Color Rec
— title: “Multimodal Color Recommendation in Vector Graphic Documents”
[Design] Multimodal Color Recommendation in Vector Graphic Documents
- paper: https://arxiv.org/pdf/2308.04118
- github: https://github.com/CyberAgentAILab/text2palette
- ACM MM 2023 accpeted (인용수: 4회, ‘25-03-22 기준)
- downstream task: Color palette completion, Full palette generation
1. Motivation
-
Graphic document 디자인에 있어, 템플릿의 다른 색상과 조화로우면서 text 내용에 어울리는 색상을 선택하는 것은 매우 중요하지만, 도전적인 task임
$\to$ 두가지 요인을 고려한 어울리는 색상을 추천해주는 모델을 만들어보자!

2. Contribution
- 주변의 color와 context를 고려하는 멀티모달 masked color model 을 제안함. 두 가지 모듈로 구성
- Clip-based: Text embedding을 추출하는 역할
- Designed integration network: 주변의 color와 추출된 text embedding간의 통합하는 역할
- Color palette recommendation / Full palette generation에 적용가능한 통합된 모델
- self-attention: color palette간의 관계를 학습 (Color-palette recommendation only)
- cross-attention: color + text간의 관계를 학습 (Color-palette recommendation)
- Color palette recommendation / Full palette generation에서 SOTA
- Color palette: 색상 set
- Evaluation Metric
- accuracy: 얼마나 정답과 색상이 일치하는가?
- distribution (다양한 색상): 얼마나 다양한 색상을 추천하는가?
- user experience: 얼마나 그럴듯한 색상을 추천하는가? (정성적 평가)
3. Masked Color Recommendation
- Graphic Design Workflow (유저 시나리오)
- App(ex. 미리캔버스)에서 사용하고자 하는 Template 검색 $\to$ 선택
- 특정 디자인 요소 변경 (ex. 딱맞는 디자인 찾기)
- 변경한 요소에 대해 전반적인 색상 & Context를 고려하여 어울리는 색상으로 변경
3.1 Approach
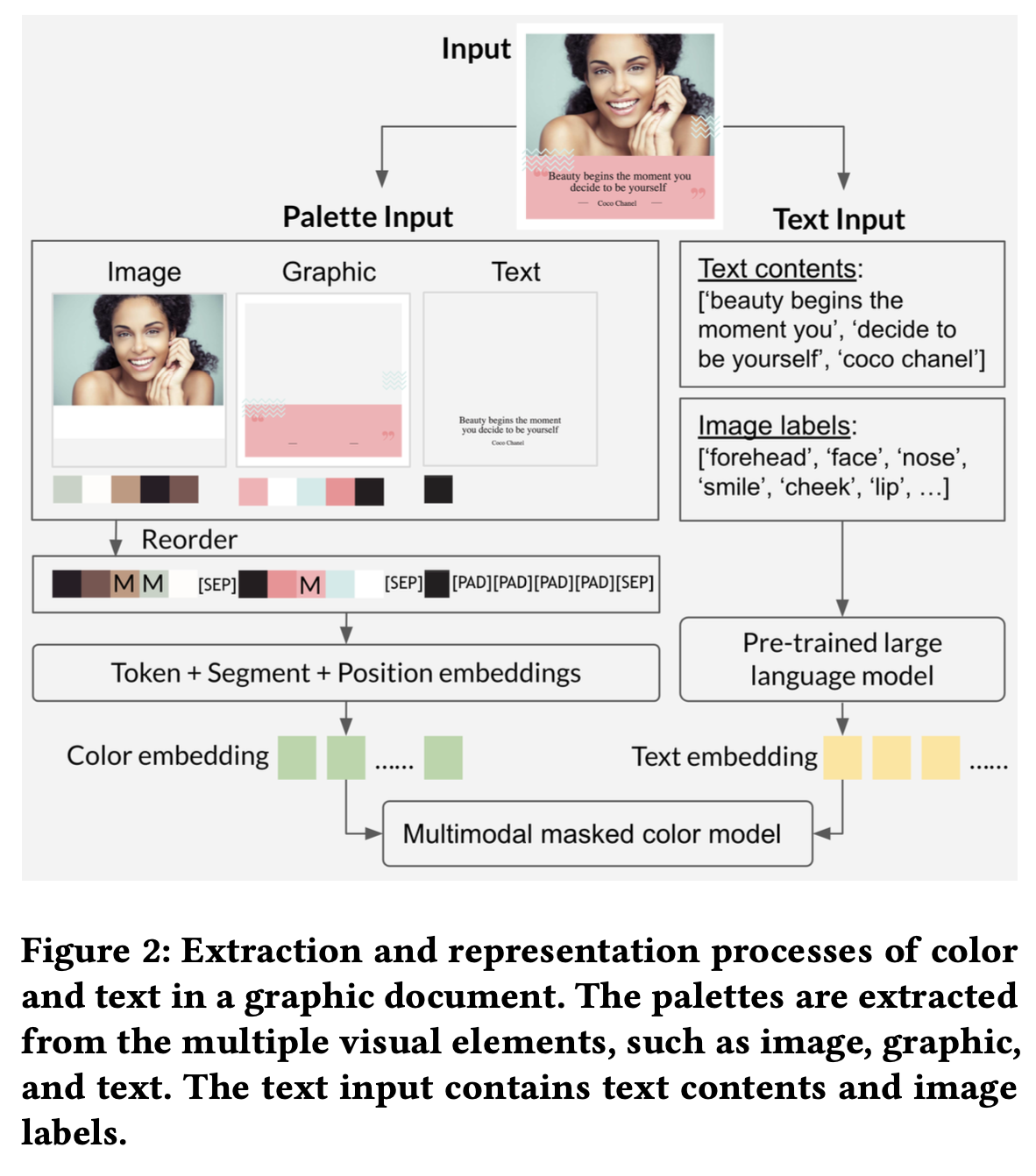
- 전체 요소를 3 묶음으로 나눔
- image: photo, image 요소
- graphic: 꾸밈 요소 (ex. lines, shapes, vector기반의 일러스트 요소)
- text: text 요소
3.1.1 Reordered Color Representation
- 색상 공간: RGB $\to$ CIELAB으로 표현
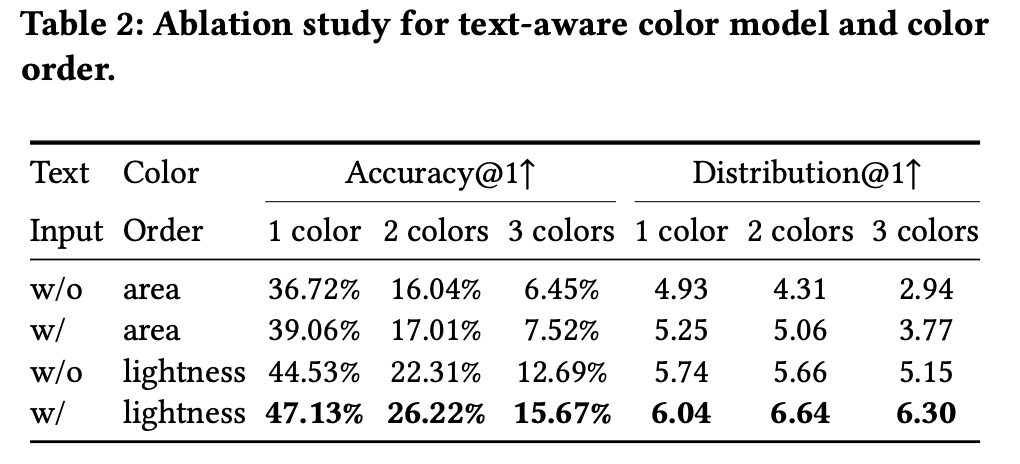
- 색상 순서: 기존에는 area를 기준으로 reordering하여 입력 색상을 제공했음 $\to$ Lightness를 기준으로 reordereing 수행
