[OD] Conditional DETR for Fast Training Convergence
[OD] Conditional DETR for Fast Training Convergence
- paper: https://arxiv.org/pdf/2108.06152.pdf
- github: https://github.com/Atten4Vis/ConditionalDETR
- ICCV 2021 accpeted (인용수: 342회, ‘23.12.19 기준)
- Microsoft Asia, Peking univerisiy
- downstream task : OD
1. Motivation
-
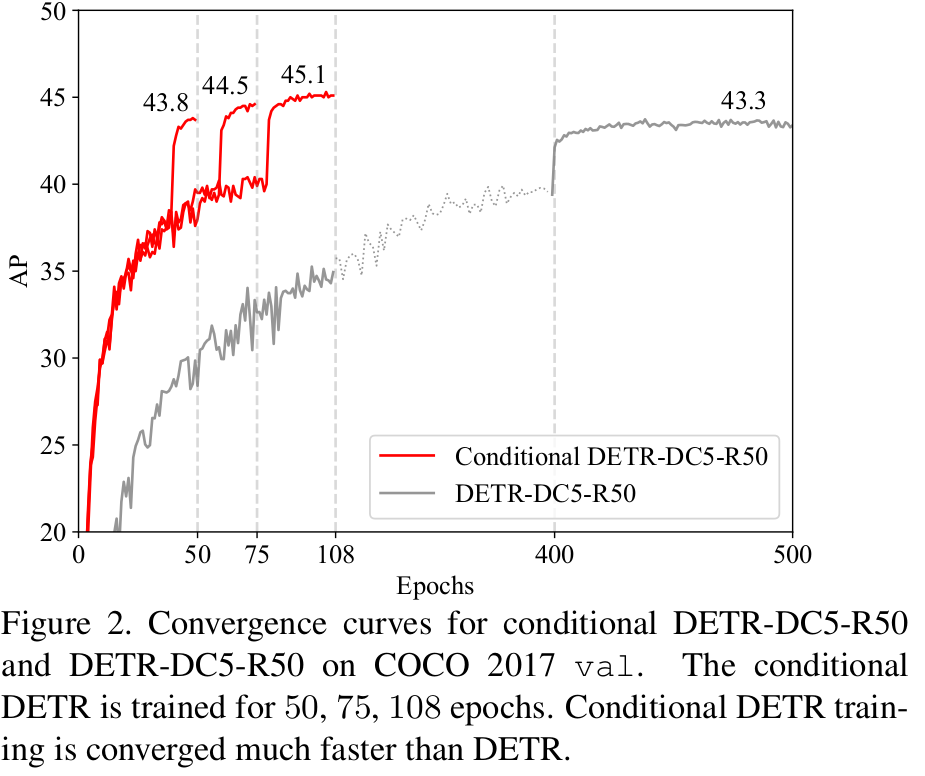
Transformer의 Encoder Decoder구조를 가진 DETR의 핵심 이슈인 “학습 속도 느림” 문제를 해결코자함
-
구체적으로, Encoder의 출력을 입력으로 받는 Key, Value와 Object Query와 positional embedding의 합으로 구성된 Query간의 attention 시, Query는 image 정보 없이 Key, Value의 encoder 출력값을 attention을 통해서 정보를 얻게 되므로 학습이 오래걸림

- 1행: Conditional-DETR 50 epoch query와 key의 attention map 결과
