서도 Thin Plate Spline (TPS)에서도 사용함)
4. Experiments
4.1. Supervised Coordinate Classification
-
각 pixel 좌표를 class로 보고, input (x,y)에 대해 해당 class를 분류하는 task
-
Train accuracy vs. Test accuracy / Train time vs. Test accuracy
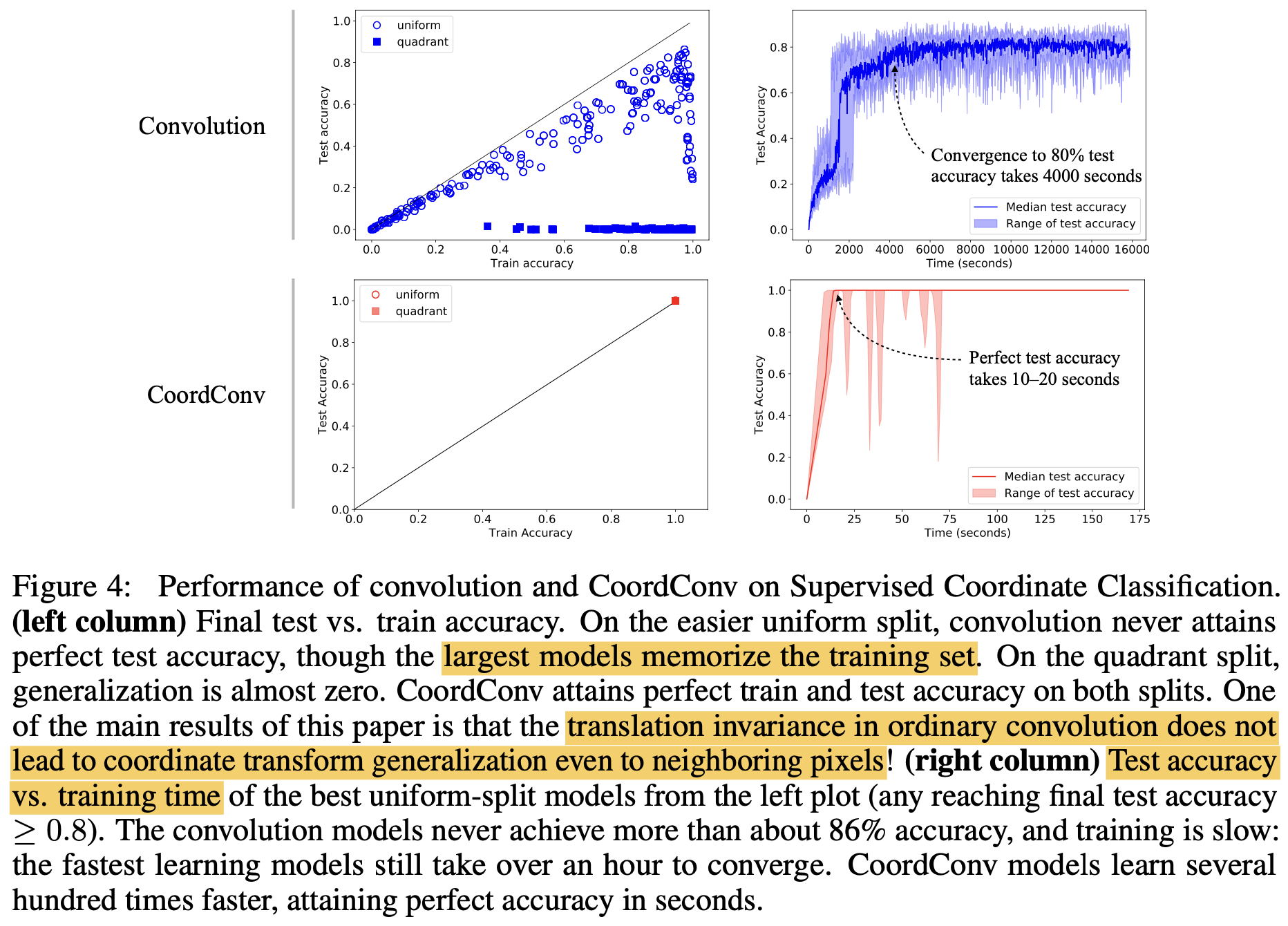
- Conv.의 경우, uniform은 잘 안되고, quadrant의 경우 test accuracy가 0이 나옴.