- Why? Gradient of lightness가 색상에서 중요한 feature임
- 색상 표현
- color: word로 표현
- palette: sentence로 표현
- 3개의 stage가 있음
- color quantization: $256 \times 256 \times 256 \to b \times b \times b$로 color 갯수를 줄이는게 목적 (b=16)
- encoding: quantized color를 learnable embedding으로 encode
- mae 학습
- 각 color별 token embedding + Segment embedding + Positional embedding의 합으로 표현
- Segment: 요소를 3개의 범주로 나누고, 각 범주별로 숫자를 메김 (image: 1, graphic: 2, text: 3)
- 특수 tokens
3.1.2 Text Representation
- Text context: Text 요소 내의 추출된 정보
- Image labels: Google Vision API를 활용하여 object detection의 category 정보
- Embedding model: CLIP text encoder
3.2 Multimodal masked color model
-
모델 구조
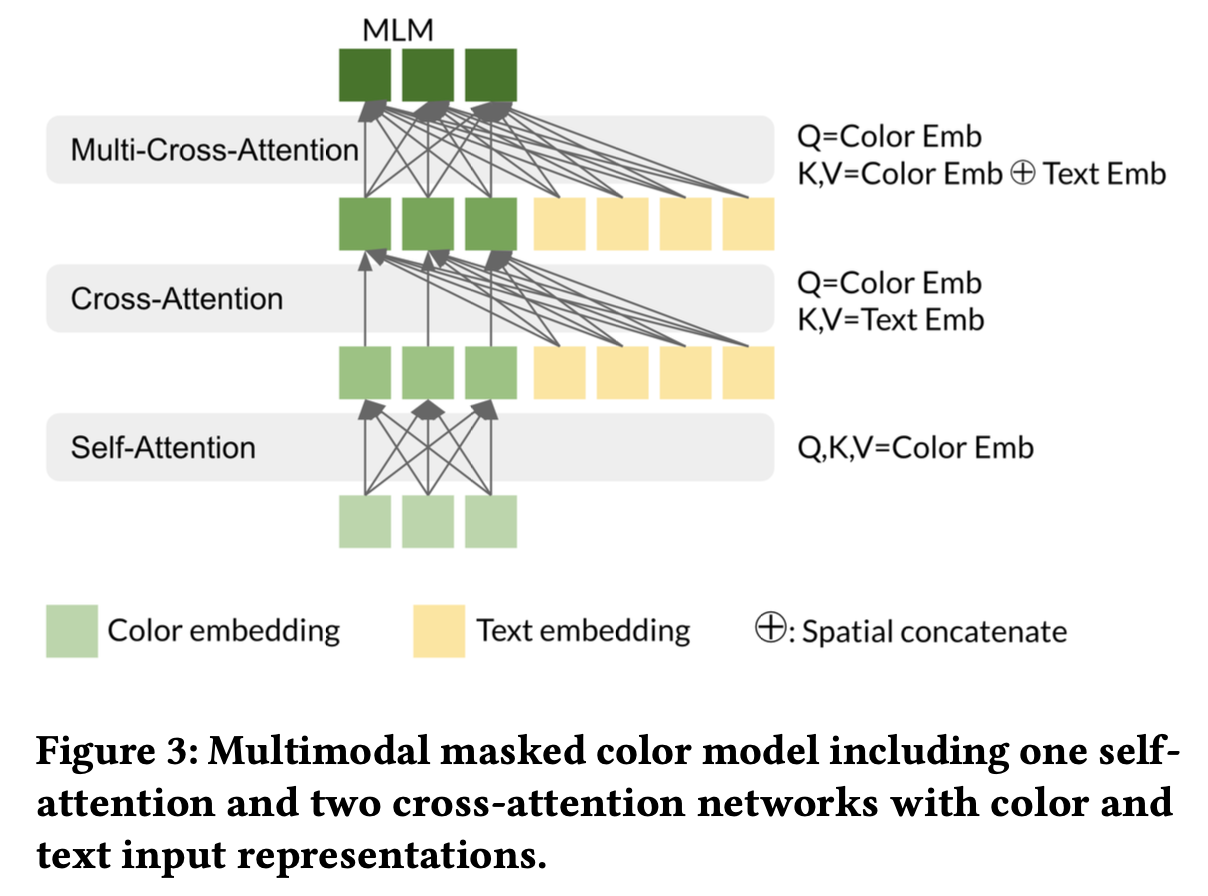
- self-attention: palette내 color 간, 다른 palette에 속한 color간의 관계를 학습
- $c={c_1, c_2, …, c_N}$: N개의 input color embeddings.