- 2행: DETR 50 epoch query와 key의 attention map 결과
- attention이 좌, 우에 해당하는 영역이 localization이 제대로 학습이 안됨
- 3행: DETR 500 epoch query와 key의 attention map 결과
2. Contribution
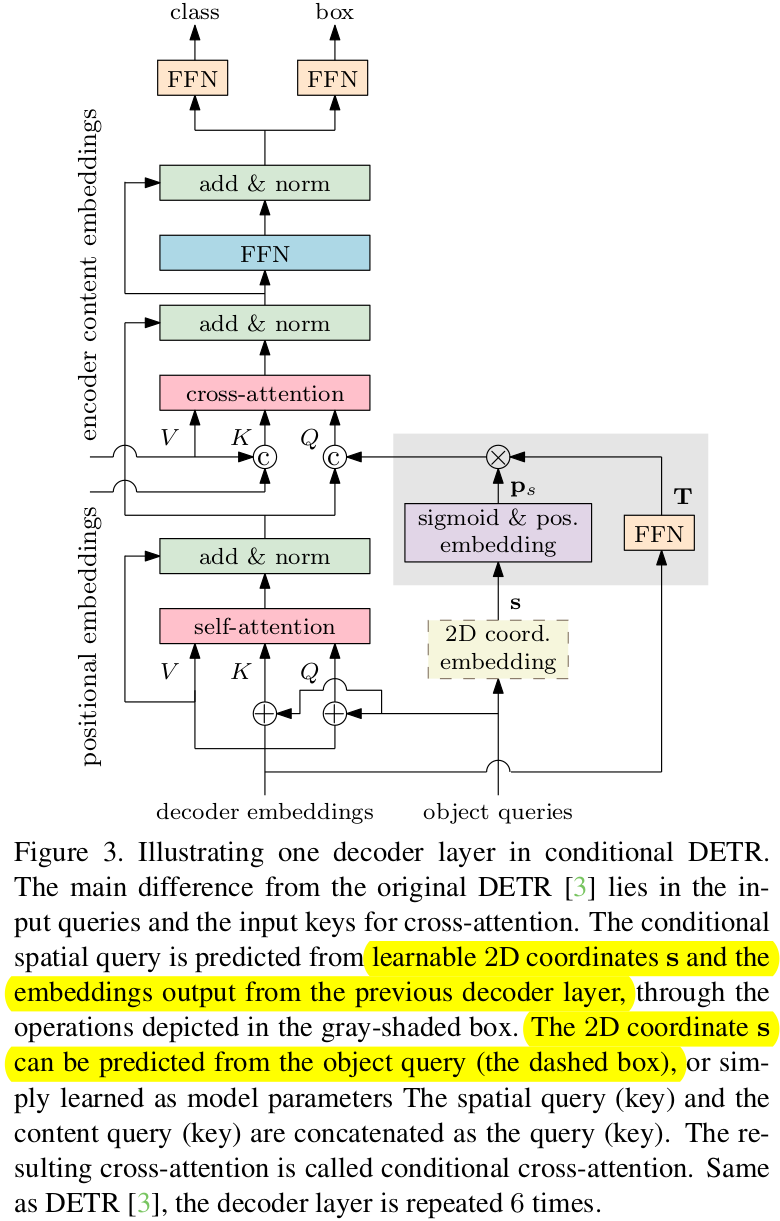
- Decoder의 Cross-attention mechanism에서 spatial query에 이전 step의 decoder layer에서 출력한 object query와 spatial embedding을 condition으로 줌으로써, spatial query와 key간의 cross attention시, key의 content embedding의 quality에 따라 학습 속도가 의존적이던 문제를 해결함
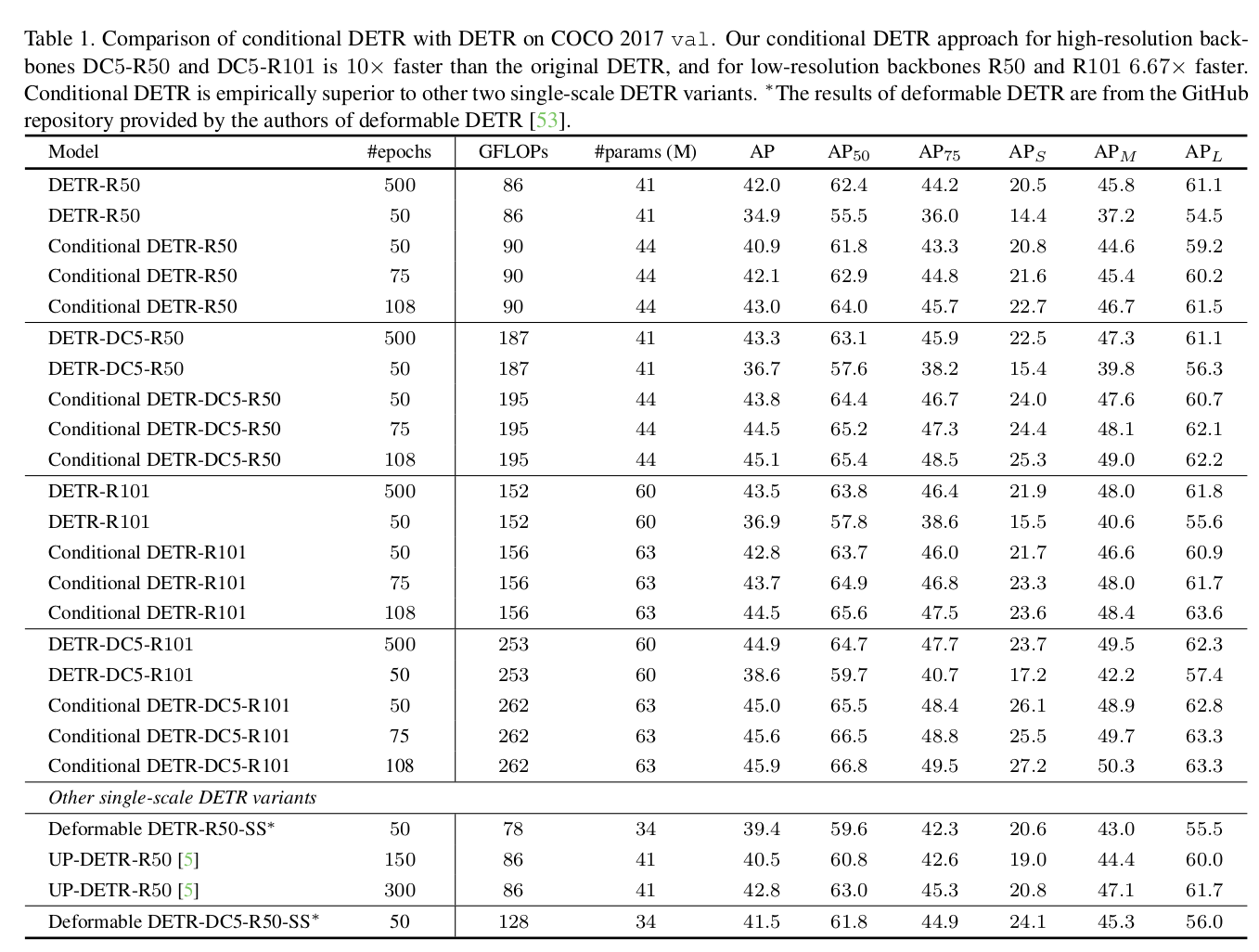
- DETR에 비해 Res50에서 x6.7배, Res101에서 x10배 빨리 수렴
3. Conditional DETR
-
Baseline : DETR
- CNN + Encoder + Decoder + class and box predictors (FFN)
-
Overview
-
Decoder를 이루는 Layer 1개에 대한 그림 (총 6개)
-
Box regression
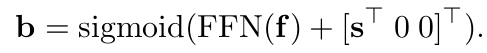