- 반면 CoordConv.의 경우 uniform / quadrant 모두 잘되며 학습도 매우 빠름
4.2. Supervised Coordinate Regression
-
CoordConv. > Conv.

4.3. Supervised Rendering
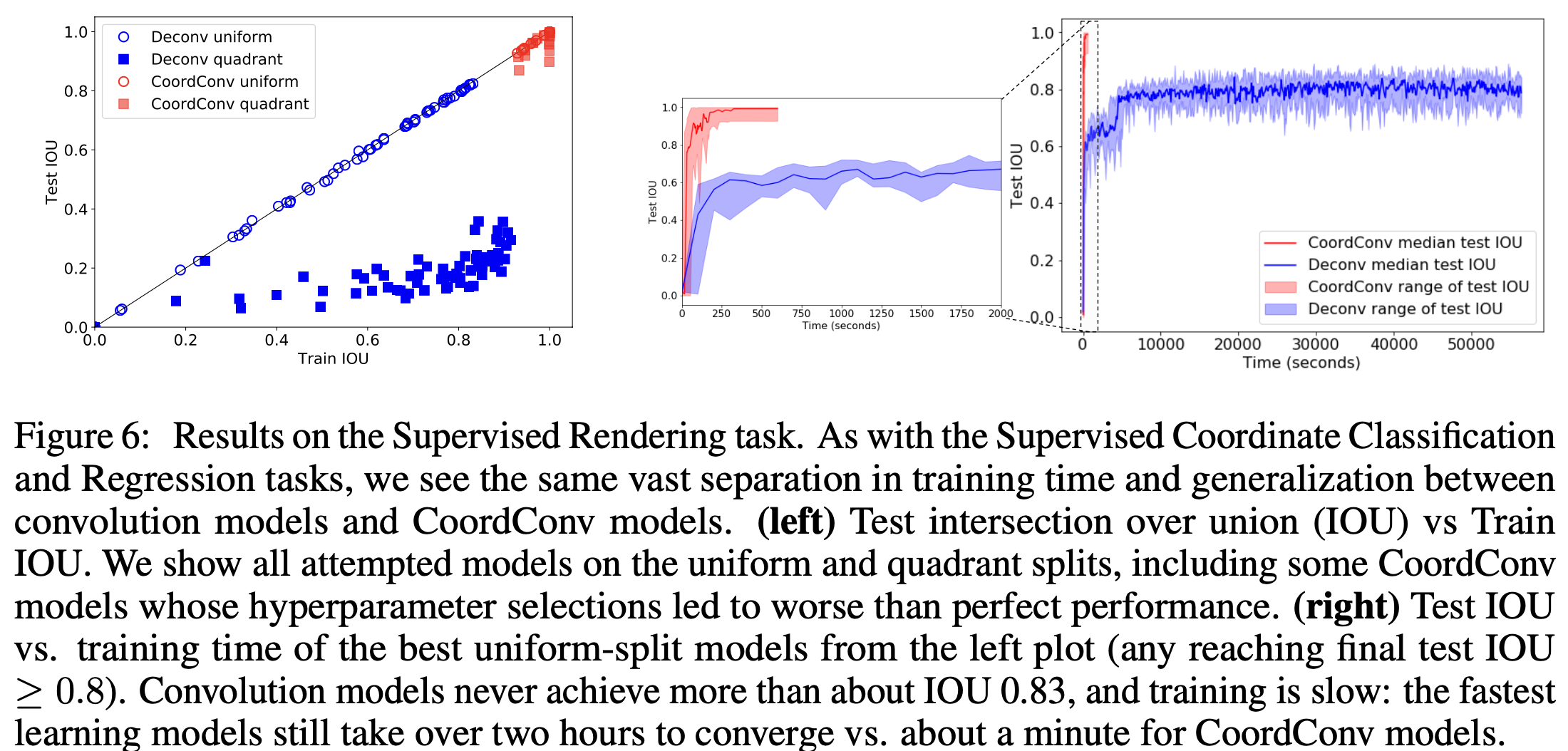
4.4. Other tasks
-
Image Classification
- 성능 하락은 발생하지 않지만, 성능 향상은 없었음. 이는 spatial 과 무관하기 때문임.