- $Q_{sa}=K_{sa}=V_{sa}=c$
- cross-attention: color + text간의 관계를 학습 (Color-palette recommendation)
- $t={t_1, t_2, …, t_M}$: M개의 textual phrases
- $Q_{ca}=O_{sa}, K_{ca}=V_{ca}=t$
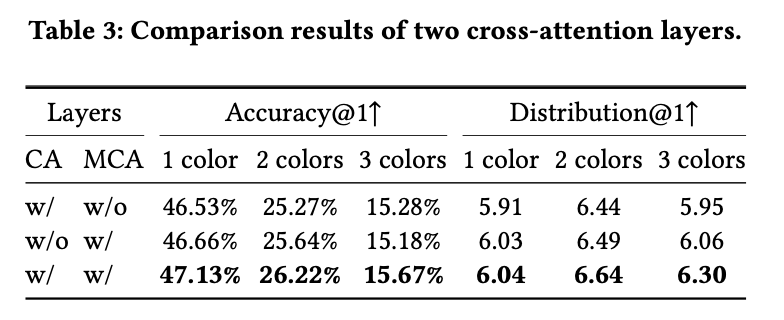
- Multi cross-attention: color, text간의 inter / intra relation을 학습
- $Q_{mca}=O_{ca}, K_{mca}=V_{mca}=concat(O_{ca}, t)$
- self-attention: palette내 color 간, 다른 palette에 속한 color간의 관계를 학습
-
학습 방법