- f: decoder embedding
- FFN: unnormalized box
- s: 2D coordinate of reference point
- b: normalized box coordinate. $[b_{cx}, b_{cy}, b_w, b_h]^T$
-
Category prediction
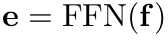
- e: category score
-
3.1 DETR Decoder Cross-Attention
-
Key
- content key $c_k$ : Encoder의 content embedding 출력
- positional embedding $p_k$ : normalized 2D coordinate
-
Value
- content key $c_v=c_k$
-
Query
-
Original
-
content query $c_q$: self-attention의 출력된 결과
-
spatial query $p_q$: object query
-
두 query의 합으로 구현
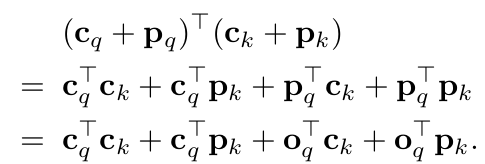
-
-
Conditional DETR
-
content query $c_q$
-
spatial query $p_q$ : reference point s와 reference point로부터의 상대적 거리를 의미하는 decoder embedding f로 구현
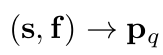
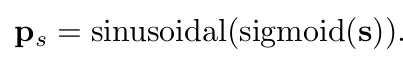
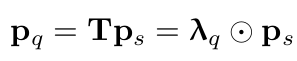
- 역할: key, value와 같은 2D coordinate로 mapping하여 학습 수렴 속도를 빠르게 하고자 함
- $p_s$: normalized reference point를 기반으로 256-dim의 sinusoidal positional embedding vector를 생성함
- T: FFN(f)로 구현.
- $\lambda_q$: 256-dim의 diagonal matrix. T를 metric화한 것.
-
두 query의 concatnation으로 구현
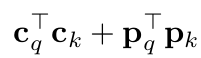
- 두 query의 역할을 구분
-
-
Multi-head Attention
- M=8로 parallel attention을 수행함으로써 localization task를 disentangle하는 역할을 함
-
3.2 Visualization Results

- 1행: Spatial attention weight map ($p_q^Tp_k$)
- 좌,우,상,하로 attention되는 기능이 head마다 disentangle되어 있음