-
Object Detection
-
Conv. $\to$ CoordConv.로 바뀜
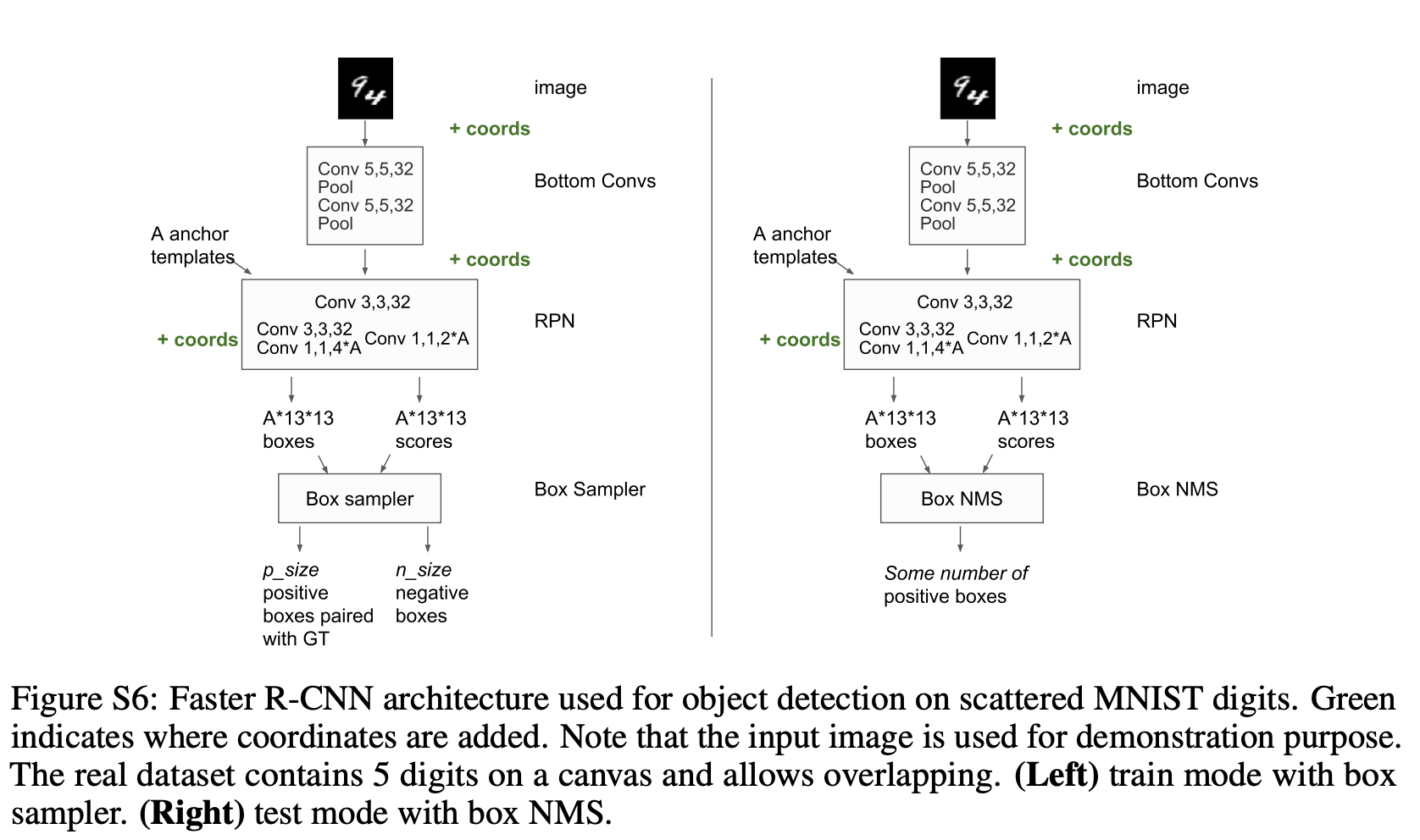
-
64x64 MNist data를 localization하는 task. test IoU 24% 향상됨
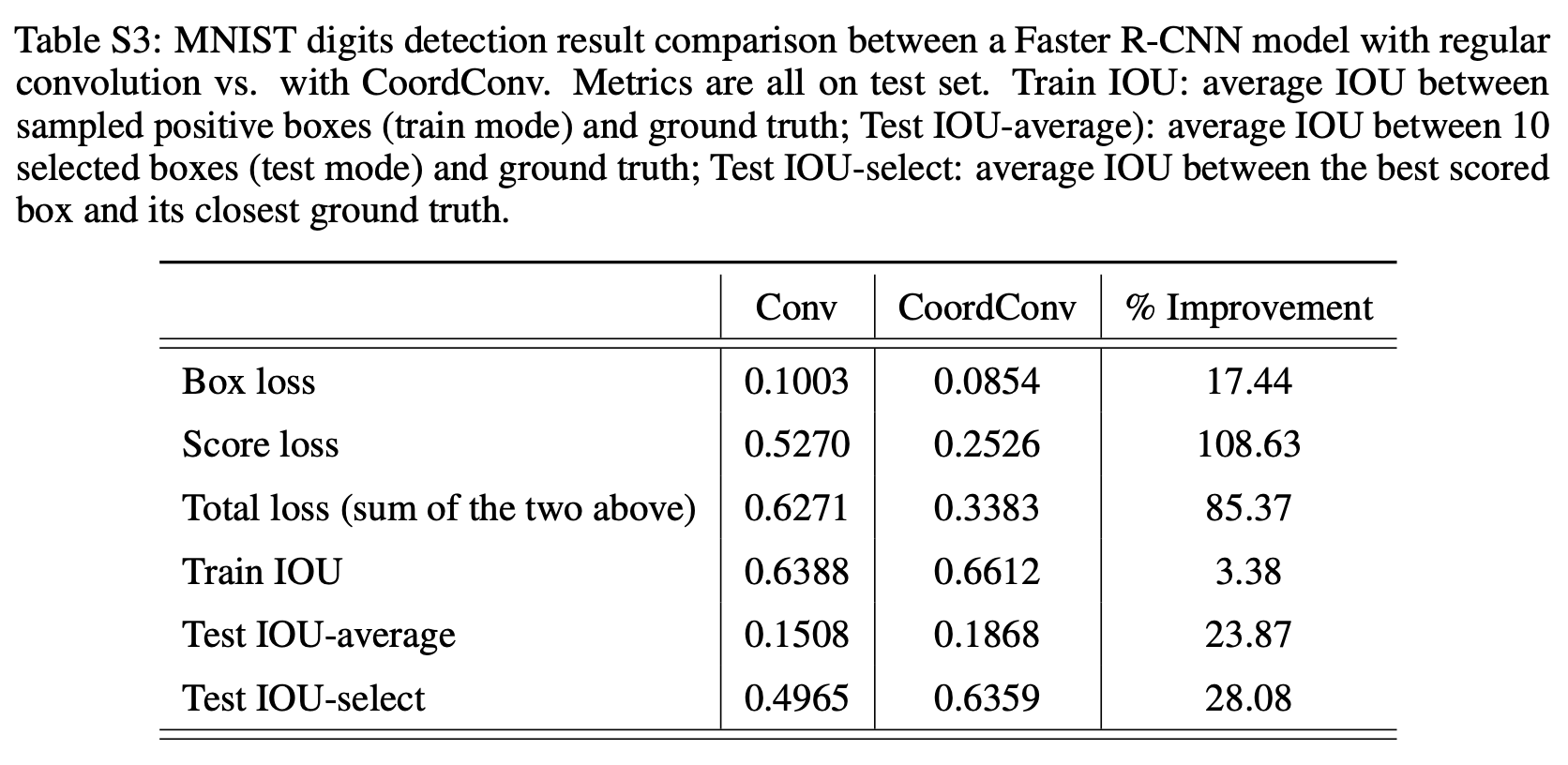
-
-
Generaltive Modeling
-
가설: 기존 Conv.기반의 GM 이 mode collapse하는 이유는 high-level semantic을 학습할 때 pixel coordinate정보를 straightforward하게 제공하지 않았기 때문임. $\to$ CoordConv.가 이를 해결할 수 있음.