- MLM (Masked Language Model)처럼 color embedding을 randomly mask (40%)하여 복원하게 학습
- Cross entrophy loss로 학습
4. Experiments
4.1 Color palette completion
-
Eval Metrics
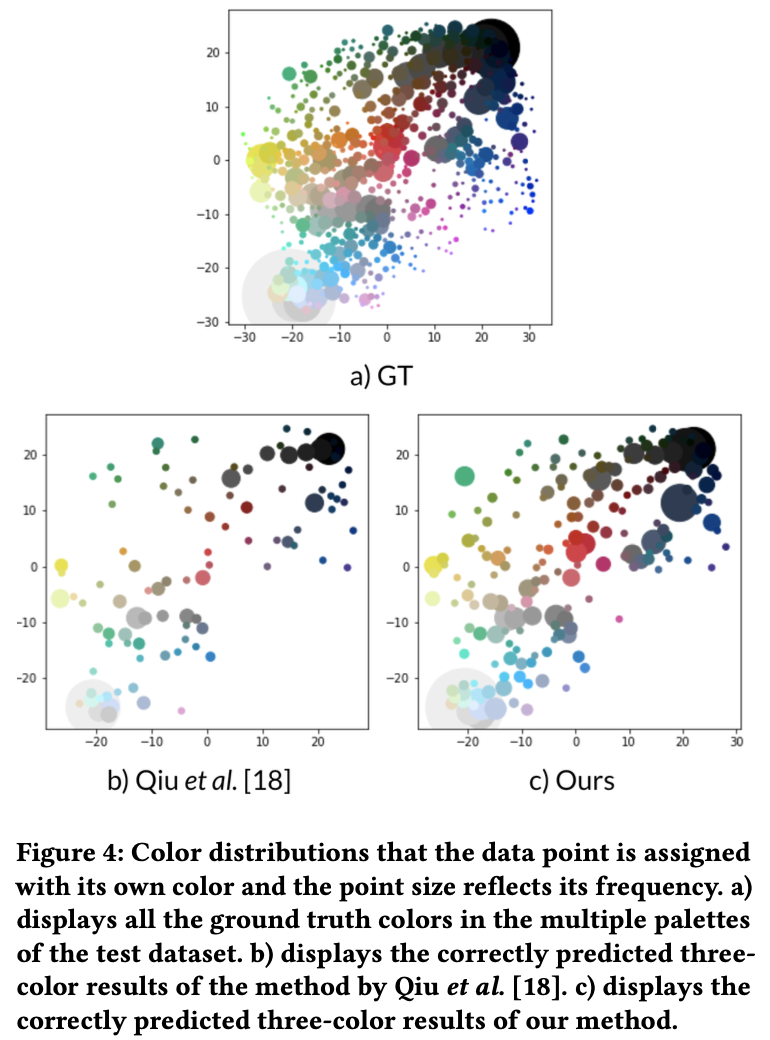
- Distribution: 흰/검 색상이 많은 특성상, 두 색상외 색상을 내뱉는 것이 중요함 $\to$ 색상을 맞춘 prediciton case들의 color distribution을 모두 뽑아 Shannon entropy로 다양함을 표현
- Accuracy: Recall@1로 표현
-
Dataset: Crello-v2 dataset
- train / val / test = 14,020 / 1,704 / 1,712
- Palette내 최대 color 수: 5개