- 2행: Content attention weight map ($c_q^Tc_k$)
- 3행 : Combined attention weight map ($p_q^Tp_k+c_q^Tc_k$)
4. Experiments
-
vs DETR
-
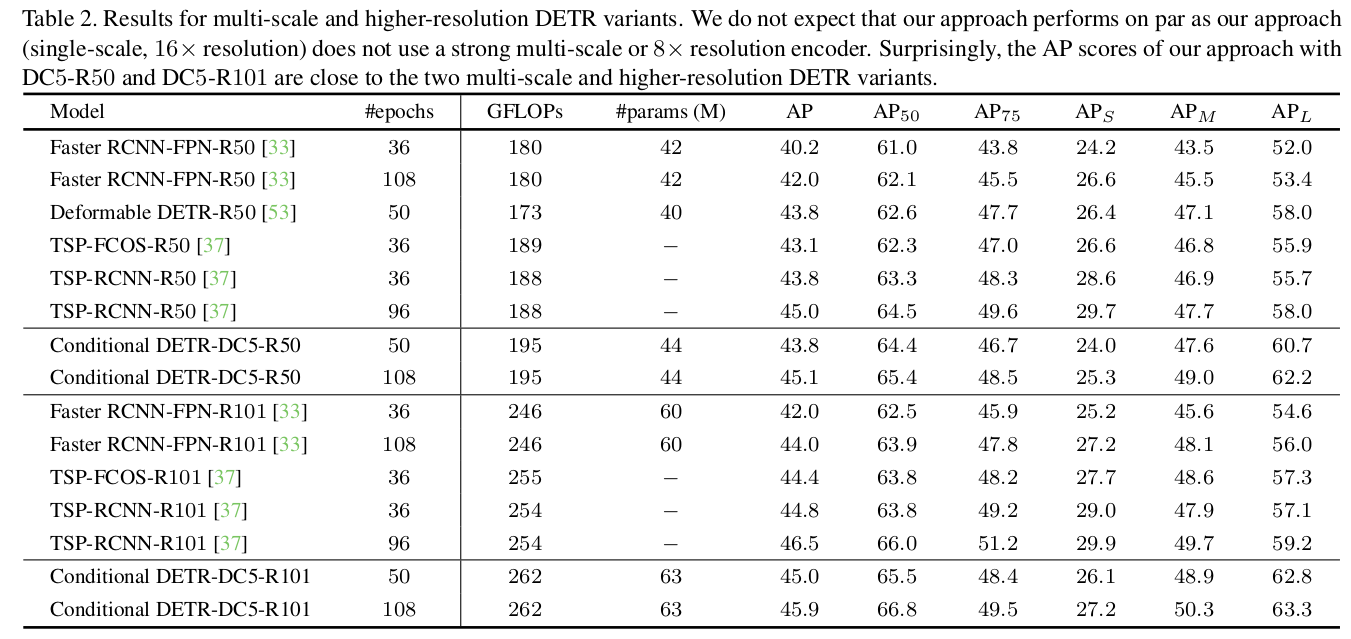
vs DETR Variants
-
Ablations
-
Different Queues
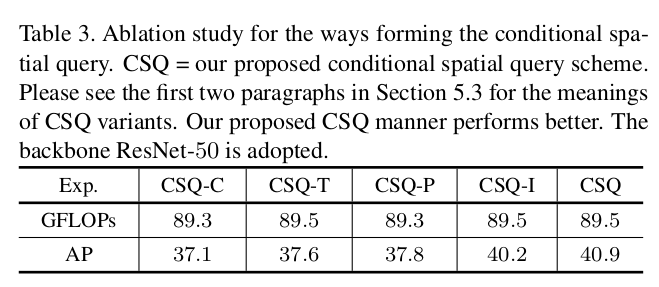
- CSQ-P: only the positional embedding as decoder query ($p_s$)
- CSQ-T: only the transformation as decoder query ($\lambda_q$)
- CSQ-C: only the decoder content embedding (f)
- CSQ-I: element-wise product of decoder self-attention output $c_q$ & positional embedding $p_s$
- CSQ: $\lambda_q \times p_s$
-
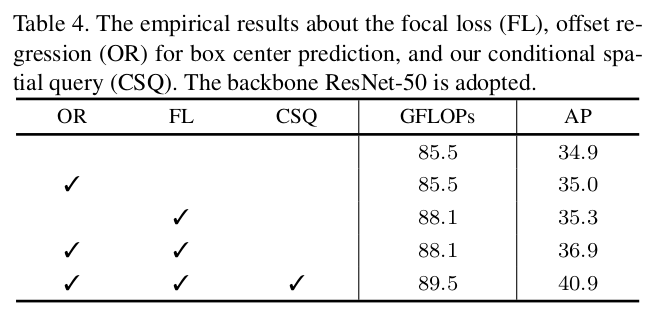
Different Losses
-
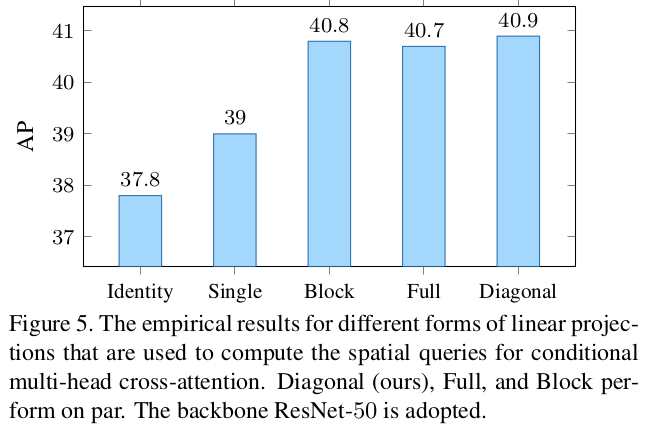
Differnt $\lambda$ matrix
-