-
기존 Conv. GAN은 2-d. input에 대해 1-d로 mode collapse 발생함을 확인. CoordConv.는 이를 해결함
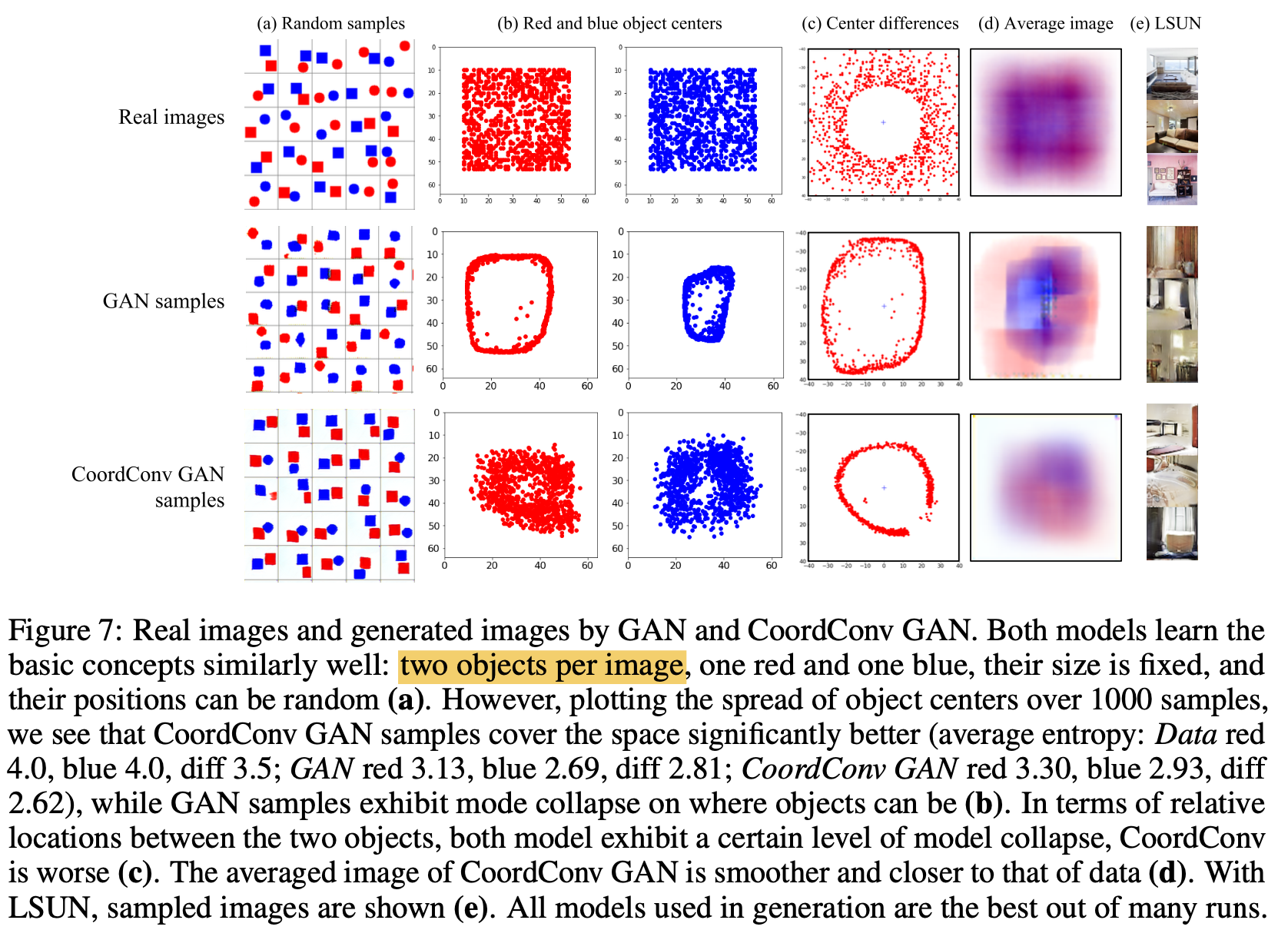
-