- Text phrase 최대 수: 10개
-
정량적 결과
-
Accuracy

-
Distribution
-
-
정성적 결과

-
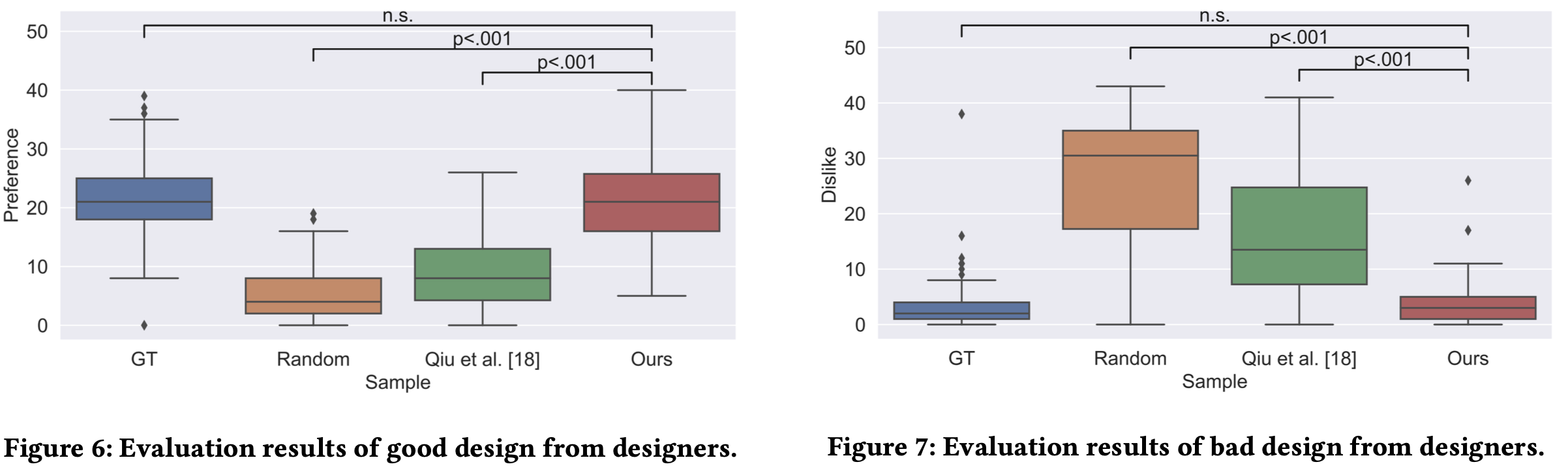
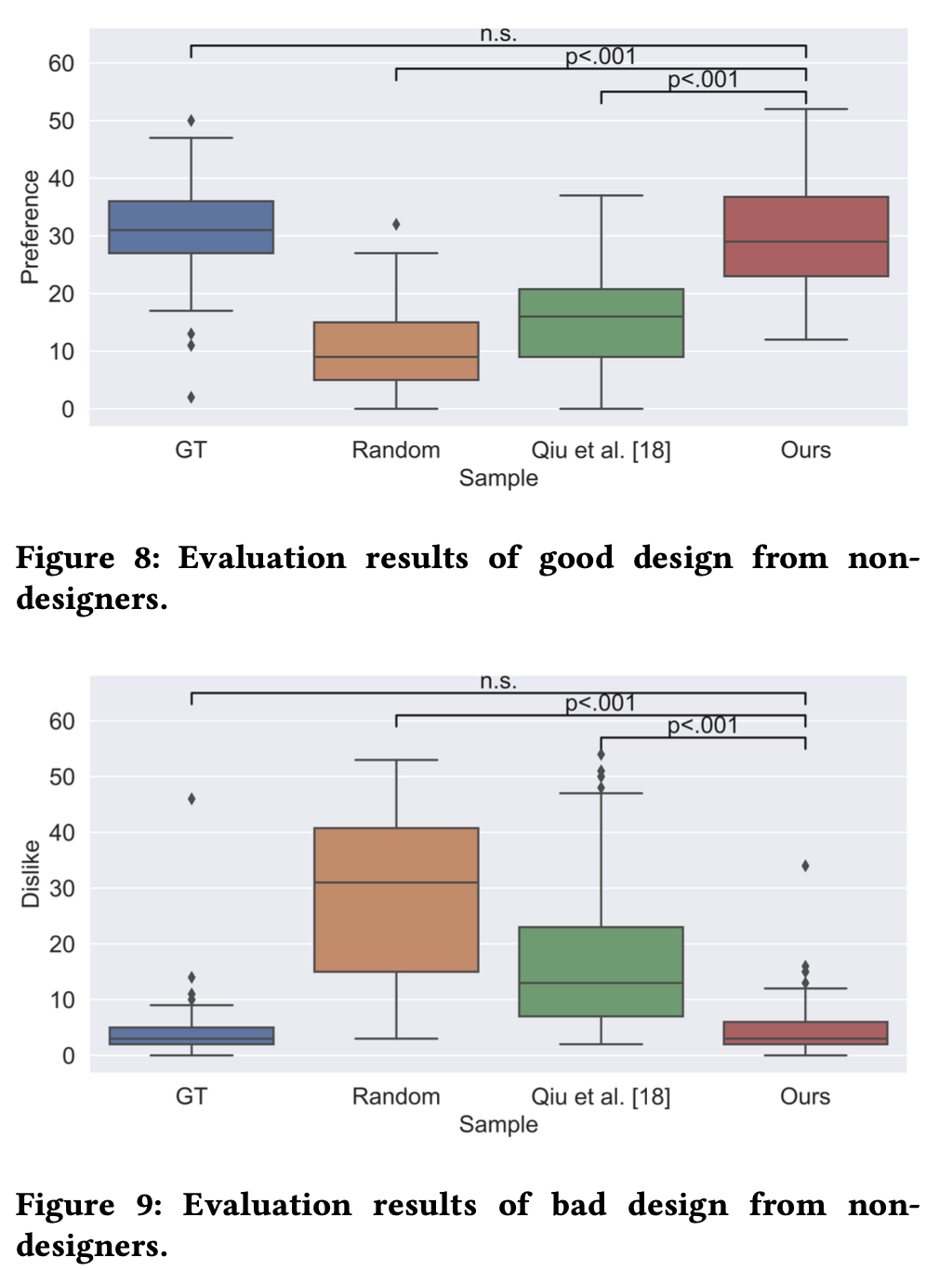
106명을 고용하여 만족도를 분석 (Non designers: 63명, Designers: 43명)
- GT > Ours > Qiu et. al > Random
-
-
Ablation studies
-
With & Without text embeddings / color ordering
-
With & Without Cross attention / Multi cross attention layer
-
Text embedding model: Clip vs. Bert
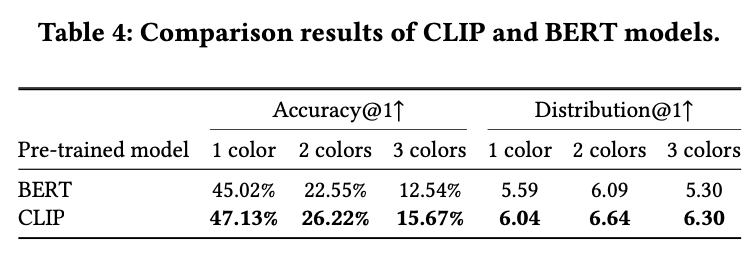
-
Masking rate에 따른 성능
-
1 color: 20% best
-
그 이상: 30~40% best
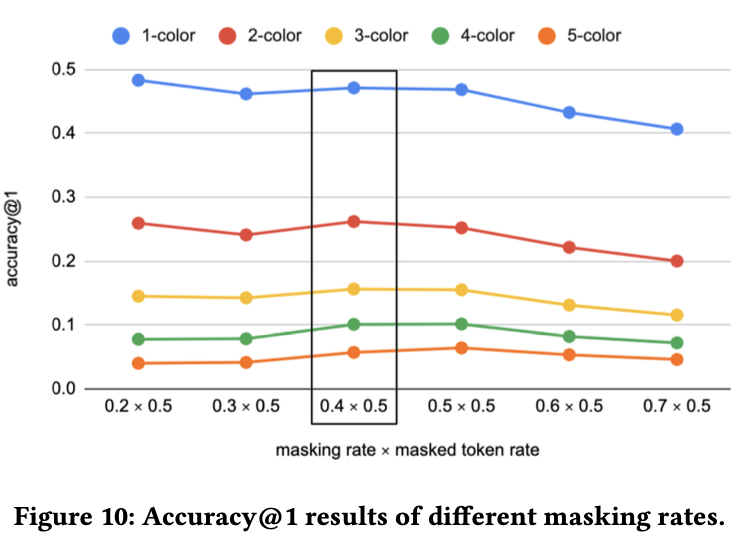
-
-
4.2 Full Palette Generation
-
Metric: DCCW (Dynamic Closest Color Wraping): 서로 다른 palette간의 minimum distance를 계산
-
Dataset: Palette-and-Text (PAT)
-
정량적 결과
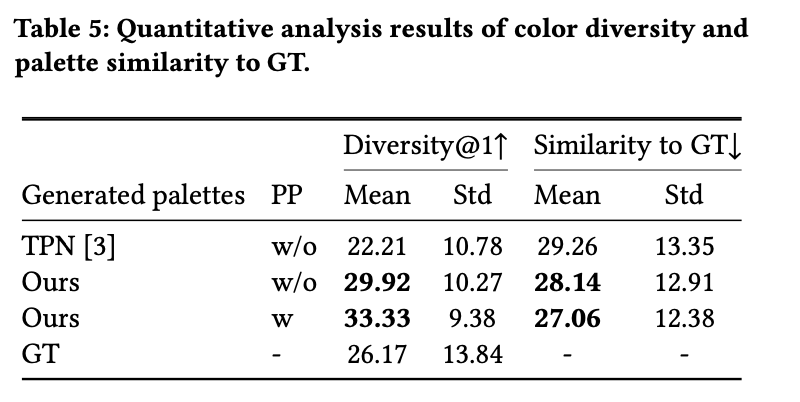
- PP: Post-processing. 겹치는 color를 1,2,3,4,5 순위에 추천 시, 다른 색이 나올때까지 반복
-
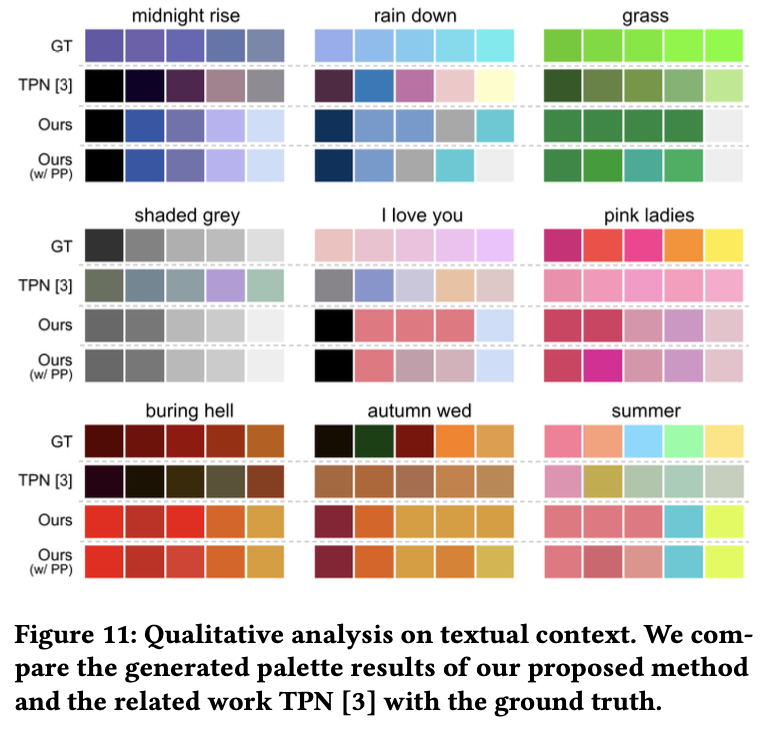
정성적 결과